html.parser --- 简单的 HTML 和 XHTML 解析器
源代码: Lib/html/parser.py
这个模块定义了一个 HTMLParser 类,为 HTML(超文本标记语言)和 XHTML 文本文件解析提供基础。
class html.parser.HTMLParser(*, convert_charrefs=True)
创建一个能解析无效标记的解析器实例。
如果 convert_charrefs 为 True (默认值),则所有字符引用( script/style 元素中的除外)都会自动转换为相应的 Unicode 字符。
一个 HTMLParser 类的实例用来接受 HTML 数据,并在标记开始、标记结束、文本、注释和其他元素标记出现的时候调用对应的方法。要实现具体的行为,请使用 HTMLParser 的子类并重载其方法。
这个解析器不检查结束标记是否与开始标记匹配,也不会因外层元素完毕而隐式关闭了的元素引发结束标记处理。
在 3.4 版更改: convert_charrefs 关键字参数被添加。
在 3.5 版更改: convert_charrefs 参数的默认值现在为 True。
HTML 解析器的示例程序
下面是简单的 HTML 解析器的一个基本示例,使用 HTMLParser 类,当遇到开始标记、结束标记以及数据的时候将内容打印出来。
from html.parser import HTMLParserclass MyHTMLParser(HTMLParser):def handle_starttag(self, tag, attrs):print("Encountered a start tag:", tag)def handle_endtag(self, tag):print("Encountered an end tag :", tag)def handle_data(self, data):print("Encountered some data :", data)parser = MyHTMLParser()
parser.feed('<html><head><title>Test</title></head>''<body><h1>Parse me!</h1></body></html>')
输出是:
Encountered a start tag: html Encountered a start tag: head Encountered a start tag: title Encountered some data : Test Encountered an end tag : title Encountered an end tag : head Encountered a start tag: body Encountered a start tag: h1 Encountered some data : Parse me! Encountered an end tag : h1 Encountered an end tag : body Encountered an end tag : html
HTMLParser 方法
HTMLParser 实例有下列方法:
HTMLParser.feed(data)
填充一些文本到解析器中。如果包含完整的元素,则被处理;如果数据不完整,将被缓冲直到更多的数据被填充,或者 close() 被调用。data 必须为 str 类型。
HTMLParser.close()
如同后面跟着一个文件结束标记一样,强制处理所有缓冲数据。这个方法能被派生类重新定义,用于在输入的末尾定义附加处理,但是重定义的版本应当始终调用基类 HTMLParser 的 close() 方法。
HTMLParser.reset()
重置实例。丢失所有未处理的数据。在实例化阶段被隐式调用。
HTMLParser.getpos()
返回当前行号和偏移值。
HTMLParser.get_starttag_text()
返回最近打开的开始标记中的文本。 结构化处理时通常应该不需要这个,但在处理“已部署”的 HTML 或是在以最小改变来重新生成输入时可能会有用处(例如可以保留属性间的空格等)。
下列方法将在遇到数据或者标记元素的时候被调用。他们需要在子类中重载。基类的实现中没有任何实际操作(除了 handle_startendtag() ):
HTMLParser.handle_starttag(tag, attrs)
调用此方法来处理一个元素的开始标记 (例如 <div id="main">)。
tag 参数是小写的标记名。attrs 参数是一个 (name, value) 形式的列表,包含了所有在标记的 <> 括号中找到的属性。name 转换为小写,value 的引号被去除,字符和实体引用都会被替换。
实例中,对于标签 <A HREF="https://www.cwi.nl/">,这个方法将以下列形式被调用 handle_starttag('a', [('href', 'https://www.cwi.nl/')]) 。
html.entities 中的所有实体引用,会被替换为属性值。
HTMLParser.handle_endtag(tag)
此方法被用来处理元素的结束标记(例如: </div> )。
tag 参数是小写的标签名。
HTMLParser.handle_startendtag(tag, attrs)
类似于 handle_starttag(), 只是在解析器遇到 XHTML 样式的空标记时被调用( <img ... />)。这个方法能被需要这种特殊词法信息的子类重载;默认实现仅简单调用 handle_starttag() 和 handle_endtag() 。
HTMLParser.handle_data(data)
这个方法被用来处理任意数据(例如:文本节点和 <script>...</script> 以及 <style>...</style> 中的内容)。
HTMLParser.handle_entityref(name)
这个方法被用于处理 &name; 形式的命名字符引用(例如 >),其中 name 是通用的实体引用(例如: 'gt')。如果 convert_charrefs 为 True,该方法永远不会被调用。
HTMLParser.handle_charref(name)
调用该方法来处理 &#NNN; 和 &#xNNN; 形式的十进制和十六进制数字字符引用。 例如,> 的等价十进制形式为 >,而十六进制形式则为 >;在这种情况下,该方法将收到 '62' 或 'x3E'。如果 convert_charrefs 为 True,则此方法永远不会被调用。
HTMLParser.handle_comment(data)
这个方法在遇到注释的时候被调用(例如: <!--comment--> )。
例如, <!-- comment --> 这个注释会用 ' comment ' 作为参数调用此方法。
Internet Explorer 条件注释(condcoms)的内容也被发送到这个方法,因此,对于 <!--[if IE 9]>IE9-specific content<![endif]--> ,这个方法将接收到 '[if IE 9]>IE9-specific content<![endif]' 。
HTMLParser.handle_decl(decl)
这个方法用来处理 HTML doctype 申明(例如 <!DOCTYPE html> )。
decl 形参为 <!...> 标记中的所有内容(例如: 'DOCTYPE html' )。
HTMLParser.handle_pi(data)
此方法在遇到处理指令的时候被调用。data 形参将包含整个处理指令。例如,对于处理指令 <?proc color='red'> ,这个方法将以 handle_pi("proc color='red'") 形式被调用。它旨在被派生类重载;基类实现中无任何实际操作。
备注
HTMLParser 类使用 SGML 语法规则处理指令。使用 '?' 结尾的 XHTML 处理指令将导致 '?' 包含在 data 中。
HTMLParser.unknown_decl(data)
当解析器读到无法识别的声明时,此方法被调用。
data 形参为 <![...]> 标记中的所有内容。某些时候对派生类的重载很有用。基类实现中无任何实际操作。
例子
下面的类实现了一个解析器,用于更多示例的演示:
from html.parser import HTMLParser
from html.entities import name2codepointclass MyHTMLParser(HTMLParser):def handle_starttag(self, tag, attrs):print("Start tag:", tag)for attr in attrs:print(" attr:", attr)def handle_endtag(self, tag):print("End tag :", tag)def handle_data(self, data):print("Data :", data)def handle_comment(self, data):print("Comment :", data)def handle_entityref(self, name):c = chr(name2codepoint[name])print("Named ent:", c)def handle_charref(self, name):if name.startswith('x'):c = chr(int(name[1:], 16))else:c = chr(int(name))print("Num ent :", c)def handle_decl(self, data):print("Decl :", data)parser = MyHTMLParser()
解析一个文档类型声明:
>>>
>>> parser.feed('<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" '
... '"http://www.w3.org/TR/html4/strict.dtd">')
Decl : DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"
解析一个具有一些属性和标题的元素:
>>>
>>> parser.feed('<img src="python-logo.png" alt="The Python logo">')
Start tag: imgattr: ('src', 'python-logo.png')attr: ('alt', 'The Python logo')
>>>
>>> parser.feed('<h1>Python</h1>')
Start tag: h1
Data : Python
End tag : h1
script 和 style 元素中的内容原样返回,无需进一步解析:
>>>
>>> parser.feed('<style type="text/css">#python { color: green }</style>')
Start tag: styleattr: ('type', 'text/css')
Data : #python { color: green }
End tag : style>>> parser.feed('<script type="text/javascript">'
... 'alert("<strong>hello!</strong>");</script>')
Start tag: scriptattr: ('type', 'text/javascript')
Data : alert("<strong>hello!</strong>");
End tag : script
解析注释:
>>>
>>> parser.feed('<!-- a comment -->'
... '<!--[if IE 9]>IE-specific content<![endif]-->')
Comment : a comment
Comment : [if IE 9]>IE-specific content<![endif]
解析命名或数字形式的字符引用,并把他们转换到正确的字符(注意:这 3 种转义都是 '>' ):
>>>
>>> parser.feed('>>>')
Named ent: >
Num ent : >
Num ent : >
填充不完整的块给 feed() 执行,handle_data() 可能会多次调用(除非 convert_charrefs 被设置为 True ):
>>>
>>> for chunk in ['<sp', 'an>buff', 'ered ', 'text</s', 'pan>']: ... parser.feed(chunk) ... Start tag: span Data : buff Data : ered Data : text End tag : span
解析无效的 HTML (例如:未引用的属性)也能正常运行:
>>>
>>> parser.feed('<p><a class=link href=#main>tag soup</p ></a>')
Start tag: p
Start tag: aattr: ('class', 'link')attr: ('href', '#main')
Data : tag soup
End tag : p
End tag : a相关文章:

html.parser --- 简单的 HTML 和 XHTML 解析器
源代码: Lib/html/parser.py 这个模块定义了一个 HTMLParser 类,为 HTML(超文本标记语言)和 XHTML 文本文件解析提供基础。 class html.parser.HTMLParser(*, convert_charrefsTrue) 创建一个能解析无效标记的解析器实例。 如果…...

赵传和源代码就是设计-UMLChina建模知识竞赛第4赛季第23轮
参考潘加宇在《软件方法》和UMLChina公众号文章中发表的内容作答。在本文下留言回答。 只要最先答对前3题,即可获得本轮优胜。第4题为附加题,对错不影响优胜者的判定,影响的是优胜者的得分。 所有题目的回答必须放在同一条消息中࿰…...
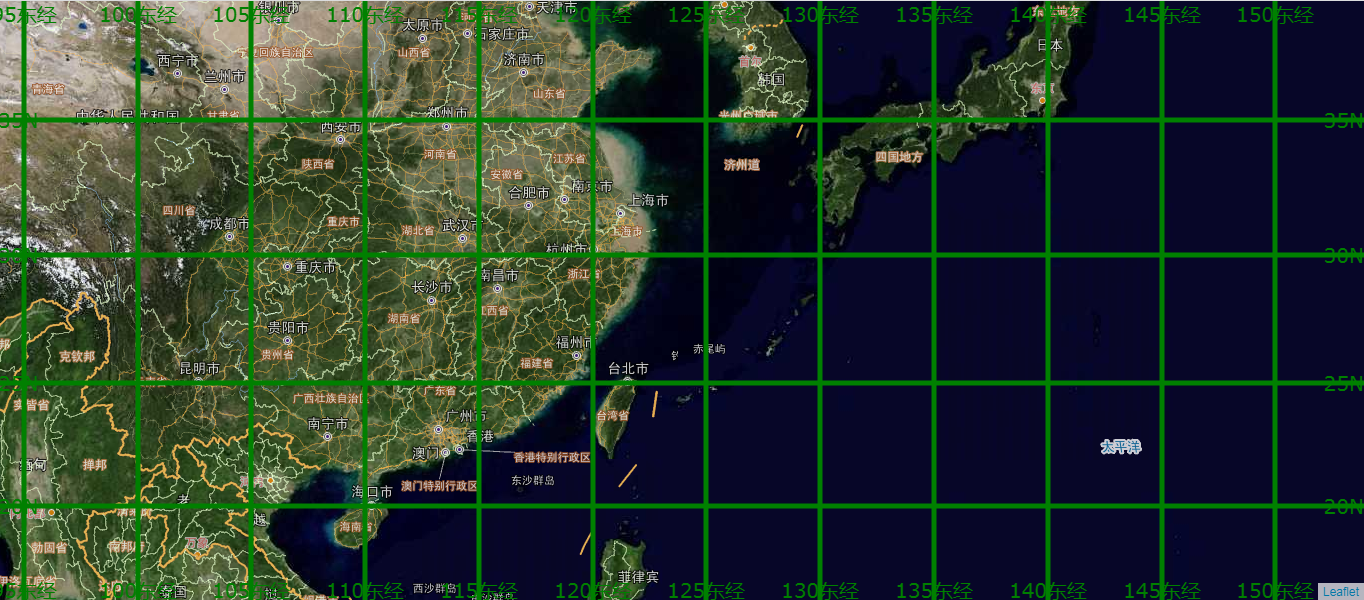
Leaflet.Graticule源码分析以及经纬度汉化展示
目录 前言 一、源码分析 1、类图设计 2、时序调用 3、调用说明 二、经纬度汉化 1、改造前 2、汉化 3、改造效果 总结 前言 在之前的博客基于Leaflet的Webgis经纬网格生成实践中,已经深入介绍了Leaflet.Graticule的实际使用方法和进行了简单的源码分析。认…...
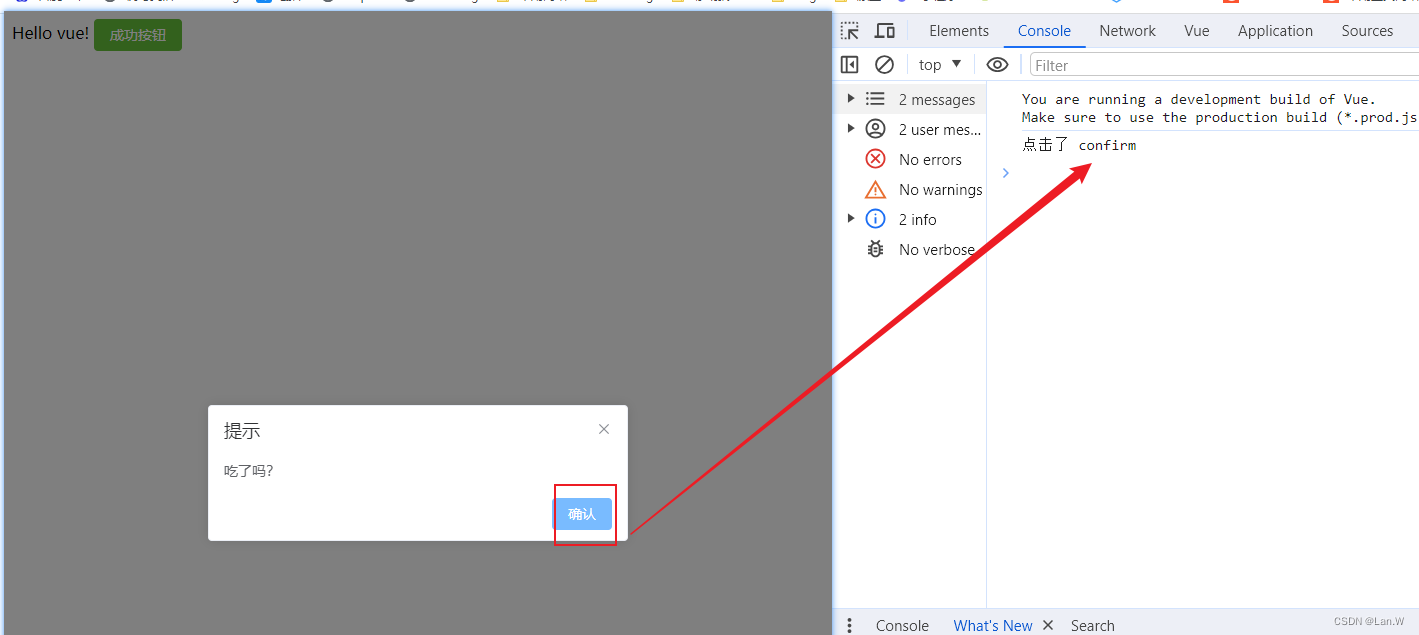
html 中vue3 的setup里调用element plus的弹窗 提示
引入Elementplus之后,在setup()方法外面导入ElMessageBox const {ElMessageBox} ElementPlus 源码 : <!DOCTYPE html> <html> <head><meta charset"UTF-8"><!-- import Vue before Elemen…...
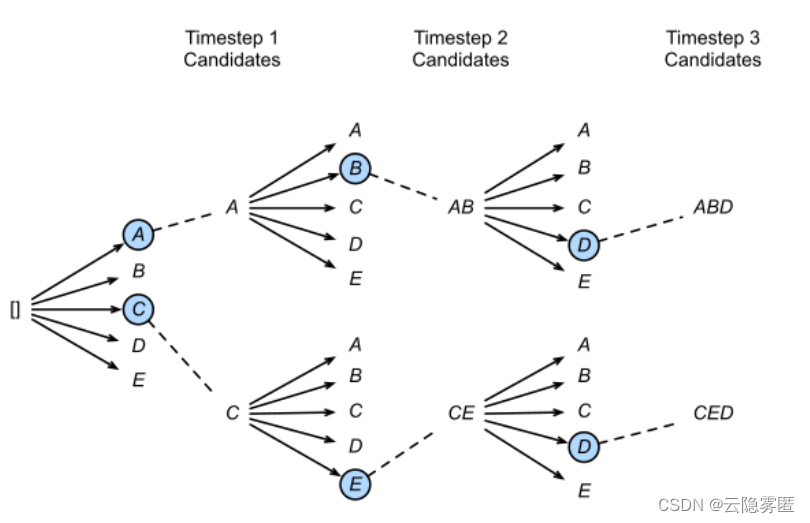
对话系统之解码策略(Top-k Top-p Temperature)
一、案例分析 在自然语言任务中,我们通常使用一个预训练的大模型(比如GPT)来根据给定的输入文本(比如一个开头或一个问题)生成输出文本(比如一个答案或一个结尾)。为了生成输出文本,…...
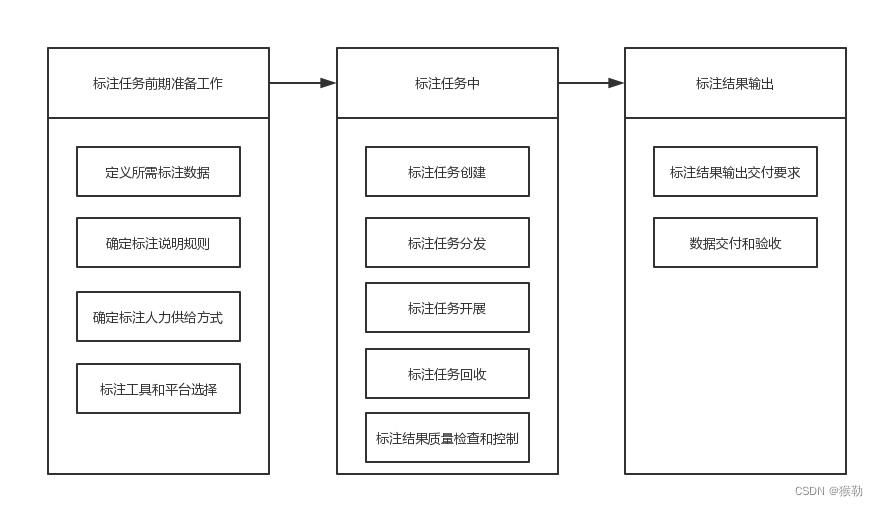
《面向机器学习的数据标注规程》摘录
说明:本文使用的标准是2019年的团体标准,最新的国家标准已在2023年发布。 3 术语和定义 3.2 标签 label 标识数据的特征、类别和属性等。 3.4 数据标注员 data labeler 对待标注数据进行整理、纠错、标记和批注等操作的工作人员。 【批注】按照定义…...

VGG(pytorch)
VGG:达到了传统串型结构深度的极限 学习VGG原理要了解CNN感受野的基础知识 model.py import torch.nn as nn import torch# official pretrain weights model_urls {vgg11: https://download.pytorch.org/models/vgg11-bbd30ac9.pth,vgg13: https://download.pytorch.org/mo…...

celery/schedules.py源码精读
BaseSchedule类 基础调度类,它定义了一些调度任务的基本属性和方法。以下是该类的主要部分的解释: __init__(self, nowfun: Callable | None None, app: Celery | None None):初始化方法,接受两个可选参数,nowfun表…...
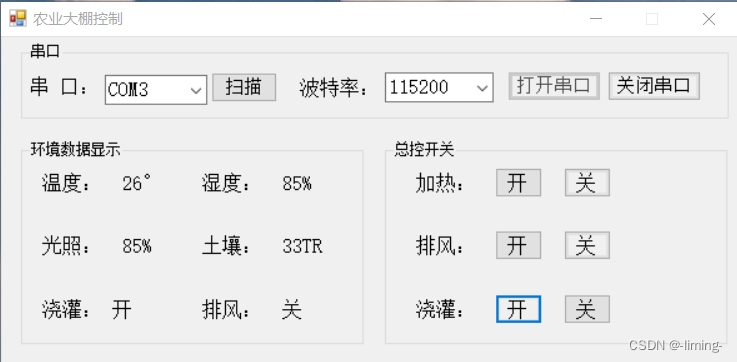
单片机上位机(串口通讯C#)
一、简介 用C#编写了几个单片机上位机模板。可定制!!! 二、效果图...

初识Flask
摆上中文版官方文档网站:https://flask.github.net.cn/quickstart.html 开启实验之路~~~~~~~~~~~~~ from flask import Flaskapp Flask(__name__) # 使用修饰器告诉flask触发函数的URL,绑定URL,后面的函数用于返回用户在浏览器上看到的内容…...

JeecgBoot jmreport/queryFieldBySql RCE漏洞复现
0x01 产品简介 Jeecg Boot(或者称为 Jeecg-Boot)是一款基于代码生成器的开源企业级快速开发平台,专注于开发后台管理系统、企业信息管理系统(MIS)等应用。它提供了一系列工具和模板,帮助开发者快速构建和部署现代化的 Web 应用程序。 0x02 漏洞概述 Jeecg Boot jmrepo…...
机器学习---模型评估
1、混淆矩阵 对以上混淆矩阵的解释: P:样本数据中的正例数。 N:样本数据中的负例数。 Y:通过模型预测出来的正例数。 N:通过模型预测出来的负例数。 True Positives:真阳性,表示实际是正样本预测成正样…...
【机器学习】应用KNN实现鸢尾花种类预测
目录 前言 一、K最近邻(KNN)介绍 二、鸢尾花数据集介绍 三、鸢尾花数据集可视化 四、鸢尾花数据分析 总结 🌈嗨!我是Filotimo__🌈。很高兴与大家相识,希望我的博客能对你有所帮助。 💡本文由Fil…...

ACL和NAT
目录 一.ACL 1.概念 2.原理 3.应用 4.种类 5.通配符 1.命令 2.区别 3.例题 4.应用原则 6.实验 1.实验目的 2.实验拓扑 3.实验步骤 7.实验拓展 1.实验目的 2.实验步骤 3.测试 二.NAT 1.基本理论 2.作用 3.分类 静态nat 动态nat NATPT NAT Sever Easy-IP…...

MX6ULL学习笔记(十二)Linux 自带的 LED 灯
前言 前面我们都是自己编写 LED 灯驱动,其实像 LED 灯这样非常基础的设备驱动,Linux 内 核已经集成了。Linux 内核的 LED 灯驱动采用 platform 框架,因此我们只需要按照要求在设备 树文件中添加相应的 LED 节点即可,本章我们就来学…...

Qt容器QToolBox工具箱
# QToolBox QToolBox是Qt框架中的一个窗口容器类,常用的几个函数有: setCurrentIndex(int index):设置当前显示的页面索引。可以通过调用该函数,将指定索引的页面设置为当前显示的页面。 addItem(QWidget * widget, const QString & text):向QToolBox中添加一个页面…...

华为实训课笔记
华为实训 12/1312/14 12/13 ping 基于ICMP协议,用来进行可达性测试 ping 目的IP地址/设备域名(主机名) 如果能收到 reply 回复,则表示双方可以正常通信 <Huawei> 用户视图,只能做查询和一些简单的资源调用&…...
基于java 的经济开发区管理系统设计与实现(源码+调试)
项目描述 临近学期结束,还是毕业设计,你还在做java程序网络编程,期末作业,老师的作业要求觉得大了吗?不知道毕业设计该怎么办?网页功能的数量是否太多?没有合适的类型或系统?等等。今天给大家介绍一篇基于java 的经济开发区管…...

外包干了3个月,技术退步明显。。。
先说一下自己的情况,本科生生,19年通过校招进入广州某软件公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测…...
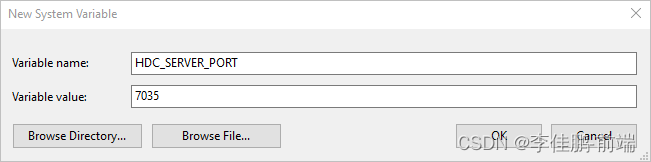
详细教程 - 从零开发 Vue 鸿蒙harmonyOS应用 第一节
关于使用Vue开发鸿蒙应用的教程,我这篇之前的博客还不够完整和详细。那么这次我会尝试写一个更加完整和逐步的指南,从环境准备,到目录结构,再到关键代码讲解,以及调试和发布等,希望可以让大家详实地掌握这个过程。 一、准备工作 下载安装 DevEco Studio 下载地址:…...

本地部署9B代码智能体:基于vLLM与CoPaw-Flash的实践与深度评估
1. 项目概述:在本地部署与评估一个9B参数的代码智能体最近在折腾一个挺有意思的项目,尝试在单张NVIDIA H100 GPU上,部署并评估一个名为CoPaw-Flash-9B的本地代码智能体。这个模型基于Qwen3.5-9B微调而来,专门针对自主智能体任务进…...

从DataFrame到MySQL:利用pandas与pymysql实现高效数据迁移
1. 为什么需要把DataFrame数据写入MySQL? 在日常数据分析工作中,我们经常使用pandas处理数据。DataFrame作为pandas的核心数据结构,提供了丰富的数据操作功能。但分析结果最终需要持久化存储时,MySQL这类关系型数据库仍然是企业级…...

别再为地址映射头疼了!台达DVP50MC11T与西门子/欧姆龙PLC的Modbus通信差异对比
台达DVP50MC11T与主流PLC的Modbus通信地址映射实战解析 在工业自动化项目中,Modbus通信协议因其简单可靠的特点被广泛应用。但对于熟悉西门子或欧姆龙PLC的工程师来说,初次接触台达DVP50MC11T系列时,往往会对其特殊的地址映射方式感到困惑。…...

开发环境准备:Python、Node.js、Docker与Git
从“环境搞了两天”到“半小时开箱即用”,一个老油条的环境配置血泪史前几天团队来了个新同事,应届生,看着简历上写着“熟悉Python、Node.js、Docker、Git”。我心想,挺好,基本功扎实。然后给了他一个新电脑࿰…...

TrollInstallerX终极指南:如何高效部署iOS越狱工具的专业解决方案
TrollInstallerX终极指南:如何高效部署iOS越狱工具的专业解决方案 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX 在iOS 14.0到16.6.1系统上安装TrollStore一…...

别再手动导网表了!巧用OrCAD Capture与Allegro PCB Editor联动,实现原理图变更一键同步
别再手动导网表了!巧用OrCAD Capture与Allegro PCB Editor联动,实现原理图变更一键同步 在PCB设计领域,效率与准确性往往决定着项目成败。当工程师面对频繁的原理图修改时,传统的手动导出-导入网表流程不仅耗时费力,还…...

PCL2启动器游戏启动失败的终极解决方案:3步快速修复指南
PCL2启动器游戏启动失败的终极解决方案:3步快速修复指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL Plain Craft Launcher 2(PCL2)…...
)
别再让FTP匿名登录成后门!手把手教你加固vsftpd服务(附CentOS 7实战配置)
企业级vsftpd安全加固实战指南:从匿名登录风险到全方位防护 FTP服务作为企业文件传输的经典解决方案,至今仍在许多组织的IT架构中扮演重要角色。然而,默认配置下的vsftpd服务往往隐藏着致命的安全隐患——匿名登录功能如同一扇未上锁的后门&a…...

工程师创意竞赛全流程策划:从社区激活到公平投票的实战指南
1. 项目概述:一场别开生面的工程师创意竞赛又到了二月底,这意味着我们年初启动的那个“独轮车”图片配文竞赛,终于要进入最激动人心的投票环节了。我记得很清楚,那是2012年2月初,编辑部觉得冬天太沉闷,想找…...

家庭网络技术演进:从CES看有线与无线技术的融合与竞争
1. 家庭网络技术演进:从CES看有线与无线的融合与竞争每年一月的拉斯维加斯,CES(国际消费电子展)都是科技行业的风向标。对于像我这样长期关注网络技术的从业者来说,CES不仅是新产品的秀场,更是观察底层技术…...