【机器学习】密度聚类:从底层手写实现DBSCAN
【机器学习】Building-DBSCAN-from-Scratch
- 概念
- 代码
- 数据导入
- 实现DBSCAN
- 使用样例及其可视化
- 补充资料
概念
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。
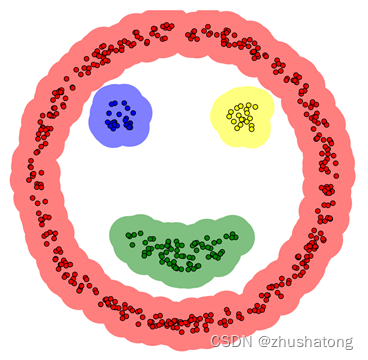
该算法的核心概念是识别位于高密度区域的样本点,并将它们划分为簇。以图中的点A为例,我们观察到A点周围有较高的点密度。根据DBSCAN算法的特定参数——即邻域半径(Epsilon)和最小点数(MinPts)——我们可以确定一个点是否为核心点、边界点或离群点。

在此过程中,算法首先随机选择一个样本点(如A点)并围绕其绘制一个圆,其半径等于邻域半径。如果在这个圆内的样本点数量达到或超过MinPts的阈值,则该点被视为核心点,并且圆心会移动到圆内的另一个样本点,继续探索相邻区域。这个过程持续进行,直到没有更多的点可以加入到当前簇中。此时,圆内最后一个样本点被视为边界点,如B或C。而那些未能被纳入任何簇的点,如N,被视为离群点。
通过这种方式,DBSCAN算法有效地将样本空间中距离相近的点聚合在一起,形成不同的簇,同时识别并排除噪声或异常值。这种基于密度的聚类方法特别适合于处理具有复杂结构或不规则形状的数据集。
代码
数据导入
from sklearn.datasets import load_iris # 导入数据集iris
import matplotlib.pyplot as plt # 导入绘图库
import numpy as np # 导入numpy库
# 加载Iris数据集
iris = load_iris()
X = iris.data # 获得其特征向量,150*4
实现DBSCAN
在OurDBSCAN类中,我们首先通过初始化函数设置了邻域半径eps和最小样本数min_samples,这两个参数是确定簇的关键。在fit方法中,对输入数据集X的每个点进行遍历和分类处理。
算法开始时,所有点都标记为未分类。接着,对每个点,先检查其状态,如果已经分类则跳过,否则通过_find_neighbors方法找出该点的所有邻居。这一步骤涉及计算点与其他所有点之间的欧氏距离,判断是否在设定的邻域半径内。如果一个点的邻居数少于min_samples,则将其标记为噪声。
当一个点有足够多的邻居被确定为核心点后,算法会创建一个新的簇,并通过迭代地探索该点的邻居来扩展这个簇。在此过程中,每个新发现的点都会被检查是否也是核心点,如果是,它的邻居也会被加入到当前簇中。这种方式使得DBSCAN能够根据密度将数据集中的点聚合成多个簇,同时识别和剔除噪声点,有效应对具有不规则形状或包含噪声和异常值的数据集。
class OurDBSCAN:def __init__(self, eps, min_samples):"""初始化DBSCAN对象。参数:eps (float): 邻域的半径。min_samples (int): 核心点的邻域中的最小样本数。"""self.eps = eps # 邻域的半径self.min_samples = min_samples # 核心点的最小样本数self.labels_ = None # 簇标签def fit(self, X):"""将DBSCAN模型拟合到输入数据。参数:X (array-like): 输入数据。返回:None"""# 将所有点标记为-1(未分类)labels = -1 * np.ones(X.shape[0]) # -1表示未分类# 簇IDcluster_id = 0for i in range(X.shape[0]): # 遍历所有点# 如果该点已被访问过,则跳过if labels[i] != -1:continue# 找到当前点的所有邻居neighbors = self._find_neighbors(i, X)# 如果邻居数小于min_samples,则标记为噪声并继续if len(neighbors) < self.min_samples:labels[i] = -2 # -2表示噪声continue# 否则,开始一个新的簇labels[i] = cluster_id# 找到当前簇的所有邻居seeds = set(neighbors) # 邻居集合seeds.remove(i) # 移除当前点while seeds: # 只要种子集合不为空# 取出一个邻居current_point = seeds.pop()# 如果是噪声,则将其标记为当前簇if labels[current_point] == -2:labels[current_point] = cluster_id# 如果已经处理过,则跳过if labels[current_point] != -1:continue# 否则,将其标记为当前簇labels[current_point] = cluster_id# 找到当前点的所有邻居current_neighbors = self._find_neighbors(current_point, X)# 如果当前点是核心点,则将其邻居添加到种子集合中if len(current_neighbors) >= self.min_samples:seeds.update(current_neighbors)# 移动到下一个簇cluster_id += 1self.labels_ = labels # 保存簇标签def _find_neighbors(self, point_idx, X):"""找到给定点的邻居。参数:point_idx (int): 点的索引。X (array-like): 输入数据。返回:neighbors (list): 邻居的索引。"""neighbors = []for i, point in enumerate(X): # 遍历所有点if np.linalg.norm(X[point_idx] - point) <= self.eps: # 计算距离neighbors.append(i)return neighbors
使用样例及其可视化
# 使用手动实现的 DBSCAN,不使用 NearestNeighbors
manual_dbscan_nn = OurDBSCAN(eps=0.5, min_samples=5)
manual_dbscan_nn.fit(X)
# 创建一个图形和子图
fig, axs = plt.subplots(2, 3, figsize=(15, 10))# 组合特征以创建散点图
feature_combinations = [(0, 1), (0, 2), (0, 3), (1, 2), (1, 3), (2, 3)]
feature_names = iris.feature_namesfor i, (fi, fj) in enumerate(feature_combinations):ax = axs[i//3, i % 3]ax.scatter(X[:, fi], X[:, fj], c=manual_dbscan_nn.labels_, cmap='viridis',marker='o', edgecolor='k', s=50)ax.set_xlabel(feature_names[fi])ax.set_ylabel(feature_names[fj])ax.set_title(f'DBSCAN Clustering with {feature_names[fi]} vs {feature_names[fj]}')plt.tight_layout()
plt.show()
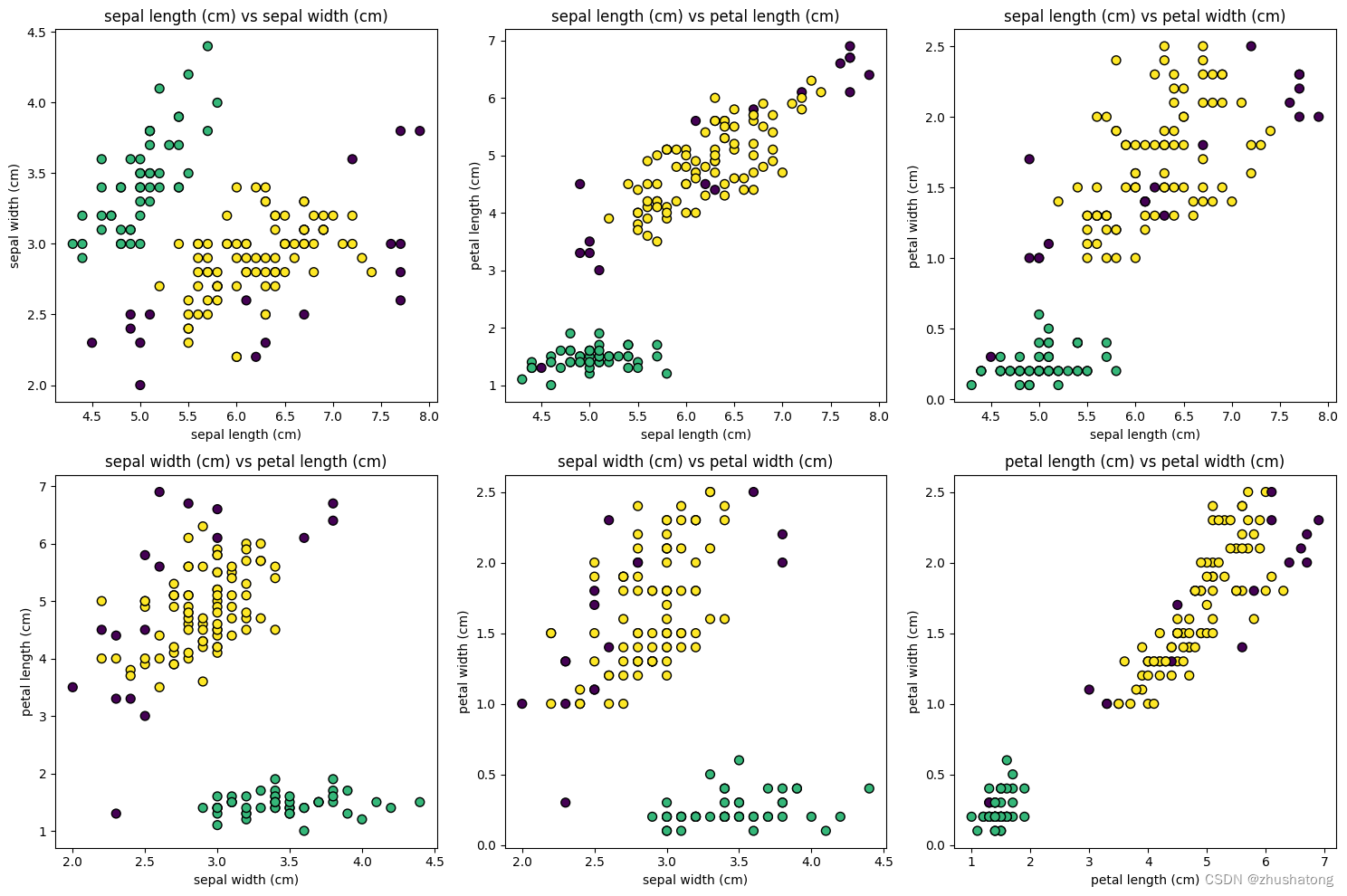
在IRIS数据集中,每个样本都有四个特征:花萼长度(sepal length)、花萼宽度(sepal width)、花瓣长度(petal length)和花瓣宽度(petal width),所有的这些特征都以厘米为单位进行测量。在第一行的图表中,我们可以看到花萼长度与花萼宽度、花瓣长度和花瓣宽度的聚类关系。在第二行,展示的是花萼宽度与花瓣长度、花瓣宽度的聚类效果,以及花瓣长度与花瓣宽度的聚类情况。
通过DBSCAN算法的密度聚类特性,我们可以看到在密度较高的区域形成了聚类簇,而在密度较低的区域,点则被标记为噪声点或者位于不同簇的边界。
补充资料
一个有趣的DBSCAN可视化网站:
https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
相关文章:
【机器学习】密度聚类:从底层手写实现DBSCAN
【机器学习】Building-DBSCAN-from-Scratch 概念代码数据导入实现DBSCAN使用样例及其可视化 补充资料 概念 DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算…...
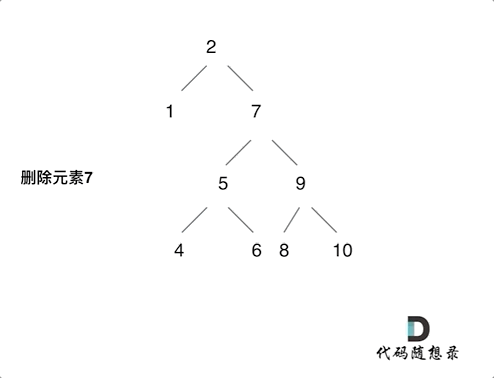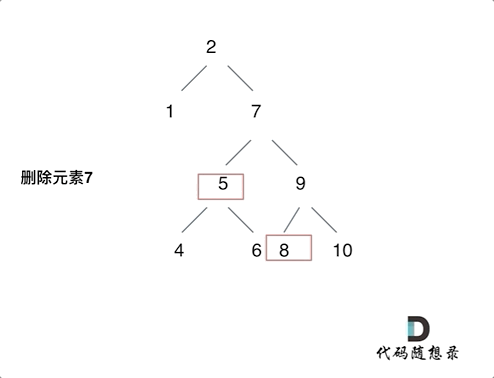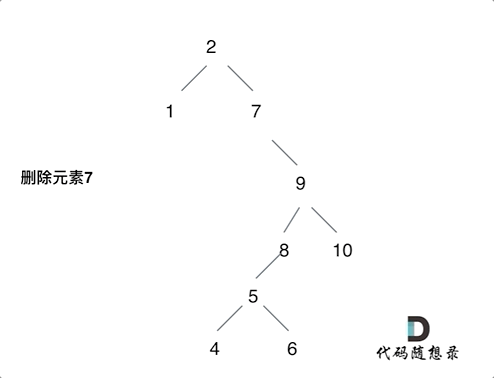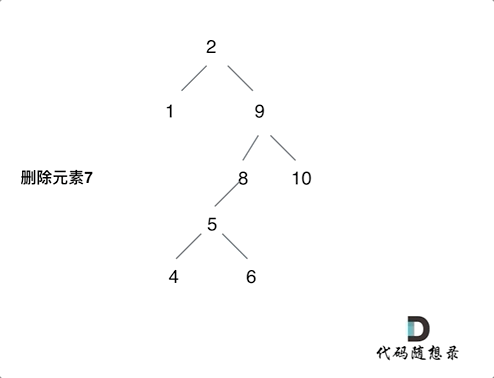
2023-12-20 二叉搜索树的最近公共祖先和二叉搜索树中的插入操作和删除二叉搜索树中的节点
235. 二叉搜索树的最近公共祖先 思想:和二叉树的公共最近祖先节点的思路基本一致的!就是不用从下往上遍历处理!可以利用的二叉搜索树的特点从上往下处理了!而且最近公共节点肯定是第一个出现在【q,p】这个区间的内的&…...
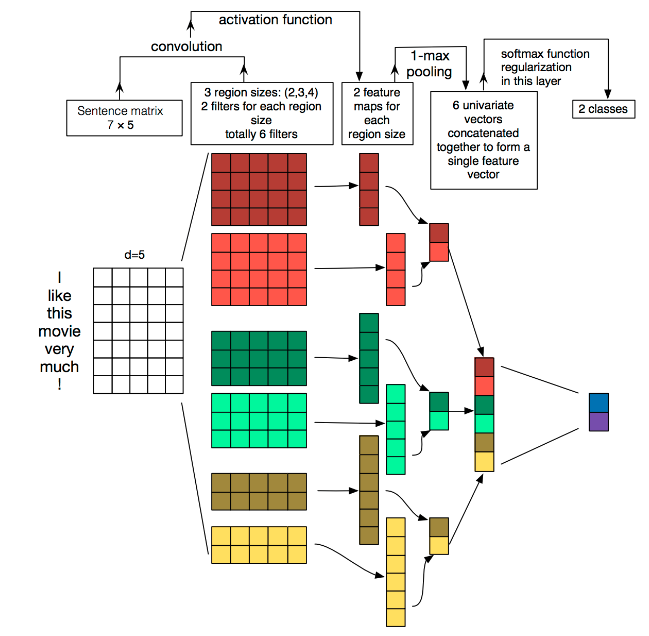
pytorch文本分类(三)模型框架(DNNtextCNN)
pytorch文本分类(三)模型框架(DNN&textCNN) 原任务链接 目录 pytorch文本分类(三)模型框架(DNN&textCNN)1. 背景知识深度学习 2. DNN2.1 从感知器到神经网络2.2 DNN的基本…...
<长篇文章!!>数据结构与算法的重要知识点与概要总结 ( •̀ ω •́ )✧✧临近考试和查漏补缺的小伙伴看这一篇就都懂啦~
目录 一、数据结构概论二、算法概论三、线性表四、栈五、队列六、串七、多维数组与矩阵八、广义表九、树与二叉树十、图 一、数据结构概论 1、数据元素和数据项 数据由数据元素组成,即数据元素是数据的基本单位,而数据元素又由若干个数据项组成…...

【安全】audispd调研
audispd调研 1 问题背景 在Linux中,当某个进程调用audit_set_pid将自己的pid保存到内核的audit模块后,如果有日志生成,kaudit内核线程就会通过netlink通信机制将审计日志发送给audit_pid,因此,只能有一个进程占用aud…...
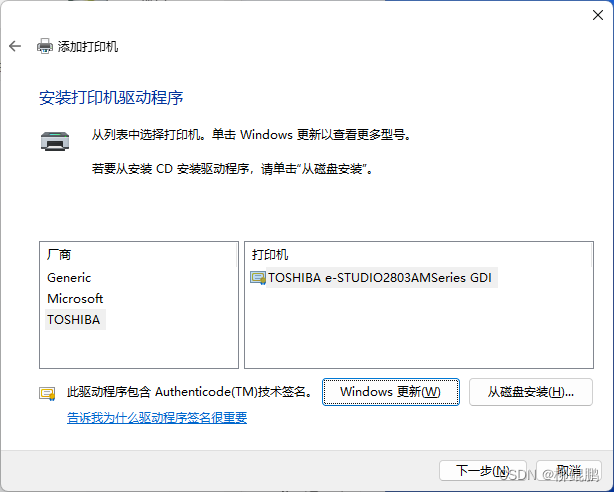
WINDOWS(WIN11)通过IP添加网络打印机
点击添加设备 点击手动添加 使用IP地址或主机名添加打印机 选择TCP/IP设备,输入打印机地址 如果有正确驱动就安装,没有就取消。 通过手动设置添加本地打印机或网络打印机 使用现有的端口 根据打印机IP,选择标准端口。 成功! 到…...

华为数通试题
选择题 华为数通推出的面向企业的云计算平台是? A) FusionSphere B) CloudEngine C) Agile Controller D) eSight 下面哪个不是华为数通的核心交换机系列? A) S12700 B) S5700 C) S9300 D) CloudEngine 华为数通的企业级路由器系列包括哪个?…...
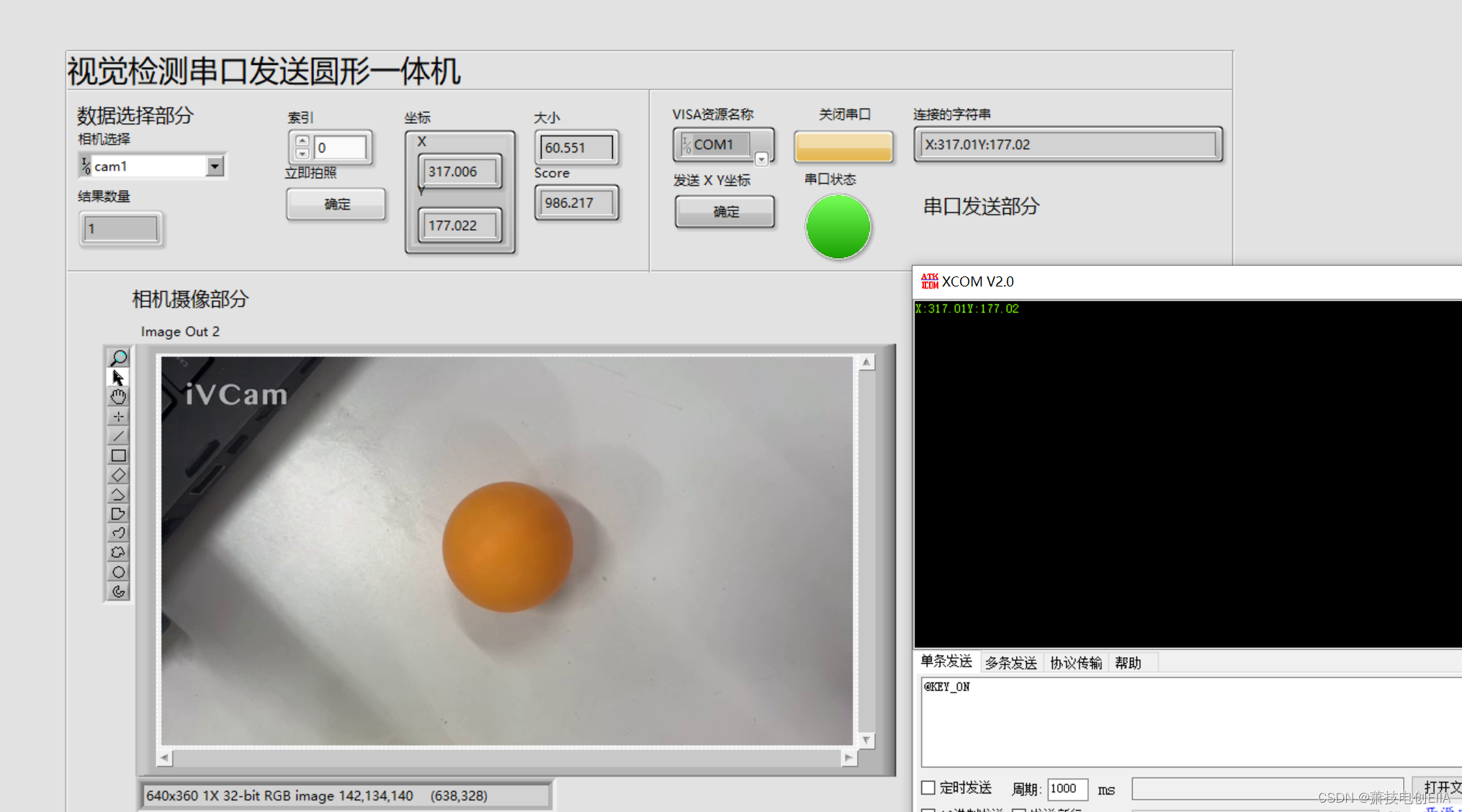
Labview Vision 机器视觉使用,从下载程序安装应用,到实战找硬币并输出值
1.前言 大家好,今天我要和机器人一起配合来打算 做机器视觉 用Labview 和 Vision 联动实现机器的视觉 2.下载软件-软件的安装 我们除了基础款的labview软件 还要安装视觉四件套 1.Labview 编程平台(我是 2023 q3) 2. NI - IMAQdx (驱动软…...

【delphi11】delphi基础探索【三、基础组件和事件】
目录 基础组件 1. TButton(按钮) 2. TLabel(标签) 3. TEdit(编辑框) 4. TMemo(多行编辑框) 5. TComboBox(组合框) 6. TCheckBox(复选框&…...

react hooks浅谈
一.useEffect useEffect是hooks中的生命周期函数 1.只要页面更新就触发回调: useEffect(() > { // 执行逻辑 }) 2.只运行一次(组件挂载和卸载时执行),第二个参数传空数组[]: useEffect(() > { // },[]) 3. 条件…...

stable diffusion webui之lora调用
1.触发词底模lora效果最好(分数不一定要取到1,0.8也行); 2.引用时一定要使用<lora:>,例如<lora:C4D_geometry_bg_v2.5:0.8>; "prompt": "(masterpiece:1.3), (best quality:1.…...

FormData文件上传多文件上传
一、简介 通常情况下,前端在使用post请求提交数据的时候,请求都是采用application/json 或 application/x-www-form-urlencoded编码类型,分别是借助JSON字符串来传递参数或者keyvalue格式字符串(多参数通过&进行连接&#…...
)
八股文打卡day4——计算机网络(4)
TCP和UDP的概念、特点、区别和对应的使用场景? 我的回答: 概念: TCP是传输控制协议,是面向连接、可靠的、基于字节流的传输层通信协议。 UDP是用户数据报协议,是无连接、不可靠的,基于数据报的传输层通信…...
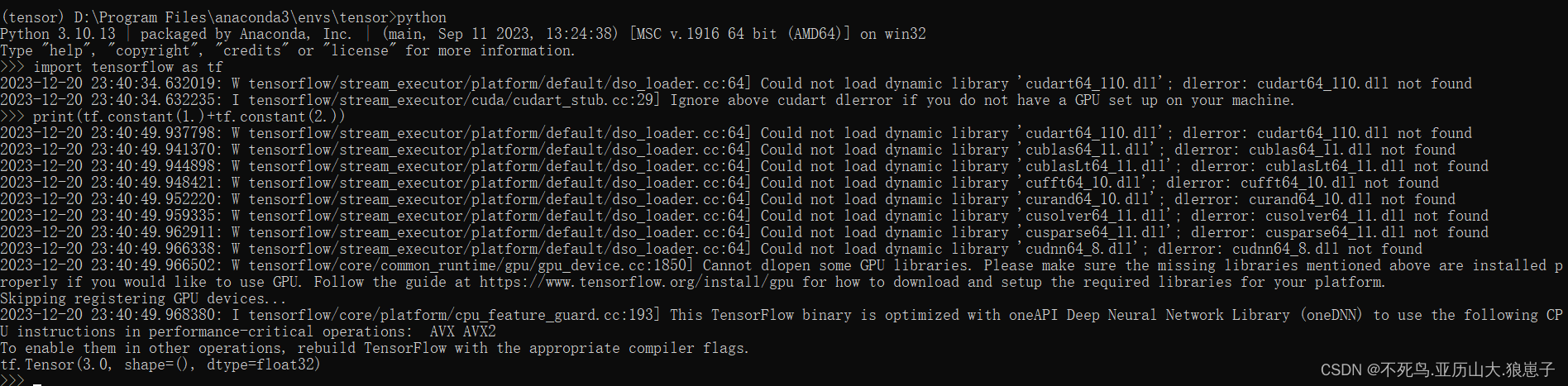
TensorFlow(2):Windows安装TensorFlow
1 安装python环境 这一步请自行安装,这边不做介绍。 2 安装anaconda 下载路径:Index of /,用户自行选择自己的需要的版本。 3 环境配置 3.1 anaconda环境配置 找到设置,点击系统->系统信息->高级系统设置->环境变量…...
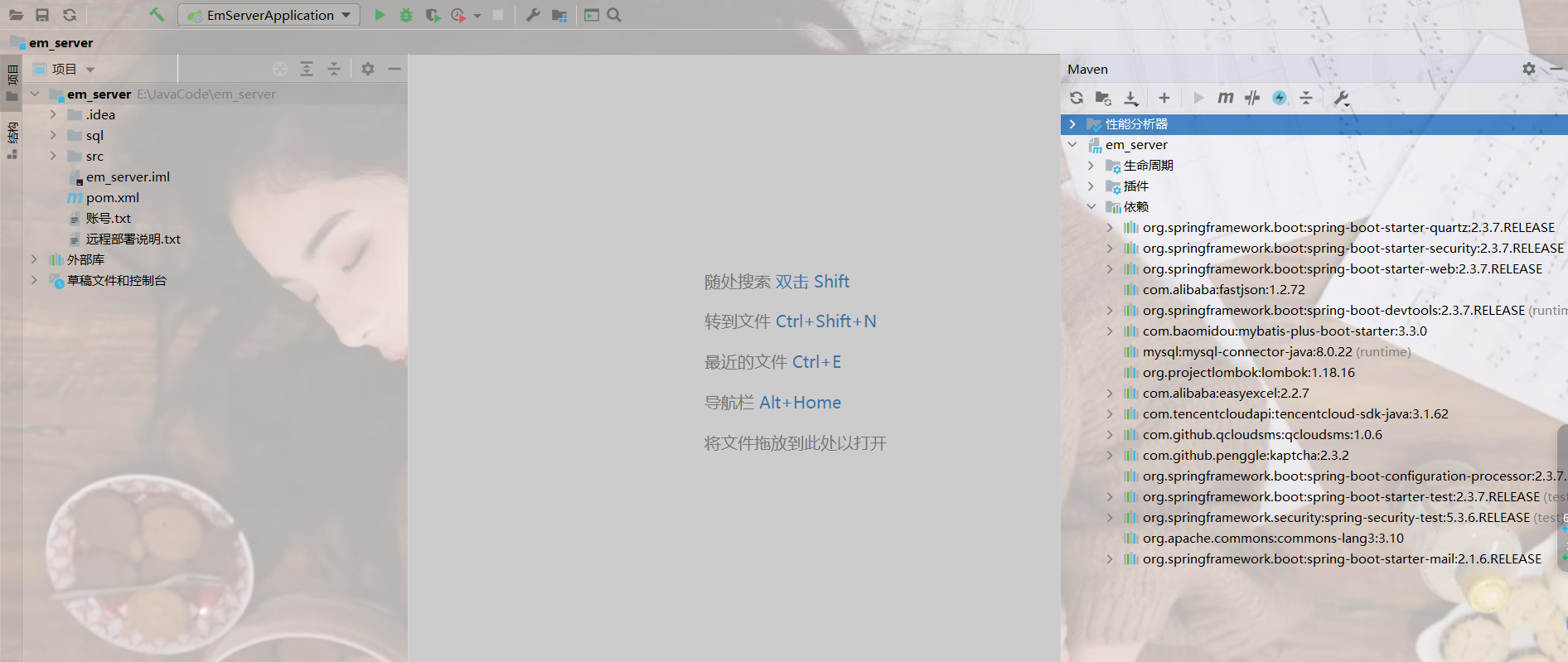
一文解决idea导入源码控制台爆红问题
文章目录 唠嗑部分背景说明idea查看maven配置 言归正传安装mavenidea配置maven 结语及资料获取 唠嗑部分 背景说明 很多新手伙伴们在导入项目源码时,都会遇到大片依赖爆红,项目跑不起来,小白也是把自己电脑重新配置了一番,复现了…...
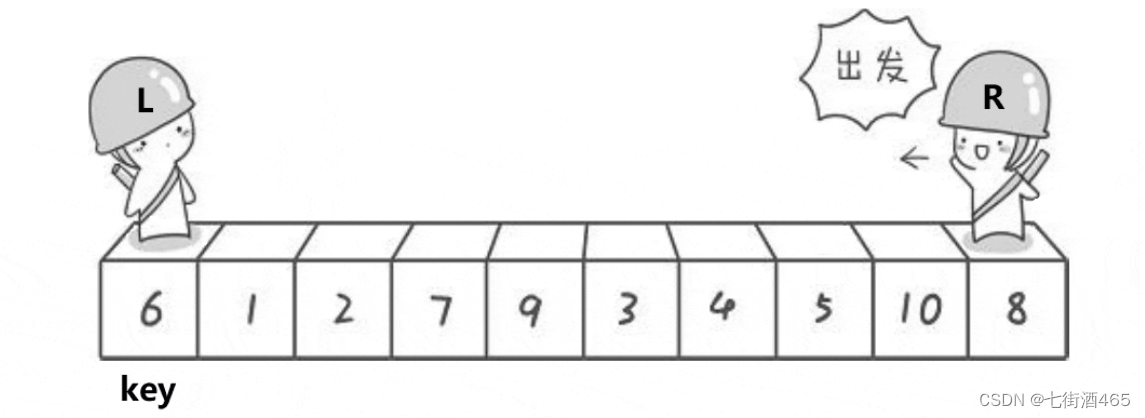
排序算法——快排
快速排序算法最早是由图灵奖获得者Tony Hoare设计出来的,他在形式化方法理论以 及ALGOL.60编程语言的发明中都有卓越的贡献,是20世纪最伟大的计算机科学家之—。 而这快速排序算法只是他众多贡献中的—个小发明而已。 快速排序(Quick Sort)的基本算法思…...
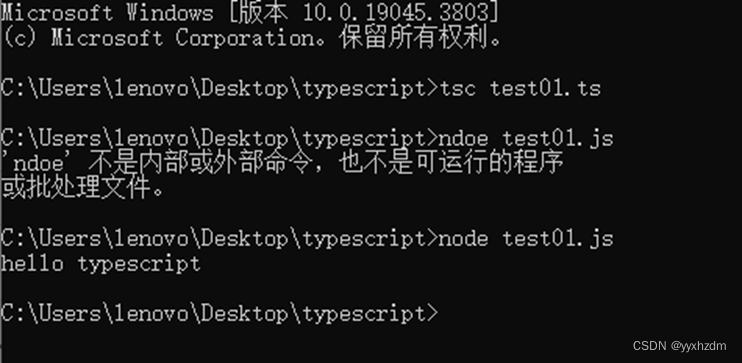
第二节TypeScript 基础语法
1、typescript程序由以下几个部分组成: 模块函数变量语句和表达式注释 2、开始第一个typescript程序 创建一个typescript程序,使之输出“hello typescript”: 代码: var message:string "hello typescript" cons…...
计算)
Go、Python、Java、JavaScript等语言的求余(取模)计算
余数符号规则: Go(%): 余数与被除数符号一致 Java(%): 余数与被除数符号一致 JavaScript(%): 余数与被除数符号一致 Python(%)…...

scrapy快加构造并发送请求
scrapy数据建模与请求 学习目标: 应用 在scrapy项目中进行建模应用 构造Request对象,并发送请求应用 利用meta参数在不同的解析函数中传递数据 1. 数据建模 通常在做项目的过程中,在items.py中进行数据建模 1.1 为什么建模 定义item即提前…...

【C++】谈谈深拷贝与浅拷贝
目录 一、浅拷贝 1.定义 2.示例 3.问题 二、深拷贝 1.定义 2.示例 3.优点 三、考虑场景 浅拷贝的考虑 1.性能要求 2.简单地数据结构 3.资源管理 深拷贝的考虑 1.动态内存分配 2.复杂数据结构 3.资源管理 总结 一、浅拷贝 1.定义 浅拷贝是指对对象进行复制时…...

LabVIEW循环进阶:隧道模式与移位寄存器的实战解析
1. LabVIEW循环基础回顾与隧道模式初探 在LabVIEW编程中,For循环是最基础也是最常用的结构之一。很多初学者都能轻松掌握循环次数N和循环索引i的基本用法,但当涉及到数据进出循环时的处理方式,往往会遇到困惑。这就是我们今天要重点讨论的隧…...

Nevis‘22基准:评估持续学习模型的计算效率与知识迁移能力
1. 项目概述:为什么我们需要一个全新的终身学习基准?在计算机视觉乃至整个机器学习领域,我们正面临一个日益尖锐的矛盾:一方面,我们希望模型能够像人类一样,在漫长的时间里持续学习新知识,不断进…...

【最新v2.7.1 版本安装包】OpenClaw 新手部署全攻略,无需命令零代码一键安装保姆级
Windows 一键部署 OpenClaw 教程|5 分钟搞定本地 AI 智能体,告别复杂配置 核心亮点 零代码门槛|全程可视化|无需手动配置运行环境|内置全部运行依赖|28 万 Tokens 额度 前言 2026 年开源圈热度居高不下…...

无人机、自动驾驶如何搞定GNSS模糊度?快速固定技巧与RTKLib实战
无人机与自动驾驶中的GNSS模糊度快速固定:RTKLib实战指南 在动态环境中实现厘米级定位的关键,往往取决于GNSS信号中整周模糊度的快速准确固定。对于无人机飞控开发者而言,模糊度固定速度直接关系到飞行轨迹的平滑性;自动驾驶工程师…...

QQ音乐加密文件解密终极指南:qmcdump工具完整教程
QQ音乐加密文件解密终极指南:qmcdump工具完整教程 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 你是否曾经…...

避开这些坑:在MATLAB中用DQN做LKA时,我的并行训练为什么失败了?
避开这些坑:在MATLAB中用DQN做LKA时,我的并行训练为什么失败了? 当你第一次在MATLAB中启用UseParalleltrue选项时,可能满怀期待地以为训练速度会直线上升。但现实往往很骨感——要么直接报错终止,要么训练效率反而比串…...

基于堆叠自编码器与LSTM的金融时间序列预测框架解析
1. 项目概述:一个基于多层神经网络的股票回报预测框架如果你对量化交易和机器学习结合感兴趣,并且已经厌倦了那些简单的线性回归或者单层LSTM模型,那么这个名为AIAlpha的项目可能会让你眼前一亮。它不是一个“即插即用”的盈利策略࿰…...
)
WPF动画避坑指南:Blend路径动画Canvas.Left与RenderTransform的实战选择(附性能对比)
WPF动画避坑指南:Blend路径动画Canvas.Left与RenderTransform的实战选择(附性能对比) 在WPF开发中,动画效果的实现往往让开发者陷入选择困境。特别是当我们需要让UI元素沿着复杂路径运动时,Canvas.Left/Top与RenderTra…...

9. 找到字符串中所有字母异位词
给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。方法一:哈希表class Solution(object):def findAnagrams(self, s, p):result{}result["".join(sorted(p))][]for i in ra…...

嵌入式系统安全设计:挑战、原则与微内核实践
1. 嵌入式系统安全的设计挑战与核心原则在万物互联的时代背景下,嵌入式系统已从封闭的独立设备转变为网络化智能节点。这种转变带来了前所未有的安全挑战——根据工业安全机构的统计,2022年针对工业控制系统的网络攻击同比增加了87%,其中针对…...