Pandas实践_分类数据
文章目录
- 一、cat对象
- 1.cat对象的属性
- 2.类别的增加、删除和修改
- 二、有序分类
- 1.序的建立
- 2.排序和比较
- 三、区间类别
- 1.利用cut和qcut进行区间构造
- 2.一般区间的构造
- 3.区间的属性与方法
一、cat对象
1.cat对象的属性
在pandas中提供了category类型,使用户能够处理分类类型的变量,将一个普通序列转换成分类变量可以使用astype方法。
df = pd.read_csv('../data/learn_pandas.csv', usecols = ['Grade', 'Name', 'Gender', 'Height', 'Weight'])
s = df.Grade.astype('category')
s.head()
#0 Freshman
#,1 Freshman
#,2 Senior
#,3 Sophomore
#,4 Sophomore
#,Name: Grade, dtype: category
#,Categories (4, object): ['Freshman', 'Junior', 'Senior', 'Sophomore']
在一个分类类型的Series中定义了cat对象,它和上一章中介绍的str对象类似,定义了一些属性和方法来进行分类类别的操作。
s.cat
#<pandas.core.arrays.categorical.CategoricalAccessor object at 0x0000020F9B7A7108>
对于一个具体的分类,有两个组成部分,其一为类别的本身,它以Index类型存储,其二为是否有序,它们都可以通过cat的属性被访问:
s.cat.categories
#Index(['Freshman', 'Junior', 'Senior', 'Sophomore'], dtype='object')s.cat.ordered
#False
另外,每一个序列的类别会被赋予唯一的整数编号,它们的编号取决于cat.categories中的顺序,该属性可以通过codes访问:
s.cat.codes.head()
#0 0
#,1 0
#,2 2
#,3 3
#,4 3
#,dtype: int8
2.类别的增加、删除和修改
通过cat对象的categories属性能够完成对类别的查询,那么应该如何进行“增改查删”的其他三个操作呢?
首先,对于类别的增加可以使用add_categories:
s = s.cat.add_categories('Graduate') # 增加一个毕业生类别
s.cat.categories
#Index(['Freshman', 'Junior', 'Senior', 'Sophomore', 'Graduate'], dtype='object')
若要删除某一个类别可以使用remove_categories,同时所有原来序列中的该类会被设置为缺失。例如,删除大一的类别:
s = s.cat.remove_categories('Freshman')
s.cat.categories
#Index(['Junior', 'Senior', 'Sophomore', 'Graduate'], dtype='object')s.head()
#0 NaN
#,1 NaN
#,2 Senior
#,3 Sophomore
#,4 Sophomore
#,Name: Grade, dtype: category
#,Categories (4, object): ['Junior', 'Senior', 'Sophomore', 'Graduate']
此外可以使用set_categories直接设置序列的新类别,原来的类别中如果存在元素不属于新类别,那么会被设置为缺失。
s = s.cat.set_categories(['Sophomore','PhD']) # 新类别为大二学生和博士
s.cat.categories
#Index(['Sophomore', 'PhD'], dtype='object')s.head()
#0 NaN
#,1 NaN
#,2 NaN
#,3 Sophomore
#,4 Sophomore
#,Name: Grade, dtype: category
#,Categories (2, object): ['Sophomore', 'PhD']
如果想要删除未出现在序列中的类别,可以使用remove_unused_categories来实现:
s = s.cat.remove_unused_categories() # 移除了未出现的博士生类别
s.cat.categories
#Index(['Sophomore'], dtype='object')
最后,“增改查删”中还剩下修改的操作,这可以通过rename_categories方法完成,同时需要注意的是,这个方法会对原序列的对应值也进行相应修改。例如,现在把Sophomore改成中文的本科二年级学生:
s = s.cat.rename_categories({'Sophomore':'本科二年级学生'})
s.head()
#0 NaN
#,1 NaN
#,2 NaN
#,3 本科二年级学生
#,4 本科二年级学生
#,Name: Grade, dtype: category
#,Categories (1, object): ['本科二年级学生']
二、有序分类
1.序的建立
有序类别和无序类别可以通过as_unordered和reorder_categories互相转化,需要注意的是后者传入的参数必须是由当前序列的无序类别构成的列表,不能够增加新的类别,也不能缺少原来的类别,并且必须指定参数ordered=True,否则方法无效。例如,对年级高低进行相对大小的类别划分,然后再恢复无序状态:
s = df.Grade.astype('category')
s = s.cat.reorder_categories(['Freshman', 'Sophomore', 'Junior', 'Senior'],ordered=True)
s.head()
#0 Freshman
#,1 Freshman
#,2 Senior
#,3 Sophomore
#,4 Sophomore
#,Name: Grade, dtype: category
#,Categories (4, object): ['Freshman' < 'Sophomore' < 'Junior' < 'Senior']s.cat.as_unordered().head()
#0 Freshman
#,1 Freshman
#,2 Senior
#,3 Sophomore
#,4 Sophomore
#,Name: Grade, dtype: category
#,Categories (4, object): ['Freshman', 'Sophomore', 'Junior', 'Senior']
2.排序和比较
在第二章中,曾提到了字符串和数值类型序列的排序,此时就要说明分类变量的排序:只需把列的类型修改为category后,再赋予相应的大小关系,就能正常地使用sort_index和sort_values。例如,对年级进行排序:
df.Grade = df.Grade.astype('category')
df.Grade = df.Grade.cat.reorder_categories(['Freshman', 'Sophomore', 'Junior', 'Senior'],ordered=True)
df.sort_values('Grade').head() # 值排序
# Grade Name Gender Height Weight
#0 Freshman Gaopeng Yang Female 158.9 46.0
#105 Freshman Qiang Shi Female 164.5 52.0
#96 Freshman Changmei Feng Female 163.8 56.0
#88 Freshman Xiaopeng Han Female 164.1 53.0
#81 Freshman Yanli Zhang Female 165.1 52.0df.set_index('Grade').sort_index().head() # 索引排序
# Name Gender Height Weight
#Grade
#Freshman Gaopeng Yang Female 158.9 46.0
#Freshman Qiang Shi Female 164.5 52.0
#Freshman Changmei Feng Female 163.8 56.0
#Freshman Xiaopeng Han Female 164.1 53.0
#Freshman Yanli Zhang Female 165.1 52.0
由于序的建立,因此就可以进行比较操作。分类变量的比较操作分为两类,第一种是==或!=关系的比较,比较的对象可以是标量或者同长度的Series(或list),第二种是>,>=,<,<=四类大小关系的比较,比较的对象和第一种类似,但是所有参与比较的元素必须属于原序列的categories,同时要和原序列具有相同的索引。
res1 = df.Grade == 'Sophomore'
res1.head()
#0 False
#,1 False
#,2 False
#,3 True
#,4 True
#,Name: Grade, dtype: boolres2 = df.Grade == ['PhD']*df.shape[0]
res2.head()
#0 False
#,1 False
#,2 False
#,3 False
#,4 False
#,Name: Grade, dtype: boolres3 = df.Grade <= 'Sophomore'
res3.head()
#0 True
#,1 True
#,2 False
#,3 True
#,4 True
#,Name: Grade, dtype: boolres4 = df.Grade <= df.Grade.sample(frac=1).reset_index(drop=True) # 打乱后比较
res4.head()
#0 True
#,1 True
#,2 False
#,3 True
#,4 True
#,Name: Grade, dtype: bool
三、区间类别
1.利用cut和qcut进行区间构造
区间是一种特殊的类别,在实际数据分析中,区间序列往往是通过cut和qcut方法进行构造的,这两个函数能够把原序列的数值特征进行装箱,即用区间位置来代替原来的具体数值。
首先介绍cut的常见用法:
其中,最重要的参数是bins,如果传入整数n,则代表把整个传入数组的按照最大和最小值等间距地分为n段。由于区间默认是左开右闭,需要在调整时把最小值包含进去,在pandas中的解决方案是在值最小的区间左端点再减去0.001(max-min),因此如果对序列[1,2]划分为2个箱子时,第一个箱子的范围(0.999,1.5],第二个箱子的范围是(1.5,2]。如果需要指定左闭右开时,需要把right参数设置为False,相应的区间调整方法是在值最大的区间右端点再加上0.001(max-min)。
s = pd.Series([1,2])
pd.cut(s, bins=2)
#0 (0.999, 1.5]
#,1 (1.5, 2.0]
#,dtype: category
#,Categories (2, interval[float64]): [(0.999, 1.5] < (1.5, 2.0]]pd.cut(s, bins=2, right=False)
#0 [1.0, 1.5)
#,1 [1.5, 2.001)
#,dtype: category
#,Categories (2, interval[float64]): [[1.0, 1.5) < [1.5, 2.001)]
bins的另一个常见用法是指定区间分割点的列表(使用np.infty可以表示无穷大):
pd.cut(s, bins=[-np.infty, 1.2, 1.8, 2.2, np.infty])
#0 (-inf, 1.2]
#,1 (1.8, 2.2]
#,dtype: category
#,Categories (4, interval[float64]): [(-inf, 1.2] < (1.2, 1.8] < (1.8, 2.2] < (2.2, inf]]
另外两个常用参数为labels和retbins,分别代表了区间的名字和是否返回分割点(默认不返回):
s = pd.Series([1,2])
res = pd.cut(s, bins=2, labels=['small', 'big'], retbins=True)
res[0]
#0 small
#,1 big
#,dtype: category
#,Categories (2, object): ['small' < 'big']res[1] # 该元素为返回的分割点
#ray([0.999, 1.5 , 2. ])
从用法上来说,qcut和cut几乎没有差别,只是把bins参数变成的q参数,qcut中的q是指quantile。这里的q为整数n时,指按照n等分位数把数据分箱,还可以传入浮点列表指代相应的分位数分割点。
s = df.Weight
pd.qcut(s, q=3).head()
#0 (33.999, 48.0]
#,1 (55.0, 89.0]
#,2 (55.0, 89.0]
#,3 (33.999, 48.0]
#,4 (55.0, 89.0]
#,Name: Weight, dtype: category
#,Categories (3, interval[float64]): [(33.999, 48.0] < (48.0, 55.0] < (55.0, 89.0]]pd.qcut(s, q=[0,0.2,0.8,1]).head()
#0 (44.0, 69.4]
#,1 (69.4, 89.0]
#,2 (69.4, 89.0]
#,3 (33.999, 44.0]
#,4 (69.4, 89.0]
#,Name: Weight, dtype: category
#,Categories (3, interval[float64]): [(33.999, 44.0] < (44.0, 69.4] < (69.4, 89.0]]
2.一般区间的构造
对于某一个具体的区间而言,其具备三个要素,即左端点、右端点和端点的开闭状态,其中开闭状态可以指定right, left, both, neither中的一类:
my_interval = pd.Interval(0, 1, 'right')
my_interval
#Interval(0, 1, closed='right')
其属性包含了mid, length, right, left, closed,,分别表示中点、长度、右端点、左端点和开闭状态。
使用in可以判断元素是否属于区间:
0.5 in my_interval
#True
使用overlaps可以判断两个区间是否有交集:
my_interval_2 = pd.Interval(0.5, 1.5, 'left')
my_interval.overlaps(my_interval_2)
#True
一般而言,pd.IntervalIndex对象有四类方法生成,分别是from_breaks, from_arrays, from_tuples, interval_range,它们分别应用于不同的情况:
from_breaks的功能类似于cut或qcut函数,只不过后两个是通过计算得到的分割点,而前者是直接传入自定义的分割点:
pd.IntervalIndex.from_breaks([1,3,6,10], closed='both')
#IntervalIndex([[1, 3], [3, 6], [6, 10]],
#, closed='both',
#, dtype='interval[int64]')
from_arrays是分别传入左端点和右端点的列表,适用于有交集并且知道起点和终点的情况:
pd.IntervalIndex.from_arrays(left = [1,3,6,10], right = [5,4,9,11], closed = 'neither')
#IntervalIndex([(1, 5), (3, 4), (6, 9), (10, 11)],
#, closed='neither',
#, dtype='interval[int64]')
from_tuples传入的是起点和终点元组构成的列表:
pd.IntervalIndex.from_tuples([(1,5),(3,4),(6,9),(10,11)], closed='neither')
#IntervalIndex([(1, 5), (3, 4), (6, 9), (10, 11)],
#, closed='neither',
#, dtype='interval[int64]')
一个等差的区间序列由起点、终点、区间个数和区间长度决定,其中三个量确定的情况下,剩下一个量就确定了,interval_range中的start, end, periods, freq参数就对应了这四个量,从而就能构造出相应的区间:
pd.interval_range(start=1,end=5,periods=8)
#IntervalIndex([(1.0, 1.5], (1.5, 2.0], (2.0, 2.5], (2.5, 3.0], (3.0, 3.5], (3.5, 4.0], (4.0, 4.5], (4.5, 5.0]],
#, closed='right',
#, dtype='interval[float64]')pd.interval_range(end=5,periods=8,freq=0.5)
#IntervalIndex([(1.0, 1.5], (1.5, 2.0], (2.0, 2.5], (2.5, 3.0], (3.0, 3.5], (3.5, 4.0], (4.0, 4.5], (4.5, 5.0]],
#, closed='right',
#, dtype='interval[float64]')
除此之外,如果直接使用pd.IntervalIndex([…], closed=…),把Interval类型的列表组成传入其中转为区间索引,那么所有的区间会被强制转为指定的closed类型,因为pd.IntervalIndex只允许存放同一种开闭区间的Interval对象。
my_interval
#Interval(0, 1, closed='right')my_interval_2
#Interval(0.5, 1.5, closed='left')pd.IntervalIndex([my_interval, my_interval_2], closed='left')
#IntervalIndex([[0.0, 1.0), [0.5, 1.5)],
#, closed='left',
#, dtype='interval[float64]')
3.区间的属性与方法
IntervalIndex上也定义了一些有用的属性和方法。同时,如果想要具体利用cut或者qcut的结果进行分析,那么需要先将其转为该种索引类型:
id_interval = pd.IntervalIndex(pd.cut(s, 3))
id_interval[:3]
#IntervalIndex([(33.945, 52.333], (52.333, 70.667], (70.667, 89.0]],
#, closed='right',
#, name='Weight',
#, dtype='interval[float64]')
与单个Interval类型相似,IntervalIndex有若干常用属性:left, right, mid, length,分别表示左右端点、两端点均值和区间长度。
id_demo = id_interval[:5] # 选出前5个展示
id_demo
#IntervalIndex([(33.945, 52.333], (52.333, 70.667], (70.667, 89.0], (33.945, 52.333], (70.667, 89.0]],
#, closed='right',
#, name='Weight',
#, dtype='interval[float64]')id_demo.left
#Float64Index([33.945, 52.333, 70.667, 33.945, 70.667], dtype='float64')id_demo.right
#Float64Index([52.333, 70.667, 89.0, 52.333, 89.0], dtype='float64')id_demo.mid
#Float64Index([43.138999999999996, 61.5, 79.8335, 43.138999999999996, 79.8335], dtype='float64')id_demo.length
#Float64Index([18.387999999999998, 18.334000000000003, 18.333,
#, 18.387999999999998, 18.333],
#, dtype='float64')
IntervalIndex还有两个常用方法,包括contains和overlaps,分别指逐个判断每个区间是否包含某元素,以及是否和一个pd.Interval对象有交集。
id_demo.contains(4)
#array([False, False, False, False, False])id_demo.overlaps(pd.Interval(40,60))
#array([ True, True, False, True, False])
参考:阿里云天池
相关文章:

Pandas实践_分类数据
文章目录 一、cat对象1.cat对象的属性2.类别的增加、删除和修改 二、有序分类1.序的建立2.排序和比较 三、区间类别1.利用cut和qcut进行区间构造2.一般区间的构造3.区间的属性与方法 一、cat对象 1.cat对象的属性 在pandas中提供了category类型,使用户能够处理分类…...
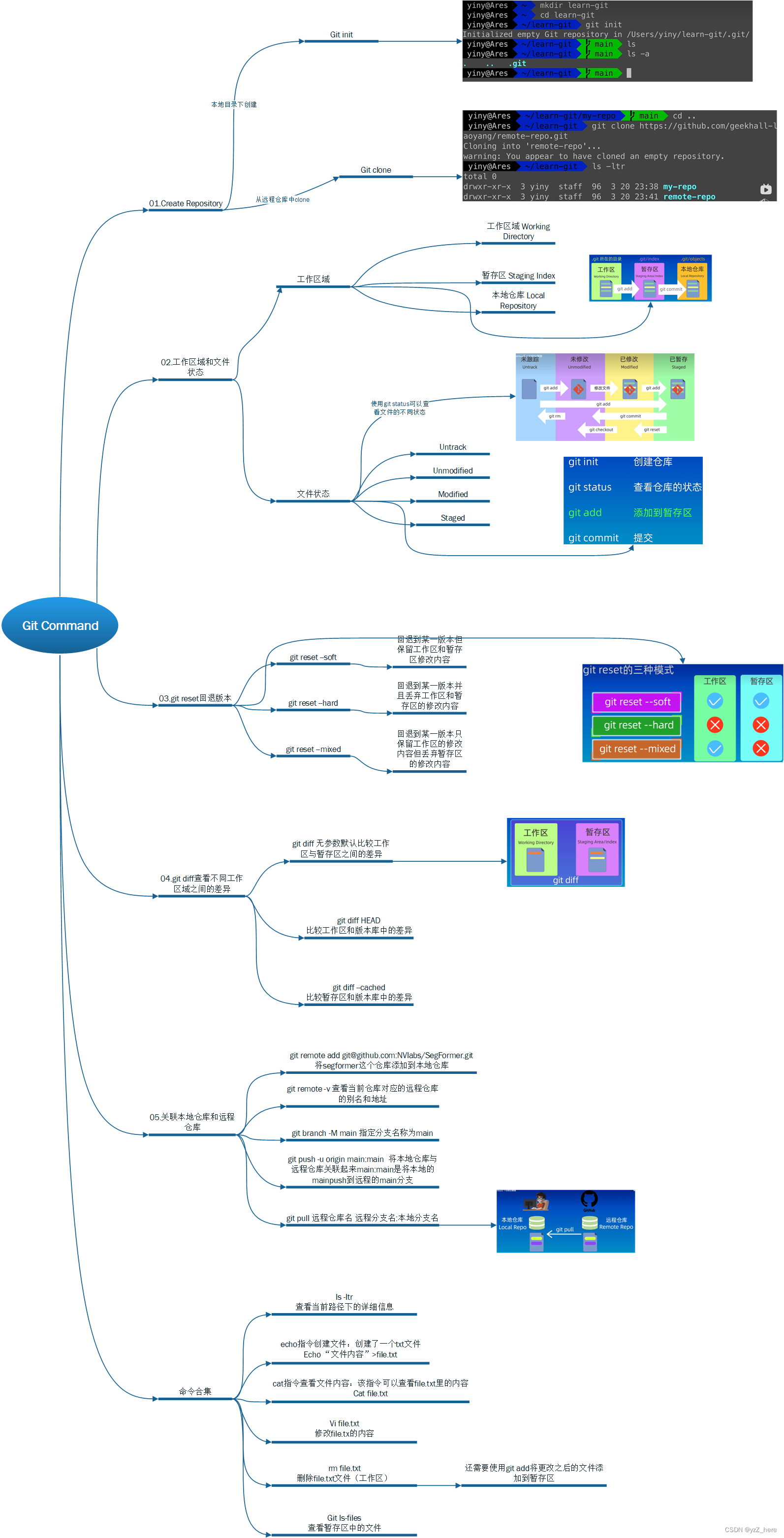
git的使用思维导图
源文件在github主页:study_collection/cpp学习/git at main stu-yzZ/study_collection (github.com)...

Qt 软件界面点击QCombBox控件,造成整个界面移位
Qt 软件界面点击QCombBox控件,造成整个界面移位 最近项目中,遇到了一个问题,在绘制界面的时候,使用了QCombBox控件,在点击QCombBox控件下拉中的item时,会造成整个界面移位的现象。 我重写了下面三个事件函…...
AI Native工程化:百度App AI互动技术实践
作者 | GodStart 导读 随着AI浪潮的兴起,越来越多的应用都在利用大模型重构业务形态,在设计和优化Prompt的过程中,我们发现整个Prompt测评和优化周期非常长,因此,我们提出了一种Prompt生成、评估与迭代的一体化解决方案…...
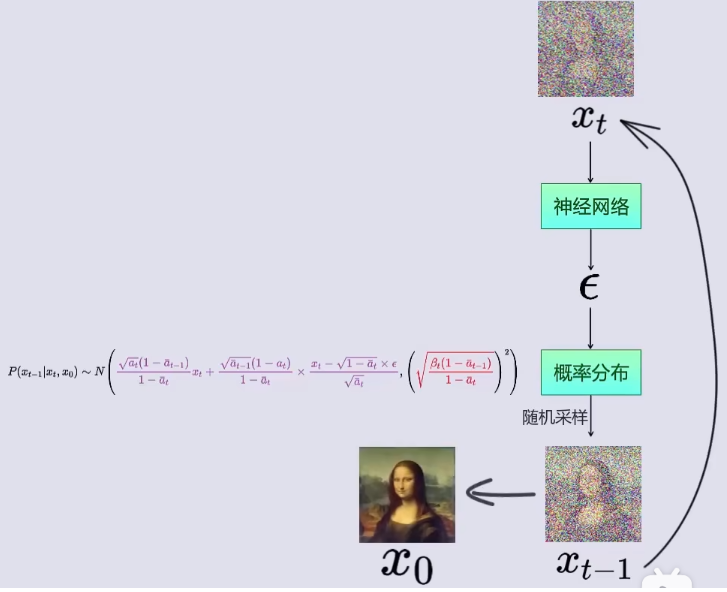
DDPM推导笔记
各位佬看文章之前,可以先去看看这个视频,并给这位up主点赞投币,这位佬讲解的太好了:大白话AI 1.前置知识的学习 1.1 正态分布特性 (1)正态分布的概率密度函数 f ( x ) 1 2 π σ e − ( x − μ ) …...

【C#/Java】【小白必看】不要只会读写文本文件了!对象序列化助你提高效率
【C#/Java】【小白必看】不要只会读写文本文件了!对象序列化助你提高效率 在编程的世界里,文件的读写操作是我们经常面对的任务之一。 当我们只涉及简单的文本文件时,这个任务似乎并不复杂。但是,当我们处理更为复杂的类对…...
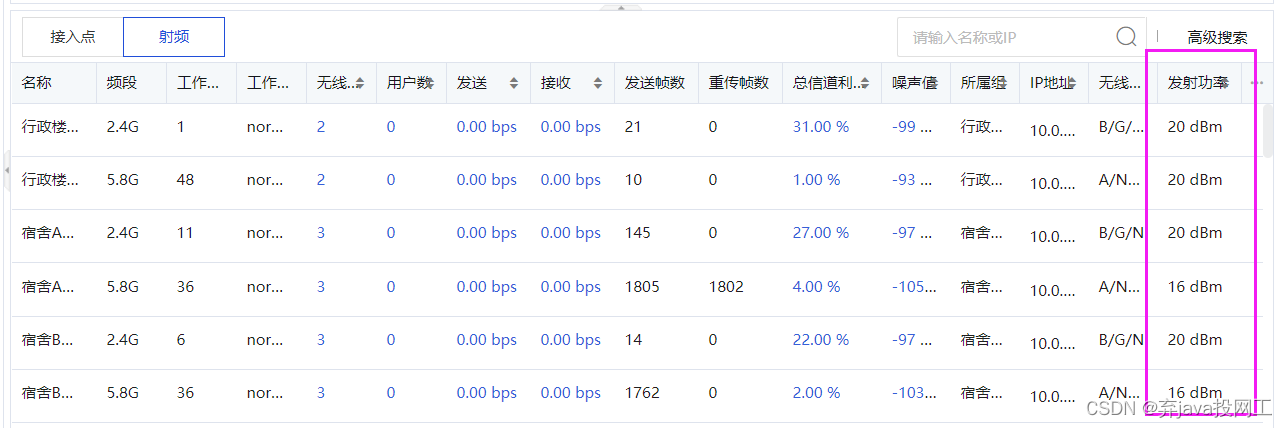
排障启示录-无线终端信号弱
现象:无线终端显示信号弱 信息收集: AP的实际发射功率低。外置天线型AP,天线松动或者没插天线现场环境问题,信号穿透衰减终端接入远端AP终端个体问题 排查步骤: 1、AP的发射功率低 查看AP的射频功率,判…...
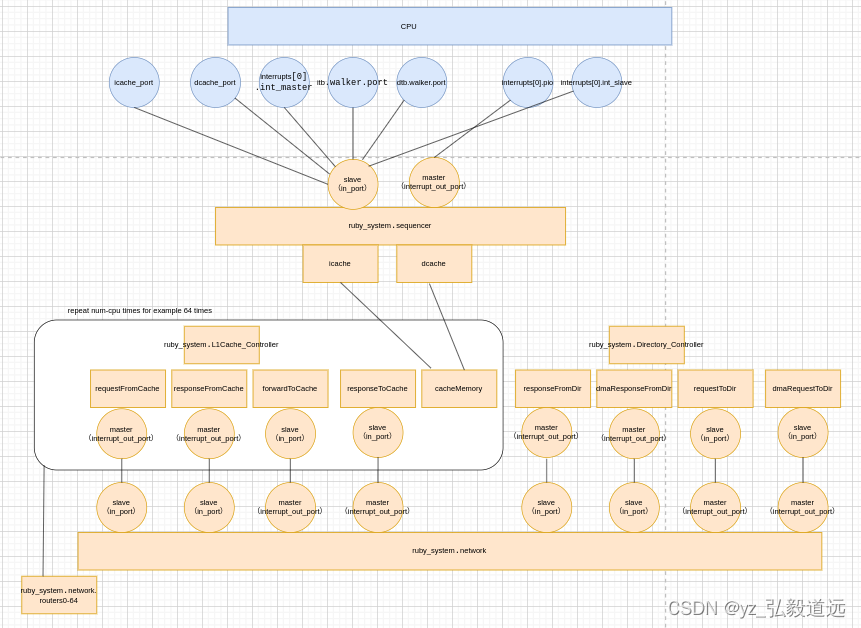
gem5 RubyPort: mem_request_port作用与连接 simple-MI_example.py
简介 回答这个问题:RubyPort的口下,一共定义了六个口,分别是mem_request_port,mem_response_port,pio_request_port,pio_response_port,in_ports, interrupt_out_ports,他们分别有什…...

无人机支持的空中无蜂窝大规模MIMO系统中上行链路分布式检测
无人机支持的空中无蜂窝大规模MIMO系统中上行链路分布式检测 无人机支持的空中无蜂窝大规模MIMO系统中上行链路分布式检测介绍题目一. 背景(解决的问题)二. 系统模型信道模型信道系数进行标准化 信道估计 和 数据传输信道估计上行数据传输 三. 具体的流程…...
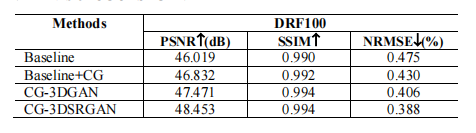
文献速递:生成对抗网络医学影像中的应用—— CG-3DSRGAN:用于从低剂量PET图像恢复图像质量的分类指导的3D生成对抗网络
文献速递:生成对抗网络医学影像中的应用—— CG-3DSRGAN:用于从低剂量PET图像恢复图像质量的分类指导的3D生成对抗网络 本周给大家分享文献的主题是生成对抗网络(Generative adversarial networks, GANs)在医学影像中的应用。文献…...

前端验收测试驱动开发
我们听说过很多关于测试驱动开发(TDD)的内容。那么什么是ATDD? ATDD代表验收测试驱动开发,这是一种定义验收标准并创建自动化测试来验证是否满足这些标准的软件开发方法。ATDD是一种协作方法,涉及客户、开发人员和测试…...
图像卷积操作
目录 一、互相关运算 二、卷积层 三、图像中目标的边缘检测 四、学习卷积核 五、特征映射和感受野 一、互相关运算 严格来说,卷积层是个错误的叫法,因为它所表达的运算其实是互相关运算(cross-correlation),而不是…...
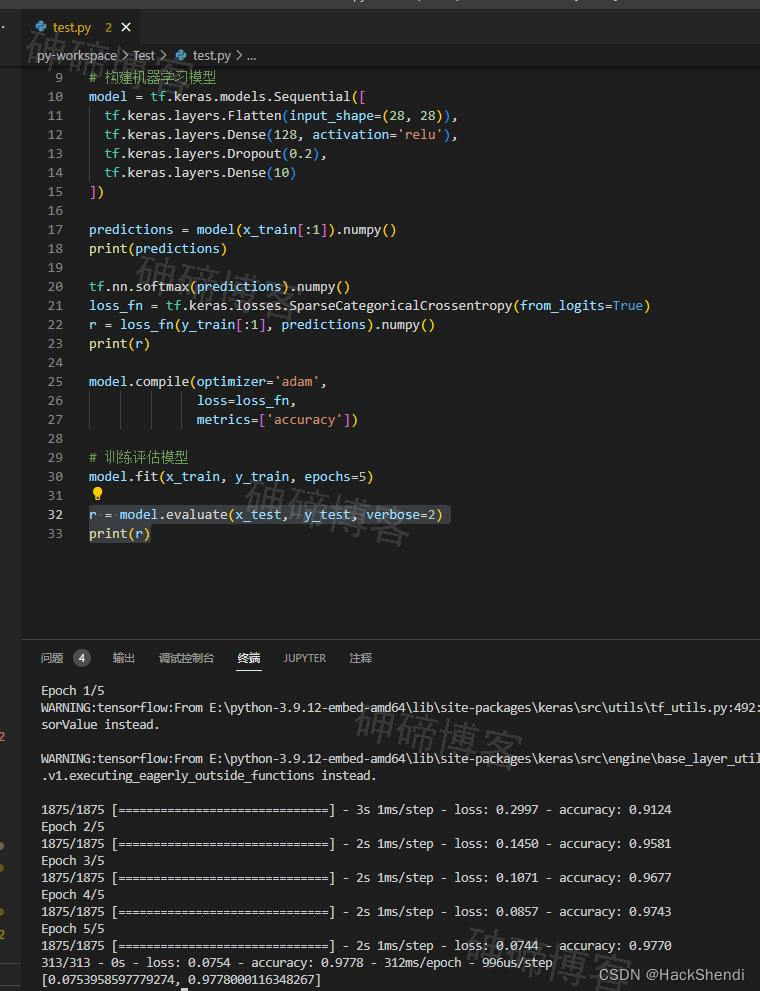
目标检测入门体验,技术选型,加载数据集、构建机器学习模型、训练并评估
Hi, I’m Shendi 1、目标检测入门体验,技术选型,加载数据集、构建机器学习模型、训练并评估 在最近有了个物体识别的需求,于是开始学习 在一番比较与询问后,最终选择 TensorFlow。 对于编程语言,我比较偏向Java或nod…...

【UE5插件推荐】运行时,通过HTTP / HTTPS下载文件(Runtime Files Downloader)
UE5 github Home gtreshchev/RuntimeFilesDownloader Wiki (github.com)...
信息论安全与概率论
目录 一. Markov不等式 二. 选择引理 三. Chebyshev不等式 四. Chernov上限 4.1 变量大于 4.2 变量小于 信息论安全中会用到很多概率论相关的上界,本文章将梳理几个论文中常用的定理,重点关注如何理解这些定理以及怎么用。 一. Markov不等式 假定…...
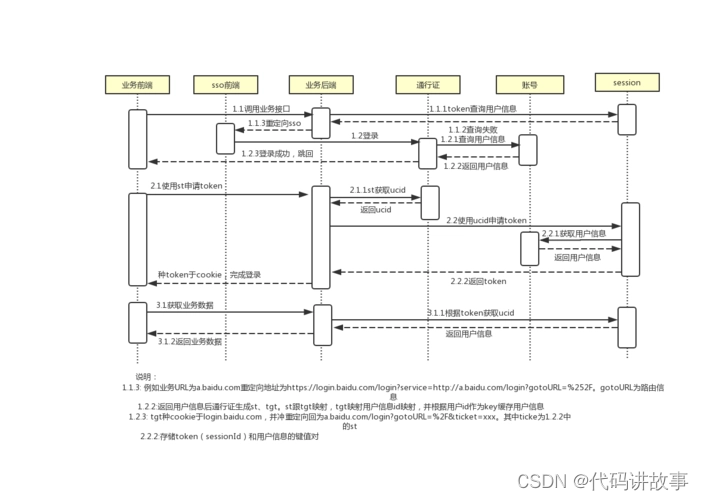
各种不同语言分别整理的拿来开箱即用的8个开源免费单点登录(SSO)系统
各种不同语言分别整理的拿来开箱即用的8个开源免费单点登录(SSO)系统。 单点登录(SSO)是一个登录服务层,通过一次登录访问多个应用。使用SSO服务可以提高多系统使用的用户体验和安全性,用户不必记忆多个密…...

Netty Review - 优化Netty通信:如何应对粘包和拆包挑战
文章目录 概述Pre概述场景复现解决办法概览方式一: 特殊分隔符分包 (演示Netty提供的众多方案中的一种)流程分析 方式二: 发送长度(推荐) DelimiterBasedFrameDecoder 源码分析 概述 Pre Netty Review - 借助SimpleTalkRoom初体验…...

vue介绍以及基本指令
目录 一、vue是什么 二、使用vue的准备工作 三、创建vue项目 四、vue插值表达式 五、vue基本指令 六、key的作用 七、v-model 九、指令修饰符 一、vue是什么 Vue是一种用于构建用户界面的JavaScript框架。它可以帮助开发人员构建单页应用程序和复杂的前端应用程序。Vue…...

重塑数字生产力体系,生成式AI将开启云计算未来新十年?
科技云报道原创。 今天我们正身处一个历史的洪流,一个巨变的十字路口。生成式AI让人工智能技术完全破圈,带来了机器学习被大规模采用的历史转折点。 它掀起的新一轮科技革命,远超出我们今天的想象,这意味着一个巨大的历史机遇正…...

JFreeChart 生成图表,并为图表标注特殊点、添加文本标识框
一、项目场景: Java使用JFreeChart库生成图片,主要场景为将具体的数据 可视化 生成曲线图等的图表。 本篇文章主要针对为数据集生成的图表添加特殊点及其标识框。具体包括两种场景:x轴为 时间戳 类型和普通 数值 类型。(y轴都为…...

高效解决付费墙难题:Bypass Paywalls Clean实用技术指南
高效解决付费墙难题:Bypass Paywalls Clean实用技术指南 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 在数字信息时代,付费墙已成为获取优质内容的主要障碍&…...
)
软件信创方案(Word)
第1章 需求分析1.1 核心项目需求自主可控、资源池、云平台建设、运维运营管理、安全系统五大核心需求第2章 云平台基础设施设计2.1 改造目标与定位2.2 设计原则2.3 总体架构设计含网络架构、云平台整体架构2.4 资源配置设计含网络、计算、数据库、存储资源池及云管模块设计第3章…...
 的演进:从游戏行业到供应链攻击的AI应用)
APT41 (Barium) 的演进:从游戏行业到供应链攻击的AI应用
前言 1. 技术背景 —— 这个技术在攻防体系中的位置 高级持续性威胁 (Advanced Persistent Threat, APT) 是网络攻防体系金字塔的顶端。它并非指某种单一技术,而是一个复杂的、有组织的、长期的网络攻击活动集合。在整个攻防图谱中,APT代表着最高级别的对…...

MAA明日方舟自动化助手:5分钟快速上手完整指南
MAA明日方舟自动化助手:5分钟快速上手完整指南 【免费下载链接】MaaAssistantArknights 一款明日方舟游戏小助手 项目地址: https://gitcode.com/GitHub_Trending/ma/MaaAssistantArknights 还在为《明日方舟》重复刷图、基建管理而烦恼吗?MAA助手…...

【故障】解决ssh连接linux卡着不动的问题
1、原因使用xshell连接一台linux机器,发现连接不上,一直都开在连接这个界面,最后超时才停止。2、排查(1)首先,检查下防火墙或者selinuxsystem status firewalld #检查服务是否处于非Running的状态getenforc…...

AI训练神器!免配置YOLO可视化工具,标注+训练+推理全流程集成,支持YOLOv8~v12+50系显卡,开源可二开
AI训练神器!免配置YOLO可视化工具,标注训练推理全流程集成,支持YOLOv8~v1250系显卡,开源可二开 yolo可视化训练工具,免配置环境,打开界面即可训练yolo模型,提供源代码及完整打包项目,…...

建行江门市分行:银发关爱在行动 暖心服务送到家
服务无边界。近日,建行广东江门分行辖内多家网点接连上演暖心一幕,员工们主动跨出柜台,将金融服务送到客户家中、病房前,用一次次“特事特办”的上门服务,化解客户的“燃眉之急”,生动诠释了“以客户为中心…...

避坑指南:VSCode Remote-SSH离线安装时,插件版本不兼容和服务器环境配置的那些坑
深度解析VSCode Remote-SSH离线安装的五大核心难题与实战解决方案 在远程开发日益普及的今天,VSCode的Remote-SSH功能已经成为开发者连接Linux服务器的首选工具。然而当网络环境受限时,离线安装过程中的各种"暗坑"往往让开发者寸步难行。本文将…...

解锁毕业论文新姿势:书匠策AI,你的学术“超级外挂”!
在学术的征途上,毕业论文无疑是每位学子必须跨越的一道重要关卡。它不仅是对你大学四年学习成果的全面检验,更是你迈向学术殿堂或职场的重要敲门砖。然而,面对堆积如山的资料、错综复杂的逻辑结构,以及那令人头疼的格式要求&#…...
)
Anaconda3重装避雷指南:Win11系统这些配置不删干净等于白装(2024实测)
Anaconda3重装避雷指南:Win11系统深度清理实战手册 为什么你的Anaconda重装总失败? 每次重装Anaconda后,那些熟悉的报错信息又阴魂不散地出现?"明明已经卸载干净了"——这是大多数数据科学从业者最常发出的困惑。实际上…...