爬虫scrapy中间件的使用
爬虫scrapy中间件的使用
学习目标:
- 应用 scrapy中使用间件使用随机UA的方法
- 应用 scrapy中使用代理ip的的方法
- 应用 scrapy与selenium配合使用
1. scrapy中间件的分类和作用
1.1 scrapy中间件的分类
根据scrapy运行流程中所在位置不同分为:
- 下载中间件
- 爬虫中间件
1.2 scrapy中间的作用:预处理request和response对象
- 对header以及cookie进行更换和处理
- 使用代理ip等
- 对请求进行定制化操作,
但在scrapy默认的情况下 两种中间件都在middlewares.py一个文件中
爬虫中间件使用方法和下载中间件相同,且功能重复,通常使用下载中间件
2. 下载中间件的使用方法:
接下来我们对腾讯招聘爬虫进行修改完善,通过下载中间件来学习如何使用中间件
编写一个Downloader Middlewares和我们编写一个pipeline一样,定义一个类,然后在setting中开启
Downloader Middlewares默认的方法:
- process_request(self, request, spider):
- 当每个request通过下载中间件时,该方法被调用。
2. 返回None值:没有return也是返回None,该request对象传递给下载器,或通过引擎传递给其他权重低的process_request方法
3. 返回Response对象:不再请求,把response返回给引擎
4. 返回Request对象:把request对象通过引擎交给调度器,此时将不通过其他权重低的process_request方法
- 当每个request通过下载中间件时,该方法被调用。
- process_response(self, request, response, spider):
- 当下载器完成http请求,传递响应给引擎的时候调用
2. 返回Resposne:通过引擎交给爬虫处理或交给权重更低的其他下载中间件的process_response方法
3. 返回Request对象:通过引擎交给调取器继续请求,此时将不通过其他权重低的process_request方法
- 当下载器完成http请求,传递响应给引擎的时候调用
- 在settings.py中配置开启中间件,权重值越小越优先执行
3. 定义实现随机User-Agent的下载中间件
3.1 在middlewares.py中完善代码 middlewares.py中自带的代码可以删除掉
import random
from Tencent.settings import USER_AGENTS_LIST # 注意导入路径,请忽视pycharm的错误提示class UserAgentMiddleware(object):def process_request(self, request, spider):user_agent = random.choice(USER_AGENTS_LIST)request.headers['User-Agent'] = user_agent # 不写return class CheckUA:def process_response(self,request,response,spider):print(request.headers['User-Agent'])return response # 不能少!
3.2 在settings中设置开启自定义的下载中间件,设置方法同管道
DOWNLOADER_MIDDLEWARES = {'Tencent.middlewares.UserAgentMiddleware': 543, # 543是权重值'Tencent.middlewares.CheckUA': 600, # 先执行543权重的中间件,再执行600的中间件
}
3.3 在settings中添加UA的列表
USER_AGENTS_LIST = ["Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)","Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)","Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)","Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)","Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6","Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1","Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0","Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
运行爬虫观察现象
4. 代理ip的使用
4.1 思路分析
- 代理添加的位置:request.meta中增加
proxy字段 - 获取一个代理ip,赋值给
request.meta['proxy']- 代理池中随机选择代理ip
- 代理ip的webapi发送请求获取一个代理ip
4.2 具体实现
免费代理ip:
class ProxyMiddleware(object):def process_request(self,request,spider):# proxies可以在settings.py中,也可以来源于代理ip的webapi# proxy = random.choice(proxies) # 免费的会失效,报 111 connection refused 信息!重找一个代理ip再试proxy = 'https://1.71.188.37:3128' request.meta['proxy'] = proxyreturn None # 可以不写return
收费代理ip:
# 人民币玩家的代码(使用abuyun提供的代理ip)
import base64# 代理隧道验证信息 这个是在那个网站上申请的
proxyServer = 'http://proxy.abuyun.com:9010' # 收费的代理ip服务器地址,这里是abuyun
proxyUser = 用户名
proxyPass = 密码
proxyAuth = "Basic " + base64.b64encode(proxyUser + ":" + proxyPass)class ProxyMiddleware(object):def process_request(self, request, spider):# 设置代理request.meta["proxy"] = proxyServer# 设置认证request.headers["Proxy-Authorization"] = proxyAuth
4.3 检测代理ip是否可用
在使用了代理ip的情况下可以在下载中间件的process_response()方法中处理代理ip的使用情况,如果该代理ip不能使用可以替换其他代理ip
class ProxyMiddleware(object):......def process_response(self, request, response, spider):if response.status != '200':request.dont_filter = True # 重新发送的请求对象能够再次进入队列return requst
在settings.py中开启该中间件
5. 在中间件中使用selenium
5.1 在爬虫文件中配置好浏览器信
#设置一个无头无可视化界面的浏览器
chrome_options = Options()
# 无可视化界面
chrome_options.add_argument("--headless")
chrome_options.add_argument("--di sable-gpu")
# 规避监测
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
self.browse = webdriver.Chrome(options=chrome_options)
5.2 在middlewares.py中使用selenium
# 开始拦截篡改下载中间件
class NewsSpiderDownloaderMiddleware:# Not all methods need to be defined. If a method is not defined,# scrapy acts as if the downloader middleware does not modify the# passed objects.@classmethoddef from_crawler(cls, crawler):# This method is used by Scrapy to create your spiders.s = cls()crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)return sdef process_request(self, request, spider):# Called for each request that goes through the downloader# middleware.# Must either:# - return None: continue processing this request# - or return a Response object# - or return a Request object# - or raise IgnoreRequest: process_exception() methods of# installed downloader middleware will be calledreturn None# 该方法拦截四大板块对应的响应对象 且篡改# 注意settings文件中一定要启动对应权限def process_response(self, request, response, spider):# 对需要篡改部分做判断 否则会影响其他请求对应的repsonseif request.url in spider.module_urls: # 获取从爬虫程序中创建出的浏览器对象browse = spider.browse# 通过selenium向四大板块的url发起请求,获取到动态加载的数据browse.get(request.url)# 下拉翻页browse.execute_script('window.scrollTo(0,document.body.scrollHeight)')time.sleep(1.5)# 获取源码page_text = browse.page_source#针对定位到的response进行篡改# 这里的篡改指实例化一个新的响应对象(符合需求:包含动态加载的数据),替换(HtmlResponse)原来的响应对象# 参数解释:url:响应对应的url body:响应体 requests:scrapy中的请求对象,数据都是跟着请求对象走的new_response = HtmlResponse(url=request.url, body=page_text, encoding='utf-8', request=request)return new_response # 篡改响应对象 不再经过download,直接将新的响应体返回给引擎# 此时就可以回到爬虫文件继续往下写 判断如果是selenium请求过来的我们才返回处理后的new_responseelse:# 其他请求对应的响应对象return response # return responsedef process_exception(self, request, exception, spider):# Called when a download handler or a process_request()# (from other downloader middleware) raises an exception.# Must either:# - return None: continue processing this exception# - return a Response object: stops process_exception() chain# - return a Request object: stops process_exception() chainpassdef spider_opened(self, spider):spider.logger.info('Spider opened: %s' % spider.name)
配置文件中设置开启该中间件后,运行爬虫可以在日志信息中看到selenium相关内容
小结
中间件的使用:
- 完善中间件代码:
- process_request(self, request, spider):
- 当每个request通过下载中间件时,该方法被调用。
- 返回None值:没有return也是返回None,该request对象传递给下载器,或通过引擎传递给其他权重低的process_request方法
- 返回Response对象:不再请求,把response返回给引擎
- 返回Request对象:把request对象通过引擎交给调度器,此时将不通过其他权重低的process_request方法
- process_response(self, request, response, spider):
- 当下载器完成http请求,传递响应给引擎的时候调用
- 返回Resposne:通过引擎交给爬虫处理或交给权重更低的其他下载中间件的process_response方法
- 返回Request对象:通过引擎交给调取器继续请求,此时将不通过其他权重低的process_request方法
- 需要在settings.py中开启中间件
DOWNLOADER_MIDDLEWARES = {
‘myspider.middlewares.UserAgentMiddleware’: 543,
}
相关文章:

爬虫scrapy中间件的使用
爬虫scrapy中间件的使用 学习目标: 应用 scrapy中使用间件使用随机UA的方法应用 scrapy中使用代理ip的的方法应用 scrapy与selenium配合使用 1. scrapy中间件的分类和作用 1.1 scrapy中间件的分类 根据scrapy运行流程中所在位置不同分为: 下载中间件…...
单片机开发笔记 [完结篇]:使用体会)
普冉(PUYA)单片机开发笔记 [完结篇]:使用体会
失败的移植:FreeRTOS 当使用了 PY32F003 的各种接口和功能后,手痒痒想把 FreeRTOS 也搬到这个 MCU 上,参考 STM32 和 GD32 对 FreeRTOS 的移植步骤,把 FreeRTOS v202212.00 版本的源码搬到了 Keil 工程中,编译倒是通过…...
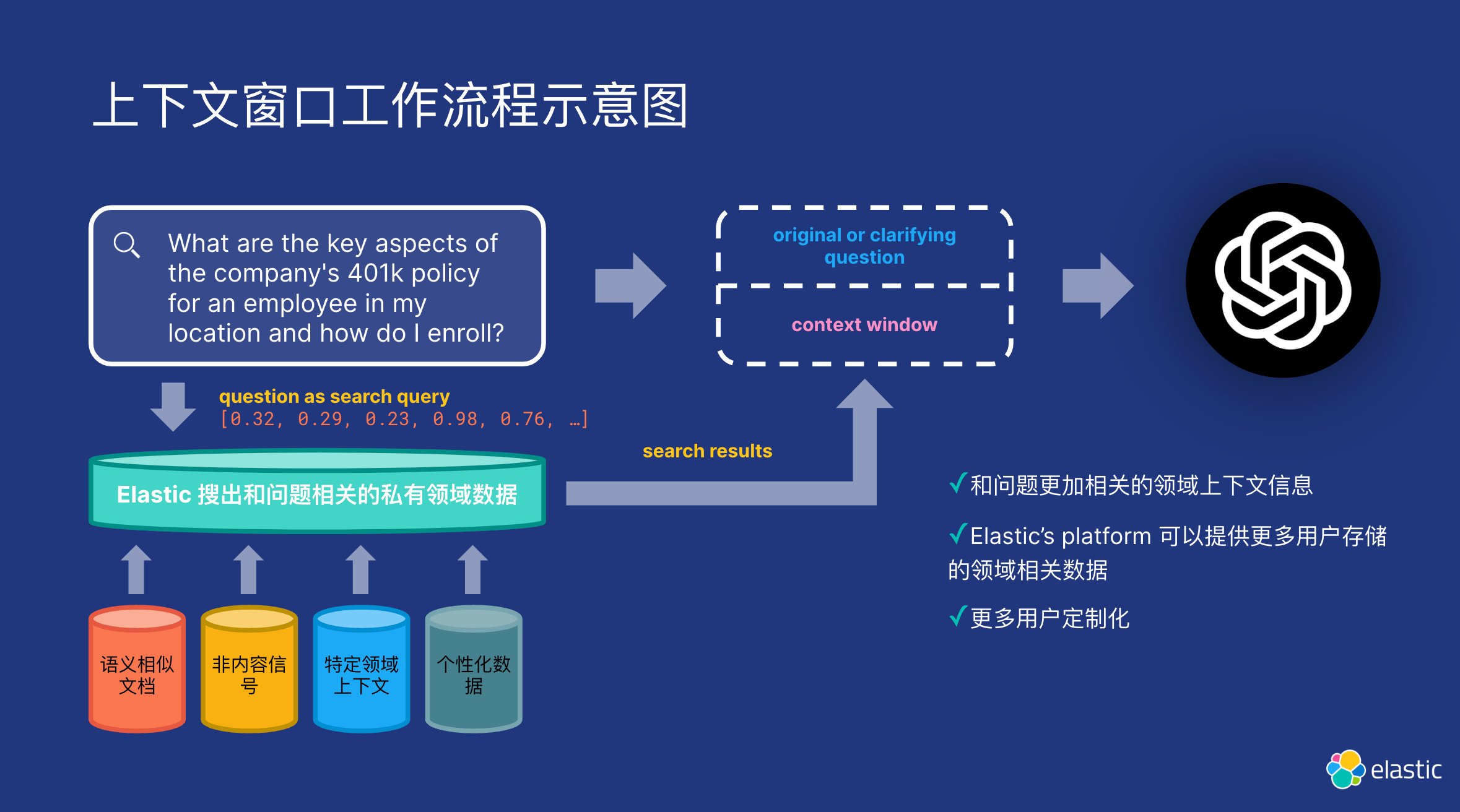
Elasticsearch:生成 AI 中的微调与 RAG
在自然语言处理 (NLP) 领域,出现了两种卓越的技术,每种技术都有其独特的功能:微调大型语言模型 (LLM) 和 RAG(检索增强生成)。 这些方法极大地影响了我们利用语言模型的方式,使它们更加通用和有效。 在本文…...

ip静态好还是dhcp好?
选择使用静态 IP 还是 DHCP(动态主机配置协议)取决于您的网络需求和环境。下面是它们的一些特点和适用场景: 静态 IP: 固定的 IP 地址:静态 IP 是手动配置在设备上的固定 IP 地址,不会随时间或网络变化而改…...

PolarDB-X、OceanBase、CockroachDB、TiDB二级索引写入性能测评
为什么要做这个测试 二级索引是关系型数据库相较于NoSQL数据库的一个关键差异。二级索引必须是强一致的,因此索引的写入需要与主键的写入放在一个事务当中,事务的性能是二级索引性能的基础。 目前市面上的分布式数据库中,从使用体验的角度看…...
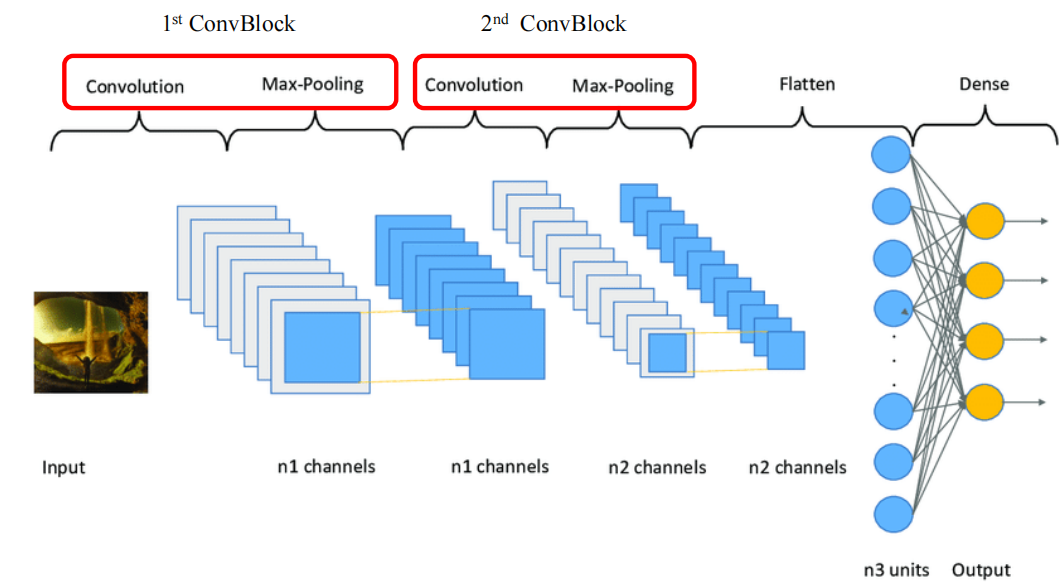
Convolutional Neural Network(CNN)——卷积神经网络
1.NN的局限性 拓展性差 NN的计算量大性能差,不利于在不同规模的数据集上有效运行若输入维度发生变化,需要修改并重新训练网络容易过拟合 全连接导致参数量特别多,容易过拟合如果增加更多层,参数量会翻倍无法有效利用局部特征 输入…...
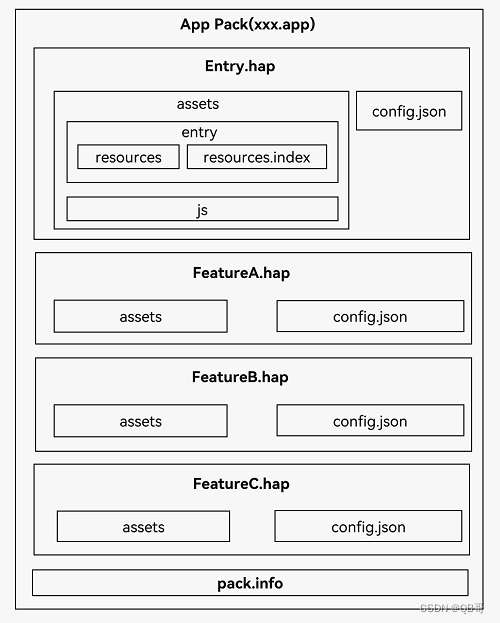
鸿蒙开发基本概念
1、开发准备 1.1、UI框架 HarmonyOS提供了一套UI开发框架,即方舟开发框架(ArkUI框架)。方舟开发框架可为开发者提供应用UI开发所必需的能力,比如多种组件、布局计算、动画能力、UI交互、绘制等。 方舟开发框架针对不同目的和技术…...
从基本概念到实践操作)
Open CV 图像处理基础:(二)从基本概念到实践操作
Open CV 图像处理基础:从基本概念到实践操作 一、引言 图像处理是计算机视觉领域的一个重要分支,它涉及对图像的各种操作和处理。了解图像的基本概念、读取和显示方法以及基本操作是图像处理的基础。本文将通过示例文章的形式,帮助初学者逐…...
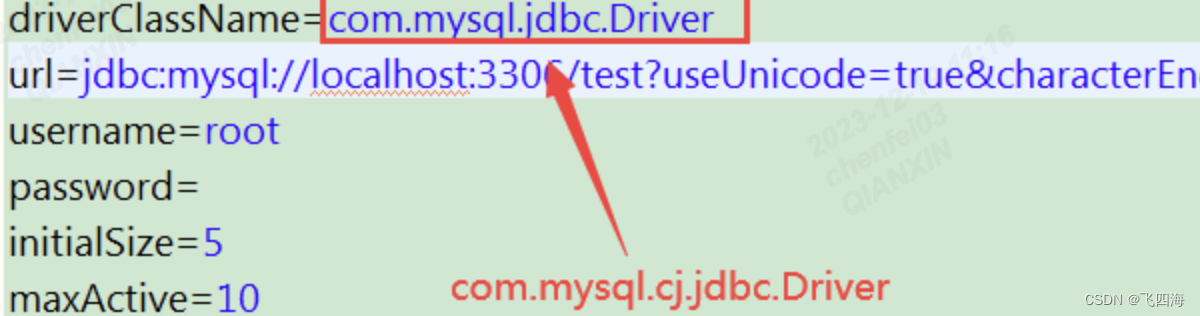
【MAC】M2 安装docker 与 mysql
一、docker下载地址 下载地址 二、安装docker完成 罗列一下docker常用命令 # 查看docker版本 docker --version# 拉取镜像 docker pull 镜像名# 查看当前所有镜像 docker images# 查看运行中的容器 docker ps -a docker ps grep| 镜像名#镜像启动操作: sudo dock…...

轻量级web开发框架Flask本地部署及无公网ip远程访问界面
文章目录 前言1. 安装部署Flask2. 安装Cpolar内网穿透3. 配置Flask的web界面公网访问地址4. 公网远程访问Flask的web界面 前言 本篇文章讲解如何在本地安装Flask,以及如何将其web界面发布到公网上并进行远程访问。 Flask是目前十分流行的web框架,采用P…...
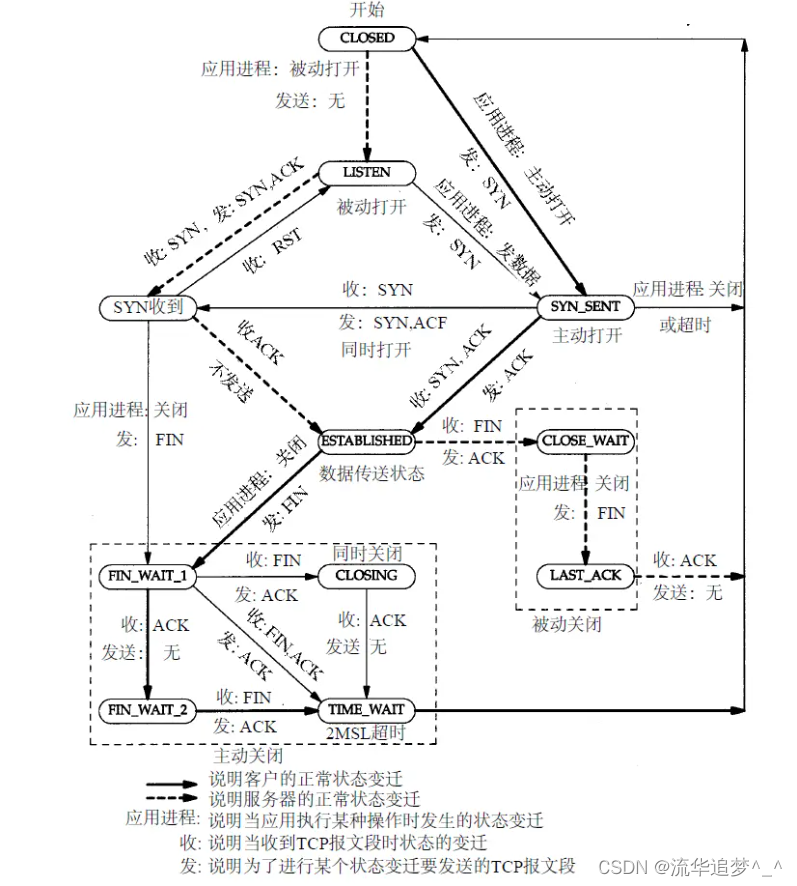
用最通俗的语言讲解 TCP “三次握手,四次挥手”
目录 一. 前言 二. TCP 报文的头部结构 三. 三次握手 3.1. 三次握手过程 3.2. 为什么要三次握手 四. 四次挥手 4.1. 四次挥手过程 4.2. 为什么要四次挥手 五. 大白话说 5.1. 大白话说三次握手 5.2. 大白话说四次挥手 六. 总结 一. 前言 TCP 是一种面向连接的、可靠…...
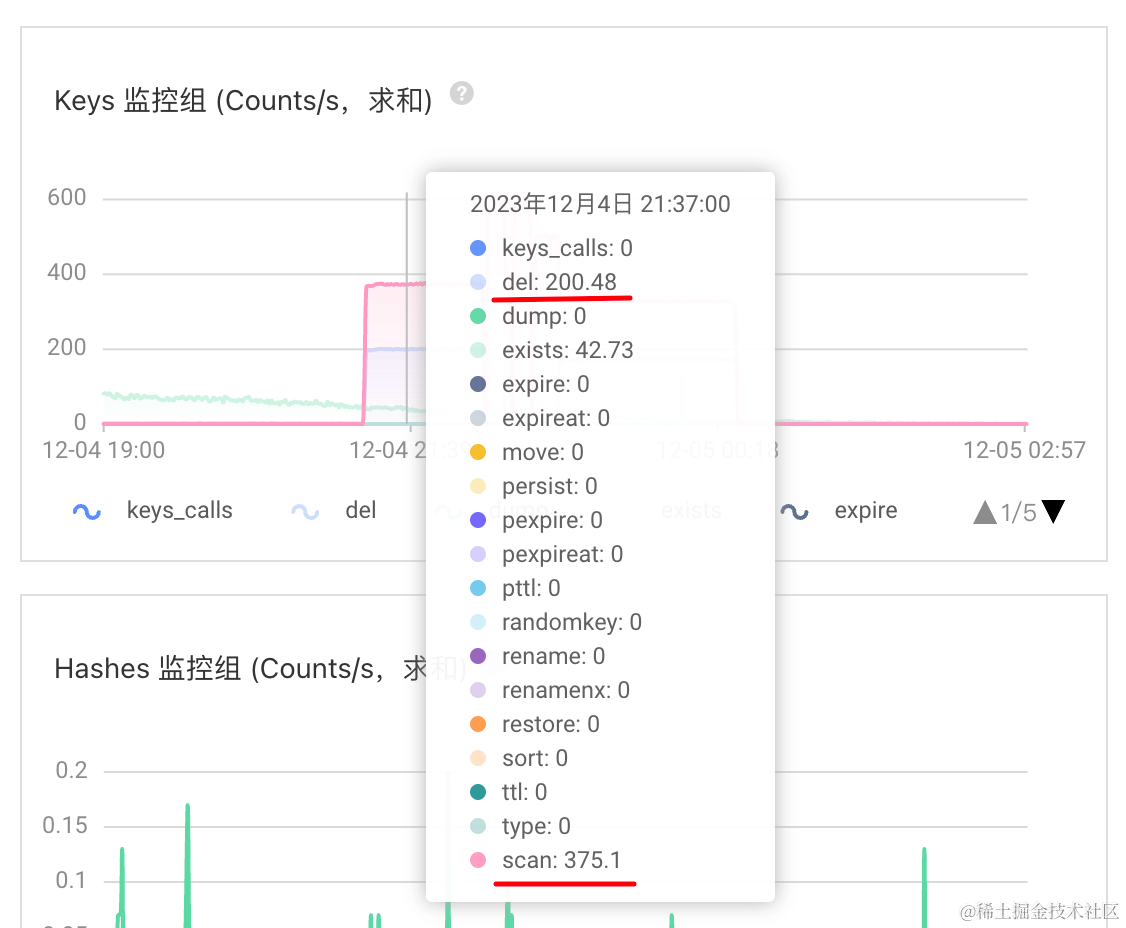
使用RedisCacheWriter#clean在线异步地批量扫描匹配删除缓存数据-spring-data-redis
1.背景 生产环境,某云的某个业务Redis实例,触发内存使用率,连续 3 次 平均值 > 85 %告警。 运维同学告知,看看需要怎么优化或者升级配置?分享了其实例RDB的内存剖析链接。 通过内存剖析详情发现,存在某…...

机器视觉:AI赋能缺陷检测,铸就芯片产品的大算力与高能效
导言:近年来,国内芯片行业快速发展,市场对芯片需求的不断增大,芯片的缺陷检测压力也越来越大。芯片产品在生产制造过程中,需要经历数道工序,每个生产环节的材料、环境、工艺参数等都有可能造成产品缺陷。不…...
(9)Linux Git的介绍以及缓冲区
💭 前言 本章我们先对缓冲区的概念进行一个详细的探究,之后会带着大家一步步去编写一个简陋的 "进度条" 小程序。最后我们来介绍一下 Git,着重讲解一下 Git 三板斧,一般只要掌握三板斧就基本够用了。 缓冲区ÿ…...
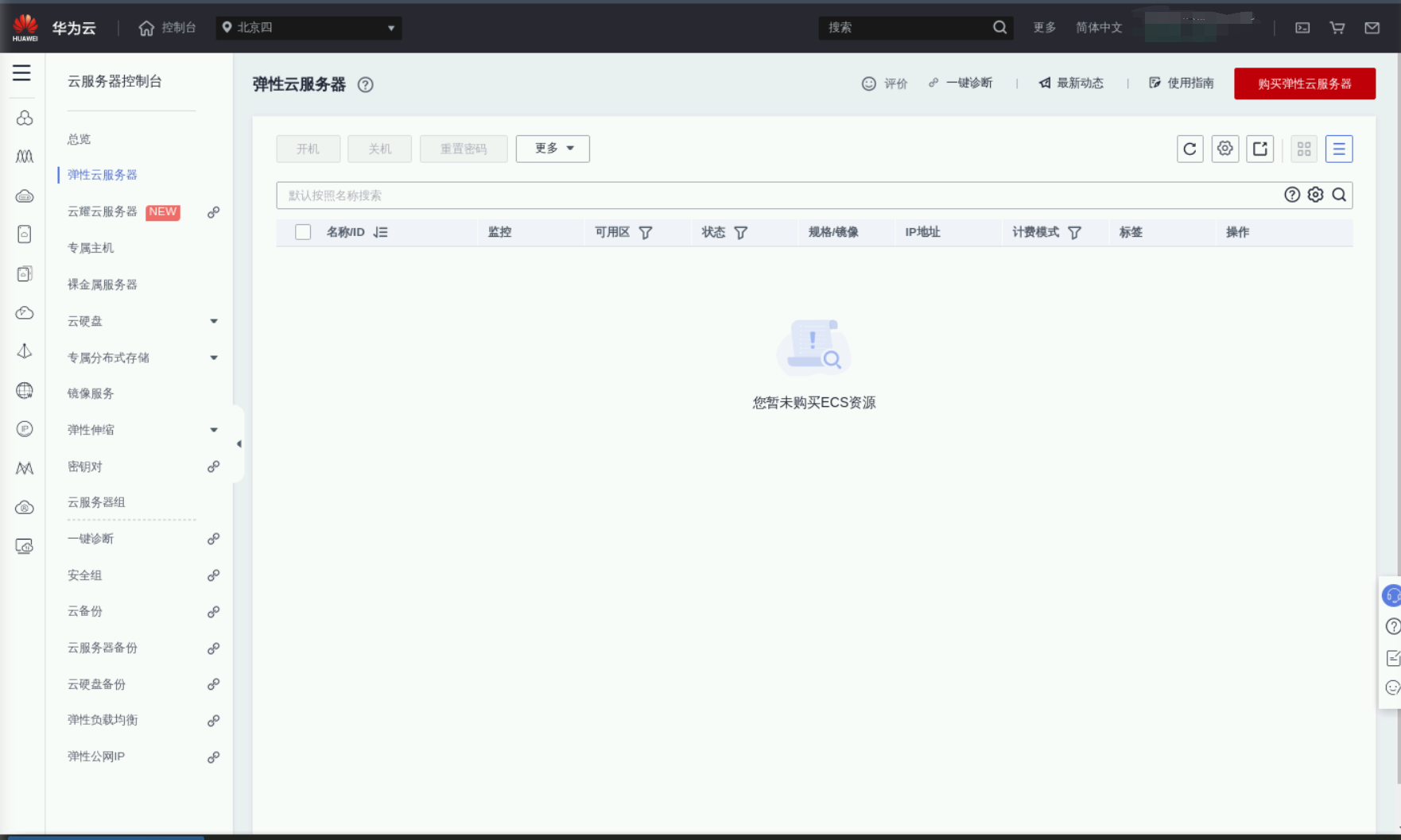
华为云之ECS云产品快速入门
华为云之ECS云产品快速入门 一、ECS云服务器介绍二、本次实践目标三、创建虚拟私有云VPC1.虚拟私有云VPC介绍2.进入虚拟私有云VPC管理页面3.创建虚拟私有云4.查看创建的VPC 四、创建弹性云服务器ECS——Linux1.进入ECS购买界面2.创建弹性云服务器(Linux)——基础配置步骤3.创建…...

tcp 的限制 (TCP_WRAPPERS)
#江南的江 #每日鸡汤:青春是打开了就合不上的书,人生是踏上了就回不了头的路,爱情是扔出了就收不回的赌注。 #初心和目标:拿到高级网络工程师 TCP_WRAPPERs Tcp_wrappers 对于七层模型中是位于第四层的安全工具,他…...

如何保证架构的质量
1. 如何保证架构的质量: ①. 稳定性、健壮性(1). 系统稳定性: ①. 定义:a. 当一个实际的系统处于一个平衡的状态时,如果受到外来作用的影响时,系统经过一个过渡过程仍然能够回到原来的平衡状态.b. 可以说这个系统是稳定的,否则系统不稳定c. 如一根绳子绑着小球,处于垂直状态,…...
JavaWeb笔记之前端开发JavaScript
一、引言 1.1 简介 JavaScript一种解释性脚本语言,是一种动态类型、弱类型、基于原型继承的语言,内置支持类型。 它的解释器被称为JavaScript引擎,作为浏览器的一部分,广泛用于客户端的脚本语言,用来给HTML网页增加…...

SCAU:18063 圈中的游戏
18063 圈中的游戏 时间限制:1000MS 代码长度限制:10KB 提交次数:0 通过次数:0 题型: 编程题 语言: G;GCC;VC Description 有n个人围成一圈,从第1个人开始报数1、2、3,每报到3的人退出圈子。编程使用链表找出最后留下的人。输入格式 输入一个数n&a…...

.NET Core中鉴权 Authentication Authorization
Authentication: 鉴定身份信息,例如用户有没有登录,用户基本信息 Authorization: 判定用户有没有权限 使用框架提供的Cookie鉴权方式 1.首先在服务容器注入鉴权服务和Cookie服务支持 services.AddAuthentication(options > {options.DefaultAuthe…...

穿越机老鸟踩坑实录:MPU6000传感器在F4飞控上的IMU方向“玄学”配置
穿越机IMU方向配置实战:从MPU6000异常自旋到飞控底层校准 当你的穿越机在通电瞬间像被无形大手狠狠抽了一记耳光般疯狂自旋,而Betaflight地面站里陀螺仪数据却显示"一切正常"时,这往往意味着你正遭遇IMU方向配置的"量子纠缠态…...

终极CoreCycler完全指南:5步掌握CPU单核稳定性测试与精准调校
终极CoreCycler完全指南:5步掌握CPU单核稳定性测试与精准调校 【免费下载链接】corecycler Script to test single core stability, e.g. for PBO & Curve Optimizer on AMD Ryzen or overclocking/undervolting on Intel processors 项目地址: https://gitco…...

从零构建个人知识库:Go+React全栈项目RocketNotes实战解析
1. 项目概述:从零到一构建个人知识管理工具最近在整理个人笔记和代码片段时,发现了一个挺有意思的开源项目fynnfluegge/rocketnotes。乍一看这个名字,可能会联想到火箭(Rocket)和笔记(Notes)的结…...

QMCFLAC2MP3终极指南:免费快速解锁QQ音乐格式限制
QMCFLAC2MP3终极指南:免费快速解锁QQ音乐格式限制 【免费下载链接】qmcflac2mp3 直接将qmcflac文件转换成mp3文件,突破QQ音乐的格式限制 项目地址: https://gitcode.com/gh_mirrors/qm/qmcflac2mp3 你是否曾经在QQ音乐下载了心爱的歌曲࿰…...
)
【优化交叉口的绿灯时间】基于遗传算法的交通灯管理研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

基于大语言模型的本地语义搜索工具LLocalSearch部署与应用指南
1. 项目概述:一个能“读懂”你电脑的本地搜索工具 如果你和我一样,电脑里塞满了各种文档、邮件、聊天记录和代码片段,那么“找东西”这件事,绝对能排进日常最耗时的任务前三。传统的文件搜索,比如Windows自带的搜索或者…...

UEFITool深度解析:实战指南与高效使用技巧
UEFITool深度解析:实战指南与高效使用技巧 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool UEFITool是一款专为UEFI固件分析设计的开源工具,能够将复杂的二进制固件映像…...

Onekey:重构Steam Depot清单下载流程的现代化解决方案
Onekey:重构Steam Depot清单下载流程的现代化解决方案 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey Onekey作为一款专为Steam Depot清单设计的自动化下载工具,通过其创…...

Grad-CAM实战:用热力图透视神经网络的决策焦点
1. Grad-CAM技术初探:为什么我们需要热力图? 当你训练了一个图像分类模型,准确率高达95%,但你真的了解它是如何做出判断的吗?我曾在项目中遇到过这样的尴尬:模型把一只坐在草地上的哈士奇误判为"狼&qu…...

AI原生编程语言Reia:为LLM设计的编程范式变革
1. 项目概述:Reia,一个面向未来的AI原生编程语言最近在AI和编程语言交叉领域,一个名为Reia的项目引起了我的注意。它来自Quaint-Studios,定位是“AI原生”的编程语言。这听起来有点抽象,但简单来说,Reia试图…...