【机器学习】应用KNN实现鸢尾花种类预测

目录
前言
一、K最近邻(KNN)介绍
二、鸢尾花数据集介绍
三、鸢尾花数据集可视化
四、鸢尾花数据分析
总结
🌈嗨!我是Filotimo__🌈。很高兴与大家相识,希望我的博客能对你有所帮助。
💡本文由Filotimo__✍️原创,首发于CSDN📚。
📣如需转载,请事先与我联系以获得授权⚠️。
🎁欢迎大家给我点赞👍、收藏⭐️,并在留言区📝与我互动,这些都是我前进的动力!
🌟我的格言:森林草木都有自己认为对的角度🌟。


前言
机器学习是一项快速发展的领域,其中K-最近邻算法(K-Nearest Neighbors,简称KNN)是一个经典且常用的算法,可以用于分类和回归问题。在本文中,我们将介绍如何使用KNN算法来实现鸢尾花种类的预测。
一、K最近邻(KNN)介绍
原理:
KNN算法的核心思想是通过计算样本之间的距离来度量它们的相似性。对于分类任务,当给定一个未知样本时,算法会找到与该样本距离最近的K个已知样本,然后根据这K个已知样本的类别标签来预测未知样本的类别。常见的距离度量方法包括欧氏距离、曼哈顿距离、闵可夫斯基距离等。
使用场景:
KNN算法在许多实际应用中被广泛使用,特别是在以下场景中表现出良好的性能:
1.数据集中类别分布均匀、样本点较为离散的情况下,KNN的效果较好。
2.数据集规模较小的情况下,KNN的计算速度较快。
3.对异常值不敏感,可以处理噪声较多的数据集。
相关术语:
K值:K是KNN算法中的一个超参数,用于指定要考虑的最近邻居的个数。选择合适的K值是KNN算法的重要部分,通常通过交叉验证或网格搜索进行选择。
距离度量:KNN算法使用距离度量来评估样本之间的相似性。常见的距离度量方法有欧氏距离、曼哈顿距离、闵可夫斯基距离等。
预测和决策规则:对于分类任务,KNN算法中常用的决策规则是投票法,即选择K个邻居中出现最频繁的类别作为预测类别。对于回归任务,通常使用K个邻居的平均值来进行预测。
超参数选择:KNN算法中常见的超参数有K值和距离度量方法等。选择合适的超参数对模型的性能和准确度至关重要,常用的方法是通过交叉验证或网格搜索来选择最佳超参数组合。
基本流程:
1.加载数据集,划分为训练集和测试集。
2.根据训练集计算样本之间的距离。
3.选择K值,并找到距离未知样本最近的K个样本。
4.使用投票法或平均值法来预测未知样本的类别或数值。
5.评估模型在测试集上的性能和准确度。
6.根据需要调整超参数K和距离度量方法,并重新训练和评估模型。
优化模型性能:
1.特征选择和特征工程:选择与分类或回归任务相关的有效特征,并对数据进行预处理和归一化处理,以减少特征间的差异性。
2.调整K值:选择合适的K值很重要,若选择较小的K值容易受到噪声干扰,而较大的K值容易忽略局部特征,因此应通过交叉验证等方法选择最佳K值。
3.距离度量方法的选择:根据实际情况选择适当的距离度量方法,如曼哈顿距离适用于处理具有非连续特征的数据,而欧氏距离适用于处理连续特征的数据。
4.数据预处理:对数据进行特征缩放、离群值处理等预处理步骤,以提高模型的鲁棒性和准确性。
5.交叉验证和模型评估:使用交叉验证来评估模型在不同数据集上的泛化能力,以选择最佳的模型。
6.集成学习:考虑使用集成学习方法,如投票集成或基于KNN的Bagging方法来进一步提升KNN算法的性能。
二、鸢尾花数据集介绍
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。
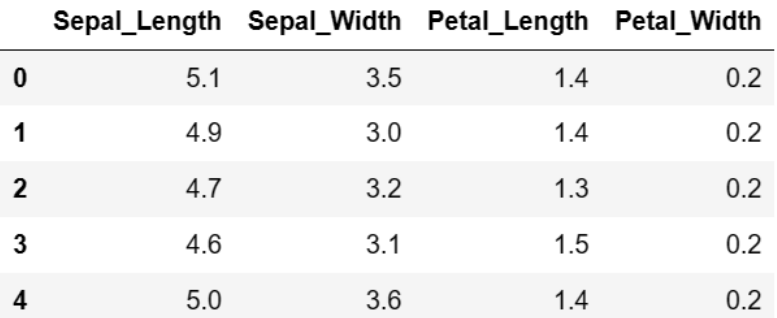
数据集介绍:

数据集样例:
三、鸢尾花数据集可视化
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets import load_irisdef iris_plot(data, x_col, y_col):sns.lmplot(x=x_col, y=y_col, data=data, hue="target", fit_reg=False)plt.title("鸢尾花数据显示")plt.show()# 设置字体为中文黑体
plt.rcParams['font.sans-serif'] = ['SimHei']# 加载数据集
iris = load_iris()# 创建数据框
iris_df = pd.DataFrame(data=iris.data, columns=['Sepal_Length', 'Sepal_Width', 'Petal_Length', 'Petal_Width'])
iris_df["target"] = iris.target# 绘制图表
iris_plot(iris_df, 'Sepal_Width', 'Petal_Length')我们使用了 seaborn 库和 matplotlib 库进行绘制。在绘制之前,先加载了鸢尾花数据集,并将其转换为数据框格式。然后定义了一个 iris_plot 函数,用于绘制散点图。最后调用该函数,以花萼宽度和花瓣长度作为 x 轴和 y 轴绘制。也就是将数据集中的样本点按照花瓣长度和花萼宽度两个指标在二维坐标系上进行了展示,并且以不同颜色对应不同类型的鸢尾花。

四、鸢尾花数据分析
import pandas as pd
import joblib
import osfrom sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaleriris = load_iris()
X = iris.data
y = iris.targetx_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)param_grid = {"n_neighbors": [1, 3, 5, 7]}
estimator = KNeighborsClassifier()
grid_search = GridSearchCV(estimator, param_grid=param_grid, cv=5)
grid_search.fit(x_train, y_train)estimator = grid_search.best_estimator_if not os.path.exists("./model"):os.makedirs("./model")joblib.dump(estimator, "./model/model.pkl")
estimator = joblib.load("./model/model.pkl")y_pred = estimator.predict(x_test)
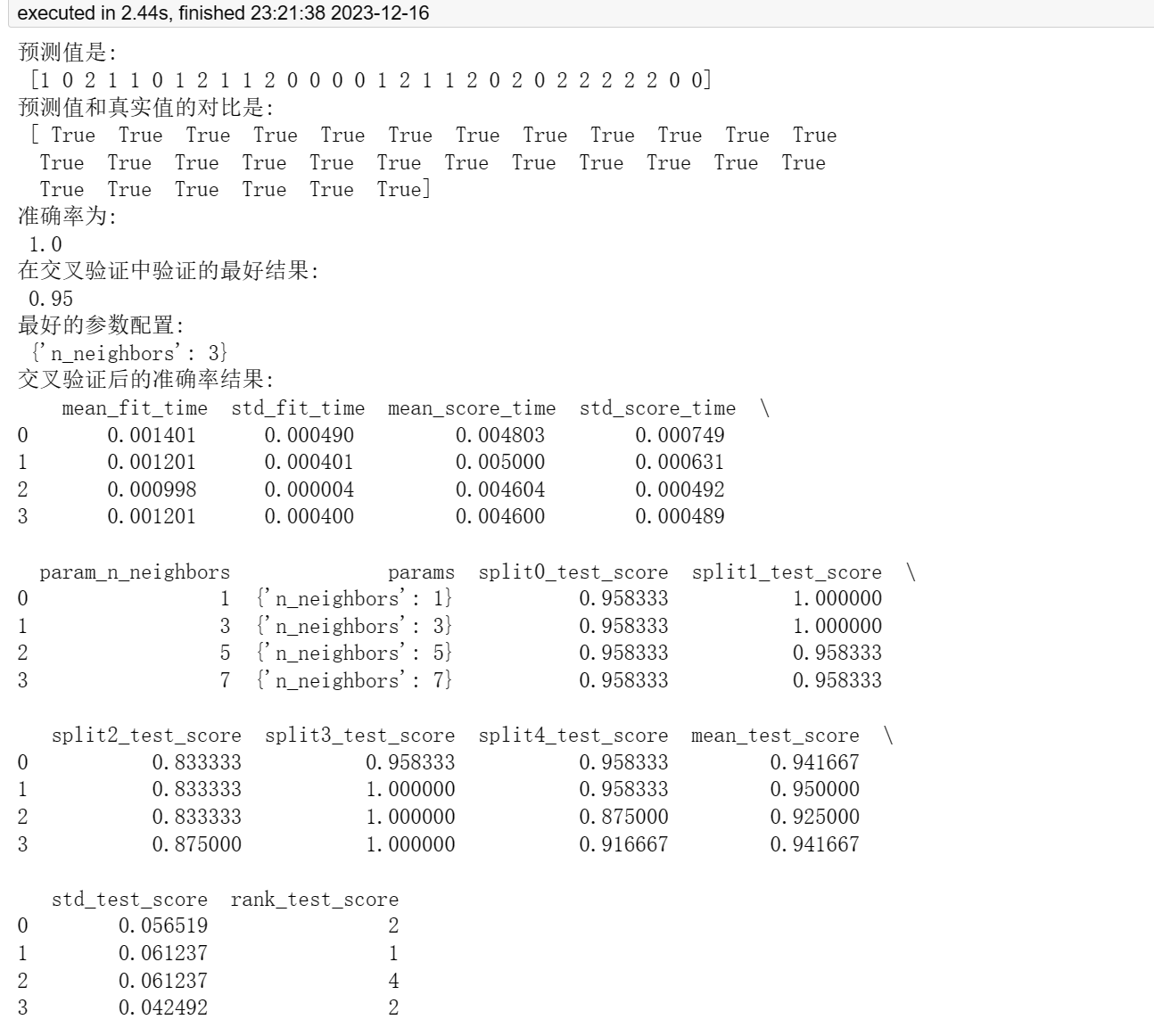
print("预测值是:\n", y_pred)
print("预测值和真实值的对比是:\n", y_pred == y_test)score = estimator.score(x_test, y_test)
print("准确率为: \n", score)print("在交叉验证中验证的最好结果:\n", grid_search.best_score_)
print("最好的参数配置:\n", grid_search.best_params_)
cv_results = pd.DataFrame(grid_search.cv_results_)
print("交叉验证后的准确率结果:\n", cv_results)使用 K 最近邻算法对鸢尾花数据集进行分类。
我们主要使用了 pandas、joblib、os、sklearn 中的一些模块和函数。
我们首先加载鸢尾花数据集,然后将数据集分为训练集和测试集。接下来对训练集和测试集进行了特征标准化处理,使用了 StandardScaler 类对数据进行标准化。
然后定义一个参数网格 param_grid,用于指定超参数 n_neighbors 的取值。创建一个 KNeighborsClassifier 估计器,用于训练和预测。通过 GridSearchCV 类对模型进行了交叉验证和参数调优,并选出了最佳的模型估计器。
通过 joblib 模块将最佳的模型保存到./model/model.pkl文件中,并再次加载该模型。
利用这个模型对测试集进行预测,并计算准确率。同时打印了预测值、预测值和真实值的对比结果,交叉验证后的最佳得分和最佳参数配置。
使用 pd.DataFrame 将交叉验证的结果转换为数据框格式,并打印交叉验证后的准确率结果。
我们可以通过这段代码可以了解到如何使用 K 最近邻算法对数据集进行分类,并使用网格搜索和交叉验证对模型进行参数调优。
总结
在本文中,我们学习了如何使用KNN算法来预测鸢尾花的种类。我们首先进行了数据准备和预处理,然后实现了KNN算法,并通过评估指标对模型进行了评估。KNN算法是一种简单而有效的算法,在处理小型数据集和简单分类问题时可以发挥很好的作用。
相关文章:
【机器学习】应用KNN实现鸢尾花种类预测
目录 前言 一、K最近邻(KNN)介绍 二、鸢尾花数据集介绍 三、鸢尾花数据集可视化 四、鸢尾花数据分析 总结 🌈嗨!我是Filotimo__🌈。很高兴与大家相识,希望我的博客能对你有所帮助。 💡本文由Fil…...

ACL和NAT
目录 一.ACL 1.概念 2.原理 3.应用 4.种类 5.通配符 1.命令 2.区别 3.例题 4.应用原则 6.实验 1.实验目的 2.实验拓扑 3.实验步骤 7.实验拓展 1.实验目的 2.实验步骤 3.测试 二.NAT 1.基本理论 2.作用 3.分类 静态nat 动态nat NATPT NAT Sever Easy-IP…...

MX6ULL学习笔记(十二)Linux 自带的 LED 灯
前言 前面我们都是自己编写 LED 灯驱动,其实像 LED 灯这样非常基础的设备驱动,Linux 内 核已经集成了。Linux 内核的 LED 灯驱动采用 platform 框架,因此我们只需要按照要求在设备 树文件中添加相应的 LED 节点即可,本章我们就来学…...

Qt容器QToolBox工具箱
# QToolBox QToolBox是Qt框架中的一个窗口容器类,常用的几个函数有: setCurrentIndex(int index):设置当前显示的页面索引。可以通过调用该函数,将指定索引的页面设置为当前显示的页面。 addItem(QWidget * widget, const QString & text):向QToolBox中添加一个页面…...

华为实训课笔记
华为实训 12/1312/14 12/13 ping 基于ICMP协议,用来进行可达性测试 ping 目的IP地址/设备域名(主机名) 如果能收到 reply 回复,则表示双方可以正常通信 <Huawei> 用户视图,只能做查询和一些简单的资源调用&…...
基于java 的经济开发区管理系统设计与实现(源码+调试)
项目描述 临近学期结束,还是毕业设计,你还在做java程序网络编程,期末作业,老师的作业要求觉得大了吗?不知道毕业设计该怎么办?网页功能的数量是否太多?没有合适的类型或系统?等等。今天给大家介绍一篇基于java 的经济开发区管…...

外包干了3个月,技术退步明显。。。
先说一下自己的情况,本科生生,19年通过校招进入广州某软件公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测…...
详细教程 - 从零开发 Vue 鸿蒙harmonyOS应用 第一节
关于使用Vue开发鸿蒙应用的教程,我这篇之前的博客还不够完整和详细。那么这次我会尝试写一个更加完整和逐步的指南,从环境准备,到目录结构,再到关键代码讲解,以及调试和发布等,希望可以让大家详实地掌握这个过程。 一、准备工作 下载安装 DevEco Studio 下载地址:…...

R语言对医学中的自然语言(NLP)进行机器学习处理(1)
什么是自然语言(NLP),就是网络中的一些书面文本。对于医疗方面,例如医疗记录、病人反馈、医生业绩评估和社交媒体评论,可以成为帮助临床决策和提高质量的丰富数据来源。如互联网上有基于文本的数据(例如,对医疗保健提供者的社交媒体评论),这些数据我们可…...

什么是CI/CD?如何在PHP项目中实施CI/CD?
CI/CD(持续集成/持续交付或持续部署)是一种软件开发和交付方法,它旨在通过自动化和持续集成来提高开发速度和交付质量。以下是CI/CD的基本概念和如何在PHP项目中实施它的一般步骤: 持续集成(Continuous Integration -…...
:容器指令、生命周期、资源限制、容器化支持、常用命令)
玩转Docker(四):容器指令、生命周期、资源限制、容器化支持、常用命令
文章目录 一、容器指令1.运行2.启动/停止/重启3.暂停/恢复4.删除 二、生命周期三、资源限制1.内存限额2.CPU限额3.磁盘读写带宽限额 四、cgroup和namespace五、常用命令 一、容器指令 1.运行 按用途容器大致可分为两类:服务类容器和工具类的容器。 服务类容器&am…...
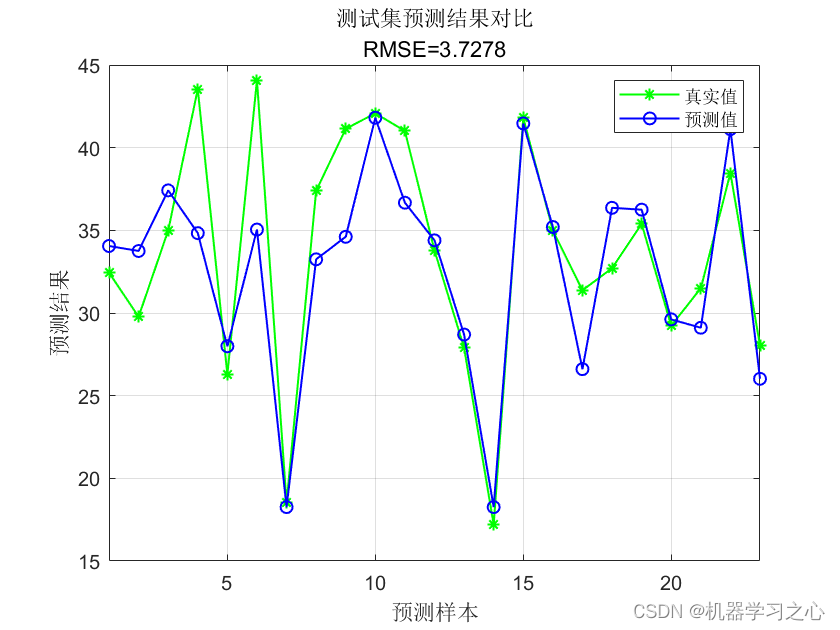
回归预测 | MATLAB实现CHOA-BiLSTM黑猩猩优化算法优化双向长短期记忆网络回归预测 (多指标,多图)
回归预测 | MATLAB实现CHOA-BiLSTM黑猩猩优化算法优化双向长短期记忆网络回归预测 (多指标,多图) 目录 回归预测 | MATLAB实现CHOA-BiLSTM黑猩猩优化算法优化双向长短期记忆网络回归预测 (多指标,多图)效果…...

Qt/C++视频监控安卓版/多通道显示视频画面/录像存储/视频播放安卓版/ffmpeg安卓
一、前言 随着监控行业的发展,越来越多的用户场景是需要在手机上查看监控,而之前主要的监控系统都是在PC端,毕竟PC端屏幕大,能够看到的画面多,解码性能也强劲。早期的手机估计性能弱鸡,而现在的手机性能不…...

【docker】容器使用(Nginx 示例)
查看 Docker 客户端命令选项 docker上面这三张图都是 常用命令: run 从映像创建并运行新容器exec 在运行的容器中执行命令ps 列出容器build 从Dockerfile构建映像pull 从注册表下载图像push 将图像上载到注册表…...
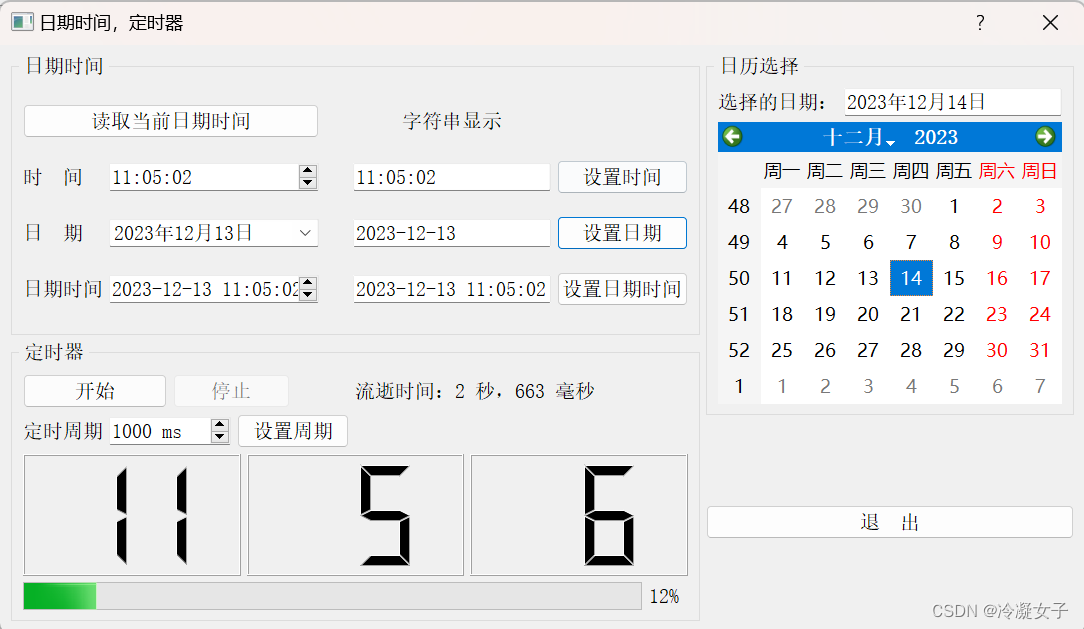
【QT】时间日期与定时器
目录 1.时间日期相关的类 2.日期时间数据与字符串之间的转换 2.1 时间、日期编辑器属性设置 2.2 日期时间数据的获取与转换为字符串 2.3 字符串转换为日期时间 3.QCaIendarWidget日历组件 3.1基本属性 3.2 公共函数 3.3 信号 4.实例程序演示时间日期与定时器的使用 …...

蓝桥杯专题-真题版含答案-【古代赌局】【古堡算式】【微生物增殖】【密码发生器】
Unity3D特效百例案例项目实战源码Android-Unity实战问题汇总游戏脚本-辅助自动化Android控件全解手册再战Android系列Scratch编程案例软考全系列Unity3D学习专栏蓝桥系列ChatGPT和AIGC 👉关于作者 专注于Android/Unity和各种游戏开发技巧,以及各种资源分…...

和鲸科技携手深圳数据交易所,“数据+数据开发者生态”赋能人工智能产业发展
信息化时代,数据驱动决策的重要性日益凸显。通过利用数据可以深入了解市场需求、客户行为、竞争态势等关键信息,从而制定更为有效的战略和决策。围绕推动数据要素产业发展,近日,深圳数据交易所(以下简称“深数所”&…...
中 CreateThread函数)
在MFC(Microsoft Foundation Classes)中 CreateThread函数
CreateThread是Windows API中用于创建新线程的函数。以下是对函数参数的详细解释: lpThreadAttributes(可选):指向SECURITY_ATTRIBUTES结构的指针,用于指定线程的安全性。可以设置为NULL,表示使用默认安全…...
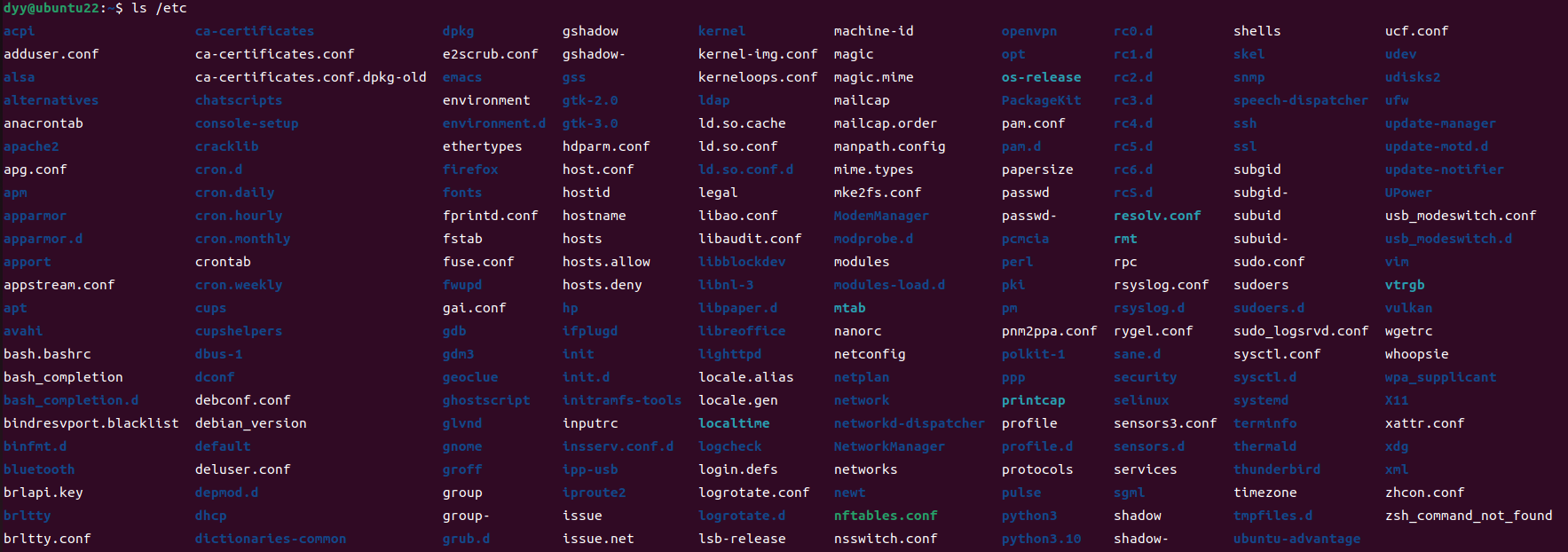
Ubuntu 常用命令之 ls 命令用法介绍
Ubuntu ls 命令用法介绍 ls是Linux系统下的一个基本命令,用于列出目录中的文件和子目录。它有许多选项可以用来改变列出的内容和格式。 以下是一些基本的ls命令选项 -l:以长格式列出文件,包括文件类型、权限、链接数、所有者、组、大小、最…...
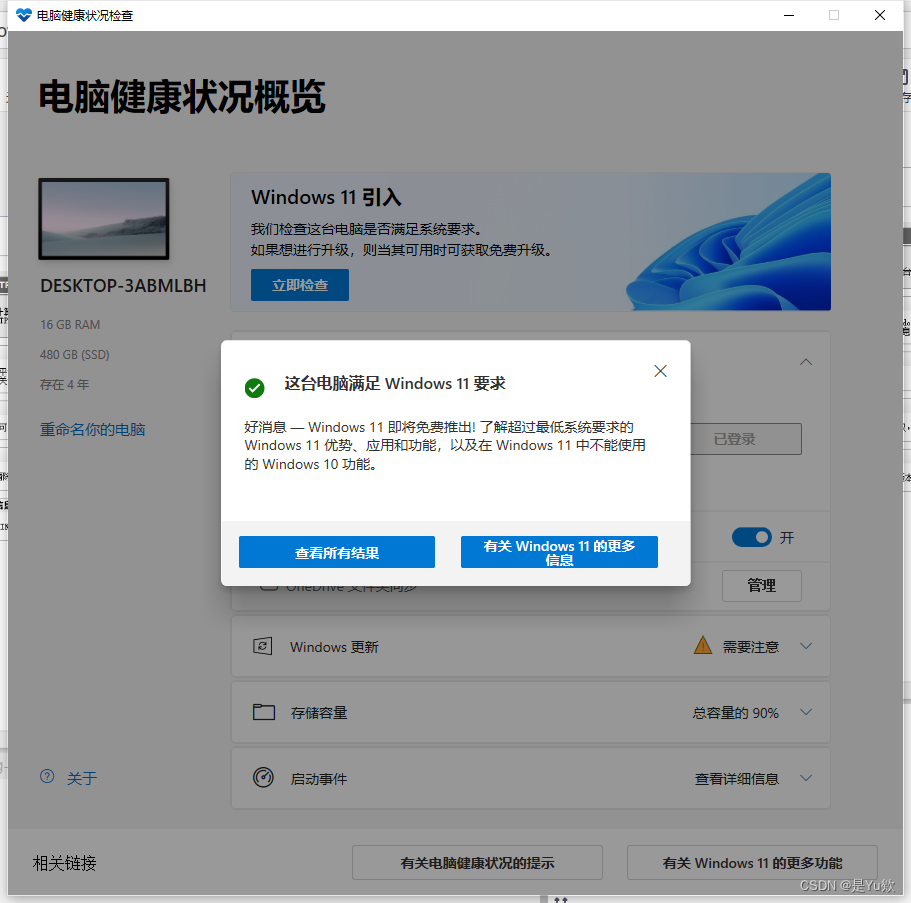
【解决】Windows 11检测提示电脑不支持 TPM 2.0(注意从DTPM改为PTT)
win11升级,tpm不兼容 写在最前面1. 打开电脑健康状况检查2. 开启tpm3. 微星主板AMD平台开启TPM2.0解决电脑健康状况检查显示可以安装win11,但是系统更新里显示无法更新 写在最前面 我想在台式电脑上用win11的专注模式,但win10不支持 1. 打…...

基于Terraform与Ansible的OpenClaw私有化AI代理自动化部署实践
1. 项目概述如果你和我一样,对AI助手的能力有更高的期待,希望它能深度融入你的工作流,甚至能帮你处理一些自动化任务,那么OpenClaw这个项目绝对值得你花时间研究。它不是一个简单的聊天机器人,而是一个可以部署在你私有…...

智能语音转文字终极指南:如何用AsrTools轻松完成音频转字幕
智能语音转文字终极指南:如何用AsrTools轻松完成音频转字幕 【免费下载链接】AsrTools ✨ AsrTools: Smart Voice-to-Text Tool | Efficient Batch Processing | User-Friendly Interface | No GPU Required | Supports SRT/TXT Output | Turn your audio into accu…...

轻量级日志聚合器Shiplog:中小团队分布式日志管理实践
1. 项目概述:一个为开发者打造的轻量级日志聚合器如果你是一名后端开发者,或者正在维护一个分布式微服务系统,那么对“日志”这个词一定又爱又恨。爱的是,它是排查线上问题的唯一“时光机”;恨的是,当服务实…...

ZYNQ实战:从零构建uCOSIII最小系统与BSP配置详解
1. 环境准备与硬件设计 第一次在ZYNQ上跑uCOSIII时,我踩了不少坑。记得当时为了找个靠谱的参考文档,翻遍了国内外论坛。现在回头看,其实只要硬件配置对了,软件移植就是水到渠成的事。咱们先从最基础的Vivado工程搭建说起。 我用的…...

3分钟掌握PC端聊天软件防撤回:RevokeMsgPatcher实战指南
3分钟掌握PC端聊天软件防撤回:RevokeMsgPatcher实战指南 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitcode.…...

免费开源运动分析神器:Kinovea 完全指南
免费开源运动分析神器:Kinovea 完全指南 【免费下载链接】Kinovea Video solution for sport analysis. Capture, inspect, compare, annotate and measure technical performances. 项目地址: https://gitcode.com/gh_mirrors/ki/Kinovea Kinovea 是一款功…...

如何轻松备份微信聊天记录:iOS用户的终极解决方案
如何轻松备份微信聊天记录:iOS用户的终极解决方案 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾经因为手机损坏或更换设备而丢失了珍贵的微信聊天记…...

深度解析20辆电动汽车29个月真实充电数据:电池容量衰减评估与健康监测关键技术
深度解析20辆电动汽车29个月真实充电数据:电池容量衰减评估与健康监测关键技术 【免费下载链接】battery-charging-data-of-on-road-electric-vehicles This repository is transfered from the personal account of Dr. Zhognwei Deng (Michael Teng) 项目地址: …...
)
Claude 3 Haiku性能白皮书首发(含AWS Inferentia2 vs NVIDIA T4实测对比数据)
更多请点击: https://intelliparadigm.com 第一章:Claude 3 Haiku性能白皮书首发概览 Anthropic 正式发布 Claude 3 系列中最轻量、响应最快的基础模型——Claude 3 Haiku,并同步公开首份面向开发者与企业用户的《Claude 3 Haiku 性能白皮书…...

Fillinger智能填充算法深度解析:从三角剖分到工程化实现
Fillinger智能填充算法深度解析:从三角剖分到工程化实现 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 在矢量图形设计领域,复杂形状内的元素填充是一个常见…...