【Hive】——DML
1 Load(加载数据)
1.1 概述

1.2 语法
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] [INPUTFORMAT 'inputformat' SERDE 'serde'] (3.0 or later)
1.2.1 filepath

1.2.2 local


1.2.3 overwrite

1.4 Hive 3.0 Load新特性

CREATE TABLE if not exists tab1 (col1 int, col2 int)PARTITIONED BY (col3 int)row format delimited fields terminated by ',';
--tab1.txt内容如下
11,22,1
33,44,2
LOAD DATA LOCAL INPATH '/root/data/tab1.txt' INTO TABLE tab1;
1.5 案例
1.5.1 创建表
--step1:建表
--建表student_local 用于演示从本地加载数据
create table student_local(num int,name string,sex string,age int,dept string) row format delimited fields terminated by ',';
--建表student_HDFS 用于演示从HDFS加载数据
create external table student_HDFS(num int,name string,sex string,age int,dept string) row format delimited fields terminated by ',';
--建表student_HDFS_p 用于演示从HDFS加载数据到分区表
create table student_HDFS_p(num int,name string,sex string,age int,dept string) partitioned by(country string) row format delimited fields terminated by ',';
1.5.1 加载数据
-- 从本地加载数据 数据位于HS2(node1)本地文件系统 本质是hadoop fs -put上传操作
LOAD DATA LOCAL INPATH '/root/hivedata/students.txt' INTO TABLE student_local;--从HDFS加载数据 数据位于HDFS文件系统根目录下 本质是hadoop fs -mv 移动操作
--先把数据上传到HDFS上 hadoop fs -put /root/hivedata/students.txt /
LOAD DATA INPATH '/students.txt' INTO TABLE student_HDFS;----从HDFS加载数据到分区表中并制定分区 数据位于HDFS文件系统根目录下
--先把数据上传到HDFS上 hadoop fs -put /root/hivedata/students.txt /
LOAD DATA INPATH '/students.txt' INTO TABLE student_HDFS_p partition(country ="China");
2 insert(插入数据)
2.1 insert
执行过程非常非常慢,原因在于底层是使用MapReduce把数据写入Hive表中
create table t_test_insert(id int,name string,age int);
insert into table t_test_insert values(1,"allen",18);
Hive官方推荐加载数据的方式:清洗数据成为结构化文件,再使用Load语法加载数据到表中。这样的效率更高。
2.2 insert+select
- insert+select表示:将后面查询返回的结果作为内容插入到指定表中,注意OVERWRITE将覆盖已有数据。
- 需要保证查询结果列的数目和需要插入数据表格的列数目一致。
- 如果查询出来的数据类型和插入表格对应的列数据类型不一致,将会进行转换,但是不能保证转换一定成功,转换失败的数据将会为NULL。
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;insert into table student_from_insert select num,name from student;
2.3 Multiple Inserts(多次插入)
翻译为多次插入,多重插入,其核心功能是:一次扫描,多次插入。
语法目的就是减少扫描的次数,在一次扫描中。完成多次insert操作。
--当前库下已有一张表student
select * from student;
--创建两张新表
create table student_insert1(sno int);
create table student_insert2(sname string);
--多重插入
from student
insert overwrite table student_insert1
select num
insert overwrite table student_insert2
select name;
2.4 dynamic partition insert(动态分区)
2.4.1 概述
- 动态分区插入指的是:分区的值是由后续的select查询语句的结果来动态确定的。
- 根据查询结果自动分区。动态分区将最后一个字段作为分区
2.4.2 配置参数

set hive.exec.dynamic.partition = true;
set hive.exec.dynamic.partition.mode = nonstrict;<property><name>hive.exec.dynamic.partition</name><value>true</value><description>Whether or not to allow dynamic partitions in DML/DDL.</description>
</property>
<property><name>hive.exec.dynamic.partition.mode</name><value>strict</value><description>In strict mode, the user must specify at least one static partitionin case the user accidentally overwrites all partitions.In nonstrict mode all partitions are allowed to be dynamic.
</description>2.4 insert Directory(导出数据)
2.4.1 概述
Hive支持将select查询的结果导出成文件存放在文件系统中。语法格式如下
注意:导出操作是一个OVERWRITE覆盖操作,慎重。
2.4.2 语法
- 目录可以是完整的URI。如果未指定scheme,则Hive将使用hadoop配置变量fs.default.name来决定导出位置;
- 如果使用LOCAL关键字,则Hive会将数据写入本地文件系统上的目录;
- 写入文件系统的数据被序列化为文本,列之间用\001隔开,行之间用换行符隔开。如果列都不是原始数据类型,那么这些列将序列化为JSON格式。也可以在导出的时候指定分隔符换行符和文件格式。
标准语法
INSERT OVERWRITE [LOCAL] DIRECTORY directory1[ROW FORMAT row_format] [STORED AS file_format]
SELECT ... FROM ...
多重多出
FROM from_statement
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1[INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] ...导出格式
DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char][MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
10.2.4.3 案例
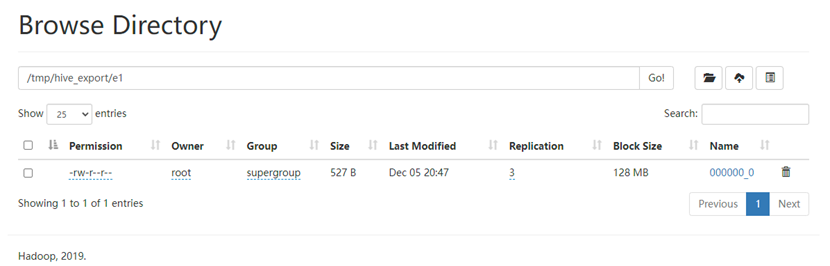
导出到hdfs文件系统
insert overwrite directory '/tmp/hive_export/e1' select * from student;
导出时指定分隔符和文件存储格式
insert overwrite directory '/tmp/hive_export/e2' row format delimited fields terminated by ',' stored as orc select * from student;
导出数据到本地文件系统指定目录下
insert overwrite local directory '/root/data/e1' select * from student;
3 事务表
3.1 实现原理
3.1.1 概述
- Hive的文件是存储在HDFS上的,而HDFS上又不支持对文件的任意修改,只能是采取另外的手段来完成。
- 用HDFS文件作为原始数据(基础数据),用delta保存事务操作的记录增量数据;
正在执行中的事务,是以一个staging开头的文件夹维护的,执行结束就是delta文件夹。每次执行一次事务操作都会有这样的一个delta增量文件夹; - 当访问Hive数据时,根据HDFS原始文件和delta增量文件做合并,查询最新的数据。
3.1.2 目录
- INSERT语句会直接创建delta目录;
- DELETE目录的前缀是delete_delta;
- UPDATE语句采用了split-update特性,即先删除、后插入;
3.1.3 命名格式
- delta_minWID_maxWID_stmtID,即delta前缀、写事务的ID范围、以及语句ID;删除时前缀是delete_delta,里面包含了要删除的文件;
- Hive会为写事务(INSERT、DELETE等)创建一个写事务ID(Write ID),该ID在表范围内唯一;
- 语句ID(Statement ID)则是当一个事务中有多条写入语句时使用的,用作唯一标识。
3.1.4 delta目录下的文件
每个事务的delta文件夹下,都有两个文件:

- _orc_acid_version的内容是2,即当前ACID版本号是2。和版本1的主要区别是UPDATE语句采用了split-update特性,即先删除、后插入。这个文件不是ORC文件,可以下载下来直接查看。
- bucket_00000文件则是写入的数据内容。如果事务表没有分区和分桶,就只有一个这样的文件。文件都以ORC格式存储,底层二级制,需要使用ORC TOOLS查看,详见附件资料。
3.1.5 bucket 文件

- operation:0 表示插入,1 表示更新,2 表示删除。由于使用了split-update,UPDATE是不会出现的,所以delta文件中的operation是0 , delete_delta 文件中的operation是2。
- originalTransaction、currentTransaction:该条记录的原始写事务ID,当前的写事务ID。
- rowId:一个自增的唯一ID,在写事务和分桶的组合中唯一。
- row:具体数据。对于DELETE语句,则为null,对于INSERT就是插入的数据,对于UPDATE就是更新后的数据。
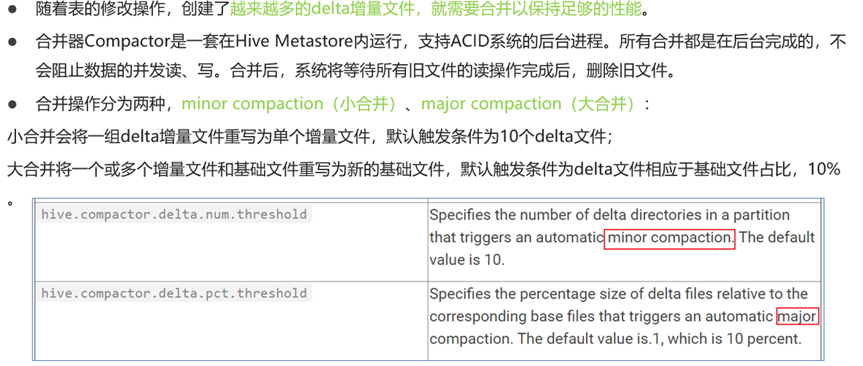
3.1.5 合并器
3.2 局限性

3.3 创建使用
--Hive中事务表的创建使用
--1、开启事务配置(可以使用set设置当前session生效 也可以配置在hive-site.xml中)
set hive.support.concurrency = true; --Hive是否支持并发
set hive.enforce.bucketing = true; --从Hive2.0开始不再需要 是否开启分桶功能
set hive.exec.dynamic.partition.mode = nonstrict; --动态分区模式 非严格
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; --
set hive.compactor.initiator.on = true; --是否在Metastore实例上运行启动压缩合并
set hive.compactor.worker.threads = 1; --在此metastore实例上运行多少个压缩程序工作线程。
--2、创建Hive事务表
create table trans_student(id int,name String,age int
) stored as orc TBLPROPERTIES('transactional'='true');
4 update、delete
只有事务表才可以更新删除。
相关文章:
【Hive】——DML
1 Load(加载数据) 1.1 概述 1.2 语法 LOAD DATA [LOCAL] INPATH filepath [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1val1, partcol2val2 ...)]LOAD DATA [LOCAL] INPATH filepath [OVERWRITE] INTO TABLE tablename [PARTITION (partcol…...
【Spring教程31】SSM框架整合实战:从零开始学习SSM整合配置,如何编写Mybatis SpringMVC JDBC Spring配置类
目录 1 流程分析2 整合配置2.1 步骤1:创建Maven的web项目2.2 步骤2:添加依赖2.3 步骤3:创建项目包结构2.4 步骤4:创建SpringConfig配置类2.5 步骤5:创建JdbcConfig配置类2.6 步骤6:创建MybatisConfig配置类2.7 步骤7:创建jdbc.properties2.8 步骤8:创建SpringMVC配置…...

Tailwind CSS 入门
什么是 Tailwind CSS? Tailwind CSS 是一个 CSS 框架,它提供了大量的预定义实用类,可以用来快速构建 HTML 页面。Tailwind CSS 的优势包括: 可扩展性:Tailwind CSS 的类库是可扩展的,可以根据自己的需要进行定制。性能:Tailwind CSS 的类库是经过精心设计的,可以提高页…...

如何在简历中解释就业空白
您的工作经历有空缺吗?你不是一个人。有很多合理的理由可以解释为什么你需要休息一下。更重要的是,在一份真实正确的简历中,这些问题是无法避免的。直接解释就业差距总是更好,而且有很多因素需要考虑。你未来的老板想要了解工作轨…...
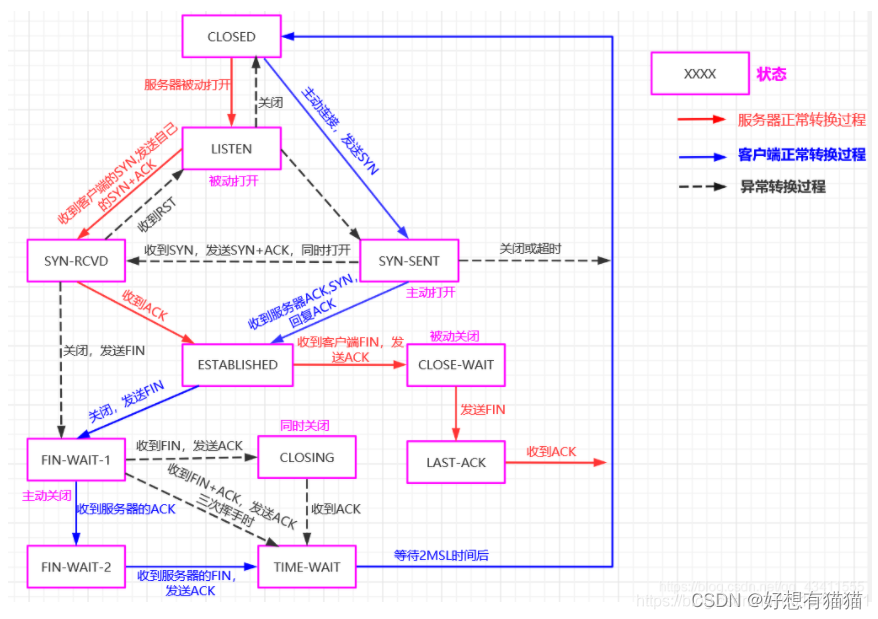
【计算机网络】TCP协议——2.连接管理(三次握手,四次挥手)
目录 前言 一. 建立连接——三次握手 1. 三次握手过程描述 2. TCP连接建立相关问题 二. 释放连接——四次挥手 1. 四次挥手过程描述 2. TCP连接释放相关问题 三. TCP状态转换 结束语 前言 TCP——传输控制协议(Transmission Control Protocol)。是一种面向连接的传…...

螺丝厂家:如何根据您的需求找到合适您的紧固件
螺丝是通用工具。它们几乎用于所有场景,并且它们的使用不限于任何一个行业。人们可以找到几乎所有周围都使用的螺钉和螺栓。在为工作选择合适的螺丝方面,人们应该记住一些事情。选择标准归结为紧固件的物理特性,包括制造它所用的原材料、施加…...

企业数字化转型进入深海区:生成式AI时代下如何制定数据战略
随着科技的不断进步,企业数字化转型已经不再是简单的概念,而是正在进入一个全新的深海区。在这个深海区,数据变得至关重要,而生成式人工智能(AI)的兴起更是推动了数字化转型的飞速发展。本文将探讨在这个生…...

html行内元素和块级元素的区别?
HTML中的元素可以分为两种类型:行内元素(inline)和块级元素(block) 文章目录 什么是行内元素什么是块级元素元素转换行内元素转块级元素块级元素转行内元素 区别总结 什么是行内元素 HTML的行内元素(inli…...

ResNet 原论文及原作者讲解
ResNet 论文摘要1. 引入2. 相关工作残差表示快捷连接 3. 深度残差学习3.1. 残差学习3.2. 快捷恒等映射3.3. 网络体系结构普通网络 plain network残差网络 residual network 3.4. 实施 4. 实验4.1. ImageNet分类普通的网络 plain network残差网络 residual network恒等vs.快捷连…...

liteflow规则引擎 执行Groovy脚本
在LiteFlow规则引擎中执行Groovy脚本的步骤相对简单。首先,确保你的项目中包含了LiteFlow的相关依赖。接下来,创建一个Groovy脚本规则,并使用LiteFlow引擎执行它。 以下是一个简单的示例: 添加LiteFlow依赖:在你的项…...
GZ015 机器人系统集成应用技术样题5-学生赛
2023年全国职业院校技能大赛 高职组“机器人系统集成应用技术”赛项 竞赛任务书(学生赛) 样题5 选手须知: 本任务书共 24页,如出现任务书缺页、字迹不清等问题,请及时向裁判示意,并进行任务书的更换。参赛队…...

Spark编程实验二:RDD编程初级实践
目录 一、目的与要求 二、实验内容 三、实验步骤 1、pyspark交互式编程 2、编写独立应用程序实现数据去重 3、编写独立应用程序实现求平均值问题 4、三个综合实例 四、结果分析与实验体会 一、目的与要求 1、熟悉Spark的RDD基本操作及键值对操作; 2、熟悉使…...
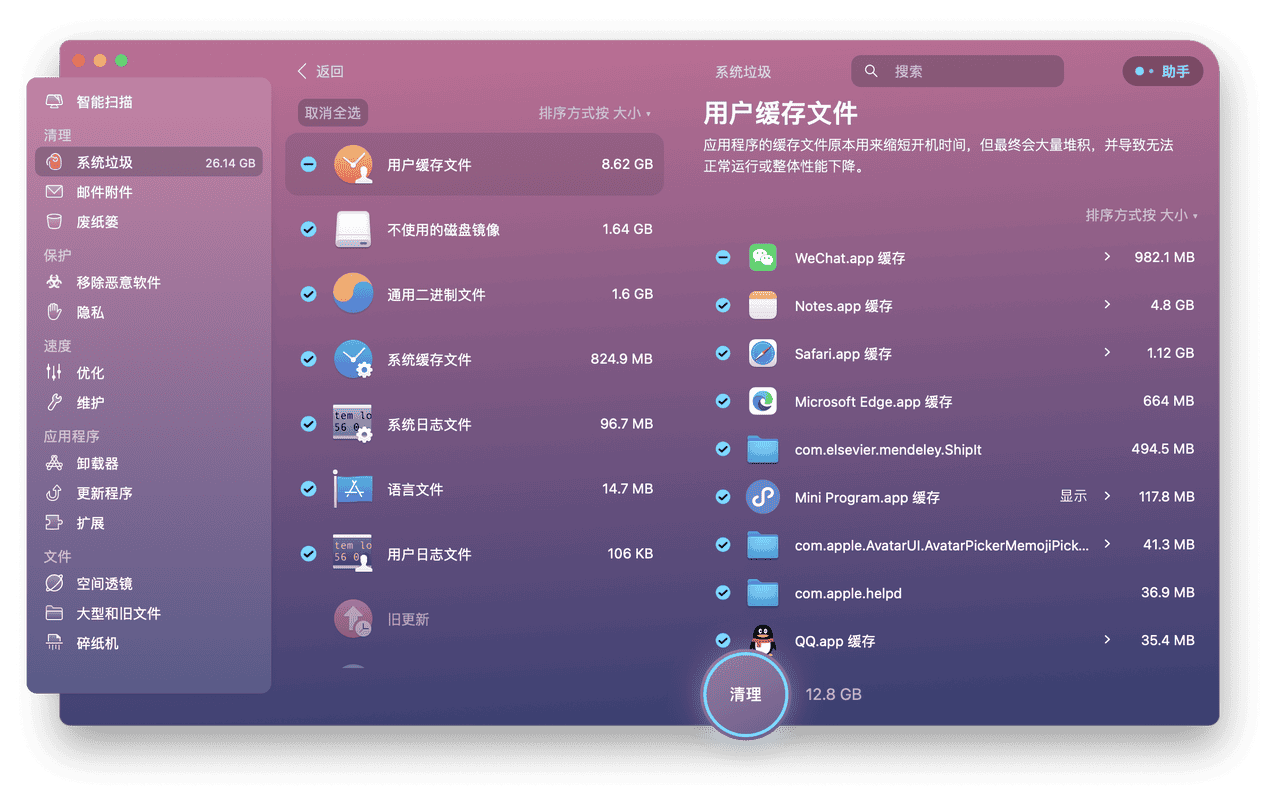
CleanMyMac X这一款mac电脑清理垃圾文件软件好用吗?
CleanMyMac X您的 Mac。极速如新。点按一下,即可优化调整整个 Mac畅享智能扫描 — 这款超级简单的工具用于优化您的 Mac。只需点按一下,即可运行所有任务,让您的 Mac 保持干净、快速并得到最佳防护。CleanMyMac 是一款功能强大的 Mac 清理程序…...
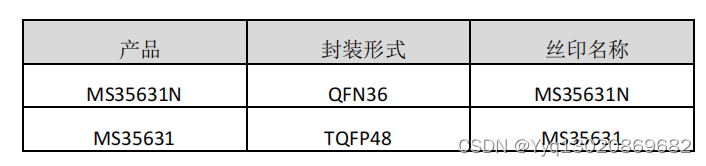
四通道 DMOS 全桥驱动MS35631N/MS35631
MS35631N/MS35631 是一款四通道 DMOS 全桥驱动器,可以驱动两 个步进电机或者四个直流电机。每个全桥的驱动电流在 24V 电源下可以 达到 1.2A 。 MS35631N/MS35631 集成了固定关断时间的 PWM 电流校正 器,以及一个 2bit 的非线性 DAC &…...
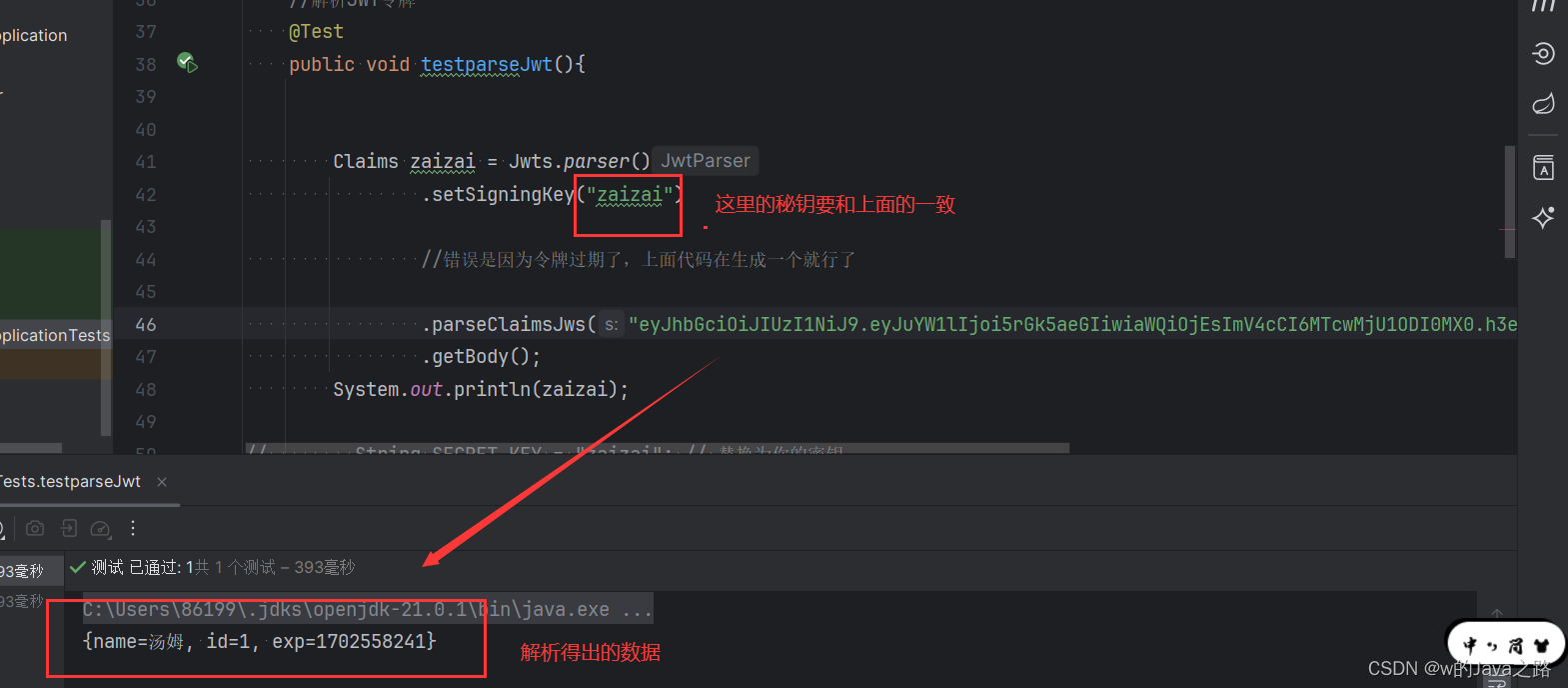
JWT令牌的作用和生成
JWT令牌(JSON Web Token)是一种用于身份验证和授权的安全令牌。它由三部分组成:头部、载荷和签名。 JWT令牌的作用如下: 身份验证:JWT令牌可以验证用户身份。当用户登录后,服务器会生成一个JWT令牌并返回…...

elementui el-pagination分页组件查询的时候当前页不更新
elementui el-pagination分页组件查询的时候当前页不更新 <mypagination v-if"pageshow" :currentPage.sync"pageNum" :pagesize"pageSize" :pagetotal"pageTotal" pagefunc"pageFunc"></mypagination>1.在加的…...
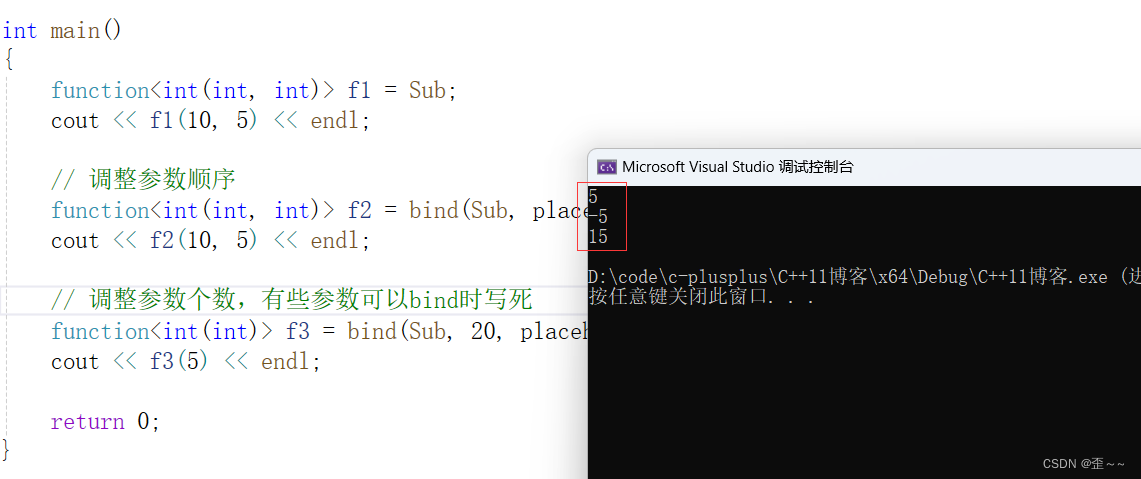
C++——C++11(1)
时至今日,C标准已经到了C23,但是你要说哪一次提出的标准最经 典,那C11一定会被人提及,C11带来了数量可观的变化,其中包 含了约140个新特性,以及对C03标准中约600个缺陷的修正,这使得 C11更像是从…...

CoPilot究竟如何使用?
基本步骤说明 CoPilot是一款由GitHub开发的人工智能代码助手,可以提供实时代码建议和自动完成功能。下面是使用CoPilot的详细介绍: 安装:首先,你需要在你的代码编辑器中安装CoPilot插件。目前,CoPilot支持一些主流的代…...
)
前端(三)
1.表格标签 数据展示: jason 123 read egon 123 dbj tank 123 hecha ... <table> <thead><tr> 一个tr就表示一行<th>username</th> 加粗文本<td>username</td> 正常文本</tr></thead> 表头(字段信息)<tbody>…...

Maven知识
文章目录 一、概念1、官方文档2、什么是Maven? 二、相关知识1、Maven生命周期1.1、clean1.2、default1.3、site 2、Pom文件3、Pom常用元素3.1、项目基本元素3.2、<properties\></properties\>3.3、pom继承相关3.4、依赖管理相关3.5、构建管理相关3.6、&…...

2026年抠图app有哪些?一篇避坑指南告诉你哪款最好用
最近身边朋友经常问我:"抠图app有哪些?"、"免费抠图app有哪些工具推荐?",我决定整理一份完整的对比指南,基于我的实际使用经验,为你揭开各款抠图工具的真实面目。说实话,现…...

2025最权威的AI辅助写作助手推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek AI辅助写作工具正深刻改变着学术研究的传统范式,这是随着人工智能技术飞快发展而…...

颠覆性创新:为什么Upkie开源轮式双足机器人正在重新定义机器人开发范式
颠覆性创新:为什么Upkie开源轮式双足机器人正在重新定义机器人开发范式 【免费下载链接】upkie Open-source wheeled biped robots 项目地址: https://gitcode.com/gh_mirrors/up/upkie 在传统机器人设计面临轮式与足式两难选择的今天,一个革命性…...

无线渗透测试框架Airecon:自动化工具链整合与实战应用
1. 项目概述与核心价值最近在整理自己的渗透测试工具箱时,又翻出了pikpikcu/airecon这个老伙计。说实话,在无线安全评估这个细分领域里,它可能不是名气最响的那个,但绝对是我个人在内部网络渗透和红队演练中最顺手、最高效的“组合…...

深度集成AI的VSCode扩展:从代码生成到调试的全流程实战指南
1. 项目概述:一个为VSCode注入AI灵魂的扩展如果你和我一样,每天有超过8小时的时间是在Visual Studio Code(VSCode)里度过的,那么你一定对提升编码效率有着近乎偏执的追求。从代码补全、语法高亮到调试、版本控制&#…...

AI智能体生态的包管理器:agenticmarket-cli 设计与实践
1. 项目概述:一个面向AI智能体生态的命令行工具如果你和我一样,长期在AI智能体(Agent)这个领域里折腾,那你肯定经历过这样的场景:为了测试一个最新的开源智能体框架,你需要先找到它的GitHub仓库…...

暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手
暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为暗黑破坏神3玩…...

【HarmonyOS 6.1 全场景实战】《灵犀厨房》之【营养分析引擎】计算个性化卡路里建议:给《灵犀厨房》装上“营养大脑”
【营养分析引擎】计算个性化卡路里建议:给《灵犀厨房》装上“营养大脑” 摘要:从“爱吃什么”到“该吃什么”,是《灵犀厨房》进化的关键一步。上一篇我们刚打通了 Health Kit 数据,今天,我们就要基于 Mifflin-St Jeor …...

如何免费高效优化电脑性能:UXTU终极调优指南
如何免费高效优化电脑性能:UXTU终极调优指南 【免费下载链接】Universal-x86-Tuning-Utility Unlock the full potential of your Intel/AMD based device. 项目地址: https://gitcode.com/gh_mirrors/un/Universal-x86-Tuning-Utility Universal x86 Tuning…...

使用mcp-maker快速构建AI工具集成服务器:从MCP协议到实践
1. 项目概述:一个为AI应用注入“超能力”的MCP服务器工厂 如果你最近在折腾AI应用开发,特别是想给ChatGPT、Claude这类大模型配上“手和脚”,让它们能操作你的本地文件、查询数据库,甚至控制你的智能家居,那你大概率已…...