单机架构到分布式架构的演变
目录
1.单机架构
2.应用数据分离架构
3.应用服务集群架构
4.读写分离 / 主从分离架构
5.引入缓存 —— 冷热分离架构
6.垂直分库
7.业务拆分 —— 微服务
8.容器化引入——容器编排架构
总结
1.单机架构
初期,我们需要利用我们精干的技术团队,快速将业务系统投入市场进行检验,并且可以迅速响应变化要求。但好在前期用户访问量很少,没有对我们的性能、安全等提出很高的要求,而且系统架构简单,无需专业的运维团队,所以选择单机架构是合适的。

用户在浏览器中输入 www.baidu.com,首先经过 DNS 服务将域名解析成 IP 地址10.102.41.1,随后浏览器访问该 IP 对应的应用服务。
优点:部署简单,成本低
缺点:存在严重的性能瓶颈, 数据库和应用互相竞争资源
2.应用数据分离架构
随着系统的上线,我们不出意外地获得了成功。市场上出现了一批忠实于我们的用户,使得系统的访问量逐步上升,逐渐逼近了硬件资源的极限,同时团队也在此期间积累了对业务流程的一批经验。面对当前的性能压力,我们需要未雨绸缪去进行系统重构、架构挑战,以提升系统的承载能力。但由于预算仍然很紧张,我们选择了将应用和数据分离的做法,可以最小代价的提升系统的承载能力。
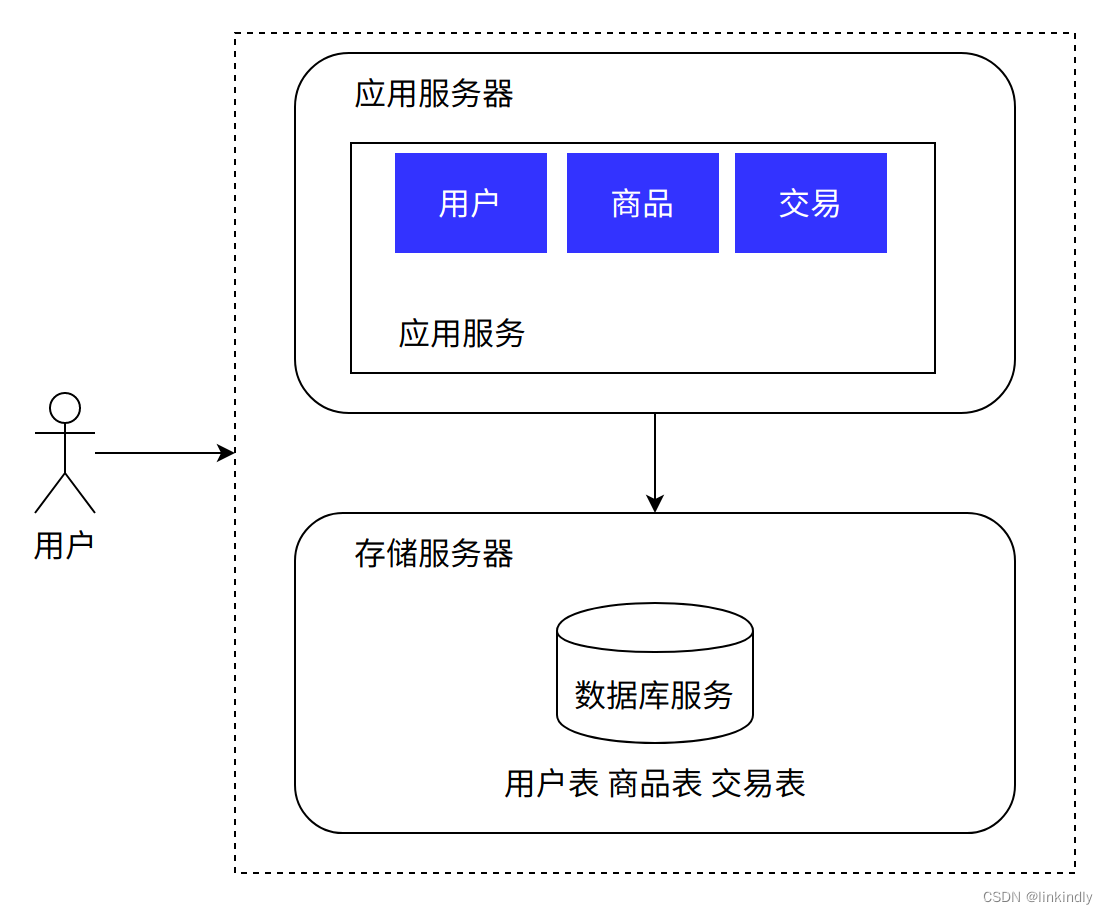
和之前架构的主要区别在于将数据库服务独立部署在同一个数据中心的其他服务器上,应用服务通过网络访问数据。
优点:成本相对可控,性能相比单机有提升,数据库单独隔离,不会因为应用把数据库搞坏,有一定的容灾能力
缺点:硬件成本变高,性能有瓶颈,无法应对海量并发
3.应用服务集群架构
我们的系统受到了用户的欢迎,并且出现了爆款,单台应用服务器已经无法满足需求了。我们的单机应用服务器首先遇到了瓶颈,摆在我们技术团队面前的有两种方案,大家针对方案的优劣展示了热烈的讨论:
• 垂直扩展 / 纵向扩展 Scale Up。通过购买性能更优、价格更高的应用服务器来应对更多的流量。这种方案的优势在于完全不需要对系统软件做任何的调整;但劣势也很明显:硬件性能和价格的增长关系是非线性的,意味着选择性能 2 倍的硬件可能需要花费超过 4 倍的价格,其次硬件性能提升是有明显上限的。
• 水平扩展 / 横向扩展 Scale Out。通过调整软件架构,增加应用层硬件,将用户流量分担到不同的应用层服务器上,来提升系统的承载能力。这种方案的优势在于成本相对较低,并且提升的上限空间也很大。但劣势是带给系统更多的复杂性,需要技术团队有更丰富的经验。经过团队的学习、调研和讨论,最终选择了水平扩展的方案,来解决该问题,但这需要引入一个新的组件 —— 负载均衡:为了解决用户流量向哪台应用服务器分发的问题,需要一个专门的系统组件做流量分发。实际中负载均衡不仅仅指的是工作在应用层的,甚至可能是其他的网络层之中。同时流量调度算法也有很多种,这里简单介绍几种较为常见的:
• Round-Robin 轮询算法。即非常公平地将请求依次分给不同的应用服务器。
• Weight-Round-Robin 轮询算法。为不同的服务器(比如性能不同)赋予不同的权
重(weight),能者多劳。
• 一致哈希散列算法。通过计算用户的特征值(比如 IP 地址)得到哈希值,根据哈希结果做分发,优点是确保来自相同用户的请求总是被分给指定的服务器。也就是我们平时遇到的专项客户经理服务。
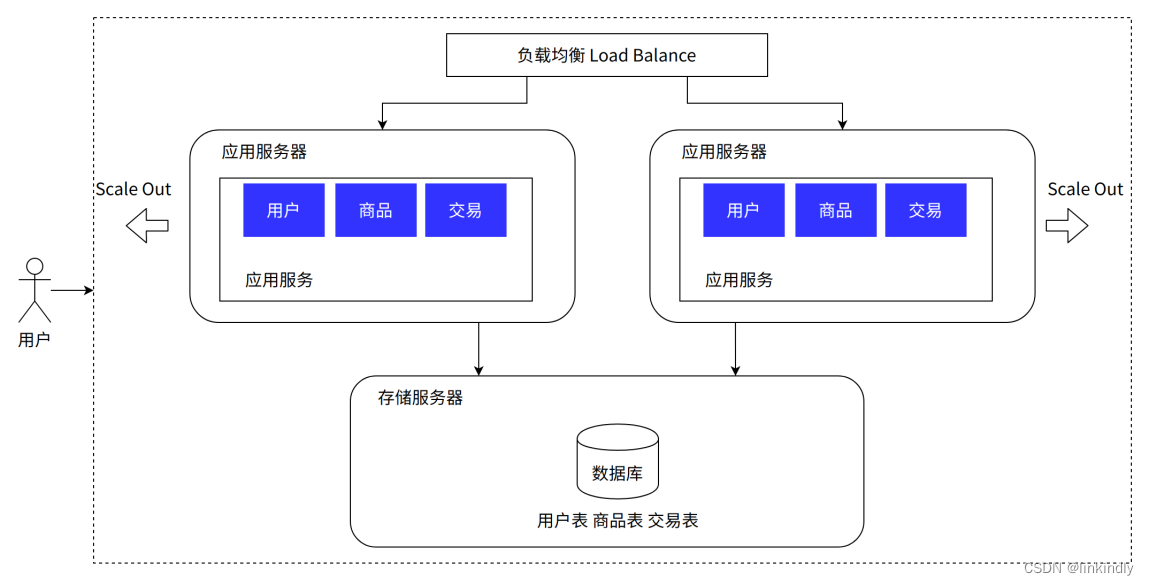
优点: 应用服务高可用:应用满足高可用,不会一个服务出问题整个站点挂掉;应用服务具备一定高性能:如果不访问数据库,应用相关处理通过扩展可以支持海量请求快速响应;应用服务有一定扩展能力:支持横向扩展
缺点:数据库成为性能瓶颈,无法应对数据库的海量查询;数据库是单点,没有高可用;运维工作增多,扩展后部署运维工作增多,需要开发对应的工具应对快速部署;硬件成本较高
4.读写分离 / 主从分离架构
前面提到,我们把用户的请求通过负载均衡分发到不同的应用服务器之后,可以并行处理了,并且可以随着业务的增长,可以动态扩张服务器的数量来缓解压力。但是现在的架构里,无论扩展多少台服务器,这些请求最终都会从数据库读写数据,到一定程度之后,数据的压力称为系统承载能力的瓶颈点。我们可以像扩展应用服务器一样扩展数据库服务器么?答案是否定的,因为数据库服务有其特殊性:如果将数据分散到各台服务器之后,数据的一致性将无法得到保障。所谓数据的一致性,此处是指:针对同一个系统,无论何时何地,我们都应该看到一个始终维持统一的数据。想象一下,银行管理的账户金额,如果收到一笔转账之后,一份数据库的数据修改了,但另外的数据库没有修改,则用户得到的存款金额将是错误的。我们采用的解决办法是这样的,保留一个主要的数据库作为写入数据库,其他的数据库作为从属数据库。从库的所有数据全部来自主库的数据,经过同步后,从库可以维护着与主库一致的数据。然后为了分担数据库的压力,我们可以将写数据请求全部交给主库处理,但读请求分散到各个从库中。由于大部分的系统中,读写请求都是不成比例的,例如 100 次读 1 次写,所以只要将读请求由各个从库分担之后,数据库的压力就没有那么大了。当然这个过程不是无代价的,主库到从库的数据同步其实是有时间成本的,但这个问题我们暂时不做进一步探讨。
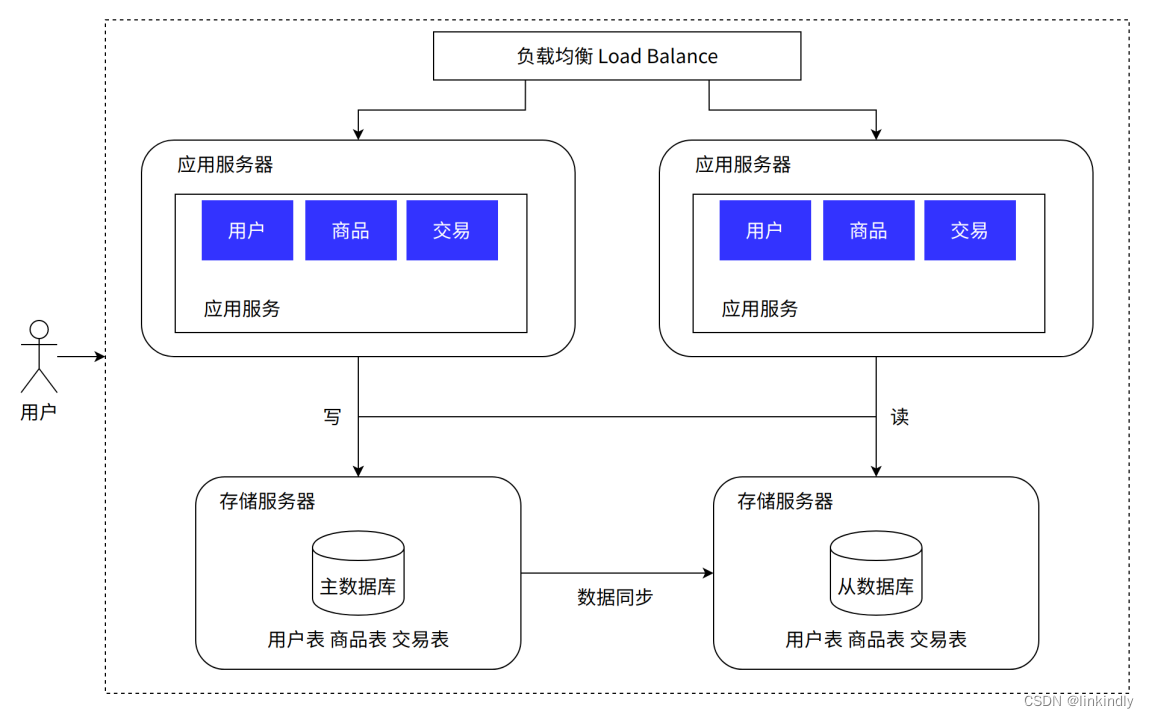
优点: 数据库的读取性能提升;读取被其他服务器分担,写的性能间接提升;数据库有从库,数据库的可用性提高了
缺点:热点数据的频繁读取导致数据库负载很高;当同步挂掉,或者同步延迟比较大时,写库和读库的数据不一致;服务器成本需要进一步增加
5.引入缓存 —— 冷热分离架构
随着访问量继续增加,发现业务中一些数据的读取频率远大于其他数据的读取频率。我们把这部分数据称为热点数据,与之相对应的是冷数据。针对热数据,为了提升其读取的响应时间,可以增加本地缓存,并在外部增加分布式缓存,缓存热门商品信息或热门商品的 html 页面等。通过缓存能把绝大多数请求在读写数据库前拦截掉,大大降低数据库压力。其中涉及的技术包括:使用 memcached 作为本地缓存,使用Redis 作为分布式缓存,还会涉及缓存一致性、缓存穿透/击穿、缓存雪崩、热点数据集中失效等问题。
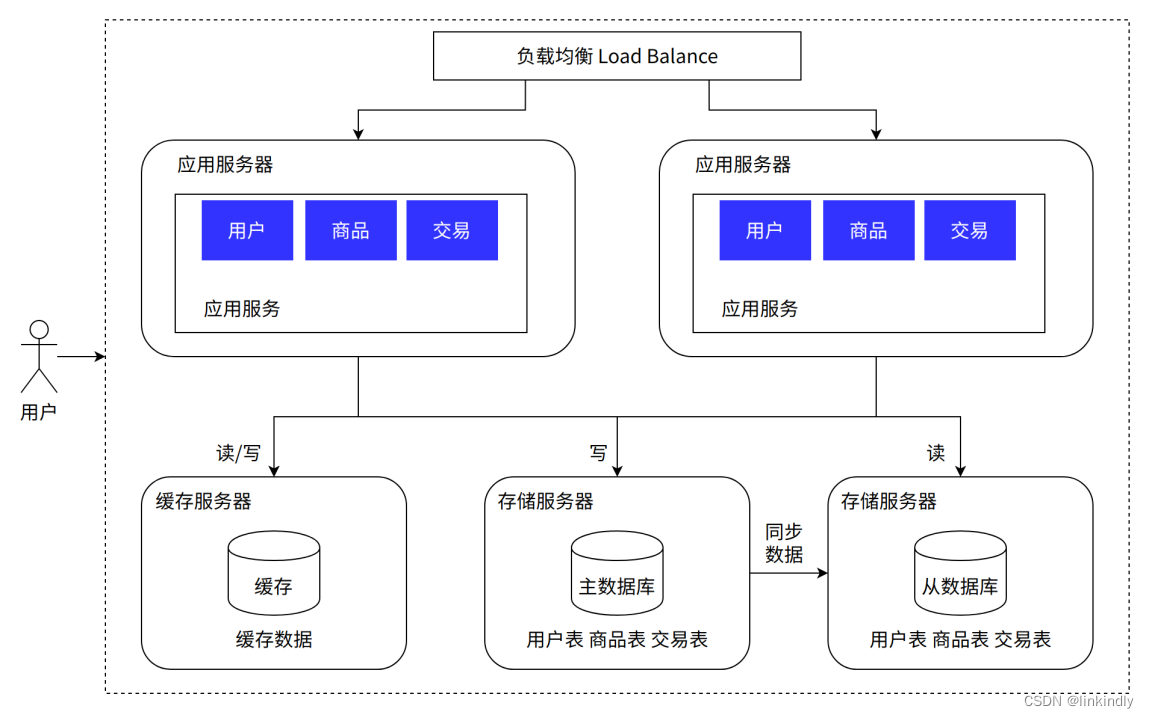
优点:大幅降低对数据库的访问请求,性能提升非常明显;
缺点:带来了缓存一致性,缓存击穿,缓存失效,缓存雪崩等问题;服务器成本需要进一步增加;业务体量支持变大后,数据不断增加,数据库单库太大,单个表体量也太大,数据查询会很慢,导致数据库再度成为系统瓶颈
6.垂直分库
随着业务的数据量增大,大量的数据存储在同一个库中已经显得有些力不从心了,所以可以按照业务,将数据分别存储。比如针对评论数据,可按照商品 ID 进行 hash,路由到对应的表中存储;针对支付记录,可按照小时创建表,每个小时表继续拆分为小表,使用用户 ID 或记录编号来路由数据。只要实时操作的表数据量足够小,请求能够足够均匀的分发到多台服务器上的小表,那数据库就能通过水平扩展的方式来提高性能。其中前面提到的 Mycat 也支持在大表拆分为小表情况下的访问控制。这种做法显著的增加了数据库运维的难度,对 DBA 的要求较高。数据库设计到这种结构时,已经可以称为分布式数据库,但是这只是一个逻辑的数据库整体,数据库里不同的组成部分是由不同的组件单独来实现的,如分库分表的管理和请求分发,由 Mycat 实现,SQL 的解析由单机的数据库实现,读写分离可能由网关和消息队列来实现,查询结果的汇总可能由数据库接口层来实现等等,这种架构其实是 MPP(大规模并行处理)架构的一类实现。
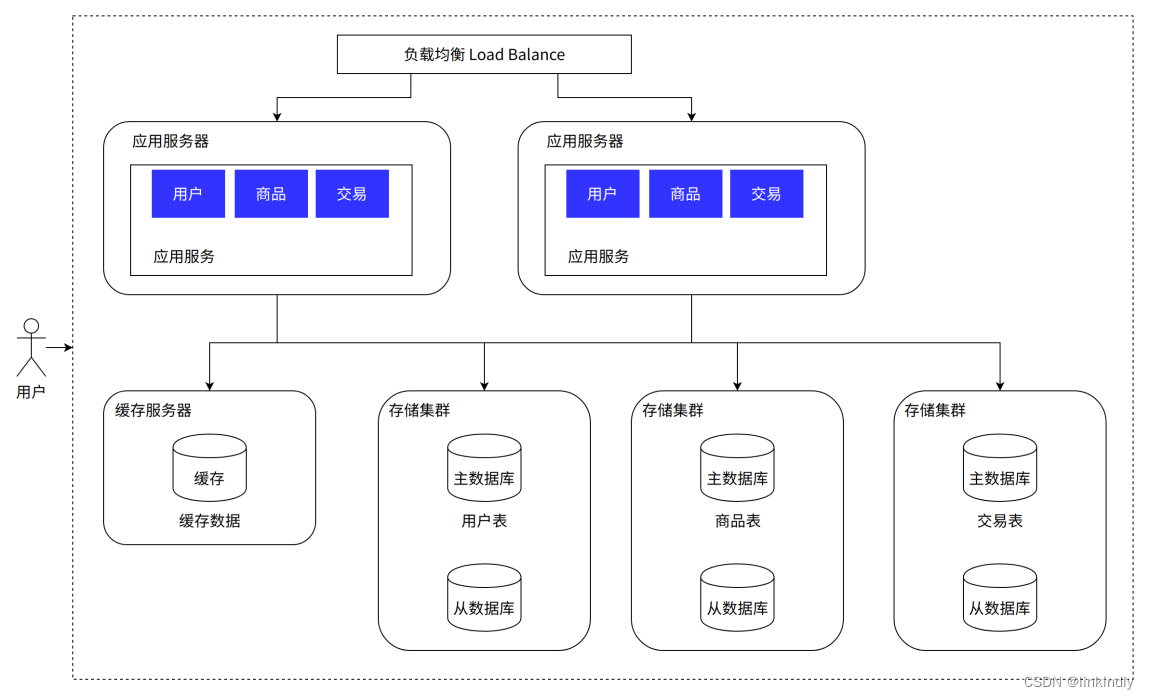
优点:数据库吞吐量大幅提升,不再是瓶颈;
缺点:跨库join、分布式事务等问题,这些需要对应的去进行解决,目前的mpp都有对应的解决方案;数据库和缓存结合目前能够抗住海量的请求,但是应用的代码整体耦合在一起,修改一行代码需要整体重新发布
7.业务拆分 —— 微服务
随着人员增加,业务发展,我们将业务分给不同的开发团队去维护,每个团队独立实现自己的微服务,然后互相之间对数据的直接访问进行隔离,可以利用 Gateway、消息总线等技术,实现相互之间的调用关联。甚至可以把一些类似用户管理等业务提成公共服务。

优点: 灵活性高:服务独立测试、部署、升级、发布;独立扩展:每个服务可以各自进行扩展;提高容错性:一个服务问题并不会让整个系统瘫痪;新技术的应用容易:支持多种编程语言
缺点:运维复杂度高:业务不断发展,应用和服务都会不断变多,应用和服务的部署变得复杂,同一台服务器上部署多个服务还要解决运行环境冲突的问题,此外,对于如大促这类需要动态扩缩容的场景,需要水平扩展服务的性能,就需要在新增的服务上准备运行环境,部署服务等,运维将变得十分困难;资源使用变多:所有这些独立运行的微服务都需要需要占用内存和 CPU ;处理故障困难:一个请求跨多个服务调用,需要查看不同服务的日志完成问题定位
8.容器化引入——容器编排架构
随着业务增长,然后发现系统的资源利用率不高,很多资源用来应对短时高并发,平时又闲置,需要动态扩缩容,还没有办法直接下线服务器,而且开发、测试、生产每套环境都要隔离的环境,运维的工作量变的非常大。容器化技术的出现给这些问题的解决带来了新的思路。
目前最流行的容器化技术是 Docker,最流行的容器管理服务是 Kubernetes(K8S),应用/服务可以打包为 Docker 镜像,通过 K8S 来动态分发和部署镜像。Docker 镜像可理解为一个能运行你的应用/服务的最小的操作系统,里面放着应用/服务的运行代码,运行环境根据实际的需要设置好。把整个“操作系统”打包为一个镜像后,就可以分发到需要部署相关服务的机器上,直接启动 Docker 镜像就可以把服务起起来,使服务的部署和运维变得简单。服务
通常会有生产和研发 k8s 集群,一般不会公用,而研发集群通过命名空间来完成应用隔离,有的公司按照研发目的划分为研发和测试集群,有的公司通过组织架构完成部门间的资源复用。
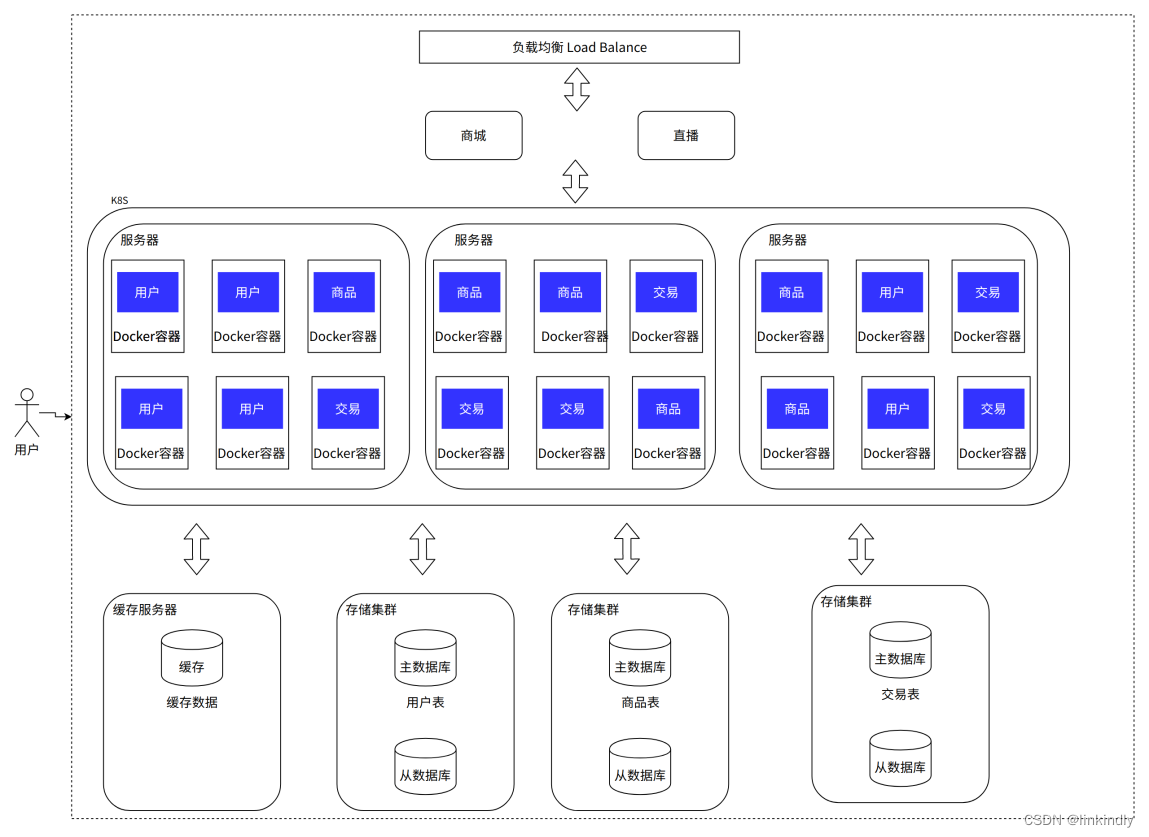
优点:部署、运维简单快速:一条命令就可以完成几百个服务的部署或者扩缩容;隔离性好:容器与容器之间文件系统、网络等互相隔离,不会产生环境冲突;轻松支持滚动更新:版本间切换都可以通过一个命令完成升级或者回滚
缺点:技术栈变多,对研发团队要求高;机器还是需要公司自身来管理,在非大促的时候,还是需要闲置着大量的机器资源来应对大促,机器自身成本和运维成本都极高,资源利用率低,可以通过购买云厂商服务器解决。
总结
至此,一个还算合理的高可用、高并发系统的基本雏形已显。注意,以上所说的架构演变顺序只是针对某个侧面进行单独的改进,在实际场景中,可能同一时间会有几个问题需要解决,或者可能先达到瓶颈的是另外的方面,这时候就应该按照实际问题实际解决。如在政府类的并发量可能不大,但业务可能很丰富的场景,高并发就不是重点解决的问题,此时优先需要的可能会是丰富需求的解决方案。对于单次实施并且性能指标明确的系统,架构设计到能够支持系统的性能指标要求就足够了,但要留有扩展架构的接口以便不备之需。对于不断发展的系统,如电商平台,应设计到能满足下一阶段用户量和性能指标要求的程度,并根据业务的增长不断的迭代升级架构,以支持更高的并发和更丰富的业务。所谓的“大数据”其实是海量数据采集清洗转换、数据存储、数据分析、数据服务等场景解决方案的一个统称,在每一个场景都包含了多种可选的技术,如数据采集有Flume、Sqoop、Kettle 等,数据存储有分布式文件系统 HDFS、FastDFS,NoSQL数据库 HBase、MongoDB 等,数据分析有 Spark 技术栈、机器学习算法等。总的来说大数据架构就是根据业务的需求,整合各种大数据组件组合而成的架构,一般会提供分布式存储、分布式计算、多维分析、数据仓库、机器学习算法等能力。而服务端架构更多指的是应用组织层面的架构,底层能力往往是由大数据架构来提供。
相关文章:
单机架构到分布式架构的演变
目录 1.单机架构 2.应用数据分离架构 3.应用服务集群架构 4.读写分离 / 主从分离架构 5.引入缓存 —— 冷热分离架构 6.垂直分库 7.业务拆分 —— 微服务 8.容器化引入——容器编排架构 总结 1.单机架构 初期,我们需要利用我们精干的技术团队,快…...
1.新入手的32位单片机资源和资料总览
前言: 学了将近1年的linux驱动和uboot,感觉反馈不足,主要是一直在学各种框架,而且也遇到了门槛,比如驱动部分,还不能随心所欲地编程,原因是有些外设的原理还不够深刻、有些复杂的底层驱动的代码…...
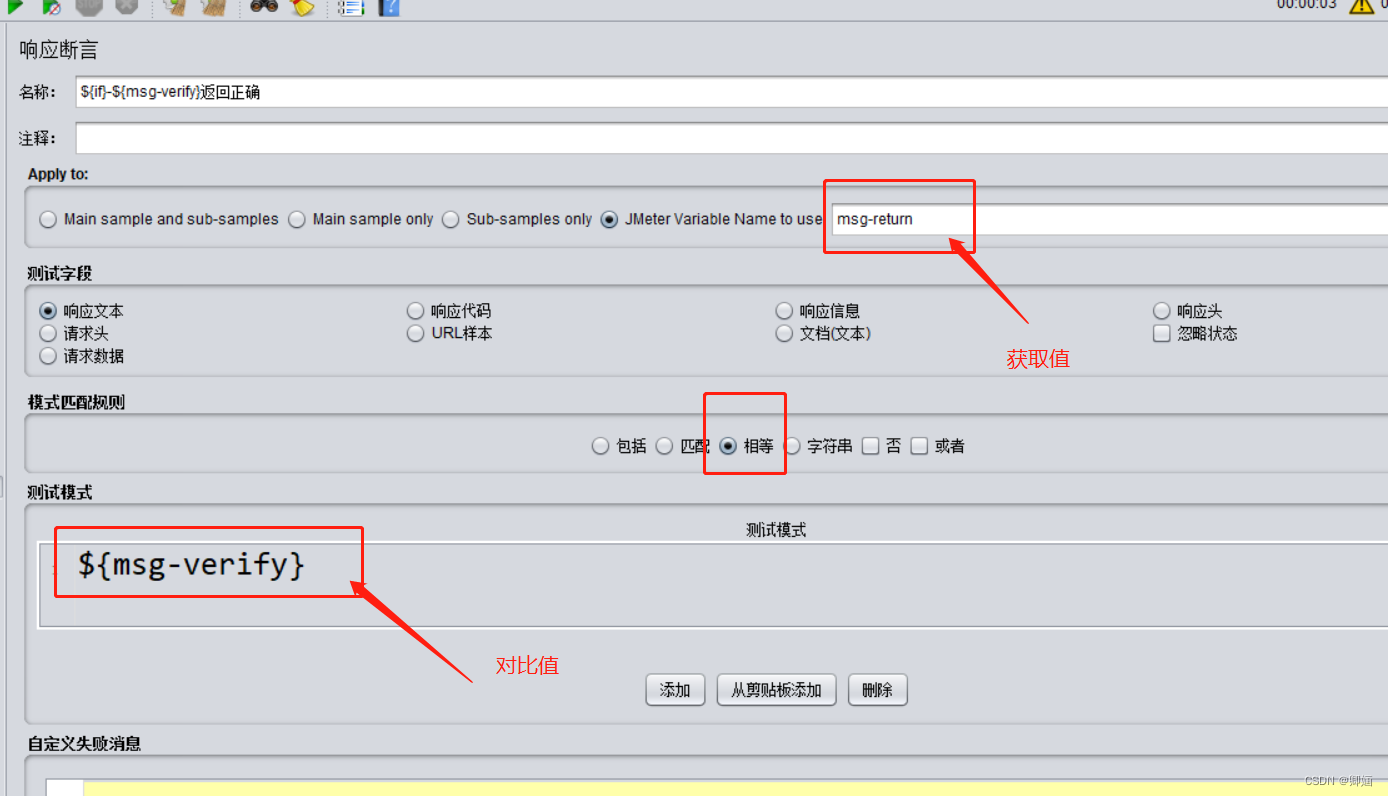
jmeter判断’响应断言‘两个变量对象是否相等
1、首先需要设置变量,json、正则、csv文件等变量 2、然后在响应断言中 ①JMeter Variable Name to use —— 输入一个变量,变量名即可 ② 模式匹配规则 ——相等 ③测试模式 ——输入引用的变量命${变量名} (注意这里是需要添加一个测试模式…...

【Linux基础命令使用】
文章目录 一. 操作系统和文件及文件路径介绍二. 基础指令介绍三. 结束语 一. 操作系统和文件及文件路径介绍 什么是操作系统?操作系统是一款进行软硬件资源管理的软件为什么要进行软硬件资源管理?对上提供良好的稳定的运行服务----工具Linux指令和图形化…...
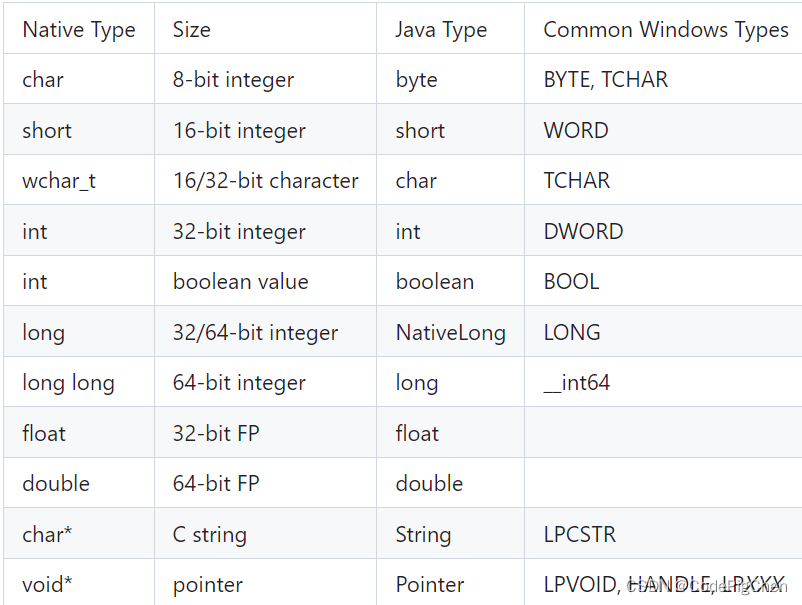
【JNA与C++基本使用示例】
JNA中java与C使用注意事项和代码示例 JNA关系映射表使用案列注意代码示例C代码java代码 JNA关系映射表 使用案列 注意 JNA只支持C方式的dll使用C的char* 作为返回值时,需要返回的变量为malloc分配的地址C的strlen函数只获得除/0以外的字符串长度 代码示例 C代码…...
HttpRunner接口自动化测试框架
简介 HttpRunner是一款面向 HTTP(S) 协议的通用测试框架,只需编写维护一份 YAML/JSON 脚本,即可实现自动化测试、性能测试、线上监控、持续集成等多种测试需求。 项目地址:GitHub - httprunner/httprunner: HttpRunner 是一个开源的 API/UI…...
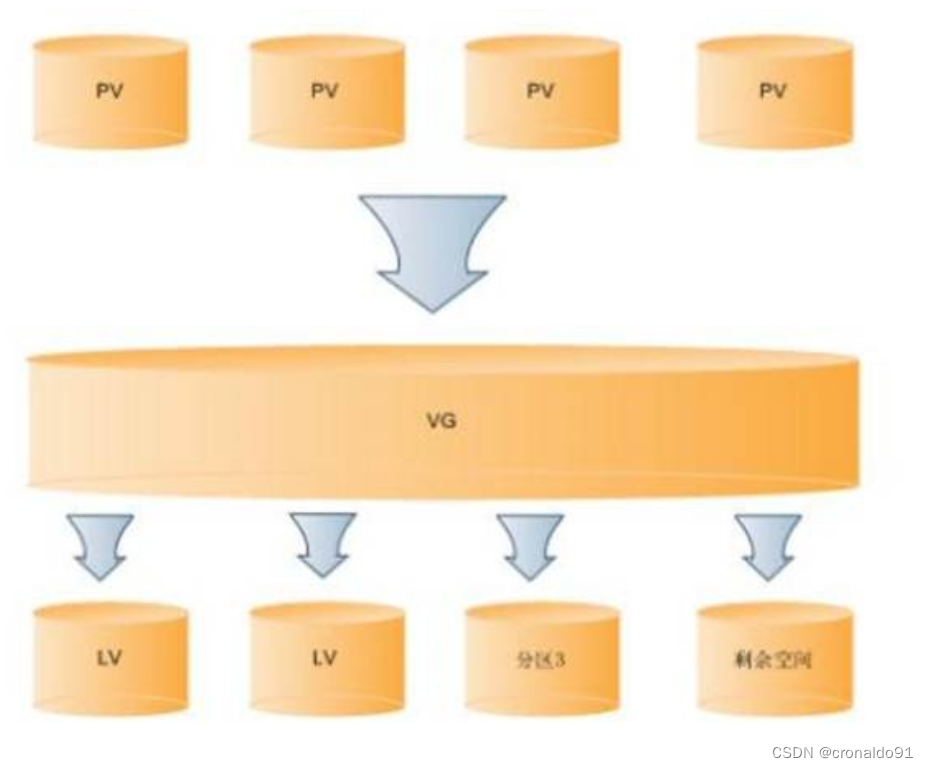
云计算:Vmware 安装 FreeNAS
目录 一、实验 1.Vmware 安装 FreeNAS 2.配置Web界面 二、问题 1.iSCSI如何限定名称 2.LUN和LVM的区别 一、实验 1.Vmware 安装 FreeNAS (1)环境准备 VMware Workstation 17 FreeNAS相关安装部署镜像: 官网地址: https://download…...
数据库交付运维高级工程师-腾讯云TDSQL
数据库交付运维高级工程师-腾讯云TDSQL上机指导,付费指导,暂定99...
)
目标检测YOLO实战应用案例100讲-光伏电站热斑检测(续)
目录 2.5 图像重建方法实验及其结果分析 2.5.1 数据集与超参数 2.5.2 结果分析...
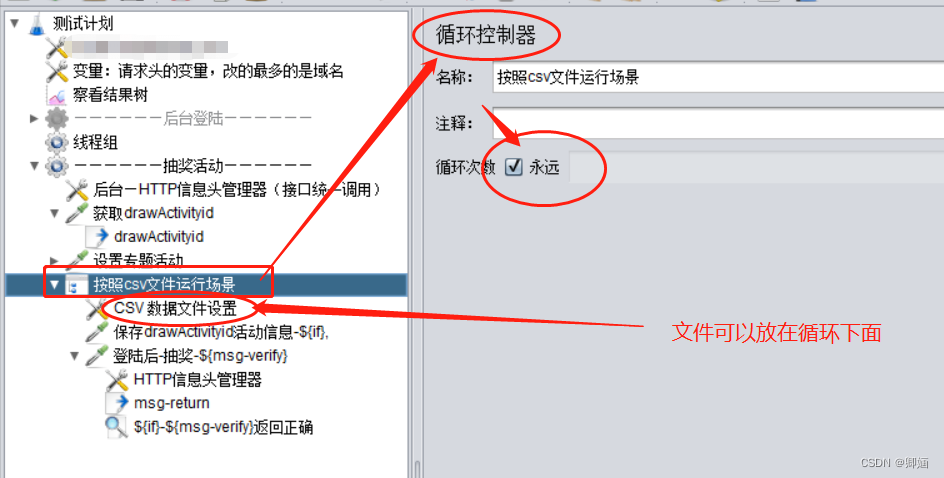
jmeter如何循环运行到csv文件最后一行后停止
1、首先在线程组中设置’循环次数‘–勾选永远 2、csv数据文件设置中设置: 遇到文件结束符再次循环?——改为:False 遇到文件结束符停止线程?——改为:True 3、再次运行就会根据文档的行数运行数据 (如果需要在循环控制器中&…...

电路中的屏蔽罩作用及设计
1.1 屏蔽罩作用 1.1.1 屏蔽电子信号,防止外界的干扰或内部向外的辐射: 一般见于通信类电路PCB,主要一个无线通信产品上有的敏感器件、模拟、数字电路、DCDC电源电路,都需屏蔽隔离,是为了不影响其它电路,也有防止其它电…...
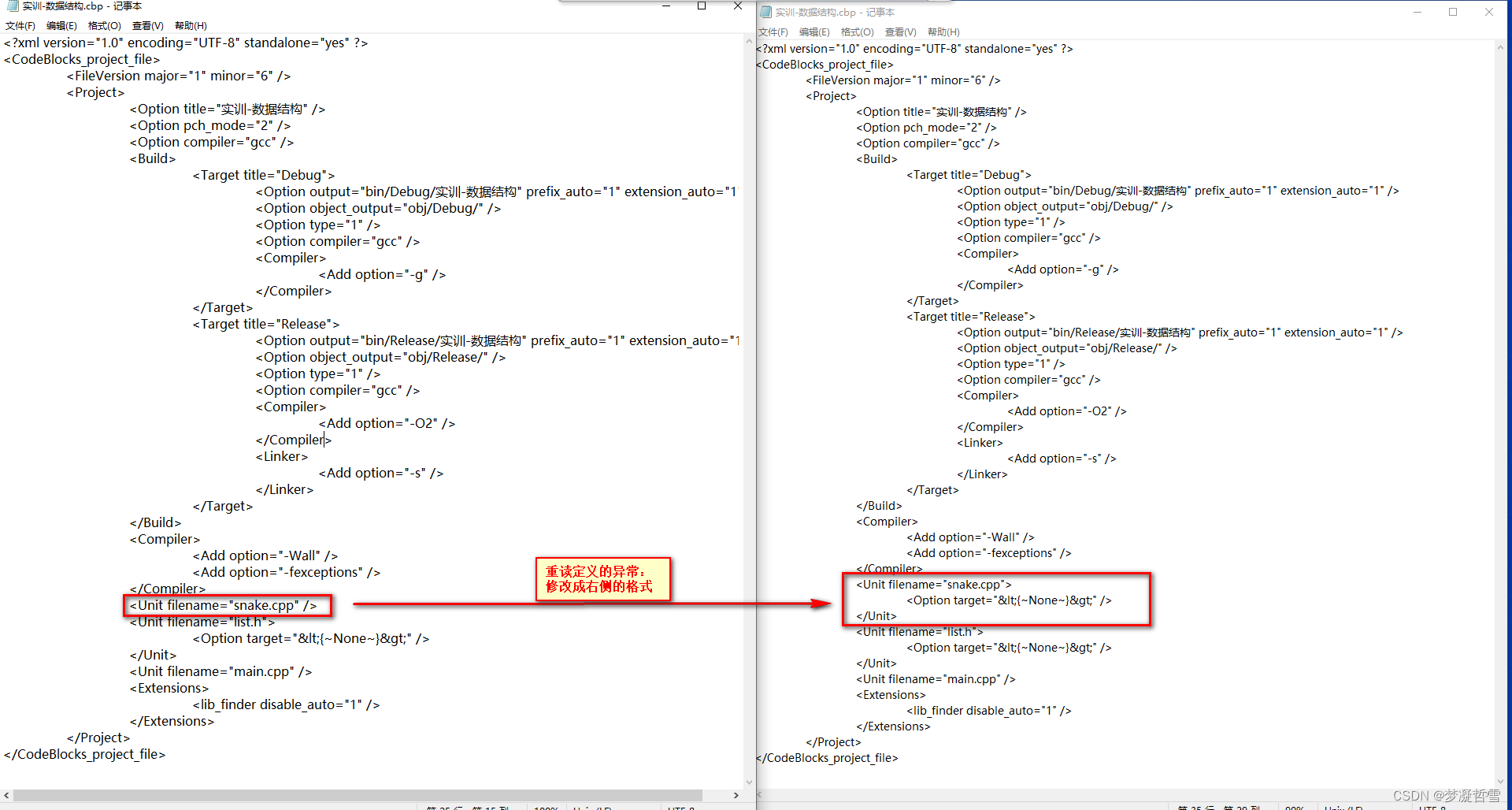
CodeBlocks定义异常:multiple definition of 和 first defined here
基于链表实现贪吃蛇案例时候,在CodeBlocks的CPP源文件定义函数和全局变量均报错 异常现象 在**自定义的cpp**文件定义全局变量、对象、函数等均出现重复定义和首次定义 multiple definition of Controller::showCopy() first defined here 异常解决方案 正确代码…...

RHEL7.5编译openssl1.1.1w源码包到rpm包
openssl1.1.1w下载地址 https://www.openssl.org/source/ 安装依赖包 yum -y install curl which make gcc perl perl-WWW-Curl rpm-build wget http://mirrors.aliyun.com/centos-vault/7.5.1804/os/x86_64/Packages/perl-WWW-Curl-4.15-13.el7.x86_64.rpm rpm -ivh pe…...

结构型设计模式(二)装饰器模式 适配器模式
装饰器模式 Decorator 1、什么是装饰器模式 装饰器模式允许通过将对象放入特殊的包装对象中来为原始对象添加新的行为。这种模式是一种结构型模式,因为它通过改变结构来改变被装饰对象的行为。它涉及到一组装饰器类,这些类用来包装具体组件。 2、为什…...

C#数据结构
C#数据结构 常见结构 1、集合 2、线性结构 3、树形结构 4、图形结构 Array/ArrayList/List 特点:内存上连续存储,节约空间,可以索引访问,读取快,增删慢 using System; namespace ArrayApplication {class MyAr…...
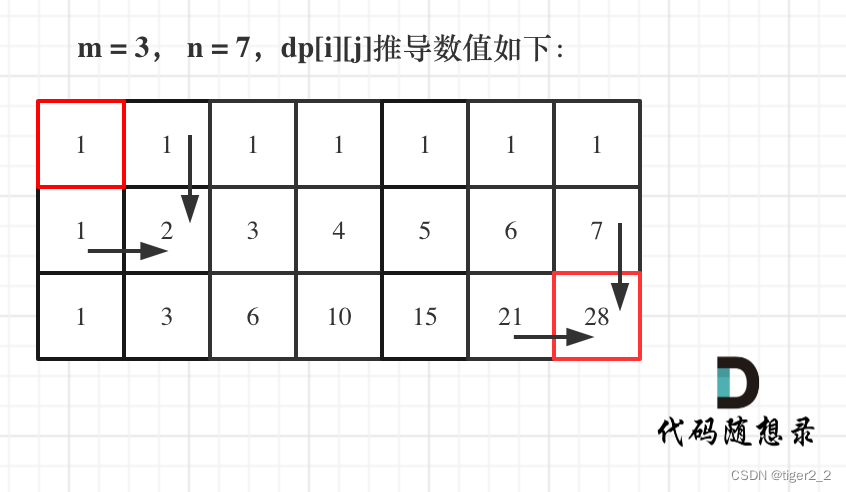
代码随想Day39 | 62.不同路径、63. 不同路径 II
62.不同路径 每次向右或者向下走两个选择,定义dp数组dp[i][j] 为到达索引ij的路径和,状态转移公式为 dp[i][j]dp[i-1][j]dp[i][j-1],初始状态的第一行和第一列为1,从左上到右下开始遍历即可。详细代码如下: class Sol…...
)
Autosar通信实战系列07-Com模块要点及其配置介绍(二)
本文框架 前言1. ComGeneral配置2. ComConfig配置2.1 ComGwMapping2.2 ComIPdus2.3 ComIPduGroups2.4 ComIPduSignals2.5 ComIPduSignalGroups2.6 ComTimeBasis前言 在本系列笔者将结合工作中对通信实战部分的应用经验进一步介绍常用,包括但不限于通信各模块的开发教程,代码…...
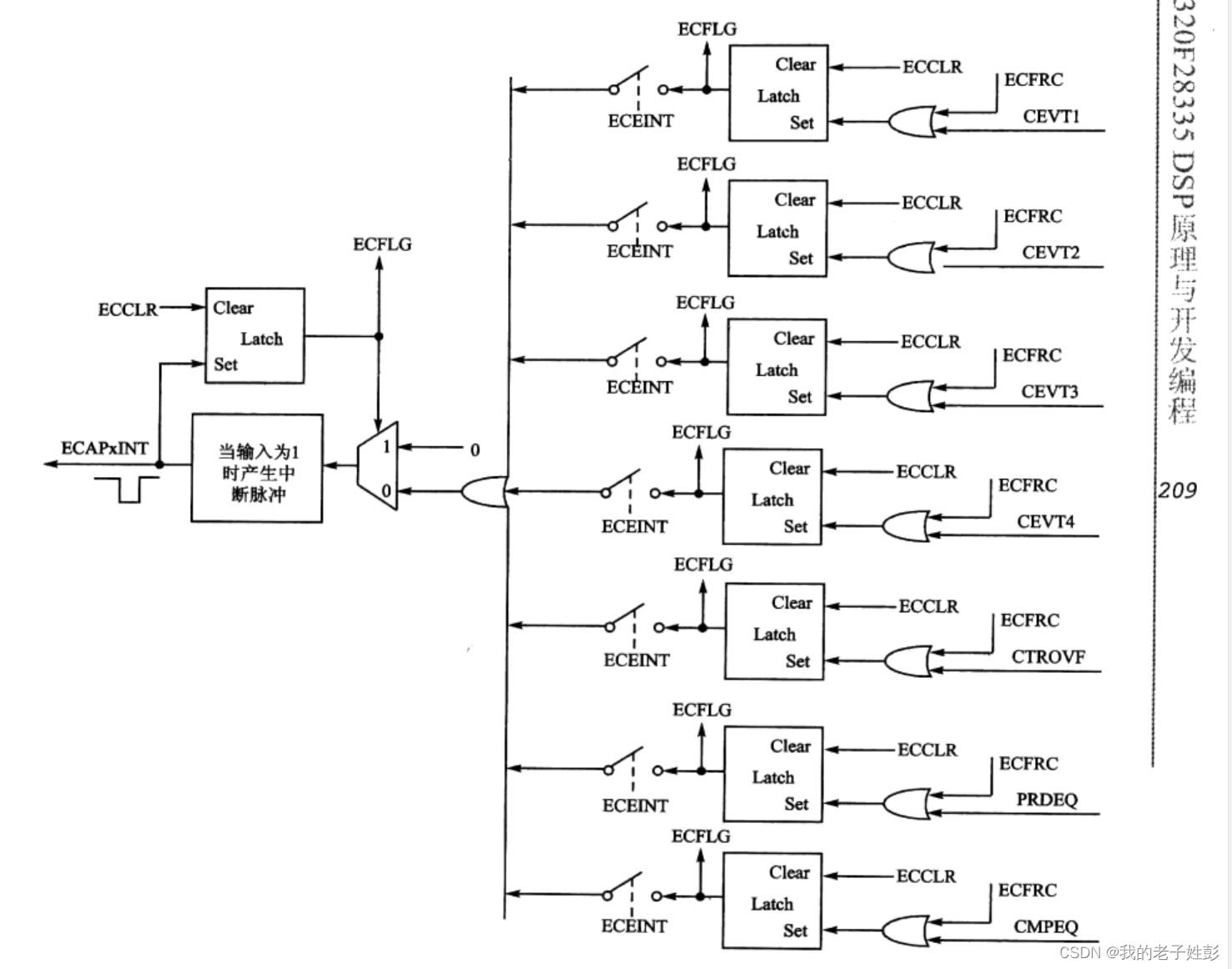
DSP捕获输入简单笔记
之前使用stm32的大概原理是: 输入引脚输入一个脉冲,捕获1开始极性捕获,捕获的是从启动捕获功能开始计数,捕获的是当前的计数值; 例如一个脉冲,捕获1捕获上升沿,捕获2捕获下降沿;而两…...

【Java基础】HashMap 原理
文章目录 1、HashMap 设置值的原理2、HashMap 获取值原理3、HashMap Hash优化4、HashMap 寻址优化5、HashMap 是如何解决Hash冲突的?5.1 get数据的时候,如果定位到指定位置的元素是一个链表,怎么办呢?5.2 红黑树 6、数组扩容6.1 数…...
vue3的大致使用
<template><div class"login_wrap"><div class"form_wrap"> <!-- 账号输入--> <el-form ref"formRef" :model"user" class"demo-dynamic" > <!--prop要跟属性名称对应-->…...

从玩具到工具:Dobot Magician桌面机械臂开箱与Blockly图形化编程初体验
从玩具到工具:Dobot Magician桌面机械臂开箱与Blockly图形化编程初体验 第一次见到Dobot Magician时,它安静地躺在包装箱里,像一件精致的工业艺术品。作为一款定位教育和个人创客市场的桌面级机械臂,它的价格只有工业机械臂的零头…...

WarcraftHelper:让你的魔兽争霸3在现代电脑上焕然新生的终极指南
WarcraftHelper:让你的魔兽争霸3在现代电脑上焕然新生的终极指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还记得那些年,…...

观察在虚拟机内使用Taotoken调用API的延迟与稳定性表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察在虚拟机内使用Taotoken调用API的延迟与稳定性表现 在开发与测试环境中,虚拟机(VM)是常见的…...

从AgentKit看AI应用工程化:架构演进与可靠性设计
1. 项目概述:一个已归档的AI应用快速启动器如果你在2023年到2024年初关注过AI应用开发,特别是基于大语言模型(LLM)的智能体(Agent)构建,那么你很可能听说过或者尝试过AgentKit。这个由BCG X&…...

5分钟掌握中兴光猫配置解密:解决网络维护难题的终极方案
5分钟掌握中兴光猫配置解密:解决网络维护难题的终极方案 【免费下载链接】ZET-Optical-Network-Terminal-Decoder 项目地址: https://gitcode.com/gh_mirrors/ze/ZET-Optical-Network-Terminal-Decoder 你是否曾经面对加密的中兴光猫配置文件束手无策&#…...

BilibiliVideoDownload故障排查指南:从登录失败到下载中断的全面解决方案
BilibiliVideoDownload故障排查指南:从登录失败到下载中断的全面解决方案 【免费下载链接】BilibiliVideoDownload Cross-platform download bilibili video desktop software, support windows, macOS, Linux 项目地址: https://gitcode.com/gh_mirrors/bi/Bilib…...

【claude code agent 实践7】后台任务机制深度解析: 从S02到S08的演进
后台任务机制深度解析 文章目录后台任务机制深度解析🔄 s02 vs s08 核心变化对比🔍 新增核心逻辑详解1. BackgroundManager类(后台任务管理器)2. agent_loop关键变化 - 每次LLM调用前排空队列📊 后台任务完整工作流程图…...

JPlag:源代码相似性检测与抄袭识别的核心技术解析
JPlag:源代码相似性检测与抄袭识别的核心技术解析 【免费下载链接】JPlag State-of-the-Art Source Code Plagiarism & Collusion Detection. Check for plagiarism in a set of programs. 项目地址: https://gitcode.com/gh_mirrors/jp/JPlag JPlag是一…...

VNote批量操作终极指南:如何一次处理百篇笔记提升效率 [特殊字符]
VNote批量操作终极指南:如何一次处理百篇笔记提升效率 🚀 【免费下载链接】vnote A pleasant note-taking platform in native C. 项目地址: https://gitcode.com/gh_mirrors/vn/vnote VNote批量操作是每个高效笔记用户必须掌握的技能!…...

AgentDock:构建可控AI智能体的开源框架与工程实践
1. 项目概述:构建可控的智能体应用框架如果你正在寻找一个既能利用大语言模型(LLM)的创造力,又能确保关键业务流程稳定可靠的开发框架,那么 AgentDock 的出现可能正合你意。我最近深度体验了这个开源项目,它…...