阿里开源自研高性能核心搜索引擎 Havenask
去年12月,阿里开源了自研的大规模分布式搜索引擎 Havenask(内部代号 HA3)。
Havenask 是阿里巴巴内部广泛使用的大规模分布式检索系统,支持了淘宝、天猫、菜鸟、优酷、高德、饿了么等在内整个阿里的搜索业务,是过去十多年阿里在电商领域积累下来的核心竞争力产品。
大数据时代,数据检索是必备的基础能力。Havenask 支持千亿级别数据实时检索、百万 QPS 查询,百万 TPS 高时效性写入保障,毫秒级查询延迟和数据更新。并具有良好的分布式架构、极致的性能优化,能够实现比现有技术方案更低的成本,帮助企业降本提效。
开源地址:http://github.com/alibaba/havenask
一、应用在阿里核心场景的搜索引擎
Havenask 主要是作为高性能 AI 智能引擎,应用在搜索、推荐和广告等最典型的 AI 场景,比如淘宝、天猫 App 的首页搜索框、首页拍照搜索、首页信息流、逛逛等。
在这个场景中,工程引擎需要支持好算法团队快速 AB 实验、快速优化迭代,做到算法优化分钟级上线;并在机器资源可控,成本可接受前提下,支持算法团队实验千亿级参数、超大模型,极致优化算法效果。算法效果的好坏直接影响客户体验,影响用户的留存、购买转化、以及广告效率。因此,Havenask 对电商业务的增长起关键作用。
以手机淘宝 App 首页的拍立淘(拍照搜商品)为例,我们对感兴趣的物品随手拍一张照片,利用这张图片,在拍立淘中搜索,淘宝就会从数十亿商品中找到一样或者类似的商品。这也是典型的向量计算场景。数十亿数据,高纬度向量计算,需要 Havenask 具备实时、高性能、低成本特性,才能实现实时无延迟的搜索体验。
Havenask 另外一个应用场景是大数据检索,比如淘宝 App 中订单检索、物流信息、优惠券发放使用等,本质上都是关键词附加多条件的检索。
传统的做法是基于数据库来实现。但在这种场景中,数据量至少是 TB、PB 规模。当数据规模特别大,高并发更新和查询操作,会给数据库性能带来较大的瓶颈,成本上也会有比较大的挑战。而基于 Havenask 搜索引擎技术,可实现千亿级数据,秒级时效性,毫秒级查询延迟,为用户提供顺滑的用户体验,成本也远低于数据库方案。
以淘宝优惠券为例,淘宝有数千万商家、数亿消费者,会有大量优惠券的发放和使用,优惠券的状态变更也具有实时性,因此优惠券的发放、使用和结算,要做到好的体验,必须准确、实时。这不是一件容易的事情,对系统性能的要求非常高,成本也不会低。但依赖 Havenask,就能以低成本实现千亿级数据查询、秒级时效性、毫秒级查询延迟。
二、阿里巴巴内部十余年的沉淀
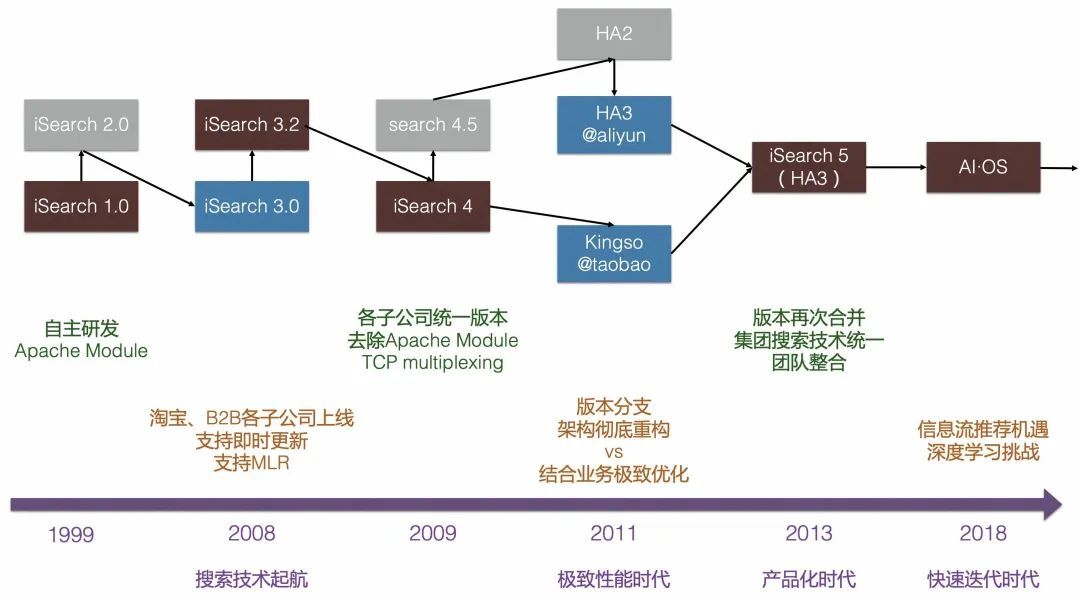
阿里电商搜索早期是以 Apache http server module 的形式实现,支持淘宝、B2B 等子公司搜索业务,一个业务一个版本分支,与业务逻辑深度耦合。因此大概从 2009 年开始,阿里支持业务的同时,组建了一支小队伍,从零开始重写整个搜索系统。
2011 年,新系统完成研发,替代雅虎老的网页搜索系统完成上线,开启自研大规模分布式高性能搜索引擎时代。当时内部代号“问天引擎”(HA3),后来随着组织架构调整成为今天的 UC 神马搜索。
上线自研引擎之后,经过一两年的时间,阿里将多个老引擎分支做了统一。问天引擎开始支持集团几乎所有搜索业务,包括淘宝、天猫等,以统一代码分支和产品化、规模化的方式支持集团大量搜索业务。搜索技术团队也统一到了一起,以极致性能优化、分布式、高可用、运维友好为目标不断打磨这个搜索产品。
2016 年,随着深度学习技术广泛应用,电商领域迎来信息流推荐的新机遇,也给工程引擎带来新的挑战。从这时开始,阿里在信息流推进的基础上,将原来的 HA3 体系发展成了阿里集团里一个比较核心的 AI 引擎。
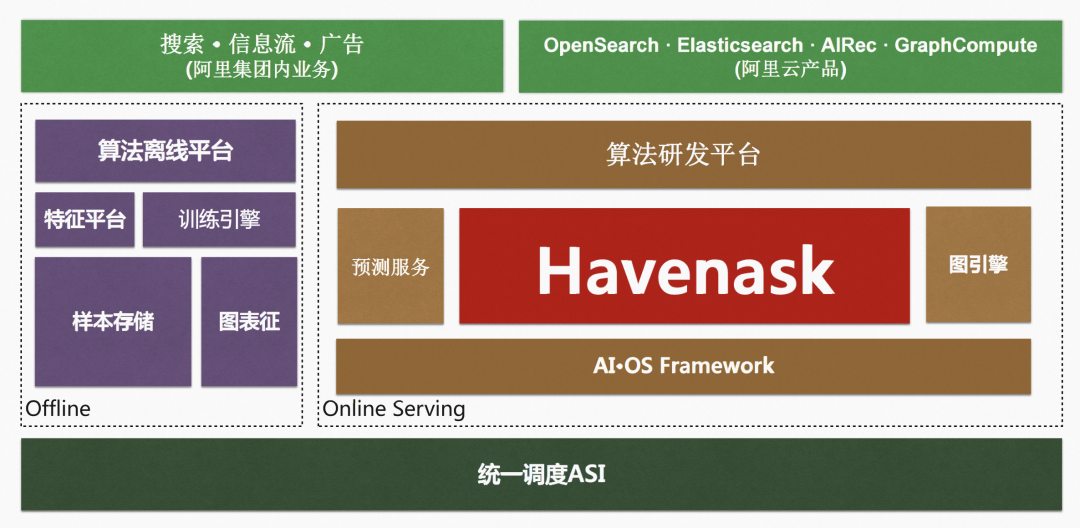
此后经过不断演进,Havenask 逐渐成为了阿里搜推广场景的核心 AI 智能引擎。作为阿里搜推广中台的工程引擎体系 AI·OS (AI Online Serving) 的核心引擎,Havenask 支撑了阿里集团包括淘宝、天猫、菜鸟、高德、饿了么等业务在内的数千搜索业务。
现在 Havenask 支持的业务,可以分为三类:
1)淘宝、天猫主搜最头部业务,直接部署使用 Havenask 搜索引擎,引擎团队贴身支持算法和业务,业务规模在个位数;
2)淘宝、天猫主搜之外的其他核心搜索业务,比如高德、优酷、饿了么、AE 等,由 Havenask 之上构建的 OpenSearch PaaS 版平台产品支持,业务方自助定制开发和运维,引擎团队提供支持,业务规模在百级别;
3)其他中长尾业务,或者无深度定制需求的核心搜索业务,由云上云下统一的云产品 OpenSearch SaaS 版(底层基于 Havenask)支持,业务方自助使用,引擎团队提供支持,业务规模在千级别。
三、搜索引擎的整体架构
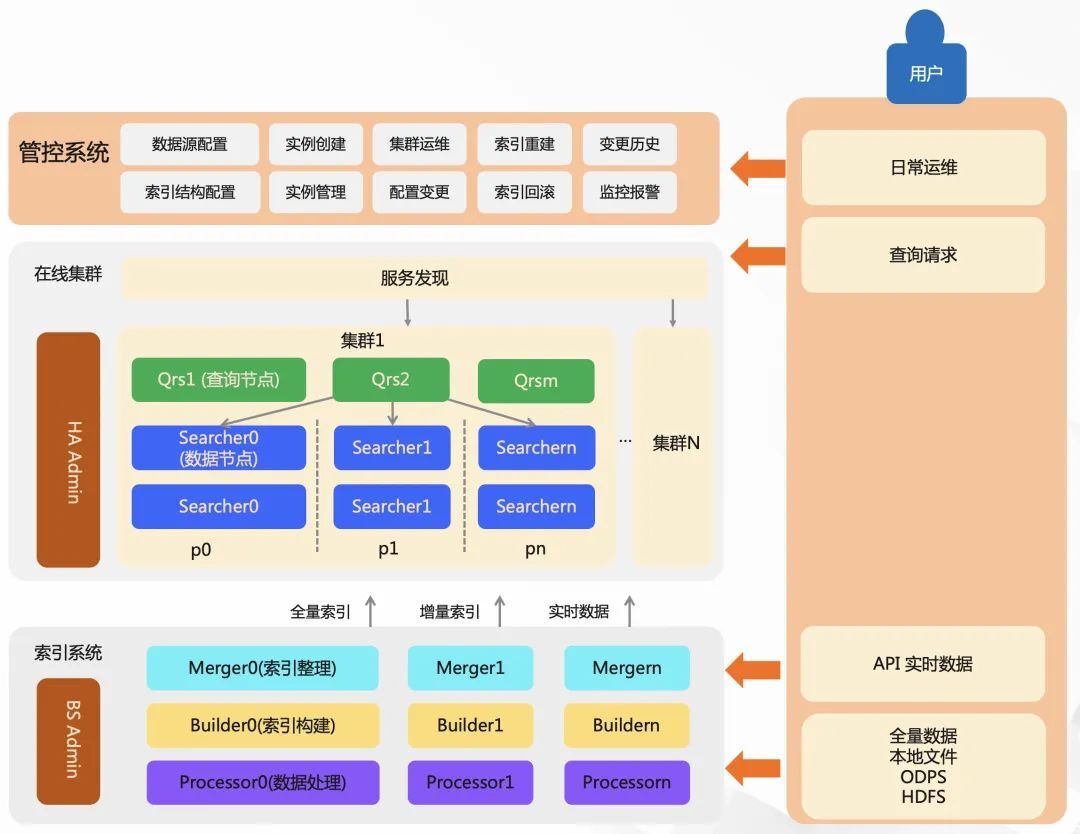
在 Havenask 中,一个较为完整的搜索服务由:在线系统、索引系统、管控系统、扩展插件等部分构成,其中包括了查询流、数据流、控制流。
1)在线系统,包含了 QRS 和 Searcher。Qrs 负责接收用户查询、查询分发、收集整合结果。Searcher 是搜索查询的执行者,负责倒排索引召回、统计、条件过滤、文档打分、排序、摘要生成等。
2)索引系统,负责索引数据生成的过程,还包含有文档处理与索引构建服务 Build Service。索引构建分为三个步骤,对数据进行前置处理(例如分词、向量计算等)、产出索引、合并索引文件的处理。
3)管控系统,负责提供强大的运维能力。
4)扩展插件,提供插件机制,索引和在线流程各环节中,均可以通过开发插件,对原始文档、查询 Query、召回、算分、排序、摘要进行灵活修改。
Havenask 作为 AI 引擎,本质上是为了帮助用户更精准的找到满足自己需求的商品,随着机器学习技术的发展,大量深度学习算法应用在电商搜索引擎上,实现个性化和智能化。以电商搜索为例,用户在搜索框中敲一个关键词或者一句话,系统首先会试图理解这个关键词或者这句话(NLP 技术),并拆分成以关键词、语义相关性、向量检索等多路方式召回,召回一批商品,并对这批商品做粗排,粗排后更小的商品集合上再做精排,这其中各个环节会大量应用机器学习算法,来实现搜索的个性化和智能化,整个过程需要在毫秒级完成。
在这个流程中,搜索团队在性能和迭代效率上做了大量优化,关键有两点:
海量物品的准确召回,是提升搜索质量的第一个环节,一般会通过多个系统的调用实现多路召回,调用链路复杂,召回延迟也可能较大。Havenask 支持在一个系统内部利用全图化思想,并发的完成关键词、语义相关性、向量、个性化等多路召回,合并后直接返回最终召回结果,做到极小的召回延迟。
针对不同的召回特性,支持 O2O(offline 计算转 online,或 online 计算转 offline)优化,支持数据、模型实时更新,并保证在离线的一致性。算法工程师可以运用更复杂的召回策略,在线上快速做各种 AB 实验,实验验证效果后可以分钟级全量上线。
另外,AI 引擎还支持丰富的插件拓展机制,和自研 CAVA 语言(类似于 JAVA 的语言)开发,并能集成达摩院 Proxima 向量库,支持多模态搜索。
阿里内部大数据检索场景的业务大部分基于 Havenask。大数据检索场景最主要的特点是数据量大,数据更新或查询并发度高,一般不需要强一致性,数据库的强一致性和事务,在这个场景下反而会导致性能瓶颈和较高的成本。
在大数据检索场景下,比较接近的对标软件是 Elasticsearch。Elasticsearch 主要以日志分析和检索、监控、安全分析、企业文档搜索、关键词召回等为主要场景。Havenask 跟 Elasticsearch 也有一些差别:
1)Havenask 数据更新时效性更好,大数据量数据写入高并发情况下,数据更新后到可查询到仍然可以做到 1 秒内。ES 受架构限制,虽然时效性可配置,但大数据量情况下,时效性配置到 1 秒在生产上基本不太可用。
2)更好的查询性能。在同一数据集上的测试表明,Havenask 用更少的资源(内存使用量少 20~50%),查询 QPS 高 2~3 倍,查询平均延迟低约 2/3。
因此,在大数据检索场景下,可以说 Havenask 给业界提供了一个极致性价比的新技术方案。
Havenask 底层全部由 C++ 实现,具备较完备的索引构建、存储和管理能力,具有较好的扩展性,既能使用单机的存储媒介、开源的分布式存储系统,也能基于云存储产品。
四、后续开源规划
搜索引擎是非常复杂的一个系统。在数据规模极大的时候,要想达到很好的稳定性、实时性,这是非常有挑战的。对于一般规模企业来说,自研大规模分布式搜索引擎,一般需要投入几十甚至上百人的团队,耗时数年。Havenask 的开源,无疑也为有类似需要的企业,节省了高昂的研发成本。开发者和企业也能借助 Havenask 在 AI 领域实现更容易、更快速的创新。
而阿里也期望 Havenask 的开源能吸引更多优秀的开发者参与共创,共同推进国产化开源搜索引擎技术快速发展,普惠更多的开发者和企业。
阿里目前已经基于 Apache 2.0 许可开源了 Havenask 核心代码,未来几个月内将发布正式版,保持与内部主干代码一致。后续有计划逐步开源阿里 AI·OS 体系更多的系统,下一个可能开源的系统是在线预测引擎(内部代号RTP)或图计算引擎(内部代号 igraph)。

相关文章:
阿里开源自研高性能核心搜索引擎 Havenask
去年12月,阿里开源了自研的大规模分布式搜索引擎 Havenask(内部代号 HA3)。  Havenask 是阿里巴巴内部广泛使用的大规模分布式检索系统,支持了淘宝、天猫、菜鸟、优酷、高德、饿了么等在内整个阿里的搜索业务&#…...
nginx日志服务之敏感信息脱敏
1. 创建实验资源 开始实验之前,您需要先创建实验相关资源。 日志服务之敏感信息脱敏与审计 2. 创建原始数据 本步骤将指导您如何创建NGINX模拟数据。 双击打开虚拟桌面的Firefox ESR浏览器。 在RAM用户登录框中单击下一步,并复制粘贴页面左上角的子…...
【uni-app教程】一、UniAPP 介绍
一、UniAPP 介绍 (1) 什么是 UniAPP? uni-app 是一个使用 Vue.js 开发所有前端应用的框架,开发者编写一套代码,可发布到 iOS,Android,HS,以及各种小程序(微信/支付宝/百度/头条/QQ/钉钉》等多个平台&#…...

Splunk Real-time Search 的研究
最近客户想搞清Splunk real-time search 和related search 有啥区别,想两个都试试,看看效果。 为了更好的说明什么是real-time search, 先看一下: With real-time searches and reports, you can search events before they are indexed and preview reports as the event…...

SWM181 串口功能使用介绍
SWM181 串口功能使用介绍📌SDK固件包:https://www.synwit.cn/kuhanshu_amp_licheng/✨注意新手谨慎选择作为入门单片机学习。🌼开发板如下图: 📋SWM181描述上写了有4个串口,在数据手册上,将引脚…...

Stochastic Approximation 随机近似方法的详解之(三)Dvoretzky’s convergence theorem
定理内容 Theorem 6.2 (Dvoretzky’s Theorem). Consider a stochastic process wk1(1−αk)wkβkηkw_{k1}\left(1-\alpha_k\right) w_k\beta_k \eta_kwk1(1−αk)wkβkηk, 其中{αk}k1∞,{βk}k1∞,{ηk}k1∞\{\alpha_k\}^\infty_{k1},\{\beta_k\}^\infty_{k1},\…...

7个ES6解构技巧让代码更简洁
您是否厌倦了编写臃肿且难以阅读的代码?想要提升您的编码技能并使您的代码更具可读性和简洁性? 从解构对象和数组到使用默认值和展开运算符,我们将涵盖所有内容,现在,我们将准备好掌握干净简洁的编码艺术。 1.解构对…...

曾经被人们看成是异想天开的产业互联网,或许终将会实现
一波还未平息,一波又起。元宇宙的热度还未彻底散去,ChatGPT已经成为了名符其实的新风口。如果用一个概念来定义现在这样一个热点和风口频出的时代的话,我想,用产业互联网或许是再合适不过的了。对此,可能有人并不认同。…...

log4j控制台不打印日志的故障解决方案
前言 接管了别的项目组的一个代码,在IDAE调试程序的过程中,发现log4j日志居然没有打印在控制台上,日志相关代码也没有问题。 在网上搜索了一圈,总结了一下个人解决这个问题的流程。 流程 1. 判断用了什么配置文件 不知道是出…...
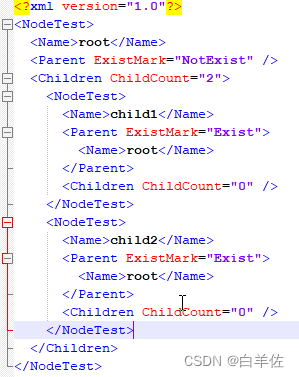
C# 序列化时“检测到循环引用”错误的彻底解决方案
目录 一,问题表现 二、没有技术含量的解决方案 三、本人彻底的解决方案 简要说明 贴代码 思路解析 思路 一,问题表现 示例代码如下: [Serializable] public class NodeTest {public NodeTest (){new List<NodeTest> ();}p…...

小红书“复刻”微信,微信“内造”小红书
配图来自Canva可画 随着互联网增长红利逐渐见顶,各大互联网平台对流量的争夺变得愈发激烈。而为了寻找新的业务可能性,各家都在不遗余力地拓宽自身边界。在此背景下,目前最为“吸睛”和“吸金”的社交、电商、种草、短视频等领域,…...
用arthas轻松排查线上问题
你是否在项目中会碰到以下一些问题: 在代码中打印各种日志来排查,比如方法的入参,出参,及在方法体中打印日志判断走哪行代码还有你觉得代码没问题,可是运行出现却是以前的bug,感觉代码没修改,或…...
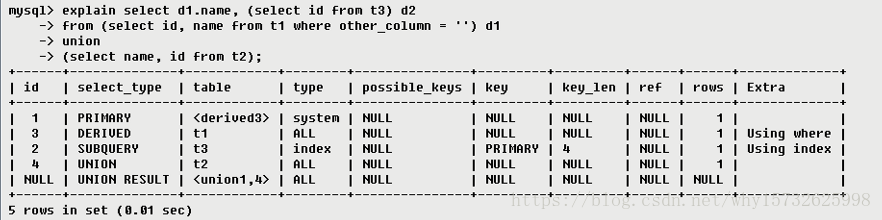
mysql一explain结果分析
1. EXPLAIN简介 使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈。 ➤ 通过EXPLAIN,我们可以分析出以下结果: 表的读取顺序数据读取操作的操作类型哪些索引可…...

原理底层计划--HashMap
HashMap 之前写了“Java集合TreeMap红黑树一生只爱一次”,说到底还是太年轻了,Map其实在排序中应用比较少,一般追求的是速度,通过HashMap来获取速度。hashmap 调用object hashcode方法用于返回对象的哈希码,主要使用在…...

win10 设备管理器中的黄色感叹号(华硕)
目录一、前言二、原因三、方案四、操作一、前言 打开设备管理器,我们可以看到自己设备的信息,但是在重装系统后,你总会在不经意间发现。咦,怎么多了几个感叹号??? 由于我已经解决该问题&#…...

新产品上市推广不是“铺货”上架
只有不断推出新产品的企业才能走得长远,但现实中往往有很多企业投入了大量人力、物力、财力研发的新产品却在推广的过程中屡屡受挫。那么,为什么适合市场的新产品会在市场营销推广的过程中夭折呢?小马识途营销顾问分析有如下几点:…...

MATLAB训练神经网络小结
MATLAB训练神经网络小结1、一个典型例子1.1 可视化神经网络1.2 指定某一层的激活函数1.3 训练神经网络时使用L1正则化1.4返回训练过程中的参数1.5 查看训练好的权重系数1.6 如何使用早停法来防止过拟合1、一个典型例子 例如输入特征为10维,想训练一个10x20x10x1的三…...
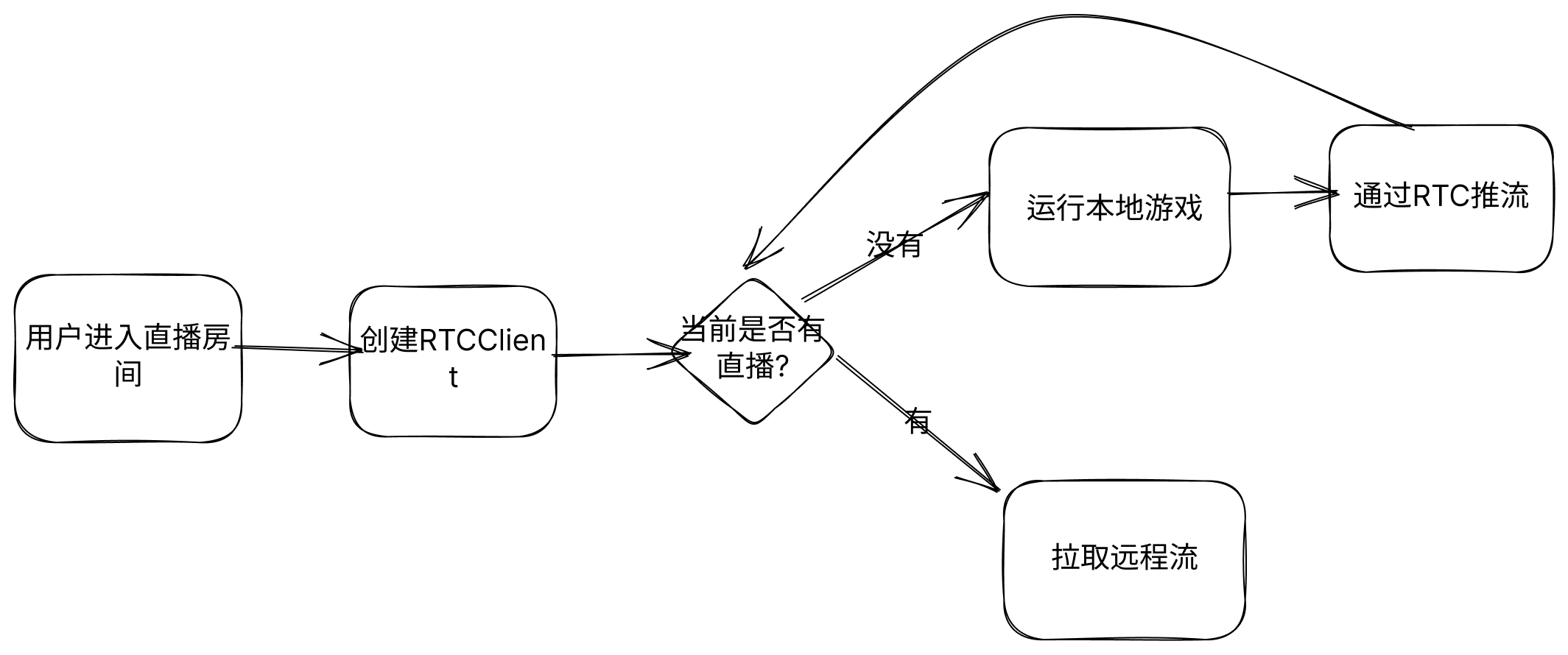
实战:一天开发一款内置游戏直播的国产版Discord应用【附源码】
游戏直播是Discord产品的核心功能之一,本教程教大家如何1天内开发一款内置游戏直播的国产版Discord应用,用户不仅可以通过IM聊天,也可以进行语聊,看游戏直播,甚至自己进行游戏直播,无任何实时音视频底层技术…...
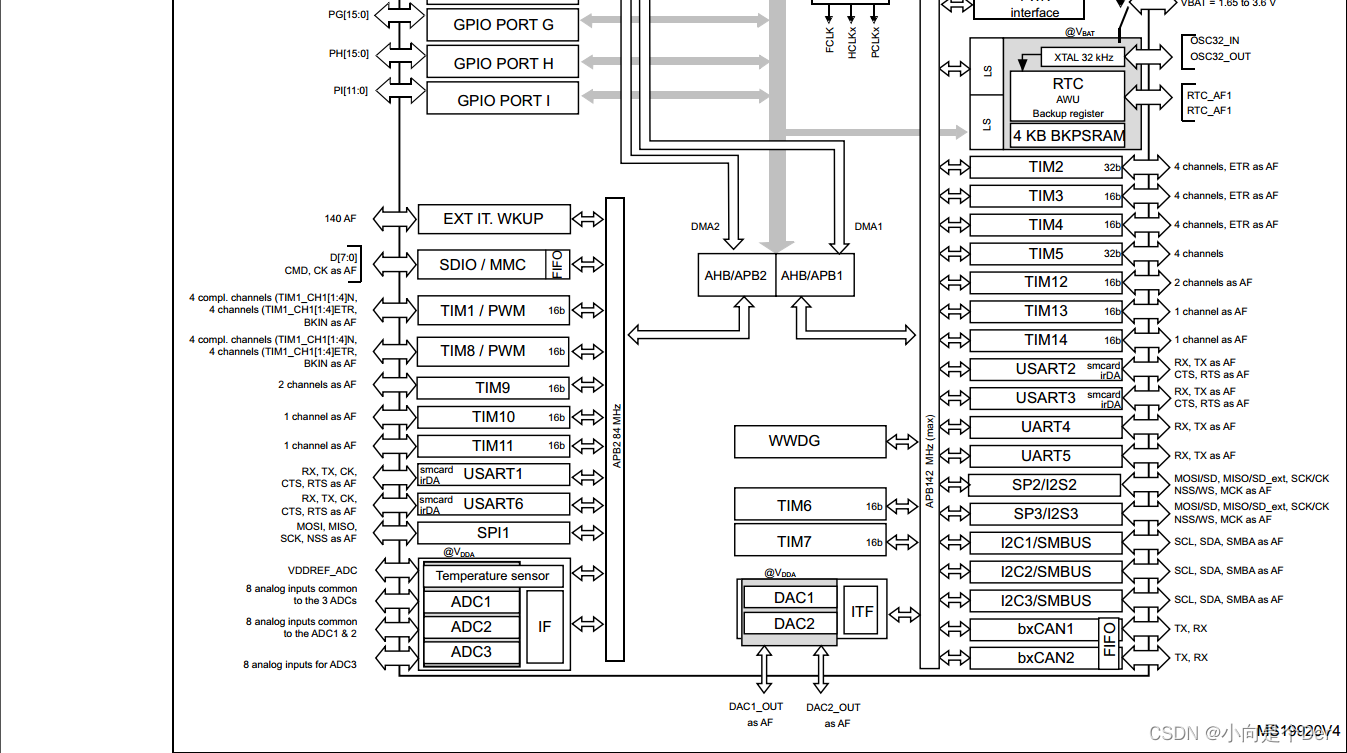
嵌入式学习笔记——基于Cortex-M的单片机介绍
基于Cortex-M的单片机介绍前言生产厂商及其产品线ARM单片机的产品线命名规则留个作业习单片机的资料准备STM32开发所需手册1.芯片的数据手册作业2前言 本文继续接着上一篇中关于Cortex-M的介绍,来记录一些关于ARM系单片机的知识。 生产厂商及其产品线 芯片厂商在…...
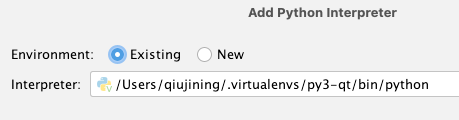
Python 虚拟环境的使用
PyCharm 创建的虚拟环境与使用 workon 命令创建的虚拟环境在本质上没有区别,它们都是 Python 的虚拟环境。 使用 PyCharm 创建工程时,使用可以使用曾经工程的虚拟环境,或者新建一个虚拟环境来安装 Python 的库,又或者使用 workon…...

开发多语言翻译服务时借助Taotoken调用专用模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发多语言翻译服务时借助Taotoken调用专用模型 设想这样一个场景:你的团队正在开发一个内容平台或国际化应用…...

熬夜赶论文效率低到哭?学长安利这几个AI论文写作软件
熬夜赶论文效率低到哭?选题没思路、大纲难搭建、初稿写不顺、文献找不全、润色没方向、降重费时间、格式不规范——这些论文写作的痛点,其实都可以通过用对AI工具、走对流程来解决。资深教授普遍推荐:千笔AI(中文全流程首选&#…...

基于随机森林与形态学参数预测星系外生恒星质量分数
1. 项目概述与核心目标在星系天文学领域,一个长期困扰我们的核心问题是:我们如何仅凭一张遥远星系的“照片”,就能解读它波澜壮阔的成长史?星系中的恒星,有些是“土生土长”的原位形成,有些则是通过“吞并”…...

量子机器学习中的偏见:从编码到测量的系统性挑战与缓解策略
1. 量子机器学习中的偏见:一个被忽视的工程挑战量子机器学习(QML)正从理论实验室走向现实应用,从药物分子筛选到金融衍生品定价,其潜力令人兴奋。然而,作为一名长期关注量子算法落地的从业者,我…...

别再只盯着深度学习!用OpenCV+Python实战传统分水岭算法,5分钟搞定细胞图像分割
用OpenCVPython玩转分水岭算法:5分钟实现细胞图像精准分割在医学图像分析领域,细胞计数和分割一直是基础且关键的环节。传统深度学习方法虽然效果惊艳,但往往需要大量标注数据和计算资源。而分水岭算法这个诞生于1992年的经典方法,…...

机器学习势函数与反向蒙特卡洛在GeO2玻璃中程有序结构解析中的对比研究
1. 项目概述:当机器学习势函数遇上反向蒙特卡洛在材料模拟的世界里,我们常常面临一个两难选择:是相信基于物理化学原理构建的“经验”模型,还是完全服从实验数据的“拟合”结果?这个问题在网络形成玻璃,比如…...

数值自举与弦论振幅:用SDPB最小化纠缠矩定位开超弦
1. 项目概述:当数值优化遇见弦论振幅在理论物理的前沿,尤其是量子场论和弦论的交叉地带,我们常常面临一个核心挑战:如何从一堆抽象的原理(如幺正性、因果性、交叉对称性)出发,反向“雕刻”出物理…...

AI Agent Harness Engineering:大模型之后的下一个技术爆发点
AI Agent Harness Engineering:大模型之后的下一个技术爆发点一、引言 1.1 钩子:从“大模型的局限性”到“人类解放双手的终极形态” 你是否有过这样的经历? 上周为了赶一份季度数据分析报告,你打开了GPT-4:先让它帮你…...

别再报错‘不在sudoers文件中’了!手把手教你用visudo安全配置CentOS/RHEL用户sudo权限
安全配置Linux系统sudo权限的终极指南当你第一次在终端输入sudo命令时,看到"用户不在sudoers文件中"的提示,那种挫败感每个Linux用户都深有体会。但别急着用chmod修改文件权限——这种"野路子"虽然能快速解决问题,却可能…...

CoQMoE:面向FPGA的MoE-ViT量化与硬件协同设计实践
1. 项目概述:当视觉Transformer遇上FPGA,为何需要“协同设计”?最近几年,视觉Transformer(ViT)在图像识别、目标检测等任务上展现出了不输甚至超越传统卷积神经网络(CNN)的性能。但随…...