Spark编程实验二:RDD编程初级实践
目录
一、目的与要求
二、实验内容
三、实验步骤
1、pyspark交互式编程
2、编写独立应用程序实现数据去重
3、编写独立应用程序实现求平均值问题
4、三个综合实例
四、结果分析与实验体会
一、目的与要求
1、熟悉Spark的RDD基本操作及键值对操作;
2、熟悉使用RDD编程解决实际具体问题的方法。
二、实验内容
1、pyspark交互式编程
给定数据集 data1.txt,包含了某大学计算机系的成绩,数据格式如下所示:
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,80
……
请根据给定的实验数据,在pyspark中通过编程来计算以下内容:
(1)该系总共有多少学生;
(2)该系共开设了多少门课程;
(3)Tom同学的总成绩平均分是多少;
(4)求每名同学的选修的课程门数;
(5)该系DataBase课程共有多少人选修;
(6)各门课程的平均分是多少;
(7)使用累加器计算共有多少人选了DataBase这门课。
2、编写独立应用程序实现数据去重
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。下面是输入文件和输出文件的一个样例,供参考。
输入文件A的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件B的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件A和B合并得到的输出文件C的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
3、编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。下面是输入文件和输出文件的一个样例,供参考。
Algorithm成绩:
小明 92
小红 87
小新 82
小丽 90
Database成绩:
小明 95
小红 81
小新 89
小丽 85
Python成绩:
小明 82
小红 83
小新 94
小丽 91
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
4、三个综合实例
题目详情可查看实验步骤。
三、实验步骤
1、pyspark交互式编程
先在终端启动pyspark:
[root@bigdata zhc]# pyspark(1)该系总共有多少学生;
>>> lines = sc.textFile("file:///home/zhc/datasets/data1.txt")
>>> res = lines.map(lambda x:x.split(",")).map(lambda x: x[0]) # 获取每行数据的第1列
>>> distinct_res = res.distinct() # 去重操作
>>> distinct_res.count() # 取元素总个数
执行结果:

(2)该系共开设了多少门课程;
>>> lines = sc.textFile("file:///home/zhc/datasets/data1.txt")
>>> res = lines.map(lambda x:x.split(",")).map(lambda x:x[1]) # 获取每行数据的第2列
>>> distinct_res = res.distinct() # 去重操作
>>> distinct_res.count() # 取元素总个数
执行结果:

(3)Tom同学的总成绩平均分是多少;
>>> lines = sc.textFile("file:///home/zhc/datasets/data1.txt")
>>> res = lines.map(lambda x:x.split(",")).filter(lambda x:x[0]=="Tom") # 筛选Tom同学的成绩信息
>>> res.foreach(print)
>>> score = res.map(lambda x:int(x[2])) # 提取Tom同学的每门成绩,并转换为int类型
>>> num = res.count() # Tom同学选课门数
>>> sum_score = score.reduce(lambda x,y:x+y) # Tom同学的总成绩
>>> avg = sum_score/num # 总成绩/门数=平均分
>>> print(avg)执行结果:

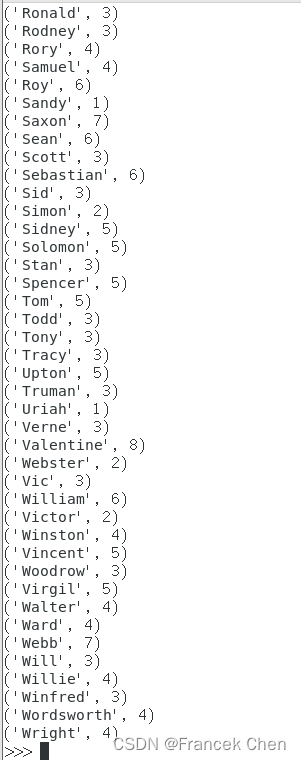
(4)求每名同学的选修的课程门数;
>>> lines = sc.textFile("file:///home/zhc/datasets/data1.txt")
>>> res = lines.map(lambda x:x.split(",")).map(lambda x:(x[0],1)) # 学生每门课程都对应(学生姓名,1),学生有n门课程则有n个(学生姓名,1)
>>> each_res = res.reduceByKey(lambda x,y: x+y) # 按学生姓名获取每个学生的选课总数
>>> each_res.foreach(print)执行结果:
 ......
......
(5)该系DataBase课程共有多少人选修;
>>> lines = sc.textFile("file:///home/zhc/datasets/data1.txt")
>>> res = lines.map(lambda x:x.split(",")).filter(lambda x:x[1]=="DataBase")
>>> res.count()执行结果:

(6)各门课程的平均分是多少;
>>> lines = sc.textFile("file:///home/zhc/datasets/data1.txt")
>>> res = lines.map(lambda x:x.split(",")).map(lambda x:(x[1],(int(x[2]),1))) # 为每门课程的分数后面新增一列1,表示1个学生选择了该课程。格式如('ComputerNetwork', (44, 1))
>>> temp = res.reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1])) # 按课程名聚合课程总分和选课人数。格式如('ComputerNetwork', (7370, 142))
>>> avg = temp.map(lambda x:(x[0], round(x[1][0]/x[1][1],2))) # 课程总分/选课人数 = 平均分,并利用round(x,2)保留两位小数
>>> avg.foreach(print)执行结果:

(7)使用累加器计算共有多少人选了DataBase这门课。
>>> lines = sc.textFile("file:///home/zhc/datasets/data1.txt")
>>> res = lines.map(lambda x:x.split(",")).filter(lambda x:x[1]=="DataBase") # 筛选出选了DataBase课程的数据
>>> accum = sc.accumulator(0) # 定义一个从0开始的累加器accum
>>> res.foreach(lambda x:accum.add(1)) # 遍历res,每扫描一条数据,累加器加1
>>> accum.value # 输出累加器的最终值执行结果:

2、编写独立应用程序实现数据去重
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。下面是输入文件和输出文件的一个样例,供参考。
输入文件A的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件B的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件A和B合并得到的输出文件C的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
在“/home/zhc/mycode/remdup”目录下新建代码文件remdup.py:
# /home/zhc/mycode/remdup/remdup.py
from pyspark import SparkContext
#初始化SparkContext
sc = SparkContext('local','remdup')
#加载两个文件A和B
lines1 = sc.textFile("file:///home/zhc/mycode/remdup/A.txt")
lines2 = sc.textFile("file:///home/zhc/mycode/remdup/B.txt")
#合并两个文件的内容
lines = lines1.union(lines2)
#去重操作
distinct_lines = lines.distinct()
#排序操作
res = distinct_lines.sortBy(lambda x:x)
#将结果写入result文件中,repartition(1)的作用是让结果合并到一个文件中,不加的话会结果写入到两个文件
res.repartition(1).saveAsTextFile("file:///home/zhc/mycode/remdup/result")在目录“/home/zhc/mycode/remdup”下执行下面命令执行程序(注意执行程序时请先退出pyspark shell,否则会出现“地址已在使用”的警告)。
[root@bigdata remdup]# python3 remdup.py在目录“/home/zhc/mycode/remdup/result”下即可得到结果文件part-00000。
[root@bigdata remdup]# cd result
[root@bigdata result]# cat part-00000 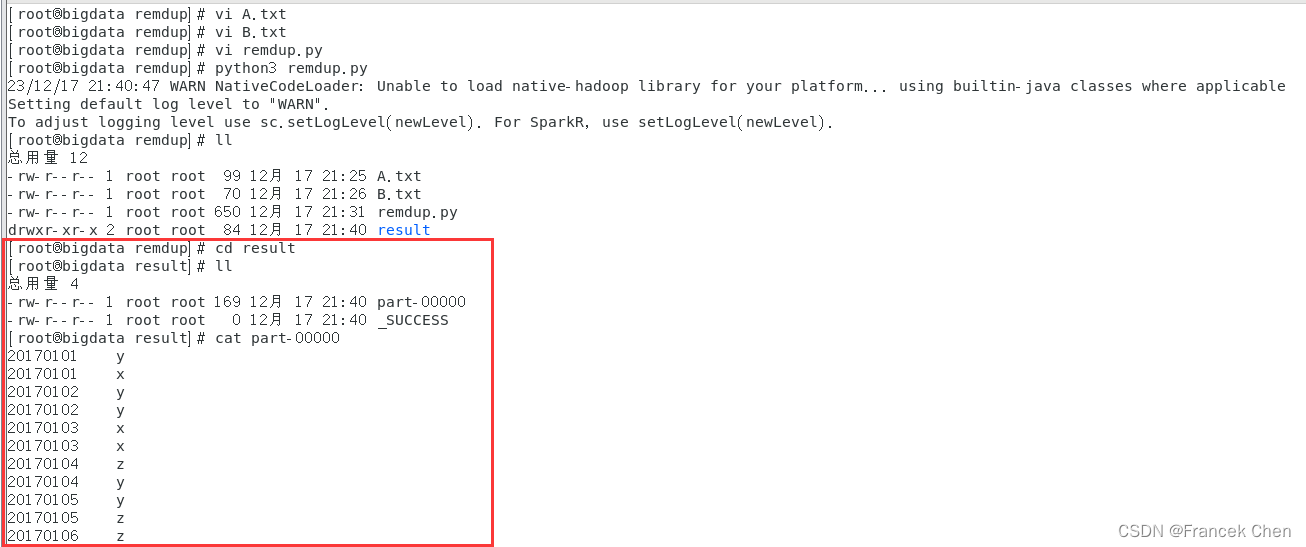
3、编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。下面是输入文件和输出文件的一个样例,供参考。
Algorithm成绩:
小明 92
小红 87
小新 82
小丽 90
Database成绩:
小明 95
小红 81
小新 89
小丽 85
Python成绩:
小明 82
小红 83
小新 94
小丽 91
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
在“/home/zhc/mycode/avgscore”目录下新建代码文件avgscore.txt:
# /home/zhc/mycode/avgscore/avgscore.txt
from pyspark import SparkContext
#初始化SparkContext
sc = SparkContext('local',' avgscore')
#加载三个文件Algorithm.txt、Database.txt和Python.txt
lines1 = sc.textFile("file:///home/zhc/mycode/avgscore/Algorithm.txt")
lines2 = sc.textFile("file:///home/zhc/mycode/avgscore/Database.txt")
lines3 = sc.textFile("file:///home/zhc/mycode/avgscore/Python.txt")
#合并三个文件的内容
lines = lines1.union(lines2).union(lines3)
#为每行数据新增一列1,方便后续统计每个学生选修的课程数目。data的数据格式为('小明', (92, 1))
data = lines.map(lambda x:x.split(" ")).map(lambda x:(x[0],(int(x[1]),1)))
#根据key也就是学生姓名合计每门课程的成绩,以及选修的课程数目。res的数据格式为('小明', (269, 3))
res = data.reduceByKey(lambda x,y:(x[0]+y[0],x[1]+y[1]))
#利用总成绩除以选修的课程数来计算每个学生的每门课程的平均分,并利用round(x,2)保留两位小数
result = res.map(lambda x:(x[0],round(x[1][0]/x[1][1],2)))
#将结果写入result文件中,repartition(1)的作用是让结果合并到一个文件中,不加的话会结果写入到三个文件
result.repartition(1).saveAsTextFile("file:///home/zhc/mycode/avgscore/result")
在目录“/home/zhc/mycode/avgscore”下执行下面命令执行程序(注意执行程序时请先退出pyspark shell,否则会出现“地址已在使用”的警告)。
[root@bigdata avgscore]# python3 avgscore.py 在目录“/home/zhc/mycode/avgscore/result”下即可得到结果文件part-00000。
[root@bigdata avgscore]# cd result
[root@bigdata result]# cat part-00000

4、三个综合实例
案例一:求Top值
任务描述:某个目录下有若干个文本文件,每个文件里包含了很多数据,每行数据由4个字段的值构成,不同字段之间用逗号隔开,4个字段分别为orderid,userid,payment和productid,要求求出Top N个payment值。
file01.txt:
1,1768,50,155
2,1218, 600,211
3,2239,788,242
4,3101,28,599
5,4899,290,129
6,3110,54,1201
7,4436,259,877
8,2369,7890,27
file02.txt:
100,4287,226,233
101,6562,489,124
102,1124,33,17
103,3267,159,179
104,4569,57,125
105,1438,37,116
[root@bigdata zhc]# cd /mycode/RDD
[root@bigdata RDD]# vi file0.txt
[root@bigdata RDD]# vi TopN.py
[root@bigdata RDD]# vi file0.txt
[root@bigdata RDD]# spark-submit TopN.py 使用vim编辑器编辑“/home/zhc/mycode/RDD/file0.txt”文件:
我这里将file01.txt和file02.txt合并为一个文件了——>file0.txt
1,1768,50,155
2,1218,600,211
3,2239,788,242
4,3101,28,599
5,4899,290,129
6,3110,54,1201
7,4436,259,877
8,2369,7890,27
100,4287,226,233
101,6562,489,124
102,1124,33,17
103,3267,159,179
104,4569,57,125
105,1438,37,116
使用vim编辑器编辑“/home/zhc/mycode/RDD/TopN.py”代码文件:
#/home/zhc/mycode/RDD/TopN.py
from pyspark import SparkConf, SparkContext
# 创建SparkConf对象,设置应用程序名称和部署模式
conf = SparkConf().setMaster("local").setAppName("ReadHBase")
# 创建SparkContext对象
sc = SparkContext(conf = conf)
# 从本地文件系统读取数据
lines= sc.textFile("file:///home/zhc/mycode/RDD/file0.txt")
# 过滤出长度不为0且包含4个逗号的行
result1 = lines.filter(lambda line:(len(line.strip()) > 0) and (len(line.split(","))== 4))
# 提取第三列数据
result2=result1.map(lambda x:x.split(",")[2])
# 将第三列数据转换成键值对(key为数字,value为空串)
result3=result2.map(lambda x:(int(x),""))
# 对数据进行重新分区,分区数为1
result4=result3.repartition(1)
# 按照键降序排序
result5=result4.sortByKey(False)
# 取出前5个键
result6=result5.map(lambda x:x[0])
result7=result6.take(5)
# 打印前5个键
for a in result7: print(a)
使用spark-submit提交TopN.py文件,得到结果如下。

案例二:文件排序
任务描述:有多个输入文件,每个文件中的每一行内容均为一个整数。要求读取所有文件中的整数,进行排序后,输出到一个新的文件中,输出的内容个数为每行两个整数,第一个整数为第二个整数的排序位次,第二个整数为原待排序的整数。
输入文件:
file1.txt:
33
37
12
40
file2.txt:
4
16
39
5
file3.txt:
1
45
25
[root@bigdata RDD]# mkdir filesort
[root@bigdata RDD]# cd filesort
[root@bigdata filesort]# vi file1.txt
[root@bigdata filesort]# vi file2.txt
[root@bigdata filesort]# vi file3.txt
[root@bigdata filesort]# cd ..
[root@bigdata RDD]# vi FileSort.py
[root@bigdata RDD]# spark-submit FileSort.py
在“/home/zhc/mycode/RDD/filesort”路径下,使用vim编辑器将上面三个文件内容输入。
使用vim编辑器编辑“/home/zhc/mycode/RDD/FileSort.py”文件:
#/home/zhc/mycode/RDD/FileSort.py
from pyspark import SparkConf, SparkContext
# 定义一个全局变量index,用于记录索引值
index=0
# 自定义函数getindex,每调用一次将index加1,并返回新的index值
def getindex():global indexindex+=1return index
def main():# 创建SparkConf对象,设置应用程序名称和部署模式(本地1核运行)conf = SparkConf().setMaster("local[1]").setAppName("FileSort") sc = SparkContext(conf = conf)lines= sc.textFile("file:///home/zhc/mycode/RDD/filesort/file*.txt") index = 0# 过滤出长度不为0的行result1 = lines.filter(lambda line:(len(line.strip()) > 0))# 将每行数据转换成整型键值对 result2=result1.map(lambda x:(int(x.strip()),"")) # 对数据进行重新分区,分区数为1result3=result2.repartition(1)# 按照键升序排序 result4=result3.sortByKey(True)# 只保留键 result5=result4.map(lambda x:x[0])# 将数据映射为(index, value)的形式result6=result5.map(lambda x:(getindex(),x)) result6.foreach(print)# 将结果保存到本地文件系统result6.saveAsTextFile("file:///home/zhc/mycode/RDD/filesort/sortresult")
if __name__ == '__main__':main()
使用spark-submit提交FileSort.py文件,得到结果如下。

可以到“/home/zhc/mycode/RDD/filesort/sortresult”目录下查看结果文件part-00000。
[root@bigdata RDD]# cd ./filesort/sortresult
[root@bigdata sortresult]# cat part-00000
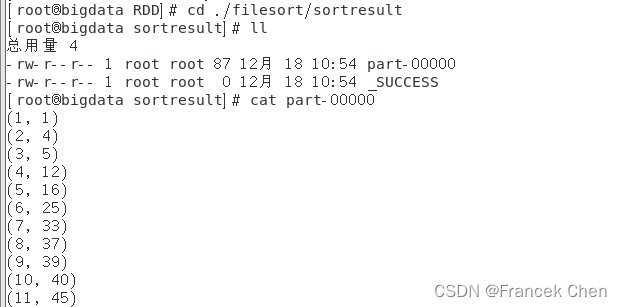
案例三:二次排序
任务描述: 对于一个给定的文件(数据如file4.txt所示),请对数据进行排序,首先根据第1列数据降序排序,如果第1列数据相等,则根据第2列数据降序排序。
输入文件 file4.txt:
5 3
1 6
4 9
8 3
4 7
5 6
3 2
[root@bigdata RDD]# vi file4.txt
[root@bigdata RDD]# vi SecondarySortApp.py
[root@bigdata RDD]# spark-submit SecondarySortApp.py在“/home/zhc/mycode/RDD”路径下,使用vim编辑器将上面file4.txt文件内容输入。
使用vim编辑器编辑“/home/zhc/mycode/RDD/SecondarySortApp.py”文件:
#/home/zhc/mycode/RDD/SecondarySortApp.py
# 导入gt函数,用于比较大小
from operator import gt
from pyspark import SparkContext, SparkConf
# 定义SecondarySortKey类
class SecondarySortKey():def __init__(self, k):self.column1 = k[0]self.column2 = k[1]# 定义__gt__方法,用于比较大小def __gt__(self, other):if other.column1 == self.column1:return gt(self.column2,other.column2)else:return gt(self.column1, other.column1)def main():# 创建SparkConf对象,设置应用程序名称和部署模式(本地1核运行)conf = SparkConf().setAppName('spark_sort').setMaster('local[1]')sc = SparkContext(conf=conf)file="file:///home/zhc/mycode/RDD/file4.txt"rdd1 = sc.textFile(file)# 过滤出长度不为0的行rdd2=rdd1.filter(lambda x:(len(x.strip()) > 0))# 将每行数据转换成带有键值对的元组,键为元组类型rdd3=rdd2.map(lambda x:((int(x.split(" ")[0]),int(x.split(" ")[1])),x))# 将数据中的键转换成SecondarySortKey类型rdd4=rdd3.map(lambda x: (SecondarySortKey(x[0]),x[1]))# 对数据进行按键排序rdd5=rdd4.sortByKey(False)# 只保留值rdd6=rdd5.map(lambda x:x[1])rdd6.foreach(print)if __name__ == '__main__':main()

使用spark-submit提交SecondarySortApp.py文件,得到结果如下。

四、结果分析与实验体会
在进行RDD编程实验之前,需要掌握Spark的基本概念和RDD的特性,例如惰性计算、分区、依赖关系等。同时需要了解Python等语言的基础知识。在实验过程中,可以通过以下步骤来完成:
(1)创建SparkContext对象,用于连接Spark集群和创建RDD;(2)通过textFile函数读取文件数据,并利用filter等函数进行数据清洗和处理;(3)将数据转换成键值对的形式,再利用map、reduceByKey等函数进行计算和处理;(4)利用sortByKey等函数进行排序操作;(5)最后通过foreach等函数将结果输出。
在实验过程中,需要注意以下几点:(1)选择合适的算子,例如filter、map、reduceByKey、sortByKey等,以及合适的lambda表达式来进行数据处理和计算。(2)对于大规模数据的处理,需要考虑分区和并行计算,以提高计算效率。(3)需要注意数据类型和格式,确保数据的正确性和一致性。(4)在进行排序操作时,需要利用自定义类来实现二次排序等功能。
总之,通过实验可以更加深入地理解Spark的原理和机制,提高数据处理和计算的效率和准确性。同时也能够培养代码编写和调试的能力,提高编程水平。
相关文章:
Spark编程实验二:RDD编程初级实践
目录 一、目的与要求 二、实验内容 三、实验步骤 1、pyspark交互式编程 2、编写独立应用程序实现数据去重 3、编写独立应用程序实现求平均值问题 4、三个综合实例 四、结果分析与实验体会 一、目的与要求 1、熟悉Spark的RDD基本操作及键值对操作; 2、熟悉使…...
CleanMyMac X这一款mac电脑清理垃圾文件软件好用吗?
CleanMyMac X您的 Mac。极速如新。点按一下,即可优化调整整个 Mac畅享智能扫描 — 这款超级简单的工具用于优化您的 Mac。只需点按一下,即可运行所有任务,让您的 Mac 保持干净、快速并得到最佳防护。CleanMyMac 是一款功能强大的 Mac 清理程序…...
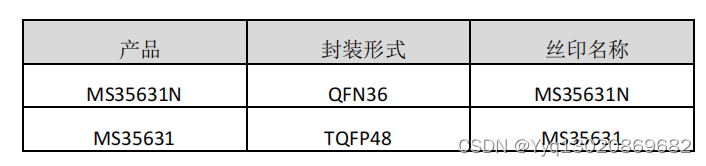
四通道 DMOS 全桥驱动MS35631N/MS35631
MS35631N/MS35631 是一款四通道 DMOS 全桥驱动器,可以驱动两 个步进电机或者四个直流电机。每个全桥的驱动电流在 24V 电源下可以 达到 1.2A 。 MS35631N/MS35631 集成了固定关断时间的 PWM 电流校正 器,以及一个 2bit 的非线性 DAC &…...
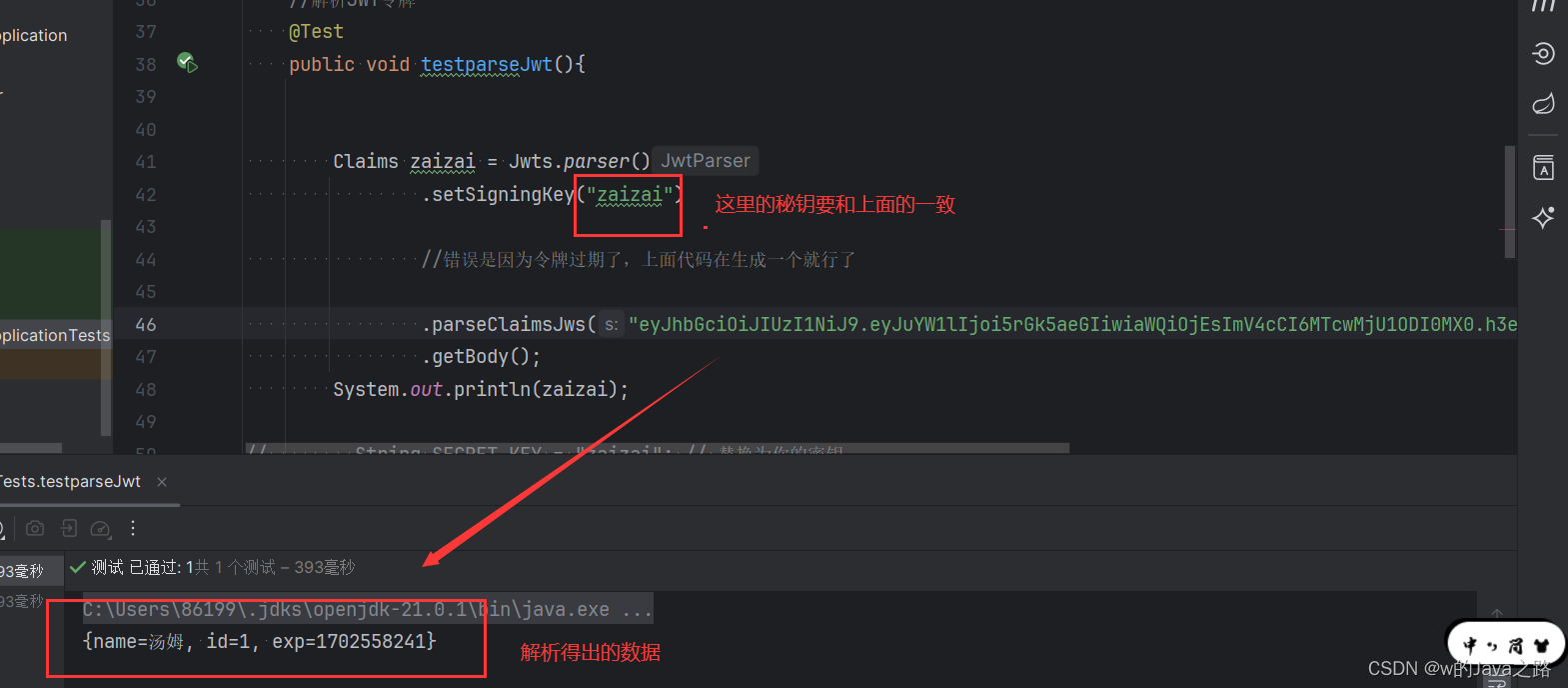
JWT令牌的作用和生成
JWT令牌(JSON Web Token)是一种用于身份验证和授权的安全令牌。它由三部分组成:头部、载荷和签名。 JWT令牌的作用如下: 身份验证:JWT令牌可以验证用户身份。当用户登录后,服务器会生成一个JWT令牌并返回…...

elementui el-pagination分页组件查询的时候当前页不更新
elementui el-pagination分页组件查询的时候当前页不更新 <mypagination v-if"pageshow" :currentPage.sync"pageNum" :pagesize"pageSize" :pagetotal"pageTotal" pagefunc"pageFunc"></mypagination>1.在加的…...
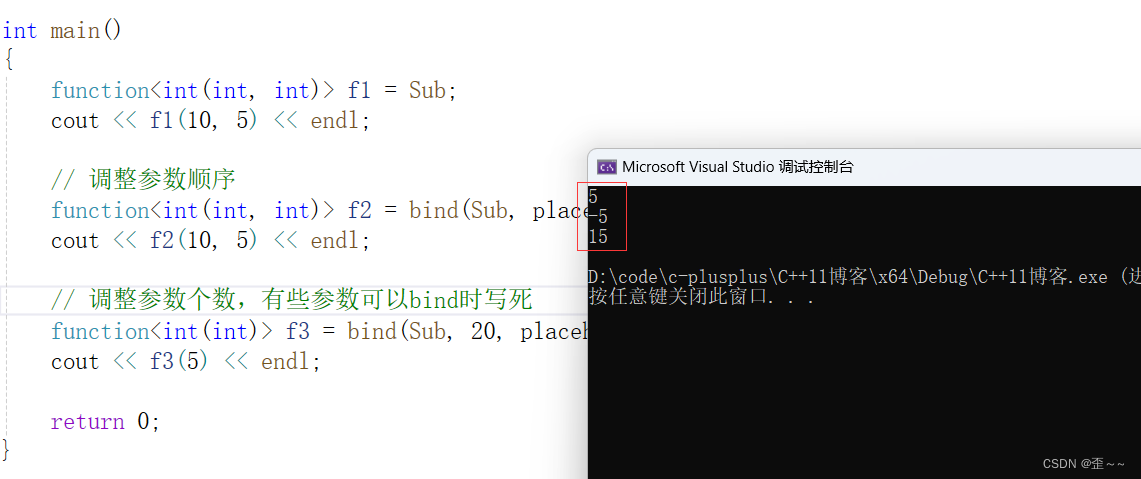
C++——C++11(1)
时至今日,C标准已经到了C23,但是你要说哪一次提出的标准最经 典,那C11一定会被人提及,C11带来了数量可观的变化,其中包 含了约140个新特性,以及对C03标准中约600个缺陷的修正,这使得 C11更像是从…...

CoPilot究竟如何使用?
基本步骤说明 CoPilot是一款由GitHub开发的人工智能代码助手,可以提供实时代码建议和自动完成功能。下面是使用CoPilot的详细介绍: 安装:首先,你需要在你的代码编辑器中安装CoPilot插件。目前,CoPilot支持一些主流的代…...
)
前端(三)
1.表格标签 数据展示: jason 123 read egon 123 dbj tank 123 hecha ... <table> <thead><tr> 一个tr就表示一行<th>username</th> 加粗文本<td>username</td> 正常文本</tr></thead> 表头(字段信息)<tbody>…...

Maven知识
文章目录 一、概念1、官方文档2、什么是Maven? 二、相关知识1、Maven生命周期1.1、clean1.2、default1.3、site 2、Pom文件3、Pom常用元素3.1、项目基本元素3.2、<properties\></properties\>3.3、pom继承相关3.4、依赖管理相关3.5、构建管理相关3.6、&…...

美颜SDK是什么?视频美颜SDK在直播平台中的集成与接入教程详解
当下,主播们追求更加自然、精致的外观,而观众也期待在屏幕前欣赏到更为清晰、美丽的画面。为了满足这一需求,美颜SDK应运而生,成为直播平台的重要利器之一。 一、什么是美颜SDK? 通过美颜SDK,开发者可以…...
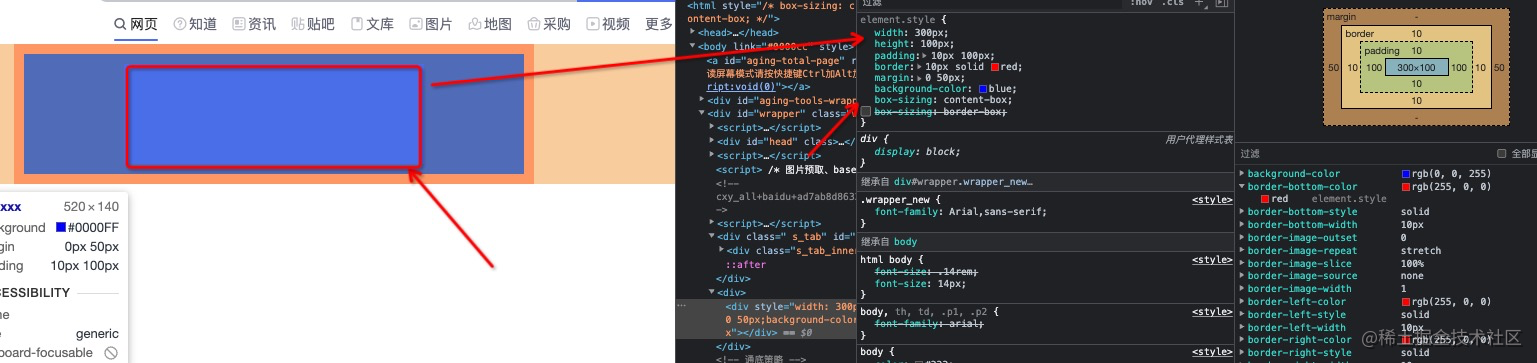
CSS基础面试题
介绍一下标准css盒子模型与低版本IE的盒子模型? 标准盒子模型:宽度内容的宽度(content) border padding margin 低版本IE盒子模型:宽度内容宽度(contentborderpadding) margin box-sizing 属性…...

L1-028 判断素数
本题的目标很简单,就是判断一个给定的正整数是否素数。 输入格式: 输入在第一行给出一个正整数N(≤ 10),随后N行,每行给出一个小于231的需要判断的正整数。 输出格式: 对每个需要判断的正整数&a…...

Scala多线程爬虫程序的数据可视化与分析实践
一、Scala简介 Scala是一种多种类型的编程语言,结合了针对对象编程和函数式编程的功能。它运行在Java虚拟机上,具有强大的运算能力和丰富的库支持。Scala常用于大数据处理、并发编程和Web应用程序开发。其灵活性和高效性编程成为编写多线程爬虫程序的理…...
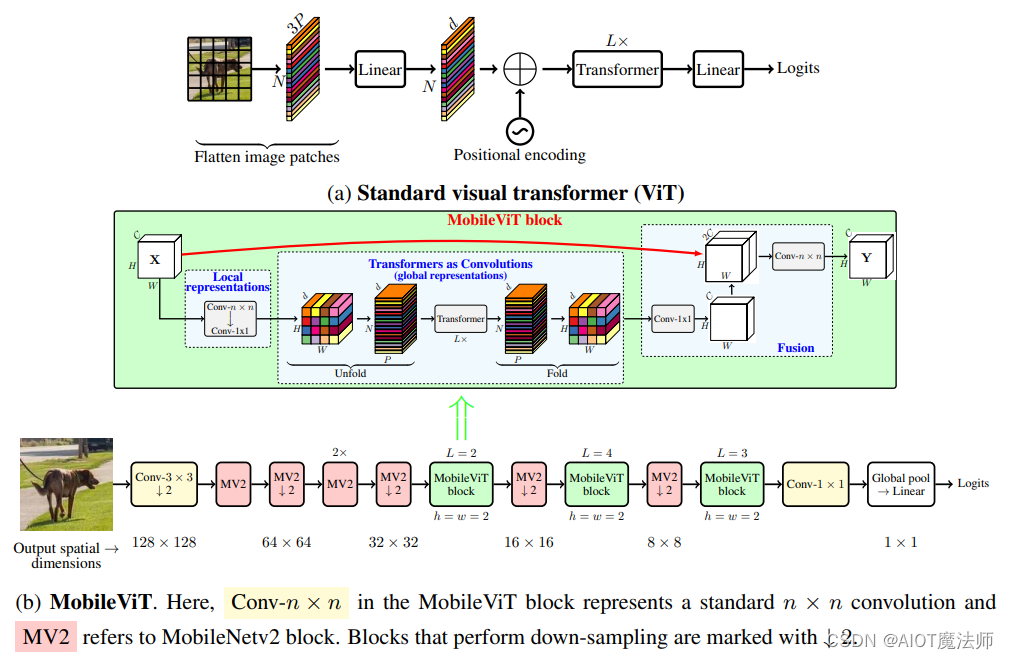
YOLOv8加入顶会ICLR2022MobileViT模块
一、原文引入介绍 MOBILEVIT:轻量级、通用型且移动友好的视觉Transformer 论文地址:https://arxiv.org/pdf/2110.02178.pdf MOBILEVIT: LIGHT-WEIGHT, GENERAL-PURPOSE,AND MOBILE-FRIENDLY VISION TRANSFORMER MobileViT是由苹果公司发表在ICLR2022顶会上的一篇文章,这篇文…...

「数据结构」二叉树1
🎇个人主页:Ice_Sugar_7 🎇所属专栏:C启航 🎇欢迎点赞收藏加关注哦! 文章目录 🍉树🍉二叉树🍌特殊二叉树🍌二叉树的性质🍌存储结构 🍉…...
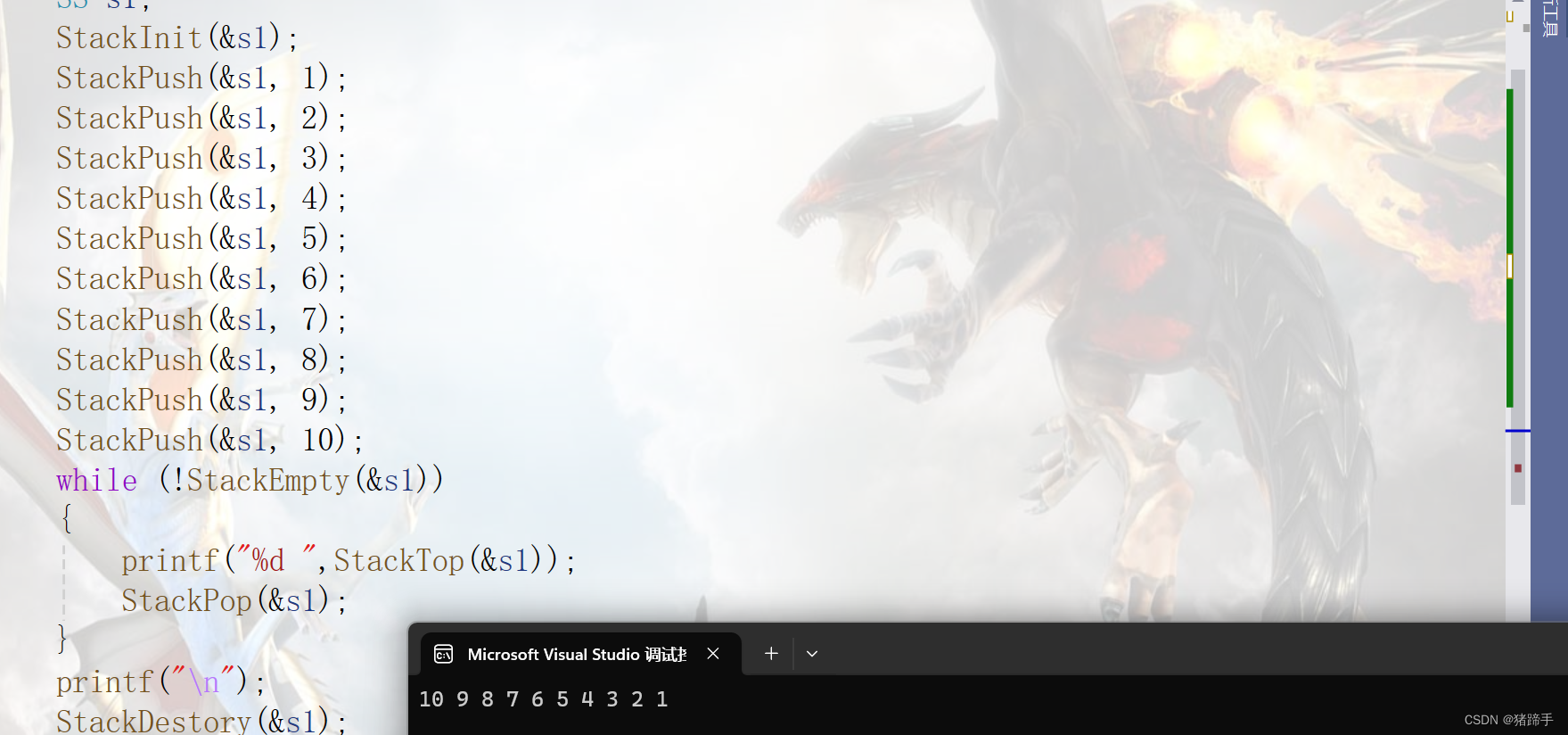
栈(C语言版)
一.栈的概念及结构 栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。 进行数据插入和删除操作的一端 称为栈顶,另一端称为栈底。 栈中的数据元素遵守 后进先出 LIFO ( Last In First Out )的原则。…...

聊聊reactor-logback的AsyncAppender
序 本文主要研究一下reactor-logback的AsyncAppender AsyncAppender reactor-logback/src/main/java/reactor/logback/AsyncAppender.java public class AsyncAppender extends ContextAwareBaseimplements Appender<ILoggingEvent>, AppenderAttachable<ILogging…...
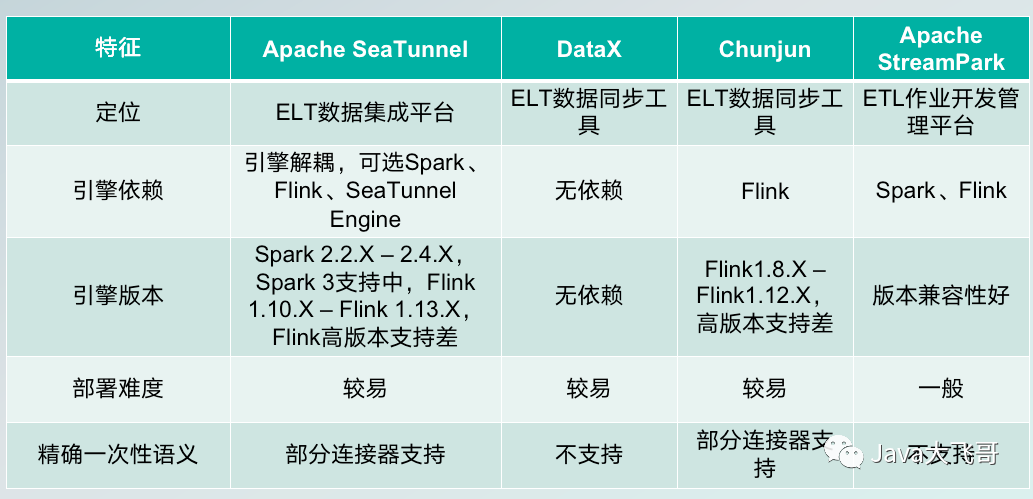
Apache SeaTunne简介
Apache SeaTunne简介 文章目录 1.Apache SeaTunne是什么?1.1[官网](https://seatunnel.apache.org/)1.2 项目地址 2.架构3.特性3.1 丰富且可扩展的连接器和插件机制3.2 支持分布式快照算法以确保数据一致性3.3 支持流、批数据处理,支持全量、增量和实时数…...

【开题报告】基于uniapp的IT资讯阅读小程序的设计与实现
1.研究背景 随着信息技术的飞速发展和互联网的普及,IT(Information Technology)行业成为了当今社会中最活跃和最具前景的领域之一。人们对于IT领域的资讯需求越来越高,希望能够第一时间获取到全面、准确、及时的IT资讯。 传统的…...

Java小案例-SpringBoot火车票订票购票票务系统
目录 前言 详细资料 源码获取 前言 SpringBoot火车票订票购票票务系统 前端使用技术:HTML5,CSS3、JavaScript、VUE等 后端使用技术:Spring boot(SSM)等 数据库:Mysql数据库 数据库管理工具:phpstud…...

从ST官方例程到产品级Bootloader:STM32F030 IAP的内存划分、中断重映射与APP配置全解析
从ST官方例程到产品级Bootloader:STM32F030 IAP的内存划分、中断重映射与APP配置全解析 在嵌入式产品开发中,固件升级是一个无法回避的挑战。想象一下,当你的设备已经部署在现场,却发现需要修复一个关键bug或添加新功能时…...

DuClaw智能体:使用手册
学习并使用技能DuClaw 在创建时已为您预置部分常用技能,可根据任务需求自动匹配调用。查看已有技能1.进入对话界面,单击“技能平台”按钮,并在弹窗中单击“查看我的技能”。2.DuClaw会回复您当前已安装的技能以及相应的技能信息。安装并使用技…...

你的Mac数字管家:Pearcleaner如何让macOS保持“梨子般“的清新体验?
你的Mac数字管家:Pearcleaner如何让macOS保持"梨子般"的清新体验? 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾…...

3个高级功能解锁NIPAP企业级IP地址管理潜力
3个高级功能解锁NIPAP企业级IP地址管理潜力 【免费下载链接】NIPAP Neat IP Address Planner - NIPAP is the best open source IPAM in the known universe, challenging classical IP address management (IPAM) systems in many areas. 项目地址: https://gitcode.com/gh_…...

ARM SMMU-700内存管理单元原理与优化实践
1. MMU-700 SMMU架构概述与典型应用场景内存管理单元(MMU)是现代计算机系统中不可或缺的核心组件,负责处理虚拟地址到物理地址的转换。在ARM架构中,系统级内存管理单元(SMMU)扮演着更为关键的角色ÿ…...

突破存储限制:群晖DSM7下Synology Photos自定义文件夹挂载实战
1. 为什么需要自定义文件夹挂载 很多群晖用户升级到DSM7后都会遇到一个头疼的问题:Synology Photos默认把所有个人照片都存放在/home/Photos目录下,而这个目录实际上位于/homes共享文件夹中。随着照片数量不断增加,/homes所在存储空间很快就会…...

轻量级工作流引擎pro-workflow:Go语言实现与实战解析
1. 项目概述:一个为专业开发者量身打造的工作流引擎如果你是一名开发者,尤其是经常需要处理复杂业务逻辑、数据流转或自动化任务的后端或全栈工程师,那么你一定对“工作流”这个概念不陌生。从简单的审批流到复杂的微服务编排,工作…...

Vim-ai插件深度指南:在Vim中无缝集成AI提升开发效率
1. 项目概述:当Vim遇上AI,一场编辑器生产力的革命如果你和我一样,是个在终端里泡了十多年的老Vim用户,那你一定经历过这样的场景:面对一个复杂的函数重构,手指在键盘上飞舞,:s、%s、宏录制轮番上…...

嵌入式测试学习第 12天:串口基础概念:UART、波特率、数据位、校验位
串口基础概念:UART、波特率、数据位、校验位一、串口整体基础概念1、什么是UART串口2、串口实物真实图片① 主板/开发板排针串口② USB转TTL串口模块③ 老式DB9工业串口公头母头二、串口四大核心参数1、波特率概念常用标准固定值通俗理解测试场景2、数据位概念作用3…...
:从F0曲线调制到微表情时序对齐)
ElevenLabs情绪驱动API实战手册(2024企业级部署全链路):从F0曲线调制到微表情时序对齐
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs情绪驱动API核心架构与演进脉络 ElevenLabs 的情绪驱动 API 并非简单叠加情感标签的语音合成增强层,而是构建在多模态表征学习与实时声学参数调控双引擎之上的闭环系统。其核心架…...