C# 序列化时“检测到循环引用”错误的彻底解决方案
目录
一,问题表现
二、没有技术含量的解决方案
三、本人彻底的解决方案
简要说明
贴代码
思路解析
思路
一,问题表现
示例代码如下:
[Serializable]
public class NodeTest
{public NodeTest (){new List<NodeTest> ();}public string Name { get; set; }public NodeTest Parent { get; set; }public List<NodeTest> Children { get; set; }}
先看错误地方,以上这个类要是序列化就会遇到,"序列化类型 Test.NodeTest 的对象时检测到循环引用。"错误。
二、没有技术含量的解决方案
网上一搜,几乎到处都是这两种解决方案:
- 使用NewtonSoft.Json,然后使用序列方法,加上设置 ReferenceLoopHandling = Newtonsoft.Json.ReferenceLoopHandling.Ignore
- 直接在循环错误属性上加XmlIgnore特性。
NodeTest nd = new NodeTest ();nd.Name = "root";NodeTest nd1 = new NodeTest ();nd1.Name = "child1";nd1.Parent = nd;NodeTest nd2 = new NodeTest ();nd2.Name = "child2";nd2.Parent = nd;nd.Children.Add ( nd1 );nd.Children.Add ( nd2 );上面的实例,采用第一种方法序列化是这结果:

采用第二种是以下结果。
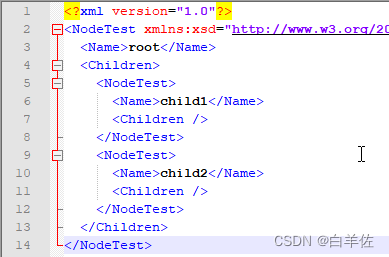
由此可见这两种方法简单,粗暴,没有一点技术含量。这么说是因为,直接忽略了其父子关系。反序列化成对象后Parent属性为空,如果需要逆向查找父对象时,完全行不通。
三、本人彻底的解决方案
-
简要说明
首先将例中NodeTest对象进行改装,让它继承自 IXmlSerializable 接口并实现,为的就是在序列化和反序列化时,可以自由控制以达到序列化时能包含父节点信息。其次是对他的属性Children进行改造,这很重要,如果继续使用List列表,会出现其他问题,这个后续会提到。
-
贴代码
现不废话,贴代码,代码看完,看后文解析,应该很容易明白,NodeTest 类:
[Serializable]public class NodeTest : IXmlSerializable{internal const string ROOT = "NodeTest";internal const string NAME = "Name";internal const string PARENT = "Parent";internal const string ELEMENT_EXISTMARK = "ExistMark";internal const string ELEMENT_EXIST = "Exist";internal const string ELEMENT_NOTEXIST = "NotExist";public NodeTest (){Children = new NodeTestCollection ();}public string Name { get; set; }public NodeTest Parent { get; set; }[XmlArray ()]public NodeTestCollection/*List<NodeTest>*/ Children { get; set; }public System.Xml.Schema.XmlSchema GetSchema (){return null;}public static void ResetSerializationStatus (){_dicAllNodes.Clear ();}private static Dictionary<string, NodeTest> _dicAllNodes= new Dictionary<string, NodeTest> ();public void ReadXml ( System.Xml.XmlReader reader ){XmlSerializer xmlSer = XmlSerializer.FromTypes ( new Type[ ] { typeof ( NodeTest ) } )[ 0 ];if ( reader.IsEmptyElement ) return;while ( reader.NodeType != System.Xml.XmlNodeType.EndElement ){reader.ReadStartElement ( ROOT );reader.ReadStartElement ( NAME );this.Name = reader.ReadString ();reader.ReadEndElement ();reader.MoveToContent ();string sExistMark = ELEMENT_NOTEXIST;if ( reader.MoveToAttribute ( ELEMENT_EXISTMARK ) ){sExistMark = reader.GetAttribute ( ELEMENT_EXISTMARK );}reader.ReadStartElement ( PARENT );switch ( sExistMark ){case ELEMENT_EXIST:reader.ReadStartElement ( NAME );Parent = new NodeTest ();Parent.Name = reader.ReadString ();reader.ReadEndElement ();reader.ReadEndElement ();break;default:break;}XmlSerializer xmlSer2 = XmlSerializer.FromTypes ( new Type[ ] { typeof ( NodeTestCollection ) } )[ 0 ];Children = ( NodeTestCollection )xmlSer2.Deserialize ( reader );if ( Children.Count != 0 ){reader.ReadEndElement ();}_dicAllNodes.Add ( this.Name, this );}for ( int i = 0 ; i < Children.Count ; i++ ){var child = Children[ i ];if ( child.Parent != null ){child.Parent = _dicAllNodes[ child.Parent.Name ];}}}public void WriteXml ( System.Xml.XmlWriter writer ){XmlSerializer xmlSer = XmlSerializer.FromTypes ( new Type[ ] { typeof ( NodeTest ) } )[ 0 ];writer.WriteStartElement ( NAME );writer.WriteString ( this.Name );writer.WriteEndElement ();writer.WriteStartElement ( PARENT );if ( Parent != null ){writer.WriteAttributeString ( ELEMENT_EXISTMARK, ELEMENT_EXIST );writer.WriteStartElement ( NAME );writer.WriteString ( Parent.Name );writer.WriteEndElement ();}else{writer.WriteAttributeString ( ELEMENT_EXISTMARK, ELEMENT_NOTEXIST );}writer.WriteEndElement ();writer.Flush ();XmlSerializer xmlSer2 = XmlSerializer.FromTypes ( new Type[ ] { typeof ( NodeTestCollection ) } )[ 0 ];xmlSer2.Serialize ( writer, this.Children );writer.Flush ();writer.Flush ();}}
List<NodeTest>改成NodeTestCollection,解决序列化时结构错乱问题(本来打算细说的,算了,懒得打字了,看客自己试试就知道了),此改动,还很利于后续的优化扩展,比如名字索引等,实现如下:
[Serializable][XmlRoot(ElementName = "Children" )]public class NodeTestCollection : IList<NodeTest>, IXmlSerializable{private const string ROOT = "Children";private const string CHILDCOUNT = "ChildCount";#region 继承实现自IList<NodeTest>private IList<NodeTest> m_lstNodes = new List<NodeTest> ();public int IndexOf ( NodeTest item ){int iIdx = -1;for ( int i = 0 ; i < m_lstNodes.Count ; i++ ){if ( m_lstNodes[ i ] == item ){iIdx = i;break;}}return iIdx;}public void Insert ( int index, NodeTest item ){m_lstNodes.Insert ( index, item );}[XmlElement ( "NodeTest", Type = typeof ( NodeTest ) )]public NodeTest this[ int index ]{get{return m_lstNodes[ index ];}set{m_lstNodes[ index ] = value;}}public void Add ( NodeTest item ){m_lstNodes.Add ( item );}public bool Contains ( NodeTest item ){return m_lstNodes.Contains ( item );}public void CopyTo ( NodeTest[ ] array, int arrayIndex ){m_lstNodes.CopyTo ( array, arrayIndex );}public bool Remove ( NodeTest item ){return m_lstNodes.Remove ( item );}IEnumerator<NodeTest> IEnumerable<NodeTest>.GetEnumerator (){return m_lstNodes.GetEnumerator ();}public void RemoveAt ( int index ){m_lstNodes.RemoveAt ( index );}public void Clear (){m_lstNodes.Clear ();}public int Count{get { return m_lstNodes.Count; }}public bool IsReadOnly{get { return false; }}System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator (){return m_lstNodes.GetEnumerator ();}#endregionpublic System.Xml.Schema.XmlSchema GetSchema (){return null;}public void ReadXml ( System.Xml.XmlReader reader ){//if ( reader.IsEmptyElement ) return;int iChildCount = 0;if ( reader.MoveToAttribute ( CHILDCOUNT ) ) iChildCount = int.Parse ( reader.GetAttribute ( CHILDCOUNT ) );reader.ReadStartElement ( ROOT );if (iChildCount > 0){XmlSerializer xmlSer = XmlSerializer.FromTypes ( new Type[ ] { typeof ( NodeTest ) } )[ 0 ];for ( int i = 0 ; i < iChildCount ; i++ ){var readerSub = reader.ReadSubtree();this.Add ( ( NodeTest )xmlSer.Deserialize ( readerSub ) );reader.ReadEndElement ();}}}public void WriteXml ( System.Xml.XmlWriter writer ){int iCnt = this.Count;writer.WriteAttributeString ( CHILDCOUNT, iCnt.ToString () );XmlSerializer xmlSer = XmlSerializer.FromTypes ( new Type[ ] { typeof ( NodeTest ) } )[ 0 ];for ( int i = 0 ; i < iCnt ; i++ ){xmlSer.Serialize ( writer, this[ i ] );}}}
-
思路解析
说说思路:改造的地方不多,主要是继承方法的实现上,也就是ReadXml 和WriteXml方法实现上。在实现它们时,采用一点手段,在方法体类对循环引用的对象进行区别处理。
思路
原理很简单,循环引用的地方,在本例中即Parent对象,采用简单存储,存储一个指引信息,这里为图简洁,直接使用Name属性作为指引【后续各位观众具体使用是可以使用唯一标识符进行优化,在此我就不改了】。将所有NodeTest对象信息存为字典,在反序列化时使用指引进行挂接,因为这是class,是引用对象,简单一改,全部挂接完成,挂接处就是For循环处。
此外还有两处XmlAttribute——ExistMark和ChildCount,分别用来辅助Parent存在时检测以及子节点存在检测。
采用这个方法,序列化出来如下图:
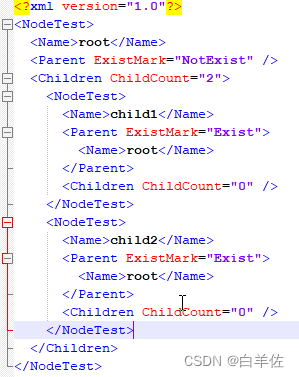
反序列化也成功进行挂接,不信,你试试。
原理就这么简单。
不懂就留言吧。
相关文章:
C# 序列化时“检测到循环引用”错误的彻底解决方案
目录 一,问题表现 二、没有技术含量的解决方案 三、本人彻底的解决方案 简要说明 贴代码 思路解析 思路 一,问题表现 示例代码如下: [Serializable] public class NodeTest {public NodeTest (){new List<NodeTest> ();}p…...

小红书“复刻”微信,微信“内造”小红书
配图来自Canva可画 随着互联网增长红利逐渐见顶,各大互联网平台对流量的争夺变得愈发激烈。而为了寻找新的业务可能性,各家都在不遗余力地拓宽自身边界。在此背景下,目前最为“吸睛”和“吸金”的社交、电商、种草、短视频等领域,…...
用arthas轻松排查线上问题
你是否在项目中会碰到以下一些问题: 在代码中打印各种日志来排查,比如方法的入参,出参,及在方法体中打印日志判断走哪行代码还有你觉得代码没问题,可是运行出现却是以前的bug,感觉代码没修改,或…...
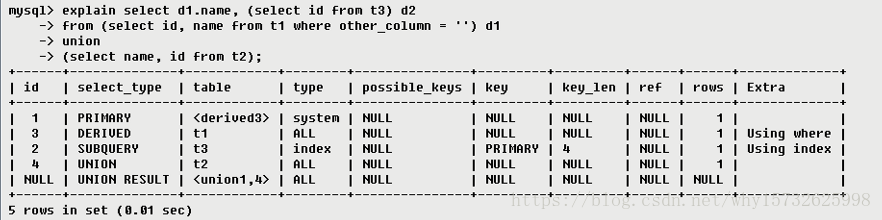
mysql一explain结果分析
1. EXPLAIN简介 使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈。 ➤ 通过EXPLAIN,我们可以分析出以下结果: 表的读取顺序数据读取操作的操作类型哪些索引可…...

原理底层计划--HashMap
HashMap 之前写了“Java集合TreeMap红黑树一生只爱一次”,说到底还是太年轻了,Map其实在排序中应用比较少,一般追求的是速度,通过HashMap来获取速度。hashmap 调用object hashcode方法用于返回对象的哈希码,主要使用在…...

win10 设备管理器中的黄色感叹号(华硕)
目录一、前言二、原因三、方案四、操作一、前言 打开设备管理器,我们可以看到自己设备的信息,但是在重装系统后,你总会在不经意间发现。咦,怎么多了几个感叹号??? 由于我已经解决该问题&#…...

新产品上市推广不是“铺货”上架
只有不断推出新产品的企业才能走得长远,但现实中往往有很多企业投入了大量人力、物力、财力研发的新产品却在推广的过程中屡屡受挫。那么,为什么适合市场的新产品会在市场营销推广的过程中夭折呢?小马识途营销顾问分析有如下几点:…...

MATLAB训练神经网络小结
MATLAB训练神经网络小结1、一个典型例子1.1 可视化神经网络1.2 指定某一层的激活函数1.3 训练神经网络时使用L1正则化1.4返回训练过程中的参数1.5 查看训练好的权重系数1.6 如何使用早停法来防止过拟合1、一个典型例子 例如输入特征为10维,想训练一个10x20x10x1的三…...
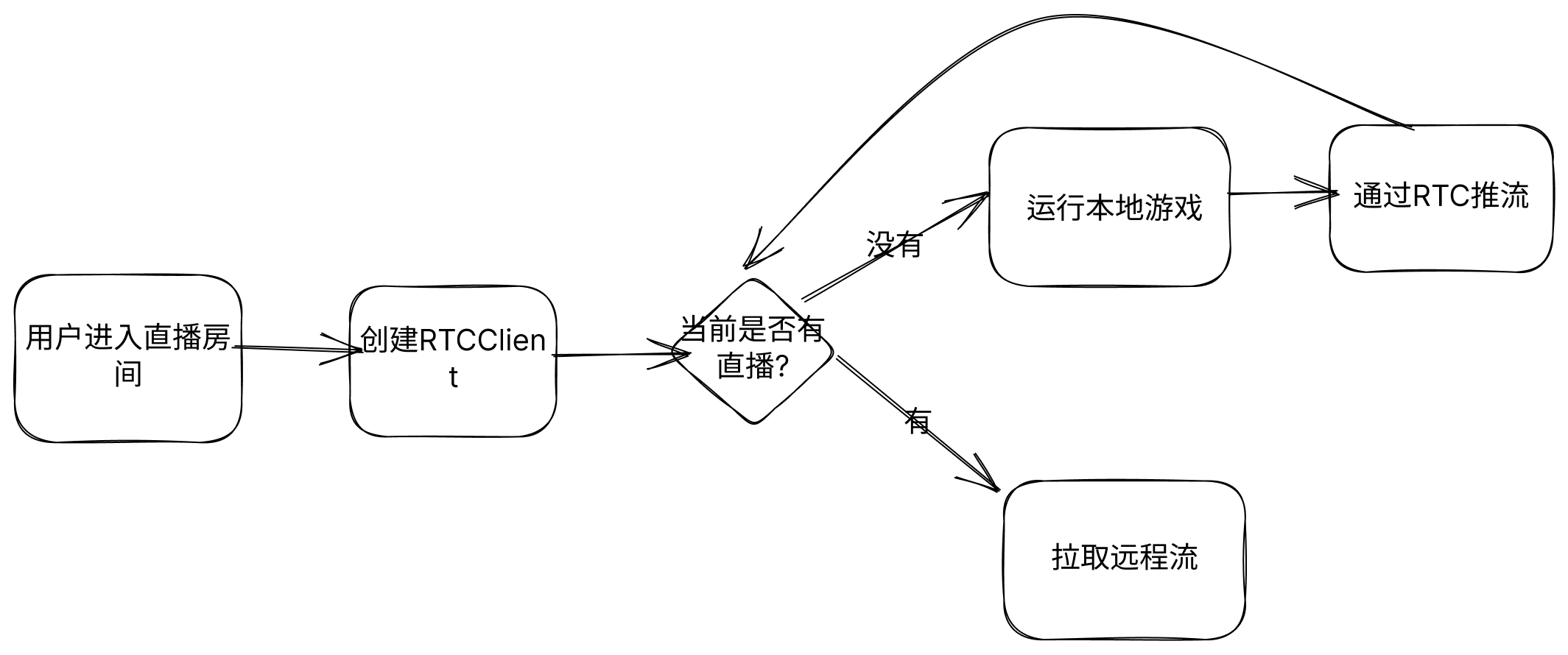
实战:一天开发一款内置游戏直播的国产版Discord应用【附源码】
游戏直播是Discord产品的核心功能之一,本教程教大家如何1天内开发一款内置游戏直播的国产版Discord应用,用户不仅可以通过IM聊天,也可以进行语聊,看游戏直播,甚至自己进行游戏直播,无任何实时音视频底层技术…...
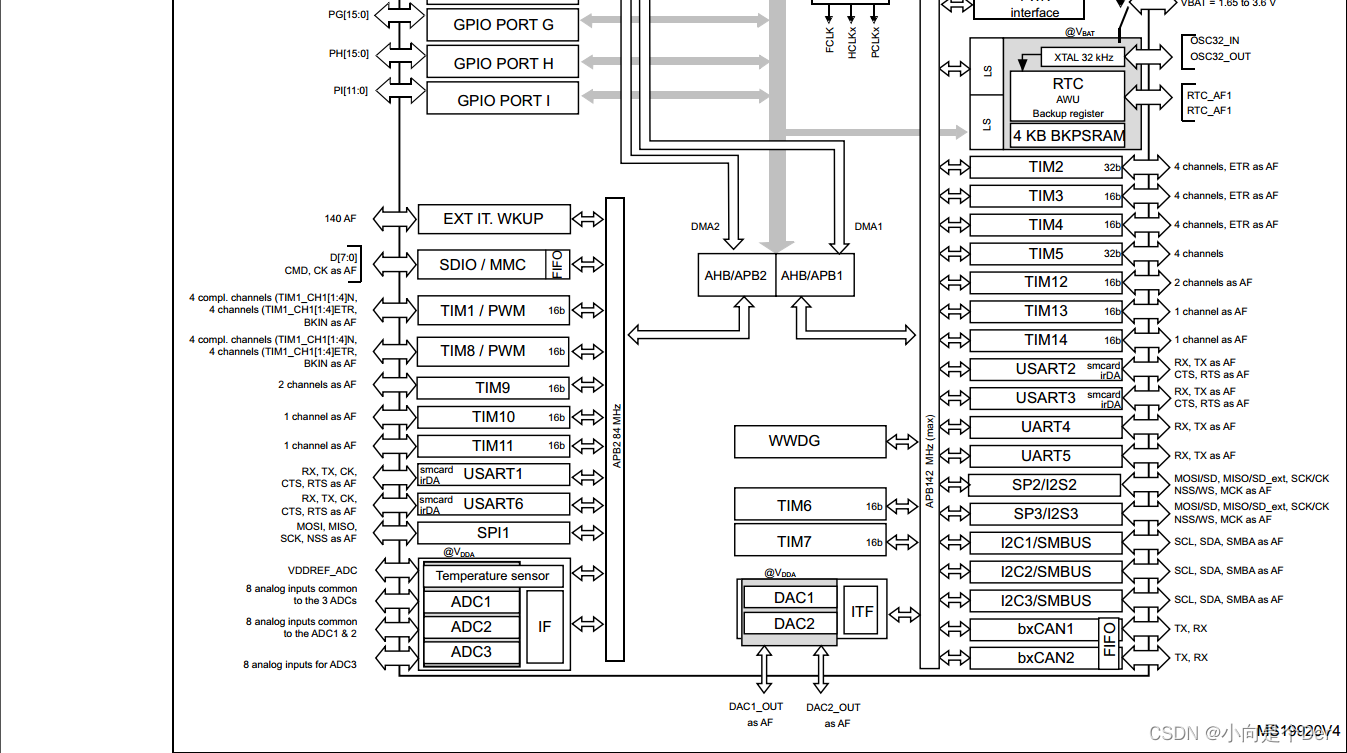
嵌入式学习笔记——基于Cortex-M的单片机介绍
基于Cortex-M的单片机介绍前言生产厂商及其产品线ARM单片机的产品线命名规则留个作业习单片机的资料准备STM32开发所需手册1.芯片的数据手册作业2前言 本文继续接着上一篇中关于Cortex-M的介绍,来记录一些关于ARM系单片机的知识。 生产厂商及其产品线 芯片厂商在…...
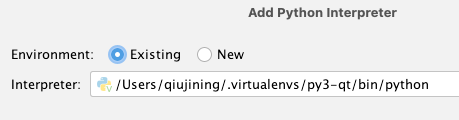
Python 虚拟环境的使用
PyCharm 创建的虚拟环境与使用 workon 命令创建的虚拟环境在本质上没有区别,它们都是 Python 的虚拟环境。 使用 PyCharm 创建工程时,使用可以使用曾经工程的虚拟环境,或者新建一个虚拟环境来安装 Python 的库,又或者使用 workon…...

招生咨询|浙江大学MPA项目2023年招生问答与通知
问:报考浙江大学MPA的基本流程是怎么样的? 答:第一阶段为网上报名与确认。MPA考生须参加全国管理类联考,网上报名时间一般为10月初开始、10月下旬截止,错过网上报名时间后不能补报。确认时间一般为11月上旬,…...

Qt std :: bad_alloc
文章目录摘要问题出现原因第一种 请求内存多余系统可提供内存第二种 地址空间过于分散,无法满足大块连续内存的请求第三种 堆管理数据结构损坏稍微总结下没想到还能更新参考关键字: std、 bad、 alloc、 OOM、 异常退出摘要 今天又是被BUG统治的一天&a…...

《设计模式》装饰者模式
《设计模式》装饰者模式 装饰者模式(Decorator Pattern)是一种结构型设计模式,它允许在不改变现有对象结构的情况下,动态地添加行为或责任到对象上。在装饰者模式中,有一个抽象组件(Component)…...
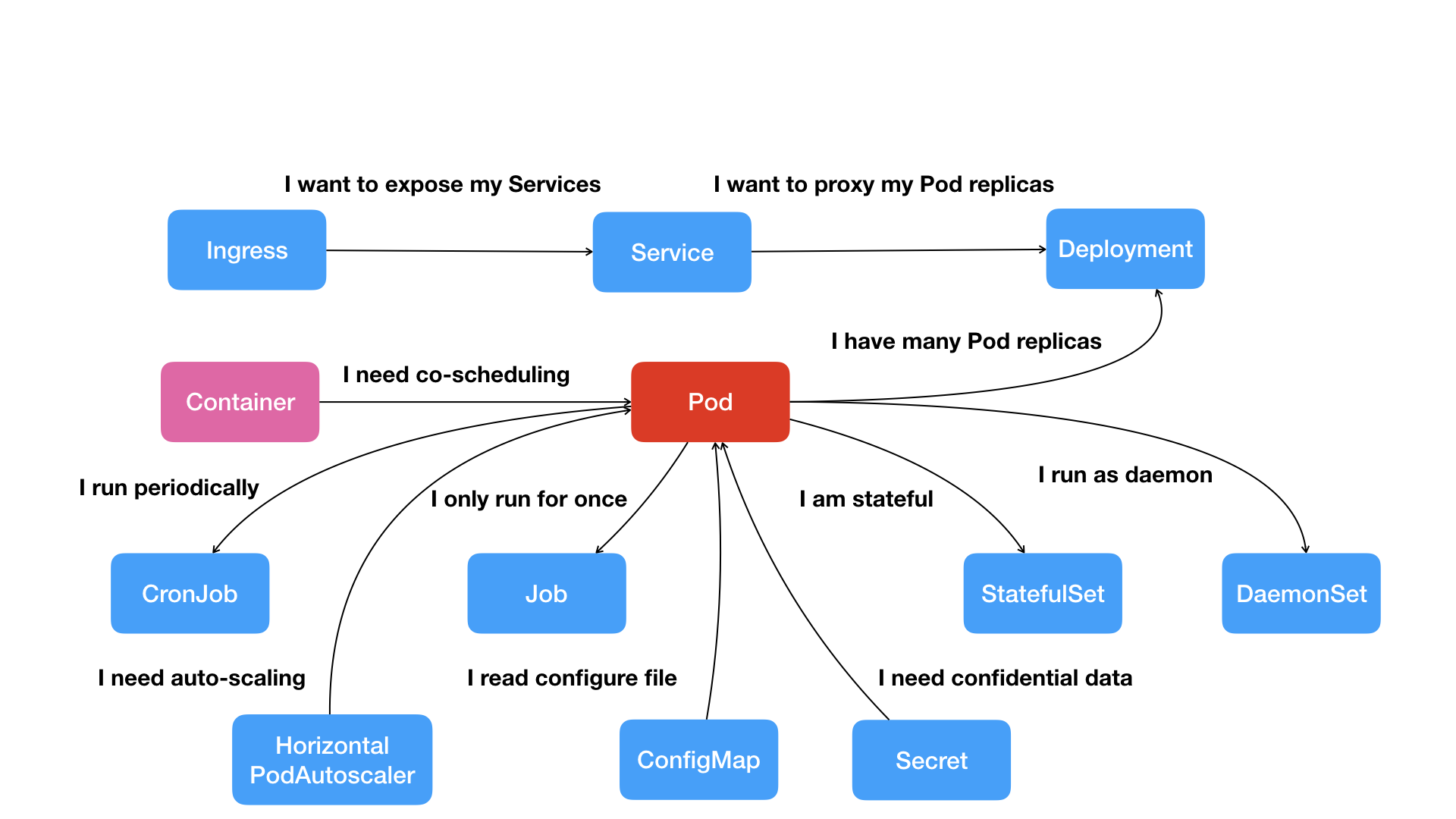
一文说清Kubernetes的本质
文章目录Kubernetes解决了什么问题?Kubernetes的全局架构Kubernetes的设计思想Kubernetes的核心功能Kubernetes如何启动一个容器化任务?Kubernetes解决了什么问题? 编排?调度?容器云?还是集群管理…...
信息发布小程序【源码好优多】
简介 信息发布小程序,实现数据与小程序数据同步共享,通过简单的配置就能搭建自己的小程序。,基于微信小程序开发的小程序。 这个框架比较简单就是用微信原生开发技术进行实现的,可以用于信息展示等相关信息。其中目前APP比较多&am…...

创新型中小企业申报流程
据工业和信息化部《优质中小企业梯度培育管理暂行办法》(工信部企业〔2022〕63号)和省《优质中小企业梯度培育管理实施细则》(鲁工信发〔2022〕8号,以下简称《细则》),现就做好2022年山东省创新型中小企业评…...
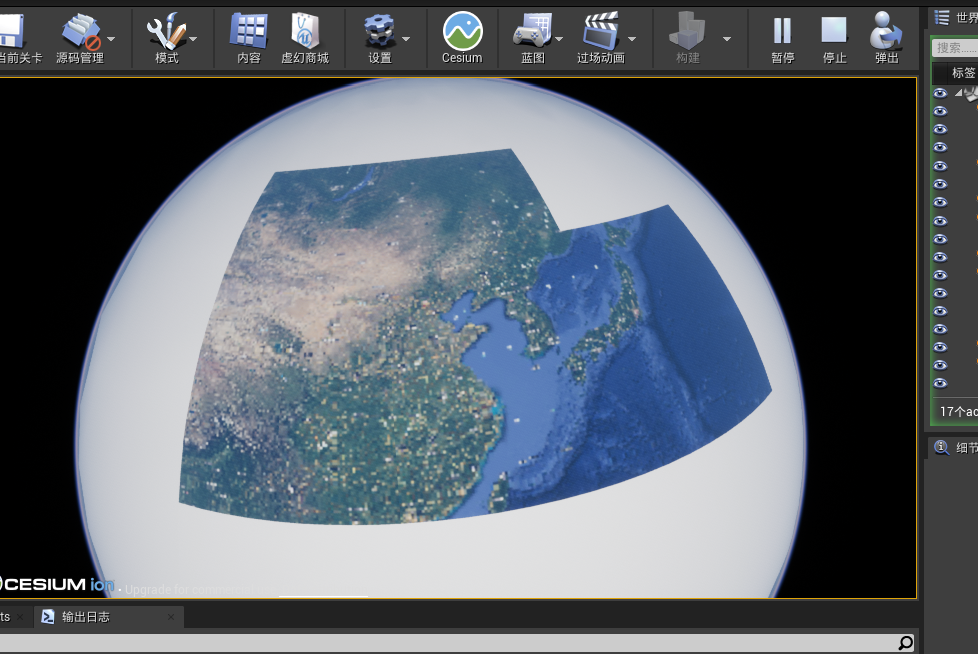
【UE4 Cesium】加载离线地图
主体思路:先使用水经注软件下载瓦片数据,再使用Python转换瓦片数据格式(TMS),使用Nginx发布网络服务,最后将网络服务加载到UE中。步骤:使用水经注下载瓦片数据,这里下载的是全球七级…...
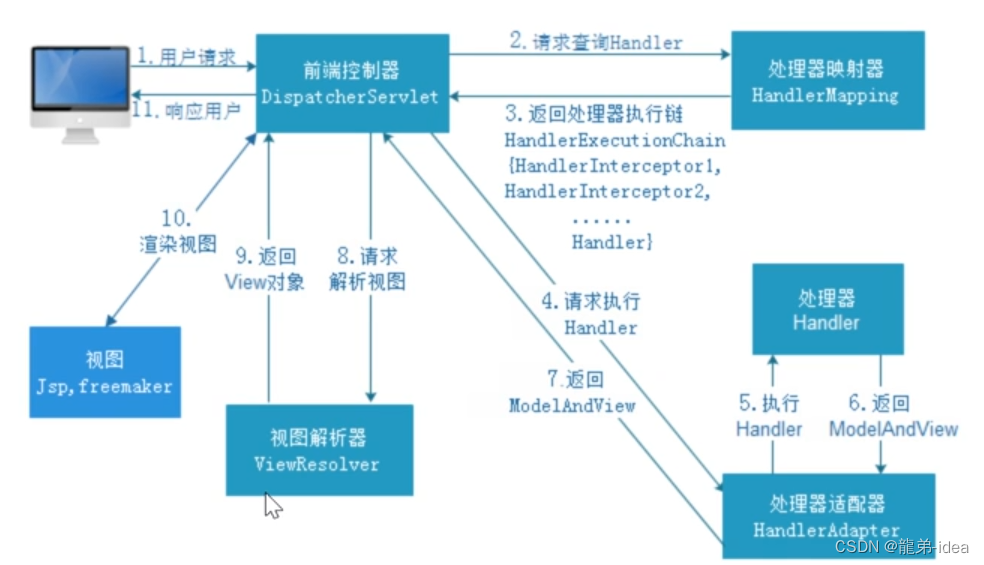
Spring面试题
目录 Spring、Springmvc、Springboot的区别是什么 SpringMVC工作流程是什么 SpringMVC的九大组件有哪些 Spring的核心是什么 spring的事务传播机制是什么 Spring框架中的单例Bean是线程安全的么 spring框架中使用了哪些设计模式及应用场景 spring事务的隔离级别有哪些?…...
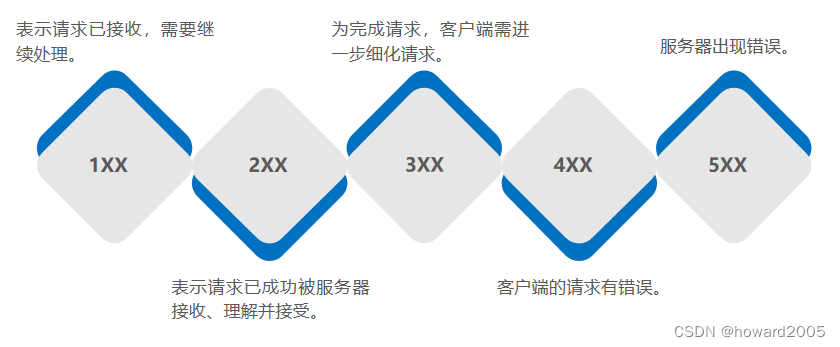
动态网站开发讲课笔记03:HTTP协议
文章目录零、本节学习目标一、HTTP概述(一)HTTP的概念1、HTTP的概念2、HTTP协议的特点(1)C/S模式(2)简单快速(3)灵活(4)无状态(二)HTT…...

Kubernetes容器运行时对比分析:选择最适合你的容器运行时
Kubernetes容器运行时对比分析:选择最适合你的容器运行时 一、容器运行时概述 容器运行时(Container Runtime) 是Kubernetes集群中负责运行容器的底层软件。它负责从镜像仓库拉取镜像、创建和管理容器进程、提供隔离环境等核心功能。 1.1 …...

影刀RPA跨境店群运营架构:Python高并发协同与Chromium多账号环境隔离实战
影刀RPA跨境店群运营架构:Python高并发协同与Chromium多账号环境隔离实战 架构师观察:流水线下的底层较量 近日,科技圈的头条毫无意外地被某头部视频生成大模型(被誉为 Seedance 2.0 最强对手)偷跑的内测演示视频彻底…...

抖音下载器:3分钟搞定批量下载,效率提升95%的秘密武器
抖音下载器:3分钟搞定批量下载,效率提升95%的秘密武器 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fal…...

网盘直链解析工具完整指南:告别下载限速,实现高速下载
网盘直链解析工具完整指南:告别下载限速,实现高速下载 【免费下载链接】netdisk-fast-download 聚合多种主流网盘的直链解析下载服务, 一键解析下载,已支持夸克网盘/uc网盘/蓝奏云/蓝奏优享/小飞机盘/123云盘等. 支持文件夹分享解析. 体验地址…...
)
告别虚拟机!手把手教你用U盘给新电脑装Win11+UOS 1060双系统(保姆级分区教程)
告别虚拟机!手把手教你用U盘给新电脑装Win11UOS 1060双系统(保姆级分区教程)刚拿到新电脑的开发者常面临一个两难选择:既需要Windows环境运行专业软件,又得适配国产操作系统完成兼容性测试。虚拟机虽然方便,…...

PearSAN框架:用PearSOL损失与VCA采样破解纳米光子学逆设计难题
1. 项目概述:当机器学习遇上纳米光子学逆设计在纳米光子学领域,我们常常面临一个“反着来”的工程难题:给定一个我们梦寐以求的光学性能目标,比如在特定波段实现近乎完美的光吸收,如何从浩如烟海的可能结构中ÿ…...

芯片设计文档查找与管理指南
1. 逻辑IP/标准单元/平台用户指南查找指南作为一名芯片设计工程师,我经常需要查阅各种工艺库和IP核的文档。最近有同事问我:"为什么在Logic IP库下载包里找不到用户指南?"这其实是个常见问题,我来分享一下我的经验。在芯…...

电信计费系统AI Agent重构实战:7天完成规则引擎迁移,零业务中断验证报告
更多请点击: https://intelliparadigm.com 第一章:电信计费系统AI Agent重构实战:7天完成规则引擎迁移,零业务中断验证报告 传统电信计费系统长期依赖硬编码规则引擎(如 Drools 7.10),平均响应…...

【AI Agent游戏行业应用实战指南】:20年资深架构师亲授7大落地场景与避坑清单
更多请点击: https://intelliparadigm.com 第一章:AI Agent游戏行业应用全景图谱 AI Agent 正在重塑游戏开发、运营与玩家体验的全生命周期。从智能NPC的行为建模,到自动化测试与关卡生成,再到实时个性化内容推荐与跨平台玩家陪伴…...
)
保姆级教程:在Ubuntu 22.04上从源码编译COLMAP 3.9(含6个常见Bug解决方案)
在Ubuntu 22.04上从源码编译COLMAP 3.9的终极避坑指南三维重建技术正在重塑数字世界的构建方式,而COLMAP作为开源领域的标杆工具,其强大的多视图几何算法让学术研究和工业应用都受益匪浅。但当你第一次尝试在Ubuntu系统上编译这个工具时,可能…...