2.基于Label studio的训练数据标注指南:(智能文档)文档抽取任务、PDF、表格、图片抽取标注等
文档抽取任务Label Studio使用指南

1.基于Label studio的训练数据标注指南:信息抽取(实体关系抽取)、文本分类等
2.基于Label studio的训练数据标注指南:(智能文档)文档抽取任务、PDF、表格、图片抽取标注等
3.基于Label studio的训练数据标注指南:文本分类任务
4.基于Label studio的训练数据标注指南:情感分析任务观点词抽取、属性抽取
目录
- 1. 安装
- 2. 文档抽取任务标注
- 2.1 项目创建
- 2.2 数据上传
- 2.3 标签构建
- 2.4 任务标注
- 2.5 数据导出
- 2.6 数据转换
- 2.7 更多配置
1. 安装
以下标注示例用到的环境配置:
- Python 3.8+
- label-studio == 1.7.1
- paddleocr >= 2.6.0.1
在终端(terminal)使用pip安装label-studio:
pip install label-studio==1.7.1
安装完成后,运行以下命令行:
label-studio start
在浏览器打开http://localhost:8080/,输入用户名和密码登录,开始使用label-studio进行标注。
2. 文档抽取任务标注
2.1 项目创建
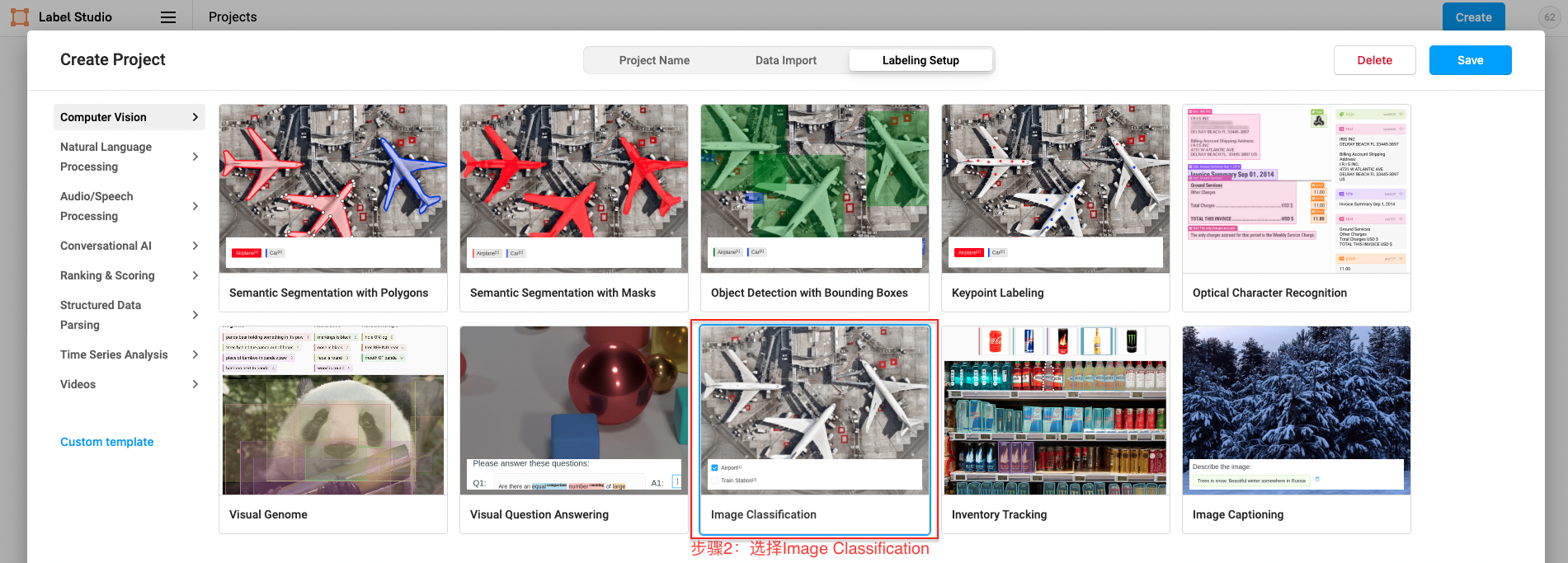
点击创建(Create)开始创建一个新的项目,填写项目名称、描述,然后选择Object Detection with Bounding Boxes。
- 填写项目名称、描述
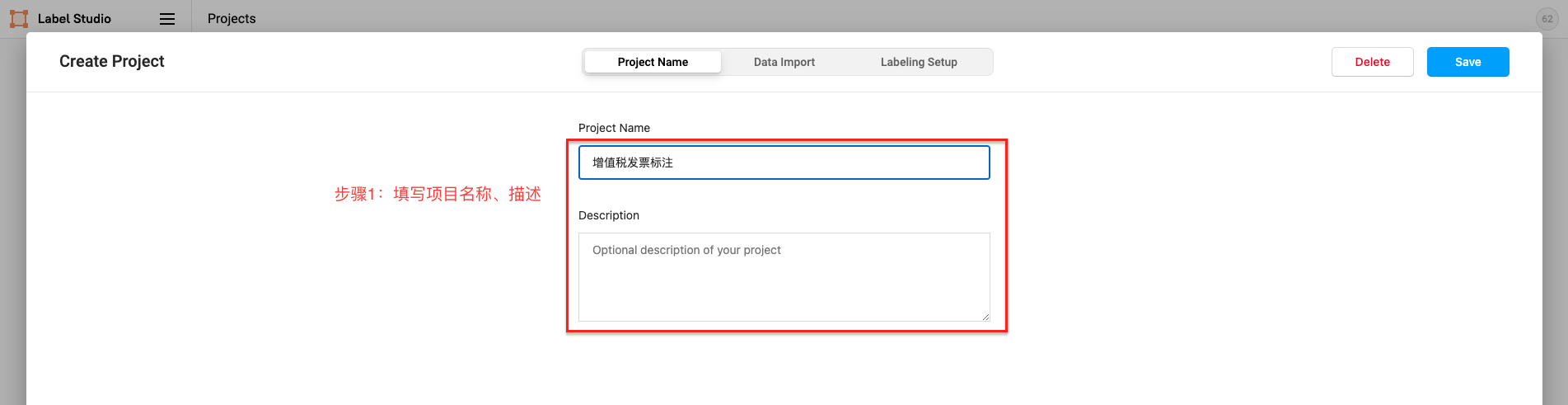
- 命名实体识别、关系抽取、事件抽取、实体/评价维度分类任务选择``Object Detection with Bounding Boxes`
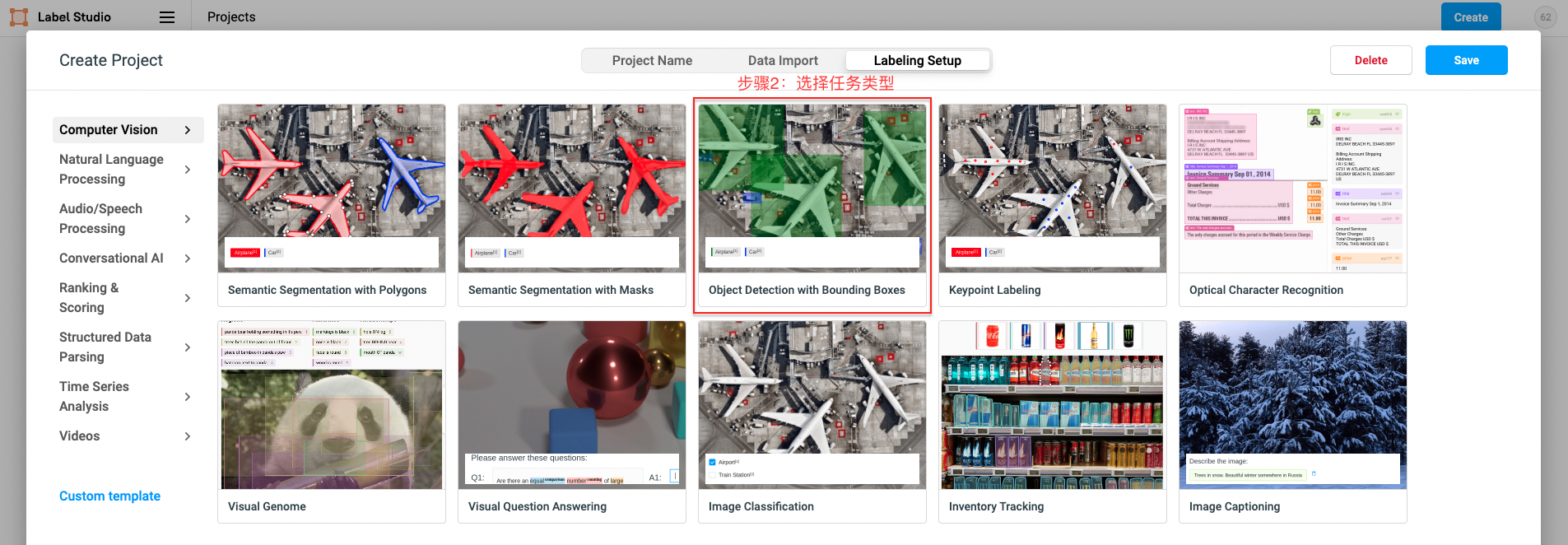
- 文档分类任务选择``Image Classification`
- 添加标签(也可跳过后续在Setting/Labeling Interface中添加)
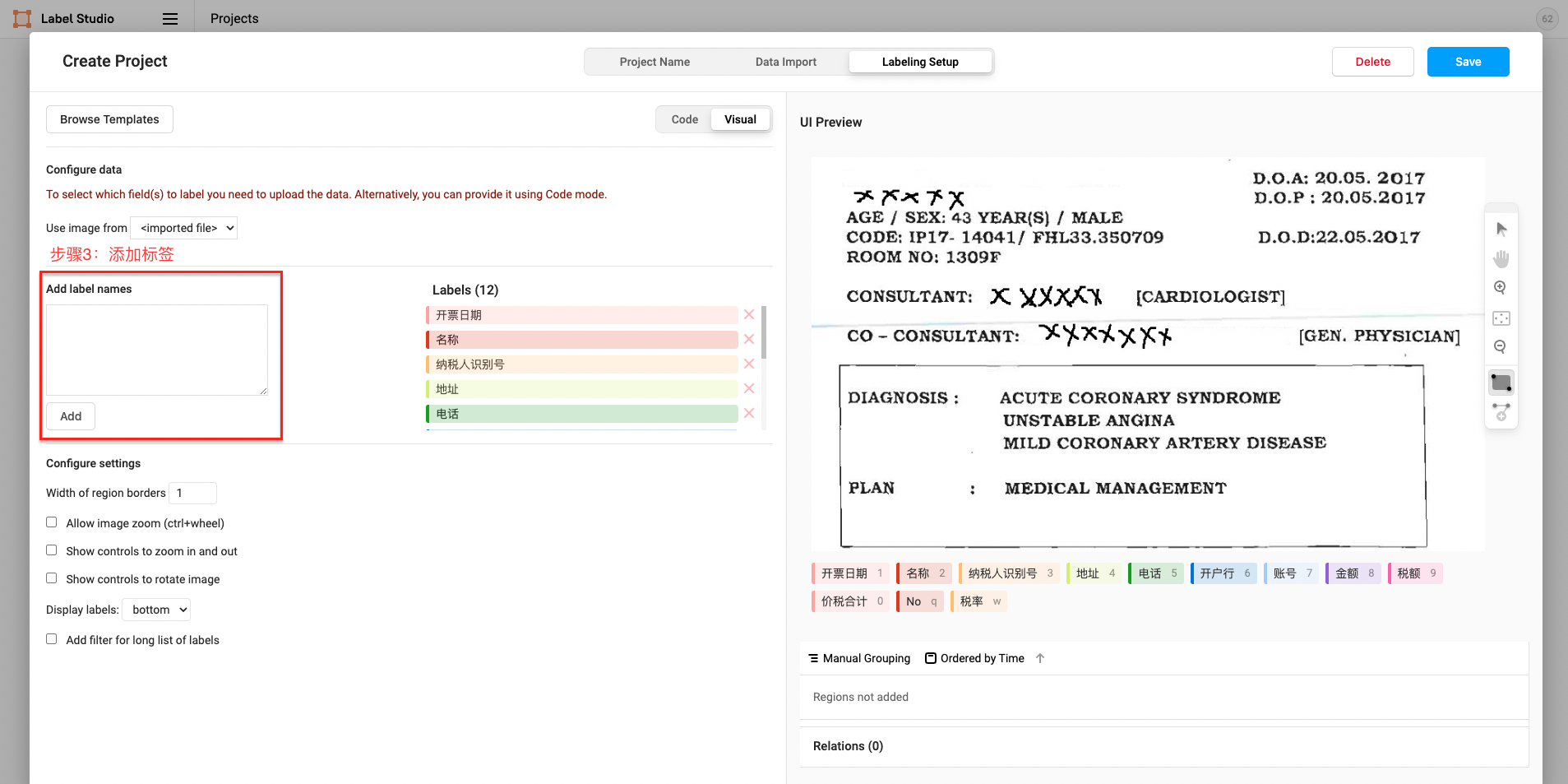
图中展示了Span实体类型标签的构建,其他类型标签的构建可参考2.3标签构建
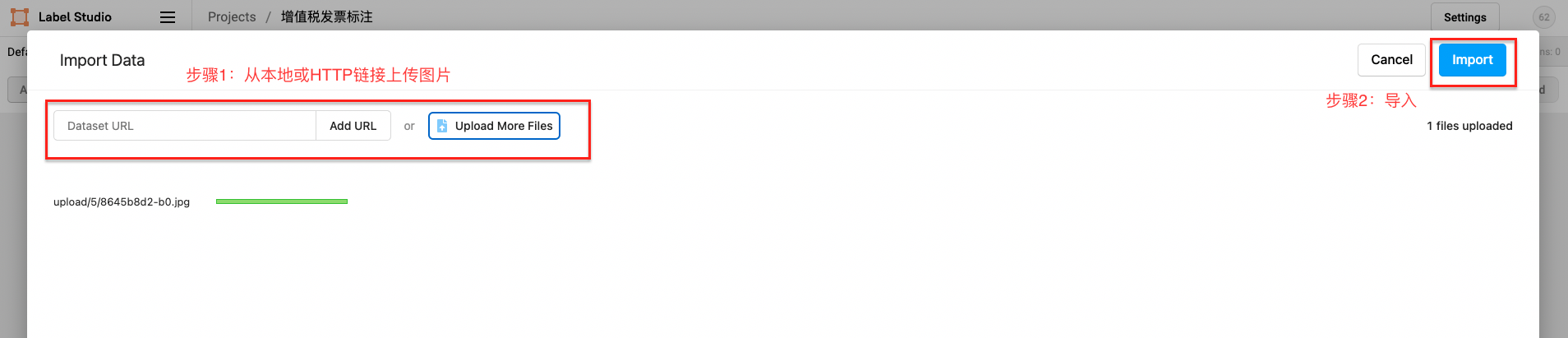
2.2 数据上传
先从本地或HTTP链接上传图片,然后选择导入本项目。
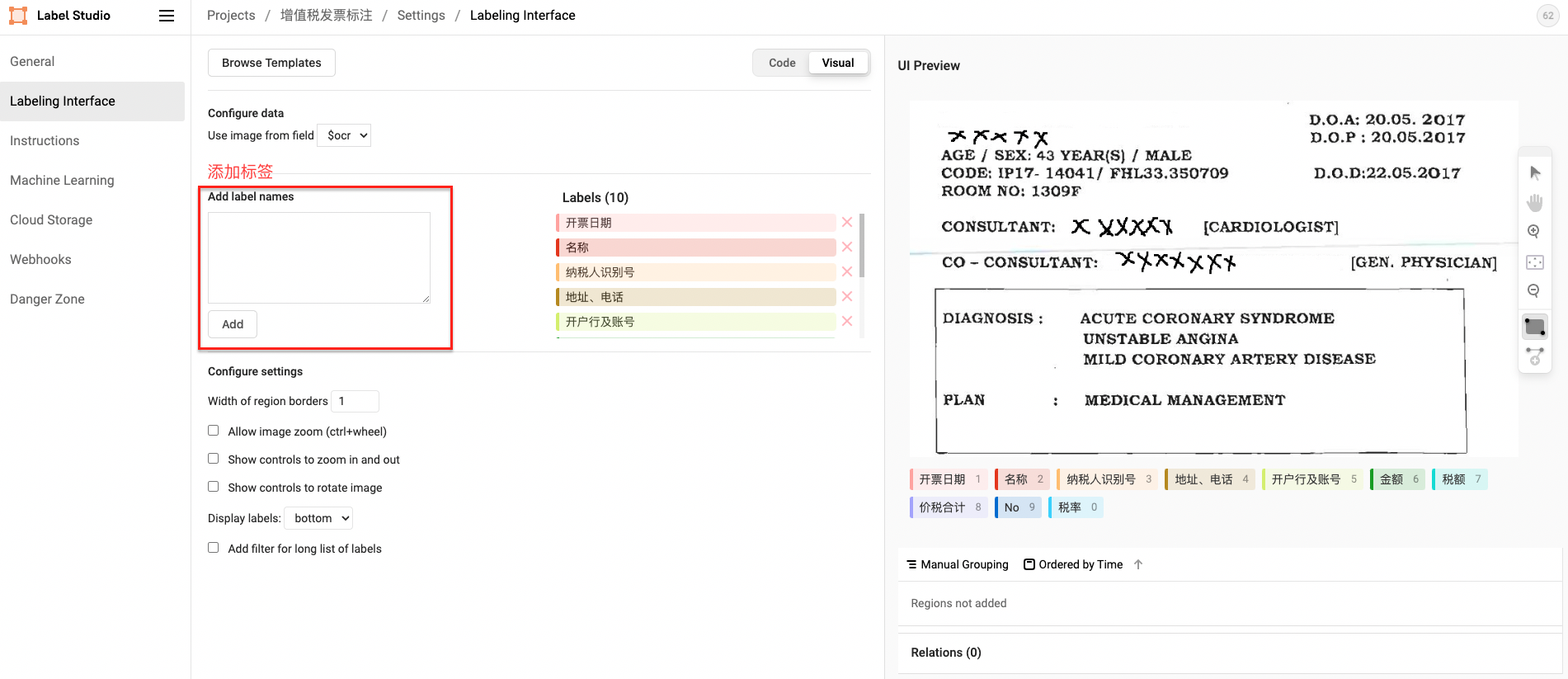
2.3 标签构建
- Span实体类型标签
- Relation关系类型标签
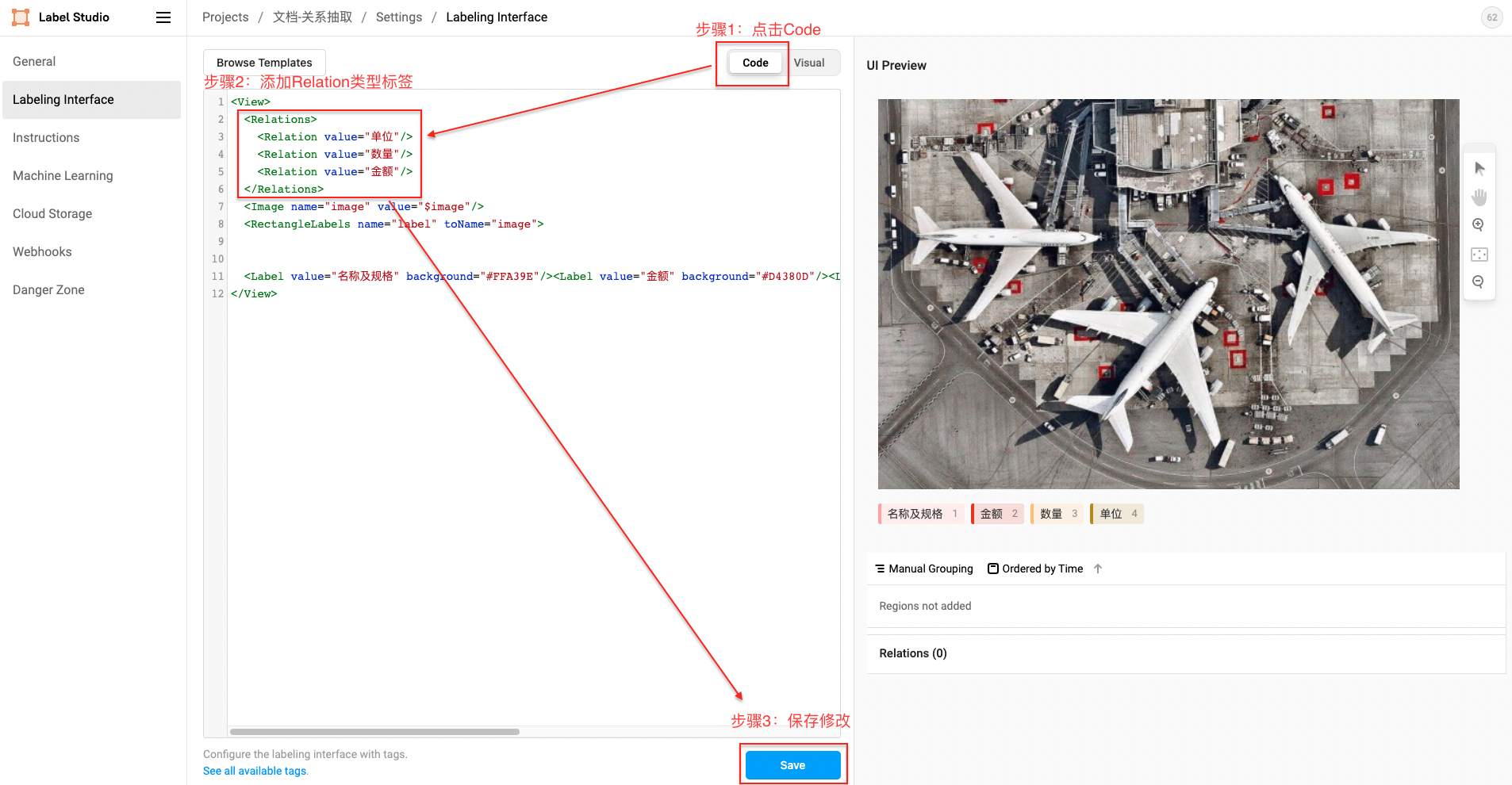
Relation XML模板:
<Relations><Relation value="单位"/><Relation value="数量"/><Relation value="金额"/></Relations>
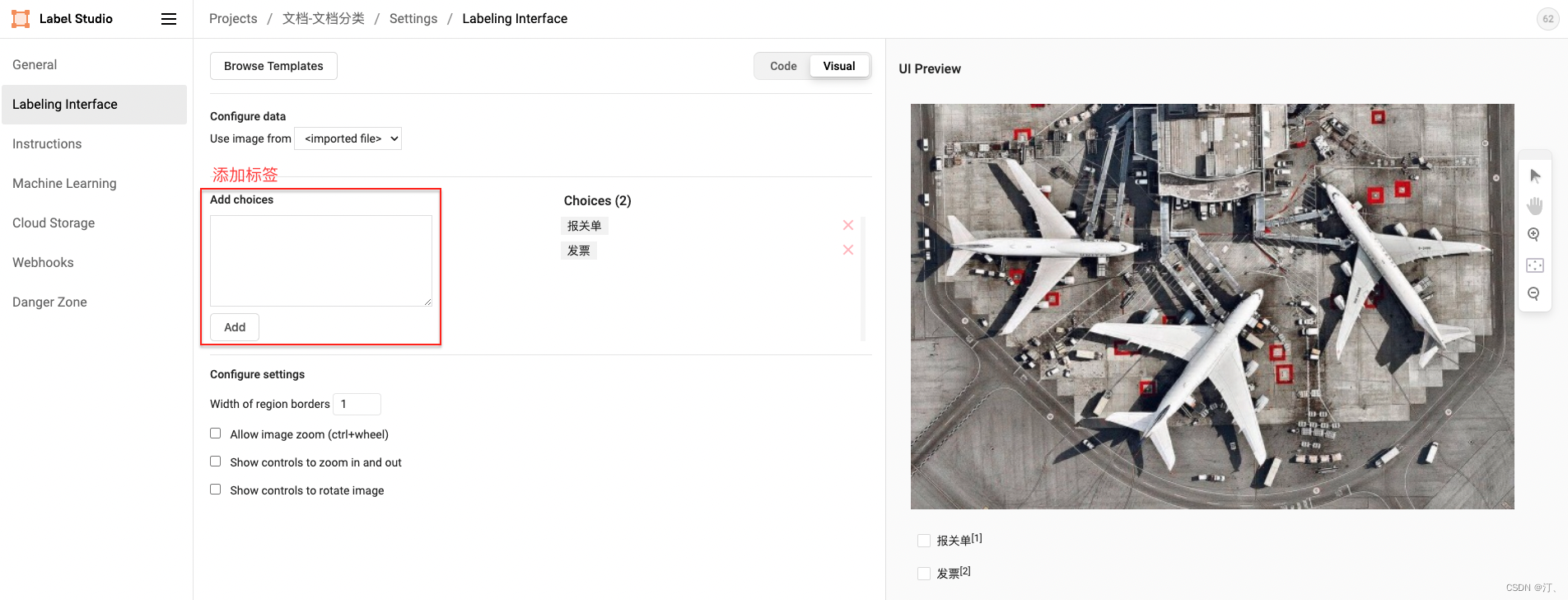
- 分类类别标签
2.4 任务标注
-
实体抽取
-
标注示例:
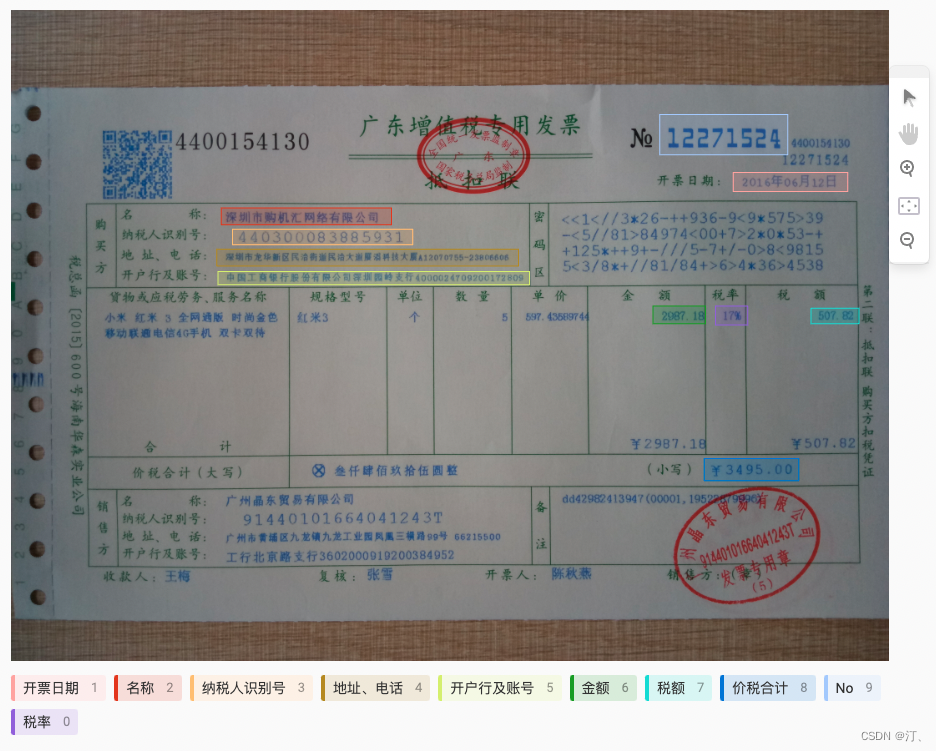
-
该标注示例对应的schema为:
schema = ['开票日期', '名称', '纳税人识别号', '地址、电话', '开户行及账号', '金额', '税额', '价税合计', 'No', '税率']
-
-
关系抽取
-
Step 1. 标注主体(Subject)及客体(Object)

-
Step 2. 关系连线,箭头方向由主体(Subject)指向客体(Object)


-
Step 3. 添加对应关系类型标签


-
Step 4. 完成标注

-
该标注示例对应的schema为:
schema = {'名称及规格': ['金额','单位','数量'] }
-
-
文档分类
-
标注示例

-
该标注示例对应的schema为:
schema = '文档类别[发票,报关单]'
-
2.5 数据导出
勾选已标注图片ID,选择导出的文件类型为JSON,导出数据:

2.6 数据转换
将导出的文件重命名为label_studio.json后,放入./document/data目录下,并将对应的标注图片放入./document/data/images目录下(图片的文件名需与上传到label studio时的命名一致)。通过label_studio.py脚本可转为UIE的数据格式。
- 路径示例
./document/data/
├── images # 图片目录
│ ├── b0.jpg # 原始图片(文件名需与上传到label studio时的命名一致)
│ └── b1.jpg
└── label_studio.json # 从label studio导出的标注文件
- 抽取式任务
python label_studio.py \--label_studio_file ./document/data/label_studio.json \--save_dir ./document/data \--splits 0.8 0.1 0.1\--task_type ext
- 文档分类任务
python label_studio.py \--label_studio_file ./document/data/label_studio.json \--save_dir ./document/data \--splits 0.8 0.1 0.1 \--task_type cls \--prompt_prefix "文档类别" \--options "发票" "报关单"
2.7 更多配置
label_studio_file: 从label studio导出的数据标注文件。save_dir: 训练数据的保存目录,默认存储在data目录下。negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。task_type: 选择任务类型,可选有抽取和分类两种类型的任务。options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为[“正向”, “负向”]。prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。默认为"情感倾向"。is_shuffle: 是否对数据集进行随机打散,默认为True。seed: 随机种子,默认为1000.separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度分类任务有效。默认为"##"。schema_lang:选择schema的语言,将会应该训练数据prompt的构造方式,可选有ch和en。默认为ch。ocr_lang:选择OCR的语言,可选有ch和en。默认为ch。layout_analysis:是否使用PPStructure对文档进行布局分析,该参数只对文档类型标注任务有效。默认为False。
备注:
- 默认情况下 label_studio.py 脚本会按照比例将数据划分为 train/dev/test 数据集
- 每次执行 label_studio.py 脚本,将会覆盖已有的同名数据文件
- 在模型训练阶段我们推荐构造一些负例以提升模型效果,在数据转换阶段我们内置了这一功能。可通过
negative_ratio控制自动构造的负样本比例;负样本数量 = negative_ratio * 正样本数量。 - 对于从label_studio导出的文件,默认文件中的每条数据都是经过人工正确标注的。
References
- Label Studio
- 参考链接
相关文章:
2.基于Label studio的训练数据标注指南:(智能文档)文档抽取任务、PDF、表格、图片抽取标注等
文档抽取任务Label Studio使用指南 1.基于Label studio的训练数据标注指南:信息抽取(实体关系抽取)、文本分类等 2.基于Label studio的训练数据标注指南:(智能文档)文档抽取任务、PDF、表格、图片抽取标注等…...

如何在openKylin操作系统上搭建Qt开发环境
一、获取linux系统下的Qt安装包 Qt官网下载地址:https://download.qt.io 国内镜像下载地址:https://mirrors.cloud.tencent.com/qt/ 。建议用镜像下载速度快。集成安装包在 official_releases/qt 目录下,新地址:https://downloa…...

T_SQL和SQL的区别
一. SQL Server和T-SQL的区别(⭐T-SQL 包含了 SQL)SQL Server是结构化查询语言,是目前关系型数据库管理系统中使用最广泛的查询语言T-SQL是标准SQL语言的扩展,是SQL Server的核心,在SQL的的基础上添加了变量,运算符,函数和流程控制等,Microso…...

用Python自己写一个分词器,python实现分词功能,隐马尔科夫模型预测问题之维特比算法(Viterbi Algorithm)的Python实现
☕️ 本文系列文章汇总: (1)HMM开篇:基本概念和几个要素 (2)HMM计算问题:前后向算法 代码实现 (3)HMM学习问题:Baum-Welch算法 代码实现(…...
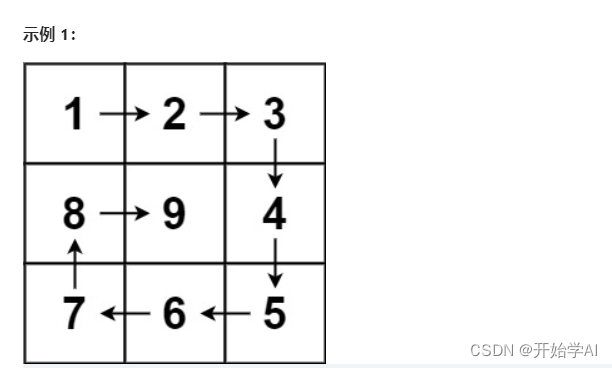
刷题笔记2 | 977.有序数组的平方 ,209.长度最小的子数组 ,59.螺旋矩阵II ,总结
977.有序数组的平方 给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。 输入:nums [-4,-1,0,3,10] 输出:[0,1,9,16,100] 解释:平方后,数组变为 […...
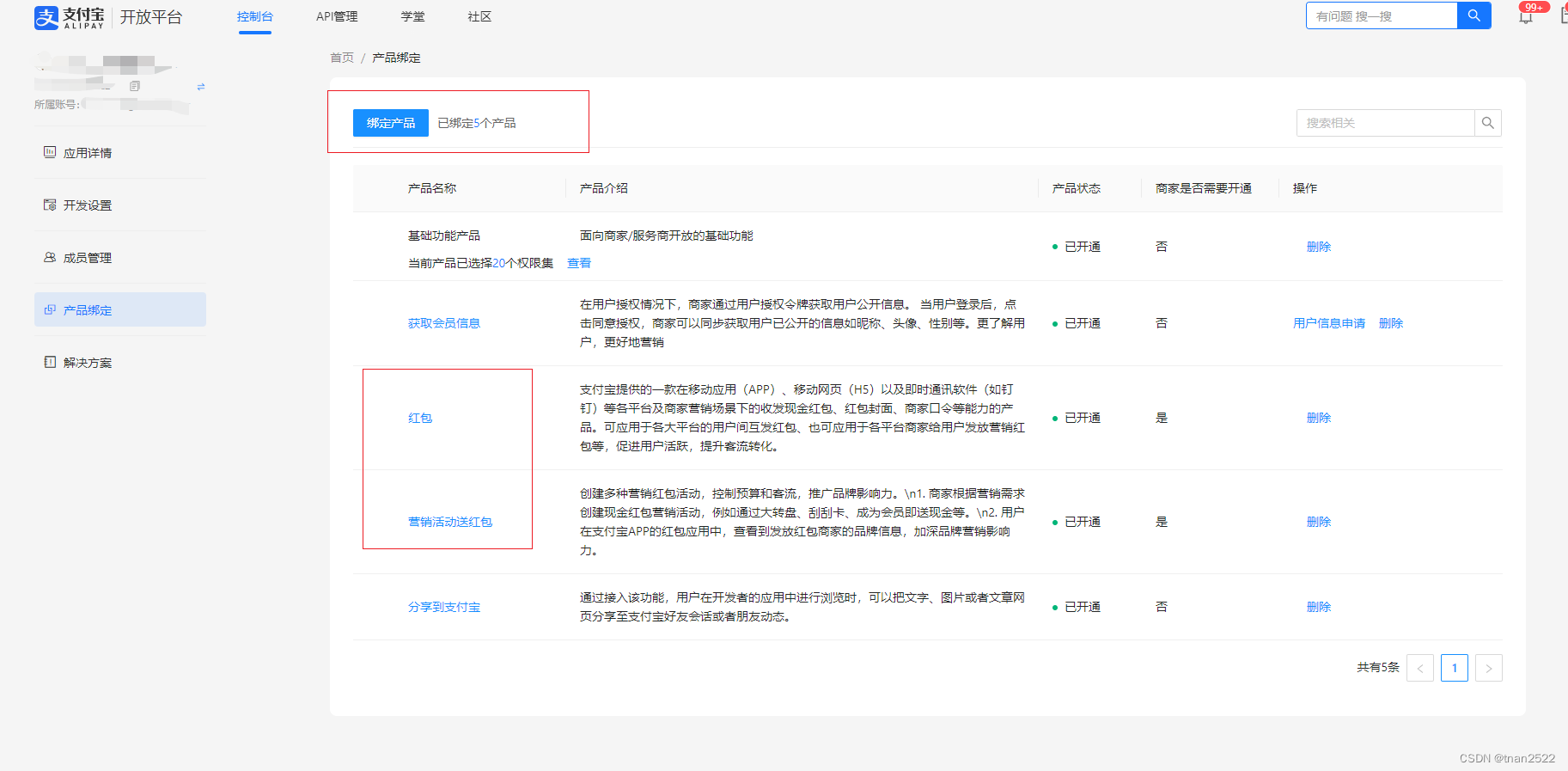
python 支付宝营销活动现金红包开发接入流程-含接口调用加签
1 创建网页/移动应用 2 配置接口加签方式 涉及到金额的需要上传证书,在上传页面有教程, 在支付宝开放平台秘钥工具中生成CSR证书,会自动保存应用公钥和私钥到电脑上,调用支付宝接口需要应用私钥进行加签 上传完CSR证书后会有三个…...

Python操作Windows
用python进行windows端UI自动化的库有很多,比如pywinauto等,本文介绍一个使用autoit3来实现的 pyautoit 库pyautoit 是一个用python写的基于AutoItX3.dll的接口库,用来进行windows窗口的一系列操作,也支持鼠标键盘的操作。安装pip…...
)
Aptos SDK交互笔记(一)
背景 之前我们已经了解TS的一些语法,接下来可以实战训练下,这系列的文章就会介绍如何通过Aptos官网提供的TypeScript SDK与Aptos进行交互,这篇文章主要讲的就是如何使用提供API在aptos区块链上转帐。 官网示例 官网提供了交互的例子&#…...
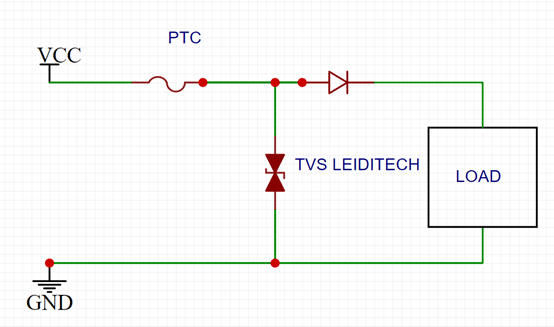
汽车 12V 和 24V 电池输入保护推荐
简介汽车电池电源线路在运行系统时容易出现瞬变。所需的典型保护包括过压、过载、反极性和跨接启动。在汽车 的生命周期中,交流发电机可能会被更换为非OEM 部件。售后市场上的交流发电机可能具有不同的负载突降(LOAD DUMP)保护或没有负载突降…...

龙蜥LoongArch架构研发全揭秘,龙芯开辟龙腾计划技术合作新范式
编者按:在开源新基建加快建设的背景下,越来越多的企业选择加入龙蜥社区,当前社区生态合作伙伴已突破 300 家。于是,龙蜥社区能为加入的企业提供哪些支持成为越多伙伴们更加关注的话题。本文将以龙蜥社区和龙芯中科联合研发龙蜥 Lo…...

剑指 Offer 16. 数值的整数次方
摘要 剑指 Offer 16. 数值的整数次方 本题的方法被称为快速幂算法,有递归和迭代两个版本。这篇题解会从递归版本的开始讲起,再逐步引出迭代的版本。当指数n为负数时,我们可以计算 x^(-n)再取倒数得到结果,因此我们只需要考虑n为…...
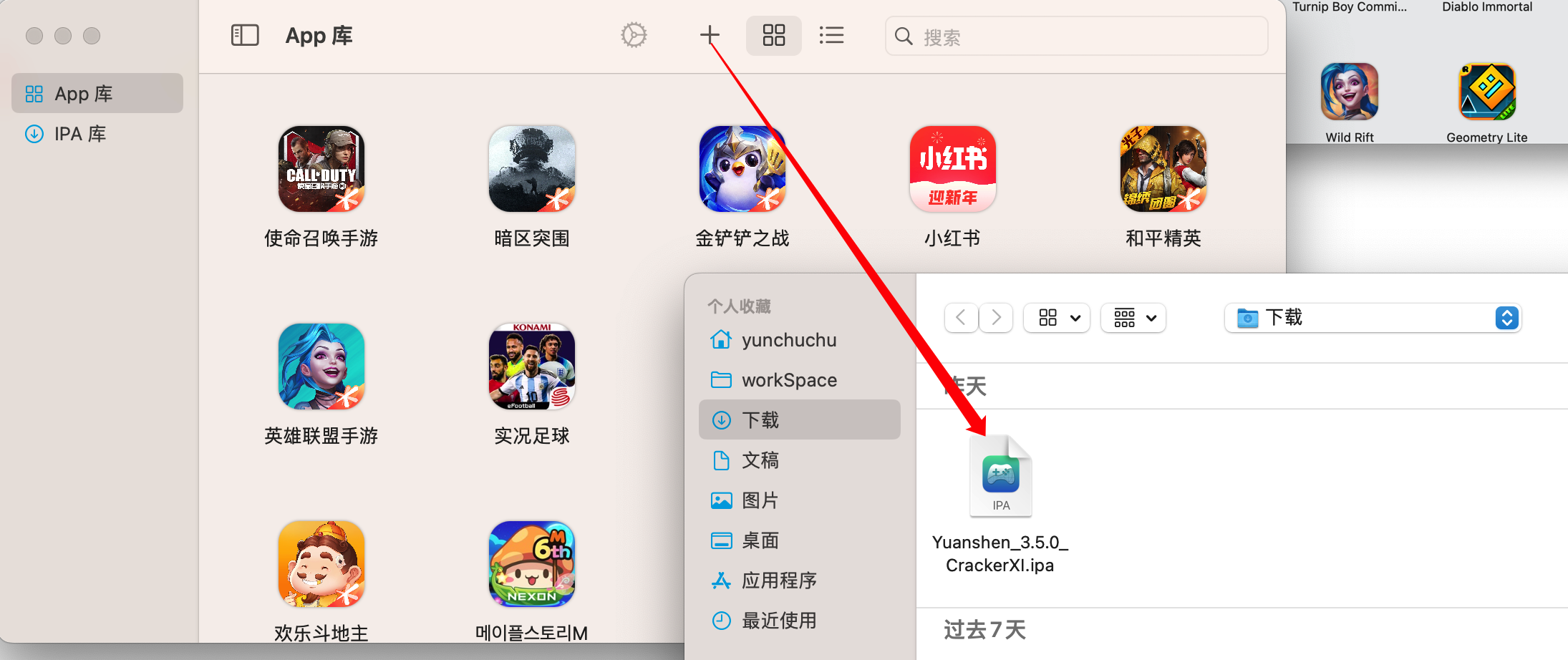
在苹果电脑 mac 上安装原神(playCover)
该方法只能在 M1、M2 mac 上安装原神 目录前言一、首先下载安装 playCover1. playCover 下载2. playCover 安装安装出现问题解决方法二、下载安装原神1.安装包下载2.安装原神三、登录、键盘映射及版本更新等问题登录键盘映射版本更新前言 最近买了新的mac,作者本人…...

数据结构考研习题精选
1 A假设比较t次,由于换或不换,则必然有2^t种可能。又设有n个关键字,n!排列组合,则必然有2^t&…...
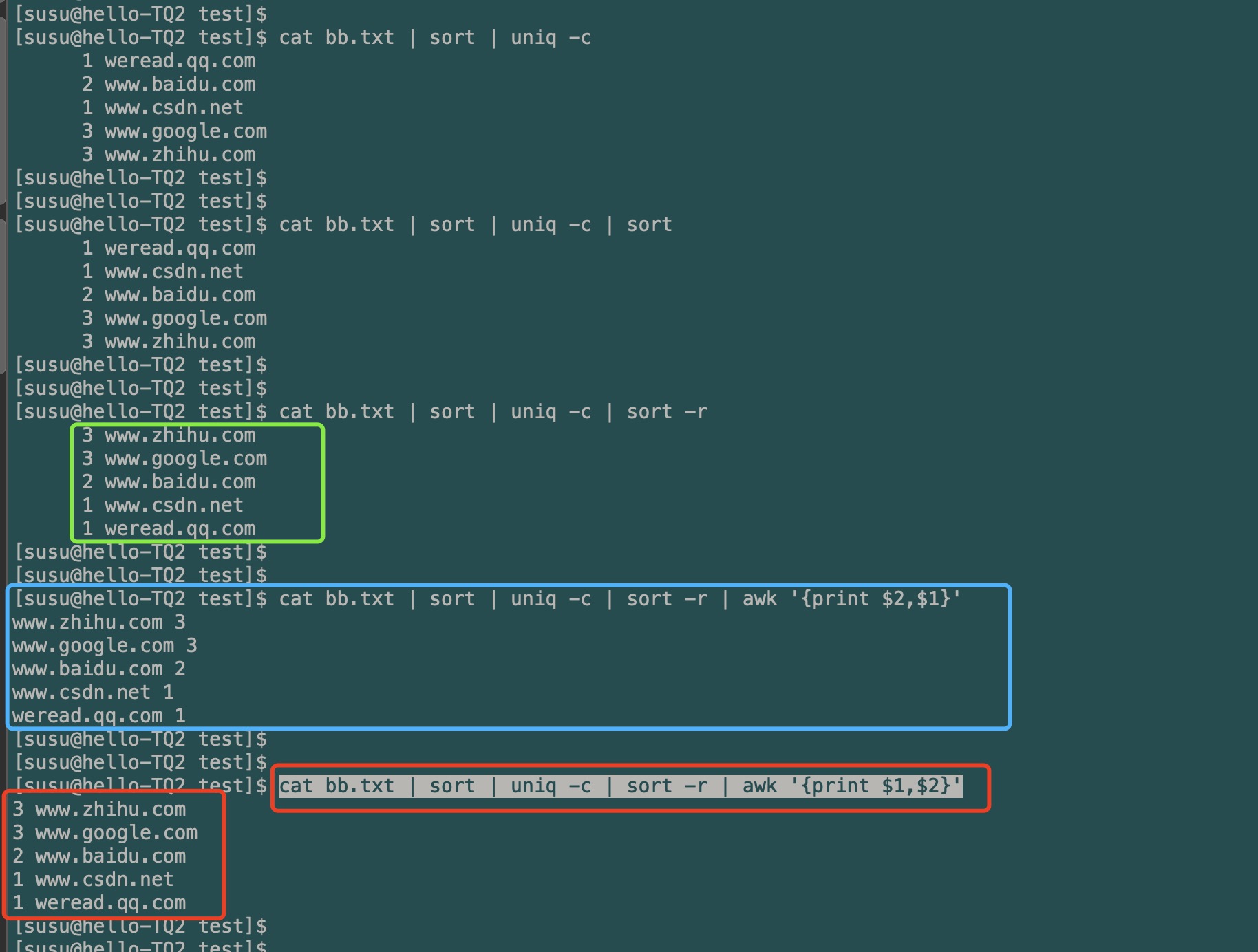
linux常用命令介绍 04 篇——uniq命令使用介绍(Linux重复数据的统计处理)
linux常用命令介绍 04 篇——uniq命令使用介绍(Linux重复数据的统计处理)1. uniq 使用语法2. sort 简单效果3. uniq 使用例子3.1 不加任何选项3.1.1 不用 sort 效果3.1.2 uniq 结合 sort 一起使用3.2 使用选项例子3.2.1 去重打印(或打印不重复…...
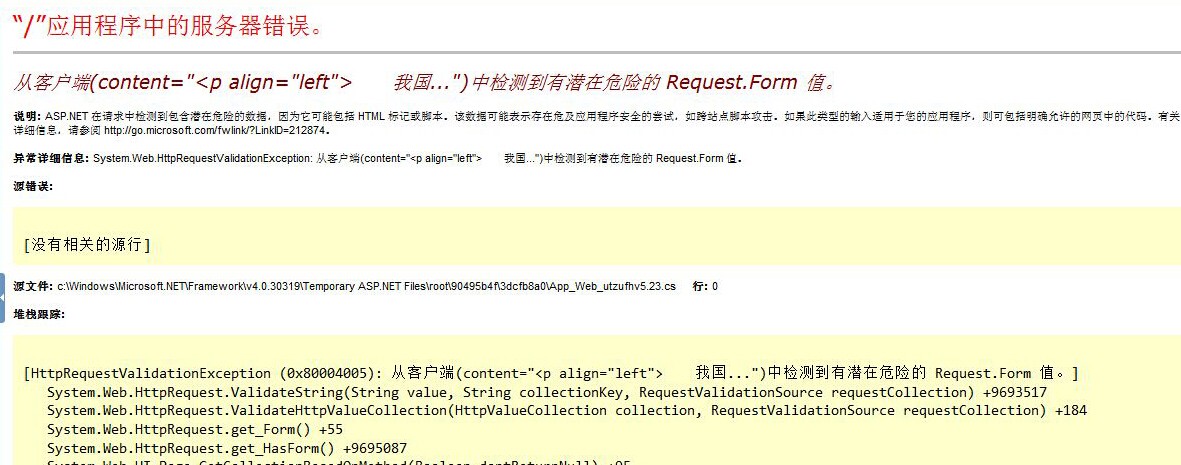
网站打不开数据库错误等常见问题解决方法
1、“主机开设成功!”上传数据后显示此内容,是因为西部数码默认放置的index.htm内容,需要核实wwwroot目录里面是否有自己的程序文件,可以删除index.htm。 2、恭喜,lanmp安装成功!这个页面是wdcp的默认页面&…...

爬虫实战进阶版【1】——某眼专业版实时票房接口破解
某眼专业版-实时票房接口破解 某眼票房接口:https://piaofang.maoyan.com/dashboard-ajax 前言 当我们想根据某眼的接口获取票房信息的时候,发现它的接口处的参数是加密的,如下图: 红色框框的参数都是动态变化的,且signKey明显是加密的一个参数。对于这种加密的参数,我们需要…...

大话数据结构-普里姆算法(Prim)和克鲁斯卡尔算法(Kruskal)
5 最小生成树 构造连通网的最小代价生成树称为最小生成树,即Minimum Cost Spanning Tree,最小生成树通常是基于无向网/有向网构造的。 找连通网的最小生成树,经典的有两种算法,普里姆算法和克鲁斯卡尔算法。 5.1 普里姆ÿ…...
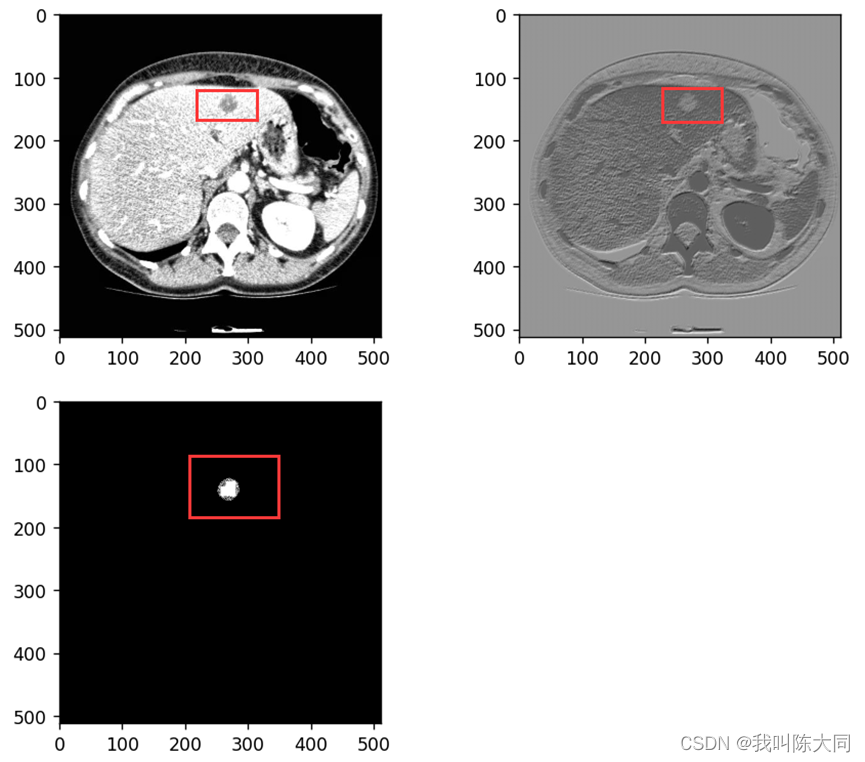
UNet-肝脏肿瘤图像语义分割
目录 一. 语义分割 二. 数据集 三. 数据增强 图像数据处理步骤 CT图像增强方法 :windowing方法 直方图均衡化 获取掩膜图像深度 在肿瘤CT图中提取肿瘤 保存肿瘤数据 四. 数据加载 数据批处理 编辑编辑 数据集加载 五. UNet神经网络模型搭建 单张图片…...

三周爆赚千万 电竞选手在无聊猿游戏赢麻了
如何用3个星期赚到1千万?普通人做梦都不敢想的事,电竞职业选手Mongraal却用几把游戏轻易完成,赚钱地点是蓝筹NFT项目Bored Ape Yacht Club(BAYC无聊猿)出品的新游戏Dookey Dash。 这款游戏类似《神庙逃亡》࿰…...

BERT学习
非精读BERT-b站有讲解视频(跟着李沐学AI) (大佬好厉害,讲的比直接看论文容易懂得多) 写在前面 在计算MLM预训练任务的损失函数的时候,参与计算的Tokens有哪些?是全部的15%的词汇还是15%词汇中真…...

青年教师评副高‘捷径’:这6本被低估的SSCI,认可度不输顶刊!
01 Academic Medicine期刊分区影响因子自引率年文章数教育学1区5.211.5%252篇投稿参考:美国医学院协会(AAMC)官方期刊,审稿周期 2–3 个月,录用率≈20%;可选非 OA 模式免版面费,适合具有实践转…...

APK Installer技术解析与实践指南:Windows平台安卓应用部署的革命性方案
APK Installer技术解析与实践指南:Windows平台安卓应用部署的革命性方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在Windows系统上运行安卓应用一直是…...

别再死记公式了!用复平面几何法直观理解Biquad滤波器设计
用复平面几何法直观理解Biquad滤波器设计 当你第一次接触数字滤波器时,那些复杂的差分方程和z变换公式是否让你望而生畏?作为音频处理领域的入门者,我曾花了整整两周时间试图理解一个简单的二阶滤波器公式,直到发现了复平面几何法…...

谷歌seo搜索引擎优化教程有吗?资深SEO总结的15个高效提速工具
很多企业主每年在独立站开发上投入超过 10 万人民币,但网站上线半年,每天的自然访问量依然是个位数。面对“谷歌seo搜索引擎优化教程有吗?”这种疑问,行业内的真实情况是:绝大部分公开课都在讲十年前的套路,…...

CLion集成LVGL与SDL:打造高效嵌入式GUI模拟开发环境
1. 为什么需要CLionLVGLSDL组合? 如果你正在开发嵌入式设备的图形界面,肯定遇到过这样的困境:每次修改UI都要烧录到硬件上测试,一个简单的颜色调整可能要反复折腾十几分钟。我在开发智能手表项目时就深受其害,直到发现…...

Burpsuite社区版实战指南:从零掌握渗透测试核心模块
1. Burpsuite社区版入门:环境搭建与基础配置 第一次接触Burpsuite时,我被它复杂的界面吓到了——满屏的英文标签、密密麻麻的功能按钮,还有那些看不懂的专业术语。但实际用下来发现,社区版的功能对新手非常友好。先说说下载安装&a…...

从零构建STM32蓝牙遥控车:基于CubeMX与HAL库的硬件驱动与无线通信详解
1. 项目概述与硬件准备 第一次接触STM32蓝牙遥控车项目时,我被这个看似复杂实则有趣的工程深深吸引了。这不仅仅是一个简单的遥控玩具,而是融合了嵌入式开发、无线通信、电机控制等多个技术领域的综合实践。对于初学者来说,完成这个项目能系统…...

网易云音乐NCM格式转换终极指南:ncmdumpGUI轻松解锁你的音乐自由
网易云音乐NCM格式转换终极指南:ncmdumpGUI轻松解锁你的音乐自由 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否遇到过这样的困扰ÿ…...

基于Agent架构的轻量级自托管部署工具Ship实战指南
1. 项目概述:一个为开发者而生的轻量级部署工具最近在折腾一个前后端分离的小项目,从本地开发到服务器部署,中间那套流程真是让人头大。代码提交、构建、测试、再到服务器上拉取、重启服务,一套组合拳下来,少说也得十几…...
)
告别编译迷茫:手把手教你读懂UEFI固件开发中的DSC文件(以EDK2 vUDK2018为例)
告别编译迷茫:手把手教你读懂UEFI固件开发中的DSC文件(以EDK2 vUDK2018为例) 当你第一次打开EDK2项目中的DSC文件时,是否被那些看似杂乱无章的配置项和宏定义搞得晕头转向?作为UEFI固件开发的核心配置文件,…...