对话系统之解码策略(Top-k Top-p Temperature)
一、案例分析
在自然语言任务中,我们通常使用一个预训练的大模型(比如GPT)来根据给定的输入文本(比如一个开头或一个问题)生成输出文本(比如一个答案或一个结尾)。为了生成输出文本,我们需要让模型逐个预测每个 token ,直到达到一个终止条件(如一个标点符号或一个最大长度)。在每一步,模型会给出一个概率分布,表示它对下一个单词的预测。
假设我们训练了一个描述个人生活喜好的模型,我们想让它来补全“我最喜欢漂亮的___”这个句子。模型可能会给出下面的概率分布:
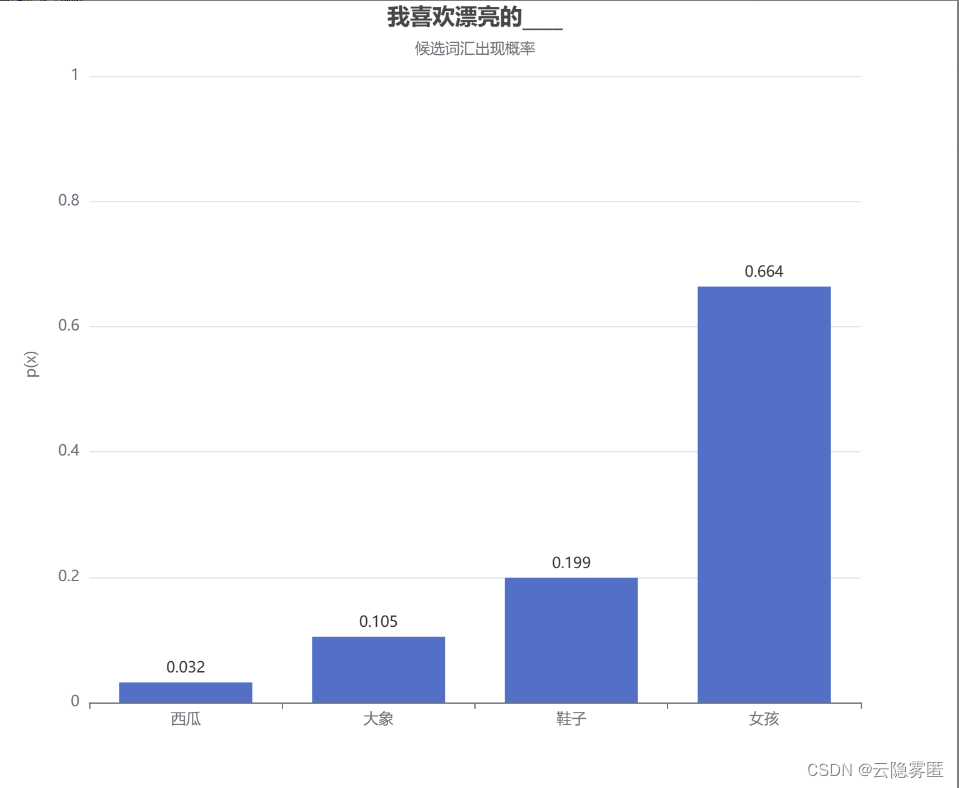
那么,我们应该如何从这个概率分布中选择下一个单词呢?以下是几种常用的方法:
- 贪心解码(Greedy Decoding):直接选择概率最高的单词。这种方法简单高效,但是可能会导致生成的文本过于单调和重复。
- 随机采样(Random Sampling):按照概率分布随机选择一个单词。这种方法可以增加生成的多样性,但是可能会导致生成的文本不连贯和无意义。
- 集束搜索(Beam Search):在每一个时间步,不再只保留当前概率最高的一个单词,而是按照概率从高到低排序,保留前num_beams个单词。这种方法可以平衡生成的质量和多样性,但也难以避免单词重复的问题。我们将在后续章节详细介绍集束搜索。
针对上述方法各自的问题,我们需要思考如何让模型生成的回复用词更加活跃呢?为此,研究人员引入了 top-k 采样、 top-p 采样和temperature采样。
二、top-k采样
在上面的例子中,如果使用贪心策略,那么选择的单词必然就是“女孩”。top-k 采样是对前面“贪心策略”的优化,它从排名前 k 的单词中进行随机抽样,允许其他概率的单词也有机会被选中。在很多情况下,这种抽样带来的随机性有助于提高生成质量。
下面是 top-k 采样的例子:
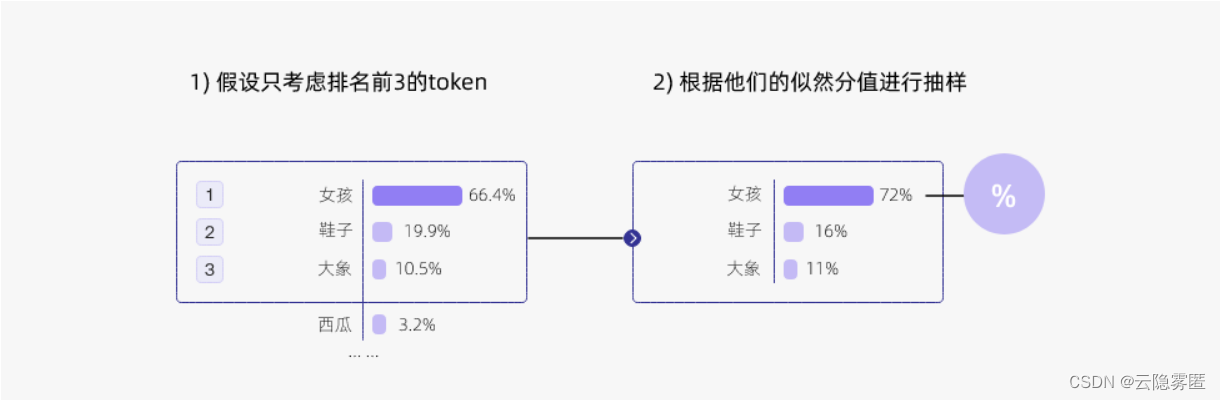
上图示例中,我们将k设置为3,那么模型将只从女孩、鞋子、大象中选择一个单词,而不考虑西瓜这个单词。具体来说,模型首先筛选似然值前三的单词,然后根据这三个单词的似然值重新计算采样概率,最后根据概率进行抽样。
通过调整 k 的大小,即可控制采样列表的大小。“贪心策略”其实就是 k = 1的 top-k 采样。
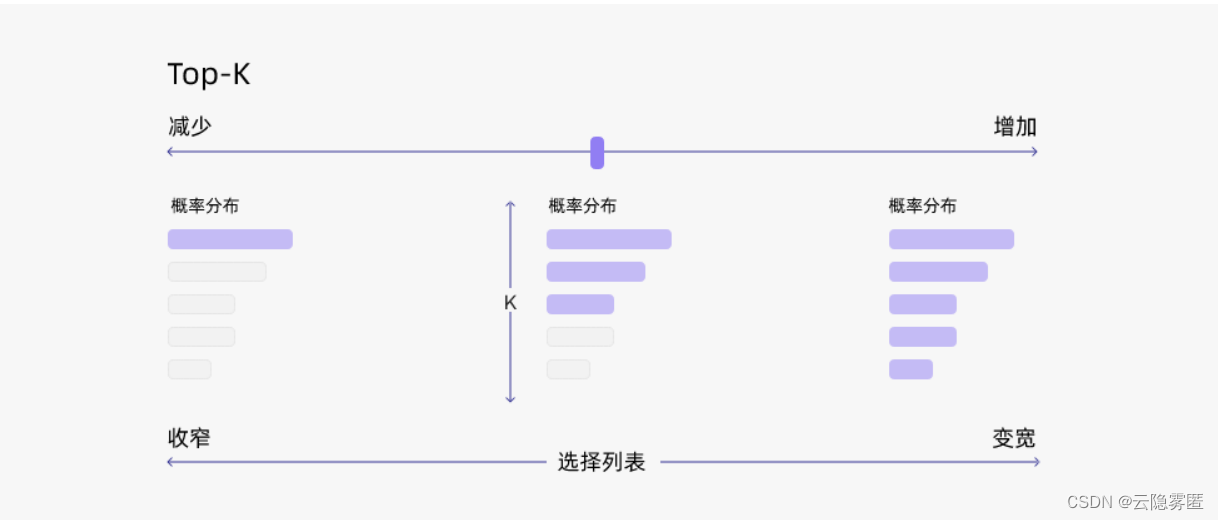
总结一下,top-k 采样有以下优点:
- 它可以通过调整 k 的大小来控制生成的多样性和质量。一般来说,k 越大,生成的多样性越高,但是生成的质量越低;k 越小,生成的质量越高,但是生成的多样性越低。因此,我们可以根据不同的任务和场景来选择合适的k 值。
- 它可以与其他解码策略结合使用,例如温度调节(Temperature Scaling)、重复惩罚(Repetition Penalty)、长度惩罚(Length Penalty)等,来进一步优化生成的效果。
但是 top-k采样也有一些缺点,比如:
- 它可能会导致生成的文本不符合常识或逻辑。这是因为 top-k 采样只考虑了单词的概率,而没有考虑单词之间的语义和语法关系。
- 它可能会导致生成的文本过于简单或无聊。这是因为 top-k 采样只考虑了概率最高的 k 个单词,而没有考虑其他低概率但有意义或有创意的单词。例如,如果输入文本是“我喜欢吃”,那么即使苹果、饺子和火锅都是合理的选择,也不一定是最有趣或最惊喜的选择,因为可能用户更喜欢吃一些特别或新奇的食物。
因此,我们通常会考虑 top-k采样和其它策略结合,比如 top-p采样。
三、top-p采样
top-k 采样有一个缺陷,那就是“k 值取多少是最优的?”这是非常难以确定。于是出现了动态设置单词候选列表大小策略,即top-p采样,又名核采样(Nucleus Sampling)。这也是chatGPT所使用的采样方法。
top-p 采样的思路是:预先设置一个概率界限 p 值,在每一步,将候选单词按照概率从高到低排序,然后依次选择单词构造集合。集合的构造原则是:如果加上当前单词,总概率小于或等于p,那么将当前单词放入集合;如果加上当前单词,总概率大于p,那么丢弃当前单词,集合构造到此结束。模型将从集合中随机选择一个单词,而不考虑集合之外的单词。
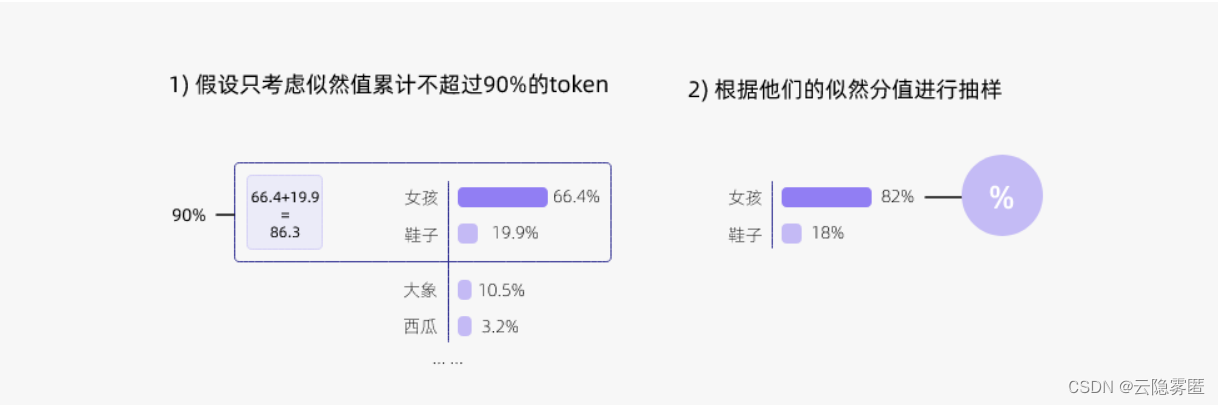
上图展示了 p 值为 0.9 的 Top-p 采样的效果。值得注意的是,我们可以同时使用 top-k采样 和 top-p采样,top-p 将在 top-k 之后起作用。
四、Temperature采样
Temperature 采样受统计热力学的启发,高温意味着更可能遇到低能态。在概率模型中,logits 扮演着能量的角色,我们可以通过将 logits 除以温度来实现Temperature 采样,然后将其输入 Softmax 函数进一步获得采样概率。
Temperature 采样中的温度与玻尔兹曼分布有关,其公式如下所示:
其中 是状态 i 的概率,
是状态 i 的能量, k 是波兹曼常数, T 是系统的温度,M 是系统所能到达的所有量子态的数目。
有机器学习背景的朋友第一眼看到上面的公式会觉得似曾相识。没错,上面的公式跟 Softmax 函数 相似:
本质上就是在 Softmax 函数上添加了温度(T)这个参数。Logits 根据我们的温度值进行缩放,然后传递到 Softmax 函数以计算新的概率分布。
上面“我喜欢漂亮的___”这个例子中,初始温度 T=1 ,我们直观看一下 T 取不同值的情况下,概率会发生什么变化:
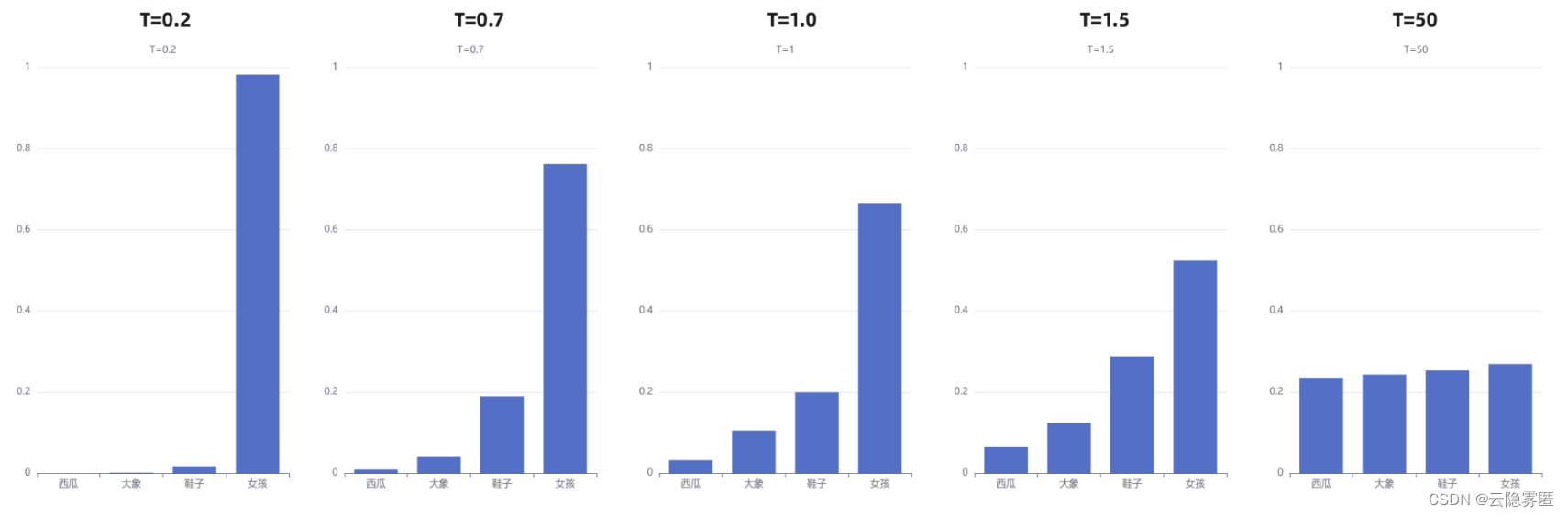
通过上图我们可以清晰地看到,随着温度的降低,模型愈来愈越倾向选择”女孩“;另一方面,随着温度的升高,分布变得越来越均匀。当T=50时,选择”西瓜“的概率已经与选择”女孩“的概率相差无几了。
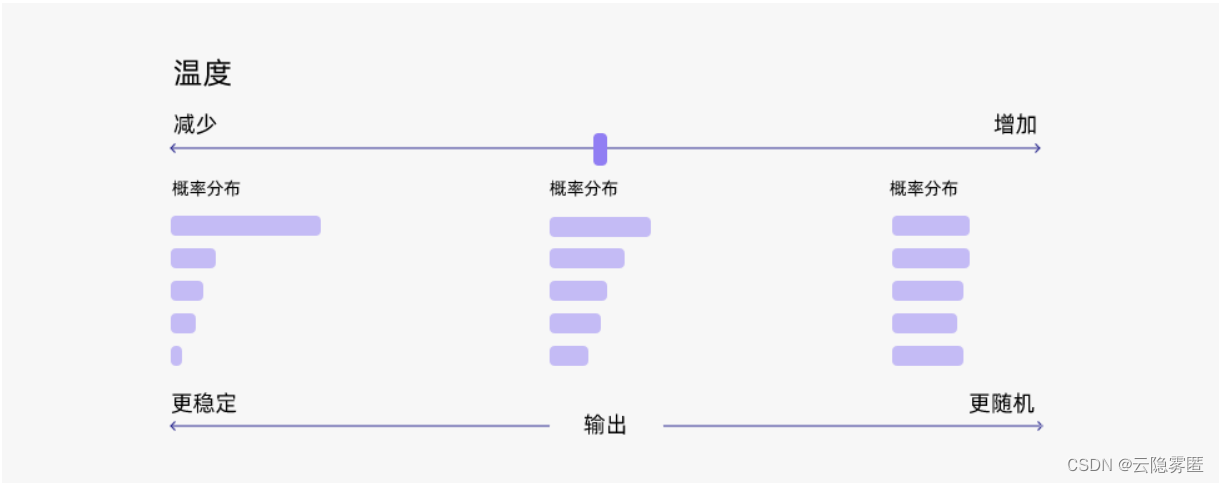
通常来说,温度与模型的“创造力”有关。但事实并非如此。温度只是调整单词的概率分布。其最终的宏观效果是,在较低的温度下,我们的模型更具确定性,而在较高的温度下,则不那么确定。
五、联合采样(top-k & top-p & Temperature)
通常我们是将 top-k、top-p、Temperature 联合起来使用。使用的先后顺序是 top-k->top-p->Temperature。
我们还是以前面的例子为例。
首先我们设置 top-k = 3,表示保留概率最高的3个 单词。这样就会保留女孩、鞋子、大象这3个 单词:
- 女孩:0.664
- 鞋子:0.199
- 大象:0.105
接下来,我们可以使用 top-p 的方法,构造集合,也就是选取女孩和鞋子这两个单词。接着我们使用 Temperature = 0.7 进行归一化,将这两个单词的似然值变为:
- 女孩:0.660
- 鞋子:0.340
接着,我们可以从上述分布中进行随机采样,选取一个单词作为最终的生成结果。
六、补充
6.1 Beam Search
本部分作为补充内容,供感兴趣的读者阅读。
Beam Search是对贪心策略一个改进。思路也很简单,就是稍微放宽一些考察的范围。在每一个时间步,不再只保留当前概率最高的1个单词,而是保留num_beams个。当num_beams=1时集束搜索就退化成了贪心搜索。
下图是一个实际的例子,每个时间步有ABCDE共5种可能的输出,图中的num_beams=2,也就是说每个时间步都会保留到当前步为止条件概率最优的2个序列。
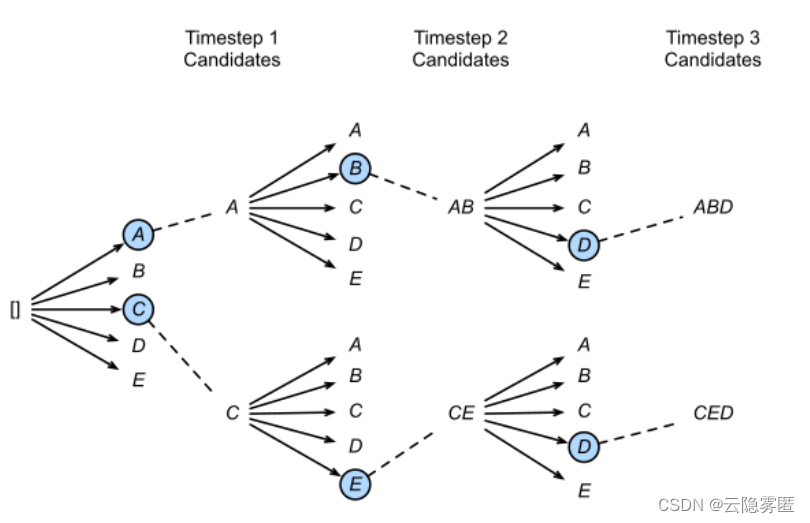
- 在第一个时间步,A和C是最优的两个,因此得到了两个结果
[A],[C],其他三个就被抛弃了; - 第二步会基于这两个结果继续进行生成,在A这个分支可以得到5个候选单词,
[AA],[AB],[AC],[AD],[AE],C也同理得到5个,此时会对这10个进行统一排名,再保留最优的两个,即图中的[AB]和[CE]; - 第三步同理,也会从新的10个候选人里再保留最好的两个,最后得到了
[ABD],[CED]两个结果。
可以发现,beam search在每一步需要考察的候选人数量是贪心搜索的num_beams倍,因此是一种牺牲时间换性能的方法。
6.2 温度(Temperature)参数介绍
温度(Temperature)是一个用于控制人工智能生成文本的创造力水平的参数。通过调整“温度”,您可以影响AI模型的概率分布,使文本更加集中或更多样化。
考虑以下示例:AI 模型必须完成句子“一只猫正在____”。下一个字具有以下标记概率:
玩:0.5
睡:0.25
吃:0.15
驾:0.05
飞:0.05
- 低温(例如0.2):AI模型变得更加专注和确定性,选择概率最高的标记,例如“玩”。
- 中温(例如1.0):AI模型在创造力和专注度之间保持平衡,根据概率选择标记,没有明显的偏见,例如“玩”、“睡”或“吃”。
- 高温(例如2.0):AI模型变得更加冒险,增加了选择不太可能的标记的机会,例如“驾”和“飞”。
如果温度较低,则对除对数概率最高的类之外的其他类进行采样的概率会很小,并且模型可能会输出最正确的文本,但相当无聊,变化较小。
如果温度高,模型可以以相当高的概率输出,或者说不是概率最高的。生成的文本会更加多样化,但出现语法错误和生成废话的可能性更高。
相关文章:
对话系统之解码策略(Top-k Top-p Temperature)
一、案例分析 在自然语言任务中,我们通常使用一个预训练的大模型(比如GPT)来根据给定的输入文本(比如一个开头或一个问题)生成输出文本(比如一个答案或一个结尾)。为了生成输出文本,…...
《面向机器学习的数据标注规程》摘录
说明:本文使用的标准是2019年的团体标准,最新的国家标准已在2023年发布。 3 术语和定义 3.2 标签 label 标识数据的特征、类别和属性等。 3.4 数据标注员 data labeler 对待标注数据进行整理、纠错、标记和批注等操作的工作人员。 【批注】按照定义…...

VGG(pytorch)
VGG:达到了传统串型结构深度的极限 学习VGG原理要了解CNN感受野的基础知识 model.py import torch.nn as nn import torch# official pretrain weights model_urls {vgg11: https://download.pytorch.org/models/vgg11-bbd30ac9.pth,vgg13: https://download.pytorch.org/mo…...

celery/schedules.py源码精读
BaseSchedule类 基础调度类,它定义了一些调度任务的基本属性和方法。以下是该类的主要部分的解释: __init__(self, nowfun: Callable | None None, app: Celery | None None):初始化方法,接受两个可选参数,nowfun表…...
单片机上位机(串口通讯C#)
一、简介 用C#编写了几个单片机上位机模板。可定制!!! 二、效果图...

初识Flask
摆上中文版官方文档网站:https://flask.github.net.cn/quickstart.html 开启实验之路~~~~~~~~~~~~~ from flask import Flaskapp Flask(__name__) # 使用修饰器告诉flask触发函数的URL,绑定URL,后面的函数用于返回用户在浏览器上看到的内容…...

JeecgBoot jmreport/queryFieldBySql RCE漏洞复现
0x01 产品简介 Jeecg Boot(或者称为 Jeecg-Boot)是一款基于代码生成器的开源企业级快速开发平台,专注于开发后台管理系统、企业信息管理系统(MIS)等应用。它提供了一系列工具和模板,帮助开发者快速构建和部署现代化的 Web 应用程序。 0x02 漏洞概述 Jeecg Boot jmrepo…...
机器学习---模型评估
1、混淆矩阵 对以上混淆矩阵的解释: P:样本数据中的正例数。 N:样本数据中的负例数。 Y:通过模型预测出来的正例数。 N:通过模型预测出来的负例数。 True Positives:真阳性,表示实际是正样本预测成正样…...
【机器学习】应用KNN实现鸢尾花种类预测
目录 前言 一、K最近邻(KNN)介绍 二、鸢尾花数据集介绍 三、鸢尾花数据集可视化 四、鸢尾花数据分析 总结 🌈嗨!我是Filotimo__🌈。很高兴与大家相识,希望我的博客能对你有所帮助。 💡本文由Fil…...

ACL和NAT
目录 一.ACL 1.概念 2.原理 3.应用 4.种类 5.通配符 1.命令 2.区别 3.例题 4.应用原则 6.实验 1.实验目的 2.实验拓扑 3.实验步骤 7.实验拓展 1.实验目的 2.实验步骤 3.测试 二.NAT 1.基本理论 2.作用 3.分类 静态nat 动态nat NATPT NAT Sever Easy-IP…...

MX6ULL学习笔记(十二)Linux 自带的 LED 灯
前言 前面我们都是自己编写 LED 灯驱动,其实像 LED 灯这样非常基础的设备驱动,Linux 内 核已经集成了。Linux 内核的 LED 灯驱动采用 platform 框架,因此我们只需要按照要求在设备 树文件中添加相应的 LED 节点即可,本章我们就来学…...

Qt容器QToolBox工具箱
# QToolBox QToolBox是Qt框架中的一个窗口容器类,常用的几个函数有: setCurrentIndex(int index):设置当前显示的页面索引。可以通过调用该函数,将指定索引的页面设置为当前显示的页面。 addItem(QWidget * widget, const QString & text):向QToolBox中添加一个页面…...

华为实训课笔记
华为实训 12/1312/14 12/13 ping 基于ICMP协议,用来进行可达性测试 ping 目的IP地址/设备域名(主机名) 如果能收到 reply 回复,则表示双方可以正常通信 <Huawei> 用户视图,只能做查询和一些简单的资源调用&…...
基于java 的经济开发区管理系统设计与实现(源码+调试)
项目描述 临近学期结束,还是毕业设计,你还在做java程序网络编程,期末作业,老师的作业要求觉得大了吗?不知道毕业设计该怎么办?网页功能的数量是否太多?没有合适的类型或系统?等等。今天给大家介绍一篇基于java 的经济开发区管…...

外包干了3个月,技术退步明显。。。
先说一下自己的情况,本科生生,19年通过校招进入广州某软件公司,干了接近4年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了四年的功能测…...
详细教程 - 从零开发 Vue 鸿蒙harmonyOS应用 第一节
关于使用Vue开发鸿蒙应用的教程,我这篇之前的博客还不够完整和详细。那么这次我会尝试写一个更加完整和逐步的指南,从环境准备,到目录结构,再到关键代码讲解,以及调试和发布等,希望可以让大家详实地掌握这个过程。 一、准备工作 下载安装 DevEco Studio 下载地址:…...

R语言对医学中的自然语言(NLP)进行机器学习处理(1)
什么是自然语言(NLP),就是网络中的一些书面文本。对于医疗方面,例如医疗记录、病人反馈、医生业绩评估和社交媒体评论,可以成为帮助临床决策和提高质量的丰富数据来源。如互联网上有基于文本的数据(例如,对医疗保健提供者的社交媒体评论),这些数据我们可…...

什么是CI/CD?如何在PHP项目中实施CI/CD?
CI/CD(持续集成/持续交付或持续部署)是一种软件开发和交付方法,它旨在通过自动化和持续集成来提高开发速度和交付质量。以下是CI/CD的基本概念和如何在PHP项目中实施它的一般步骤: 持续集成(Continuous Integration -…...
:容器指令、生命周期、资源限制、容器化支持、常用命令)
玩转Docker(四):容器指令、生命周期、资源限制、容器化支持、常用命令
文章目录 一、容器指令1.运行2.启动/停止/重启3.暂停/恢复4.删除 二、生命周期三、资源限制1.内存限额2.CPU限额3.磁盘读写带宽限额 四、cgroup和namespace五、常用命令 一、容器指令 1.运行 按用途容器大致可分为两类:服务类容器和工具类的容器。 服务类容器&am…...
回归预测 | MATLAB实现CHOA-BiLSTM黑猩猩优化算法优化双向长短期记忆网络回归预测 (多指标,多图)
回归预测 | MATLAB实现CHOA-BiLSTM黑猩猩优化算法优化双向长短期记忆网络回归预测 (多指标,多图) 目录 回归预测 | MATLAB实现CHOA-BiLSTM黑猩猩优化算法优化双向长短期记忆网络回归预测 (多指标,多图)效果…...

基于MCP协议构建AI工具服务器:从原理到企业级实践
1. 项目概述:一个连接上下文与工具的智能服务器最近在折腾AI应用开发,特别是想让大语言模型(LLM)能更“聪明”地使用外部工具和数据。我发现,很多项目要么是把工具调用逻辑硬编码在提示词里,要么就是搞一套…...

小波散射网络:从理论优势到小样本图像分类实践
1. 小波散射网络为什么值得关注 第一次听说小波散射网络时,我和大多数搞机器学习的朋友反应一样:"这玩意儿和普通卷积神经网络(CNN)有什么区别?"直到去年接手一个医疗影像项目,手头只有200张标注…...

从泊松比到广义胡克定律:物理仿真中的材料形变建模指南
1. 泊松比:材料形变的"性格密码" 第一次接触泊松比这个概念时,我正对着橡胶减震器的仿真结果发愁——明明设置了正确的杨氏模量,为什么变形效果总是不对劲?直到导师指着屏幕问:"你考虑过这个橡胶材料的…...

JD-GUI深度解析:Java字节码逆向工程的瑞士军刀
JD-GUI深度解析:Java字节码逆向工程的瑞士军刀 【免费下载链接】jd-gui A standalone Java Decompiler GUI 项目地址: https://gitcode.com/gh_mirrors/jd/jd-gui 在Java开发的世界里,我们常常需要面对只有字节码没有源码的困境——第三方库的调试…...

HS2-HF_Patch深度解析:Honey Select 2终极增强补丁实战指南
HS2-HF_Patch深度解析:Honey Select 2终极增强补丁实战指南 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch HS2-HF_Patch是一款专为Honey Select 2游…...

基于Python的自动化数据简报生成:从模板驱动到部署实践
1. 项目概述:数据简报的自动化生成利器如果你也和我一样,每天需要从一堆数据库、日志文件和API接口里捞出数据,然后吭哧吭哧地整理成PPT或者Word报告,那你一定懂这种重复劳动的痛苦。数据本身就在那里,但把它们变成老板…...

如何快速掌握Avogadro 2:开源分子可视化工具的终极指南
如何快速掌握Avogadro 2:开源分子可视化工具的终极指南 【免费下载链接】avogadrolibs Avogadro libraries provide 3D rendering, visualization, analysis and data processing useful in computational chemistry, molecular modeling, bioinformatics, material…...

对比直接使用官方 API 体验 Taotoken 聚合接入在配置简化上的优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方 API 体验 Taotoken 聚合接入在配置简化上的优势 对于需要调用多种大模型能力的开发者而言,直接与各家…...

Laravel DDD架构实践:使用Neuron Core构建可维护业务系统
1. 项目概述:一个为Laravel打造的现代化神经元网络核心如果你正在用Laravel构建一个中大型应用,并且已经受够了在控制器里塞满几百行业务逻辑,或者在模型里写满各种scope和accessor,让它们变得臃肿不堪,那么neuron-cor…...

深度解析:PC端即时通讯防撤回功能的技术实现
深度解析:PC端即时通讯防撤回功能的技术实现 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitcode.com/GitHub_…...