「基础篇」机器学习概览
文章目录
- 1. 什么是机器学习
- 2. 引入机器学习
- 3. 应用场景
- 4. 机器学习分类
- 4.1. 有无人类监督
- 4.2. 是否增量学习
- 4.3. 泛化方式
- 5. 主要挑战
- 6. 测试与验证
1. 什么是机器学习
机器学习(Machine Learning,ML)是一个研究领域,让计算机无需进行明确编程,就具备从数据学习的能力;
一个计算机程序利用经验 E 来学习任务 T,性能是 P,如果针对任务 T 的性能 P 随着经验 E 不断增长,则称为机器学习;
垃圾邮件过滤器,根据垃圾邮件(用户标记为垃圾)和普通邮件学习标记垃圾邮件;任务 T 就是标记新邮件是否是垃圾邮件,经验 E 就是训练数据,性能 P 需要定义(如准确率:正确分类的邮件比例);
训练集,系统用来进行学习的样例;训练实例(样本),每一个训练样例;
2. 引入机器学习
垃圾邮件过滤器(传统规则系统)
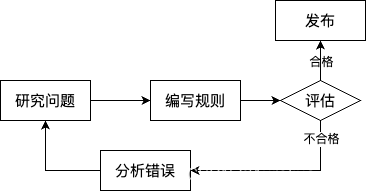
研究问题:看垃圾邮件一般是什么样子;比如垃圾邮件会频繁出现一些固定模式的词或短语(4U、credit card、free、amazing 等);编写规则:为每个模式各写一个检测算法,程序在邮件中匹配到一个模式(规律),就将之标记为垃圾邮件;评估&分析错误:测试程序匹配正确性,重复迭代,直到匹配效果足够好;
传统规则系统应对这类需要大量人工微调或大量规则的问题,很难维护大量复杂的规则;
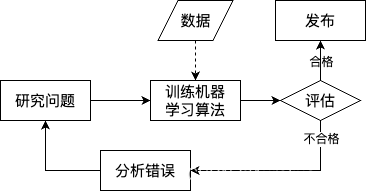
ML 技术的垃圾邮件过滤器会自动学习词和短语(预测因素),通过与非垃圾邮件比较,检测垃圾邮件中反复出现的词语模式;更易维护,也更精确;

-
更新数据:用户手动标记垃圾邮件,此时 ML 算法会自动完成垃圾邮件标记,无须人工干预; -
数据挖掘,在训练了足够多的样本后,就可以列出模型的特征,这有时可能发现不引人注意的关联或新趋势,有助于更好的理解问题;这种使用机器学习方法挖掘大量数据来发现不明显规律的方式,就是数据挖掘;
ML 适用场景
- 有解决方案,但需要大量人工微调或准信大量规则的问题,机器学习通常可以简化代码,相比传统方法有更好的性能(如
垃圾邮件过滤器); - 传统方法难以解决的复杂问题,最好的 ML 自我学习算法也许可以找到解决方案(如
语言识别); - 环境有波动的问题,ML 算法可以适应新数据;
- 帮助人类洞察复杂问题和大量数量(
数据挖掘);
3. 应用场景
图像分类:使用卷积神经网络(CNN)分析生产线产品图像,对产品进行自动分类;语义分割:通过脑部扫描图像,使用CNN给图像每个像素分类,以确认肿瘤的确切位置和形状;文本分类:使用循环神经网络(RNN)、CNN、Transformer等自然语言处理(NLP)工具进行新闻自动分类:文本分类:使用自然语言处理(NLP)工具自动标识论坛中的恶评;文本总结:使用自然语言处理(NLP)工具自动对长文章做总结;自然语言理解(NLU)&问答模块:使用自然语言处理(NLP)工具创建聊天机器人或个人助理;回归问题:使用回归模型,如线性回归、多项式回归、SVM 回归、随机森林回归、人工神经网络等,或通过过去性能指标使用如RNN、CNN、Transformer等,预测公司下一年的收入;语言识别:使用 RNN、CNN、Transformer 等处理音频采样,实现对语言命令做出反应;异常检测:检测性用卡欺诈;聚类问题:基于客户的购买记录对客户进行分类,对不同类别的客户设计不同的市场策略;数据可视化:通过降维技术,使用图表展示复杂的高维数据集;推荐系统:使用人工神经网络,基于以前的购买记录给客户推荐可能感兴趣的产品;强化学习(RL):通过奖惩机制训练代理,为游戏建造智能机器人;
4. 机器学习分类
| 分类方式 | 类别 |
|---|---|
| 是否在人类监督下 | 监督学习、无监督学习、半监督学习、强化学习 |
| 是否动态进行增量学习 | 在线学习、批量学习 |
| 泛化方式 | 基于实例的学习、基于模型的学习 |
4.1. 有无人类监督
- 有监督学习
通过经标记的数据(标签)进行训练的学习任务;
标签,在学习中,提供给算法的包含解决方案的训练集;属性,一种数据类型,反映事件或对象在某方面的表现或性质的事项;特征,通常指一个属性加上其值;也可指代属性;分类任务,典型的有监督学习任务,通过大量包含类别信息的样本进行训练,学习如何对新样本进行分类;预测结果为离散值;回归任务,典型的有监督学习任务,通过大量包含标签的样本进行训练,学习如何给新的样本预测一个目标数值;预测结果为连续值;
重要的监督学习算法
k-近邻算法线性回归逻辑回归支持向量机(SVM)决策树和随机森林神经网络
- 无监督学习
通过未经标记的数据进行训练的学习任务;
聚类,将通常不拥有标记信息的训练集的样本分为若干组,每个组称为一个“簇”(cluster),对应一些潜在的概念划分;可视化,将大量复杂的未经标记的数据绘制成 2D 或 3D 的数据表示,保留尽可能多的结构,并识别出一些未知的模式;降维,在不丢失太多信息的前提下简化数据,如将多个相关特征合并为一个(特征提取:如将汽车的里程和使用年限合并成一个磨损度的特征);异常检测,用正常的实例进行训练,然后判断新势力是正常还是异常;关联规则学习,挖掘大量数据,发现属性之间的联系;
可以通过降维减少训练数据的维度,在将之提供给另一个 ML 算法(比如监督学习算法),这样可以缩小运行所需空间,并提升执行性能;
重要的无监督学习算法
聚类算法k-均值算法DBSCAN分层聚类异常检测和新颖性检测单类 SVM孤立森林可视化和降维主成分分析(PCA)局部线性嵌入(LLE)t-分布随机近邻嵌入(t-SNE)关联规则学习AprioriEclat
- 半监督学习
处理部分已标记数据的算法,被称为半监督学习算法;
照片托管服务,先自动识别照片中出现的人物 A、B、C,然后由认为告诉系统 A、B、C 是谁;
半监督学习算法
深度信念网络(DBN),基于一种互相堆叠的无监督组件(受限玻尔兹曼机(RBM),无监督),使用监督学习技术对整个系统进行微调;
- 强化学习
通过观察环境,做出选择,执行动作,并获得正负回报(奖惩),从而学习什么是最好的策略;如 DeepMind 的 AlphaGo,机器人行走等;
4.2. 是否增量学习
- 批量学习
使用所有可用数据进行离线训练,得到系统,然后将停止学习的系统投入生产环境,将所学到的应用出来;
新数据的学习需要在完整数据集(新旧数据)的基础上重新训练系统,然后停用旧系统,用新系统取代;
无法增量学习,需要的大量时间和计算资源(CPU、内存、磁盘空间、磁盘 I/O、网络 I/O 等);
- 在线学习
循序渐进的给系统提供训练数据,逐步积累学习成果;模型经过训练并投入生产环境,然后根据飞速写入的最新数据继续不断学习;
新的数据一旦经过在线学习系统的学习,就可以丢弃(节省了大量资源,除非需要留备重新学习);
适用于资源有限的系统,或者超大数据集的学习任务(核外学习,将数据集分成小批量数据用于在线学习系统的持续训练);
在线学习在接收不良数据后,系统的性能会逐渐下降;这需要密切监控系统,一旦性能下降,及时中断学习(甚至恢复之前的工作状态);需要监控输入数据,检测出异常数据(异常检测算法);
学习率,在线学习系统的一个参数,代表适应新数据的速度;学习率高,则很快适应新数据,但会很快忘记旧数据;学习率低,则系统存在较高的惰性,学习会更缓慢,但也会对新数据的噪声和非典型数据点(离群值)的序列更不敏感;
4.3. 泛化方式
泛化,系统通过给定的训练示例,在它未见过的示例上进行预测的能力(ML 的真正目的是要在新的对象实例上表现出色,而非局限在训练集上);
- 基于实例学习
系统会记住训练实例(死记硬背),通过使用相识度度量来比较新实例和已学习的实例,从而泛化新实例;
例:k-近邻回归
通过找到与新实例最相近的若干训练实例,将这些训练实例的均值作为新实例的预测结果;
- 基于模型学习
泛化出适配训练实例的模型(可以描述实例分布的代数表示?),使用该模型进行新实例的预测;
模型,数据中学得的结果,对应了数据中某种潜在的规律,亦称假设,规律本身称作“真相”,学习过程就是为了找出或逼近真相(模型表示全局性结果,模式表示局部性结果,比如一条规则);模型训练,运行一种寻找模型参数的算法,通过训练样本,找出最符合训练数据的模型参数,使成本函数最小;模型选择,包括选择模型的类型和完全指定它的架构(输入输出结构);效用函数,衡量模型多好的函数;成本函数,衡量模型多差的函数;
例:线性回归
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import sklearn.linear_model
# Load the data
oecd_bli = pd.read_csv("oecd_bli_2015.csv", thousands=',')
gdp_per_capita = pd.read_csv("gdp_per_capita.csv",thousands=',',delimiter='\t',encoding='latin1', na_values="n/a")
# Prepare the data
country_stats = prepare_country_stats(oecd_bli, gdp_per_capita)
X = np.c_[country_stats["GDP per capita"]]
y = np.c_[country_stats["Life satisfaction"]]
# Visualize the data
country_stats.plot(kind='scatter', x="GDP per capita", y='Life satisfaction')
plt.show()# Select a linear model
model = sklearn.linear_model.LinearRegression()
# Train the model
model.fit(X, y)
# Make a prediction for Cyprus
X_new = [[22587]] # Cyprus's GDP per capita
print(model.predict(X_new)) # outputs [[ 5.96242338]]# # Select a 3-Nearest Neighbors regression model
# import sklearn.neighbors
# model1 = sklearn.neighbors.KNeighborsRegressor(n_neighbors=3)
通过模型训练找到最拟合训练数据的模型参数,然后直接通过得到的模型计算新实例的预测结果;
研究数据 -> 选择模型 -> 训练模型 -> 模型推理;
5. 主要挑战
在 ML 过程中最主要的任务是选择学习算法、使用某些数据进行训练;因此最可能出现的问题就是坏算法和坏数据;
- 数据不足
数据的不合理有效性,给定足够数据,不同的 ML 算法在自然语言歧义消除上表现几乎一致;
把钱和时间花在算法的开发上,还是语料库的建设上是需要权衡的问题;对于复杂的问题,数据比算法更重要;
- 训练数据不具代表性
对于将要泛化的新实例,训练数据必须有非常强的代表性;
采样偏差,若样本集太小,会出现采样噪声;即使样本集够大,若采样方式欠妥,也可能拿到非代表性数据集;
- 低质量数据
训练集是错误、异常值或噪声,系统将难以检测底层模式,学习效果不可能好;
- 若某些实例明显异常,可以直接丢弃、或尝试手动修复;
- 若某些实例缺少部分特征,可以整体忽略这些特征、忽略这部分缺失的实例、将缺失部分补全(中位数等)、训练一个带这个特征的模型,再训练一个不带这个特征的模型,进行比较;
- 无关特征
只有训练数据里包含足够多的相关特征,较少的无关特征,系统才能完成学习;
特征工程,提取一组好的用来训练的特征集;特征选择,从现有特征中选择最有用的特征进行训练;特征提取,将现有特征进行整合,产生更有用的特征(如降维);创建新特征,收集新数据等;
- 过拟合
把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质;可以检测到数据中微小模式,但若训练集本身是有噪声的,或者数据集太小(引入了采样噪声),就很可能导致模型检测噪声本身的模式;这些模式不能泛化新的实例;
-
简化模型,选择较少参数的模型(高阶多项式模型 -> 线性模型)、减少训练数据中的属性数量、约束模型; -
收集更多训练数据;
-
减少训练数据中的噪声(修复数据错误和异常值);
-
自由度,模型的参数个数代表了调整模型的自由度大小; -
正则化,通过约束模型使其更简单,并降低过拟合的风险,这个过程叫正则化; -
超参数,学习算法本身的参数,并非模型的参数,如应用正则化的数量;
在完美匹配数据和保持模型简单之间找到平衡点,从而确保模型能够较好的泛化;
- 欠拟合
欠拟合与过拟合相反,表示底层数据结构的模型太简单;对训练样本的一般性质尚未学好;
- 选择一个带有更多参数、更强大的模型;
- 给学习算法提供更好的特征集(
特征工程); - 减少模型中的约束(减少正则化超参数);
6. 测试与验证
一旦训练了一个模型,不能只是希望它可以正确的对新的场景做出泛化,还需要评估它,必要时做出一些调整;
了解一个模型对新场景的泛化能力唯一的办法是让模型真实的去处理新场景(部署到生产环境,然后监控它的输出,但可能导致用户抱怨);
将数据分割为两部分:训练集、测试集;
训练集,用于训练模型的数据集;测试集,用于测试模型泛化能力的数据集;从样本真实分布中独立同分布采样而得,应尽量与训练集互斥,且未被训练集使用过(为了得到泛化性能强的模型);泛化误差,样例外误差,通过测试集评估模型,评估应对新场景的误差率,体现了模型处理新场景时的能力;
训练误差很低,但泛化误差很高,就是典型的过拟合;
- 超参数调整与模型选择
使用若干个不同超参数训练出不同的模型,用验证集找到其中最佳的超参数版本(最佳模型);然后用完整的训练集(训练集 + 验证集)训练这个最佳模型,最后在测试集上评估这个模型的泛化误差;
若直接使用测试集进行超参数调整和模型选择,则使用测试集进行的拟合评估是无效的,因为通过测试集选择出来的模型必然会高度拟合测试集,因此需要再从训练集中分出一个验证集,专用于做超参数调整与模型选择;
保持验证,保留训练集的一部分,以评估几种候选模型,并选择最佳模型;新的保留集称为验证集(或开发集,dev set);验证集,用于评估和选择模型超参数的数据集;奥卡姆剃刀(偏好选择),若有多个假设与观察一致,则选最简单的那一个;
验证集太小则模型选择不精确,太大则训练集剩余部分变小,犹如让短跑运动员参加马拉松;
交叉验证法(cross validation)/k 折交叉验证(k-fold cross validation),将数据集 D 划分为 k 个大小相似,数据分布一致(通过分层采样获得)的互斥子集,每次用 k-1 个子集对并集作为训练集,剩余那个子集作为验证集;这样可以获得 k 组训练/验证集,进行 k 次训练和测试后,求 k 次测试结果的均值;
- 数据不匹配
验证集和测试集必须与在生产环境中使用的数据具有相同的代表性,可以将其混洗,一半作为验证集,一半作为测试集(确保两者不重复也不接近重复);
分层采样(stratified sampling),保留类别比例的采样方式;
当训练集与验证集和测试集的数据之间不匹配时,可以使用 train-dev 集;
-
train-dev 集,训练集的一部分(模型未在其上训练过,该数据集应始终与模型投入生产环境后使用的数据尽可能接近);模型在训练集的其他部分上进行训练,并在train-dev 集和验证集上进行评估;- 如果模型在
训练集上表现良好,但在train-dev 集上表现不佳,则该模型可能过拟合训练集; - 如果它在
训练集和train-dev 集上均表现良好,但在验证集上却表现不佳,那么训练集与验证集和测试集之间可能存在明显的数据不匹配,应该尝试改善训练数据,使其看起来更像验证集和测试集;
- 如果模型在
-
NFL(No Free Lunch Theorem,没有免费的午餐): 无论算法 a 多聪明,算法 b 多笨拙,他们的期望性能相同,若对数据绝对没有任何假设,就没有理由偏好于某个模型;脱离具体问题,空泛地谈论什么学习算法更好毫无意义;
专栏:《机器学习》
PS:感谢每一位志同道合者的阅读,欢迎关注、评论、赞!
参考资料:
- [1]《机器学习》
- [2]《机器学习实战》
相关文章:
「基础篇」机器学习概览
文章目录1. 什么是机器学习2. 引入机器学习3. 应用场景4. 机器学习分类4.1. 有无人类监督4.2. 是否增量学习4.3. 泛化方式5. 主要挑战6. 测试与验证1. 什么是机器学习 机器学习(Machine Learning,ML)是一个研究领域,让计算机无需…...
揭秘可视化图探索工具 NebulaGraph Explore 是如何实现图计算的
前言 在可视化图探索工具 NebulaGraph Explorer 3.1.0 版本中加入了图计算工作流功能,针对 NebulaGraph 提供了图计算的能力,同时可以利用工作流的 nGQL 运行能力支持简单的数据读取,过滤及写入等数据处理功能。 本文将简单分享下 NebulaGr…...
移动架构43_什么是Jetpack
Android移动架构汇总 文章目录一 Android 开发框架演变1 MVC2 MVP3 MVVM二 什么是JetPack三 如何构建支持Jetpack项目一 Android 开发框架演变 1 MVC Model-View-Controller,模型-视图-控制器,Model负责数据管理,View负责UI显…...

TiDB的分布式事务原理探究
事务开启 获取全局授时作为startTS构建一个tikvTxn对象(包括snapshot)。 事务写 txn.Set方法本质上将kv值写入了一个内存缓存(即kv/memdb_buffer.go中的memDbBuffer)中。该内存kv数据库利用的是golevel提供的功能。 事务回滚 直接将tikvTxn的valid字段…...

【C语言】函数指针和指针函数
文章目录[TOC](文章目录)前言概述函数指针定义:使用:回调函数指针函数前言 今天学一下函数指针 提示:以下是本篇文章正文内容,下面案例可供参考 概述 函数指针:是一个指向函数的指针,在内存空间中存放的…...

Nodejs中npx简介和作用
一、npx简介npm从5.25.2版开始,增加了 npx 命令。方便了我在项目中使用全局包。二、安装Node安装后自带npm模块,可以直接使用npx命令。如果不能使用用,就要手动安装一下。npm install -g npx三、使用npx想要解决的主要问题,就是调…...
Matplotlib精品学习笔记001——绘制3D图形详解+实例讲解
3D图片更生动,或许在时间序列数据的展示上更胜一筹 想法: 学习3D绘图的想法来自科研绘图中。我从事的专业是古植物学,也就是和植物化石打交道。化石有三大信息:1.物种信息,也就是它的分类学价值;2.时间信息…...

学习ifconfig实战技巧,成为网络管理高手
文章目录前言一. ifconfig 命令介绍二. 语法格式及常用选项三. 参考案例3.1 显示网络设备信息3.2 启动和关闭指定的网卡3.3 对指定的网卡设备执行修改IP地址操作3.4 启动和关闭ARP协议3.5 使用ifconfig添加网卡总结前言 大家好,又见面了,我是沐风晓月&a…...
、322. 零钱兑换、279.完全平方数)
day38|70. 爬楼梯(进阶)、322. 零钱兑换、279.完全平方数
70. 爬楼梯(进阶) 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 示例 1: 输入:n 2 输出:2 解释:有两种方法可以爬到楼顶。 1. 1 阶 1 阶 2. 2…...
SpringBoot全局异常处理
一、目的 当客户端/前端向服务端发送一个请求后,这个请求并不是每次都能完全正确的处理,比如出现一些资源不存在、参数错误或者内部错误等信息的时候,就需要将异常反馈给客户端或者前端。那么这就需要程序有完整的异常处理机制。 在 Java 中所…...

SpringBoot异常处理
目录 一、 错误处理 1. 默认规则 2. 定制错误处理逻辑 二、自定义异常处理 1. 实现 ErrorController 2. RestControllerAdvice/ControllerAdvice ExceptionHandler 实现自定义异常 3. 新建 UserController.class 测试 3 种不同异常的处理 4. 最终效果如下 补充 1. 参…...
《C++ Primer Plus》(第6版)第8章编程练习
《C Primer Plus》(第6版)第8章编程练习《C Primer Plus》(第6版)第8章编程练习1. 打印字符串2. CandyBar3. 将string对象的内容转换为大写4. 设置并打印字符串5. max5()6. maxn()7. SumArray()《C Primer Plus》(第6版…...

RAD Studio 11.3 Alexandria Crack
RAD Studio 11.3 Alexandria Crack 瞄准最新平台版本-此版本增加了对Android 13和Apple macOS Ventura的官方支持。它还支持Ubuntu 22 LTS和Microsoft Windows Server 2022。 使用生物特征认证-New为FireMonkey移动应用程序提供了新的移动生物特征认证组件。 部署嵌入式InterBa…...

Stm32 iic 协议使用
/* 第1个参数为I2C操作句柄 第2个参数为从机设备地址 第3个参数为从机寄存器地址 第4个参数为从机寄存器地址长度 第5个参数为发送的数据的起始地址 第6个参数为传输数据的大小 第7个参数为操作超时时间 */ HAL_I2C_Mem_Write(&hi2c2,salve_add,0,0,PA_BUFF,sizeof(PA_BUFF…...
Malware Dev 02 - Windows SDDL 后门利用之 SCManager
写在最前 如果你是信息安全爱好者,如果你想考一些证书来提升自己的能力,那么欢迎大家来我的 Discord 频道 Northern Bay。邀请链接在这里: https://discord.gg/9XvvuFq9Wb我拥有 OSCP,OSEP,OSWE,OSED&…...

每日一题29——山峰数组的顶部
符合下列属性的数组 arr 称为 山峰数组(山脉数组) : arr.length > 3 存在 i(0 < i < arr.length - 1)使得: arr[0] < arr[1] < ... arr[i-1] < arr[i] arr[i] > arr[i1] > ... &g…...

Linux- 系统随你玩之--好用到炸裂的系统级监控、诊断工具
文章目录1、前言2、lsof介绍2.1、问题来了: 所有用户都可以采用该命令吗?3、 服务器安装lsof3.1、安装3.2、检查安装是否正常。4、lsof 命令4.1、常用功能选项4.2、输出内容4.2.1 、FD和 TYPE列5、 lsof 命令实操常见用法6 、常用组合命令7、 结语1、前言…...
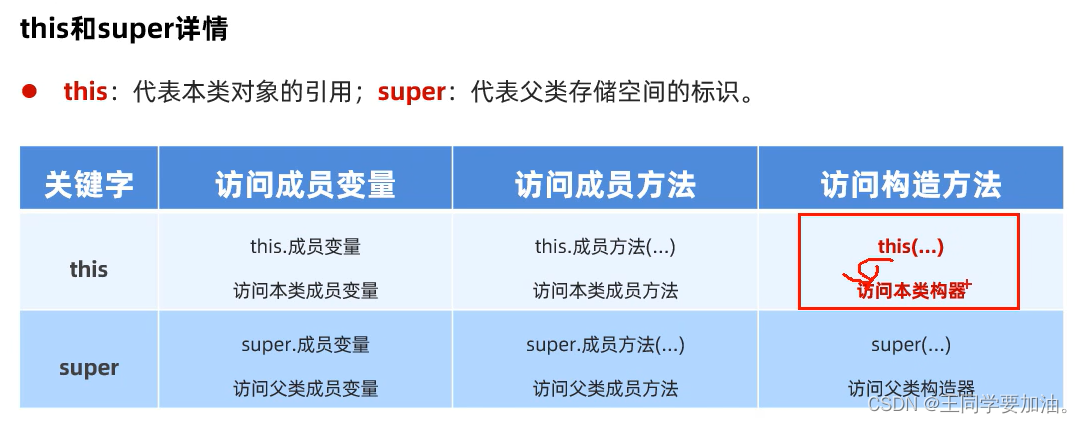
第十三节 继承
什么是继承? java中提供一个关键字extends,用这个关键字,我们可以让一个类和另一个类建立父子关系。 public class Student extends People{} student为子类(派生类),people为父类(基类或者超类…...

【优化】性能优化Springboot 项目配置内置Tomcat使用Http11AprProtocol(AIO)
Springboot 项目配置内置tomcat使用Http11AprProtocol(AIO) Windows版本 1.下载Springboot对应版本tomcat包 下载地址 Apache Tomcat - Apache Tomcat 9 Software Downloads 找到bin目录下 tcnative-1.dll 文件 2 放到jdk的bin目录下 Linux版本 在Springboot中内嵌的Tomcat默…...
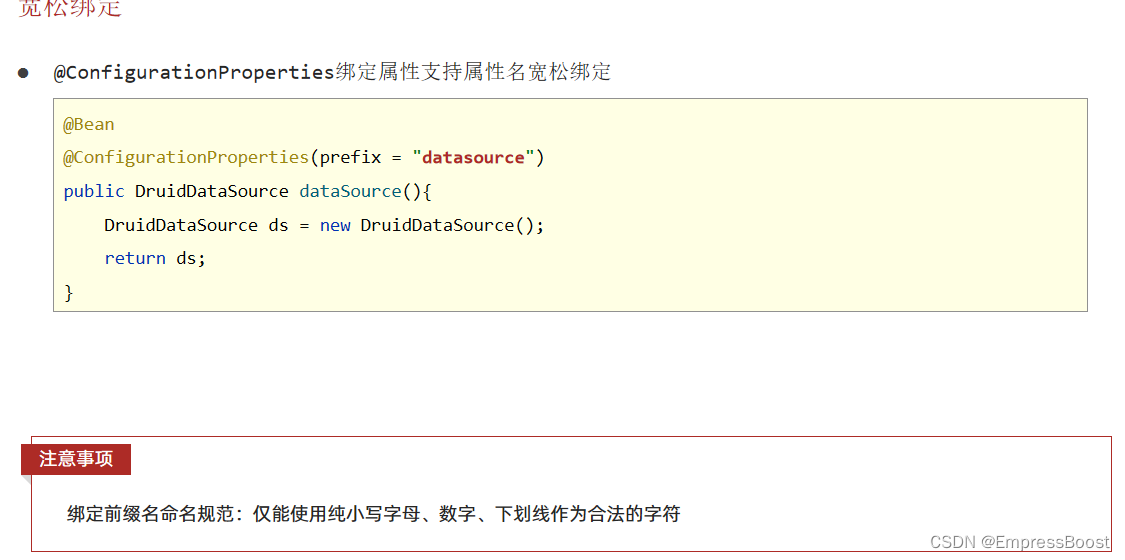
SpringBoot之@ConfigurationProperties、@EnableConfigurationProperties
ConfigurationProperties 这个注解不仅可以为yml某个类注入还可以为第三方bean绑定属性 为yml某个类注入 只要将对应的yml类对象声明实体pojo并交给spring容器管理,再在类上使用ConfigurationProperties绑定对应的类名即可 涉及到两个知识点,这个类对…...

抖音无水印下载器完整指南:5分钟快速上手免费批量下载
抖音无水印下载器完整指南:5分钟快速上手免费批量下载 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppo…...

AMD Ryzen终极调试指南:5分钟掌握SMUDebugTool核心调校技巧
AMD Ryzen终极调试指南:5分钟掌握SMUDebugTool核心调校技巧 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https…...

系统设计:负载均衡器
原文:towardsdatascience.com/system-design-load-balancer-9a3582176f9b 简介 大型分布式应用每秒处理超过数千个请求。在某个时刻,处理单个机器上的请求变得不再可能。这就是为什么软件工程师关心水平扩展,即整个系统持续地组织在多个服务…...

PyWxDump:微信数据解析技术的合规边界与技术挑战
PyWxDump:微信数据解析技术的合规边界与技术挑战 【免费下载链接】PyWxDump 删库 项目地址: https://gitcode.com/GitHub_Trending/py/PyWxDump PyWxDump是一个曾专注于微信数据解析的开源项目,它展示了在复杂软件生态中进行数据提取和分析的技术…...

【权威预警】SITS 2026注册系统将于3月15日关闭早鸟通道——附2025参会者未公开的6条避坑清单
更多请点击: https://intelliparadigm.com 第一章:SITS 2026上海站定档4月:2026奇点智能技术大会报名通道开启 大会核心信息速览 SITS(Singularity Intelligence Technology Summit)2026上海站正式官宣:将…...

从‘//’到‘///’:解锁C#注释的正确姿势与隐藏的IDE效率技巧
从‘//’到‘///’:解锁C#注释的正确姿势与隐藏的IDE效率技巧 在代码的世界里,注释就像地图上的标记,不仅指引着后来的开发者理解代码的意图,更是开发者与未来自己对话的桥梁。对于C#开发者而言,注释不仅仅是简单的代…...

深入Linux内核:SysRq‘魔法键’的驱动实现与串口调试的底层奥秘
深入Linux内核:SysRq‘魔法键’的驱动实现与串口调试的底层奥秘 当系统陷入僵死状态,普通快捷键失效时,Linux开发者常会祭出终极武器——SysRq组合键。这个被称为"魔术键"的机制,能强制唤醒崩溃的进程、安全重启系统甚至…...

如何三分钟永久解锁科学文库加密PDF?ScienceDecrypting工具使用全攻略
如何三分钟永久解锁科学文库加密PDF?ScienceDecrypting工具使用全攻略 【免费下载链接】ScienceDecrypting 破解CAJViewer带有效期的文档,支持破解科学文库、标准全文数据库下载的文档。无损破解,保留文字和目录,解除有效期限制。…...

OpenCore Legacy Patcher终极指南:五步让老Mac重获新生
OpenCore Legacy Patcher终极指南:五步让老Mac重获新生 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否还在为手中的老旧Mac无法升级到最新…...

别再手动改图号了!Word 2016 交叉引用功能,让你的论文排版效率翻倍
告别手动编号:用Word 2016交叉引用功能打造智能学术文档 在撰写学术论文或技术报告时,最令人头疼的莫过于图表编号的维护。想象一下这样的场景:你刚刚完成了一篇50页的论文,导师要求在第20页和第35页之间插入三张新图表——这意味…...