一文说清Kubernetes的本质
文章目录
- Kubernetes解决了什么问题?
- Kubernetes的全局架构
- Kubernetes的设计思想
- Kubernetes的核心功能
- Kubernetes如何启动一个容器化任务?
Kubernetes解决了什么问题?
编排?调度?容器云?还是集群管理?
实际上,这个问题到目前为止都没有固定的答案。因为在不同的发展阶段,Kubernetes 需要着重解决的问题是不同的。
但是,对于大多数用户来说,他们希望 Kubernetes 项目带来的体验是确定的:现在我有了应用的容器镜像,请帮我在一个给定的集群上把这个应用运行起来。
更进一步地说,我还希望 Kubernetes 能给我提供路由网关、水平扩展、监控、备份、灾难恢复等一系列运维能力。
等一下,这些功能听起来好像有些耳熟?这不就是经典 PaaS(比如,Cloud Foundry)项目的能力吗?
而且,有了 Docker 之后,我根本不需要什么 Kubernetes、PaaS,只要使用 Docker 公司的 Compose+Swarm 项目,就完全可以很方便地 DIY 出这些功能了!
所以说,如果 Kubernetes 项目只是停留在拉取用户镜像、运行容器,以及提供常见的运维功能的话,那么别说跟“原生”的 Docker Swarm 项目竞争了,哪怕跟经典的 PaaS 项目相比也难有什么优势可言。
Kubernetes的全局架构
实际上,在定义核心功能的过程中,Kubernetes 项目正是依托着 Borg 项目的理论优势,才在短短几个月内迅速站稳了脚跟,进而确定了一个如下图所示的全局架构:
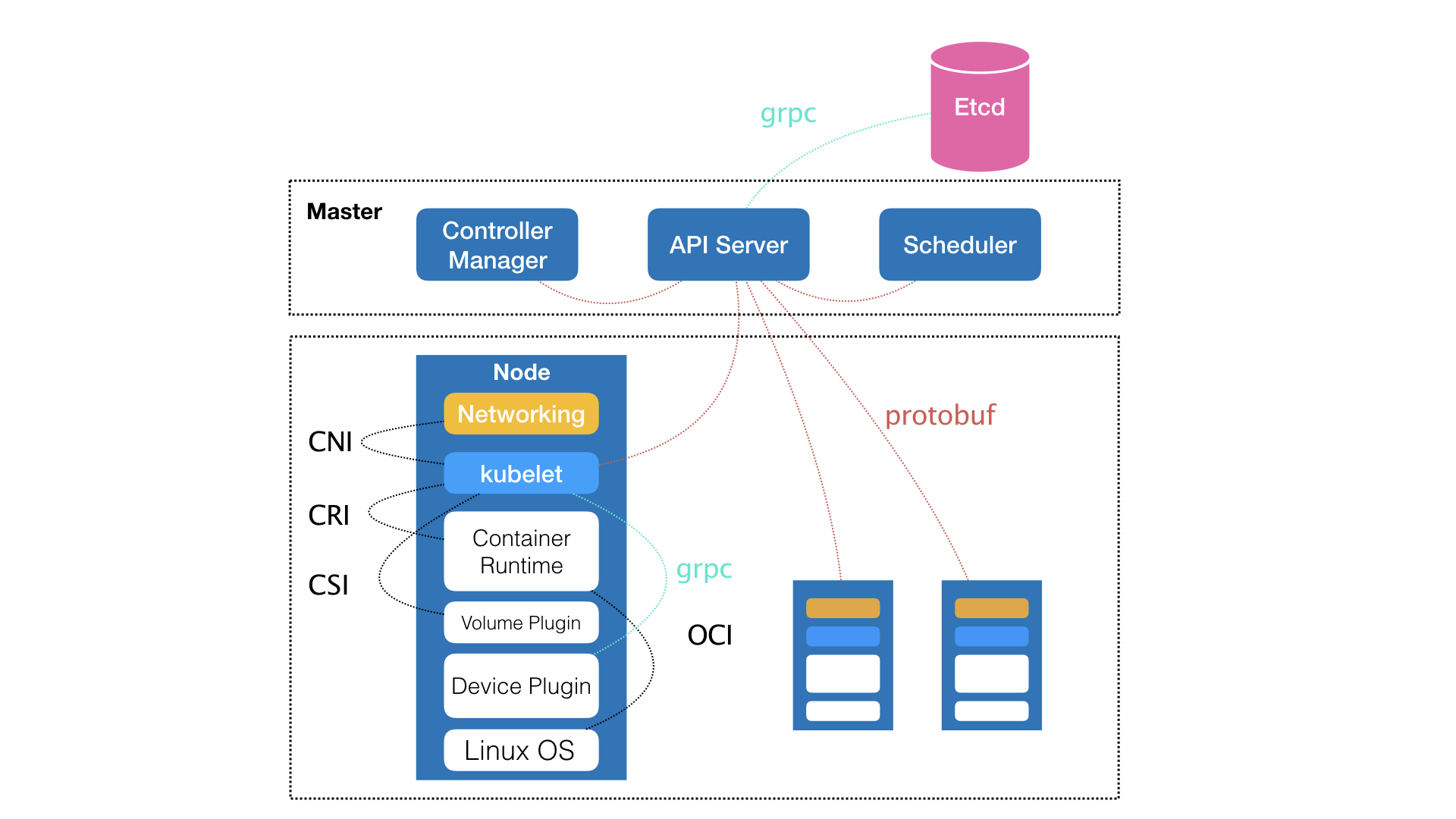
可以看到,Kubernetes 项目的架构由 Master 和 Node 两种节点组成,而这两种角色分别对应着控制节点和计算节点。
其中,控制节点,即 Master 节点,由三个紧密协作的独立组件组合而成,它们分别是负责 API 服务的 kube-apiserver、负责调度的 kube-scheduler,以及负责容器编排的 kube-controller-manager。整个集群的持久化数据,则由 kube-apiserver 处理后保存在 Etcd 中。
而计算节点上最核心的部分,则是一个叫作 kubelet 的组件。
在 Kubernetes 项目中,kubelet 主要负责同容器运行时(比如 Docker 项目)打交道。而这个交互所依赖的,是一个称作 CRI(Container Runtime Interface)的远程调用接口,这个接口定义了容器运行时的各项核心操作,比如:启动一个容器需要的所有参数。
这也是为何,Kubernetes 项目并不关心你部署的是什么容器运行时、使用的什么技术实现,只要你的这个容器运行时能够运行标准的容器镜像,它就可以通过实现 CRI 接入到 Kubernetes 项目当中。
而具体的容器运行时,比如 Docker 项目,则一般通过 OCI 这个容器运行时规范同底层的 Linux 操作系统进行交互,即:把 CRI 请求翻译成对 Linux 操作系统的调用(操作 Linux Namespace 和 Cgroups 等)。
此外,kubelet 还通过 gRPC 协议同一个叫作 Device Plugin 的插件进行交互。这个插件,是 Kubernetes 项目用来管理 GPU 等宿主机物理设备的主要组件,也是基于 Kubernetes 项目进行机器学习训练、高性能作业支持等工作必须关注的功能。
而 kubelet 的另一个重要功能,则是调用网络插件和存储插件为容器配置网络和持久化存储。这两个插件与 kubelet 进行交互的接口,分别是 CNI(Container Networking Interface)和 CSI(Container Storage Interface)。
总结:
- CRI(Container Runtime Interface):主要负责同容器运行时打交道
- CNI(Container Networking Interface):调用网络插件为容器配置网络
- CSI(Container Storage Interface):调用存储插件为容器做持久化存储
Kubernetes的设计思想
从一开始,Kubernetes 项目就没有像同时期的各种“容器云”项目那样,把 Docker 作为整个架构的核心,而仅仅把它作为最底层的一个容器运行时实现。
而 Kubernetes 项目要着重解决的问题,则来自于 Borg 的研究人员在论文中提到的一个非常重要的观点:
运行在大规模集群中的各种任务之间,实际上存在着各种各样的关系。这些关系的处理,才是作业编排和管理系统最困难的地方。
事实也正是如此。
其实,这种任务与任务之间的关系,在我们平常的各种技术场景中随处可见。比如,一个 Web 应用与数据库之间的访问关系,一个负载均衡器和它的后端服务之间的代理关系,一个门户应用与授权组件之间的调用关系。更进一步地说,同属于一个服务单位的不同功能之间,也完全可能存在这样的关系。比如,一个 Web 应用与日志搜集组件之间的文件交换关系。
而在容器技术普及之前,传统虚拟机环境对这种关系的处理方法都是比较“粗粒度”的。你会经常发现很多功能并不相关的应用被一股脑儿地部署在同一台虚拟机中,只是因为它们之间偶尔会互相发起几个 HTTP 请求。更常见的情况则是,一个应用被部署在虚拟机里之后,你还得手动维护很多跟它协作的守护进程(Daemon),用来处理它的日志搜集、灾难恢复、数据备份等辅助工作。
容器技术出现以后,你就不难发现,在“功能单位”的划分上,容器有着独一无二的“细粒度”优势:毕竟容器的本质,只是一个进程而已。
也就是说,只要你愿意,那些原先拥挤在同一个虚拟机里的各个应用、组件、守护进程,都可以被分别做成镜像,然后运行在一个个专属的容器中。它们之间互不干涉,拥有各自的资源配额,可以被调度在整个集群里的任何一台机器上。而这,正是一个 PaaS 系统最理想的工作状态,也是所谓“微服务”思想得以落地的先决条件。
当然,如果只做到“封装微服务、调度单容器”这一层次,Docker Swarm 项目就已经绰绰有余了。如果再加上 Compose 项目,你甚至还具备了处理一些简单依赖关系的能力,比如:一个“Web 容器”和它要访问的数据库“DB 容器”。
这种单独针对一种案例设计的解决方案就太过简单了。如果你做过架构方面的工作,就会深有感触:一旦要追求项目的普适性,那就一定要从顶层开始做好设计。
所以,Kubernetes 项目最主要的设计思想是,从更宏观的角度,以统一的方式来定义任务之间的各种关系,并且为将来支持更多种类的关系留有余地。
比如,Kubernetes 项目对容器间的“访问”进行了分类,首先总结出了一类非常常见的“紧密交互”的关系,即:这些应用之间需要非常频繁的交互和访问;又或者,它们会直接通过本地文件进行信息交换。
在常规环境下,这些应用往往会被直接部署在同一台机器上,通过 Localhost 通信,通过本地磁盘目录交换文件。而在 Kubernetes 项目中,这些容器则会被划分为一个“Pod”,Pod 里的容器共享同一个 Network Namespace、同一组数据卷,从而达到高效率交换信息的目的。
Pod 是 Kubernetes 项目中最基础的一个对象,源自于 Google Borg 论文中一个名叫 Alloc 的设计。在后续的文章中,我们会对 Pod 做更进一步地阐述。
而对于另外一种更为常见的需求,比如 Web 应用与数据库之间的访问关系,Kubernetes 项目则提供了一种叫作“Service”的服务。像这样的两个应用,往往故意不部署在同一台机器上,这样即使 Web 应用所在的机器宕机了,数据库也完全不受影响。可是,我们知道,对于一个容器来说,它的 IP 地址等信息不是固定的,那么 Web 应用又怎么找到数据库容器的 Pod 呢?
所以,Kubernetes 项目的做法是给 Pod 绑定一个 Service 服务,而 Service 服务声明的 IP 地址等信息是“终生不变”的。这个Service 服务的主要作用,就是作为 Pod 的代理入口(Portal),从而代替 Pod 对外暴露一个固定的网络地址。
这样,对于 Web 应用的 Pod 来说,它需要关心的就是数据库 Pod 的 Service 信息。不难想象,Service 后端真正代理的 Pod 的 IP 地址、端口等信息的自动更新、维护,才是 Kubernetes 项目的职责。
Kubernetes的核心功能
像这样,围绕着容器和 Pod 不断向真实的技术场景扩展,我们就能够摸索出一幅如下所示的 Kubernetes 项目核心功能的“全景图”。
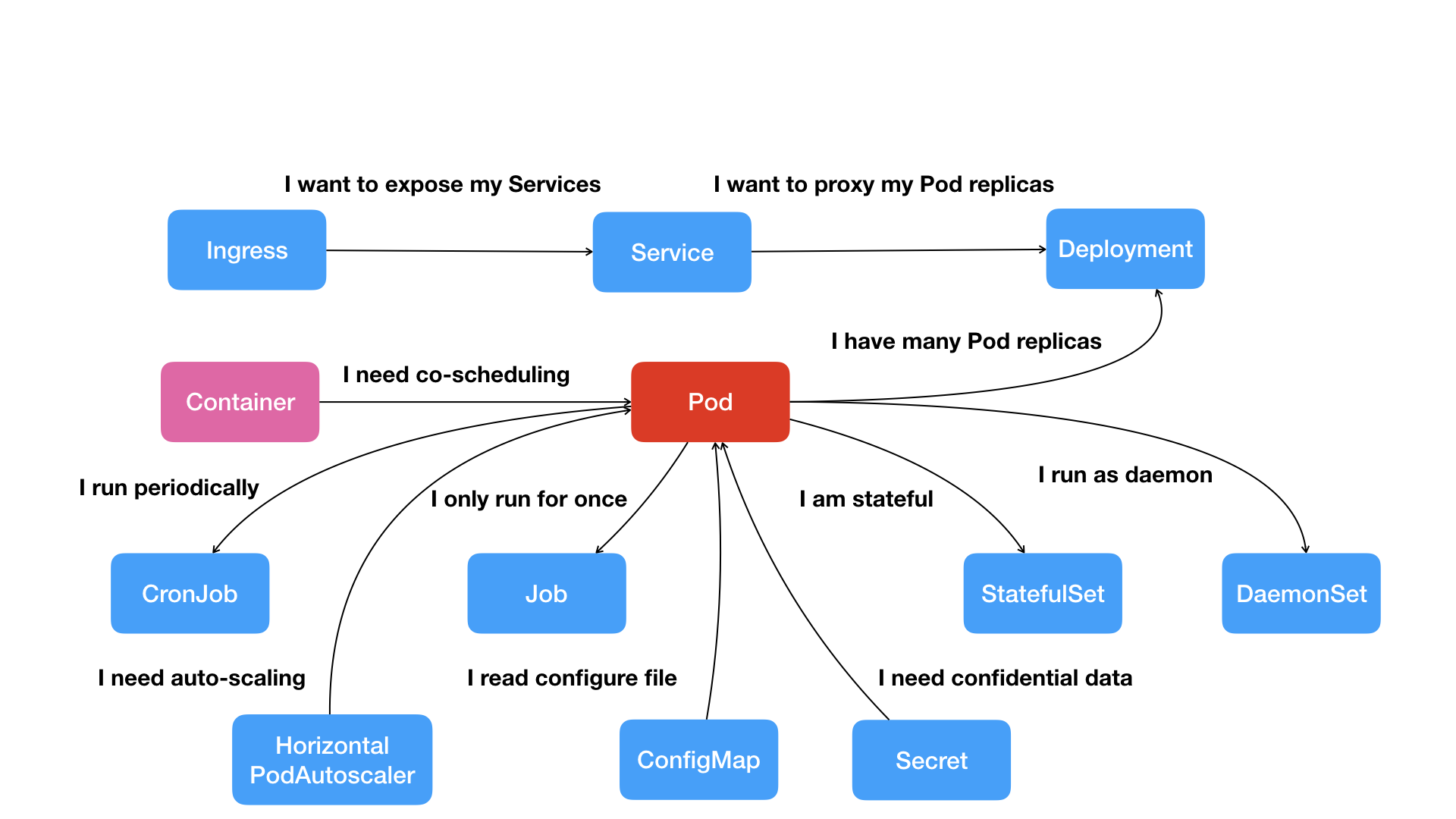
按照这幅图的线索,我们从容器这个最基础的概念出发,首先遇到了容器间“紧密协作”关系的难题,于是就扩展到了 Pod;有了 Pod 之后,我们希望能一次启动多个应用的实例,这样就需要 Deployment 这个 Pod 的多实例管理器;而有了这样一组相同的 Pod 后,我们又需要通过一个固定的 IP 地址和端口以负载均衡的方式访问它,于是就有了 Service。
可是,如果现在两个不同 Pod 之间不仅有“访问关系”,还要求在发起时加上授权信息。最典型的例子就是 Web 应用对数据库访问时需要 Credential(数据库的用户名和密码)信息。那么,在 Kubernetes 中这样的关系又如何处理呢?
Kubernetes 项目提供了一种叫作 Secret 的对象,它其实是一个保存在 Etcd 里的键值对数据。这样,你把 Credential 信息以 Secret 的方式存在 Etcd 里,Kubernetes 就会在你指定的 Pod(比如,Web 应用的 Pod)启动时,自动把 Secret 里的数据以 Volume 的方式挂载到容器里。这样,这个 Web 应用就可以访问数据库了。
除了应用与应用之间的关系外,应用运行的形态是影响“如何容器化这个应用”的第二个重要因素。
为此,Kubernetes 定义了新的、基于 Pod 改进后的对象。比如 Job,用来描述一次性运行的 Pod(比如,大数据任务);再比如 DaemonSet,用来描述每个宿主机上必须且只能运行一个副本的守护进程服务;又比如 CronJob,则用于描述定时任务等等。
如此种种,正是 Kubernetes 项目定义容器间关系和形态的主要方法。
可以看到,Kubernetes 项目并没有像其他项目那样,为每一个管理功能创建一个指令,然后在项目中实现其中的逻辑。这种做法,的确可以解决当前的问题,但是在更多的问题来临之后,往往会力不从心。
相比之下,在 Kubernetes 项目中,我们所推崇的使用方法是:
- 首先,通过一个“编排对象”,比如 Pod、Job、CronJob 等,来描述你试图管理的应用;
- 然后,再为它定义一些“服务对象”,比如 Service、Secret、Horizontal Pod Autoscaler(自动水平扩展器)等。这些对象,会负责具体的平台级功能。
这种使用方法,就是所谓的“声明式 API”。这种 API 对应的“编排对象”和“服务对象”,都是 Kubernetes 项目中的 API 对象(API Object)。
这就是 Kubernetes 最核心的设计理念。
Kubernetes如何启动一个容器化任务?
比如,我现在已经制作好了一个 Nginx 容器镜像,希望让平台帮我启动这个镜像。并且,我要求平台帮我运行两个完全相同的 Nginx 副本,以负载均衡的方式共同对外提供服务。
如果是自己 DIY 的话,可能需要启动两台虚拟机,分别安装两个 Nginx,然后使用 keepalived 为这两个虚拟机做一个虚拟 IP。
而如果使用 Kubernetes 项目呢?你需要做的则是编写如下这样一个 YAML 文件(比如名叫 nginx-deployment.yaml):
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deploymentlabels:app: nginx
spec:replicas: 2selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.7.9ports:- containerPort: 80
在上面这个 YAML 文件中,我们定义了一个 Deployment 对象,它的主体部分(spec.template 部分)是一个使用 Nginx 镜像的 Pod,而这个 Pod 的副本数是 2(replicas=2)。
然后执行:
$ kubectl create -f nginx-deployment.yaml
这样,两个完全相同的 Nginx 容器副本就被启动了。
笔记来源于:极客时间《深入剖析Kubernetes》
相关文章:
一文说清Kubernetes的本质
文章目录Kubernetes解决了什么问题?Kubernetes的全局架构Kubernetes的设计思想Kubernetes的核心功能Kubernetes如何启动一个容器化任务?Kubernetes解决了什么问题? 编排?调度?容器云?还是集群管理…...
信息发布小程序【源码好优多】
简介 信息发布小程序,实现数据与小程序数据同步共享,通过简单的配置就能搭建自己的小程序。,基于微信小程序开发的小程序。 这个框架比较简单就是用微信原生开发技术进行实现的,可以用于信息展示等相关信息。其中目前APP比较多&am…...

创新型中小企业申报流程
据工业和信息化部《优质中小企业梯度培育管理暂行办法》(工信部企业〔2022〕63号)和省《优质中小企业梯度培育管理实施细则》(鲁工信发〔2022〕8号,以下简称《细则》),现就做好2022年山东省创新型中小企业评…...
【UE4 Cesium】加载离线地图
主体思路:先使用水经注软件下载瓦片数据,再使用Python转换瓦片数据格式(TMS),使用Nginx发布网络服务,最后将网络服务加载到UE中。步骤:使用水经注下载瓦片数据,这里下载的是全球七级…...
Spring面试题
目录 Spring、Springmvc、Springboot的区别是什么 SpringMVC工作流程是什么 SpringMVC的九大组件有哪些 Spring的核心是什么 spring的事务传播机制是什么 Spring框架中的单例Bean是线程安全的么 spring框架中使用了哪些设计模式及应用场景 spring事务的隔离级别有哪些?…...
动态网站开发讲课笔记03:HTTP协议
文章目录零、本节学习目标一、HTTP概述(一)HTTP的概念1、HTTP的概念2、HTTP协议的特点(1)C/S模式(2)简单快速(3)灵活(4)无状态(二)HTT…...

2023年天津财经大学珠江学院专升本专业课考试题型
天津财经大学珠江学院关于2023年高职升本科专业课考试时间及题型一、专业课考试 (一)时间安排 2023年天津财经大学珠江学院高职升本科专业课考试定于2023年3月25日14:00-17:00进行,凡报考工商管理、旅游管理、税收学专业的考生&am…...

五方面提高销售流程管理的CRM系统
销售充满了不确定性,面对不同的客户,销售人员需要采用不同的销售策略。也正因为这种不确定性,规范的销售流程对企业尤为重要,它会让销售工作更加有效,快速地实现成交。下面小编给您推荐个不错的CRM销售流程管理系统。 …...

AutoCAD通过handle id选择实体
获得实体的handle id。注意是handle id 不是id,方法有2种:方法(a):通过ArxDeg插件(ObjectARX附带的源码编译得到:\samples\database\ARXDBG)查找:此handle id本来就是16进…...
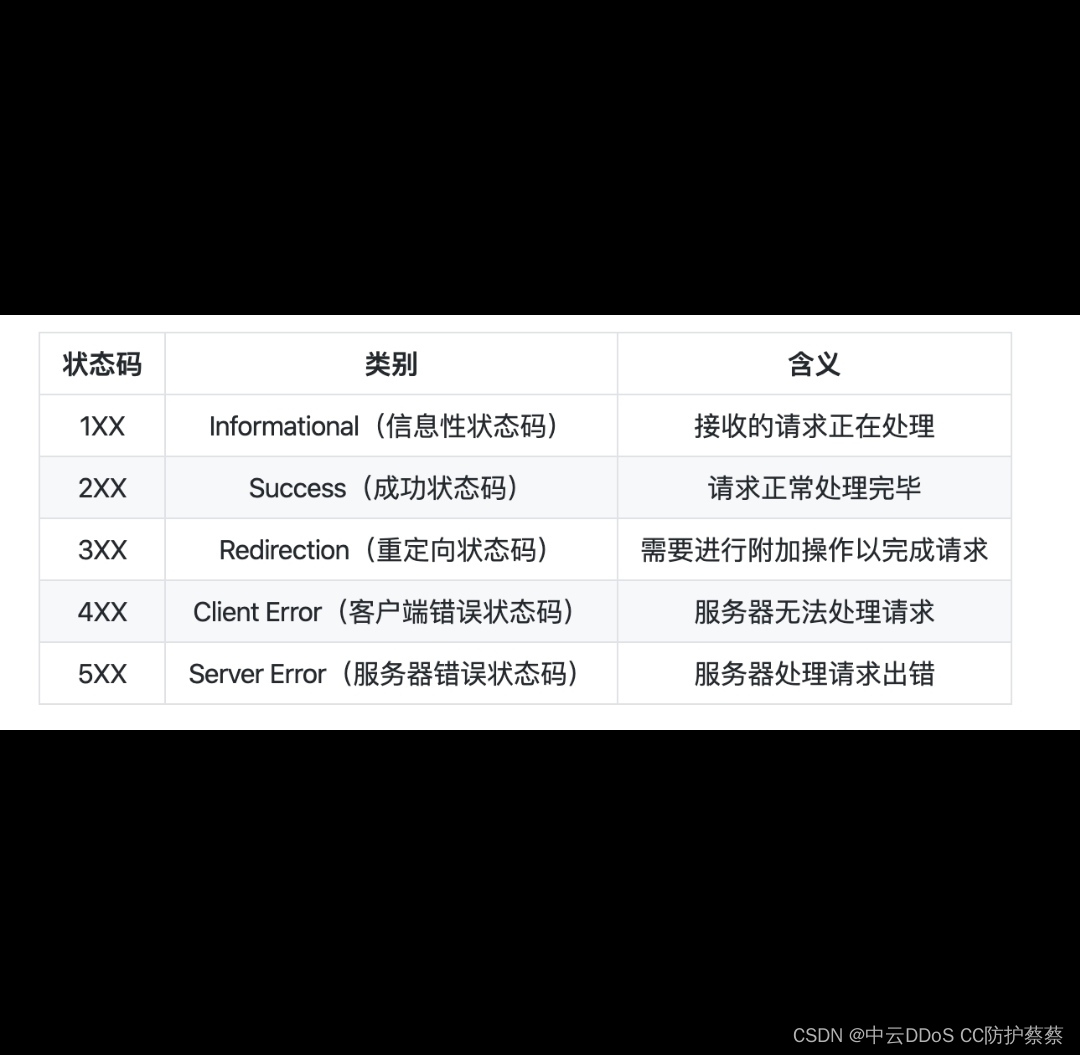
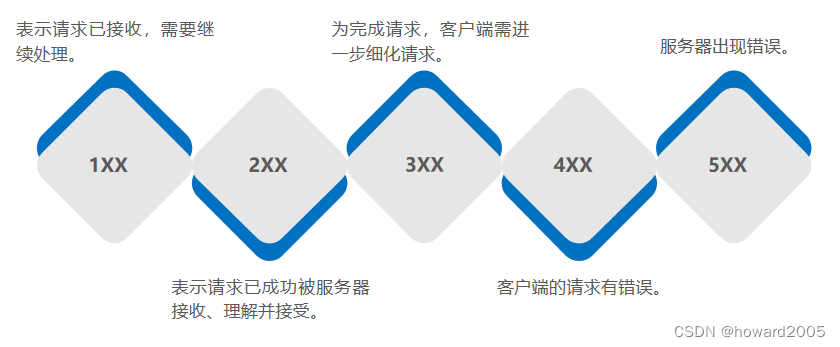
页面状态码的含义
使用互联网产品或服务的过程中,会遇到网页报错的情况, 比如404、505等,具体这些数字有什么含义呢?本文基本涵盖了99%的报错情况,可供大家查询使用。 状态码的定义 状态码一般是由3位数字和原因短语组成的(…...

Redis 越来越慢?常见延迟问题定位与分析
Redis作为内存数据库,拥有非常高的性能,单个实例的QPS能够达到10W左右。但我们在使用Redis时,经常时不时会出现访问延迟很大的情况,如果你不知道Redis的内部实现原理,在排查问题时就会一头雾水。很多时候,R…...
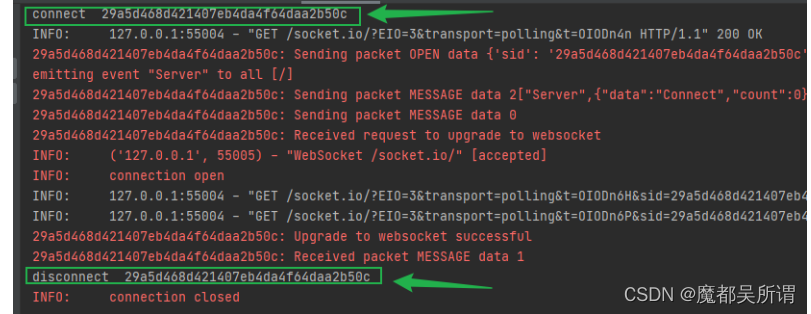
【python】python-socketio+firecamp使用踩坑指南
server.py: import eventlet import asyncioeventlet.monkey_patch()import socketio import eventlet.wsgisio socketio.Server(async_modeeventlet, cors_allowed_origins*) # 指明在evenlet模式下sio.event def connect(sid, environ):print(f"connect, sid{sid}, e…...
【OJ比赛日历】快周末了,不来一场比赛吗? #03.04-03.10 #12场
CompHub 实时聚合多平台的数据类(Kaggle、天池…)和OJ类(Leetcode、牛客…)比赛。本账号同时会推送最新的比赛消息,欢迎关注!更多比赛信息见 CompHub主页 或 点击文末阅读原文以下信息仅供参考,以比赛官网为准目录2023-03-04&…...

C++11:继承
目录 继承的基本概念 继承方式 基类和派生类对象赋值转换/切片 继承中的作用域 派生类的四个成员函数: 构造函数 拷贝构造函数 赋值重载 析构函数 静态成员 继承与友元 多继承 菱形继承 多继承的指针偏移问题 组合 继承的基本概念 继承出现的契机是某一…...
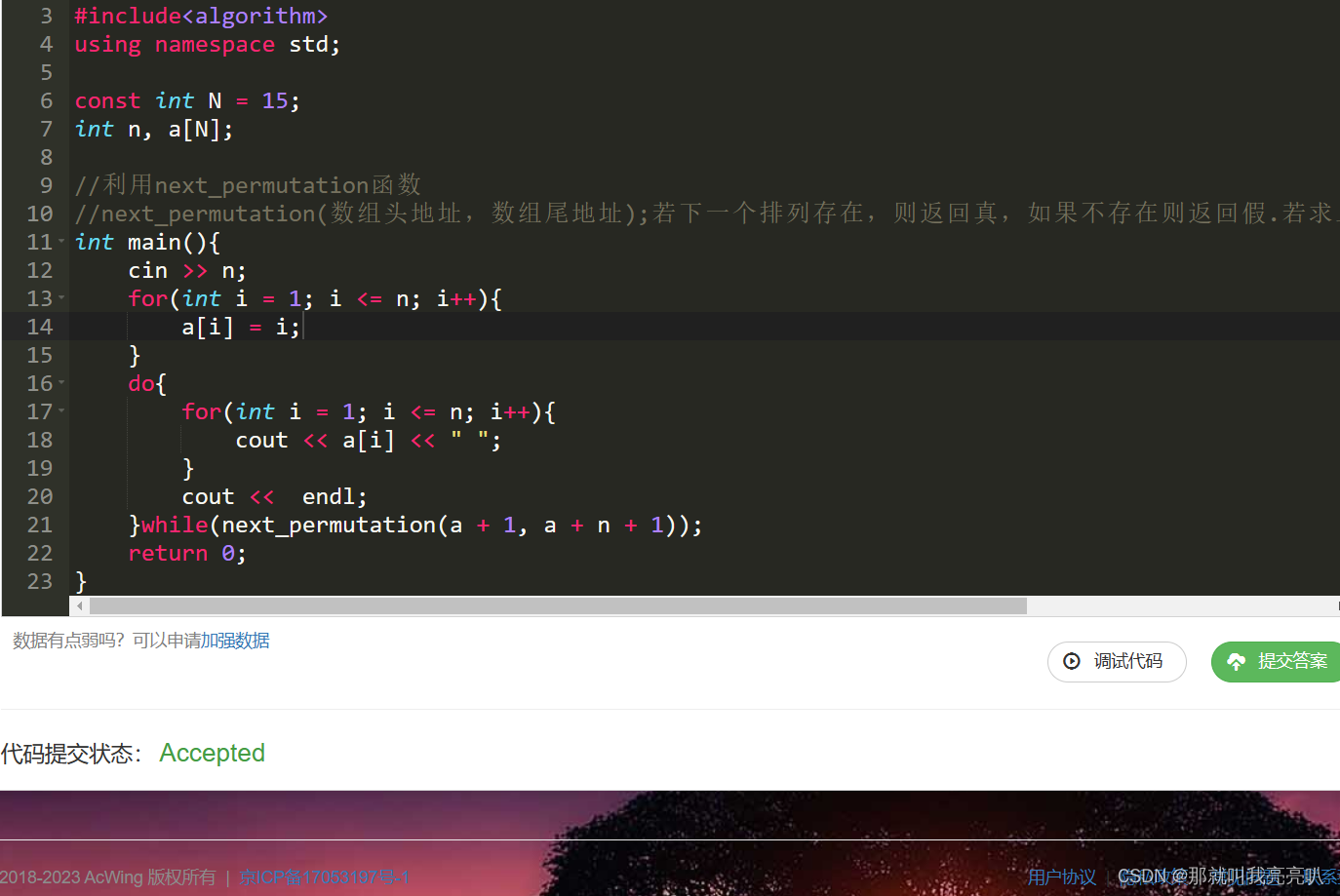
【蓝桥杯试题】递归实现排列型枚举
💃🏼 本人简介:男 👶🏼 年龄:18 🤞 作者:那就叫我亮亮叭 📕 专栏:蓝桥杯试题 文章目录1. 题目描述2. 代码展示法一:dfs法二:next_perm…...
入职字节测试岗外包一个月,我离职了...
有一种打工人的羡慕,叫做“大厂”。真是年少不知大厂香,错把青春插稻秧。但是,在深圳有一群比大厂员工更庞大的群体,他们顶着大厂的“名”,做着大厂的工作,还可以享受大厂的伙食,却没有大厂的“…...

weak学习入门-01
作用:集中在特征提取、算法选择和参数调优上 本篇几乎是汇总了大佬的参考 官网https://www.cs.waikato.ac.nz/ml/weka 大佬的入门教程:初试weka数据挖掘 - 加拿大小哥哥 - 博客园 (cnblogs.com) 参考书:数据挖掘实用机器学习技术(原书第2版)...

线程池中shutdown()和shutdownNow()方法的区别
线程池中shutdown()和shutdownNow()方法的区别 一般情况下,当我们频繁的使用线程的时候,为了节约资源快速响应需求,我们都会考虑使用线程池,线程池使用完毕都会想着关闭,关闭的时候一般情况下会用到shutdown和shutdow…...
高可用/性能
文章目录1.数据库系统架构发展(1)单库架构(2)主备架构(3)主从架构2.主从复制主从同步配置主从复制模式(1)异步复制(2)半同步复制(3)全…...

PriorityQueues优先队列
优先队列优先队列(priority queue)是计算机科学中的一类抽象数据类型。优先队列中的每个元素都有各自的优先级,优先级最高的元素最先得到服务;优先级相同的元素按照其在优先队列中的顺序得到服务。优先队列通常使用“堆”…...

为什么说Full Page Screen Capture是Chrome网页截图的终极解决方案?
为什么说Full Page Screen Capture是Chrome网页截图的终极解决方案? 【免费下载链接】full-page-screen-capture-chrome-extension One-click full page screen captures in Google Chrome 项目地址: https://gitcode.com/gh_mirrors/fu/full-page-screen-capture…...

<项目代码>yolo缆绳识别<目标检测>
项目代码下载链接 YOLOv8是一种单阶段(one-stage)检测算法,它将目标检测问题转化为一个回归问题,能够在一次前向传播过程中同时完成目标的分类和定位任务。相较于两阶段检测算法(如Faster R-CNN)࿰…...

如何快速掌握开源笔记工具:Xournal++ 终极使用指南
如何快速掌握开源笔记工具:Xournal 终极使用指南 【免费下载链接】xournalpp Xournal is a handwriting notetaking software with PDF annotation support. Written in C with GTK3, supporting Linux (e.g. Ubuntu, Debian, Arch, SUSE), macOS and Windows 10. S…...
3分钟掌握Translumo:免费实时屏幕翻译工具终极指南
3分钟掌握Translumo:免费实时屏幕翻译工具终极指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否曾经…...

如何在Windows上快速安装苹果设备驱动:告别连接烦恼的完整指南
如何在Windows上快速安装苹果设备驱动:告别连接烦恼的完整指南 【免费下载链接】Apple-Mobile-Drivers-Installer Powershell script to easily install Apple USB and Mobile Device Ethernet (USB Tethering) drivers on Windows! 项目地址: https://gitcode.co…...

Bun Image:无需 npm 依赖的图像处理管道,支持多格式解码与转换!
1. Bun Image 是什么? Bun Image 是一个可链式调用的图像处理管道,用于对 JPEG、PNG、WebP、HEIC 和 AVIF 图像进行解码、调整大小、旋转和重新编码。它基于 libjpeg - turbo、spng、libwebp 和 SIMD 几何内核构建,无需 npm 依赖,…...

QKeyMapper终极指南:免费开源按键映射工具,5分钟让你的键盘鼠标手柄随心所欲
QKeyMapper终极指南:免费开源按键映射工具,5分钟让你的键盘鼠标手柄随心所欲 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支…...

基于SVD/HOSVD与DLinear的流体场高分辨率预测模型解析
1. 项目概述:当流体动力学遇上智能预测在计算流体动力学(CFD)和科学机器学习(SciML)的交叉领域,我们每天都在和数据洪流搏斗。一次高保真度的湍流模拟,动辄产生TB级的高维时空数据——速度场、压…...

机器学习势函数与反向蒙特卡洛在GeO2玻璃中程有序结构解析中的对比研究
1. 项目概述:当机器学习势函数遇上反向蒙特卡洛在材料模拟的世界里,我们常常面临一个两难选择:是相信基于物理化学原理构建的“经验”模型,还是完全服从实验数据的“拟合”结果?这个问题在网络形成玻璃,比如…...

PXE安装麒麟Kylin后,我用这个脚本搞定了软件源、远程桌面和sudo免密
PXE安装麒麟Kylin后的高效配置脚本实战指南当你通过PXE完成麒麟Kylin系统的无人值守安装后,系统往往处于"毛坯房"状态——基础框架有了,但离真正的生产环境还有距离。本文将分享一个名为.kylin-post-actions的神奇脚本,它能帮你一键…...