深度学习 Day19——P8YOLOv5-C3模块实现
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
文章目录
- 前言
- 1 我的环境
- 2 代码实现与执行结果
- 2.1 前期准备
- 2.1.1 引入库
- 2.1.2 设置GPU(如果设备上支持GPU就使用GPU,否则使用CPU)
- 2.1.3 导入数据
- 2.1.4 可视化数据
- 2.1.4 图像数据变换
- 2.1.4 划分数据集
- 2.1.4 加载数据
- 2.1.4 查看数据
- 2.2 构建yolov5-C3网络模型
- 2.3 训练模型
- 2.3.1 设置超参数
- 2.3.2 编写训练函数
- 2.3.3 编写测试函数
- 2.3.4 正式训练
- 2.4 结果可视化
- 2.4 指定图片进行预测
- 2.6 模型评估
- 3 知识点详解
- 3.1 YOLOv5详解
- 3.1.1 YOLOv5算法概述
- 3.1.2 YOLOv5算法基本原理
- 3.1.3 特点
- 3.1.4 YOLOv5模型结构
- 3.1.5 Backbone骨干网络
- 3.1.5.1 Focus模块
- 3.1.5.1 Conv模块
- 3.1.5.2 C3模块
- 3.1.5.2 SPPF模块
- 3.1.6 Neck特征金字塔
- 3.1.7 Head目标检测头
- 3.1.8 YOLOv5总结
- 总结
前言
本文将采用pytorch框架创建YOLOv5-C3模块实现天气识别。讲述实现代码与执行结果,并浅谈涉及知识点。
关键字: YOLOV5 C3
1 我的环境
- 电脑系统:Windows 11
- 语言环境:python 3.8.6
- 编译器:pycharm2020.2.3
- 深度学习环境:
torch == 1.9.1+cu111
torchvision == 0.10.1+cu111 - 显卡:NVIDIA GeForce RTX 4070
2 代码实现与执行结果
2.1 前期准备
2.1.1 引入库
import torch
import torch.nn as nn
from torchvision import transforms, datasets
import time
from pathlib import Path
from PIL import Image
import torchsummary as summary
import torch.nn.functional as Fimport copy
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率
import warningswarnings.filterwarnings('ignore') # 忽略一些warning内容,无需打印2.1.2 设置GPU(如果设备上支持GPU就使用GPU,否则使用CPU)
"""前期准备-设置GPU"""
# 如果设备上支持GPU就使用GPU,否则使用CPUdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")print("Using {} device".format(device))
输出
Using cuda device
2.1.3 导入数据
'''前期工作-导入数据'''
data_dir = r"D:\DeepLearning\data\CoffeeBean"
data_dir = Path(data_dir)data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[-1] for path in data_paths]
print(classeNames)
输出
['cloudy', 'rain', 'shine', 'sunrise']2.1.4 可视化数据
'''前期工作-可视化数据'''subfolder = Path(data_dir)/"Angelina Jolie"image_files = list(p.resolve() for p in subfolder.glob('*') if p.suffix in [".jpg", ".png", ".jpeg"])plt.figure(figsize=(10, 6))for i in range(len(image_files[:12])):image_file = image_files[i]ax = plt.subplot(3, 4, i + 1)img = Image.open(str(image_file))plt.imshow(img)plt.axis("off")# 显示图片plt.tight_layout()plt.show()

2.1.4 图像数据变换
'''前期工作-图像数据变换'''
total_datadir = data_dir# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder(total_datadir, transform=train_transforms)
print(total_data)
print(total_data.class_to_idx)
输出
Dataset ImageFolderNumber of datapoints: 1125Root location: D:\DeepLearning\data\weather_photosStandardTransform
Transform: Compose(Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=None)ToTensor()Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]))
{'cloudy': 0, 'rain': 1, 'shine': 2, 'sunrise': 3}2.1.4 划分数据集
'''前期工作-划分数据集'''
train_size = int(0.8 * len(total_data)) # train_size表示训练集大小,通过将总体数据长度的80%转换为整数得到;
test_size = len(total_data) - train_size # test_size表示测试集大小,是总体数据长度减去训练集大小。
# 使用torch.utils.data.random_split()方法进行数据集划分。该方法将总体数据total_data按照指定的大小比例([train_size, test_size])随机划分为训练集和测试集,
# 并将划分结果分别赋值给train_dataset和test_dataset两个变量。
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print("train_dataset={}\ntest_dataset={}".format(train_dataset, test_dataset))
print("train_size={}\ntest_size={}".format(train_size, test_size))
输出
train_dataset=<torch.utils.data.dataset.Subset object at 0x0000020A3A209730>
test_dataset=<torch.utils.data.dataset.Subset object at 0x0000020A3A209BB0>
train_size=900
test_size=225
2.1.4 加载数据
'''前期工作-加载数据'''
batch_size = 32train_dl = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=1)
2.1.4 查看数据
'''前期工作-查看数据'''
for X, y in test_dl:print("Shape of X [N, C, H, W]: ", X.shape)print("Shape of y: ", y.shape, y.dtype)break
输出
Shape of X [N, C, H, W]: torch.Size([32, 3, 224, 224])
Shape of y: torch.Size([32]) torch.int64
2.2 构建yolov5-C3网络模型
import torch.nn.functional as Fdef autopad(k, p=None): # kernel, padding# Pad to 'same'if p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):# Standard convolutiondef __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groupssuper().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())def forward(self, x):return self.act(self.bn(self.conv(x)))class Bottleneck(nn.Module):# Standard bottleneckdef __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_, c2, 3, 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class C3(nn.Module):# CSP Bottleneck with 3 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))class model_K(nn.Module):def __init__(self):super(model_K, self).__init__()# 卷积模块self.Conv = Conv(3, 32, 3, 2) # C3模块1self.C3_1 = C3(32, 64, 3, 2)# 全连接网络层,用于分类self.classifier = nn.Sequential(nn.Linear(in_features=802816, out_features=100),nn.ReLU(),nn.Linear(in_features=100, out_features=4))def forward(self, x):x = self.Conv(x)x = self.C3_1(x)x = torch.flatten(x, start_dim=1)x = self.classifier(x)return xdevice = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))model = model_K().to(device)
print(summary.summary(model, (3, 224, 224)))#查看模型的参数量以及相关指标输出
----------------------------------------------------------------Layer (type) Output Shape Param #
================================================================Conv2d-1 [-1, 32, 112, 112] 864BatchNorm2d-2 [-1, 32, 112, 112] 64SiLU-3 [-1, 32, 112, 112] 0Conv-4 [-1, 32, 112, 112] 0Conv2d-5 [-1, 32, 112, 112] 1,024BatchNorm2d-6 [-1, 32, 112, 112] 64SiLU-7 [-1, 32, 112, 112] 0Conv-8 [-1, 32, 112, 112] 0Conv2d-9 [-1, 32, 112, 112] 1,024BatchNorm2d-10 [-1, 32, 112, 112] 64SiLU-11 [-1, 32, 112, 112] 0Conv-12 [-1, 32, 112, 112] 0Conv2d-13 [-1, 32, 112, 112] 9,216BatchNorm2d-14 [-1, 32, 112, 112] 64SiLU-15 [-1, 32, 112, 112] 0Conv-16 [-1, 32, 112, 112] 0Bottleneck-17 [-1, 32, 112, 112] 0Conv2d-18 [-1, 32, 112, 112] 1,024BatchNorm2d-19 [-1, 32, 112, 112] 64SiLU-20 [-1, 32, 112, 112] 0Conv-21 [-1, 32, 112, 112] 0Conv2d-22 [-1, 32, 112, 112] 9,216BatchNorm2d-23 [-1, 32, 112, 112] 64SiLU-24 [-1, 32, 112, 112] 0Conv-25 [-1, 32, 112, 112] 0Bottleneck-26 [-1, 32, 112, 112] 0Conv2d-27 [-1, 32, 112, 112] 1,024BatchNorm2d-28 [-1, 32, 112, 112] 64SiLU-29 [-1, 32, 112, 112] 0Conv-30 [-1, 32, 112, 112] 0Conv2d-31 [-1, 32, 112, 112] 9,216BatchNorm2d-32 [-1, 32, 112, 112] 64SiLU-33 [-1, 32, 112, 112] 0Conv-34 [-1, 32, 112, 112] 0Bottleneck-35 [-1, 32, 112, 112] 0Conv2d-36 [-1, 32, 112, 112] 1,024BatchNorm2d-37 [-1, 32, 112, 112] 64SiLU-38 [-1, 32, 112, 112] 0Conv-39 [-1, 32, 112, 112] 0Conv2d-40 [-1, 64, 112, 112] 4,096BatchNorm2d-41 [-1, 64, 112, 112] 128SiLU-42 [-1, 64, 112, 112] 0Conv-43 [-1, 64, 112, 112] 0C3-44 [-1, 64, 112, 112] 0Linear-45 [-1, 100] 80,281,700ReLU-46 [-1, 100] 0Linear-47 [-1, 4] 404
================================================================
Total params: 80,320,536
Trainable params: 80,320,536
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 150.06
Params size (MB): 306.40
Estimated Total Size (MB): 457.04
----------------------------------------------------------------2.3 训练模型
2.3.1 设置超参数
"""训练模型--设置超参数"""
loss_fn = nn.CrossEntropyLoss() # 创建损失函数,计算实际输出和真实相差多少,交叉熵损失函数,事实上,它就是做图片分类任务时常用的损失函数
learn_rate = 1e-4 # 学习率
optimizer1 = torch.optim.SGD(model.parameters(), lr=learn_rate)# 作用是定义优化器,用来训练时候优化模型参数;其中,SGD表示随机梯度下降,用于控制实际输出y与真实y之间的相差有多大
optimizer2 = torch.optim.Adam(model.parameters(), lr=learn_rate)
lr_opt = optimizer2
model_opt = optimizer2
# 调用官方动态学习率接口时使用2
lambda1 = lambda epoch : 0.92 ** (epoch // 4)
# optimizer = torch.optim.SGD(model.parameters(), lr=learn_rate)
scheduler = torch.optim.lr_scheduler.LambdaLR(lr_opt, lr_lambda=lambda1) #选定调整方法2.3.2 编写训练函数
"""训练模型--编写训练函数"""
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小,一共60000张图片num_batches = len(dataloader) # 批次数目,1875(60000/32)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 加载数据加载器,得到里面的 X(图片数据)和 y(真实标签)X, y = X.to(device), y.to(device) # 用于将数据存到显卡# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # 清空过往梯度loss.backward() # 反向传播,计算当前梯度optimizer.step() # 根据梯度更新网络参数# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_loss
2.3.3 编写测试函数
"""训练模型--编写测试函数"""
# 测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器
def test(dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小,一共10000张图片num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad(): # 测试时模型参数不用更新,所以 no_grad,整个模型参数正向推就ok,不反向更新参数for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()#统计预测正确的个数test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_loss2.3.4 正式训练
"""训练模型--正式训练"""
epochs = 40
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_test_acc=0for epoch in range(epochs):milliseconds_t1 = int(time.time() * 1000)# 更新学习率(使用自定义学习率时使用)# adjust_learning_rate(lr_opt, epoch, learn_rate)model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, model_opt)scheduler.step() # 更新学习率(调用官方动态学习率接口时使用)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)# 获取当前的学习率lr = lr_opt.state_dict()['param_groups'][0]['lr']milliseconds_t2 = int(time.time() * 1000)template = ('Epoch:{:2d}, duration:{}ms, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}, Lr:{:.2E}')if best_test_acc < epoch_test_acc:best_test_acc = epoch_test_acc#备份最好的模型best_model = copy.deepcopy(model)template = ('Epoch:{:2d}, duration:{}ms, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}, Lr:{:.2E},Update the best model')print(template.format(epoch + 1, milliseconds_t2-milliseconds_t1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss, lr))
# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)
print('Done')
输出最高精度为Test_acc:42.5%
Epoch: 1, duration:8711ms, Train_acc:77.8%, Train_loss:1.207, Test_acc:55.6%,Test_loss:1.484, Lr:1.00E-04,Update the best model
Epoch: 2, duration:7423ms, Train_acc:87.8%, Train_loss:0.400, Test_acc:74.7%,Test_loss:0.999, Lr:1.00E-04,Update the best model
Epoch: 3, duration:7113ms, Train_acc:92.4%, Train_loss:0.241, Test_acc:88.4%,Test_loss:0.343, Lr:1.00E-04,Update the best model
Epoch: 4, duration:7393ms, Train_acc:98.1%, Train_loss:0.059, Test_acc:89.3%,Test_loss:0.316, Lr:9.20E-05,Update the best model
Epoch: 5, duration:7734ms, Train_acc:99.0%, Train_loss:0.048, Test_acc:88.4%,Test_loss:0.393, Lr:9.20E-05
Epoch: 6, duration:7802ms, Train_acc:98.4%, Train_loss:0.080, Test_acc:85.8%,Test_loss:0.395, Lr:9.20E-05
Epoch: 7, duration:8622ms, Train_acc:94.9%, Train_loss:0.159, Test_acc:85.8%,Test_loss:0.466, Lr:9.20E-05
Epoch: 8, duration:7842ms, Train_acc:97.8%, Train_loss:0.067, Test_acc:87.1%,Test_loss:0.385, Lr:8.46E-05
Epoch: 9, duration:7179ms, Train_acc:99.2%, Train_loss:0.029, Test_acc:88.0%,Test_loss:0.359, Lr:8.46E-05
Epoch:10, duration:7072ms, Train_acc:99.9%, Train_loss:0.011, Test_acc:90.2%,Test_loss:0.294, Lr:8.46E-05,Update the best model
Epoch:11, duration:7350ms, Train_acc:99.9%, Train_loss:0.006, Test_acc:89.8%,Test_loss:0.300, Lr:8.46E-05
Epoch:12, duration:7111ms, Train_acc:99.8%, Train_loss:0.024, Test_acc:91.1%,Test_loss:0.677, Lr:7.79E-05,Update the best model
Epoch:13, duration:7521ms, Train_acc:99.7%, Train_loss:0.015, Test_acc:89.8%,Test_loss:0.356, Lr:7.79E-05
Epoch:14, duration:7089ms, Train_acc:99.8%, Train_loss:0.018, Test_acc:90.7%,Test_loss:0.344, Lr:7.79E-05
Epoch:15, duration:7102ms, Train_acc:99.1%, Train_loss:0.049, Test_acc:88.4%,Test_loss:0.479, Lr:7.79E-05
Epoch:16, duration:6926ms, Train_acc:99.7%, Train_loss:0.014, Test_acc:91.6%,Test_loss:2.172, Lr:7.16E-05,Update the best model
Epoch:17, duration:6975ms, Train_acc:99.7%, Train_loss:0.014, Test_acc:92.0%,Test_loss:0.353, Lr:7.16E-05,Update the best model
Epoch:18, duration:7112ms, Train_acc:99.6%, Train_loss:0.196, Test_acc:89.3%,Test_loss:0.447, Lr:7.16E-05
Epoch:19, duration:7393ms, Train_acc:98.3%, Train_loss:0.059, Test_acc:86.7%,Test_loss:0.827, Lr:7.16E-05
Epoch:20, duration:7197ms, Train_acc:99.2%, Train_loss:0.013, Test_acc:90.2%,Test_loss:0.558, Lr:6.59E-052.4 结果可视化
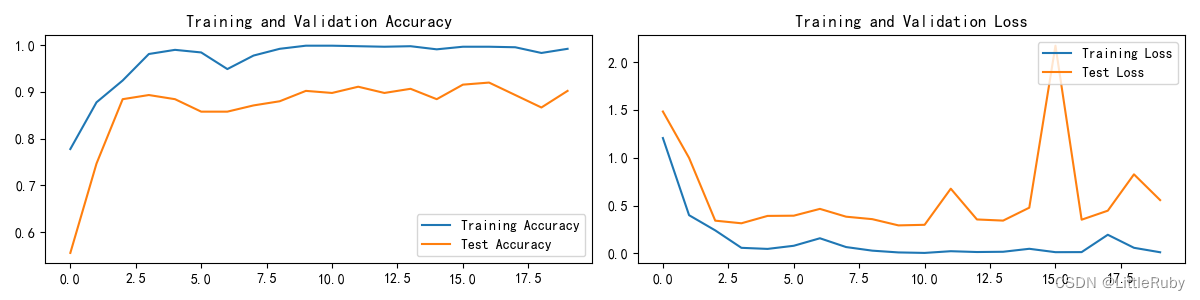
"""训练模型--结果可视化"""
epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
2.4 指定图片进行预测
def predict_one_image(image_path, model, transform, classes):test_img = Image.open(image_path).convert('RGB')plt.imshow(test_img) # 展示预测的图片plt.show()test_img = transform(test_img)img = test_img.to(device).unsqueeze(0)model.eval()output = model(img)_, pred = torch.max(output, 1)pred_class = classes[pred]print(f'预测结果是:{pred_class}')# 将参数加载到model当中
model.load_state_dict(torch.load(PATH, map_location=device))"""指定图片进行预测"""
classes = list(total_data.class_to_idx)
# 预测训练集中的某张照片
predict_one_image(image_path=str(Path(data_dir)/"Dark/dark (1).png"),model=model,transform=train_transforms,classes=classes)

输出
预测结果是:cloudy
2.6 模型评估
"""模型评估"""
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
# 查看是否与我们记录的最高准确率一致
print(epoch_test_acc, epoch_test_loss)输出
0.92 0.35305984411388636
3 知识点详解
3.1 YOLOv5详解
3.1.1 YOLOv5算法概述
Yolov5是一种目标检测算法,采用基于Anchor的检测方式,属于单阶段目标检测方法。相比于Yolov4,Yolov5有着更快的速度和更高的精度,是目前业界领先的目标检测算法之一。
3.1.2 YOLOv5算法基本原理
Yolov5基于目标检测算法中的one-stage方法,其主要思路是将整张图像划分为若干个网格,每个网格预测出该网格内物体的种类和位置信息,然后根据预测框与真实框之间的IoU值进行目标框的筛选,最终输出预测框的类别和位置信息。
3.1.3 特点
Yolov5具有以下几个特点:
高效性:相比于其他目标检测算法,Yolov5在保证高精度的前提下,速度更快,尤其是在GPU环境下可以实现实时检测。
精度高:通过使用多尺度预测和CIoU loss等机制,Yolov5可以提高目标检测的精度。
易用性强:Yolov5开源且易于使用,提供了PyTorch版本和ONNX版本,可以在不同的硬件上运行。
Yolov5可以应用于各种实际场景中的目标检测任务,例如物体检测、人脸检测、交通标志检测、动物检测等等。
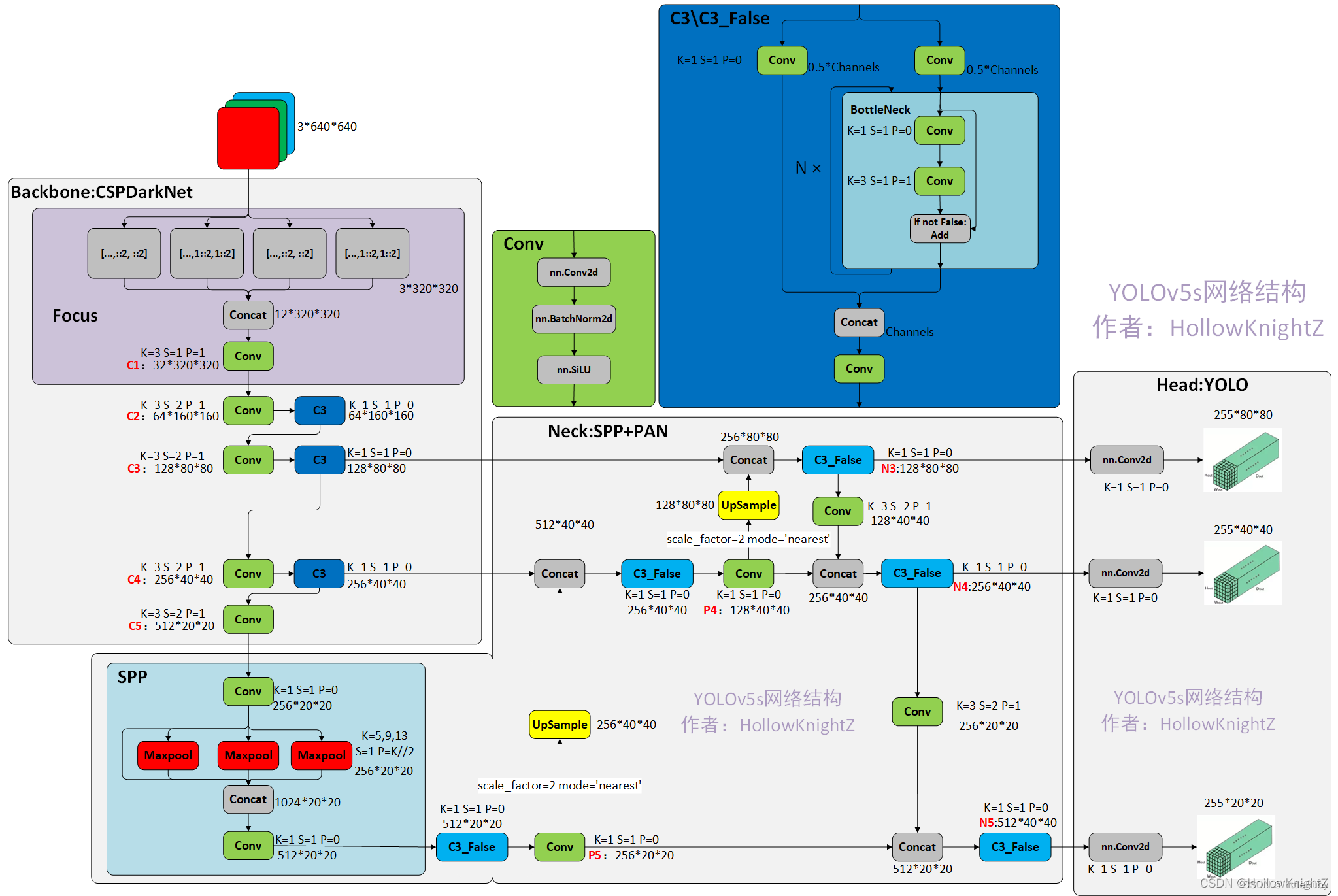
3.1.4 YOLOv5模型结构
yolov5有五个版本:yolov5s、yolov5m、yolov5l、yolov5x和yolov5nano。其中,yolov5s是最小的版本,yolov5x是最大的版本。它们的区别在于网络的深度、宽度和参数量等方面。
下面以yolov5s为模板详解yolov5。其具有较高的精度和较快的检测速度,同时参数量更少。
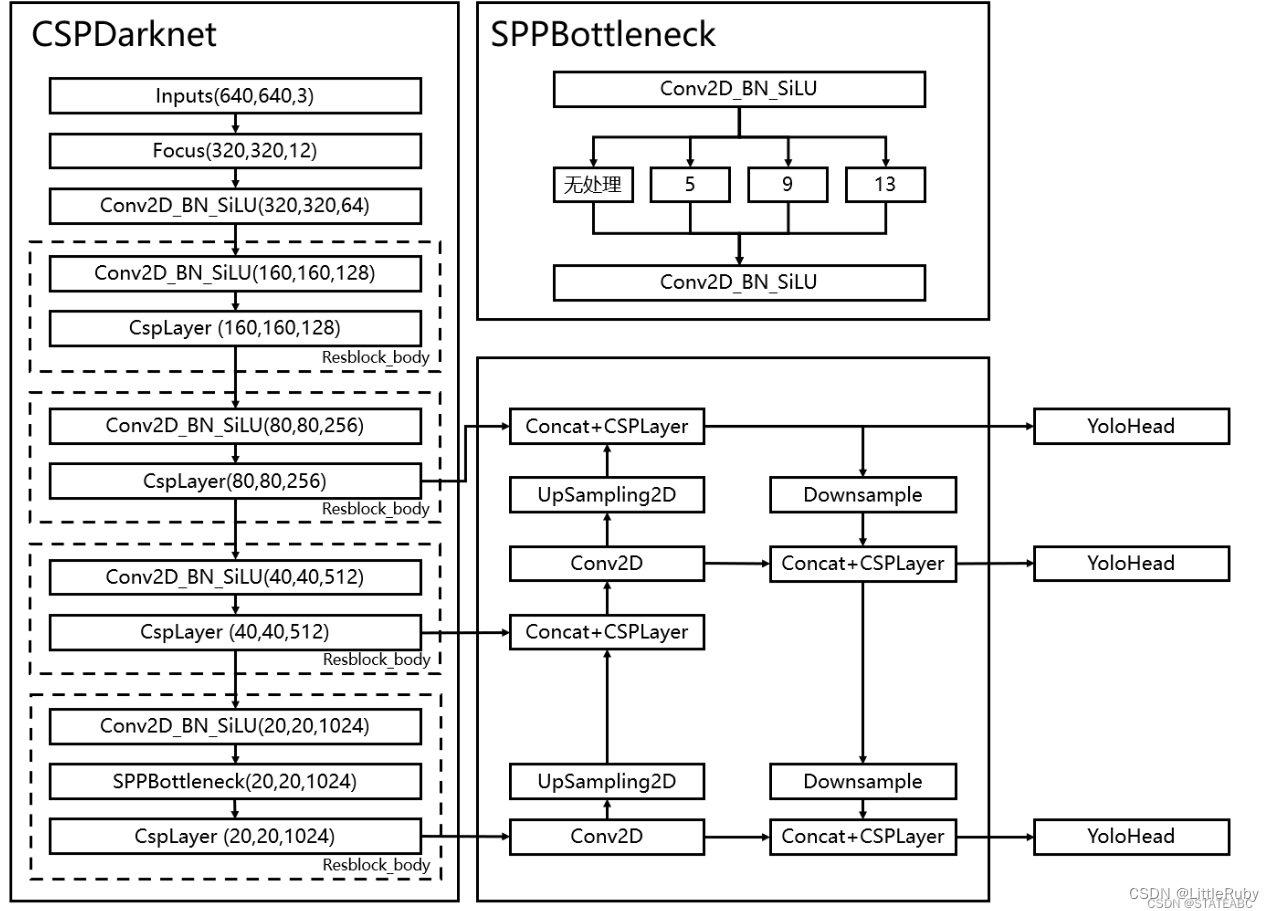
YOLOv5s 模型主要由 Backbone、Neck 和Head 三部分组成,网络模型见下图。其中:
Backbone 主要负责对输入图像进行特征提取。
Neck 负责对特征图进行多尺度特征融合,并把这些特征传递给预测层。
Head 进行最终的回归预测。
3.1.5 Backbone骨干网络
骨干网络是指用来提取图像特征的网络,它的主要作用是将原始的输入图像转化为多层特征图,以便后续的目标检测任务使用。在Yolov5中,使用的是CSPDarknet53或ResNet骨干网络,这两个网络都是相对轻量级的,能够在保证较高检测精度的同时,尽可能地减少计算量和内存占用。
Backbone中的主要结构有Conv模块、C3模块、SPPF模块。
3.1.5.1 Focus模块
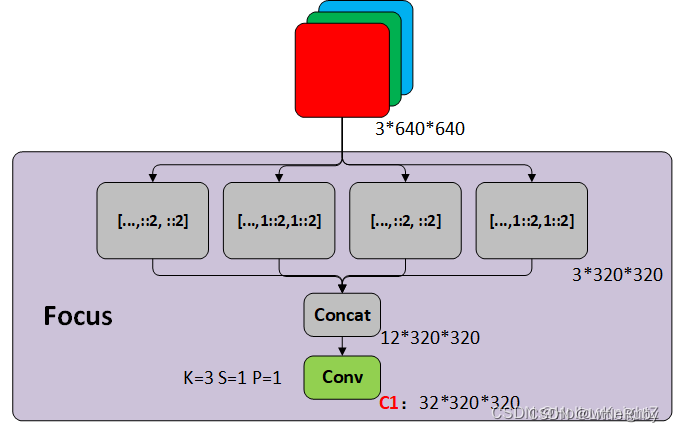 从卷积的过程上来看如下所示:
从卷积的过程上来看如下所示:
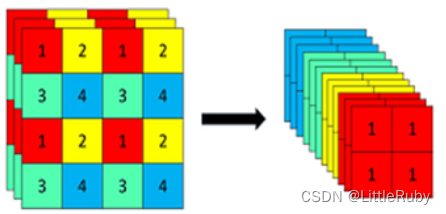
Focus模块将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map,然后在接上一个3x3大小的卷积层。YOLOv5在v6.0版本后相比之前版本有一个很小的改动,把网络的第一层(原来是Focus模块)换成了一个6x6大小的卷积层。两者在理论上其实等价的,但是对于现有的一些GPU设备(以及相应的优化算法)使用6x6大小的卷积层比使用Focus模块更加高效。
3.1.5.1 Conv模块
Conv模块是卷积神经网络中常用的一种基础模块,它主要由卷积层、BN层和激活函数组成。下面对这些组成部分进行详细解析。
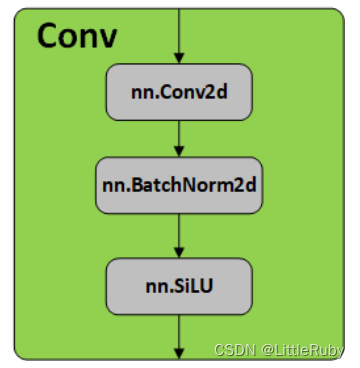
- 卷积层是卷积神经网络中最基础的层之一,用于提取输入特征中的局部空间信息。卷积操作可以看作是一个滑动窗口,窗口在输入特征上滑动,并将窗口内的特征值与卷积核进行卷积操作,从而得到输出特征。卷积层通常由多个卷积核组成,每个卷积核对应一个输出通道。卷积核的大小、步长、填充方式等超参数决定了卷积层的输出大小和感受野大小。卷积神经网络中,卷积层通常被用来构建特征提取器。
- BN层是在卷积层之后加入的一种归一化层,用于规范化神经网络中的特征值分布。它可以加速训练过程,提高模型泛化能力,减轻模型对初始化的依赖性。BN层的输入为一个batch的特征图,它将每个通道上的特征进行均值和方差的计算,并对每个通道上的特征进行标准化处理。标准化后的特征再通过一个可学习的仿射变换(拉伸和偏移)进行还原,从而得到BN层的输出。
- 激活函数是一种非线性函数,用于给神经网络引入非线性变换能力。常用的激活函数包括sigmoid、ReLU、LeakyReLU、ELU等。它们在输入值的不同范围内都有不同的输出表现,可以更好地适应不同类型的数据分布。其中SiLU (x)=x∗ sigmoid(x)。
综上所述,Conv模块是卷积神经网络中常用的基础模块,它通过卷积操作提取局部空间信息,并通过BN层规范化特征值分布,最后通过激活函数引入非线性变换能力,从而实现对输入特征的转换和提取。
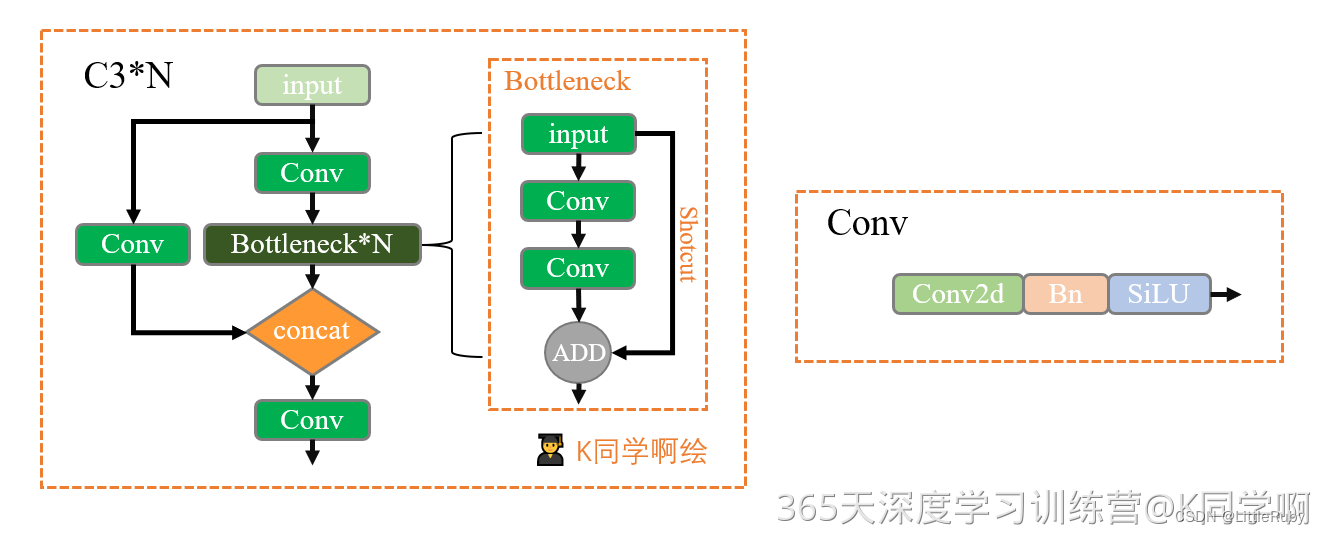
3.1.5.2 C3模块
C3模块是YOLOv5网络中的一个重要组成部分,其主要作用是增加网络的深度和感受野,提高特征提取的能力。C3/C3_False的区别在于Botttleneck是否使用shortcut,其结构如下图
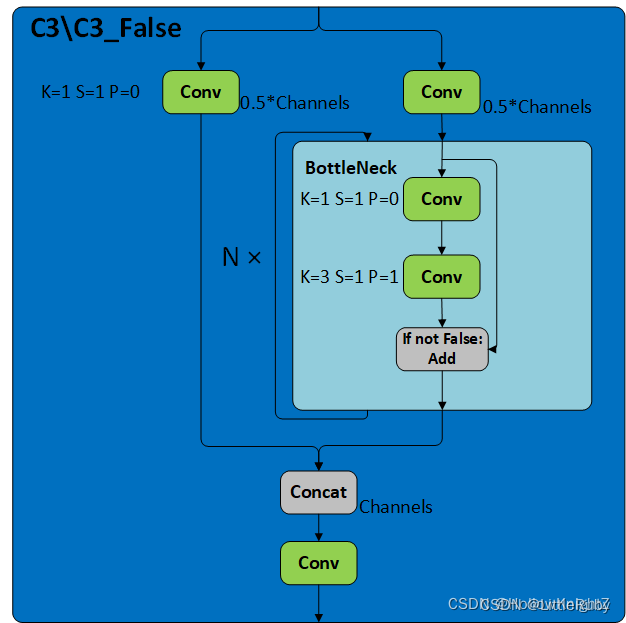
C3采用的是CSP结构,CSP的思想是将通道拆分成两个部分,分别走上图左右两条路,而源码中是将全部的输入特征利用两路1x1进行transition,比直接划分通道能够进一步提高特征的重用性,并且在输入到resiudal block之前也确实通道减半,减少了计算量。
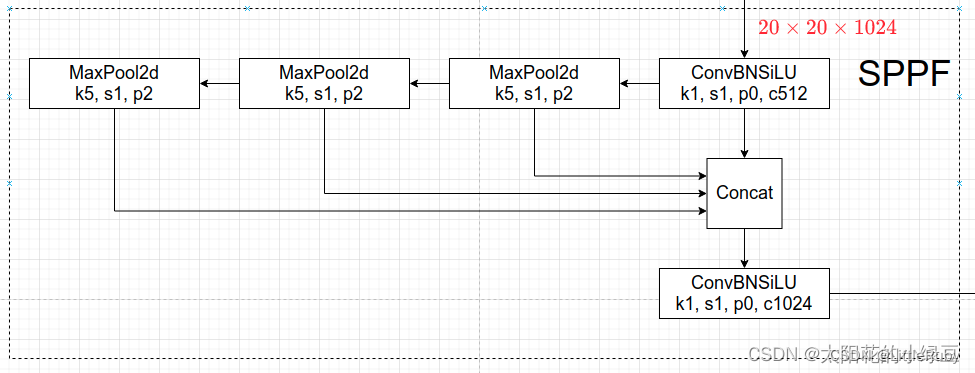
3.1.5.2 SPPF模块
SPP模块是一种池化模块,通常应用于卷积神经网络中,旨在实现输入数据的空间不变性和位置不变性,以便于提高神经网络的识别能力。其主要思想是将不同大小的感受野应用于同一张图像,从而能够捕捉到不同尺度的特征信息。在SPP模块中,首先对输入特征图进行不同大小的池化操作,以得到一组不同大小的特征图。然后将这些特征图连接在一起,并通过全连接层进行降维,最终得到固定大小的特征向量。SPP结构如下图所示,是将输入并行通过多个不同大小的MaxPool,然后做进一步融合,能在一定程度上解决目标多尺度问题。
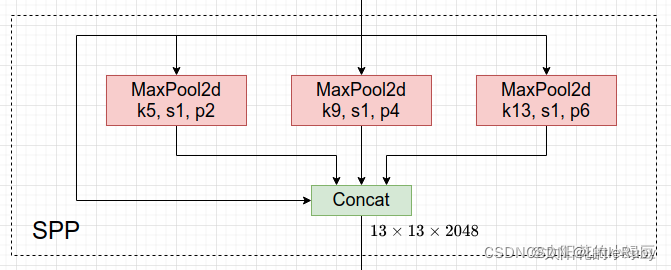
SPP模块通常由三个步骤组成:
池化:将输入特征图分别进行不同大小的池化操作,以获得一组不同大小的特征图。
连接:将不同大小的特征图连接在一起。
全连接:通过全连接层将连接后的特征向量降维,得到固定大小的特征向量。
v6.0版本后首先是将SPP换成成了SPPF(Glenn Jocher自己设计的),这个改动我个人觉得还是很有意思的,两者的作用是一样的,但后者效率更高。
3.1.6 Neck特征金字塔
由于物体在图像中的大小和位置是不确定的,因此需要一种机制来处理不同尺度和大小的目标。特征金字塔是一种用于处理多尺度目标检测的技术,它可以通过在骨干网络上添加不同尺度的特征层来实现。在Yolov5中,采用的是FPN(Feature Pyramid Network)特征金字塔结构,通过上采样和下采样操作将不同层次的特征图融合在一起,生成多尺度的特征金字塔。自顶向下部分主要是通过上采样和与更粗粒度的特征图融合来实现不同层次特征的融合,而自下向上则是通过使用一个卷积层来融合来自不同层次的特征图。
在目标检测算法中,Neck模块通常被用于将不同层级的特征图结合起来,生成具有多尺度信息的特征图,以提高目标检测的准确率。在 YOLOv5 中,使用了一种名为 PANet 的特征融合模块作为 Neck 模块。
YoloV5提取多特征层进行目标检测,一共提取三个特征层。
三个特征层位于主干部分CSPdarknet的不同位置,分别位于中间层,中下层,底层,当输入为(640,640,3)的时候,三个特征层的shape分别为feat1=(80,80,256)、feat2=(40,40,512)、feat3=(20,20,1024)。
在获得三个有效特征层后,利用这三个有效特征层进行FPN层的构建,构建方式为:
1.feat3=(20,20,1024)的特征层进行1次1X1卷积调整通道后获得P5,P5进行上采样UmSampling2d后与feat2=(40,40,512)特征层进行结合,然后使用CSPLayer进行特征提取获得P5_upsample,此时获得的特征层为(40,40,512)。
2.P5_upsample=(40,40,512)的特征层进行1次1X1卷积调整通道后获得P4,P4进行上采样UmSampling2d后与feat1=(80,80,256)特征层进行结合,然后使用CSPLayer进行特征提取P3_out,此时获得的特征层为(80,80,256)。
3.P3_out=(80,80,256)的特征层进行一次3x3卷积进行下采样,下采样后与P4堆叠,然后使用CSPLayer进行特征提取P4_out,此时获得的特征层为(40,40,512)。
4.P4_out=(40,40,512)的特征层进行一次3x3卷积进行下采样,下采样后与P5堆叠,然后使用CSPLayer进行特征提取P5_out,此时获得的特征层为(20,20,1024)。
特征金字塔可以将不同shape的特征层进行特征融合,有利于提取出更好的特征。
具体来说,自顶向下部分是通过上采样和与更粗粒度的特征图融合来实现不同层次特征的融合,主要分为以下几步:
1.对最后一层特征图进行上采样,得到更精细的特征图;
2.将上采样后的特征图与上一层特征图进行融合,得到更丰富的特征表达;
3.重复以上两个步骤,直到达到最高层。
自下向上部分主要是通过使用一个卷积层来融合来自不同层次的特征图,主要分为以下几步:
1.对最底层特征图进行卷积,得到更丰富的特征表达;
2.将卷积后的特征图与上一层特征图进行融合,得到更丰富的特征表达;
3.重复以上两个步骤,直到达到最高层。
最后,自顶向下部分和自下向上部分的特征图进行融合,得到最终的特征图,用于目标检测。
3.1.7 Head目标检测头
目标检测头是用来对特征金字塔进行目标检测的部分,它包括了一些卷积层、池化层和全连接层等。在 YOLOv5 模型中,检测头模块主要负责对骨干网络提取的特征图进行多尺度目标检测。该模块主要包括三个部分,此外,Yolov5还使用了一些技巧来进一步提升检测精度,比如GIoU loss、Mish激活函数和多尺度训练等。
- Anchors:用于定义不同大小和长宽比的目标框,通常使用 K-means 聚类对训练集的目标框进行聚类得到,可以在模型训练之前进行计算,存储在模型中,用于预测时生成检测框。
- Classification:用于对每个检测框进行分类,判断其是否为目标物体,通常采用全连接层加 Softmax 函数的形式对特征进行分类。
- Regression:用于对每个检测框进行回归,得到其位置和大小,通常采用全连接层的形式对特征进行回归。
YOLOv5的检测层由几个重要的组成部分构成,包括:
Anchors(锚框):
锚框是预定义的一组边界框,用于在特征图上生成候选框。
YOLOv5通过提前定义不同比例和尺寸的锚框来适应不同大小的目标。Convolutional Layers(卷积层):
YOLOv5的检测层包含一系列卷积层,用于处理特征图和提取特征。
这些卷积层可以通过调整通道数和核大小来适应不同的检测任务。Prediction Layers(预测层):
每个预测层负责预测一组边界框和类别。
每个预测层通常由卷积层和一个输出层组成。
输出层的通道数和形状决定了预测的边界框数量和类别数量。Non-Maximum Suppression (NMS)(非极大值抑制):
在输出的边界框中,使用非极大值抑制算法来抑制重叠的边界框,只保留最具有代表性的边界框。
YOLOv5 的检测头模块采用了多层级特征融合的方法,首先将骨干网络输出的特征图经过一个 Conv 模块进行通道数的降维和特征图的缩放,然后再将不同层级的特征图进行融合,得到更加丰富的特征信息,从而提高检测性能。
3.1.8 YOLOv5总结
Yolov5是目标检测领域中的一种深度学习算法,是对Yolov4的改进版本,其在速度和精度方面都取得了很大的提升。Yolov5的整体架构由主干网络、FPN、Neck、Head等模块组成。
主干网络部分采用的是CSPDarknet53,通过使用残差结构和特征重用机制,可以有效地提高模型的特征提取能力。
FPN部分采用的是基于高斯加权的特征金字塔,可以解决多尺度目标检测的问题。
Neck部分采用的是SPP和PAN结合的结构,能够在保持高效性的同时提升模型的性能。
Head部分采用的是YOLOv5头结构,可以输出网络的预测结果。
总的来说,Yolov5在各个模块上的设计都充分考虑了速度和精度的平衡,使得它在目标检测任务中表现出色。
参考链接:
【YOLOv5】Backbone、Neck、Head各模块详解
YOLOv5网络详解
从YOLOv5源码yolo.py详细介绍Yolov5的网络结构
YOLOv5网络详解
总结
通过本文的学习,对YOLOv5网络结构有了一个初步的了解。
相关文章:
深度学习 Day19——P8YOLOv5-C3模块实现
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制 文章目录 前言1 我的环境2 代码实现与执行结果2.1 前期准备2.1.1 引入库2.1.2 设置GPU(如果设备上支持GPU就使用GPU,否则使用C…...

轻量封装WebGPU渲染系统示例<51>- 视差贴图(Parallax Map)(源码)
视差纹理是一种片段着色阶段增强材质表面凹凸细节的技术。 这里在WebGPU的实时渲染材质管线中实现了视差贴图计算,以便增强相关的纹理细节表现力。 当前示例源码github地址: https://github.com/vilyLei/voxwebgpu/blob/feature/material/src/voxgpu/sample/Para…...

YOLOv8改进 | 2023主干篇 | 华为最新VanillaNet主干替换Backbone实现大幅度长点
一、本文介绍 本文给大家来的改进机制是华为最新VanillaNet网络,其是今年最新推出的主干网络,VanillaNet是一种注重极简主义和效率的神经网络架构。它的设计简单,层数较少,避免了像深度架构和自注意力这样的复杂操作(需要注意的是…...
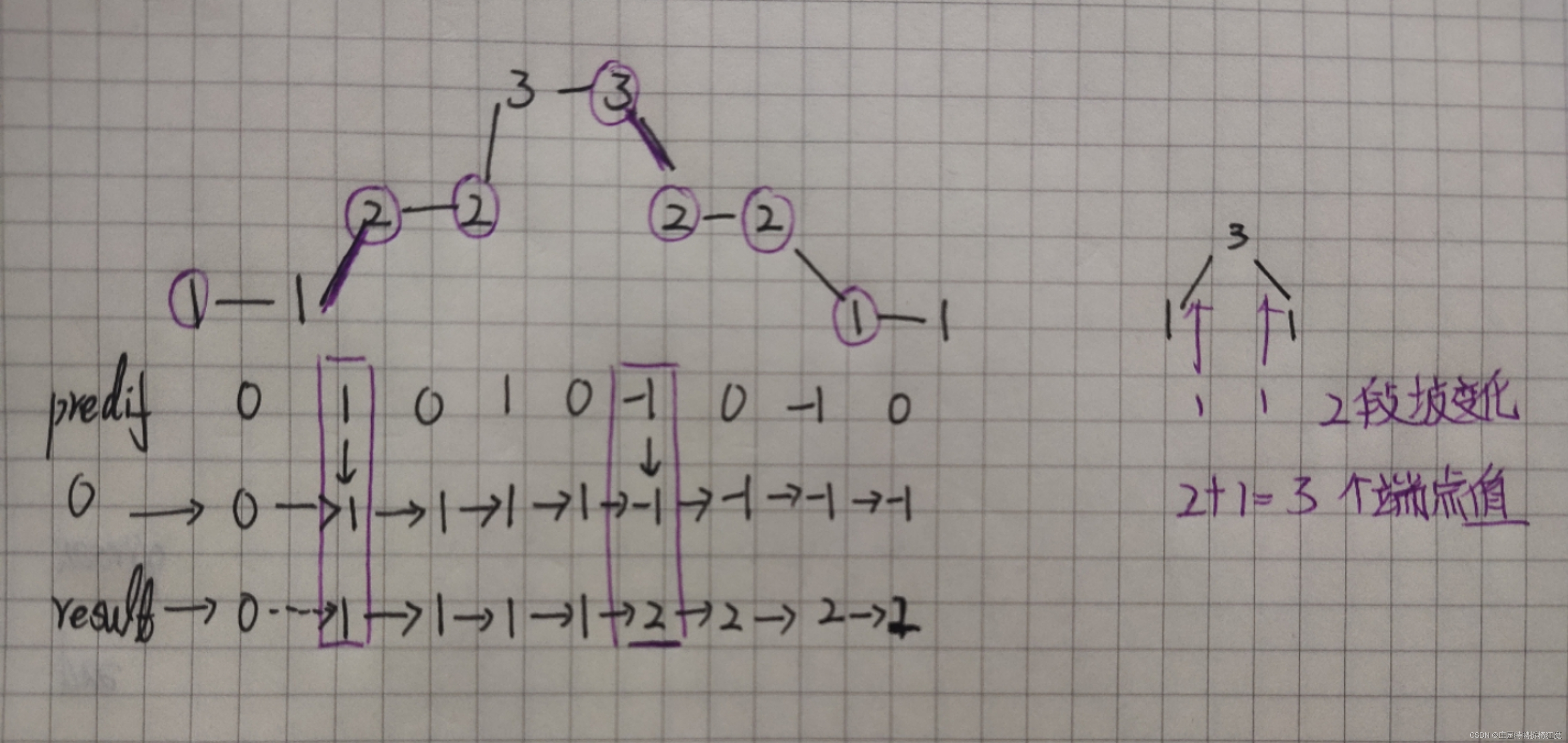
Leetcode 376 摆动序列
题意理解: 如果连续数字之间的差严格地在正数和负数之间交替,则数字序列称为 摆动序列 如果是摆动序列,前后差值呈正负交替出现 为保证摆动序列尽可能的长,我们可以尽可能的保留峰值,,删除上下坡的中间值&…...

51单片机控制1602LCD显示屏输出自定义字符二
51单片机控制1602LCD显示屏输出自定义字符二 1.概述 1602LCD除了内置的字符外还提供自定义字符功能,当内置的字符中没有我们想要输出的字符时,我们就可以自己创造字符让他显示,下面介绍1602如何创建自定义字符。 2.1602LCD创建字符原理 自…...

HarmonyOS自学-Day2(@Builder装饰器)
目录 文章声明⭐⭐⭐让我们开始今天的学习吧!Builder装饰器:自定义构建函数Builder介绍Builder使用说明自定义组件中创建自定义构建函数全局自定义构建函数 Builder参数传递规则按引用传递参数按值传递参数 文章声明⭐⭐⭐ 该文章为我(有编程…...

bottom-up-attention-vqa-master 成功复现!!!
代码地址 1、create_dictionary.py 建立词典和使用预训练的glove向量 (1)create_dictionary() 遍历每个question文件取出所关注的question部分,qs 遍历qs,对每个问题的文本内容进行分词,并将分词结果添加到字典中&…...

BigDecimal中divide方法详解
BigDecimal中divide方法详解 大家好,我是免费搭建查券返利机器人赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天,让我们一起深入探讨Java中BigDecimal的divide方法,揭开这个…...

视频推拉流EasyDSS互联网直播/点播平台构建户外无人机航拍直播解决方案
一、背景分析 近几年,国内无人机市场随着航拍等业务走进大众,出现爆发式增长。无人机除了在民用方面的应用越来越多,在其他领域也已经开始广泛应用,比如公共安全、应急搜救、农林、环保、交通 、通信、气象、影视航拍等。无人机使…...
行为型设计模式-策略模式(Strategy Pattern)
策略模式 策略模式:百度百科中引述为:指对象有某个行为,但是在不同的场景中,该行为有不同的实现算法。 策略模式是对算法的包装,是把使用算法的责任和算法本身分割开来,委派给不同的对象管理。策略模式通…...
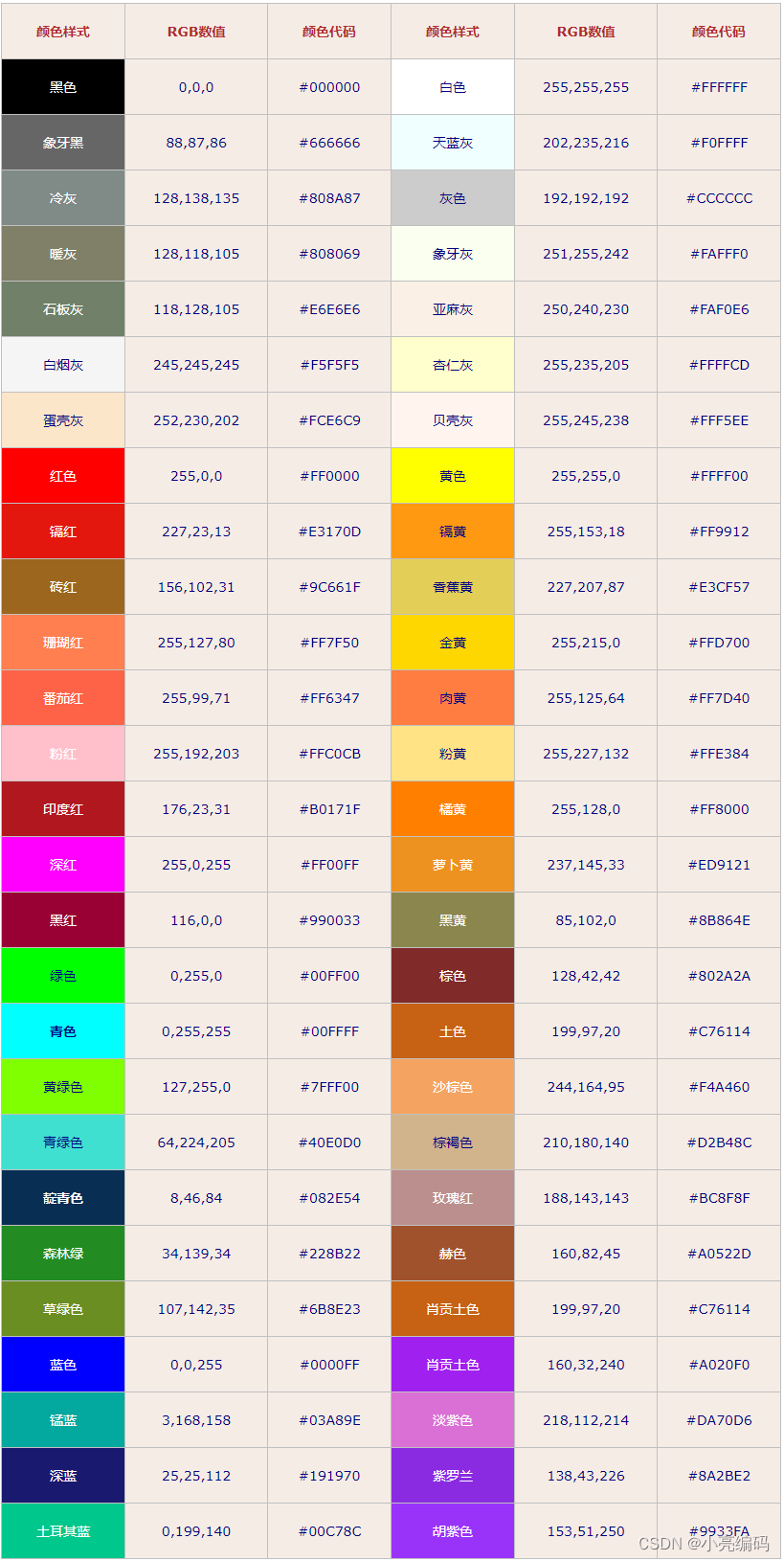
html中RGB和RGBA颜色表示法
文章目录 RGB什么是RGBRGB颜色模式的取值范围RGB常用颜色对照表 RGBA什么是RGBARGBA颜色模式的取值范围 总结 RGB 什么是RGB RGB是一种颜色空间,其中R代表红色(Red)、G代表绿色(Green)、B代表蓝色(Blue&a…...

【BEV感知】BEVFormer 融合多视角相机空间特征和时序特征的端到端框架 ECCV 2022
前言 本文分享BEV感知方案中,具有代表性的方法:BEVFormer。 基本思想:使用可学习的查询Queries表示BEV特征,查找图像中的空间特征和先前BEV地图中的时间特征。 它基于Deformable Attention实现了一种融合多视角相机空间特征和时序特征的端到端框架,适用于多种自动驾驶感…...

git拉取hugging face代码失败:443
报错信息:fatal: unable to access http://huggingface.co/THUDM/chatglm2-6b/: OpenSSL SSL_connect: Connection reset by peer in connection to huggingface.co:443 解决方法:(127.0.0.1:7890配置为自己的实际代理ip及端口) …...

【赠书活动】OpenCV4工业缺陷检测的六种方法
文章目录 前言机器视觉缺陷检测工业上常见缺陷检测方法延伸阅读推荐语 赠书活动 前言 随着工业制造的发展,对产品质量的要求越来越高。工业缺陷检测是确保产品质量的重要环节,而计算机视觉技术的应用能够有效提升工业缺陷检测的效率和精度。 OpenCV是一…...

设计模式之创建型设计模式(一):单例模式 原型模式
单例模式 Singleton 1、什么是单例模式 在软件设计中,单例模式是一种创建型设计模式,其主要目的是确保一个类只有一个实例,并提供一个全局访问点。 这意味着无论何时需要该类的实例,都可以获得相同的实例,而不会创建…...
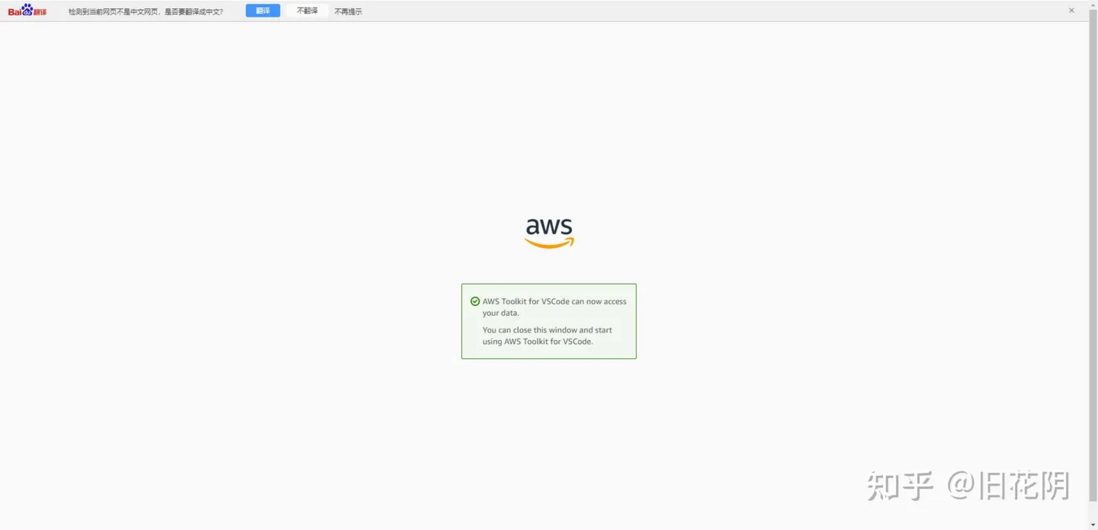
Amazon CodeWhisperer 在 vscode 的应用
文章作者:旧花阴 CodeWhisperer 是一款可以帮助程序员更快、更安全地编写代码的工具,可以在他们的开发环境中实时提供代码建议和推荐。亚马逊云科技发布的这款代码生成工具 CodeWhisperer 最大的优势就是对于个人用户免费。以在 vscode 为例,演示安装过程…...
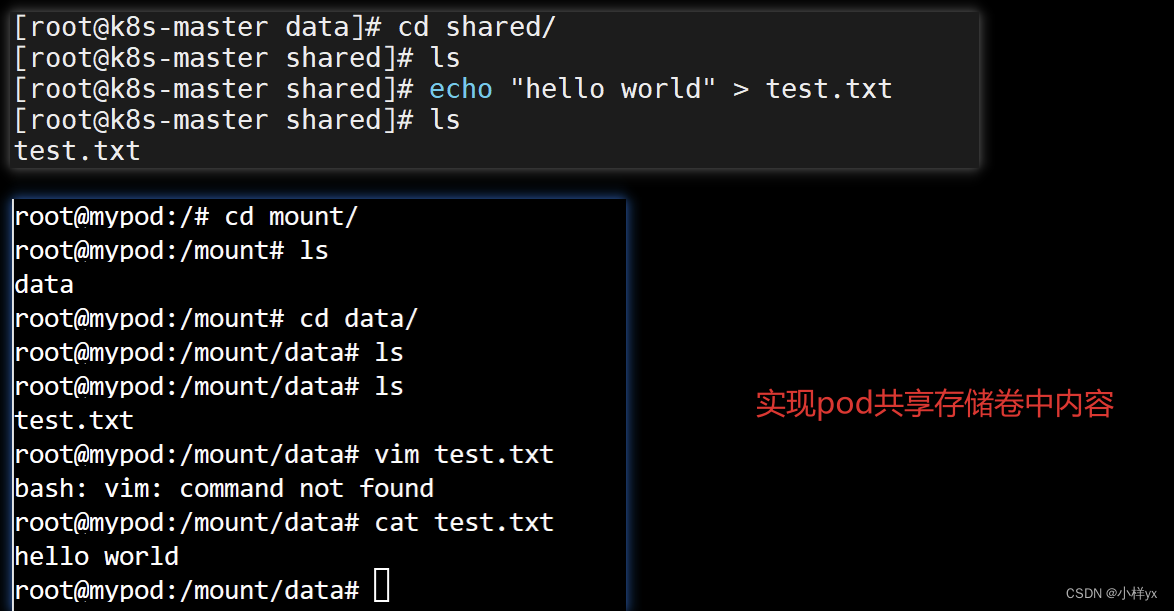
【Java】基于fabric8io库操作k8s集群实战(pod、deployment、service、volume)
目录 前言一、基于fabric8io操作pod1.1 yaml创建pod1.2 fabric8io创建pod案例 二、基于fabric8io创建Service(含Deployment)2.1 yaml创建Service和Deployment2.2 fabric8io创建service案例 三、基于fabric8io操作Volume3.1 yaml配置挂载存储卷3.2 基于fa…...

uniapp微信小程序下载保存图片流到本地,base64
我们在开发时下载图片或文件,地址基本上都是https的格式,下面来说一下后端返回base64的文件流,是如何下载的 必须把返回的流去掉这一部分:data:image/png;base64,否则下载不了 如我自己的流: data:image/…...
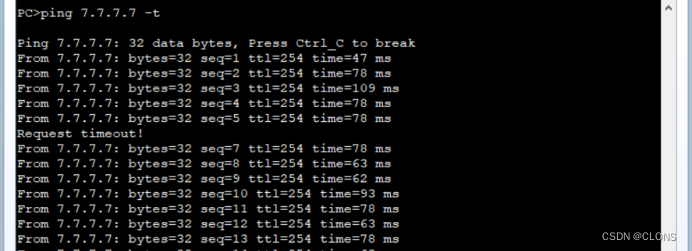
华为数通——企业双出口冗余
目标:默认数据全部经过移动上网,联通低带宽。 R1 [ ]ip route-static 0.0.0.0 24 12.1.1.2 目的地址 掩码 下一条 [ ]ip route-static 0.0.0.0 24 13.1.1.3 preference 65 目的地址 掩码 下一条 设置优先级为65 R…...
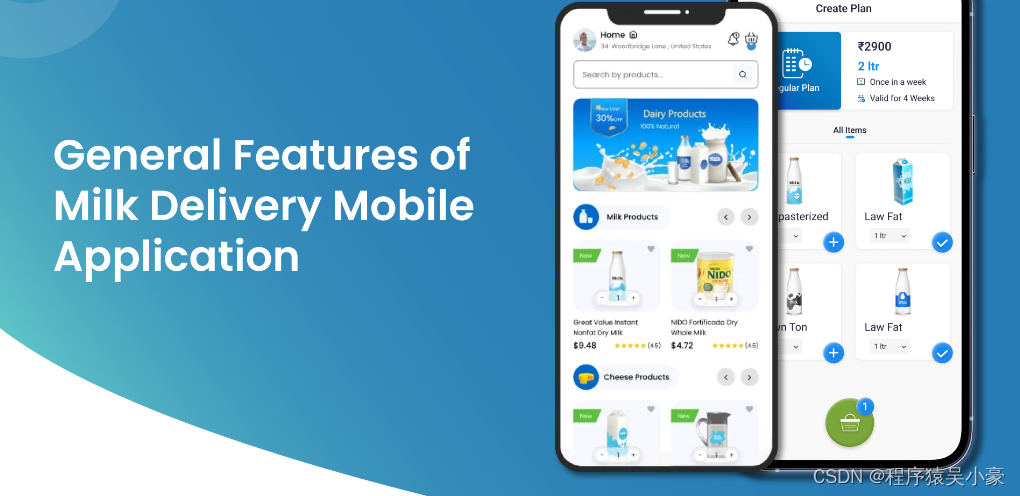
送奶APP开发:终极指南
您是否有兴趣使用新鲜牛奶和乳制品,但不想每天早上去乳制品店或最近的商店?借助技术,订购日常用品(例如杂货和牛奶)变得更加简单。 DailyMoo 是最受欢迎的送奶应用,收入达数百万人民币。因此,投…...

告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点
告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点每次在终端敲入docker ps、docker stop、docker rm时,你是否想过——当容器数量超过两位数,这种重复劳动是否在消耗你的生命?去年我们团队在迁移微服务架…...

从Gamma函数到泊松分布:一个概率论中的含参量积分实用案例解析
Gamma函数与泊松分布:概率论中的数学之美 在数据科学和机器学习的实践中,概率分布构成了建模的基石。当我们深入探究这些分布背后的数学原理时,Gamma函数以其优雅的性质和广泛的应用脱颖而出。它不仅连接了离散与连续概率世界,更在…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...

多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?
多智能体谈判系统:Agent 如何通过博弈达成最优交易价格?关键词 多智能体系统、自动谈判、博弈论、纳什均衡、帕累托最优、双边/多边谈判、强化学习谈判、动态定价 摘要 想象一个没有人类中介的世界:电商平台上的智能客服自动和批发商砍价、供…...

ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库
ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various c…...

Taotoken的审计日志功能为企业API安全与合规管理提供支持
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的审计日志功能为企业API安全与合规管理提供支持 当企业决定将大模型能力集成到内部业务流程中时,IT管理员和安…...

脉冲神经网络加速器设计与边缘计算优化
1. 脉冲神经网络加速器的设计挑战与突破在边缘计算领域,脉冲神经网络(SNN)正以其独特的生物启发特性引发新一轮技术变革。与传统人工神经网络(ANN)相比,SNN通过离散的脉冲信号传递信息,模拟生物神经元的工作机制,理论上可实现超低…...

解决方法:庐山派K230接串口没识别到端口问题
一、插入usb转串口工具之前二、插入usb转串口工具之后三、解决方法说明:🔍 核心原因:USB Serial 设备,没有被识别为 COM 口你现在看到的 USB Serial,说明开发板已经正常启动了,USB 也被电脑识别到了&#x…...

LeagueAkari:英雄联盟终极自动化助手革命性指南
LeagueAkari:英雄联盟终极自动化助手革命性指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否在英雄联盟游戏中反复经历这…...

基于树莓派打造万能遥控器:从硬件选型到Web控制界面全解析
1. 项目概述:打造一个能“学习”的万能遥控器家里遥控器越来越多,电视、空调、风扇、灯带……每个设备都配一个,找起来麻烦,用起来也乱。市面上所谓的“万能遥控器”其实并不万能,它内置的码库有限,很多小众…...