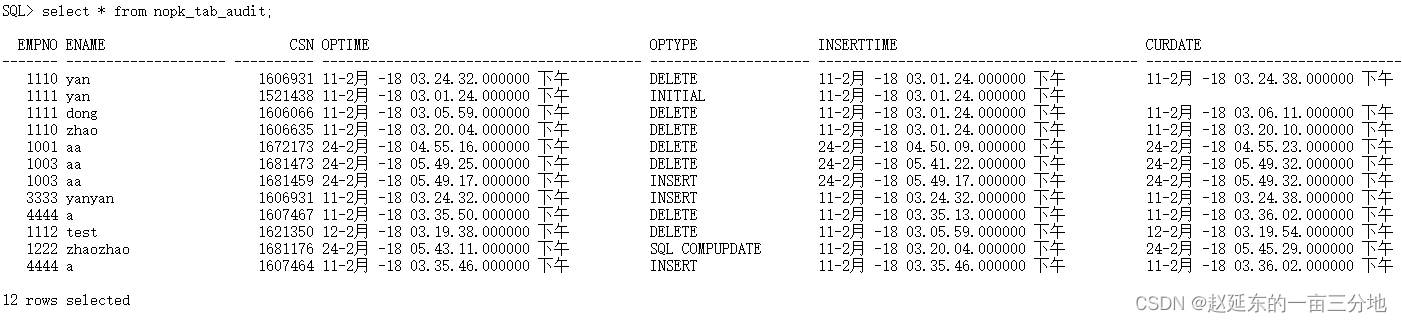
Spark 内存运用
RDD Cache
当同一个 RDD 被引用多次时,就可以考虑进行 Cache,从而提升作业的执行效率
// 用 cache 对 wordCounts 加缓存
wordCounts.cache
// cache 后要用 action 才能触发 RDD 内存物化
wordCounts.count// 自定义 Cache 的存储介质、存储形式、副本数量
wordCounts.persist(MEMORY_ONLY)
Spark 的 Cache 机制 :
- 缓存的存储级别:限定了数据缓存的存储介质,如 : 内存、磁盘
- 缓存的计算过程:从 RDD 展开到分片 (Block),存储于内存或磁盘的过程
- 缓存的销毁过程:缓存数据主动或被动删除的内存或磁盘的过程
存储级别
Spark 支持的存储级别:
- RDD 缓存的默认存储级别:MEMORY_ONLY
- DataFrame 缓存的默认存储级别:MEMORY_AND_DISK
| 存储级别 | 存储介质 | 存储形式 | 副本设置 | |||
|---|---|---|---|---|---|---|
| 内存 | 磁盘 | 对象值 | 序列化 | |||
| MEMORY_ONLY | √ | √ | 1 | |||
| MEMORY_ONLY_2 | √ | √ | 2 | |||
| MEMORY_ONLY_SER | √ | √ | 1 | |||
| MEMORY_ONLY_SER_2 | √ | √ | 2 | |||
| DISK_ONLY | √ | √ | 1 | |||
| DISK_ONLY_2 | √ | √ | 2 | |||
| DISK_ONLY_3 | √ | √ | 3 | |||
| MEMORY_AND_DISK | √ | √ | √ | √ | 1 | 内存以对象值存储,磁盘以序列化 |
| MEMORY_AND_DISK_2 | √ | √ | √ | √ | 2 | |
| MEMORY_AND_DISK_SER | √ | √ | √ | 1 | 内存/磁盘都以序列化的字节数组存储 | |
| MEMORY_AND_DISK_SER2 | √ | √ | √ | 2 |
计算过程
缓存的计算过程 :
- MEMORY_AND_DISK :先把数据集全部缓存到内存,内存不足时,才把剩余的数据落磁盘
- MEMORY_ONLY :只把数据往内存里塞
内存中的存储过程 :
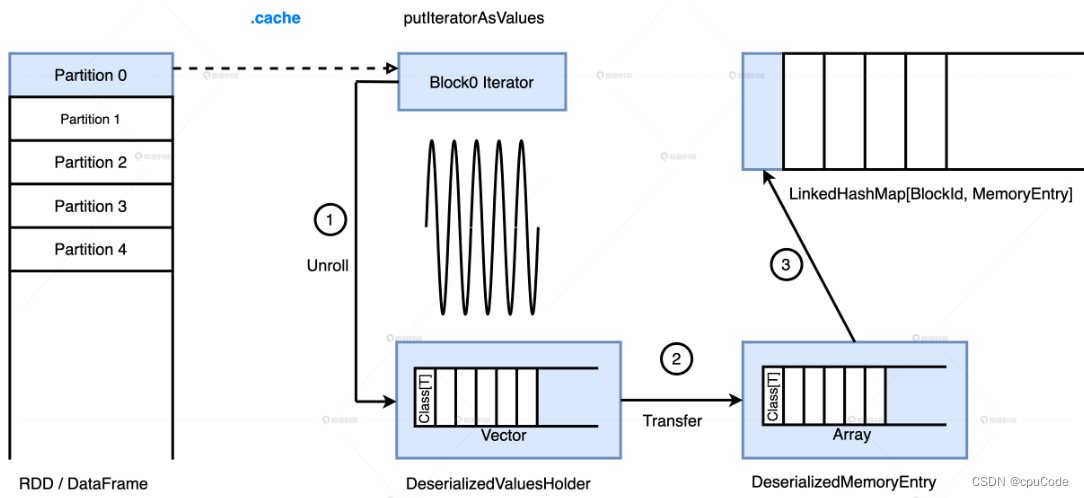
销毁过程
缓存的销毁过程 :
- 缓存抢占 Execution Memory 空间,会进行缓存释放
Spark 清除缓存的原则:
- LRU:按元素的访问顺序,优先清除那些最近最少访问的 BlockId、MemoryEntry 键值对
- 在清除时,同属一个 RDD 的 MemoryEntry 不会清除
Spark 实现 LRU 的数据结构:LinkedHashMap , 内部有两个数据结构
- HashMap : 用于快速访问,根据指定的 BlockId,O(1) 返回 MemoryEntry
- 双向链表 : 用于维护元素(BlockId 和 MemoryEntry 键值对)的访问顺序
Spark 会释放 LRU 的 MemoryEntry :
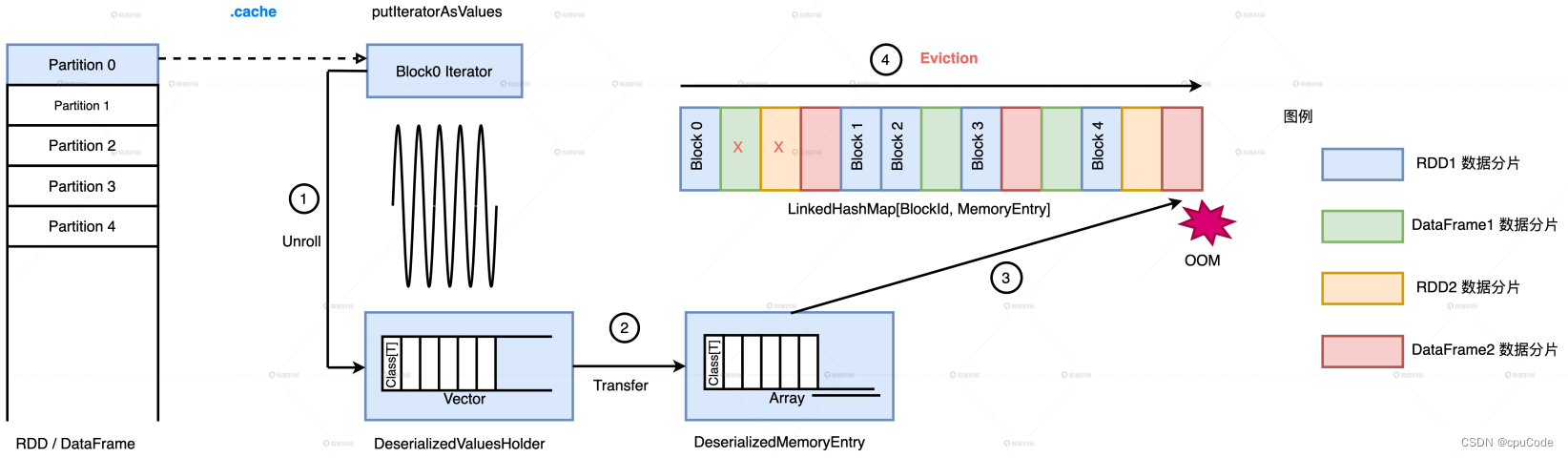
Cache 注意点
用 Cache 的基本原则 :
- 当
RDD/DataFrame/Dataset的引用数为 1,坚决不用 Cache - 当引用数大于 1,且运行成本超过 30%,就考虑用 Cache
运行成本占比 : 计算某个分布式数据集要消耗的总时间与作业执行时间的比值
- 端到端的执行时间为 1 小时
- DataFrame 被引用了 2 次
- 从读取数据源到生成该 DataFrame 花了 12 分钟
- 该 DataFrame 的运行成本占比 =
12*2/60 = 40%
用 noop 计算 DataFrame 运行时间 :
df.write.format("noop").save()
.cache 是惰性操作,在调用 .cache后,要先用 count 才能触发缓存的完全物化
Cache 要遵循最小公共子集原则 :
val filePath: String = _
val df: DataFrame = spark.read.parquet(filePath)//Cache方式一
val cachedDF = df.cache
//数据分析
cachedDF.filter(col2 > 0).select(col1, col2)
cachedDF.select(col1, col2).filter(col2 > 100)
两个查询的 Analyzed Logical Plan 不一致,无法缓存复用
//Cache方式二
df.select(col1, col2).filter(col2 > 0).cache
//数据分析
df.filter(col2 > 0).select(col1, col2)
df.select(col1, col2).filter(col2 > 100)
Analyzed Logical Plan 完全一致,能缓存复用
//Cache方式三
val cachedDF = df.select(col1, col2).cache
//数据分析
cachedDF.filter(col2 > 0).select(col1, col2)
cachedDF.select(col1, col2).filter(col2 > 100)
及时清理 Cache :
- 异步模式 (常用):调用 unpersist() 或 unpersist(False)
- 同步模式:调用 unpersist(True)
OOM
OOM的具体区域 :
- 发生 OOM 的 LOC(Line Of Code),代码位置
- OOM 发生在 Driver 端,还是在 Executor 端
- 在 Executor 端的哪片内存区域
Driver OOM
Driver 端的 OOM 位置 :
- 创建小规模的分布式数据集:使用 parallelize、createDataFrame 创建数据集
- 收集计算结果:通过 take、show、collect 把结果收集到 Driver 端
Driver 端的 OOM 原因:
- 创建的数据集超过内存上限
- 收集的结果集超过内存上限
广播变量的创建与分发 :
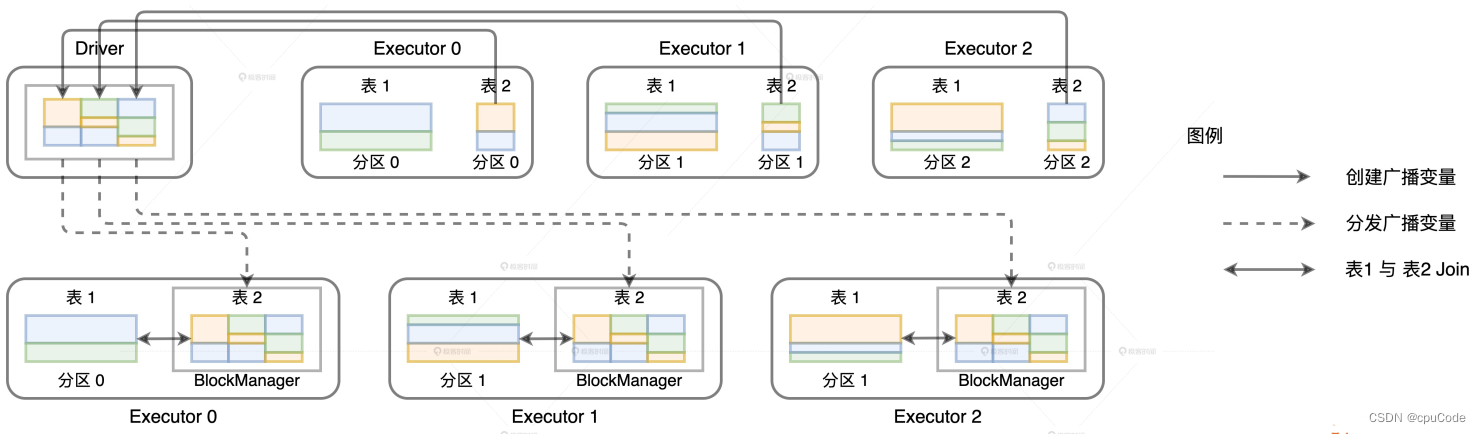
广播变量的数据拉取就是用 collect 。当数据总大小超过 Driver 端内存时 , 就报 OOM :
java.lang.OutOfMemoryError: Not enough memory to build and broadcast
对结果集尺寸预估,适当增加 Driver 内存配置
- Driver 内存大小 :
spark.driver.memory
查看执行计划 :
val df: DataFrame = _
df.cache.countval plan = df.queryExecution.logical
val estimated: BigInt = spark.sessionState.executePlan(plan).optimizedPlan.stats.sizeInBytes
Executor OOM
当 Executors OOM 时,定位 Execution Memory 和 User Memory
User Memory OOM
User Memory 用于存储用户自定义的数据结构,如: 数组、列表、字典
当自定义数据结构的总大小超出 User Memory 上限时,就会报错
java.lang.OutOfMemoryError: Java heap space at java.util.Arrays.copyOf
java.lang.OutOfMemoryError: Java heap space at java.lang.reflect.Array.newInstance
计算 User Memory 消耗时,要考虑 Executor 的线程池大小
- 当 dict 大小为
#size, Executor 线程池大小为#threads - dict 对 User Memory 的总消耗:
#size * #threads - 当总消耗超出 User Memory 上限,就会 OOM
val dict = List("spark", "tune")
val words = spark.sparkContext.textFile("~/words.csv")val keywords = words.filter(word => dict.contains(word))
keywords.map((_, 1)).reduceByKey(_ + _).collect
自定义数据分发 :
- 自定义的列表 dict 会随着 Task 分发到所有 Executors
- 多个 Task 的 dict 会对 User Memory 产生重复消耗
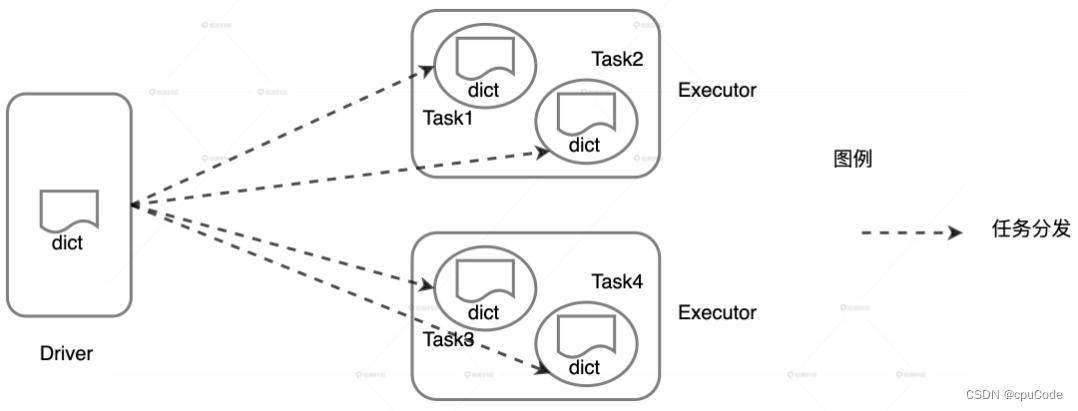
解决 User Memory OOM 的思路 :
- 先对数据结构的消耗进行预估
- 相应地扩大 User Memory
UserMemory 总大小 = spark.executor.memory * (1 - spark.memory.fraction)
Execution Memory OOM
Execution Memory OOM 常见实例:数据倾斜和 数据膨胀
配置说明:
- 2 个 CPU core,每个 core 有两个线程,内存大小为 1GB
- spark.executor.cores = 3,spark.executor.memory = 900MB
- Execution Memory = 180MB
- Storage Memory = 180MB
- Execution Memory 上限 = 360MB
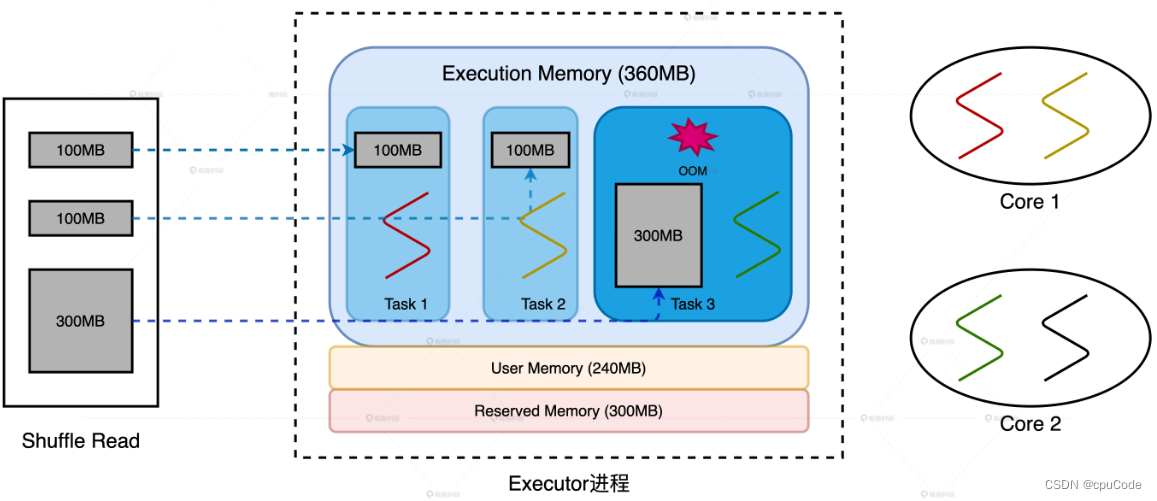
数据倾斜
3 个 Reduce Task 对应的数据分片大小分别是 100MB , 100MB , 300MB
- 当 Executor 线程池大小为 3,所以每个 Reduce Task 最多 360MB * 1/3 = 120MB
数据倾斜导致OOM :
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NHRj4w40-1677761995168)(…/…/png/%E5%86%85%E5%AD%98%E8%BF%90%E7%94%A8/image-20230209210919876.png)]
2 种调优思路:
- 消除数据倾斜,让所有的数据分片尺寸都小于 100MB
- 调整 Executor 线程池、内存、并行度等相关配置,提高 1/N 上限到 300MB
在 CPU 利用率高下解决 OOM :
- 维持并发度、并行度不变,增大执行内存设置,提高 1/N 上限到 300MB
- 维持并发度、执行内存不变,提升并行度把数据打散,将所有的数据分片尺寸都缩小到 100MB 内
数据膨胀
3 个 Map Task 对应的数据分片大小都是 100MB
数据膨胀导致OOM :
2 种调优思路:
- 把数据打散,提高数据分片数量、降低数据粒度,让膨胀后的数据量降到 100MB 左右
- 加大内存配置,结合 Executor 线程池调整,提高 1/N 上限到 300MB
相关文章:
Spark 内存运用
RDD Cache 当同一个 RDD 被引用多次时,就可以考虑进行 Cache,从而提升作业的执行效率 // 用 cache 对 wordCounts 加缓存 wordCounts.cache // cache 后要用 action 才能触发 RDD 内存物化 wordCounts.count// 自定义 Cache 的存储介质、存储形式、副本…...
SpringBoot集成Swagger3.0(入门) 02
文章目录Swagger3常用配置注解接口测试API信息配置Swagger3 Docket开关,过滤,分组Swagger3常用配置注解 ApiImplicitParams,ApiImplicitParam:Swagger3对参数的描述。 参数名参数值name参数名value参数的具体意义,作用。required参…...

网络协议丨ICMP协议
ICMP协议,全称 Internet Control Message Protocol,就是互联网控制报文协议。我们其实对它并不陌生,我们平时经常使用的”ping“一下就是基于这个协议工作的。网络包在异常复杂的网络环境中传输时,常常会遇到各种各样的问题。当遇…...
12.1 基于Django的服务器信息查看应用(系统信息、用户信息)
文章目录新建Django项目创建子应用并设置本地化创建数据库表创建超级用户git管理项目(requirements.txt、README.md、.ignore)主机信息监控应用的框架搭建具体功能实现系统信息展示前端界面设计视图函数设计用户信息展示视图函数设计自定义过滤器的实现前…...
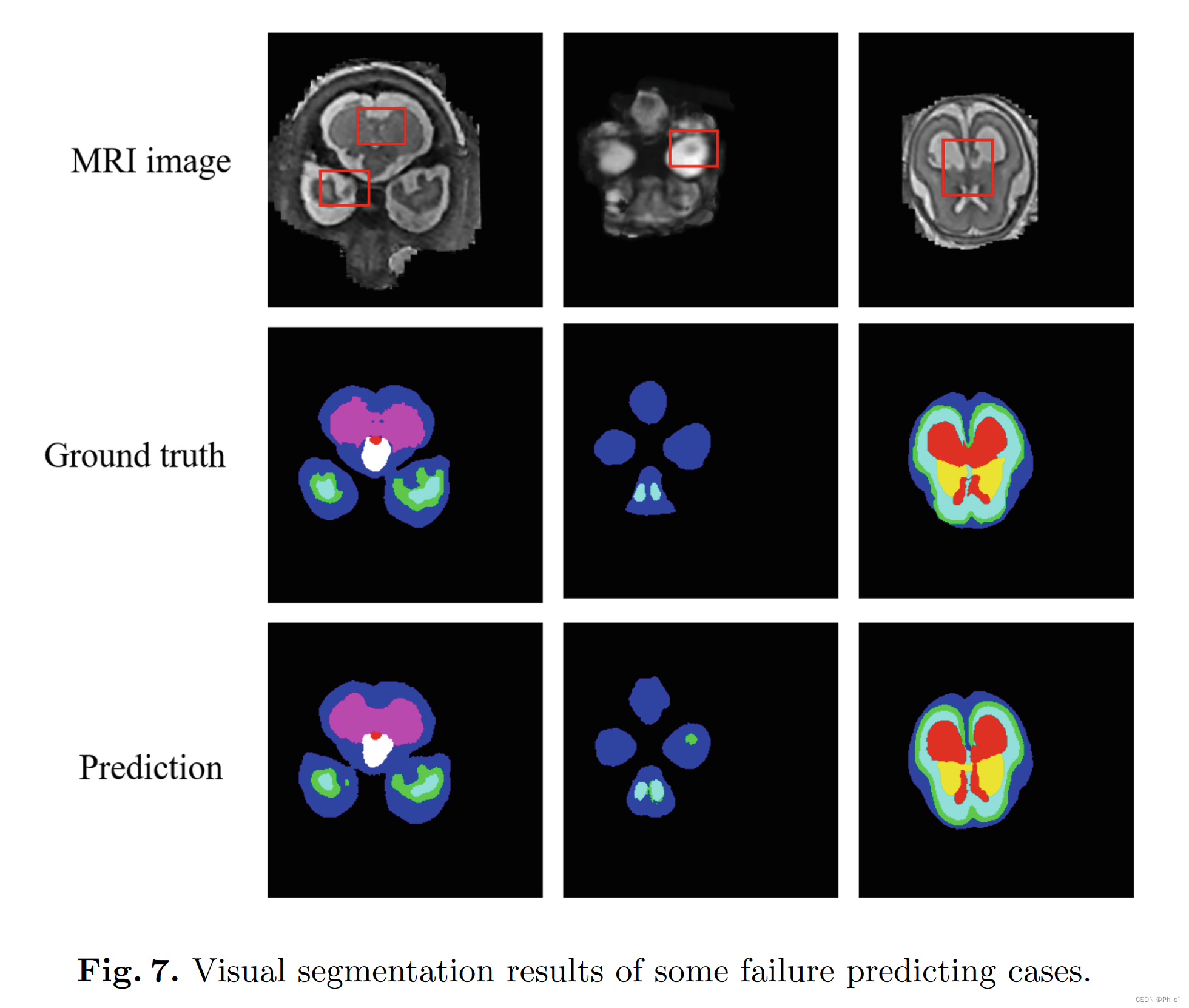
ExSwin-Unet 论文研读
ExSwin-Unet摘要1 引言2 方法2.1 基于窗口的注意力块2.2 外部注意力块2.3 不平衡的 Unet 架构2.4 自适应加权调整2.5 双重损失函数3 实验结果3.1 数据集3.2 实现细节3.3 与 SOTA 方法的比较3.4 消融研究4 讨论和限制5 结论数据集来源: https://feta.grand-challenge…...
置顶!!!主页禁言提示原因:在自己论坛发动态误带敏感词,在自己论坛禁止评论90天
置顶!!!主页禁言提示原因:在自己论坛发动态误带敏感词,在自己论坛禁止评论90天 置顶!!!主页禁言提示原因:在自己论坛发动态误带敏感词,在自己论坛禁止评论90天…...

优思学院|解密六西格玛:探索DMAIC和DMADV之间的区别
六西格玛方法中最为广泛使用的两种方法是DMAIC和DMADV。这两种方法都是为了让企业流程更加高效和有效而设计的。虽然这两种方法有一些重要的共同特点,但它们并不可以互相替代,并且被开发用于不同的企业流程。在更详细地比较这两种方法之前,我…...
)
Pytorch的DataLoader输入输出(以文本为例)
本文不做太多原理介绍,直讲使用流畅。想看更多底层实现-〉传送门。DataLoader简介torch.utils.data.DataLoader是PyTorch中数据读取的一个重要接口,该接口定义在dataloader.py脚本中,只要是用PyTorch来训练模型基本都会用到该接口。本文介绍t…...

代谢组学:Microbiome又一篇!绘制重症先天性心脏病新生儿肠道微生态全景图谱
文章标题:Mapping the early life gut microbiome in neonates with critical congenital heart disease: multiomics insights and implications for host metabolic and immunological health 发表期刊:Microbiome 影响因子:16.837…...

Java基本类型所占字节简述
类型分类所占字节取值范围boolean布尔型1bit0 false、 1 true (1个bit 、1个字节、4个字节)char 字符型(Unicode字符集中的一个元素) 2字节-32768~32767(-2的15次方~2的15次方-1)byte整型1字节-128&a…...

Linux vi常用操作
vi/vim 共分为三种模式,分别是命令模式(Command mode),输入模式(Insert mode)和底线命令模式(Last line mode)。 这三种模式的作用分别是: 命令模式: 用户刚…...
、ANSI(多字节))
Unicode(宽字节)、ANSI(多字节)
1、什么时候用Unicode(宽字节),什么时候用ANSI(多字节)? 在linux/windows等操作系统中使用的,一般都是Unicode(宽字节)。 下位机PLC/单片机等硬件设备中使用,一般都是ANSI(多字节)。 所以,通讯中(比如VS项目&#x…...

STM32实战之LED循环点亮
接着上一章讲。本章我们来讲一讲LED流水灯,循环点亮LED。 在LED章节有的可能没有讲到,本章会对其进行说明,尽量每个函数说一下作用。也会在最后说一下STM32的寄存器,在编程中寄存器是避免不了的东西,寄存器也是非常好理…...

智慧厕所智能卫生间系统有哪些功能
南宁北站智能厕所主要功能有哪些?1、卫生间环境空气监测男厕、女厕环境空气监测系统包括对厕所内的温度、湿度、氨气、硫化氢、PM2.5、烟雾等气体数据的实时监测。2、卫生间厕位状态监测系统实时监测厕位内目前的使用状态(有人或无人),数据信…...
【网络】套接字 -- TCP
🥁作者: 华丞臧. 📕专栏:【网络】 各位读者老爷如果觉得博主写的不错,请诸位多多支持(点赞收藏关注)。如果有错误的地方,欢迎在评论区指出。 推荐一款刷题网站 👉 LeetCode刷题网站 文章…...
NDK C++ map容器
map容器// TODO map容器 #include <iostream> #include <map>using namespace std;int main() {// TODO map<int, string>按key值排序,同一个key不可以重复插入map<int, string> map1;map1.insert(pair<int, string>(1, "111&qu…...

linux(Centos)安装docker
官网地址:Install Docker Engine on CentOS 首先检查linux系统版本及内核: 安装docker要求系统版本至少为7.x版本,内核至少为3.8以上 cat /etc/redhat-release # 查看系统版本号uname -r #查看linux系统内核 检查系统是否能连上外网&#…...
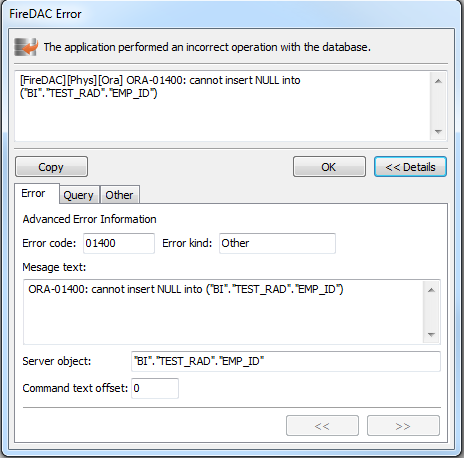
Delphi 中 FireDAC 数据库连接(处理错误)
参见:Delphi 中 FireDAC 数据库连接(总览)本主题描述了如何用FireDAC处理数据库错误。一、概述EFDDBEngineException类是所有DBMS异常的基类。单个异常对象是一个数据库错误的集合,可以通过EFDDBEngineException.Errors[]属性访问…...

算法小抄3-理解使用Python容器之列表
引言 首先说一个概念哈,程序算法数据结构,算法是条件语句与循环语句组成的逻辑结构,而数据结构也就是容器. 算法决定数据该如何处理,而容器则决定如何数据如何存储. 不同的语言对容器有不同的实现方式, 但他们的功能都是相似的, 打好容器基础,你就可以在各式各样的语言中来回横…...
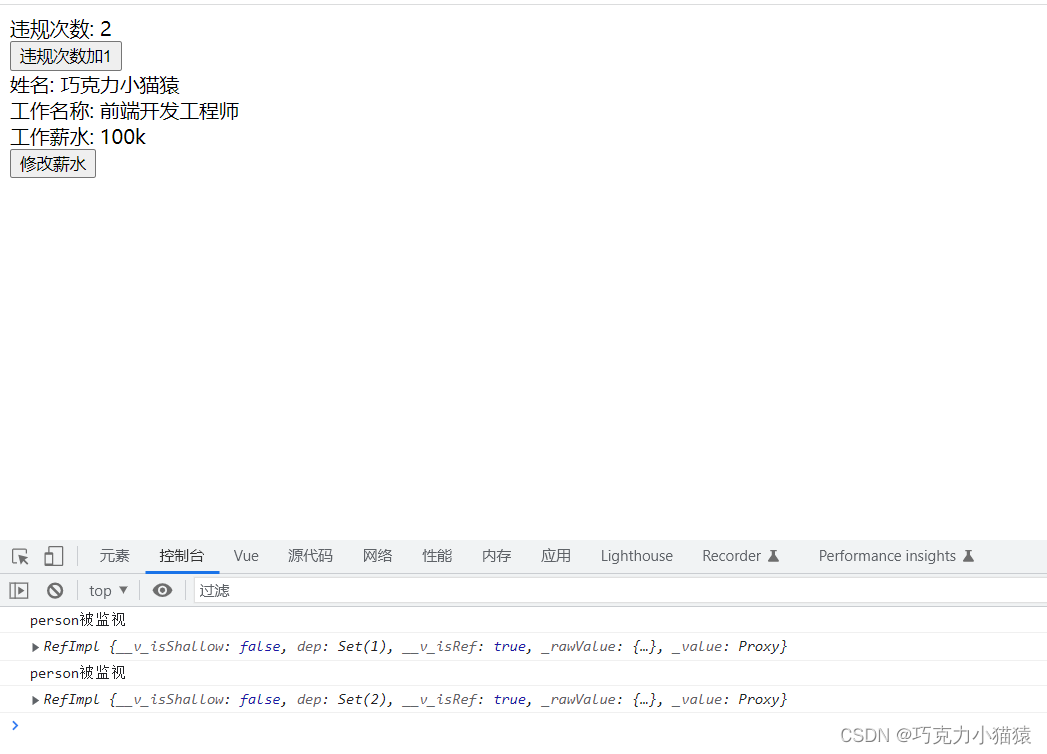
Vue3中watch的value问题
目录前言一,ref和reactive的简单复习1.ref函数1.2 reactive函数1.3 用ref定义对象类型数据不用reactive二,watch的value问题2.1 ref2.1.1 普通类型数据2.1.2 对象类型数据2.1.3 另一种方式2.2 reactive三,总结后记前言 在Vue3中,…...

TI C2000 DSP入门新姿势:Simulink硬件支持包安装与CCS v10.1.0联调实战记录
TI C2000 DSP开发环境搭建:从Simulink支持包到CCS联调全指南 当第一次打开Matlab准备为C2000 DSP开发算法时,很多人会惊讶地发现:明明安装了CCS和Matlab,却无法直接在Simulink中找到C2000的硬件支持。这不是个例——根据TI官方论坛…...

全球化技术团队协作:跨越文化差异的沟通与管理实践
1. 从“理所当然”到“文化自觉”:全球化职场的思维转型在电子设计自动化(EDA)和半导体行业摸爬滚打了十几年,我参与过跨国项目,也带过分布在全球各地的团队。一个深刻的体会是,我们这些搞技术的࿰…...
:ChatGPT与Gemini,你选错一个就多花237万年运维成本)
仅剩72小时可获取的2026终极对比手册(含Prompt工程调优参数表、国产信创环境适配补丁包、等保2.0三级适配验证清单):ChatGPT与Gemini,你选错一个就多花237万年运维成本
更多请点击: https://intelliparadigm.com 第一章:ChatGPT与Gemini 2026年全面对比的基准定义与评估范式 为确保跨模型评估的科学性与可复现性,2026年主流AI基准已统一采用**多维动态评估范式(MDEP)**,该范…...

终极指南:快速掌握碧蓝航线Live2D资源提取技术
终极指南:快速掌握碧蓝航线Live2D资源提取技术 【免费下载链接】AzurLaneLive2DExtract OBSOLETE - see readme / 碧蓝航线Live2D提取 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneLive2DExtract 在数字内容创作和游戏开发领域,Live2D动…...

RO-ViT:区域感知预训练如何革新开放词汇目标检测
1. 项目概述:从“闭门造车”到“开箱即用”的视觉检测新范式在计算机视觉领域,目标检测一直是个硬骨头。传统的检测模型,比如我们熟悉的Faster R-CNN、YOLO系列,都遵循一个“闭集”范式:模型在训练时见过多少类物体&am…...

S2C如何以FPGA原型验证方案破解中国芯片设计团队的验证痛点
1. 从EDA巨头东迁,看一个被忽视的蓝海市场最近业内有个不大不小的新闻,Altium这家知名的电子设计自动化(EDA)公司把总部搬到了中国。这事儿引起了不少讨论,但说实话,它既不是第一个这么干的,也未…...

基于Qt与STM32的跨平台遥控小车调试助手设计与实现
1. 项目背景与需求分析 遥控小车作为嵌入式开发的经典项目,调试环节往往是最耗时的部分。传统调试方式需要反复修改下位机代码、烧录固件、观察串口打印数据,整个过程效率低下。我在实际项目中就遇到过这样的困扰:每次调整PID参数都要重新编译…...

孤舟笔记 IO 与网络编程篇五 网络编程你真的懂吗?从Socket到TCP连接全解析
文章目录一、先说结论:网络编程核心事实二、TCP 编程:三次握手的 Socket 视角三、UDP 编程:无连接的数据报四、服务端线程模型演进模型一:一连接一线程(最原始)模型二:线程池(改进&a…...

ComfyUI-Impact-Pack完整安装指南:解决AI图像增强插件功能缺失问题
ComfyUI-Impact-Pack完整安装指南:解决AI图像增强插件功能缺失问题 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地…...

PyInstaller打包的EXE程序修改与反编译
PyInstaller打包的EXE程序修改与反编译完全指南 前言 在实际工作中,我们经常会遇到需要修改已打包的Python EXE程序的情况——可能是界面文字需要调整,也可能是功能需要微调。本文将系统介绍如何对PyInstaller打包的EXE程序进行反编译、修改和重新打包&a…...