【Logback技术专题】「入门到精通系列教程」深入探索Logback日志框架的原理分析和开发实战技术指南(上篇)
深入探索Logback日志框架的原理分析和开发实战指南系列
- Logback日志框架
- Logback基本模块
- logback-core
- logback-classic
- logback-access
- Logback的核心类
- Logger
- Appender
- Layout
- Layout和Appender
- filter
- logback模块和核心所属关系
- Logbackj日志级别
- 日志输出级别
- 日志级别介绍
- Logback的maven依赖
- Logback的Logger详细介绍
- Root根上下文
- Root元素的属性包括
- Logger
- 配置案例
- Logback的Filter详细介绍
- Regular Filter
- Turbo Filter
- 常见的过滤器
- LevelFilter
- 属性
- 具体用法介绍
- 具体案例分析
- EvaluatorFilter
- 属性
- 具体用法介绍
- ThresholdFilter
- 具体用法介绍
- 本文总结
Logback日志框架
“Logback"是一个开源的日志组件,它的设计者也是"Log4j"的作者。相比于"Log4j”,它拥有更好的特性,因此成为了一个取代"Log4j"的优秀的日志框架。如果您正寻找一款优秀的日志组件,那么"Logback"将是一个不错的选择。
Logback基本模块

logback-core
logback-core是logback日志系统的核心组件,提供了基础结构,如Loggers、Appenders、Layouts、Filters等等,用于创建、配置和管理logback事件。它是logback的最底层组件,为其他组件提供支持,但使用者通常不需要直接使用它,而是通过更高级别的logback组件使用它的功能。
logback-classic
logback-classic是logback日志系统的核心实现,基于logback-core,提供了更高级别和更易用的API及强大的日志框架功能,如异步日志、日志分级、Logger上下文等等。它还支持SLF4J,提供符合JDK标准的Java日志框架API接口,同时也具备logback自身的特性。因此,logback-classic是使用logback的主要方式,也是logback日志系统的经典实现。
logback-access
logback-access是logback日志系统的其中一个模块,专为记录web应用程序的访问日志而设计。它类似于访问日志分析工具,可帮助开发人员深入了解客户端请求、服务器响应和应用程序运行状态,以便进行调整和优化。logback-access能够自动捕捉HTTP请求和响应对象,提供多种配置选项,定制记录内容和格式化方式。此外,它与logback-classic能够很好地配合使用,将应用程序访问日志和其他日志信息记录到同一文件中,方便管理和分析。
Logback的核心类

Logger
在Logback-classic模块中,日志记录器负责记录日志,并将其关联到应用程序的上下文中,以便存储日志对象。此外,日志记录器还可用于定义日志的级别和类型。
Appender
在Logback-core模块中,主要作用是指定日志输出的目标地点,包括但不限于控制台、文件、远程套接字服务器、MySQL、PostreSQL、Oracle数据库、以及其他数据库、JMS和远程UNIX Syslog守护进程。
Layout
在Logback-core模块中,日志布局(Log Layout)子模块负责将事件转换成字符串并格式化日志信息的输出。如果需要进一步了解布局的详细信息,可以参考Log4j的布局(Layout)模块,以获得更深入的理解。
Layout和Appender
Appender和Layout实现与Logger分离,它们不依赖Logger,也不受Logger的影响。但是,如此才能够保证日志信息能够正常打印出来,Logger需要依赖于Appender和Layout的协作。
filter
Filter主要应用于Appender,用于过滤与日志相关的信息,并仅在Appender级别生效,主要用于控制的日志的可见性功能问题和管理。
logback模块和核心所属关系

Logbackj日志级别
Logback 日志框架共有5种级别,分别为 TRACE 、 DEBUG 、 INFO 、 WARN 、 ERROR,这些级别均被定义在ch.qos.logback.classic.Level类中。
日志输出级别
日志级别可以分为五个等级,从低到高依次为:TRACE < DEBUG < INFO < WARN < ERROR。

从上面可以看出,等级高的级别,可见性越大,举一个案例,TRACE级别最低,所以说它可以看到的范围只能是它的级别,但是DEBUG级别的范围日志,则看到的是DEBUG+TRACE这两个级别范围的日志数据,一次类推即可。
日志级别介绍
日志级别可以从低到高分为:
- TRACE:用于输出程序运行时的详细信息,一般在调试程序时使用。
- DEBUG:用于输出调试信息,可以用来判断代码是否按预期执行。
- INFO:用于输出一些重要的运行时信息,可以用来确认程序运行是否正常。
- WARN:用于输出一些警告信息,不影响程序的运行但需要进行注意。
- ERROR:用于输出错误信息,会影响到程序运行。
此外还有两个特殊的日志级别:
- OFF:表示关闭全部日志。
- ALL:表示开启全部日志。
Logback的maven依赖
<dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>x.y.z</version>
</dependency>
<dependency><groupId>ch.qos.logback</groupId><artifactId>logback-core</artifactId><version>x.y.z</version>
</dependency>
<dependency><groupId>ch.qos.logback</groupId><artifactId>logback-classic</artifactId><version>x.y.z</version>
</dependency>
Logback的Logger详细介绍
在logback中,可以使用logger元素来定义一个日志输出器。logger元素的设置包括多个属性,其中包括:
- name:指定该logger的名称。
- level:指定该logger的日志级别。
- additivity:指示是否遵循缺省机制。
在additivity属性中,常见的有两种值:
- true:代表遵循缺省机制,即该logger和它的祖先logger都会被输出日志。
- false:代表该logger不遵循缺省机制,只有该logger会输出日志,而其祖先logger不会输出。
在logback中,还有一个特殊的logger,叫做Root Logger,它是所有logger的祖先logger。如果想要改变所有logger的默认行为,可以修改Root Logger的设置。
Root根上下文
使用Root元素可以为logback定义一个日志输出器。
Root元素的属性包括

- name: 定义logger的名字,以便被后文引用
- additivity: 取值为"true"(默认)或"false",用于控制logger是否继承父logger的属性
- level:定义该logger的日志级别,按照从低到高为:All < Trace < Debug < Info < Warn < Error < Fatal < OFF。
- appender-ref:Root的子节点,用于指定该日志输出到哪个Appender,通过ref指定。
Logger
可以使用Logger节点单独指定日志形式。它包括以下属性:
- name:用于指定该Logger所适用的类或者类所在的包全路径,继承自Root节点。
- additivity:用于控制Logger是否继承父Logger的属性。
- level:用于设置日志输出级别,共有8个级别,按照从低到高为:All < Trace < Debug < Info < Warn < Error < Fatal < OFF。
- appender-ref:是Logger的子节点,用来指定该日志输出到哪个Appender。如果没有指定,就会默认继承自Root。如果指定了,日志将会在指定的这个Appender和Root的Appender中都会输出。此时,可以设置Logger的additivity=“false”,只在自定义的Appender中进行输出。
配置案例
<loggers><!--默认的root的logger--><root level="DEBUG"><appender-ref ref="Console"/><appender-ref ref="RollingFileInfo"/><appender-ref ref="RollingFileWarn"/><appender-ref ref="RollingFileError"/><appender-ref ref="RollingFileDebug"/></root><!--额外配置的logger--><!--记录druid-sql的记录--><logger name="druid.sql.Statement" level="debug" additivity="false"><appender-ref ref="druidSqlRollingFile"/></logger><!--log4j2 自带过滤日志--><Logger name="org.apache.catalina.startup.DigesterFactory" level="error" /><Logger name="org.apache.catalina.util.LifecycleBase" level="error" /><Logger name="org.apache.coyote.http11.Http11NioProtocol" level="warn" /><logger name="org.apache.sshd.common.util.SecurityUtils" level="warn"/><Logger name="org.apache.tomcat.util.net.NioSelectorPool" level="warn" /><Logger name="org.crsh.plugin" level="warn" /><logger name="org.crsh.ssh" level="warn"/><Logger name="org.eclipse.jetty.util.component.AbstractLifeCycle" level="error" /><Logger name="org.hibernate.validator.internal.util.Version" level="warn" /><logger name="org.springframework.boot.actuate.autoconfigure.CrshAutoConfiguration" level="warn"/><logger name="org.springframework.boot.actuate.endpoint.jmx" level="warn"/><logger name="org.thymeleaf" level="warn"/>
</loggers>
-
如果logger没有被分配级别,name它将从有被分配级别的最近的父类那里继承级别,root logger默认级别是DEBUG。
-
日志输出的时候,级别大的会输出,根据当前ROOT级别,日志输出时,级别高于root默认的级别时会输出,比如如果root的级别是info,那么会输出info以及info级别以上的日志。
Logback的Filter详细介绍
Logback提供了两类过滤器:Regular Filter和Turbo Filter。
Regular Filter
Regular Filter主要应用于Appender上,并且只在Appender级别起作用。Appender实例上可以绑定一个Regular Filter实例链。Regular Filter继承实现“ch.qos.logback.core.filter.Filter”类,自定义自己的Regular Filter需要继承“ch.qos.logback.core.filter.Filter”类,并实现decide()方法。
Turbo Filter
Turbo Filter对象绑定到日志记录上下文,因此不仅在使用给定的Appender时调用它们,而且每次都会发出日志记录请求。它们的范围比附加到Appender的过滤器更宽。更重要的是,它们在LoggingEvent对象创建之前被调用。Turbo Filter对象不需要实例化日志记录事件来过滤日志记录请求。因此,Turbo Filter旨在用于记录事件的高性能过滤,甚至在创建事件之前。要实现该类型的过滤器需要继承“ch.qos.logback.classic.turbo.TurboFilter”。
常见的过滤器
在logback中,经常使用3种常见的过滤器。

LevelFilter
级别过滤器(Level Filter)根据日志级别进行过滤。当日志级别与配置级别相同时,过滤器根据onMatch和onMismatch属性的配置来接收或拒绝日志事件。
根据精确的级别匹配过滤事件的是LevelFilter。如果事件的级别等于配置的级别,则过滤器接受或拒绝该事件,具体取决于onMatch和onMismatch属性的配置。
属性
<level>:设置过滤级别<onMatch>:用于配置符合过滤条件的操作<onMismatch>:用于配置不符合过滤条件的操作
具体用法介绍
如果日志级别等于配置的级别,在满足onMatch设置的条件时,LevelFilter会接受该日志;反之,在满足onMismatch设置的条件时,LevelFilter会拒绝该日志。
具体案例分析
将过滤器的日志级别配置为INFO,所有等于INFO级别的日志交给appender处理,不等于INFO级别的日志,被过滤掉。
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.LevelFilter"> <level>INFO</level> <onMatch>ACCEPT</onMatch> <onMismatch>DENY</onMismatch>
</filter>
<encoder> <pattern> %-4relative [%thread] %-5level %logger{30} - %msg%n </pattern>
</encoder>
</appender>
EvaluatorFilter
求值过滤器(EventEvaluator)用于评估、鉴别日志是否符合指定条件。它会评估给定的日志事件是否满足设定的条件,如果匹配或不匹配,则托管的EvaluatorFilter将分别返回在onMatch或onMismatch属性中指定的值。
需要注意的是,EventEvaluator是一个抽象类。若想实现自己的事件评估逻辑,可以通过对EventEvaluator进行子类化来实现。
属性
<evaluator>:鉴别器通常用于过滤日志事件,其中常用的鉴别器是JaninoEventEvaluator,并且也是默认的鉴别器。该鉴别器可以接受任意布尔表达式作为条件进行求值,该表达式可以通过配置文件进行解析并动态编译。如果求值条件返回true,则表示该事件符合过滤条件。在配置过程中,鉴别器的表达式可以在子标签中进行配置。<onMatch>:用于配置符合过滤条件的操作<onMismatch>:用于配置不符合过滤条件的操作
具体用法介绍
EvaluatorFilter是求值过滤器,评估、鉴别日志是否符合指定条件。过滤掉所有日志消息中不包含“billing”字符串的日志。
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.core.filter.EvaluatorFilter"> <evaluator> <!-- 默认为 ch.qos.logback.classic.boolex.JaninoEventEvaluator --> <expression>return message.contains("billing");</expression> </evaluator> <OnMatch>ACCEPT </OnMatch> <OnMismatch>DENY</OnMismatch>
</filter>
<encoder> <pattern> %-4relative [%thread] %-5level %logger - %msg%n </pattern>
</encoder>
</appender>
ThresholdFilter
临界值过滤器(ThresholdFilter)用于过滤掉低于指定临界值的日志。如果日志级别等于或高于临界值,则过滤器返回NEUTRAL。反之,如果日志级别低于临界值,则该日志会被拒绝。
需要注意的是,ThresholdFilter会过滤低于指定阈值的事件。对于等于或高于阈值的事件,ThresholdFilter将在调用decision()方法时响应NEUTRAL,但是将拒绝级别低于阈值的事件。
具体用法介绍
过滤掉所有低于INFO级别的日志。
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<!-- 过滤掉 TRACE 和 DEBUG 级别的日志-->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter"> <level>INFO</level>
</filter>
<encoder> <pattern> %-4relative [%thread] %-5level %logger{30} - %msg%n </pattern>
</encoder>
</appender>
本文总结
Logback是一种Java日志框架,可以提供高度可配置的日志记录功能,包括级别控制和事件过滤等功能。它基于SLF4J(Simple Logging Facade for Java)日志抽象层,可以与多种流行的Java日志框架兼容,如Log4j和Java Util Logging。Logback的核心组件包括Logger、Appender和Layout,它们可以协同工作以产生可定制和易于理解的日志输出。Logback支持多种输出形式,例如控制台输出、文件输出等。它还支持异步日志记录和事件过滤器,可以高效地记录大量日志数据,并快速定位和解决问题。Logback还支持动态配置和可插拔式的架构设计,使得它非常易于使用和扩展。作为一种广泛应用于Java应用程序的日志框架,Logback的功能介绍非常重要。
相关文章:
【Logback技术专题】「入门到精通系列教程」深入探索Logback日志框架的原理分析和开发实战技术指南(上篇)
深入探索Logback日志框架的原理分析和开发实战指南系列 Logback日志框架Logback基本模块logback-corelogback-classiclogback-accessLogback的核心类LoggerAppenderLayoutLayout和Appender filterlogback模块和核心所属关系 Logbackj日志级别日志输出级别日志级别介绍 Logback的…...

vue3+element Plus 清空el-tree复选框选中项
前提问题:el-tree加了show-checkbox复选框属性后,在选择完复选框后切换,不会自动清空选中内容,要求在切换时清空复选框选中内容,解决过程:设置el-tree的ref值,使用setCheckedKeys方法可清空复选…...
【VScode】设置语言为中文
1、下载安装好vscode 2、此时可看到页面为英文,为方便使用可切换为中文 3、键盘按下 ctrlshiftP 4、在输入框内输入configure display language 5、选择中文,restart即可(首次会有install安装过程,等待安装成功后重启即可&am…...
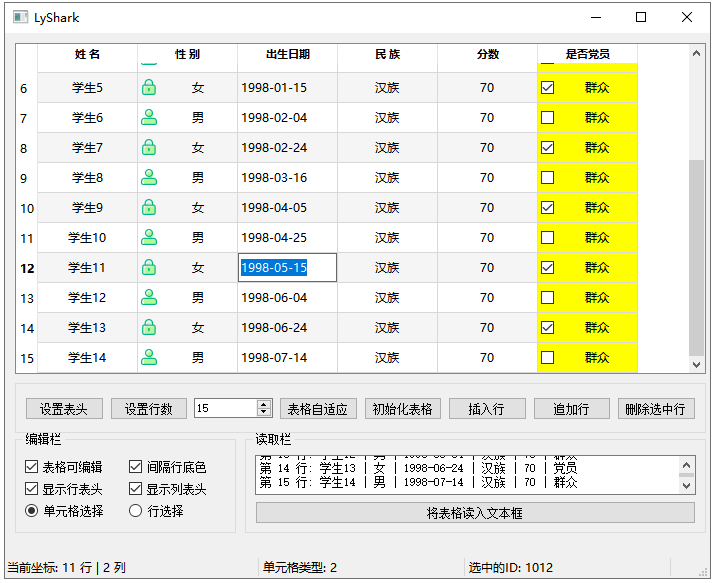
C++ Qt开发:TableWidget表格组件
Qt 是一个跨平台C图形界面开发库,利用Qt可以快速开发跨平台窗体应用程序,在Qt中我们可以通过拖拽的方式将不同组件放到指定的位置,实现图形化开发极大的方便了开发效率,本章将重点介绍TableWidget表格组件的常用方法及灵活运用。 …...
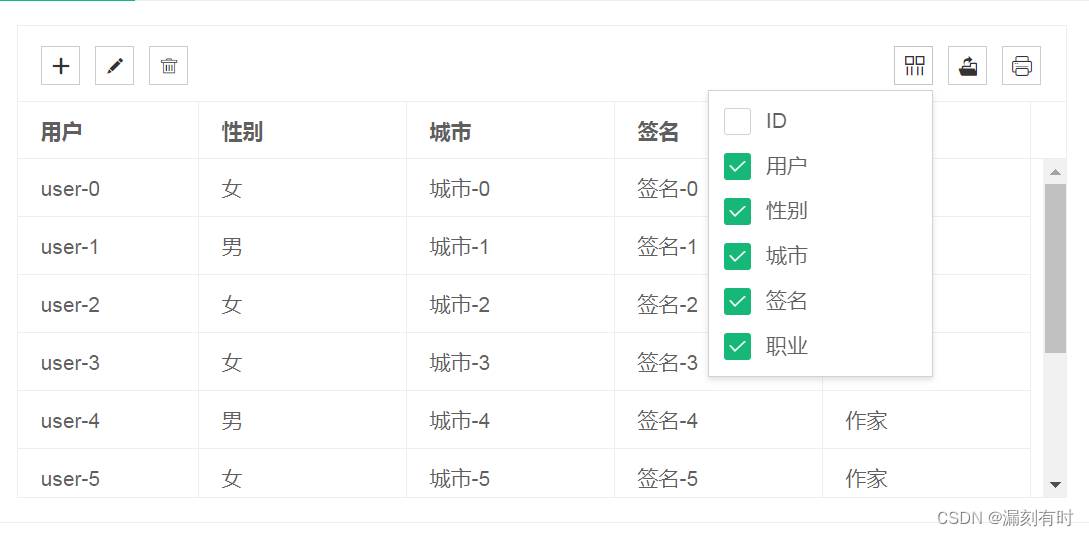
layui框架实战案例(25):table组件筛选列记忆功能
即点击当前表格右上角筛选图标后,对表头进行显示隐藏勾选,再刷新页面依然保留当前筛选状态。 要实现layui表格组件的筛选列记忆功能,可以采取以下步骤: 存储筛选数据:当用户进行筛选操作时,将筛选的数据…...

20、WEB攻防——PHP特性缺陷对比函数CTF考点CMS审计实例
文章目录 一、PHP常用过滤函数:1.1 与1.2 md51.3 intval1.4 strpos1.5 in_array1.6 preg_match1.7 str_replace CTFshow演示三、参考资料 一、PHP常用过滤函数: 1.1 与 :弱类型对比(不考虑数据类型),甚至…...

互换数组的两个轴 numpy.swapaxes()
【小白从小学Python、C、Java】 【计算机等考500强证书考研】 【Python-数据分析】 互换数组的两个轴 numpy.swapaxes() 选择题 请问下列程序运行的的结果是: import numpy as np arr1 np.array([[11,12],[21,22]]).reshape((2,2)) print("【显示】arr1:\n…...
金蝶云星空修改业务对象标识
文章目录 金蝶云星空修改业务对象标识说明解决方案具体操作实操 金蝶云星空修改业务对象标识 说明 一个业务对象的产生,涉及10个表起。 解决方案 还是手工删除重新创建保险。 具体操作 先备份需要删除的元数据,或者扩展,然后重新创建或…...
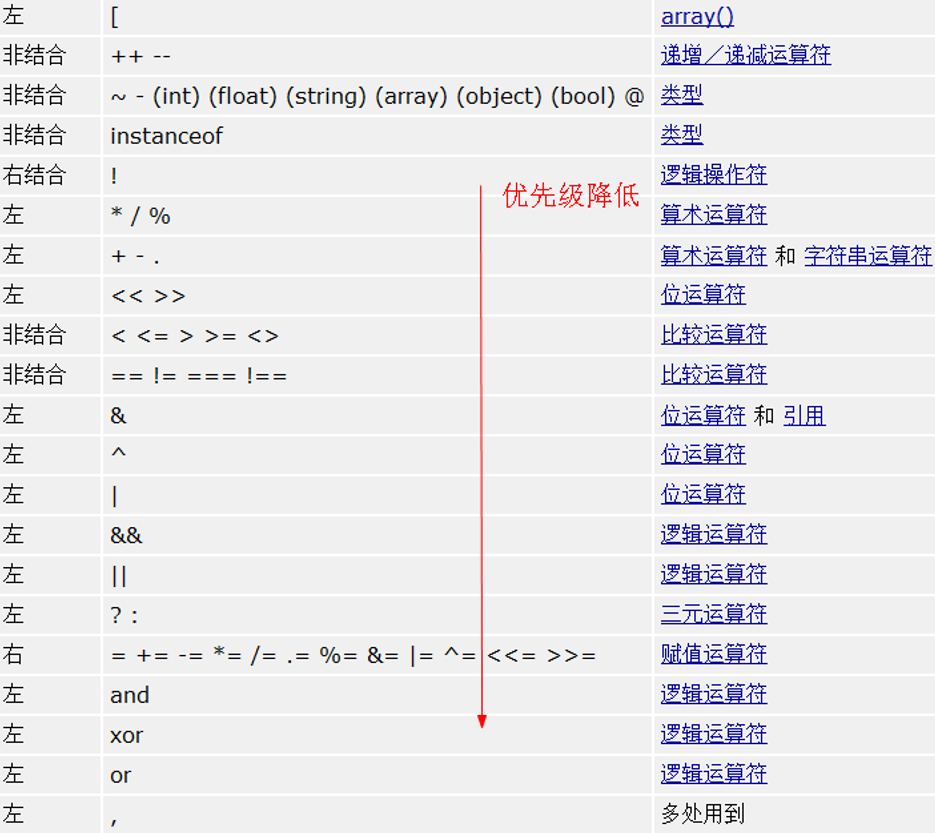
【PHP入门】2.1-运算符
-运算符- 运算符:operator,是一种将数据进行运算的特殊符号,在PHP中一共有十种运算符之多。 2.1.1赋值运算符 赋值运算:符号是“”,表示将右边的结果(可以是变量、数据、常量和其它运算出来的结果&#…...

【Hive】——DML
1 Load(加载数据) 1.1 概述 1.2 语法 LOAD DATA [LOCAL] INPATH filepath [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1val1, partcol2val2 ...)]LOAD DATA [LOCAL] INPATH filepath [OVERWRITE] INTO TABLE tablename [PARTITION (partcol…...
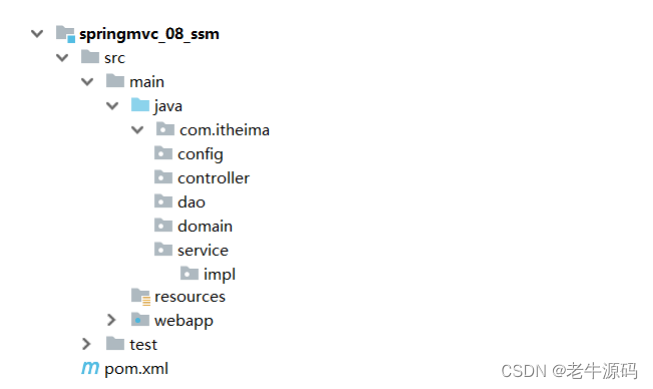
【Spring教程31】SSM框架整合实战:从零开始学习SSM整合配置,如何编写Mybatis SpringMVC JDBC Spring配置类
目录 1 流程分析2 整合配置2.1 步骤1:创建Maven的web项目2.2 步骤2:添加依赖2.3 步骤3:创建项目包结构2.4 步骤4:创建SpringConfig配置类2.5 步骤5:创建JdbcConfig配置类2.6 步骤6:创建MybatisConfig配置类2.7 步骤7:创建jdbc.properties2.8 步骤8:创建SpringMVC配置…...

Tailwind CSS 入门
什么是 Tailwind CSS? Tailwind CSS 是一个 CSS 框架,它提供了大量的预定义实用类,可以用来快速构建 HTML 页面。Tailwind CSS 的优势包括: 可扩展性:Tailwind CSS 的类库是可扩展的,可以根据自己的需要进行定制。性能:Tailwind CSS 的类库是经过精心设计的,可以提高页…...

如何在简历中解释就业空白
您的工作经历有空缺吗?你不是一个人。有很多合理的理由可以解释为什么你需要休息一下。更重要的是,在一份真实正确的简历中,这些问题是无法避免的。直接解释就业差距总是更好,而且有很多因素需要考虑。你未来的老板想要了解工作轨…...
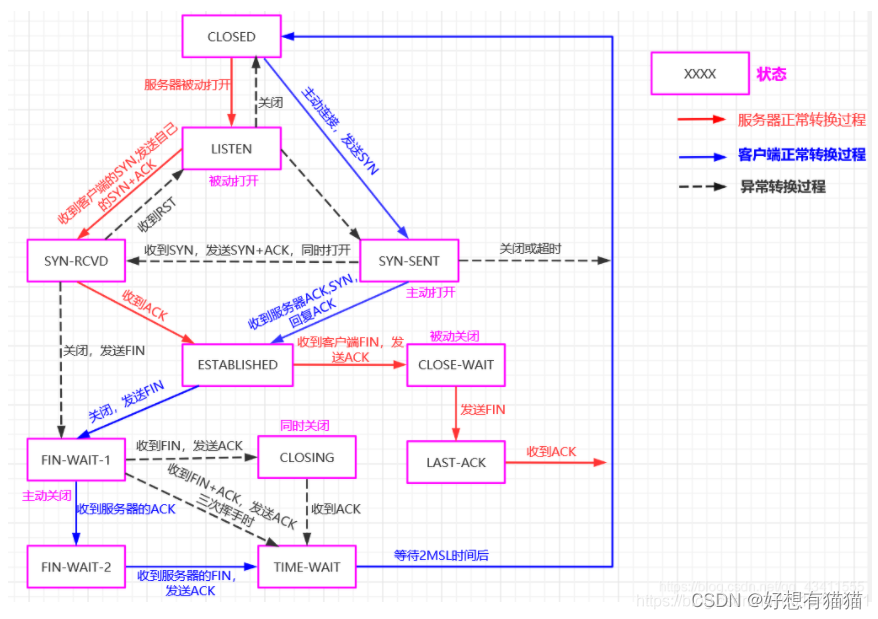
【计算机网络】TCP协议——2.连接管理(三次握手,四次挥手)
目录 前言 一. 建立连接——三次握手 1. 三次握手过程描述 2. TCP连接建立相关问题 二. 释放连接——四次挥手 1. 四次挥手过程描述 2. TCP连接释放相关问题 三. TCP状态转换 结束语 前言 TCP——传输控制协议(Transmission Control Protocol)。是一种面向连接的传…...

螺丝厂家:如何根据您的需求找到合适您的紧固件
螺丝是通用工具。它们几乎用于所有场景,并且它们的使用不限于任何一个行业。人们可以找到几乎所有周围都使用的螺钉和螺栓。在为工作选择合适的螺丝方面,人们应该记住一些事情。选择标准归结为紧固件的物理特性,包括制造它所用的原材料、施加…...

企业数字化转型进入深海区:生成式AI时代下如何制定数据战略
随着科技的不断进步,企业数字化转型已经不再是简单的概念,而是正在进入一个全新的深海区。在这个深海区,数据变得至关重要,而生成式人工智能(AI)的兴起更是推动了数字化转型的飞速发展。本文将探讨在这个生…...

html行内元素和块级元素的区别?
HTML中的元素可以分为两种类型:行内元素(inline)和块级元素(block) 文章目录 什么是行内元素什么是块级元素元素转换行内元素转块级元素块级元素转行内元素 区别总结 什么是行内元素 HTML的行内元素(inli…...

ResNet 原论文及原作者讲解
ResNet 论文摘要1. 引入2. 相关工作残差表示快捷连接 3. 深度残差学习3.1. 残差学习3.2. 快捷恒等映射3.3. 网络体系结构普通网络 plain network残差网络 residual network 3.4. 实施 4. 实验4.1. ImageNet分类普通的网络 plain network残差网络 residual network恒等vs.快捷连…...

liteflow规则引擎 执行Groovy脚本
在LiteFlow规则引擎中执行Groovy脚本的步骤相对简单。首先,确保你的项目中包含了LiteFlow的相关依赖。接下来,创建一个Groovy脚本规则,并使用LiteFlow引擎执行它。 以下是一个简单的示例: 添加LiteFlow依赖:在你的项…...
GZ015 机器人系统集成应用技术样题5-学生赛
2023年全国职业院校技能大赛 高职组“机器人系统集成应用技术”赛项 竞赛任务书(学生赛) 样题5 选手须知: 本任务书共 24页,如出现任务书缺页、字迹不清等问题,请及时向裁判示意,并进行任务书的更换。参赛队…...
实战XSS:从标签事件到高级Payload的攻防演练)
Pikachu(皮卡丘靶场)实战XSS:从标签事件到高级Payload的攻防演练
1. 初识XSS与Pikachu靶场环境搭建 跨站脚本攻击(XSS)就像在别人的网页里偷偷塞小纸条,当其他用户打开这个网页时,小纸条上的内容就会被浏览器执行。想象一下,你在图书馆的公共留言板上贴了一张看似普通的便利贴&#x…...

Hermes Agent 连接 Taotoken 自定义供应商的配置要点与排错
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent 连接 Taotoken 自定义供应商的配置要点与排错 基础教程类,指导 Hermes Agent 用户按照文档要求ÿ…...

DDrawCompat:让经典DirectX游戏在现代Windows系统上重获新生的兼容神器
DDrawCompat:让经典DirectX游戏在现代Windows系统上重获新生的兼容神器 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_m…...

2026实测:能耗管控场景下的AI工具数据分析能力横向对比,实在Agent如何通过ISSUT打破数据孤岛?
【摘要】 步入2026年,全球能源结构转型进入深水区。随着数据中心耗电量突破1000太瓦时(TWh)以及工业领域对“双碳”目标的刚性对标,能耗管控场景已成为企业运营的战略核心。然而,企业在推进自动化能效管理时࿰…...
)
用Python和OpenCV手把手教你搞定自动驾驶图像坐标系转换(附NuScenes数据集实战代码)
用Python和OpenCV手把手教你搞定自动驾驶图像坐标系转换(附NuScenes数据集实战代码) 自动驾驶技术的核心在于让车辆"看懂"周围环境,而坐标系转换正是连接物理世界与数字世界的桥梁。想象一下,当一辆自动驾驶汽车行驶在…...

Codesys ST语言PID调参避坑指南:从仿真到实战,手把手教你搞定温控/电机项目
Codesys ST语言PID调参避坑指南:从仿真到实战的工程化解决方案 在工业自动化领域,PID控制算法占据着核心地位。无论是恒温控制、电机调速还是压力调节,一个精心调校的PID控制器往往能决定整个系统的性能表现。然而,许多工程师在掌…...

技能工程化框架:从标准化定义到编排实战
1. 项目概述:从“技能”到“智能”的工程化桥梁在当今的软件开发领域,尤其是涉及复杂交互和自动化流程的场景,我们常常会听到“技能”这个词。它听起来很抽象,但如果你拆解过任何一款智能助手、自动化机器人或者一个大型的业务流程…...

猫抓插件:5分钟掌握浏览器资源嗅探的终极武器
猫抓插件:5分钟掌握浏览器资源嗅探的终极武器 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字内容无处不在的今天,你…...

技术解构:逆向工程视角下的百度网盘下载链接解析机制
技术解构:逆向工程视角下的百度网盘下载链接解析机制 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 想象一下,当你收到朋友分享的百度网盘链接时&…...

全域态势数字孪生,筑牢楼宇长效安全透明防护屏障
全域态势数字孪生,筑牢楼宇长效安全透明防护屏障副标题:全要素三维动态实时复刻楼宇实景,依托无感全域人员感知、多机位跨镜联动追踪、身体指纹唯一身份归档,异常行为、区域滞留、安全隐患提前透明预警处置一、方案概述伴随城市高…...