【Hadoop面试】HDFS读写流程
HDFS(Hadoop Distributed File System)是GFS的开源实现。
HDFS架构
HDFS是一个典型的主/备(Master/Slave)架构的分布式系统,由一个名字节点Namenode(Master) +多个数据节点Datanode(Slave)组成。其中Namenode提供元数据服务,Datanode提供数据流服务,用户通过HDFS客户端与Namenode和Datanode交互访问文件系统。
如图3-1所示HDFS把文件的数据划分为若干个块(Block),每个Block存放在一组Datanode上,Namenode负责维护文件到Block的命名空间映射以及每个Block到Datanode的数据块映射。
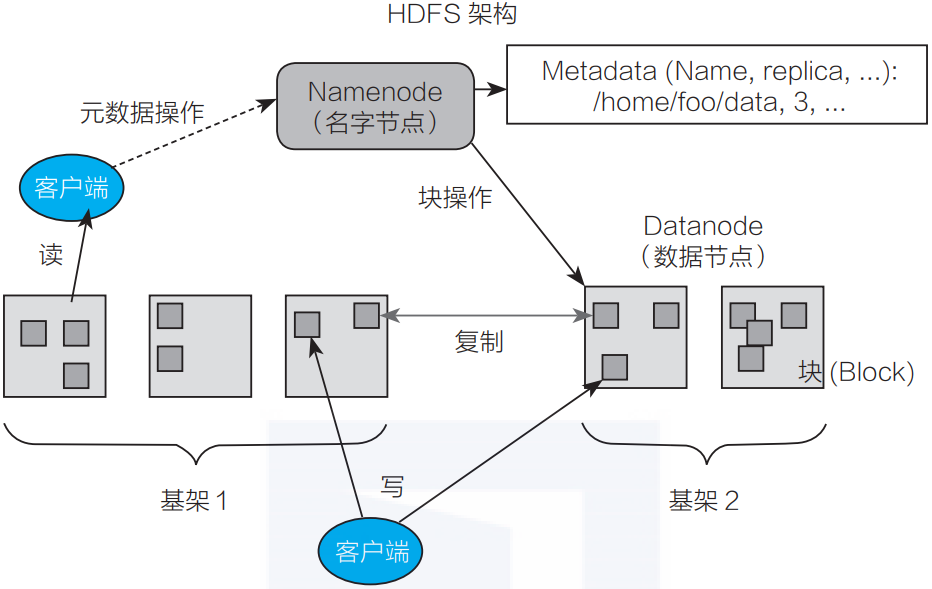
▲图3-1 HDFS架构
HDFS客户端对文件系统进行操作时,如创建、打开、重命名等,Namenode响应请求并对命名空间进行变更,再返回相关数据块映射的Datanode,客户端按照流协议完成数据的读写。
- HDFS基本概念
HDFS架构比较简单,但涉及概念较多,其中几个重要的概念如下:
1. 块(Block)
Block是HDFS文件系统处理的最小单位,一个文件可以按照Block大小划分为多个Block,不同于Linux文件系统中的数据块,HDFS文件通常是超大文件,因此Block大小一般设置得比较大,默认为128MB。
2. 复制(Replica)
HDFS通过冗余存储来保证数据的完整性,即一个Block会存放在N个Datanode中,HDFS客户端向Namenode申请新Block时,Namenode会根据Block分配策略为该Block分配相应的Datanode replica,这些Datanode组成一个流水线(pipeline),数据依次串行写入,直至Block写入完成。
3. 名字节点(Namenode)
Namenode是HDFS文件系统的管理节点,主要负责维护文件系统的命名空间(Namespace)或文件目录树(Tree)和文件数据块映射(BlockMap),以及对外提供文件服务。
HDFS文件系统遵循POXIS协议标准,与Linux文件系统类似,采用基于Tree的数据结构,以INode作为节点,实现一个目录下多个子目录和文件。INode是一个抽象类,表示File/Directory的层次关系,对于一个文件来说,INodeFile除了包含基本的文件属性信息,也包含对应的Block信息。
数据块映射信息则由BlockMap负责管理,在Datanode的心跳上报中,将向Namenode汇报负责存储的Block列表情况,BlockMap负责维护BlockID到Datanode的映射,以方便文件检索时快速找到Block对应的HDFS位置。
HDFS每一步操作都以FSEditLog的信息记录下来,一旦Namenode发生宕机重启,可以从每一个FSEditLog还原出HDFS操作以恢复整个文件目录树,如果HDFS集群发生过很多变更操作,整个过程将相当漫长。
因此HDFS会定期将Namenode的元数据以FSImage的形式写入文件中,这一操作相当于为HDFS元数据打了一个快照,在恢复时,仅恢复FSImage之后的FSEditLog即可。
由于Namenode在内存中需要存放大量的信息,且恢复过程中集群不可用,HDFS提供HA(主/备Namenode实现故障迁移Failover)以及Federation(多组Namenode提供元数据服务,以挂载表的形式对外提供统一的命名空间)特性以提高稳定性和减少元数据压力。
4. Datanode
Datanode是HDFS文件系统的数据节点,提供基于Block的本地文件读写服务。定期向Namenode发送心跳。Block在本地文件系统中由数据文件及元数据文件组成,前者为数据本身,后者则记录Block长度和校验和(checksum)等信息。扫描或读取数据文件时,HDFS即使运行在廉价的硬件上,也能通过多副本的能力保证数据一致性。
5. FileSystem
HDFS客户端实现了标准的Hadoop FileSystem接口,向上层应用程序提供了各种各样的文件操作接口,在内部使用了DFSClient等对象并封装了较为复杂的交互逻辑,这些逻辑对客户端都是透明的。
HDFS读写流程
HDFS写流程

写详细步骤:
- 客户端向NameNode发出写文件请求。
- 检查是否已存在文件、检查权限。若通过检查,直接先将操作写入EditLog,并返回输出流对象。
(注:WAL,write ahead log,先写Log,再写内存,因为EditLog记录的是最新的HDFS客户端执行所有的写操作。如果后续真实写操作失败了,由于在真实写操作之前,操作就被写入EditLog中了,故EditLog中仍会有记录,我们不用担心后续client读不到相应的数据块,因为在第5步中DataNode收到块后会有一返回确认信息,若没写成功,发送端没收到确认信息,会一直重试,直到成功) - client端按128MB的块切分文件。
- client将NameNode返回的分配的可写的DataNode列表和Data数据一同发送给最近的第一个DataNode节点,此后client端和NameNode分配的多个DataNode构成pipeline管道,client端向输出流对象中写数据。client每向第一个DataNode写入一个packet,这个packet便会直接在pipeline里传给第二个、第三个…DataNode。
(注:并不是写好一个块或一整个文件后才向后分发) - 每个DataNode写完一个块后,会返回确认信息。
(注:并不是每写完一个packet后就返回确认信息,个人觉得因为packet中的每个chunk都携带校验信息,没必要每写一个就汇报一下,这样效率太慢。正确的做法是写完一个block块后,对校验信息进行汇总分析,就能得出是否有块写错的情况发生) - 写完数据,关闭输输出流。
- 发送完成信号给NameNode。
(注:发送完成信号的时机取决于集群是强一致性还是最终一致性,强一致性则需要所有DataNode写完后才向NameNode汇报。最终一致性则其中任意一个DataNode写完后就能单独向NameNode汇报,HDFS一般情况下都是强调强一致性)
HDFS客户端写流程详解
图3-2所示为客户端完成HDFS文件写入的主流程。

▲图3-2 客户端完成HDFS写入的主流程
1)创建文件并获得租约
HDFS客户端通过调用DistributedFileSystem# create来实现远程调用Namenode提供的创建文件操作,Namenode在指定的路径下创建一个空的文件并为该客户端创建一个租约(在续约期内,将只能由这一个客户端写数据至该文件),随后将这个操作记录至EditLog(编辑日志)。Namenode返回相应的信息后,客户端将使用这些信息,创建一个标准的Hadoop FSDataOutputStream输出流对象。
2)写入数据
HDFS客户端开始向HdfsData-OutputStream写入数据,由于当前没有可写的Block,DFSOutputStream根据副本数向Namenode申请若干Datanode组成一条流水线来完成数据的写入,如图3-3所示。
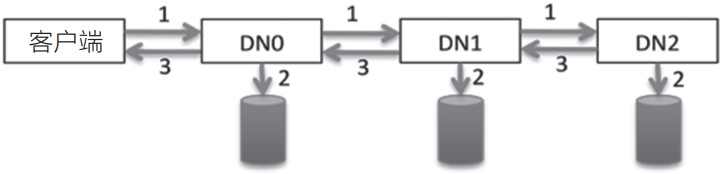
▲图3-3 流水线数据写入示意图
3)串行写入数据,直到写完Block
客户端的数据以字节(byte)流的形式写入chunk(以chunk为单位计算checksum(校验和))。若干个chunk组成packet,数据以packet的形式从客户端发送到第一个Datanode,再由第一个Datanode发送数据到第二个Datanode并完成本地写入,以此类推,直到最后一个Datanode写入本地成功,可以从缓存中移除数据包(packet),如图3-4所示。

▲图3-4 串行写入数据示意图
4)重复步骤2和步骤3,然后写数据包和回复数据包,直到数据全部写完。
5)关闭文件并释放租约
客户端执行关闭文件后,HDFS客户端将会在缓存中的数据被发送完成后远程调用Namenode执行文件来关闭操作。
Datanode在定期的心跳上报中,以增量的信息汇报最新完成写入的Block,Namenode则会更新相应的数据块映射以及在新增Block或关闭文件时根据Block映射副本信息判断数据是否可视为完全持久化(满足最小备份因子)。
HDFS读流程
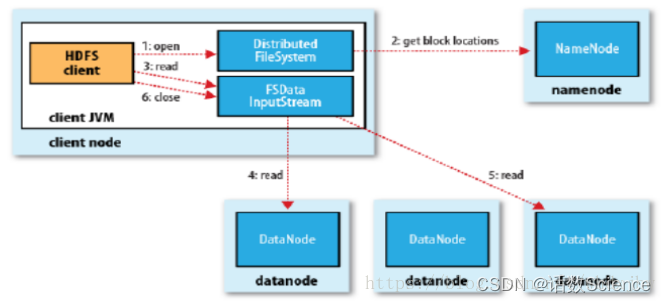
读详细步骤:
- client访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
- 就近挑选一台datanode服务器,请求建立输入流 。
- DataNode向输入流中中写数据,以packet为单位来校验。
- 关闭输入流
HDFS客户端读流程详解
相对于HDFS文件写入流程,HDFS读流程相对简单,如图3-5所示。
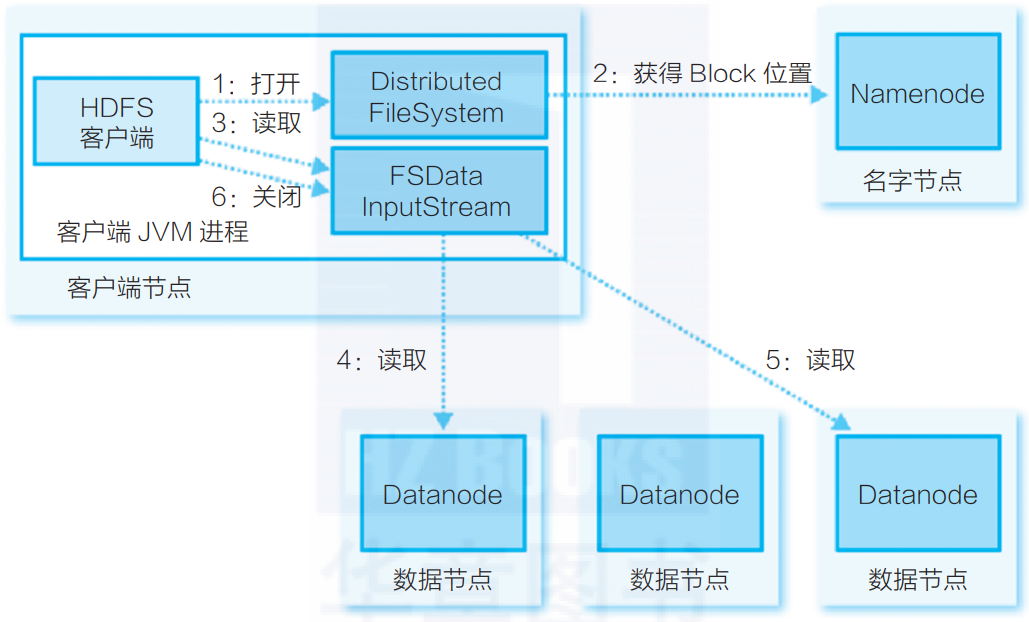
▲图3-5 HDFS读流程
1)HDFS客户端远程调用Namenode,查询元数据信息,获得这个文件的数据块位置列表,返回封装DFSIntputStream的HdfsDataInputStream输入流对象。
2)客户端选择一台可用Datanode服务器,请求建立输入流。
3)Datanode向输入流中写原始数据和以packet为单位的checksum。
4)客户端接收数据。如遇到异常,跳转至步骤2,直到数据全部读出,而后客户端关闭输入流。当客户端读取时,可能遇到Datanode或Block异常,导致当前读取失败。正由于HDFS的多副本保证,DFSIntputStream将会切换至下一个Datanode进行读取。与HDFS写入类似,通过checksum来保证读取数据的完整性和准确性。
相关文章:
【Hadoop面试】HDFS读写流程
HDFS(Hadoop Distributed File System)是GFS的开源实现。 HDFS架构 HDFS是一个典型的主/备(Master/Slave)架构的分布式系统,由一个名字节点Namenode(Master) 多个数据节点Datanode(Slave)组成。其中Namenode提供元数…...
B01、JVM与Java体系结构-01
字节码与多语言混合编程 字节码概述: 我们平时说的java字节码,指的是用java语言编译成的字节码。准确的说任何能在jvm平台上执行的字节码格式都是一样的。所以应该统称为:jvm字节码。不同的编译器,可以编译出相同的字节码文件&…...

Python:Jupyter
Jupyter是一个开源的交互式计算环境,由Fernando Perez和Brian Granger于2014年创立。它提供了一种方便的方式来展示、共享和探索数据,并且可以与多种编程语言和数据格式进行交互。Jupyter的历史可以追溯到2001年,当时Fernando Perez正在使用P…...

macos苹果电脑开启tftp server上传fortigate60e固件成功
cat /System/Library/LaunchDaemons/tftp.plist<?xml version"1.0" encoding"UTF-8"?> <!DOCTYPE plist PUBLIC "-//Apple Computer//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd"> <plist…...
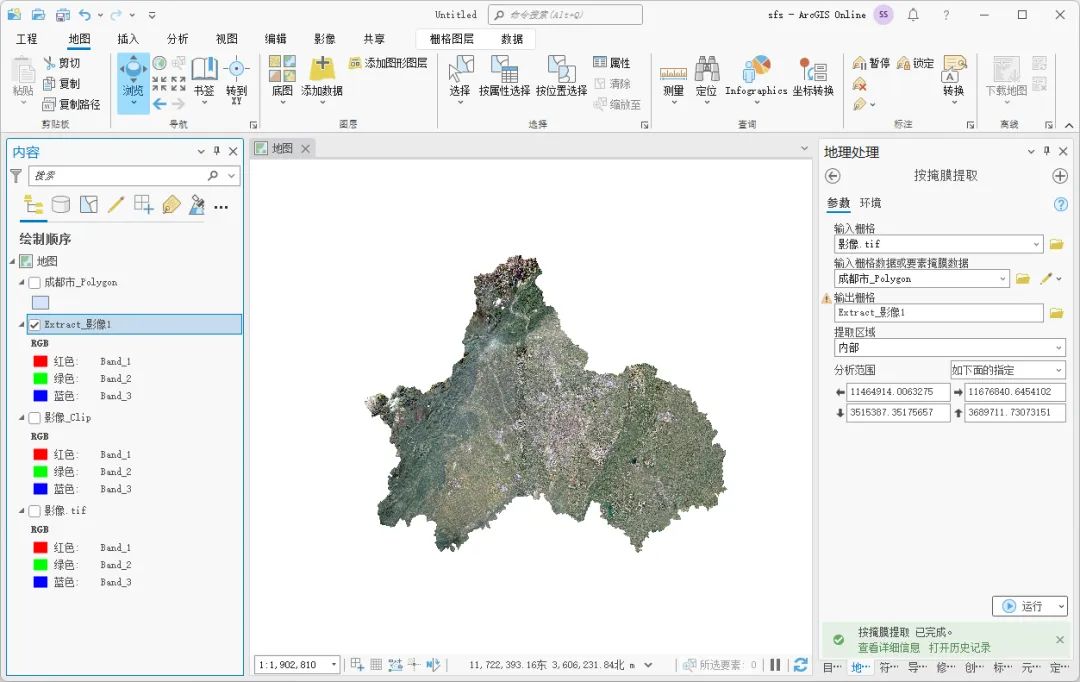
如何使用ArcGIS Pro裁剪影像
对影像进行裁剪是一项比较常规的操作,因为到手的影像可能是多种范围,需要根据自己需求进行裁剪,这里为大家介绍一下ArcGIS Pro中裁剪的方法,希望能对你有所帮助。 数据来源 本教程所使用的数据是从水经微图中下载的影像和行政区…...
Tekton 构建容器镜像
Tekton 构建容器镜像 介绍如何使用 Tektonhub 官方 kaniko task 构建docker镜像,并推送到远程dockerhub镜像仓库。 kaniko task yaml文件下载地址:https://hub.tekton.dev/tekton/task/kaniko 查看kaniko task yaml内容: 点击Install&…...

netty-daxin-4(httpwebsocket)
文章目录 学习链接http服务端NettyHttpServerHelloWorldServerHandler 客户端ApiPost websocket初步了解为什么需要 WebSocket简介 浏览器的WebSocket客户端客户端的简单示例客户端的 APIWebSocket 构造函数webSocket.readyStatewebSocket.onopenwebSocket.onclosewebSocket.ο…...

文章解读与仿真程序复现思路——电力系统自动化EI\CSCD\北大核心《市场环境下考虑全周期经济效益的工业园区共享储能优化配置》
这个标题涉及到工业园区中共享储能系统的优化配置,考虑了市场环境和全周期经济效益。以下是对标题中各个要素的解读: 市场环境下: 指的是工业园区所处的商业和经济背景。这可能包括市场竞争状况、电力市场价格波动、政策法规等因素。在这一环…...
WPF——命令commond的实现方法
命令commond的实现方法 属性通知的方式 鼠标监听绑定事件 行为:可以传递界面控件的参数 第一种: 第二种: 附加属性 propa:附加属性快捷方式...
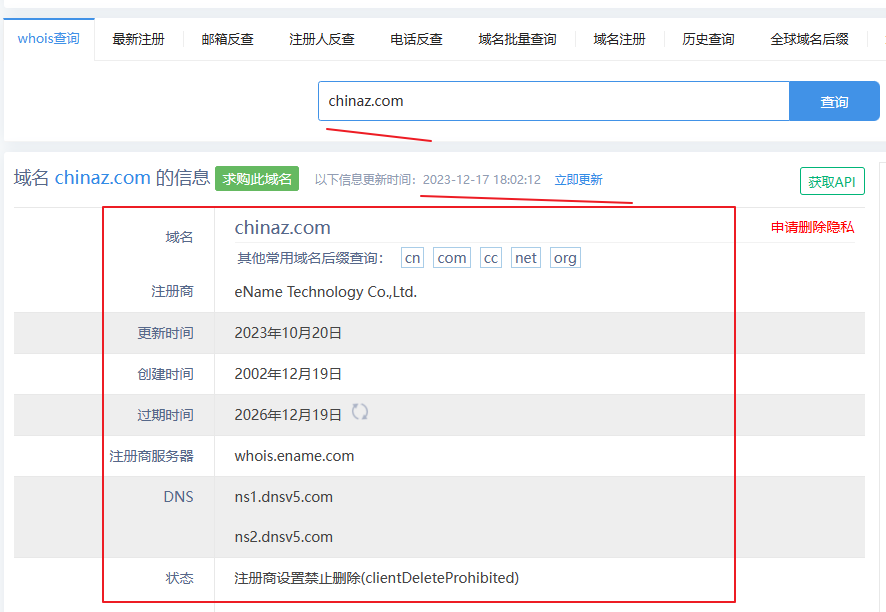
信息收集 - 域名
1、Whois查询: Whois 是一个用来查询域名是否已经被注册以及相关详细信息的数据库(如:域名所有人、域名注册商、域名注册日期和过期日期等)。通过访问 Whois 服务器,你可以查询域名的归属者联系方式和注册时间。 你可以在 域名Whois查询 - 站长之家 上进行在线查询。 2、…...
基于YOLOv8深度学习的路面标志线检测与识别系统【python源码+Pyqt5界面+数据集+训练代码】目标检测、深度学习实战
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...

leetCode算法—1.两数之和
难度:* 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。 你…...

oracle 设置访问白名单
有相关安全策略会要求部分 ip 禁止访问oracle数据库,那么如何实现对IP的白名单设置呢?又如何细分到对用户的限制访问呢?本文将介绍方法给大伙。 1、禁止IP访问数据库(修改sqlnet.ora方式实现) vi $ORACLE_HOME/network…...

Flink系列之:窗口关联
Flink系列之:窗口关联 一、窗口关联二、INNER/LEFT/RIGHT/FULL OUTER三、SEMI四、ANTI五、限制 一、窗口关联 适用于流、批窗口关联就是增加时间维度到关联条件中。在此过程中,窗口关联将两个流中在同一窗口且符合 join 条件的元素 join 起来。窗口关联…...

Eolink 两项产品入选 2023 年广东省名优高新技术产品名录!
近日,2023 年广东省名优高新技术产品正式名单已经发布,Eolink 旗下两项产品荣幸入选! “广东省名优高新技术产品”是广东省对高新技术产品领域的升级和优化的重要措施。名优产品的评选不仅强调了技术的先进性,更对产品的质量、市…...

054:vue工具 --- BASE64加密解密互相转换
第054个 查看专栏目录: VUE ------ element UI 专栏目标 在vue和element UI联合技术栈的操控下,本专栏提供行之有效的源代码示例和信息点介绍,做到灵活运用。 (1)提供vue2的一些基本操作:安装、引用,模板使…...
自动驾驶学习笔记(二十)——Planning算法
#Apollo开发者# 学习课程的传送门如下,当您也准备学习自动驾驶时,可以和我一同前往: 《自动驾驶新人之旅》免费课程—> 传送门 《Apollo 社区开发者圆桌会》免费报名—>传送门 文章目录 前言 参考线平滑 双层状态机 EM Planner …...

adb的使用
Adb windows 环境搭建 (1)将adb包安装或者解压到一个路径,并拿到adb.exe所在的路径值,例如,D:\Tools\adb (2)将路径值放进windows环境变量 我的电脑(此电脑图标)右键–》 选择“属…...

会旋转的树,你见过吗?
🎈个人主页:🎈 :✨✨✨初阶牛✨✨✨ 🐻强烈推荐优质专栏: 🍔🍟🌯C的世界(持续更新中) 🐻推荐专栏1: 🍔🍟🌯C语言初阶 🐻推荐专栏2: 🍔…...

Azure Machine Learning - 提示工程简介
OpenAI的GPT-3、GPT-3.5和GPT-4模型基于用户输入的文本提示工作。有效的提示构造是使用这些模型的关键技能,涉及到配置模型权重以执行特定任务。这不仅是技术操作,更像是一种艺术,需要经验和直觉。本文旨在介绍适用于所有GPT模型的提示概念和…...

MobaXterm实战:一站式打通串口调试与远程SSH管理
1. 为什么选择MobaXterm作为全能终端工具 第一次接触嵌入式开发时,我被各种终端工具搞得晕头转向——串口调试要用SecureCRT,SSH连接得开PuTTY,文件传输还得额外装WinSCP。直到同事推荐了MobaXterm,这个法国开发者打造的免费工具彻…...

CodeWarrior IDE文件操作与ARM开发实践
1. CodeWarrior IDE文件操作深度解析在嵌入式开发领域,文件操作的高效管理直接影响着开发效率和代码安全性。作为ARM开发的经典工具链组件,CodeWarrior IDE提供了一套完整的文件管理机制,特别适合处理ARM架构的嵌入式项目。我使用这套工具开发…...
详解:如何让你的代码跑在不同的飞控板上(以STM32为例))
ArduPilot硬件抽象层(HAL)详解:如何让你的代码跑在不同的飞控板上(以STM32为例)
ArduPilot硬件抽象层深度解析:从STM32到多平台移植实战指南 引言:为什么HAL是飞控开发的核心枢纽 在无人机飞控开发领域,硬件平台的多样性一直是开发者面临的首要挑战。不同厂商的MCU架构、外设接口和操作系统差异,往往导致代码…...

3步彻底清理Windows右键菜单:ContextMenuManager高效管理指南
3步彻底清理Windows右键菜单:ContextMenuManager高效管理指南 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是否曾因Windows右键菜单中堆积如山的…...

深入解析Android网络通信框架:OkHttp与Retrofit原理与实践
第一章:引言 移动互联网时代,网络通信是Android应用的核心能力之一。OkHttp与Retrofit作为Android生态中最主流的网络通信框架,已成为开发者必须掌握的技术栈。本章将简要介绍二者在项目中的定位及其技术演进历程。 第二章:OkHttp核心原理剖析 2.1 OkHttp架构设计 OkHtt…...

为OpenClaw配置Taotoken作为其AI模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw配置Taotoken作为其AI模型供应商 基础教程类,指导使用OpenClaw这类Agent工具的开发者,如何将其后…...

【uniapp】告别静态focus:动态控制input聚焦的实战与思考
1. 为什么静态focus在uniapp中会失效 很多刚开始接触uniapp的开发者都会遇到一个奇怪的现象:明明在input组件上设置了focus"true",但页面加载后输入框却没有自动聚焦。这个问题困扰了不少人,我也是在踩过这个坑之后才明白其中的原理…...

GD32C10x 标准库 EXTI 驱动源码深度解析
前言 在 GD32C10x 单片机开发中,外部中断 EXTI是实现外设异步响应、按键检测、电平触发等功能的核心外设,几乎所有嵌入式项目都会用到 EXTI。 兆易创新提供的 GD32C10x 标准库中,gd32c10x_exti.c是 EXTI 外设的底层驱动文件,封装了 EXTI 初始化、中断使能、标志位操作、软…...

基于大语言模型的学术论文阅读辅助分析系统的研究与应用
基于大语言模型的学术论文阅读辅助分析系统的研究与应用 摘要 随着科研论文数量的指数级增长,科研工作者面临着前所未有的信息过载挑战。传统学术论文阅读方式依赖线性文本呈现,难以快速定位关键信息,跨文献知识整合效率低下。大语言模型的发展为解决这一问题提供了新的技…...

51单片机驱动SG90舵机:从PWM原理到按键控制实战
1. SG90舵机与51单片机的基础认知 第一次接触SG90舵机时,我盯着那三根彩色导线发愣——这玩意儿怎么就能精准控制角度呢?后来发现它其实是微型伺服系统的典型代表,红色接5V电源,褐色接地线,黄色信号线接任意IO口&#…...