Flink 数据类型 TypeInformation信息
Flink流应用程序处理的是以数据对象表示的事件流。所以在Flink内部,我么需要能够处理这些对象。它们需要被序列化和反序列化,以便通过网络传送它们;或者从状态后端、检查点和保存点读取它们。为了有效地做到这一点,Flink需要明确知道应用程序所处理的数据类型。并为每个数据类型生成特定的序列化器、反序列化器和比较器。Flink支持非常完善的数据类型,数据类型描述信息都是由TypeInformation定义,比较常用的TypeInformation有BasicTypeInfo、TupleTypeInfo、CaseClassTypeInfo、PojoTypeInfo类等。TypeInformation主要作用是为了在 Flink系统内有效地对数据结构类型进行管理,能够在分布式计算过程中对数据的类型进行管理和推断。同时基于对数据的类型信息管理,Flink内部对数据存储也进行了相应的性能优化。Flink能够支持任意的Java或Scala的数据类型,不用像Hadoop中的org.apache.hadoop.io.Writable而实现特定的序列化和反序列化接口,从而让用户能够更加容易使用已有的数据结构类型。另外使用TypeInformation管理数据类型信息,能够在数据处理之前将数据类型推断出来,而不是真正在触发计算后才识别出,这样能够及时有效地避免用户在使用Flink编写应用的过程中的数据类型问题。
原生数据类型
Flink通过实现BasicTypeInfo数据类型,能够支持任意Java 原生基本类型(装箱)或String类型,例如Integer、String、Double等,如以下代码所示,通过从给定的元素集中创建DataStream数据集。
//创建 Int 类型的数据集
DataStreamSource<Integer> integerDataStreamSource = env.fromElements(1, 2, 3, 4, 5);
//创建 String 的类型的数据集
DataStreamSource<String> stringDataStreamSource = env.fromElements("Java", "Scala");
Flink实现另外一种TypeInfomation是BasicArrayTypeInfo,对应的是Java基本类型数组(装箱)或String对象的数组,如下代码通过使用 Array数组和List集合创建DataStream数据集。
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 5);
//通过 List 集合创建数据集
DataStreamSource<Integer> integerDataStreamSource1 = env.fromCollection(integers);
Java Tuples类型
通过定义TupleTypeInfo来描述Tuple类型数据,Flink在Java接口中定义了元祖类Tuple供用户使用。Flink Tuples是固定长度固定类型的Java Tuple实现,不支持空值存储。目前支持任意的Flink Java Tuple类型字段数量上限为25,如果字段数量超过上限,可以通过继承Tuple类的方式进行拓展。如下代码所示,创建Tuple数据类型数据集。
//通过实例化 Tuple2 创建具有两个元素的数据集
DataStreamSource<Tuple2<String, Integer>> tuple2DataStreamSource = env.fromElements(new Tuple2<>("a", 1), new Tuple2<>("b", 2));
//通过实例化 Tuple3 创建具有三个元素的数据集
DataStreamSource<Tuple3<String, Integer, Long>> tuple3DataStreamSource = env.fromElements(new Tuple3<>("a", 1, 3L), new Tuple3<>("b", 2, 3L));
Scala Case Class类型
Flink通过实现CaseClassTypeInfo支持任意的Scala Case Class,包括Scala tuples类型,支持的字段数量上限为22,支持通过字段名称和位置索引获取指标,不支持存储空值。如下代码实例所示,定义WordCount Case Class数据类型,然后通过fromElements方法创建input数据集,调用keyBy()方法对数据集根据 word字段重新分区。
//定义 WordCount Case Class 数据结构
case class WordCount(word: Sring, count: Int)
//通过 fromElements 方法创建数据集
val input = env.fromElements(WordCount("hello", 1),WordCount("word",2))
val keyStream1 = input.keyBy("word")//根据word字段为分区字段,
val keyStream2 = input.keyBy(0)//也可以通过制定position分区
通过使用Scala Tuple创建DataStream数据集,其他的使用方式和Case Class相似。需要注意的是,如果根据名称获取字段,可以使用 Tuple中的默认字段名称。
//通过实例化Scala Tuple2 创建具有两个元素的数据集
val tupleStream: DataStream[Tuple2[String,Int]] = env.fromElements(("a",1),("b",2));
//使用默认名字段获取字段,表示第一个 tuple字段,相当于下标0
tuple2DataStreamSource.keyBy("_1");
POJOs 类型
POJOs类可以完成复杂数据结构的定义,Flink通过实现PojoTypeInfo来描述任意的POJOs,包括Java和Scala类。在Flink中使用POJOs类可以通过字段名称获取字段,例如dataStream.join(otherStream).where("name").equalTo("personName"),对于用户做数据处理则非常透明和简单,如代码所示。如果在Flink中使用POJOs数据类型,需要遵循以下要求:
【1】POJOs类必须是Public修饰且必须独立定义,不能是内部类;
【2】POJOs类中必须含有默认空构造器;
【3】POJOs类中所有的 Fields必须是Public或者具有Public修饰的getter和setter方法;
【4】POJOs类中的字段类型必须是Flink支持的。
//类和属性具有 public 修饰
public class Persion{public String name;public Integer age;//具有默认的空构造器public Persion(){}public Persion(String name,Integer age){this.name = name;this.age = age;};
}
定义好POJOs Class后,就可以在 Flink环境中使用了,如下代码所示,使用fromElements接口构建Person类的数据集。POJOs类仅支持字段名称指定字段,如代码中通过Person name来指定Keyby字段。
DataStreamSource<Persion> persionDataStreamSource = env.fromElements(new Persion("zzx", 18), new Persion("fj", 16));
persionData.keyBy("name").sum("age");
Flink Value类型
Value数据类型实现了org.apache.flink.types.Value,其中包括read()和write()两个方法完成序列化和反序列化操作,相对于通用的序列化工具会有着比较高效的性能。目前Flink提供了內建的Value类型有IntValue、DoubleValue以及StringValue等,用户可以结合原生数据类型和Value类型使用。
特殊数据类型
在Flink中也支持一些比较特殊的数据数据类型,例如Scala中的List、Map、Either、Option、Try数据类型,以及Java中Either数据类型,还有Hadoop的Writable数据类型。如下代码所示,创建Map和List类型数据集。这种数据类型使用场景不是特别广泛,主要原因是数据中的操作相对不像POJOs类那样方便和透明,用户无法根据字段位置或者名称获取字段信息,同时要借助Types Hint帮助Flink推断数据类型信息,关于Tyeps Hmt介绍可以参考下一小节。
//创建 map 类型数据集
Map map = new HashMap<>();
map.put("name","zzx");
map.put("age",12);
env.fromElements(map);
//创建 List 类型数据集
env.fromElements(Arrays.asList(1,2,3,4,5),Arrays.asList(3,4,5));
TypeInformation信息获取: 通常情况下Flink都能正常进行数据类型推断,并选择合适的serializers以及comparators。但在某些情况下却无法直接做到,例如定义函数时如果使用到了泛型,JVM就会出现类型擦除的问题,使得Flink并不能很容易地获取到数据集中的数据类型信息。同时在Scala API和Java API中,Flink分别使用了不同的方式重构了数据类型信息。
Scala API类型信息
Scala API通过使用Manifest和类标签,在编译器运行时获取类型信息,即使是在函数定义中使用了泛型,也不会像Java API出现类型擦除的问题,这使得Scala API具有非常精密的类型管理机制。同时在Flink中使用到Scala Macros框架,在编译代码的过程中推断函数输入参数和返回值的类型信息,同时在Flink中注册成TypeInformation以支持上层计算算子使用。
当使用Scala API开发 Flink应用,如果使用到Flink已经通过TypeInformation定义的数据类型,TypeInformation类不会自动创建,而是使用隐式参数的方式引入,代码不会直接抛出编码异常,但是当启动Flink应用程序时就会报could not find implicit value for evidence parameter of type TypeInformation的错误。这时需要将TypeInformation类隐式参数引入到当前程序环境中,代码实例如下:
import org.apache.flink.api.scala._
Java API类型信息
由于Java的泛型会出现类型擦除问题,Flink通过Java反射机制尽可能重构类型信息,例如使用函数签名以及子类的信息等。同时类型推断在当输出类型依赖于输入参数类型时相对比较容易做到,但是如果函数的输出类型不依赖于输入参数的类型信息,这个时候就需要借助于类型提示Ctype Himts来告诉系统函数中传入的参数类型信息和输出参数信息。如代码清单通过在returns方法中传入TypeHint实例指定输出参数类型,帮助Flink系统对输出类型进行数据类型参数的推断和收集。
//定义泛型函数,输入参数 T,O 输出参数为 O
class MyMapFucntion<T,O> implements MapFunction<T,O>{@Overridepublic O map(T t) throws Exception {//定义计算逻辑return null;}
}//通过 List 集合创建数据集
DataStreamSource<Integer> input = env.fromCollection(integers);
input.flatMap(new MyMapFucntion<String,Integer>()).returns(new TypeHint<Integer>() {//通过returns方法指定返回参数类型
})
在使用Java API定义POJOs类型数据时,PojoTypeInformation为POJOs类中的所有字段创建序列化器,对于标准的类型,例如Integer、String、Long等类型是通过Flink自带的序列化器进行数据序列化,对于其他类型数据都是直接调用Kryo序列化工具来进行序列化。通常情况下,如果Kryo序列化工具无法对POJOs类序列化时,可以使用Avro对POJOs类进行序列化,如下代码通过在ExecutionConfig中调用 enableForceAvro()来开启Avro序列化。
//获取运行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//开启 avro 序列化
env.getConfig().enableForceAvro();
如果用户想使用Kryo序列化工具来序列化POJOs所有字段,则在ExecutionConfig中调用enableForceKryo()来开启Kryo序列化。
//获取运行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//开启 Kryo 序列化
env.getConfig().enableForceKryo();
如果默认的Kryo序列化类不能序列化POJOs对象,通过调用ExecutionConfig的addDefaultKryoSerializer()方法向Kryo中添加自定义的序列化器。
public void addDefaultKryoSerializer(Class<?> type, Class<? extends Serializer<?>> serializerClass)
自定义TypeInformation
除了使用已有的TypeInformation所定义的数据格式类型之外,用户也可以自定义实现TypeInformation,来满足的不同的数据类型定义需求。Flink提供了可插拔的 Type Information Factory让用户将自定义的TypeInformation注册到Flink类型系统中。如下代码所示只需要通过实现org.apache.flink.api.common.typeinfo.TypeInfoFactory接口,返回相应的类型信息。通过@TypeInfo注解创建数据类型,定义CustomTuple数据类型。
@TypeInfo(CustomTypeInfoFactory.class)
public class CustomTuple<T0,T1>{public T0 field0;public T1 field1;
}
然后定义CustomTypeInfoFactory类继承于TypeInfoFactory,参数类型指定CustomTuple。最后重写createTypeInfo方法,创建的CustomTupleTypeInfo就是CustomTuple数据类型TypeInformation。
public class CustomTypeInfoFactory extends TypeInfoFactory<CustomTuple>{@Overridepublic TypeInfomation<CustomTuple> createTypeInfo(Type t, Map<String,TypeInfoFactory<?>> genericParameters){return new CustomTupleTypeInfo(genericParameters.get("T0"),genericParameters.get("T1");}
}
相关文章:

Flink 数据类型 TypeInformation信息
Flink流应用程序处理的是以数据对象表示的事件流。所以在Flink内部,我么需要能够处理这些对象。它们需要被序列化和反序列化,以便通过网络传送它们;或者从状态后端、检查点和保存点读取它们。为了有效地做到这一点,Flink需要明确知…...

基于python的leetcode算法介绍之递归
文章目录 零 算法介绍一 简单示例 辗转相除法Leetcode例题与思路[509. 斐波那契数](https://leetcode.cn/problems/fibonacci-number/)解题思路:题解: [206. 反转链表](https://leetcode.cn/problems/reverse-linked-list/)解题思路:题解&…...

2023年度佳作:AIGC、AGI、GhatGPT、人工智能大语言模型的崛起与挑战
目录 前言 01 《ChatGPT 驱动软件开发》 内容简介 02 《ChatGPT原理与实战》 内容简介 03 《神经网络与深度学习》 04 《AIGC重塑教育》 内容简介 05 《通用人工智能》 目 录 前言 2023年是人工智能大语言模型大爆发的一年,一些概念和英文缩写也在这一…...
Axure的交互以及情形的介绍
一. 交互 1.1 交互概述 通俗来讲就是,谁用了什么方法做了什么事情,主体"谁"对应的就是axure中的元件,"什么方法"对应的就是交互事件,比如单击事件、双击事件,"什么事情"对应的就是交互…...
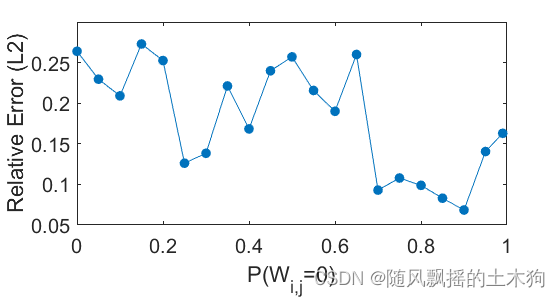
【MATLAB第84期】基于MATLAB的波形叠加极限学习机SW-ELM代理模型的sobol全局敏感性分析法应用
【MATLAB第84期】基于MATLAB的波形叠加极限学习机SW-ELM代理模型的sobol全局敏感性分析法应用 前言 跟往期sobol区别: 1.sobol计算依赖于验证集样本,无需定义变量上下限。 2.SW-ELM自带激活函数,计算具有phi(x)e^x激…...
米游社区表情包整合网站源码
源码介绍 米游社表情包整合网站源码,来自Github大佬的项目,包含米游兔123枚,米游社 玩家12枚,崩坏 星穹铁道112枚,绝区零218枚,NAP32枚,崩坏RPG62枚,崩坏3-1282枚,原神 …...

easyexcel调用公共导出方法导出数据
easyexcel备忘 Slf4j public class ConditionDownloadUtil {//扫描在xboot 包下所有IService 接口的子类, 每次启动服务后, 重新扫描public final static Class[] classesExtendsIService ClassUtil.scanPackageBySuper("cn.exrick.xboot", IService.class).toArra…...
C语言插入排序算法及代码
一、原理 在待排序的数组里,从数组的第二个数字开始,通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。 二、代码部分 #include<stdio.h> #include<stdlib.h> int ma…...
2023年中国法拍房用户画像和数据分析
法拍房主要平台 法拍房主要平台有3家,分别是阿里、京东和北交互联平台。目前官方认定纳入网络司法拍卖的平台共有7家,其中阿里资产司法拍卖平台的挂拍量最大。 阿里法拍房 阿里法拍房数据显示2017年,全国法拍房9000套;2018年&a…...

Android 清除临时文件,清空缓存
python 代码: import os import shutil import tracebackdef delete_folder(path):if os.path.exists(path):print(f"删除文件夹: {path}")shutil.rmtree(path)print("删除完成")def delete_file(path):if os.path.exists(path):print(f"删…...
Guava限流神器:RateLimiter使用指南
1. 引言 可能有些小伙伴听到“限流”这个词就觉得头大,感觉像是一个既复杂又枯燥的话题。别急,小黑今天就要用轻松易懂的方式,带咱们一探RateLimiter的究竟。 想象一下,当你去超市排队结账时,如果收银台开得越多&…...

【六大排序详解】开篇 :插入排序 与 希尔排序
插入排序 与 希尔排序 六大排序之二 插入排序 与 希尔排序1 排序1.1排序的概念 2 插入排序2.1 插入排序原理2.2 排序步骤2.3 代码实现 3 希尔排序3.1 希尔排序原理3.2 排序步骤3.3 代码实现 4 时间复杂度分析 Thanks♪(・ω・)ノ下一篇文章见&am…...

凸优化问题求解
这里写目录标题 1. 线性规划基本定理2.单纯形法2.1 转轴运算 3. 内点法3.1 线性规划的内点法 1. 线性规划基本定理 首先我们指出,线性规划均可等价地化成如下标准形式 { min c T x , s . t A x b , x ⪰ 0 , \begin{align}\begin{cases}\min~c^Tx,\\\mathrm{s.…...
文件操作入门指南
目录 一、为什么使用文件 二、什么是文件 2.1 程序文件 2.2 数据文件 2.3 文件名 三、文件的打开和关闭 3.1 文件指针 3.2 文件的打开和关闭 四、文件的顺序读写 编辑 🌻深入理解 “流”: 🍂文件的顺序读写函数介绍: …...

Axure之交互与情节与一些实例
目录 一.交互与情节简介 二.ERP登录页到主页的跳转 三.ERP的菜单跳转到各个页面的跳转 四.省市联动 五.手机下拉加载 今天就到这里了,希望帮到你哦!!! 一.交互与情节简介 "交互"通常指的是人与人、人与计算机或物体…...
)
【数据库设计和SQL基础语法】--连接与联接--多表查询与子查询基础(二)
一、子查询基础 1.1 子查询概述 子查询是指在一个查询语句内部嵌套另一个查询语句的过程。子查询可以嵌套在 SELECT、FROM、WHERE 或 HAVING 子句中,用于从数据库中检索数据或执行其他操作。子查询通常返回一个结果集,该结果集可以被包含它的主查询使用…...
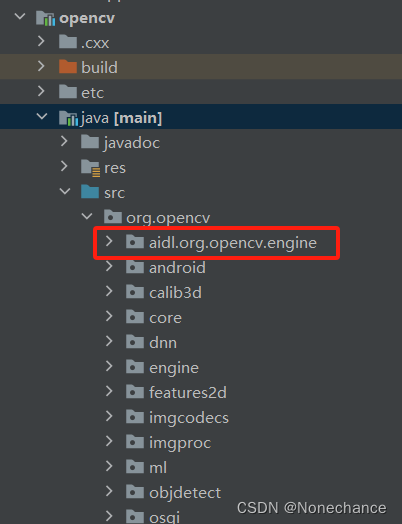
Android studio中导入opencv库
具体opencv库的导入流程参考链接:Android Studio开发之路 (五)导入OpenCV以及报错解决 一、出现的错误:NullPointerException: Cannot invoke “java.io.File.toPath()” because “this.mySdkLocation” is null 解决办法&#…...
_基础知识)
Linux(1)_基础知识
第一部分 一、Linux系统概述 创始人:芬兰大学大一的学生写的Linux内核,李纳斯托瓦兹。 Linux时unix的类系统; 特点:多用户 多线程的操作系统; 开源操作系统; 开源项目:操作系统,应用…...

网络相关面试题
简述 TCP 连接的过程(淘系) 参考答案: TCP 协议通过三次握手建立可靠的点对点连接,具体过程是: 首先服务器进入监听状态,然后即可处理连接 第一次握手:建立连接时,客户端发送 syn 包…...

Vue2面试题:说一下对跨域的理解?
http请求分为两大类:普通http请求(如百度请求)和ajax请求(跨域是出现在ajax请求) 同源策略:在浏览器发起ajax请求时,当前的网址和被请求的网址协议、域名、端口号必须完全一致,目的是…...

深入理解STM32的FSMC:如何像操作SRAM一样轻松点亮你的TFTLCD屏幕
深入理解STM32的FSMC:如何像操作SRAM一样轻松点亮你的TFTLCD屏幕 在嵌入式开发领域,TFTLCD屏幕的驱动一直是让开发者又爱又恨的难题。传统的GPIO模拟时序方式虽然简单直接,但在高分辨率屏幕和复杂应用场景下往往力不从心。这时,S…...

taotoken模型广场功能体验与主流模型选型建议
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 taotoken模型广场功能体验与主流模型选型建议 1. 平台入口与模型广场概览 登录Taotoken控制台后,最直观的功能入口之一…...

从一次内部渗透测试说起:我是如何利用SSRF漏洞,通过Gopher协议拿下Redis的
渗透测试实战:SSRF漏洞到Redis未授权访问的完整攻击链剖析 在一次常规的企业内部渗透测试中,我发现了一个看似普通的SSRF漏洞,却意外打开了通往内网核心系统的大门。这个故事不是教科书式的漏洞复现,而是一个真实攻击者视角下的完…...
到Stream API:Java二维数组初始化的几种高效写法与性能对比)
从Arrays.fill()到Stream API:Java二维数组初始化的几种高效写法与性能对比
从Arrays.fill()到Stream API:Java二维数组初始化的几种高效写法与性能对比 在算法竞赛和数据处理应用中,二维数组的初始化往往是性能优化的第一个瓶颈。我曾在一个图像处理项目中,因为选择了不当的初始化方式,导致整体性能下降了…...

从极坐标栅格到地面点云:一种基于坡度与邻域一致性的分割实践
1. 极坐标栅格构建:自动驾驶的"地面扫描仪" 想象你正在玩一款赛车游戏,车辆需要自动识别哪些是能开的平坦路面,哪些是必须绕开的障碍物。现实中自动驾驶车辆面临同样的挑战,而极坐标栅格就是它的"地面扫描仪"…...
)
信息学奥赛刷题必备:最长平台问题三种解法详解(附C++代码)
信息学奥赛刷题进阶:最长平台问题的多维解法与竞赛实战 在信息学奥赛的备战过程中,"最长平台"问题作为数组统计类题目的经典代表,频繁出现在各大OJ平台的题库中。这道题目看似简单,却蕴含着丰富的解题思路和优化技巧。对…...

风机技术演进与主动冷却系统优化实践
1. 风机技术演进与主动空气冷却系统优化作为一名在热管理领域工作多年的工程师,我见证了风机技术从简单的散热部件发展为精密的热管理系统的全过程。现代电子设备功率密度不断提升,从智能手机到数据中心服务器,散热设计已成为产品成败的关键因…...

多模态大模型在光谱分析中的应用:温度参数调优与性能评估
1. 项目概述:当光谱分析遇上多模态大模型光谱分析,无论是红外、拉曼还是近红外光谱,一直是材料科学、生物医药、环境监测等领域的“火眼金睛”。它能通过物质与光的相互作用,揭示出样品的成分、结构乃至状态信息。然而,…...

纯Java实现Gemma大模型推理:在JVM中部署轻量级AI的工程实践
1. 项目概述:当Gemma遇上Java,一个轻量级AI推理的新选择最近在开源社区里,一个名为mukel/gemma4.java的项目引起了我的注意。作为一名长期在Java生态和机器学习边缘部署领域摸爬滚打的开发者,看到这个标题的第一反应是:…...

构建个人技能知识库:从Markdown管理到自动化实践
1. 项目概述:一个技能库的诞生与价值最近在整理个人知识体系时,我一直在思考一个问题:如何将那些零散的、跨领域的“技能点”系统化地管理起来,形成一个可以持续迭代、随时取用的个人工具箱?这不仅仅是写一份简历上的技…...