【halcon深度学习之那些封装好的库函数】determine_dl_model_detection_param
determine_dl_model_detection_param
目标检测的数据准备过程中的有一个库函数determine_dl_model_detection_param
“determine_dl_model_detection_param” 直译为 “确定深度学习模型检测参数”。
这个过程会自动针对给定数据集估算模型的某些高级参数,强烈建议使用这一过程来优化训练和推断性能。
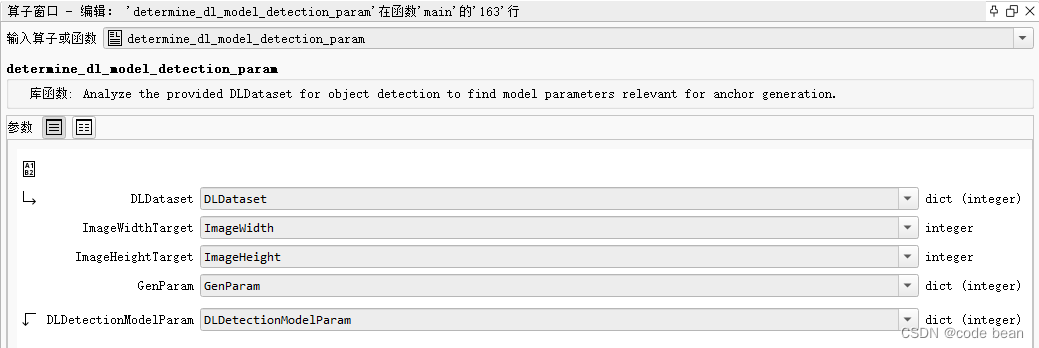
过程签名
determine_dl_model_detection_param(: : DLDataset, ImageWidthTarget, ImageHeightTarget, GenParam : DLDetectionModelParam)
描述
该过程用于分析提供的深度学习数据集(DLDataset)以进行目标检测,以确定与锚点生成相关的模型参数。生成的DLDetectionModelParam是一个包含建议值的字典,用于各种目标检测模型的参数。
参数
- DLDataset:用于目标检测的深度学习数据集的字典。
- ImageWidthTarget:作为模型输入的目标图像宽度(经过预处理后的图像宽度)。
- ImageHeightTarget:作为模型输入的目标图像高度(经过预处理后的图像高度)。
- GenParam:包含通用输入参数的字典。
- DLDetectionModelParam:包含建议的模型参数的输出字典。
参数解析
第一个参数DLDataset,就是我们读取到的数据集,数据集 (数据集就是我们标注好的图片数据集, 我们可以通过 read_dict() 读取halcon提供的数据集。也可以通过 read_dl_dataset_from_coco 读取通用的coco数据集)
图片缩放
第二,第三个参数,是图片的大小设置。我们知道数据集里是有描述图片原始大小的数据的。这里需要你输入预处理后图片的大小,也就是说,你可以通过这两个参数对图片进行缩放。一般我们会设置一个较小的大小,已加快训练的速度!
GenParam
GenParam 是一个字典,包含一些通用的输入参数,可以用来影响 determine_dl_model_detection_param 过程中参数的确定。
使用输入字典GenParam,可以进一步影响参数的确定。可以设置不同的键值对来影响锚点生成和模型参数的确定。
你可以根据你的需求在 GenParam 中设置不同的键值对来调整算法的行为。以下是键和对应的值:
-
‘anchor_num_subscales’: 整数值(大于0),确定搜索锚点子尺度数量的上限值。默认值为3。
-
‘class_ids_no_orientation’: 元组,包含表示类别标识的整数值。设置那些应该忽略方向的类别的标识。这些被忽略类别的边界框被视为方向为0的轴对齐边界框。仅适用于检测实例类型为’rectangle2’的情况。
-
‘display_histogram’: 确定是否显示数据直方图以进行数据集的视觉分析。可能的值有’true’和’false’(默认为’false’)。
-
‘domain_handling’: 指定图像域的处理方式。可能的值有:
'full_domain'(默认):图像不被裁剪。'crop_domain':图像被缩小到其域定义。'ignore_direction':布尔值(或’true’/‘false’),确定是否考虑边界框的方向。仅在检测实例类型为’rectangle2’的情况下可用。参考 ‘get_dl_model_param’ 文档以获取有关此参数的更多信息。
-
‘max_level’: 整数值(大于1),确定搜索最大层级的上限值。默认值为6。
-
‘max_num_samples’: 整数值(大于0或-1),确定用于确定参数值的最大样本数。如果设置为-1,则选择所有样本。请注意,不要将此值设置得太高,因为这可能导致内存消耗过大,对机器造成高负载。然而,如果 ‘max_num_samples’ 设置得太低,确定的检测参数可能无法很好地代表数据集。默认值为1500。
-
‘min_level’: 整数值(大于1),确定搜索最小层级的下限值。默认值为2。
-
‘preprocessed_path’: 指定预处理目录的路径。预处理目录包含DLDataset的字典(.hdict文件),以及一个名为’samples’的子目录,其中包含预处理的样本(例如,由过程’preprocess_dl_dataset’生成)。对于已经预处理的数据集,将忽略输入参数ImageWidthTarget和ImageHeightTarget,并可将它们设置为[]。仅当数据集已经为应用程序进行了预处理时,此参数才适用。
-
‘image_size_constant’: 如果将此参数设置为’true’,则假定数据集中的所有图像具有相同的大小,以加速处理。图像大小由数据集中的第一个样本确定。此参数仅在数据集尚未预处理且’domain_handling’为’full_domain’时适用。默认值为’true’。
-
‘split’: 确定用于分析的数据集拆分。可能的值包括 ‘train’(默认)、‘validation’、‘test’ 和 ‘all’。如果指定的拆分无效或数据集未创建拆分,则使用所有样本。
-
‘compute_max_overlap’: 如果将此参数设置为’true’,将为数据集确定检测参数 ‘max_overlap’ 和 ‘max_overlap_class_agnostic’。
建议的模型参数 DLDetectionModelParam
DLDetectionModelParam是模型的输出参数
输出字典(DLDetectionModelParam)包括以下参数的建议值:
- ‘class_ids’:类别标识
- ‘class_names’:类别名称
- ‘image_width’:图像宽度
- ‘image_height’:图像高度
- ‘min_level’:最小层级
- ‘max_level’:最大层级
- ‘instance_type’:实例类型
- ‘anchor_num_subscales’:锚点子尺度数量
- ‘anchor_aspect_ratios’:锚点纵横比
- ‘anchor_angles’:锚点角度(仅用于’instance_type’为’rectangle2’的模型)
- ‘ignore_direction’:是否忽略方向(仅用于’instance_type’为’rectangle2’的模型)
- ‘max_overlap’:最大重叠度(如果’compute_max_overlap’设置为’true’)
- ‘max_overlap_class_agnostic’:最大重叠度(如果’compute_max_overlap’设置为’true’)
注意事项
文档中提到的返回值是对模型运行时间和检测性能之间的折衷的近似值,可能需要进一步的实验来优化参数。此外,建议的参数是基于原始数据集而不考虑训练期间可能的数据增强。如果应用了某些数据增强方法(如’mirror’、‘rotate’),可能需要调整生成的参数以涵盖所有边界框形状。
小结
determine_dl_model_detection_param 会根据输入的数据集,得到模型的某些高级参数,这些高级参数会用到后续的训练和推理。换句话说,训练和推理需要用到一些高级参数。 而这个函数,可以根据输入的数据集,帮你分析,然后得到这些高级参数的值,让你用于后续的操作!这个函数让我们后续调参有了一定的依据!
代码上下文
*
* ************************
* ** Set parameters ***
* ************************
*
* Set obligatory parameters.
Backbone := 'pretrained_dl_classifier_compact.hdl'
NumClasses := 10
* Image dimensions of the network. Later, these values are
* used to rescale the images during preprocessing.
ImageWidth := 512
ImageHeight := 320* Read in a DLDataset.
* Here, we read the data from a COCO file.
* Alternatively, you can read a DLDataset dictionary
* as created by e.g., the MVTec Deep Learning Tool using read_dict().
read_dl_dataset_from_coco (PillBagJsonFile, HalconImageDir, dict{read_segmentation_masks: false}, DLDataset)
*
* Split the dataset into train/validation and test.
split_dl_dataset (DLDataset, TrainingPercent, ValidationPercent, [])
*
* **********************************************
* ** Determine model parameters from data ***
* **********************************************
*
* Generate model parameters min_level, max_level, anchor_num_subscales,
* and anchor_aspect_ratios from the dataset in order to improve the
* training result. Please note that optimizing the model parameters too
* much on the training data can lead to overfitting. Hence, this should
* only be done if the actual application data are similar to the training
* data.
GenParam := dict{['split']: 'train'}
*
determine_dl_model_detection_param (DLDataset, ImageWidth, ImageHeight, GenParam, DLDetectionModelParam)
*
* Get the generated model parameters.
MinLevel := DLDetectionModelParam.min_level
MaxLevel := DLDetectionModelParam.max_level
AnchorNumSubscales := DLDetectionModelParam.anchor_num_subscales
AnchorAspectRatios := DLDetectionModelParam.anchor_aspect_ratios
*
* *******************************************
* ** Create the object detection model ***
* *******************************************
*
* Create dictionary for generic parameters and create the object detection model.
DLModelDetectionParam := dict{}
DLModelDetectionParam.image_width := ImageWidth
DLModelDetectionParam.image_height := ImageHeight
DLModelDetectionParam.image_num_channels := ImageNumChannels
DLModelDetectionParam.min_level := MinLevel
DLModelDetectionParam.max_level := MaxLevel
DLModelDetectionParam.anchor_num_subscales := AnchorNumSubscales
DLModelDetectionParam.anchor_aspect_ratios := AnchorAspectRatios
DLModelDetectionParam.capacity := Capacity
*
* Get class IDs from dataset for the model.
ClassIDs := DLDataset.class_ids
DLModelDetectionParam.class_ids := ClassIDs
* Get class names from dataset for the model.
ClassNames := DLDataset.class_names
DLModelDetectionParam.class_names := ClassNames
*
* Create the model.
create_dl_model_detection (Backbone, NumClasses, DLModelDetectionParam, DLModelHandle)
*
* Write the initialized DL object detection model
* to train it later in part 2.
write_dl_model (DLModelHandle, DLModelFileName)
*
*
* *********************************
* ** Preprocess the dataset ***
* *********************************
*
* Get preprocessing parameters from model.
create_dl_preprocess_param_from_model (DLModelHandle, 'none', 'full_domain', [], [], [], DLPreprocessParam)
*
* Preprocess the dataset. This might take a few minutes.
GenParam := dict{overwrite_files: 'auto'}
preprocess_dl_dataset (DLDataset, DataDirectory, DLPreprocessParam, GenParam, DLDatasetFilename)
*
* Write preprocessing parameters to use them in later parts.
write_dict (DLPreprocessParam, PreprocessParamFileName, [], [])从这里,我们就看到了,create_dl_model_detection 创建检测模型的时候,就用到了这些参数了!后续的训练过程中也会用到,我们下一篇见
相关文章:
【halcon深度学习之那些封装好的库函数】determine_dl_model_detection_param
determine_dl_model_detection_param 目标检测的数据准备过程中的有一个库函数determine_dl_model_detection_param “determine_dl_model_detection_param” 直译为 “确定深度学习模型检测参数”。 这个过程会自动针对给定数据集估算模型的某些高级参数,强烈建议…...
跟着我学Python进阶篇:01.试用Python完成一些简单问题
往期文章 跟着我学Python基础篇:01.初露端倪 跟着我学Python基础篇:02.数字与字符串编程 跟着我学Python基础篇:03.选择结构 跟着我学Python基础篇:04.循环 跟着我学Python基础篇:05.函数 跟着我学Python基础篇&#…...

neo4j-Py2neo使用
neo4j-Py2neo(一):基本库介绍使用 py2neo的文档地址:https://neo4j-contrib.github.io/py2neo/ py2neo的本质是可以采用两种方式进行操作,一种是利用cypher语句,一种是使用库提供的DataTypes,Data类的实例需要和远程…...
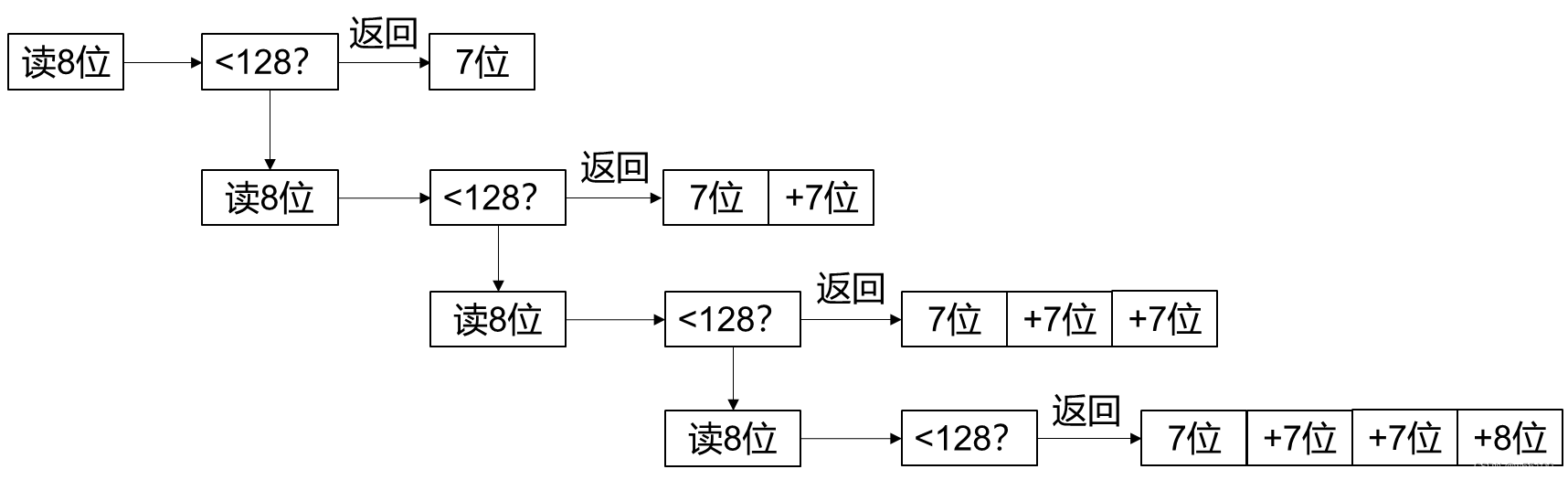
uint29传输格式
前言 不知道谁想出来的。 反正我是想不到。 我看网上也没人讲这个。 写篇博客帮一下素未谋面的网友。 uint29 本质上是网络传输的时候,借用至多4字节Bytes,表达29位的无符号整数。 读8位数字,判断小于128? 是的话,返回末7位…...
Linux:终端定时自动注销
这样防止了,当我们临时离开电脑这个空隙,被坏蛋给趁虚而入 定几十秒或者分钟,如果这个时间段没有输入东西那么就会自动退出 全局生效 这个系统中的所有用户生效 vim /etc/profile在末尾加入TMOUT10 TMOUT10 这个就是10 秒,按…...
STM32F103RCT6开发板M3单片机教程06--定时器中断
前言 除非特别说明,本章节描述的模块应用于整个STM32F103xx微控制器系列,因为我们使用是STM32F103RCT6开发板是mini最小系统板。本教程使用是(光明谷SUN_STM32mini开发板) STM32F10X定时器(Timer)基础 首先了解一下是STM32F10X…...
数据库故障Waiting for table metadata lock
场景:早上来发现一个程序,链接mysql数据库有点问题,随后排查,因为容器在k8s里面。所以尝试重启了pod没有效果 一、重启pod: 这里是几种在Kubernetes中重启Pod的方法: 删除Pod,利用Deployment重建 kubectl delete pod mypodDepl…...

Springboot数据校验与异常篇
一、异常处理 1.1Http状态码 HTTP状态码是指在HTTP通信过程中,服务器向客户端返回的响应状态。它通过3位数字构成,第一个数字定义了响应的类别,后两位数字没有具体分类作用。以下是常见的HTTP状态码及其含义: - 1xx(信…...

第三十六章 XML 模式的高级选项 - 创建子类型的替换组
文章目录 第三十六章 XML 模式的高级选项 - 创建子类型的替换组创建子类型的替换组将子类限制在替换组中 第三十六章 XML 模式的高级选项 - 创建子类型的替换组 创建子类型的替换组 XML 模式规范还允许定义替换组,这可以是创建选择的替代方法。语法有些不同。无需…...
堆与二叉树(上)
本篇主要讲的是一些概念,推论和堆的实现(核心在堆的实现这一块) 涉及到的一些结论,证明放到最后,可以选择跳过,知识点过多,当复习一用差不多,如果是刚学这一块的,建议打…...

HBase查询的一些限制与解决方案
Apache HBase 是一个开源的、非关系型、分布式数据库,它是 Hadoop 生态系统的一部分,用于存储和处理大量的稀疏数据。HBase 在设计上是为了提供快速的随机读写能力,但与此同时,它也带来了一些查询上的限制: 没有SQL支持…...

软件开发 VS Web开发
我的新书《Android App开发入门与实战》已于2020年8月由人民邮电出版社出版,欢迎购买。点击进入详情 目录 介绍: 角色和职责: 软件开发人员: Web开发人员: 技能: 软件开发人员: Web开发人…...
基于Springboot的旅游网站设计与实现(论文+调试+源码)
项目描述 临近学期结束,还是毕业设计,你还在做java程序网络编程,期末作业,老师的作业要求觉得大了吗?不知道毕业设计该怎么办?网页功能的数量是否太多?没有合适的类型或系统?等等。这里根据疫情当下,你想解决的问…...
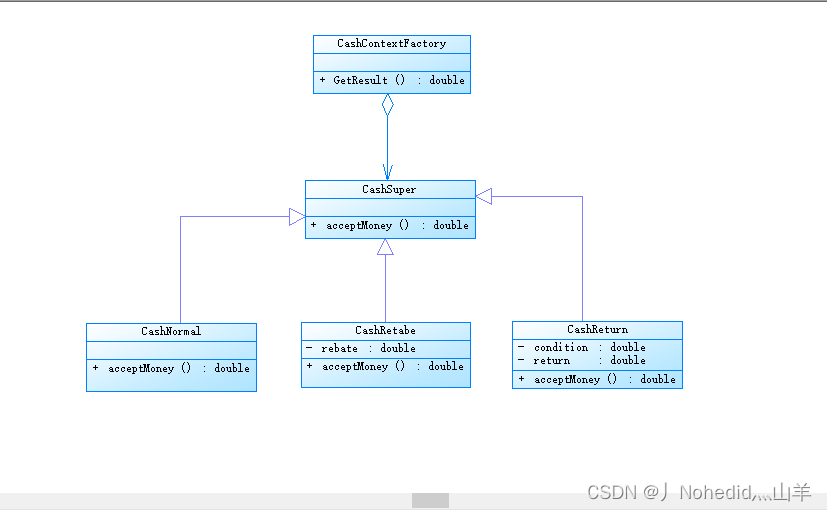
【从零开始学习--设计模式--策略模式】
返回首页 前言 感谢各位同学的关注与支持,我会一直更新此专题,竭尽所能整理出更为详细的内容分享给大家,但碍于时间及精力有限,代码分享较少,后续会把所有代码示例整理到github,敬请期待。 此章节介绍策…...
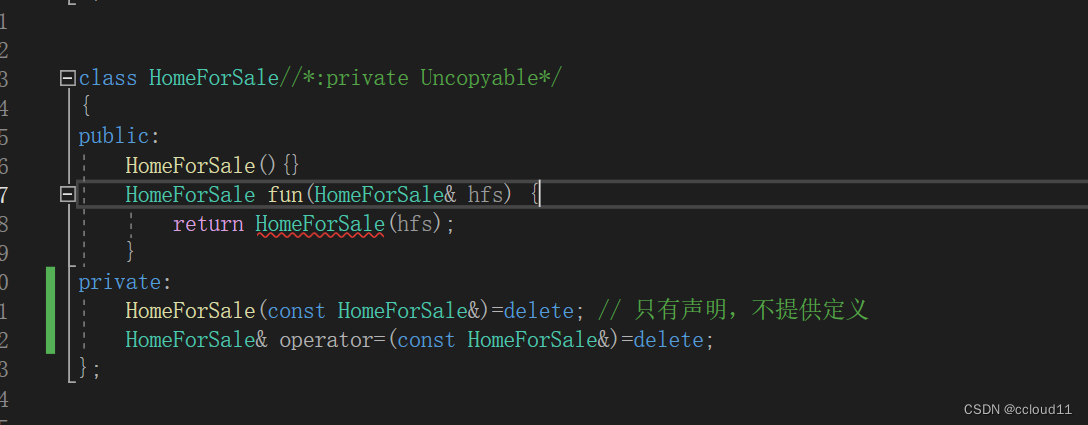
条款6:若不想使用编译器自动生成的函数,就该明确拒绝
有些场景我们不需要编译器默认实现的构造函数,拷贝构造函数,赋值函数,这时候我们应该明确的告诉编译器,我们不需要,一个可行的方法是将拷贝构造函数和赋值函数声明为private。 class HomeForSale { ... }; HomeForSal…...
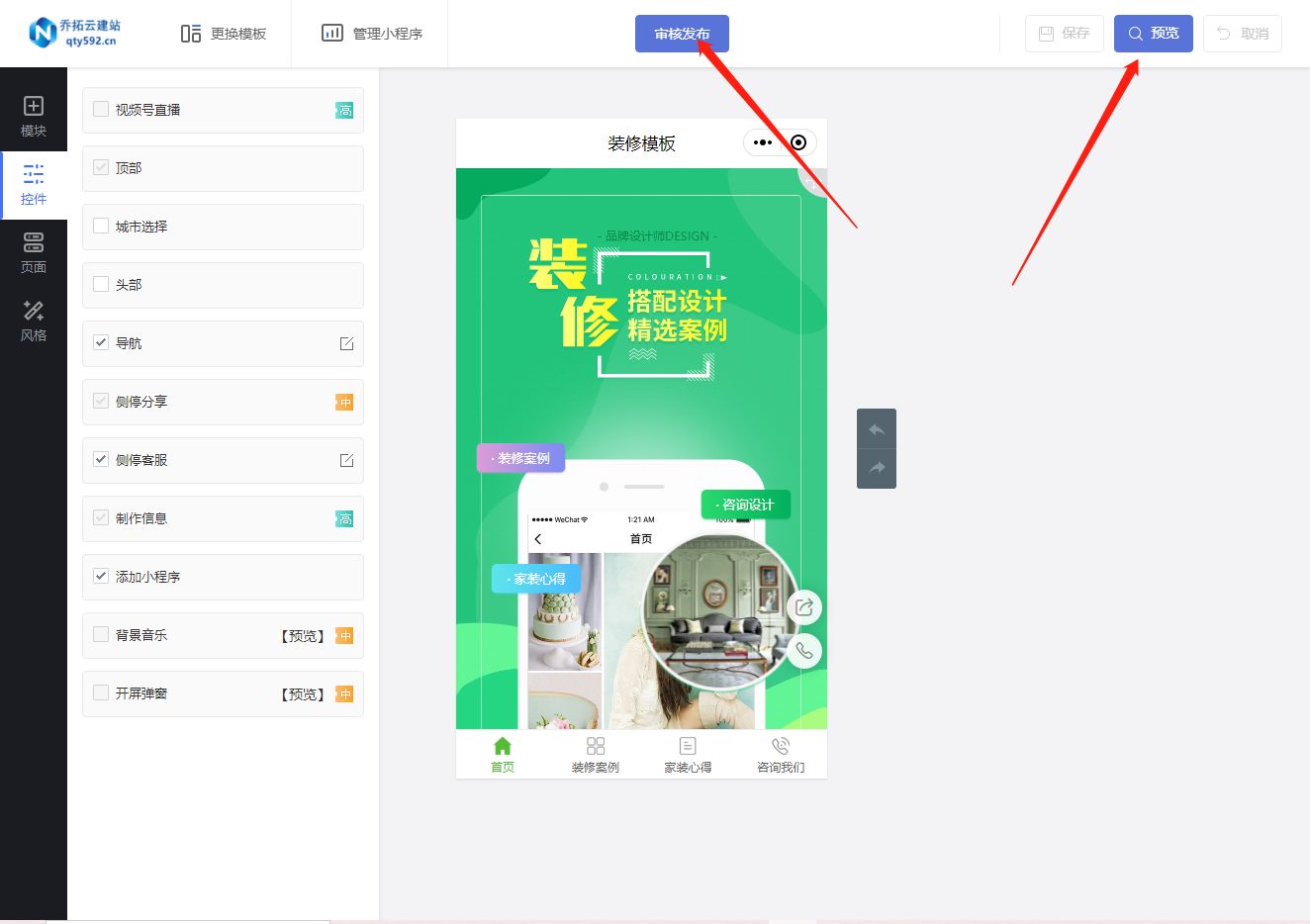
零基础也能制作家装预约咨询小程序
近年来,随着互联网的快速发展,越来越多的消费者倾向于使用手机进行购物和咨询。然而,许多家装实体店却发现自己的客流量越来越少,急需一种新的方式来吸引顾客。而开发家装预约咨询小程序则成为了一种利用互联网技术来解决这一问题…...

Mybatis的插件运⾏原理,如何编写⼀个插件?
🚀 作者主页: 有来技术 🔥 开源项目: youlai-mall 🍃 vue3-element-admin 🍃 youlai-boot 🌺 仓库主页: Gitee 💫 Github 💫 GitCode 💖 欢迎点赞…...

C++复合数据类型:字符数组|读取键盘输入|简单读写文件
文章目录 字符数组(C风格字符串)读取键盘输入使用输入操作符读取单词读取一行信息getline使用get读取一个字符 读写文件 字符数组(C风格字符串) 字符串就是一串字符的集合,本质上其实是一个“字符的数组”。 在C中为了…...
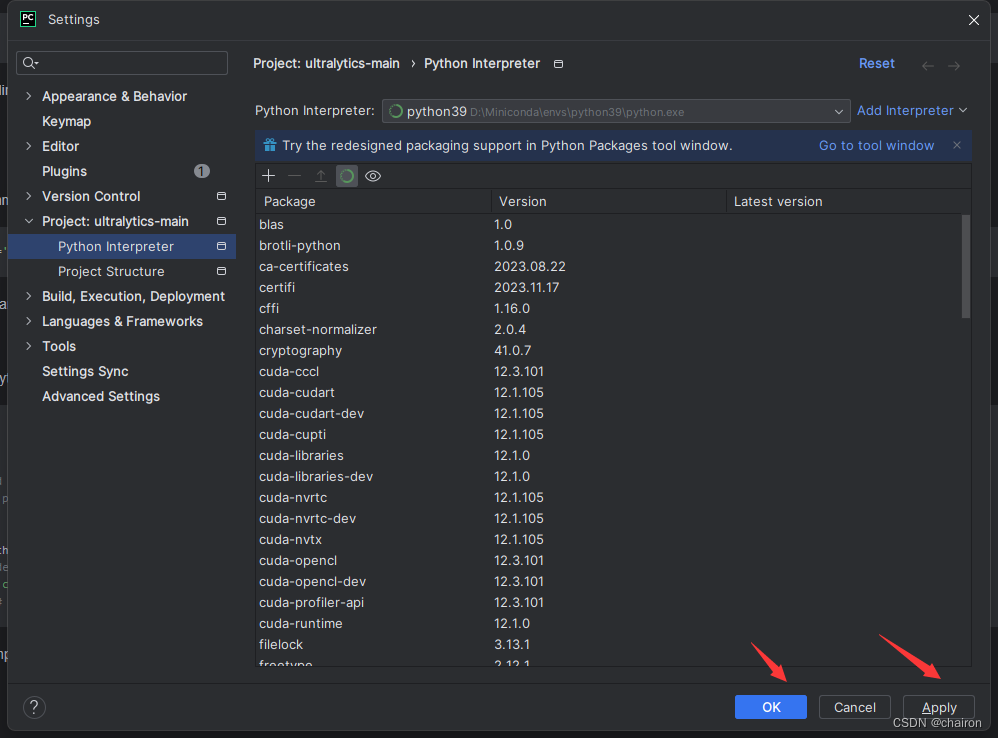
Windows11环境下配置深度学习环境(Pytorch)
目录 1. 下载安装Miniconda2. 新建Python3.9虚拟环境3. 下载英伟达驱动4. 安装CUDA版Pytorch5. CPU版本pytorch安装6. 下载并配置Pycharm 1. 下载安装Miniconda 下载安装包:镜像文件地址 将Miniconda相关路径添加至系统变量的路径中。 打开Anaconda Powershell Pr…...
泛型深入理解
泛型的概述 泛型:是JDK5中引入的特性,可以在编译阶段约束操作的数据类型,并进行检查。 泛型的格式:<数据类型>; 注意:泛型只能支持引用数据类型。 集合体系的全部接口和实现类都是支持泛型的使用的。 泛型的…...

Redis集群模式下如何高效模糊匹配Key?RedisTemplate+Scan全节点遍历实战
Redis集群环境下高效模糊匹配Key的工程实践 Redis作为高性能缓存数据库,在分布式系统中扮演着重要角色。当系统规模扩大,单节点Redis无法满足需求时,集群模式成为必然选择。但在集群环境下,如何高效地进行模糊Key匹配却成为开发者…...

计算机毕业设计springboot基于Android的运动助手 基于SpringBoot框架的个人健身管理平台设计与实现 面向Android用户的智能运动健康追踪系统开发
计算机毕业设计springboot基于Android的运动助手c6672log (配套有源码 程序 mysql数据库 论文) 本套源码可以在文本联xi,先看具体系统功能演示视频领取,可分享源码参考。随着现代生活节奏加快和工作压力增大,健康问题日益受到人们…...
)
从零到一:STM32F407 HAL库定时器中断精准点亮LED(CubeMX实战)
1. 开发环境搭建与硬件准备 第一次接触STM32开发的朋友可能会被各种专业术语吓到,但其实只要跟着步骤来,配置开发环境就像搭积木一样简单。我手头用的是正点原子探索者V3开发板,主控芯片是STM32F407ZGT6,这块板子对新手特别友好&a…...

别再死记公式!一张图带你理清随机过程家族:从泊松、马尔可夫到维纳过程
随机过程家族图谱:用生活场景破解泊松、马尔可夫与维纳过程 想象一下午后的咖啡馆,顾客推门的间隔时间、咖啡师制作饮品的速度、甚至窗外飘落的樱花轨迹——这些看似无关的现象,背后都藏着随机过程的精妙规律。对于学习《随机过程》的同学们来…...
)
腾讯云GPU服务器上,手把手教你5分钟搞定Isaac Sim 5.0环境(附VNC黑屏自救指南)
腾讯云GPU服务器5分钟极速部署Isaac Sim 5.0全攻略 在机器人仿真与AI训练领域,NVIDIA Isaac Sim已成为行业标杆工具。但许多开发者在云端部署时,往往耗费数小时甚至数天时间卡在环境配置环节。本文将基于腾讯云GPU服务器,分享一套经过实战验证…...

ArcGIS缓冲区与叠加分析在环境评估中的实战应用
1. ArcGIS缓冲区与叠加分析基础概念 当你第一次听说"缓冲区"和"叠加分析"这两个词时,可能会觉得这是很高深的技术术语。其实它们的原理非常简单,就像我们日常生活中常见的场景。想象一下,如果你在小区里扔了一块石头&…...

铜钟音乐:告别广告与社交干扰的纯净听歌工具
铜钟音乐:告别广告与社交干扰的纯净听歌工具 【免费下载链接】tonzhon-music 铜钟 (Tonzhon.com): 免费听歌; 没有直播, 社交, 广告, 干扰; 简洁纯粹, 资源丰富, 体验独特!(密码重置功能已回归) 项目地址: https://gitcode.com/GitHub_Trending/to/ton…...

Go语言中的Kubernetes部署实战
Go语言中的Kubernetes部署实战 Kubernetes作为容器编排的事实标准,已经成为现代云原生应用部署的基石。本文将深入介绍如何将Go语言应用部署到Kubernetes集群,从基础概念到生产实践,帮助你掌握容器编排的核心技能。 Kubernetes核心概念 Pod&a…...

从智能电池到服务器风扇:手把手解析SMBus的15种通信协议与应用实例
从智能电池到服务器风扇:手把手解析SMBus的15种通信协议与应用实例 当你在笔记本电脑上看到剩余电量精确到1%时,或是服务器机柜里的风扇根据温度自动调节转速时,背后都有一个低调的"通信专家"在默默工作——它就是SMBus࿰…...

智能排障:借助快马AI构建Vivado安装问题自动诊断与修复助手
作为一名FPGA开发者,Vivado安装过程中的各种报错简直是家常便饭。每次遇到新问题都要花大量时间搜索解决方案,效率实在太低。最近尝试用InsCode(快马)平台的AI能力搭建了一个智能诊断工具,效果出乎意料的好,分享下具体实现思路。 …...