初识scrapy
认识scrapy
scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需实现少量的代码,就能实现数据的快速抓取
scrapy使用了Twisted异步网络架构,可以加快下载速度 pip install twisted
安装:pip install scrapy
流程图
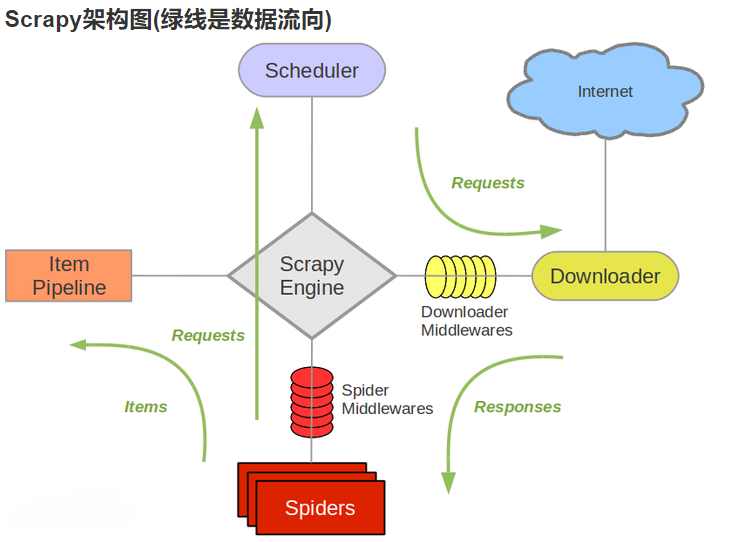
组件介绍
组件 | 作用 |
Scrapy Engine(引擎) | 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等 |
Scheduler(调度器) | 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎 |
Downloader(下载器) | 负责下载(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。 |
Spider(爬虫) | 它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler |
Item Pipeline(管道) | 它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方 |
Downloader Middlewares下载中间件 | 一个可以自定义扩展下载功能的组件。 |
Spider Middlewares(Spider中间件) | 一个可以自定扩展和操作引擎和Spider中间通信的功能组件 |
运行流程
引擎:Hi!Spider, 你要处理哪一个网站?
Spider:老大要我处理xxxx.com。
引擎:你把第一个需要处理的URL给我吧。
Spider:给你,第一个URL是xxxxxxx.com。
引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
调度器:好的,正在处理你等一下。
引擎:Hi!调度器,把你处理好的request请求给我。
调度器:给你,这是我处理好的request
引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求
下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给**def parse()**这个函数处理的)
Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
管道调度器:好的,现在就做!
快速入门
创建一个scrapy项目
scrapy startproject name # name 为项目名称创建一个spider
cd name # 进入创建的项目scrapy genspider spider_name url # spider_name为爬虫名,url为要抓取的目标网站scrapy crawl spider_name # 执行爬虫spider
手动创建的spider文件
import scrapyclass BdSpiderSpider(scrapy.Spider):name = 'spider_name'allowed_domains = ['baidu.com']start_urls = ['https://www.baidu.com']def parse(self, response,**kwargs):pass**name:**标识spider。它在一个项目中必须是唯一的,即不能为不同的爬行器设置相同的名称
**allowed_domains:**允许爬取url的域名
**start_urls:**一个url列表,spider从这些网页开始抓取
**parse():**一个方法,当start_urls里面的网页抓取下来之后需要调用这个方法解析网页内容
items
定义抓取的字段名
import scrapyclass MySpiderItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()passpipeline
数据存储的位置
from itemadapter import ItemAdapterclass MySpiderPipeline:def process_item(self, item, spider):return itemsettings
项目配置文件
# Scrapy settings for my_spider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlBOT_NAME = 'my_spider'SPIDER_MODULES = ['my_spider.spiders']
NEWSPIDER_MODULE = 'my_spider.spiders'# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.71'# Obey robots.txt rules
# robots协议,默认遵守
ROBOTSTXT_OBEY = False
# 日志等级,ERROR最高
LOG_LEVEL = "ERROR"# Configure maximum concurrent requests performed by Scrapy (default: 16)
# 并发请求(concurrent requests)的最大值
#CONCURRENT_REQUESTS = 32# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs# 下载延迟
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
# 对单个网站进行并发请求的最大值
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
# 对单个IP进行并发请求的最大值。如果非0,则忽略
#CONCURRENT_REQUESTS_PER_IP = 16# Disable cookies (enabled by default)
# COOKIES_ENABLED = False# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False# Override the default request headers:
# DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
# }# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'my_spider.middlewares.MySpiderSpiderMiddleware': 543,
#}# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'my_spider.middlewares.MySpiderDownloaderMiddleware': 543,
#}# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {# 优先级 数字越小,越靠近管道'my_spider.pipelines.MySpiderPipeline': 300,
}# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'相关文章:
初识scrapy
认识scrapyscrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需实现少量的代码,就能实现数据的快速抓取scrapy使用了Twisted异步网络架构,可以加快下载速度 pip install twisted安装:pip install s…...
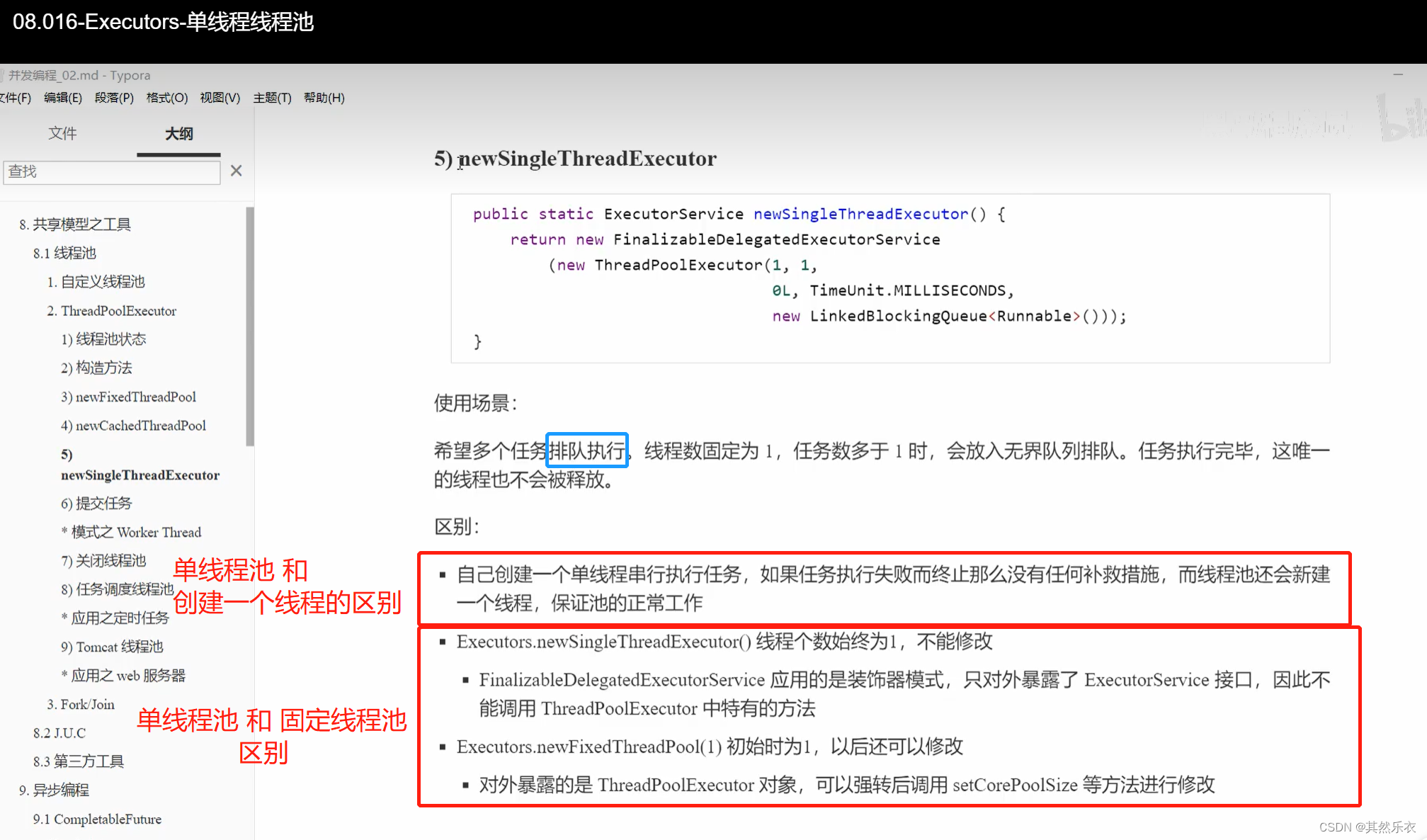
(JUC)核心线程 和 救急线程的区别;Executors-固定大小线程池单线程线程池
核心线程 和 救急线程的区别 救急线程是有个生存时间的,它执行完任务了,过了一段时间,没有新任务了,救急线程就会销毁掉,变成结束的状态 核心线程没有生存时间,它执行完任务后,它仍然会被保存…...
vue2的动画和过渡效果
文章目录过渡 & 动画Transition 组件基于 CSS 的过渡效果CSS 过渡类名 class为过渡效果命名CSS 过渡 transition实例1:实例2:CSS 动画自定义过渡的类名同时使用 transition 和 animation深层级过渡与显式过渡时长性能考量JavaScript 动画可复用过渡效…...

正数负数的取反运算推导过程
取反题目题目:数据常用位十进制数据举例 我们计算a 60的取反运算c~a 求c 引用的知识点知识点: 正数的反码 补码 都一样。 0的补码反码都一样 负数的反码,最高是标记符号位,其他位置1变0 1变0 负数的补码 反码1 步骤斜体样式本篇我们全用8位二…...

C语言 条件编译
目录 1. #if #elif #else #endif 2. #ifdef #else #endif 3. #ifndef #else #endif 4. 三者区别 根据不同情况编译不同代码、产生不同目标文件的机制,称为条件编译。 条件编译是预处理程序的功能,不是编译器的功能。 1. #if #elif #else #endif …...
Linux: ARM GIC只中断CPU 0问题分析
文章目录1. 前言2. 分析背景3. 问题4. 分析4.1 ARM GIC 中断芯片简介4.1.1 中断类型和分布4.1.2 拓扑结构4.2 问题根因4.2.1 设置GIC SPI 中断CPU亲和性4.2.2 GIC初始化:缺省的CPU亲和性4.2.2.1 boot CPU亲和性初始化流程4.2.2.1 其它非 boot CPU亲和性初始化流程5.…...

测试软件5
一 css基础 css定义:可以设置网页中的样式,外观,美化 css中文名字:级联样式表,层叠样式表,样式表 二 css基础语法 1.style标签写在title标签后面 2.选择器{属性名1:属性值1;属性名…...
前端JS内存管理
JS内存管理 内存原理: 任何变成语言在执行的时候都需要操作系统来分配内存,只是有些语言需要手动管理分配的内存有些语言有专门来管理内存的方式 如 JVM 了解以上的概念之后,我们再来了解一下大致的内存周期 分配需要的内存使用内存在不使用…...
第七章.集成学习(Ensemble Learning)—袋装(bagging),随机森林(Random Forest)
第七章.集成学习 (Ensemble Learning) 7.1 集成学习—袋装(bagging),随机森林(Random Forest) 集成学习就是组合多个学习器,最后得到一个更好的学习器。 1.常见的4种集成学习算法 个体学习器之间不存在强依赖关系,袋装(bagging)…...
Java_面向对象
Java_面向对象 1.面向对象概述 面向对象是一种符合人类思想习惯的编程思想。显示生活中存在各种形态的不同事物,这些食物存在着各种各样的联系。在程序中使用对象来映射现实中的事物,使用对象的关系来描述事物之间的关系,这种思想就是面…...

【IoT】智能烟雾报警器
设计简介 硬件设计由AT89C51单片机、DS18B20温度传感器、4位共阳数码管、电源模块、报警模块、按键模块、MQ-2烟雾检测模块和ADC0832模数转换模块组成。 烟雾传感器MQ-2检测空气中的烟雾气体,通过ADC0832进行数据转换,经过单片机的运算处理后在数码管上…...
)
Python实现定时执行脚本(5)
前言 本文是该专栏的第17篇,后面会持续分享python的各种干货知识,值得关注。 笔者在前面有详细介绍过几种使用python实现定时执行任务的方法,可以说都是简单易上手的那种。而本文,再来详细介绍另外一种定时方法,那就是利用任务框架APScheduler(advanceded python schedu…...
JavaSe第4次笔记
1.转义字符和编程语言无关。 2.斜杠(\)需要转义,反斜杠(/)不需要转义。 3.不能做switch的参数的数据类型:long float double boolean( String可以)。 4.输入的写法:Scanner(回车自动带头文件(import java.util.Scanner;)) Scanner scan …...

epoll机制
预备知识 文件描述符file descriptor 文件描述符是Linux系统中对文件、套接字等I/O资源的抽象,每个打开的文件或套接字都有一个唯一的文件描述符。应用程序可以使用文件描述符来读写文件或进行网络通信。 epoll允许程序监控多个文件描述符,以便在这些…...
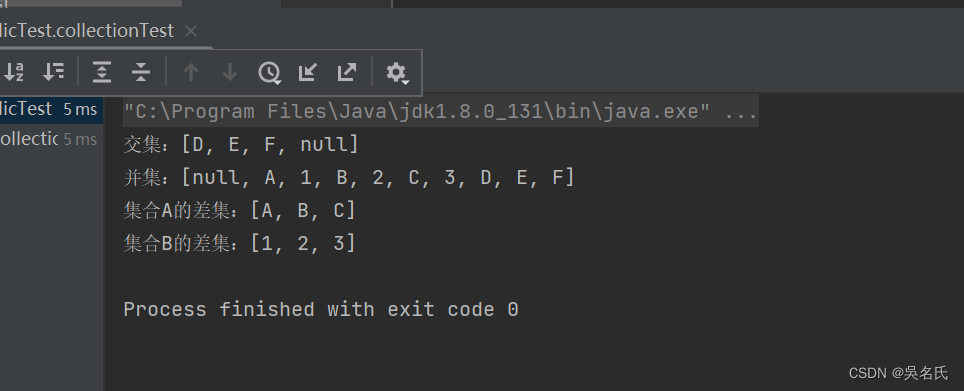
Java使用不同方式获取两个集合List的交集、补集、并集(相加)、差集(相减)
1 明确概念首先知道几个单词的意思:并集 union交集 intersection补集 complement析取 disjunction减去 subtract1.1 并集对于两个给定集合A、B,由两个集合所有元素构成的集合,叫做A和B的并集。记作:AUB 读作“A并B”例&#…...

【Android笔记80】Android之Retrofit适配器和文件上传下载
这篇文章,主要介绍Android之Retrofit适配器和文件上传下载。 目录 一、Retrofit适配器 1.1、Retrofit适配器 (1)引入RxJava依赖 (2)定义接口...

Nodejs模块化
1.模块化 1.1.模块化的基本概念 模块化是指解决一个复杂问题时,自顶向下逐层把系统划分为若干模块的过程。对于整个系统而言,模块是可组合、分解和更换的单元。 1.2 编程中的模块化 编程领域的模块化就是把一个大文件拆成独立并相互依赖的多个小模块…...

C++STL基础
STL基础 诞生 cpp的面向对象和泛型编程的思想本质就是提高复用性诞生了STL库 基本概念 STL标准模板库STL从广义上分为容器、算法及迭代器容器和算法之间通过迭代器进行连接STL几乎所有的代码都采用了模板类或者模板函数 基本组件 容器、算法、迭代器、仿函数、适配器、空间配置…...

数学建模经验【更新中】
数学建模简单入门 一、 分工 3人,1人论文,1人代码主力,1人论文代码(前一半时间主代码,后一半时间主论文) Tips: 不养闲人,论文必须要在对代码和题目极其了解并且能跟上队友思路的情况下才能写…...
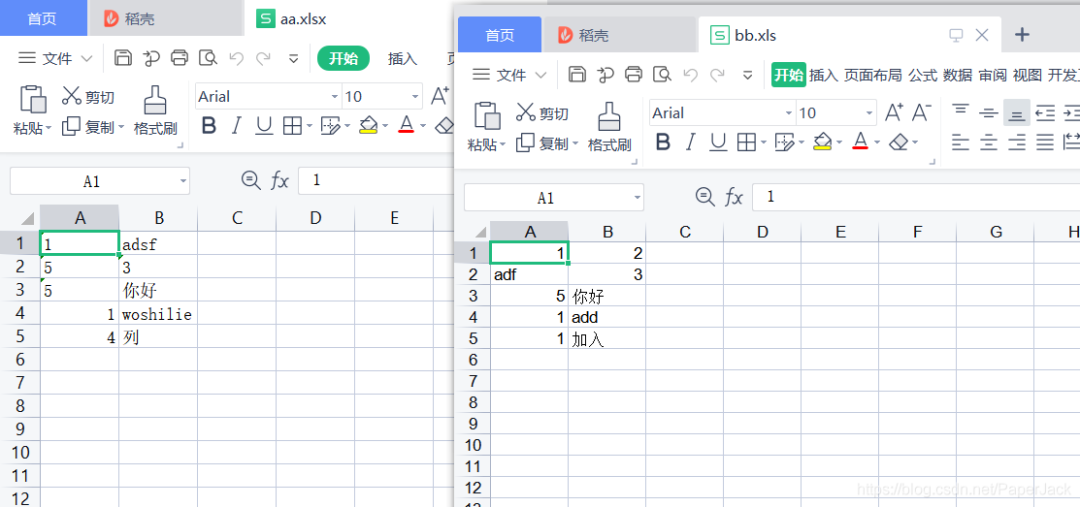
【python学习笔记】:Excel 数据的封装函数
对比其它编程语言,我们都知道Python最大的优势是代码简单,有丰富的第三方开源库供开发者使用。伴随着近几年数据分析的热度,Python也成为最受欢迎的编程语言之一。而对于数据的读取和存储,对于普通人来讲,除了数据库之…...

让 Agent 也能发邮件:Cloudflare Email Service 正式公测
原文:Cloudflare Email Service: now in public beta. Ready for your agents 邮件是世界上最通用的接口 不需要下载特定 App,不需要接入自定义 SDK,不需要注册新平台。全球几十亿人都有邮箱,任何人都可以通过一封邮件和你的应用…...

5步掌握OpenCore Configurator:黑苹果配置终极可视化指南
5步掌握OpenCore Configurator:黑苹果配置终极可视化指南 【免费下载链接】OpenCore-Configurator A configurator for the OpenCore Bootloader 项目地址: https://gitcode.com/gh_mirrors/op/OpenCore-Configurator 如果你正在为黑苹果系统的复杂配置而烦恼…...

告别模拟开关:用TLC7528双DAC为你的STM32项目扩展模拟输出通道
告别模拟开关:用TLC7528双DAC为你的STM32项目扩展模拟输出通道 在嵌入式系统开发中,模拟信号输出是许多控制系统的核心需求。无论是精密仪器、工业自动化还是音频处理,都需要稳定可靠的模拟输出通道。然而,大多数STM32微控制器内置…...

如何快速集成Prometheus和Jaeger:Echo框架第三方中间件终极指南
如何快速集成Prometheus和Jaeger:Echo框架第三方中间件终极指南 【免费下载链接】echo High performance, minimalist Go web framework 项目地址: https://gitcode.com/gh_mirrors/ec/echo Echo是一个高性能、极简的Go Web框架,为开发者提供了轻…...

为什么你需要LRCGET:5步为离线音乐库实现完美歌词同步
为什么你需要LRCGET:5步为离线音乐库实现完美歌词同步 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 还在为数千首离线音乐缺少歌词而烦恼…...
)
Win10/Win11更新后飞行堡垒风扇快捷键失效?手把手教你找回丢失的FN+F5控制(附各型号解决方案对照表)
Win10/Win11更新后飞行堡垒风扇快捷键失效?深度修复指南与全型号适配方案 每次Windows大版本更新后,总有些硬件功能像变魔术一样消失——比如飞行堡垒系列笔记本的风扇控制快捷键FNF5。这背后其实是微软系统更新机制与厂商驱动之间的微妙博弈。作为从飞…...

AI文本处理利器:MCP服务器实现结构化信息提取与智能解析
1. 项目概述:一个为AI应用注入结构化文本处理能力的MCP服务器 最近在折腾AI应用开发,特别是那些需要让大语言模型(LLM)与外部工具和数据源打交道的场景,我发现一个核心痛点:如何高效、可靠地将非结构化的文…...

Perfmon性能计数器深度解析:从指标选取到瓶颈定位实战
1. Perfmon性能计数器入门:为什么它是Windows运维的瑞士军刀 第一次接触Perfmon(Performance Monitor)是在十年前处理一台频繁卡顿的数据库服务器时。当时我尝试了各种工具都找不到问题根源,直到一位老工程师教我打开了这个Window…...

Universal Data Tool 新功能解析:骨骼姿态标注与数据格式转换实战
1. 项目概述:一个数据标注工具的进化最近在整理一个计算机视觉项目的数据集时,我又一次打开了Universal Data Tool(UDT)。这个工具我用了快两年了,从它早期版本支持基础的图像分类和物体检测框标注开始,就一…...

元调优技术:如何让大模型学会严谨的数学推理与验证
1. 项目概述:当大模型遇上数学题作为一名长期混迹于AI工程一线的从业者,我经常被问到:“你们搞的大模型,做做文本生成还行,真让它解个数学题,能靠谱吗?” 这个问题问到了点子上。数学推理&#…...