importlib --- import 的实现
3.1 新版功能.
源代码 Lib/importlib/__init__.py
概述
importlib 包具有三重目标。
一是在 Python 源代码中提供 import 语句的实现(并且因此而扩展 __import__() 函数)。 这提供了一个可移植到任何 Python 解释器的 import 实现。 与使用 Python 以外的编程语言实现的方式相比这一实现也更易于理解。
第二个目的是实现 import 的部分被公开在这个包中,使得用户更容易创建他们自己的自定义对象 (通常被称为 importer) 来参与到导入过程中。
三,这个包也包含了对外公开用于管理 Python 包的各个方面的附加功能的模块:
-
importlib.metadata 代表对来自第三方发行版的元数据的访问。
-
importlib.resources 提供了用于对来自 Python 包的非代码“资源”的访问的例程。
参见
import 语句
import 语句的语言参考
包规格说明
包的初始规范。自从编写这个文档开始,一些语义已经发生改变了(比如基于 sys.modules 中 None 的重定向)。
__import__() 函数
import 语句是这个函数的语法糖。
sys.path 模块搜索路径的初始化
sys.path 的初始化。
PEP 235
在忽略大小写的平台上进行导入
PEP 263
定义 Python 源代码编码
PEP 302
新导入钩子
PEP 328
导入:多行和绝对/相对
PEP 366
主模块显式相对导入
PEP 420
隐式命名空间包
PEP 451
导入系统的一个模块规范类型
PEP 488
消除PYO文件
PEP 489
多阶段扩展模块初始化
PEP 552
确定性的 pyc 文件
PEP 3120
使用 UTF-8 作为默认的源编码
PEP 3147
PYC 仓库目录
函数
importlib.__import__(name, globals=None, locals=None, fromlist=(), level=0)
内置 __import__() 函数的实现。
备注
程序式地导入模块应该使用 import_module() 而不是这个函数。
importlib.import_module(name, package=None)
导入一个模块。 参数 name 指定了以绝对或相对导入方式导入什么模块 (比如要么像这样 pkg.mod 或者这样 ..mod)。 如果参数 name 使用相对导入的方式来指定,那么 package 参数必须设置为那个包名,这个包名作为解析这个包名的锚点 (比如 import_module('..mod', 'pkg.subpkg') 将会导入 pkg.mod)。
import_module() 函数是一个对 importlib.__import__() 进行简化的包装器。 这意味着该函数的所有语义都来自于 importlib.__import__()。 这两个函数之间最重要的不同点在于 import_module() 返回指定的包或模块 (例如 pkg.mod),而 __import__() 返回最高层级的包或模块 (例如 pkg)。
如果动态导入一个自解释器开始执行以来被创建的模块(即创建了一个 Python 源代码文件),为了让导入系统知道这个新模块,可能需要调用 invalidate_caches()。
在 3.3 版更改: 父包会被自动导入。
importlib.invalidate_caches()
使查找器存储在 sys.meta_path 中的内部缓存无效。如果一个查找器实现了 invalidate_caches(),那么它会被调用来执行那个无效过程。 如果创建/安装任何模块,同时正在运行的程序是为了保证所有的查找器知道新模块的存在,那么应该调用这个函数。
3.3 新版功能.
在 3.10 版更改: 当注意到相同命名空间已被导入之后在不同 sys.path 位置中创建/安装的命名空间包。
importlib.reload(module)
重新加载之前导入的 module。 那个参数必须是一个模块对象,所以它之前必须已经成功导入了。 这在你已经使用外部编辑器编辑过了那个模块的源代码文件并且想在退出 Python 解释器之前试验这个新版本的模块的时候将很适用。 函数的返回值是那个模块对象(如果重新导入导致一个不同的对象放置在 sys.modules 中,那么那个模块对象是有可能会不同)。
当执行 reload() 的时候:
-
Python 模块的代码会被重新编译并且那个模块级的代码被重新执行,通过重新使用一开始加载那个模块的 loader,定义一个新的绑定在那个模块字典中的名称的对象集合。扩展模块的
init函数不会被调用第二次。 -
与Python中的所有的其它对象一样,旧的对象只有在它们的引用计数为0之后才会被回收。
-
模块命名空间中的名称重新指向任何新的或更改后的对象。
-
其他旧对象的引用(例如那个模块的外部名称)不会被重新绑定到引用的新对象的,并且如果有需要,必须在出现的每个命名空间中进行更新。
有一些其他注意事项:
当一个模块被重新加载的时候,它的字典(包含了那个模块的全区变量)会被保留。名称的重新定义会覆盖旧的定义,所以通常来说这不是问题。如果一个新模块没有定义在旧版本模块中定义的名称,则将保留旧版本中的定义。这一特性可用于作为那个模块的优点,如果它维护一个全局表或者对象的缓存 —— 使用 try 语句,就可以测试表的存在并且跳过它的初始化,如果有需要的话:
try:cache
except NameError:cache = {}
重新加载内置的或者动态加载模块,通常来说不是很有用处。不推荐重新加载"sys,__main__,builtins 和其它关键模块。在很多例子中,扩展模块并不是设计为不止一次的初始化,并且当重新加载时,可能会以任意方式失败。
如果一个模块使用 from ... import ... 导入的对象来自另外一个模块,给其它模块调用 reload() 不会重新定义来自这个模块的对象 —— 解决这个问题的一种方式是重新执行 from 语句,另一种方式是使用 import 和限定名称(module.name)来代替。
如果一个模块创建一个类的实例,重新加载定义那个类的模块不影响那些实例的方法定义———它们继续使用旧类中的定义。对于子类来说同样是正确的。
3.4 新版功能.
在 3.7 版更改: 如果重新加载的模块缺少 ModuleSpec ,则会触发 ModuleNotFoundError 。
importlib.abc —— 关于导入的抽象基类
源代码: Lib/importlib/abc.py
importlib.abc 模块包含了 import 使用到的所有核心抽象基类。在实现核心的 ABCs 中,核心抽象基类的一些子类也提供了帮助。
ABC 类的层次结构:
object+-- MetaPathFinder+-- PathEntryFinder+-- Loader+-- ResourceLoader --------++-- InspectLoader |+-- ExecutionLoader --++-- FileLoader+-- SourceLoader
class importlib.abc.MetaPathFinder
一个代表 meta path finder 的抽象基类。
3.3 新版功能.
在 3.10 版更改: 不再是 Finder 的子类。
find_spec(fullname, path, target=None)
一个抽象方法,用于查找指定模块的 spec 。若是顶层导入,path 将为 None。 否则就是查找子包或模块,path 将是父级包的 __path__ 值。找不到则会返回 None。传入的 target 是一个模块对象,查找器可以用来对返回的规格进行更有依据的猜测。在实现具体的 MetaPathFinders 代码时,可能会用到 importlib.util.spec_from_loader() 。
3.4 新版功能.
invalidate_caches()
当被调用的时候,一个可选的方法应该将查找器使用的任何内部缓存进行无效。将在 sys.meta_path 上的所有查找器的缓存进行无效的时候,这个函数被 importlib.invalidate_caches() 所使用。
在 3.4 版更改: 当方法被调用的时候,方法返回是 None 而不是 NotImplemented 。
class importlib.abc.PathEntryFinder
一个抽象基类,代表 path entry finder。虽然与 MetaPathFinder 有些相似之处,但 PathEntryFinder 仅用于 importlib.machinery.PathFinder 提供的基于路径的导入子系统中。
3.3 新版功能.
在 3.10 版更改: 不再是 Finder 的子类。
find_spec(fullname, target=None)
一个抽象方法,用于查找指定模块的 spec。搜索器将只在指定的 path entry 内搜索该模块。找不到则会返回 None。在实现具体的 PathEntryFinders 代码时,可能会用到 importlib.util.spec_from_loader() 。
3.4 新版功能.
invalidate_caches()
可选方法,调用后应让查找器用到的所有内部缓存失效。要让所有缓存的查找器的缓存无效时,可供 importlib.machinery.PathFinder.invalidate_caches() 调用。
class importlib.abc.Loader
loader 的抽象基类。 关于一个加载器的实际定义请查看 PEP 302。
想要支持资源读取的加载器应当实现 importlib.resources.abc.ResourceReader 所规定的 get_resource_reader() 方法。
在 3.7 版更改: 引入了可选的 get_resource_reader() 方法。
create_module(spec)
当导入一个模块的时候,一个返回将要使用的那个模块对象的方法。这个方法可能返回 None ,这暗示着应该发生默认的模块创建语义。"
3.4 新版功能.
在 3.6 版更改: 当 exec_module() 已定义时此方法将不再是可选项。
exec_module(module)
当一个模块被导入或重新加载时在自己的命名空间中执行该模块的的抽象方法。 该模块在 exec_module() 被调用时应该已经被初始化了。 当此方法存在时,必须要定义 create_module()。
3.4 新版功能.
在 3.6 版更改: create_module() 也必须要定义。
load_module(fullname)
用于加载模块的传统方法。 如果模块无法被导入,则会引发 ImportError,在其他情况下将返回被加载的模块。
如果请求的模块已存在于 sys.modules 中,则该模块应当被使用并重新加载。 在其他情况下加载器应当创建一个新模块并在任何加载操作开始之前将其插入到 sys.modules 中,以防止来自导入的无限递归。 如果加载器插入了一个模块并且加载失败,则必须用加载器将其从 sys.modules 中移除;在加载器开始执行之前已经存在于 sys.modules 中的模块应当保持原样。
加载器应当在模块上设置几个属性(请注意在模块被重新加载时这些属性有几个可能发生改变):
-
__name__
模块的完整限定名称。 对于被执行的模块来说是
'__main__'。 -
__file__
被 loader 用于加载指定模块的位置。 例如,对于从一个 .py 文件加载的模块来说即文件名。 这不一定会在所有模块上设置(例如内置模块就不会设置)。
-
__cached__
模块代码的编译版本的文件名。 这不一定会在所有模块上设置(例如内置模块就不会设置)。
-
__path__
用于查找指定包的子模块的位置列表。 在大多数时候这将为单个目录。 导入系统会以与 sys.path 相同但专门针对指定包的方式将此属性传给
__import__()和查找器。 这不会在非包模块上设置因此它可以被用作确定模块是否为包的指示器。 -
__package__
指定模块所在包的完整限定名称(或者对于最高层级模块来说则为空字符串)。 如果模块是包则它将与 __name__ 相同。
-
__loader__
用于加载模块的 loader。
当 exec_module() 可用的时候,那么则提供了向后兼容的功能。
在 3.4 版更改: 当被调用时将引发 ImportError 而不是 NotImplementedError。 在 exec_module() 可用时提供的功能。
3.4 版后已移除: 用于加载模块的推荐 API 是 exec_module() (和 create_module())。 加载器应该实现它而不是 load_module()。 当实现了 exec_module() 时导入机制将会承担 load_module() 的所有其他责任。
class importlib.abc.ResourceLoader
一个 loader 的抽象基类,它实现了可选的 PEP 302 协议用于从存储后端加载任意资源。
3.7 版后已移除: 这个 ABC 已被弃用并转为通过 importlib.resources.abc.ResourceReader 来支持资源加载。
abstractmethod get_data(path)
一个用于返回位于 path 的字节数据的抽象方法。有一个允许存储任意数据的类文件存储后端的加载器能够实现这个抽象方法来直接访问这些被存储的数据。如果不能够找到 path,则会引发 OSError 异常。path 被希望使用一个模块的 __file 属性或来自一个包的 __path__ 来构建。
在 3.4 版更改: 引发 OSError 异常而不是 NotImplementedError 异常。
class importlib.abc.InspectLoader
一个实现加载器检查模块可选的 PEP 302 协议的 loader 的抽象基类。
get_code(fullname)
返回一个模块的代码对象,或如果模块没有一个代码对象(例如,对于内置的模块来说,这会是这种情况),则为 None。 如果加载器不能找到请求的模块,则引发 ImportError 异常。
备注
当这个方法有一个默认的实现的时候,出于性能方面的考虑,如果有可能的话,建议覆盖它。
在 3.4 版更改: 不再抽象并且提供一个具体的实现。
abstractmethod get_source(fullname)
一个返回模块源的抽象方法。使用 universal newlines 作为文本字符串被返回,将所有可识别行分割符翻译成 '\n' 字符。 如果没有可用的源(例如,一个内置模块),则返回 None。 如果加载器不能找到指定的模块,则引发 ImportError 异常。
在 3.4 版更改: 引发 ImportError 而不是 NotImplementedError。
is_package(fullname)
可选方法,如果模块为包,则返回 True,否则返回 False。 如果 loader 找不到模块,则会触发 ImportError。
在 3.4 版更改: 引发 ImportError 而不是 NotImplementedError。
static source_to_code(data, path='<string>')
创建一个来自Python源码的代码对象。
参数 data 可以是任意 compile() 函数支持的类型(例如字符串或字节串)。 参数 path 应该是源代码来源的路径,这可能是一个抽象概念(例如位于一个 zip 文件中)。
在有后续代码对象的情况下,可以在一个模块中通过运行 exec(code, module.__dict__) 来执行它。
3.4 新版功能.
在 3.5 版更改: 使得这个方法变成静态的。
exec_module(module)
Loader.exec_module() 的实现。
3.4 新版功能.
load_module(fullname)
Loader.load_module() 的实现。
3.4 版后已移除: 使用 exec_module() 来代替。
class importlib.abc.ExecutionLoader
一个继承自 InspectLoader 的抽象基类,当被实现时,帮助一个模块作为脚本来执行。 这个抽象基类表示可选的 PEP 302 协议。
abstractmethod get_filename(fullname)
一个用来为指定模块返回 __file__ 的值的抽象方法。如果无路径可用,则引发 ImportError。
如果源代码可用,那么这个方法返回源文件的路径,不管是否是用来加载模块的字节码。
在 3.4 版更改: 引发 ImportError 而不是 NotImplementedError。
class importlib.abc.FileLoader(fullname, path)
一个继承自 ResourceLoader 和 ExecutionLoader,提供 ResourceLoader.get_data() 和 ExecutionLoader.get_filename() 具体实现的抽象基类。
参数 fullname 是加载器要处理的模块的完全解析的名字。参数 path 是模块文件的路径。
3.3 新版功能.
name
加载器可以处理的模块的名字。
path
模块的文件路径
load_module(fullname)
调用super的 load_module()。
3.4 版后已移除: 使用 Loader.exec_module() 来代替。
abstractmethod get_filename(fullname)
返回 path。
abstractmethod get_data(path)
读取 path 作为二进制文件并且返回来自它的字节数据。
class importlib.abc.SourceLoader
一个用于实现源文件(和可选地字节码)加载的抽象基类。这个类继承自 ResourceLoader 和 ExecutionLoader,需要实现:
-
ResourceLoader.get_data()
-
ExecutionLoader.get_filename()
应该是只返回源文件的路径;不支持无源加载。
由这个类定义的抽象方法用来添加可选的字节码文件支持。不实现这些可选的方法(或导致它们引发 NotImplementedError 异常)导致这个加载器只能与源代码一起工作。 实现这些方法允许加载器能与源 和 字节码文件一起工作。不允许只提供字节码的 无源式 加载。字节码文件是通过移除 Python 编译器的解析步骤来加速加载的优化,并且因此没有开放出字节码专用的 API。
path_stats(path)
返回一个包含关于指定路径的元数据的 dict 的可选的抽象方法。 支持的字典键有:
-
'mtime'(必选项): 一个表示源码修改时间的整数或浮点数; -
'size'(可选项):源码的字节大小。
字典中任何其他键会被忽略,以允许将来的扩展。 如果不能处理该路径,则会引发 OSError。
3.3 新版功能.
在 3.4 版更改: 引发 OSError 而不是 NotImplemented。
path_mtime(path)
返回指定文件路径修改时间的可选的抽象方法。
3.3 版后已移除: 在有了 path_stats() 的情况下,这个方法被弃用了。 没必要去实现它了,但是为了兼容性,它依然处于可用状态。 如果文件路径不能被处理,则引发 OSError 异常。
在 3.4 版更改: 引发 OSError 而不是 NotImplemented。
set_data(path, data)
往一个文件路径写入指定字节的的可选的抽象方法。任何中间不存在的目录不会被自动创建。
当对路径的写入因路径为只读而失败时 (errno.EACCES/PermissionError),不会传播异常。
在 3.4 版更改: 当被调用时,不再引起 NotImplementedError 异常。
get_code(fullname)
InspectLoader.get_code() 的具体实现。
exec_module(module)
Loader.exec_module() 的具体实现。
3.4 新版功能.
load_module(fullname)
Concrete implementation of Loader.load_module().
3.4 版后已移除: 使用 exec_module() 来代替。
get_source(fullname)
InspectLoader.get_source() 的具体实现。
is_package(fullname)
InspectLoader.is_package() 的具体实现。一个模块被确定为一个包的条件是:它的文件路径(由 ExecutionLoader.get_filename() 提供)当文件扩展名被移除时是一个命名为 __init__ 的文件,并且 这个模块名字本身不是以 __init__ 结束。
class importlib.abc.ResourceReader
被 TraversableResources 取代
提供读取 resources 能力的一个 abstract base class 。
从这个 ABC 的视角出发,resource 指一个包附带的二进制文件。常见的如在包的 __init__.py 文件旁的数据文件。这个类存在的目的是为了将对数据文件的访问进行抽象,这样包就和其数据文件的存储方式无关了。不论这些文件是存放在一个 zip 文件里还是直接在文件系统内。
对于该类中的任一方法,resource 参数的值都需要是一个在概念上表示文件名称的 path-like object。 这意味着任何子目录的路径都不该出现在 resouce 参数值内。 因为对于阅读器而言,包的位置就代表着「目录」。 因此目录和文件名就分别对应于包和资源。 这也是该类的实例都需要和一个包直接关联(而不是潜在指代很多包或者一整个模块)的原因。
想支持资源读取的加载器需要提供一个返回实现了此 ABC 的接口的 get_resource_reader(fullname) 方法。如果通过全名指定的模块不是一个包,这个方法应该返回 None。 当指定的模块是一个包时,应该只返回一个与这个抽象类ABC兼容的对象。
3.7 新版功能.
从 3.12 版起不建议使用,将在 3.14 版中移除: 使用 importlib.resources.abc.TraversableResources 代替。
abstractmethod open_resource(resource)
返回一个打开的 file-like object 用于 resource 的二进制读取。
如果无法找到资源,将会引发 FileNotFoundError。
abstractmethod resource_path(resource)
返回 resource 的文件系统路径。
如果资源并不实际存在于文件系统中,将会引发 FileNotFoundError。
abstractmethod is_resource(name)
如果 name 被视作资源,则返回True。如果 name 不存在,则引发 FileNotFoundError 异常。
abstractmethod contents()
反回由字符串组成的 iterable,表示这个包的所有内容。 请注意并不要求迭代器返回的所有名称都是实际的资源,例如返回 is_resource() 为假值的名称也是可接受的。
允许非资源名字被返回是为了允许存储的一个包和它的资源的方式是已知先验的并且非资源名字会有用的情况。比如,允许返回子目录名字,目的是当得知包和资源存储在文件系统上面的时候,能够直接使用子目录的名字。
这个抽象方法返回了一个不包含任何内容的可迭代对象。
class importlib.abc.Traversable
一个具有 pathlib.Path 中方法的子集并适用于遍历目录和打开文件的对象。
对于该对象在文件系统中的表示形式,请使用 importlib.resources.as_file()。
3.9 新版功能.
从 3.12 版起不建议使用,将在 3.14 版中移除: 使用 importlib.resources.abc.Traversable 代替。
name
抽象属性。 此对象的不带任何父引用的基本名称。
abstractmethod iterdir()
产出 self 中的 Traversable 对象。
abstractmethod is_dir()
如果 self 是一个目录则返回 True。
abstractmethod is_file()
如果 self 是一个文件则返回 True。
abstractmethod joinpath(child)
返回 self 中的 Traversable 子对象。
abstractmethod __truediv__(child)
返回 self 中的 Traversable 子对象。
abstractmethod open(mode='r', *args, **kwargs)
mode 可以为 'r' 或 'rb' 即以文本或二进制模式打开。 返回一个适用于读取的句柄(与 pathlib.Path.open 样同)。
当以文本模式打开时,接受与 io.TextIOWrapper 所接受的相同的编码格式形参。
read_bytes()
以字节串形式读取 self 的内容。
read_text(encoding=None)
以文本形式读取 self 的内容。
class importlib.abc.TraversableResources
针对能够为 importlib.resources.files() 接口提供服务的资源读取器的抽象基类。 子类化 importlib.resources.abc.ResourceReader 并为 importlib.resources.abc.ResourceReader 的抽象方法提供具体实现。 因此,任何提供了 importlib.abc.TraversableResources 的加载器也会提供 ResourceReader。
需要支持资源读取的加载器应实现此接口。
3.9 新版功能.
从 3.12 版起不建议使用,将在 3.14 版中移除: 使用 importlib.resources.abc.TraversableResources 代替。
abstractmethod files()
为载入的包返回一个 importlib.resources.abc.Traversable 对象。
importlib.machinery —— 导入器和路径钩子函数。
源代码: Lib/importlib/machinery.py
本模块包含多个对象,以帮助 import 查找并加载模块。
importlib.machinery.SOURCE_SUFFIXES
一个字符串列表,表示源模块的可识别的文件后缀。
3.3 新版功能.
importlib.machinery.DEBUG_BYTECODE_SUFFIXES
一个字符串列表,表示未经优化字节码模块的文件后缀。
3.3 新版功能.
3.5 版后已移除: 改用 BYTECODE_SUFFIXES 。
importlib.machinery.OPTIMIZED_BYTECODE_SUFFIXES
一个字符串列表,表示已优化字节码模块的文件后缀。
3.3 新版功能.
3.5 版后已移除: 改用 BYTECODE_SUFFIXES 。
importlib.machinery.BYTECODE_SUFFIXES
一个字符串列表,表示字节码模块的可识别的文件后缀(包含前导的句点符号)。
3.3 新版功能.
在 3.5 版更改: 该值不再依赖于 __debug__ 。
importlib.machinery.EXTENSION_SUFFIXES
一个字符串列表,表示扩展模块的可识别的文件后缀。
3.3 新版功能.
importlib.machinery.all_suffixes()
返回字符串的组合列表,代表标准导入机制可识别模块的所有文件后缀。这是个助手函数,只需知道某个文件系统路径是否会指向模块,而不需要任何关于模块种类的细节(例如 inspect.getmodulename())。
3.3 新版功能.
class importlib.machinery.BuiltinImporter
用于导入内置模块的 importer。 所有已知的内置模块都已列入 sys.builtin_module_names。 此类实现了 importlib.abc.MetaPathFinder 和 importlib.abc.InspectLoader 抽象基类。
此类只定义类的方法,以减轻实例化的开销。
在 3.5 版更改: 作为 PEP 489 的一部分,现在内置模块导入器实现了 Loader.create_module() 和 Loader.exec_module()。
class importlib.machinery.FrozenImporter
用于已冻结模块的 importer。 此类实现了 importlib.abc.MetaPathFinder 和 importlib.abc.InspectLoader 抽象基类。
此类只定义类的方法,以减轻实例化的开销。
在 3.4 版更改: 有了 create_module() 和 exec_module() 方法。
class importlib.machinery.WindowsRegistryFinder
Finder 用于查找在 Windows 注册表中声明的模块。该类实现了基础的 importlib.abc.MetaPathFinder 。
此类只定义类的方法,以减轻实例化的开销。
3.3 新版功能.
3.6 版后已移除: 改用 site 配置。未来版本的 Python 可能不会默认启用该查找器。
class importlib.machinery.PathFinder
用于 sys.path 和包的 __path__ 属性的 Finder 。该类实现了基础的 importlib.abc.MetaPathFinder。
此类只定义类的方法,以减轻实例化的开销。
classmethod find_spec(fullname, path=None, target=None)
类方法试图在 sys.path 或 path 上为 fullname 指定的模块查找 spec。对于每个路径条目,都会查看 sys.path_importer_cache 。如果找到非 False 的对象,则将其用作 path entry finder 来查找要搜索的模块。如果在 sys.path_importer_cache 中没有找到条目,那会在 sys.path_hooks 检索该路径条目的查找器,找到了则和查到的模块信息一起存入 sys.path_importer_cache 。如果查找器没有找到,则缓存中的查找器和模块信息都存为 None ,然后返回。
3.4 新版功能.
在 3.5 版更改: 如果当前工作目录不再有效(用空字符串表示),则返回 None,但在 sys.path_importer_cache 中不会有缓存值。
classmethod invalidate_caches()
为所有存于 sys.path_importer_cache 中的查找器,调用其 importlib.abc.PathEntryFinder.invalidate_caches() 方法。 sys.path_importer_cache 中为 None 的条目将被删除。
在 3.7 版更改: sys.path_importer_cache 中为 None 的条目将被删除。
在 3.4 版更改: 调用 sys.path_hooks 中的对象,当前工作目录为 '' (即空字符串)。
class importlib.machinery.FileFinder(path, *loader_details)
importlib.abc.PathEntryFinder 的一个具体实现,它会缓存来自文件系统的结果。
参数 path 是查找器负责搜索的目录。
loader_details 参数是数量不定的二元组,每个元组包含加载器及其可识别的文件后缀列表。加载器应为可调用对象,可接受两个参数,即模块的名称和已找到文件的路径。
查找器将按需对目录内容进行缓存,通过对每个模块的检索进行状态统计,验证缓存是否过期。因为缓存的滞后性依赖于操作系统文件系统状态信息的粒度,所以搜索模块、新建文件、然后搜索新文件代表的模块,这会存在竞争状态。如果这些操作的频率太快,甚至小于状态统计的粒度,那么模块搜索将会失败。为了防止这种情况发生,在动态创建模块时,请确保调用 importlib.invalidate_caches()。
3.3 新版功能.
path
查找器将要搜索的路径。
find_spec(fullname, target=None)
尝试在 path 中找到处理 fullname 的规格。
3.4 新版功能.
invalidate_caches()
清理内部缓存。
classmethod path_hook(*loader_details)
一个类方法,返回供 sys.path_hooks 使用的闭包。 使用直接提供给闭包的路径参数和间接提供的 loader_details 闭包将返回一个 FileFinder 的实例。
如果给闭包的参数不是已存在的目录,将会触发 ImportError。
class importlib.machinery.SourceFileLoader(fullname, path)
importlib.abc.SourceLoader 的一个具体实现,该实现子类化了 importlib.abc.FileLoader 并提供了其他一些方法的具体实现。
3.3 新版功能.
name
该加载器将要处理的模块名称。
path
源文件的路径
is_package(fullname)
如果 path 看似包的路径,则返回 True。
path_stats(path)
importlib.abc.SourceLoader.path_stats() 的具体代码实现。
set_data(path, data)
importlib.abc.SourceLoader.set_data() 的具体代码实现。
load_module(name=None)
importlib.abc.Loader.load_module() 的具体代码实现,这里要加载的模块名是可选的。
3.6 版后已移除: 改用 importlib.abc.Loader.exec_module() 。
class importlib.machinery.SourcelessFileLoader(fullname, path)
importlib.abc.FileLoader 的具体代码实现,可导入字节码文件(也即源代码文件不存在)。
请注意,直接用字节码文件(而不是源代码文件),会让模块无法应用于所有的 Python 版本或字节码格式有所改动的新版本 Python。
3.3 新版功能.
name
加载器将要处理的模块名。
path
二进制码文件的路径。
is_package(fullname)
根据 path 确定该模块是否为包。
get_code(fullname)
返回由 path 创建的 name 的代码对象。
get_source(fullname)
因为用此加载器时字节码文件没有源码文件,所以返回 None。
load_module(name=None)
importlib.abc.Loader.load_module() 的具体代码实现,这里要加载的模块名是可选的。
3.6 版后已移除: 改用 importlib.abc.Loader.exec_module() 。
class importlib.machinery.ExtensionFileLoader(fullname, path)
importlib.abc.ExecutionLoader 的具体代码实现,用于扩展模块。
参数 fullname 指定了加载器要支持的模块名。参数 path 是指向扩展模块文件的路径。
请注意,在默认情况下,在子解释器中导入未实现多阶段初始化的扩展模块 (参见 PEP 489) 将会失败,即使在其他情况下能够成功导入。
3.3 新版功能.
在 3.12 版更改: 在子解释器中使用时需要多阶段初始化。
name
装载器支持的模块名。
path
扩展模块的路径。
create_module(spec)
根据 PEP 489 ,由给定规范创建模块对象。
3.5 新版功能.
exec_module(module)
根据 PEP 489,初始化给定的模块对象。
3.5 新版功能.
is_package(fullname)
根据 EXTENSION_SUFFIXES ,如果文件路径指向某个包的 __init__ 模块,则返回 True。
get_code(fullname)
返回 None,因为扩展模块缺少代码对象。
get_source(fullname)
返回 None,因为扩展模块没有源代码。
get_filename(fullname)
返回 path。
3.4 新版功能.
class importlib.machinery.NamespaceLoader(name, path, path_finder)
一个针对命名空间包的 importlib.abc.InspectLoader 具体实现。 这是一个私有类的别名,仅为在命名空间包上内省 __loader__ 属性而被设为公有:
>>>
>>> from importlib.machinery import NamespaceLoader >>> import my_namespace >>> isinstance(my_namespace.__loader__, NamespaceLoader) True >>> import importlib.abc >>> isinstance(my_namespace.__loader__, importlib.abc.Loader) True
3.11 新版功能.
class importlib.machinery.ModuleSpec(name, loader, *, origin=None, loader_state=None, is_package=None)
针对特定模块的导入系统相关状态的规范说明。 这通常是作为模块的 __spec__ 属性对外公开。 在下面的描述中,圆括号内的名称给出了在模块对象上直接可用的对应属性,例如 module.__spec__.origin == module.__file__。 但是要注意,虽然 values 通常是相等的,但它们也可以因为两个对象之间没有进行同步而不相等。 举例来说,有可能在运行时更新模块的 __file__ 而这将不会自动反映在模块的 __spec__.origin 中,反之亦然。
3.4 新版功能.
name
(__name__)
模块的完整限定名称。 finder 总是应当将此属性设为一个非空字符串。
loader
(__loader__)
用于加载模块的 loader。 finder 总是应当设置此属性。
origin
(__file__)
应当被 loader 用来加载模块的位置。 例如,对于从 .py 文件加载的模块来说这将为文件名。 finder 总是应当将此属性设为一个有意义的值供 loader 使用。 在少数没有可用值的情况下(如命名空间包),它应当被设为 None。
submodule_search_locations
(__path__)
将被用于包的子模块查找的位置列表。 在大多数时候这将为单个目录。 finder 应当将此属性设为一个列表,甚至可以是空列表,以便提示导入系统指定的模块是一个包。 对于非包模块它应当被设为 None。 对于命名空间包它会在稍后被自动设为一个特殊对象。
loader_state
finder 可以将此属性设为一个包含额外的模块专属数据的对象供加载模块时使用。 在其他情况下应将其设为 None。
cached
(__cached__)
模块代码的编译版本的文件名。 finder 总是应当设置此属性但是对于不需要存储已编译代码的模块来说可以将其设为 None。
parent
(__package__)
(只读)指定模块所在的包的完整限定名称(或者对于最高层级模块来说则为空字符串)。 如果模块是包则它将与 name 相同。
has_location
如果 spec 的 origin 指向一个可加载的位置则为 True,
在其他情况下为 False。 该值将确定如何解读 origin 以及如何填充模块的 __file__。
importlib.util —— 导入器的工具程序代码
源代码: Lib/importlib/util.py
本模块包含了帮助构建 importer 的多个对象。
importlib.util.MAGIC_NUMBER
代表字节码版本号的字节串。若要有助于加载/写入字节码,可考虑采用 importlib.abc.SourceLoader。
3.4 新版功能.
importlib.util.cache_from_source(path, debug_override=None, *, optimization=None)
返回 PEP 3147/PEP 488 定义的,与源 path 相关联的已编译字节码文件的路径。 例如,如果 path 为 /foo/bar/baz.py 则 Python 3.2 中的返回值将是 /foo/bar/__pycache__/baz.cpython-32.pyc。 字符串 cpython-32 来自于当前的魔法标签 (参见 get_tag(); 如果 sys.implementation.cache_tag 未定义则将会引发 NotImplementedError)。
参数 optimization 用于指定字节码文件的优化级别。空字符串代表没有优化,所以 optimization 为 的 /foo/bar/baz.py,将会得到字节码路径为 /foo/bar/__pycache__/baz.cpython-32.pyc。None 会导致采用解释器的优化。任何其他字符串都会被采用,所以 optimization 为 '' 的 /foo/bar/baz.py 会导致字节码路径为 /foo/bar/__pycache__/baz.cpython-32.opt-2.pyc。optimization 字符串只能是字母数字,否则会触发 ValueError。
debug_override 参数已废弃,可用于覆盖系统的 __debug__ 值。True 值相当于将 optimization 设为空字符串。False 则相当于*optimization* 设为 1。如果 debug_override 和 optimization 都不为 None,则会触发 TypeError。
3.4 新版功能.
在 3.5 版更改: 增加了 optimization 参数,废弃了 debug_override 参数。
在 3.6 版更改: 接受一个 path-like object。
importlib.util.source_from_cache(path)
根据指向一个 PEP 3147 文件名的 path,返回相关联的源代码文件路径。 举例来说,如果 path 为 /foo/bar/__pycache__/baz.cpython-32.pyc 则返回的路径将是 /foo/bar/baz.py。 path 不需要已存在,但如果它未遵循 PEP 3147 或 PEP 488 的格式,则会引发 ValueError。 如果未定义 sys.implementation.cache_tag,则会引发 NotImplementedError。
3.4 新版功能.
在 3.6 版更改: 接受一个 path-like object。
importlib.util.decode_source(source_bytes)
对代表源代码的字节串进行解码,并将其作为带有通用换行符的字符串返回(符合 importlib.abc.InspectLoader.get_source() 要求)。
3.4 新版功能.
importlib.util.resolve_name(name, package)
将模块的相对名称解析为绝对名称。
如果 name 前面没有句点,那就简单地返回 name。这样就能采用 importlib.util.resolve_name('sys', __spec__.parent) 之类的写法,而无需检查是否需要 package 参数。
如果 name 是一个相对模块名称但 package 为假值(如为 None 或空字符串)则会引发 ImportError。 如果相对名称离开了其所在的包(如为从 spam 包请求 ..bacon 的形式)则也会引发 ImportError。
3.3 新版功能.
在 3.9 版更改: 为了改善与 import 语句的一致性,对于无效的相对导入尝试会引发 ImportError 而不是 ValueError。
importlib.util.find_spec(name, package=None)
查找模块的 spec,可选择相对于指定的 package 名称。 如果该模块位于 sys.modules 中,则会返回 sys.modules[name].__spec__ (除非 spec 为 None 或未设置,在此情况下则会引发 ValueError)。 在其他情况下将使用 sys.meta_path 进行搜索。 如果找不到任何 spec 则返回 None。
如果 name 为一个子模块(带有一个句点),则会自动导入父级模块。
name 和 package 的用法与 import_module() 相同。
3.4 新版功能.
在 3.7 版更改: 如果 package 实际上不是一个包(即缺少 __path__ 属性)则会引发 ModuleNotFoundError 而不是 AttributeError。
importlib.util.module_from_spec(spec)
基于 spec 和 spec.loader.create_module 创建一个新模块。
如果 spec.loader.create_module 未返回 None,那么先前已存在的属性不会被重置。另外,如果 AttributeError 是在访问 spec 或设置模块属性时触发的,则不会触发 。
本函数比 types.ModuleType 创建新模块要好,因为用到 spec 模块设置了尽可能多的导入控制属性。
3.5 新版功能.
importlib.util.spec_from_loader(name, loader, *, origin=None, is_package=None)
一个工厂函数,用于创建基于加载器的 ModuleSpec 实例。参数的含义与 ModuleSpec 的相同。该函数会利用当前可用的 loader API,比如 InspectLoader.is_package(),以填充所有缺失的规格信息。
3.4 新版功能.
importlib.util.spec_from_file_location(name, location, *, loader=None, submodule_search_locations=None)
一个工厂函数,根据文件路径创建 ModuleSpec 实例。缺失的信息将根据 spec 进行填补,利用加载器 API ,以及模块基于文件的隐含条件。
3.4 新版功能.
在 3.6 版更改: 接受一个 path-like object。
importlib.util.source_hash(source_bytes)
以字节串的形式返回 source_bytes 的哈希值。基于哈希值的 .pyc 文件在头部嵌入了对应源文件内容的 source_hash()。
3.7 新版功能.
importlib.util._incompatible_extension_module_restrictions(*, disable_check)
一个可以暂时跳过扩展模块兼容性检查的上下文管理器。 在默认情况下该检查将被启用并且当在子解释器中导入单阶段初始化模块时该检查会失败。 如果多阶段初始化模块没有显式地支持针对子解释器的 GIL,那么当它在一个有自己的 GIL 的解释器中被导入时,该检查也会失败。
请注意该函数是为了适应一种不寻常的情况;这种情况可能最终会消失。 这很有可能不是你需要考虑的事情。
你可以通过实现多阶段初始化的基本接口 (PEP 489) 并假装支持多解释器 (或解释器级的 GIL) 来获得与该函数相同的效果。
警告
使用该函数来禁用检查可能会导致预期之外的行为甚至崩溃。 它应当仅在扩展模块开发过程中使用。
3.12 新版功能.
class importlib.util.LazyLoader(loader)
此类会延迟执行模块加载器,直至该模块有一个属性被访问到。
此类 仅仅 适用于定义 exec_module() 作为需要控制模块使用何种模块类型的加载器。 出于相同理由,加载器的 create_module() 方法必须返回 None 或其 __class__ 属性可被改变并且不使用 槽位 的类型。 最后,用于替换已放入 sys.modules 的对象的模块将无法工作因为没有办法安全地在整个解释器中正确替换模块引用; 如果检测到这种替换则会引发 ValueError。
备注
如果项目对启动时间要求很高,只要模块未被用过,此类能够最小化加载模块的开销。对于启动时间并不重要的项目来说,由于加载过程中产生的错误信息会被暂时搁置,因此强烈不建议使用此类。
3.5 新版功能.
在 3.6 版更改: 开始调用 create_module(),移除 importlib.machinery.BuiltinImporter 和 importlib.machinery.ExtensionFileLoader 的兼容性警告。
classmethod factory(loader)
一个返回创建延迟加载器的可调用对象的类方法。 这专门被用于加载器由类而不是实例来传入的场合。
suffixes = importlib.machinery.SOURCE_SUFFIXES loader = importlib.machinery.SourceFileLoader lazy_loader = importlib.util.LazyLoader.factory(loader) finder = importlib.machinery.FileFinder(path, (lazy_loader, suffixes))
例子
用编程方式导入
要以编程方式导入一个模块,请使用 importlib.import_module() :
import importlibitertools = importlib.import_module('itertools')
检查某模块可否导入。
如果你需要在不实际执行导入的情况下确定某个模块是否可被导入,则你应当使用 importlib.util.find_spec()。
请注意如果 name 是一个子模块(即包含一个点号),则 importlib.util.find_spec() 将会导入父模块。
import importlib.util
import sys# For illustrative purposes.
name = 'itertools'if name in sys.modules:print(f"{name!r} already in sys.modules")
elif (spec := importlib.util.find_spec(name)) is not None:# If you chose to perform the actual import ...module = importlib.util.module_from_spec(spec)sys.modules[name] = modulespec.loader.exec_module(module)print(f"{name!r} has been imported")
else:print(f"can't find the {name!r} module")
直接导入源码文件。
要直接导入 Python 源文件,请使用以下写法:
import importlib.util import sys# For illustrative purposes. import tokenize file_path = tokenize.__file__ module_name = tokenize.__name__spec = importlib.util.spec_from_file_location(module_name, file_path) module = importlib.util.module_from_spec(spec) sys.modules[module_name] = module spec.loader.exec_module(module)
实现延迟导入
以下例子展示了如何实现延迟导入:
>>>
>>> import importlib.util
>>> import sys
>>> def lazy_import(name):
... spec = importlib.util.find_spec(name)
... loader = importlib.util.LazyLoader(spec.loader)
... spec.loader = loader
... module = importlib.util.module_from_spec(spec)
... sys.modules[name] = module
... loader.exec_module(module)
... return module
...
>>> lazy_typing = lazy_import("typing")
>>> #lazy_typing is a real module object,
>>> #but it is not loaded in memory yet.
>>> lazy_typing.TYPE_CHECKING
False
导入器的配置
对于导入的深度定制,通常你需要实现一个 importer。 这意味着同时管理 finder 和 loader 两方面。 对于查找器来说根据你的需求有两种类别可供选择: meta path finder 或 path entry finder。 前者你应当放到 sys.meta_path 而后者是使用 path entry hook 在 sys.path_hooks 上创建并与 sys.path 条目一起创建一个潜在的查找器。 下面的例子将向你演示如何注册自己的导入器供导入机制使用 (关于自行创建导入器,请阅读在本包内定义的相应类的文档):
import importlib.machinery import sys# For illustrative purposes only. SpamMetaPathFinder = importlib.machinery.PathFinder SpamPathEntryFinder = importlib.machinery.FileFinder loader_details = (importlib.machinery.SourceFileLoader,importlib.machinery.SOURCE_SUFFIXES)# Setting up a meta path finder. # Make sure to put the finder in the proper location in the list in terms of # priority. sys.meta_path.append(SpamMetaPathFinder)# Setting up a path entry finder. # Make sure to put the path hook in the proper location in the list in terms # of priority. sys.path_hooks.append(SpamPathEntryFinder.path_hook(loader_details))
importlib.import_module() 的近似实现
导入过程本身是用 Python 代码实现的,这样就有可能通过 importlib 来对外公开大部分导入机制。 以下代码通过提供 importlib.import_module() 的近似实现来说明 importlib 所公开的几种 API:
import importlib.util
import sysdef import_module(name, package=None):"""An approximate implementation of import."""absolute_name = importlib.util.resolve_name(name, package)try:return sys.modules[absolute_name]except KeyError:passpath = Noneif '.' in absolute_name:parent_name, _, child_name = absolute_name.rpartition('.')parent_module = import_module(parent_name)path = parent_module.__spec__.submodule_search_locationsfor finder in sys.meta_path:spec = finder.find_spec(absolute_name, path)if spec is not None:breakelse:msg = f'No module named {absolute_name!r}'raise ModuleNotFoundError(msg, name=absolute_name)module = importlib.util.module_from_spec(spec)sys.modules[absolute_name] = modulespec.loader.exec_module(module)if path is not None:setattr(parent_module, child_name, module)return module相关文章:

importlib --- import 的实现
3.1 新版功能. 源代码 Lib/importlib/__init__.py 概述 importlib 包具有三重目标。 一是在 Python 源代码中提供 import 语句的实现(并且因此而扩展 __import__() 函数)。 这提供了一个可移植到任何 Python 解释器的 import 实现。 与使用 Python 以…...

【PyTorch】现代卷积神经网络
文章目录 1. 理论介绍1.1. 深度卷积神经网络(AlexNet)1.1.1. 概述1.1.2. 模型设计 1.2. 使用块的网络(VGG)1.3. 网络中的网络(NiN)1.4. 含并行连结的网络(GoogLeNet)1.5. 批量规范化…...

用python编写九九乘法表
1 问题 我们在学习一门语言的过程中,都会练习到编写九九乘法表这个代码,下面介绍如何编写九九乘法表的流程。 2 方法 (1)打开pycharm集成开发环境,创建一个python文件,并编写第一行代码,主要构建…...
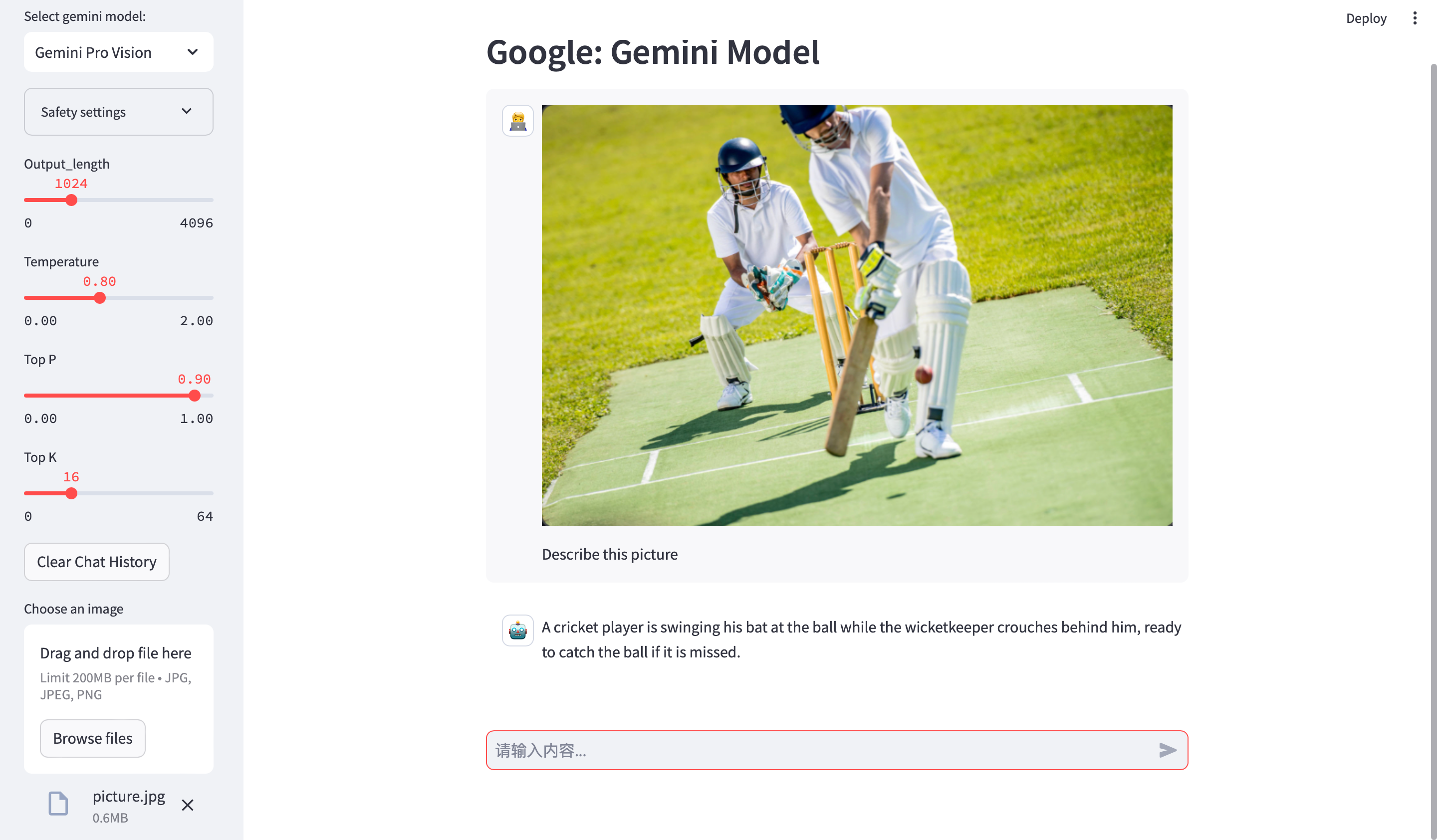
Google Gemini 模型本地可视化
Google近期发布了Gemini模型,而且开放了Gemini Pro API,Gemini Pro 可免费使用! Gemini Pro支持全球180个国家的38种语言,目前接受文本、图片作为输入并生成文本作为输出。 Gemini Pro的表现超越了其他同类模型,当前版…...

数据修复:.BlackBit勒索病毒来袭,安全应对方法解析
导言: 黑色数字罪犯的新玩具——.BlackBit勒索病毒,近来成为网络安全领域的头号威胁。这种恶意软件以其高度隐秘性和毁灭性而引起广泛关注。下面是关于.BlackBit勒索病毒的详细介绍,如不幸感染这个勒索病毒,您可添加我们的技术服…...

拓扑排序实现循环依赖判断 | 京东云技术团队
本文记录如何通过拓扑排序,实现循环依赖判断 前言 一般提到循环依赖,首先想到的就是Spring框架提供的Bean的循环依赖检测,相关文档可参考: https://blog.csdn.net/cristianoxm/article/details/113246104 本文方案脱离Spring Be…...
Java的NIO工作机制
文章目录 1. 问题引入2. NIO的工作方式3. Buffer的工作方式4. NIO数据访问方式 1. 问题引入 在网络通信中,当连接已经建立成功,服务端和客户端都会拥有一个Socket实例,每个Socket实例都有一个InputStream和OutputStream,并通过这…...

一个简单的光线追踪渲染器
前言 本文参照自raytracing in one weekend教程,地址为:https://raytracing.github.io/books/RayTracingInOneWeekend.html 什么是光线追踪? 光线追踪模拟现实中的成像原理,通过模拟一条条直线在场景内反射折射,最终…...
C++学习笔记(十二)------is_a关系(继承关系)
你好,这里是争做图书馆扫地僧的小白。 个人主页:争做图书馆扫地僧的小白_-CSDN博客 目标:希望通过学习技术,期待着改变世界。 提示:以下是本篇文章正文内容,下面案例可供参考 文章目录 前言 一、继承关系…...

DC电源模块的设计与制造技术创新
BOSHIDA DC电源模块的设计与制造技术创新 DC电源模块的设计与制造技术创新主要涉及以下几个方面: 1. 高效率设计:传统的DC电源模块存在能量转换损耗较大的问题,技术创新可通过采用高效率的电路拓扑结构、使用高性能的功率开关器件和优化控制…...

Sketch for Mac:实现你的创意绘图梦想的矢量绘图软件
随着数字时代的到来,矢量绘图软件成为了广告设计、插画创作和UI设计等领域中必不可少的工具。在众多矢量绘图软件中,Sketch for Mac(矢量绘图软件)以其强大的功能和简洁的界面脱颖而出,成为了众多设计师的首选。 Sket…...

ReactNative0.73发布,架构升级与更好的调试体验
这次更新包含了多种提升开发体验的改进,包括: 更流畅的调试体验: 通过 Hermes 引擎调试支持、控制台日志历史记录和实验性调试器,让调试过程更加高效顺畅。稳定的符号链接支持: 简化您的开发工作流程,轻松将文件或目录链接到其他…...

SVN忽略文件的两种方式
当使用版本管理工具时,提交到代码库的文档我们不希望存在把一些临时文件也推送到仓库中,这样就需要用到忽略文件。SVN的忽略相比于GIT稍显麻烦,GIT只需要在.gitignore添加忽略规则即可。而SVN有两种忽略方式,一个是全局设置&#…...

手写VUE后台管理系统10 - 封装Axios实现异常统一处理
目录 前后端交互约定安装创建Axios实例拦截器封装请求方法业务异常处理 axios 是一个易用、简洁且高效的http库 axios 中文文档:http://www.axios-js.com/zh-cn/docs/ 前后端交互约定 在本项目中,前后端交互统一使用 application/json;charsetUTF-8 的请…...

JavaScript装饰者模式
JavaScript装饰者模式 1 什么是装饰者模式2 模拟装饰者模式3 JavaScript的装饰者4 装饰函数5 AOP装饰函数6 示例:数据统计上报 1 什么是装饰者模式 在程序开发中,许多时候都我们并不希望某个类天生就非常庞大,一次性包含许多职责。那么我们就…...

C++学习笔记01
01.C概述(了解) c语言在c语言的基础上添加了面向对象编程和泛型编程的支持。 02.第一个程序helloworld(掌握) #define _CRT_SECURE_NO_WARNINGS #include<iostream> using namespace std;//标准命名空间int main() {//co…...
【UE5】初识MetaHuman 创建虚拟角色
步骤 在UE5工程中启用“Quixel Bridge”插件 打开“Quixel Bridge” 点击“MetaHumans-》MetaHuman Presets UE5” 点击“START MHC” 在弹出的网页中选择一个虚幻引擎版本,然后点击“启动 MetaHuman Creator” 等待一段时间后,在如下页面点击选择一个人…...

物流实时数仓:数仓搭建(DWD)一
系列文章目录 物流实时数仓:采集通道搭建 物流实时数仓:数仓搭建 物流实时数仓:数仓搭建(DIM) 物流实时数仓:数仓搭建(DWD)一 文章目录 系列文章目录前言一、文件编写1.目录创建2.b…...

MATLAB安装
亲自验证有效,多谢这位网友的分享: https://blog.csdn.net/xiajinbiaolove/article/details/88907232...
C语言——预处理详解(#define用法+注意事项)
#define 语法规定 #define定义标识符 语法: #define name stuff #define例子 #include<stdio.h> #define A 100 #define STR "abc" #define FOR for(;;)int main() {printf("%d\n", A);printf("%s\n", STR);FOR;return 0; } 运行结果…...

Cogito-v1-preview-llama-3B效果展示:STEM题目分步推导+代码生成真实截图
Cogito-v1-preview-llama-3B效果展示:STEM题目分步推导代码生成真实截图 1. 模型能力概览 Cogito v1 预览版是Deep Cogito推出的混合推理模型系列,在大多数标准基准测试中均超越了同等规模下最优的开源模型。这个3B参数的模型在编码、STEM题目解答、指…...

家庭实验室:树莓派控制OpenClaw调用远程Qwen3-32B
家庭实验室:树莓派控制OpenClaw调用远程Qwen3-32B 1. 为什么选择树莓派OpenClaw组合 去年冬天,我在整理家庭实验室设备时发现一个闲置的树莓派4B。这台信用卡大小的电脑曾经用来跑Home Assistant控制智能家居,但后来换了NUC主机就被束之高阁…...

Linux性能调优实战:CPU与内存优化指南
Linux 性能调优实战指南1. 性能优化基础概念1.1 性能指标Linux性能优化的两个核心指标是吞吐量和延迟。从应用负载角度看,直接影响终端用户体验;从系统资源角度看,关注资源使用率和饱和度。性能问题的本质是系统资源已达瓶颈但请求处理不够快…...

终极指南:用Java打造你的专属微信机器人 - 深入解析wechat-api框架
终极指南:用Java打造你的专属微信机器人 - 深入解析wechat-api框架 【免费下载链接】wechat-api 🗯 wechat-api by java7. 项目地址: https://gitcode.com/gh_mirrors/we/wechat-api 想象一下这样的场景:每天早上7点,你的微…...

风扇智能调节终极指南:三步打造安静高效的散热系统
风扇智能调节终极指南:三步打造安静高效的散热系统 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/Fa…...

Nuxt4 官网访问来源统计的实现
今天我遇到一个值得记录的问题,场景是这样的:官网后台需要做访问统计,我得把访问来源和访问目标的 URL 传递给后端。绕了好一阵子,才终于理清楚。 项目结构上,Nuxt 4 负责官网展示,后端是 Java 服务。核心…...

【AI+教育】AI总犯“金鱼记忆”?揭秘大模型长期记忆架构,让它真正记住你!
在和AI对话时,你是否有过这样的抓狂时刻:前脚刚告诉它“我叫小明,我不吃香蕉”,五分钟后它又热情地向你推荐香蕉饼? 目前的多数大语言模型就像拥有“金鱼记忆”,一刷新就忘得一干二净。为了让智能体(Agent)能像真正的老朋友一样懂你,我们设计了一套长期记忆功能模块。…...

【实战指南】SVN SSL协议不兼容问题:从TLS版本冲突到降级解决方案
1. 当SVN遇上SSL:TLS协议冲突的典型症状 最近在帮团队排查SVN代码拉取问题时,遇到了一个经典的错误提示:"error running context: an error occurred during ssl communication"。这个看似简单的报错背后,其实是现代加密…...

解锁TikTok电商API:PHP开发者的零门槛接入方案
解锁TikTok电商API:PHP开发者的零门槛接入方案 【免费下载链接】tiktokshop-php Unofficial Tiktok Shop API Client in PHP. Use API version 202309 and later 项目地址: https://gitcode.com/gh_mirrors/ti/tiktokshop-php 跨境电商API对接新选择…...

ZephyrOS--实战Bluetooth LE心率监测
1. 从零开始搭建ZephyrOS开发环境 第一次接触ZephyrOS时,我花了整整两天时间才把开发环境搭好。现在回想起来,其实只要掌握几个关键步骤就能避开那些坑。这里我以nRF52开发板为例,带你快速搭建起心率监测项目的开发环境。 首先需要安装Zephyr…...