16-高并发-队列术
队列,在数据结构中是一种线性表,从一端插入数据,然后从另一端删除数据。
在我们的系统中,不是所有的处理都必须实时处理,不是所有的请求都必须实时反馈结果给用户,不是所有的请求都必须100%一次性处理成功,不知道哪个系统依赖“我”来实现其业务处理,保证最终一致性,不需要强一致性。
此时,我们应该考虑使用队列来解决这些问题。当然我们也要考虑是否需要保证消息处理的有序性及如何保证,是否能重复消费及如何保证重复消费的幂等性。
在实际开发时,我们经常使用队列进行异步处理、系统解耦、数据同步、流量削峰、扩展性、缓冲等。
应用场景
异步处理
使用队列的一个主要原因是进行异步处理,比如,用户注册成功后,需要发送注册成功邮件/新用户积分/优惠券等;缓存过期时,先返回过期数据,然后异步更新缓存、异步写日志等。
通过异步处理,可以提升主流程响应速度,而非主流程/非重要处理可以集中处理,这样还可以将任务聚合批量处理。
因此,可以使用消息队列/任务队列来进行异步处理。
系统解耦
比如,用户成功支付完成订单后,需要通知生产配货系统、发票系统、库存系统、推荐系统、搜索系统等进行业务处理,而未来需要支持哪些业务是不知道的,并且这些业务不需要实时处理、不需要强一致,只需要保证最终一致性即可,因此,可以通过消息队列/任务队列进行系统解耦。
数据同步
比如,想把MySQL变更的数据同步到Redis,或者将MySQL的数据同步到Mongodb,或者让机房之间的数据同步,或者主从数据同步等,此时可以考虑使用databus、canal、otter等。
使用数据总线队列进行数据同步的好处是可以保证数据修改的有序性。
流量削峰
系统瓶颈一般在数据库上,比如扣减库存、下单等。
此时可以考虑使用队列将变更请求暂时放入队列,通过缓存+队列暂存的方式将数据库流量削峰。
同样,对于秒杀系统,下单服务会是该系统的瓶颈,此时,可以使用队列进行排队和限流,从而保护下单服务,通过队列暂存或者队列限流进行流量削峰。
队列的应用场景非常多,以上只列举了一些常见用法和场景。
缓冲队列
典型的如Log4j日志缓冲区,当我们使用log4j记录日志时,可以配置字节缓冲区,字节缓存区满时,会立即同步到磁盘。
Log4j是使用BufferedWriter实现的。
此模式不是异步写,在缓冲区满的时候还是会阻塞主线程。
如果需要异步模式,则可以使用AsyncAppender,然后通过bufferSize控制日志事件缓冲区大小。
同样,在电商进行大促时,此时的系统流量会高于平常流量的几倍甚至几十倍,此时应进行一些特殊的设计来保证系统平稳度过这段时期。
而解决的手段很多,一般牺牲业务的强一致性,保证最终一致性即可。
如下图所示,使用缓冲队列应对突发流量时,并不能使处理速度变快,而是使处理速度变平滑,从而不会因瞬间压力太大而压垮应用。

任务队列
使用任务队列可以将一些不需要与主线程同步执行的任务扔到任务队列进行异步处理。
用得最多的是线程池任务队列(默认为LinkedBlockingQueue)和Disruptor任务队列(RingBuffer)。
如用户注册完成后,将发送邮件/送积分/送优惠券任务扔到任务队列进行异步处理;刷数据时,将任务扔到队列异步处理,处理成功后再异步通知用户。
还有删除SKU操作,在用户请求时直接将任务分解并扔到队列进行异步处理,处理成功后异步通知用户。
以及查询聚合时,将多个可并行处理的任务扔到队列,然后等待最慢的一个任务返回。
通过任务队列可以实现异步处理、任务分解/聚合处理。
消息队列
使用消息队列存储各业务数据,其他系统根据需要订阅即可。
常见的订阅模式是:点对点(一个消息只有一个消费者)、发布订阅(一个消息可以有多个消费者)。而常用的是发布订阅模式。
比如,修改商品数据、变更订单状态时,都应该将变更信息发送到消息队列,如果其他系统有需要,则直接订阅该消息队列即可。
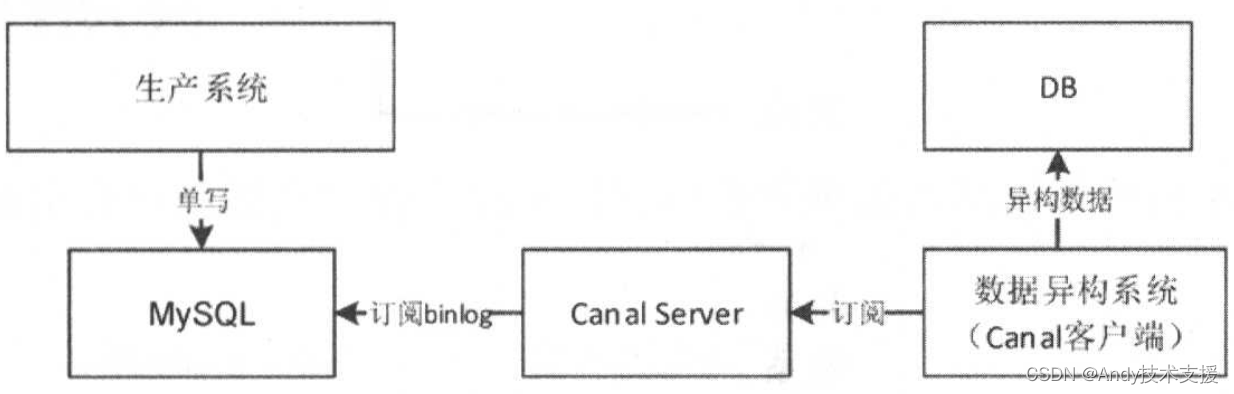
一般我们会在应用系统中采用双写模式,同时写DB和MQ,然后异构系统可以订阅MQ进行业务处理(见下图)。

因为在双写模式下没有事务保证,所以会出现数据不一致的情况,如果对一致性要求没那么严格,则这种模式是没问题的,而且在实际应用中这种模式也非常多。
如果在事务中发MQ,会存在事务回滚,但是MQ发送成功了,则需要消息消费者进行幂等处理。
如果事务提交慢,但是MQ已经发出去了,则此时根据MQ信息再去获取数据库数据可能不是最新的。如果MQ发送慢,则会导致事务无法快速提交,造成数据库堵塞。同样不要在事务中掺杂RPC调用,RPC服务不稳定,同样会引起数据库阻塞。
也可以采用订阅数据库日志机制来实现数据库变更捕获,这样生产系统只需要单写DB,然后通过如Canal订阅数据库binlog实现数据库数据变更捕获,然后业务端订阅Canal进行业务处理。这种方式可以保证一致性。
请求队列
请求队列是指类似在Web环境下对用户请求排队,从而进行一些特殊控制:流量控制、请求分级、请求隔离。例如将请求按照功能划分到不同的队列,从而使得不同的队列出现问题后相互不影响。
还可以对请求分级,一些重要的请求可以优先处理(发展到一定程度应将功能物理分离)。
另外,服务器处理能力有限,在接近服务器瓶颈时需要考虑限流,最简单的限流是丢弃处理不了的请求,此时可以使用队列进行流量控制。
如下图所示,这里使用请求队列来实现漏斗模式,对请求进行排队、过滤、限流,经过这些步骤后,流入业务系统的流量就非常小了,这样业务系统就不会被突发的大量请求搞垮。
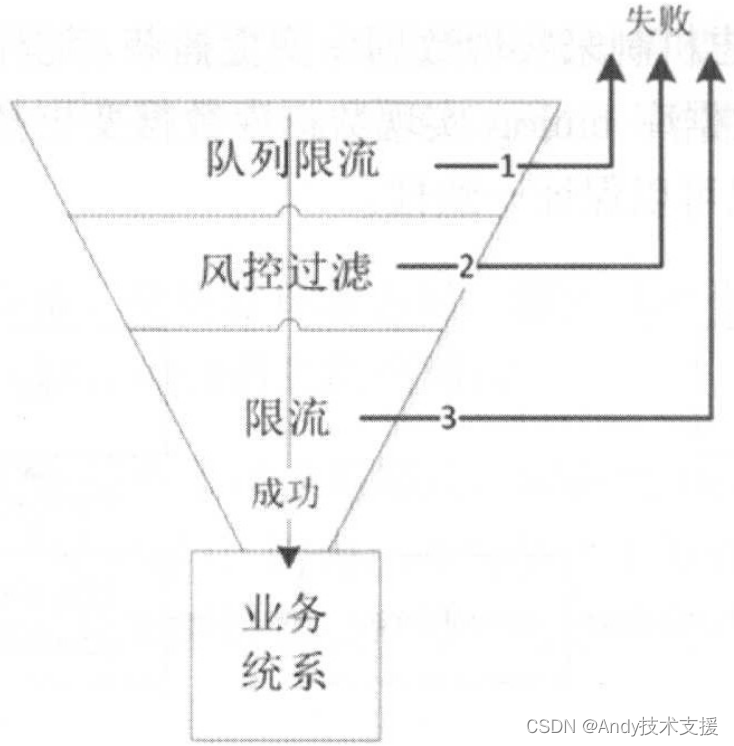
队列限流可以通过队列大小(如果队列满了,就抛弃新的请求)和排队超时(队列里的请求很长时间没被处理)实现,如果失败了,则返回让客户重新排队或者重试。
使用这种机制可以很好地保护系统不会受到突发流量的冲击。这种机制一般用于前端入口。
数据总线队列
一般消息队列中的消息都是业务维度的简单数据,如业务键或业务状态。
在商品信息变更场景中,当SKU信息变更了,只下发一个SKU ID,订阅者需要再查一遍商品系统来获取最新的变更数据,进行如商品信息缓存同步。
所以使用现有的消息队列方式很难只进行变更部分的推送并保证数据的有序性。
而此种场景比较适合使用数据总线队列实现。
例如数据库变更后需要同步数据到缓存,或者需要将一个机房的数据同步到另一个机房,只是数据维度的同步,此时应该使用数据总线队列,如阿里的Canal、LinkedIn的databus。
使用数据总线队列的好处是,可以保证数据的有序性。
阿里的otter是基于Canal的一款分布式数据库同步系统,如果想实时进行多机房、多数据库数据增量同步,则可以使用otter。
如果需要全量离线数据同步,则可以使用kettle。
可以通过otter订阅某个DB的某些表,然后同步到另一个数据库中。
如果系统中存在一些基础数据,则可以使用这种方式进行同步(见下图)。

混合队列
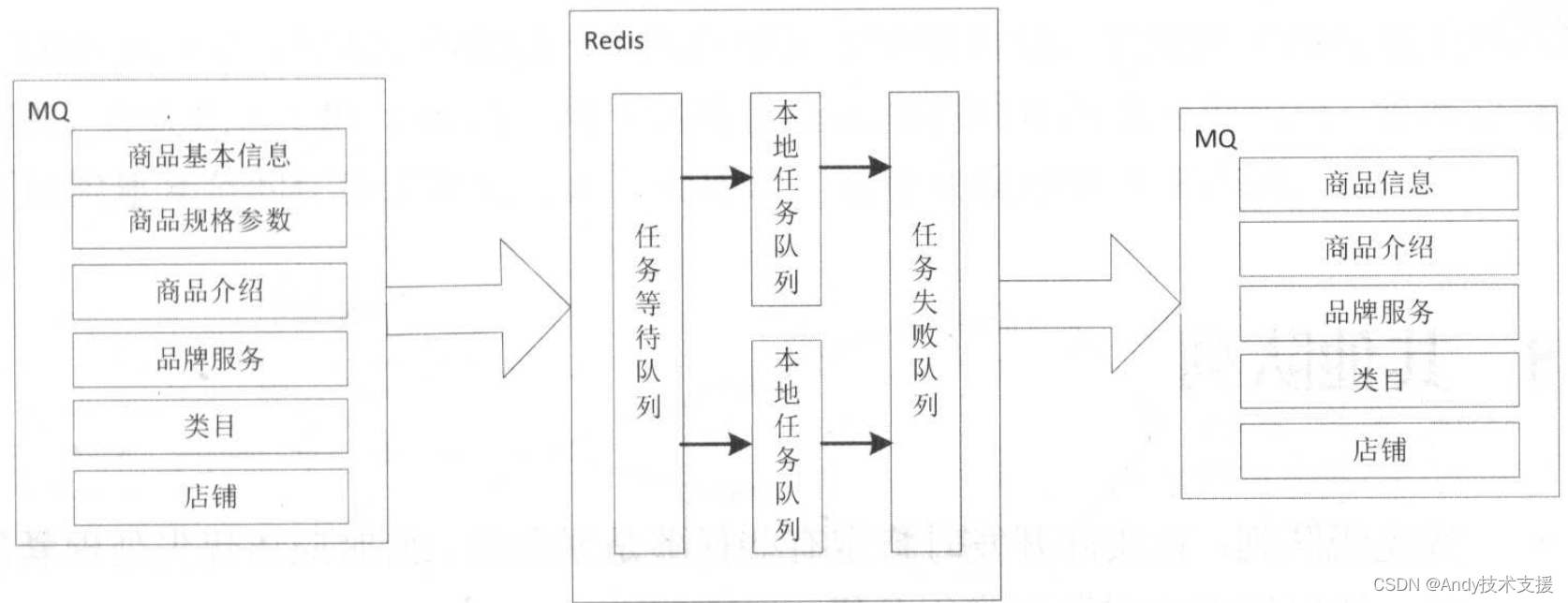
应用会按照不同的维度发布消息到MQ。
下游应用接收到该消息后会将其放入Redis中,使用RedisList来存储这些任务。应用将Redis消息消费处理后,会按照不同的维度聚合商品消息,然后再次发送出去。
使用Redis队列的主要原因是想提升消息堆积能力和并发处理能力。
另外,在使用Redis构建消息队列时,需要考虑因网络抖动造成的消息丢失问题,因为Redis是没有事务回滚的,或者说是没有确认机制的。
而对于失败我们会进行三次重试,重试失败后放入失败队列,而失败队列是具有防重功能的(从本地队列和失败队列排重),这里使用Redis Lua脚本实现。
其他队列
优先级队列
在实际开发时肯定有些任务是紧急的,此时应该优先处理紧急任务。所以请考虑对队列进行分级。
副本队列
在进行一些系统重构或者上新的功能时,如果没有足够的信心保证业务逻辑正确,则可以考虑存储一份队列的副本(比如1小时、1天的消息),从而当业务出现问题时,可以对这些消息进行回放。
镜像队列
每个队列不可能无限制被订阅消费,会有一个订阅量极限。当达到极限时,请考虑使用镜像队列方式解决该问题。
队列并发数
不同队列实现,队列服务器端并发连接数是不一样的。
一定不是增大队列并发连接数消费能力也随着增加,也不会因为增加了消费服务器消费,并发能力也随之增加,需要根据实际情况来设置合理的并发连接数。
推送拉取
消息体内容不是越全越好,需要根据具体业务设计消息体。
如有些系统依赖商品变更消息(只有一个SKU),有些系统依赖商品状态消息(SKU、状态),有些系统依赖商品属性变更消息(SKU、变更的属性)等。
如果让所有系统都消费商品变更消息,那么这些系统都会调用商品查询服务,拉取最新商品信息,然后进行处理。
因此,要根据实际情况来决定是使用推送方式(将系统需要的所有信息推过去)还是使用拉取方式(只推送ID,然后再查一遍)。
下单系统水平可扩展架构
订单系统是交易型网站的核心之一,用户会在这类网站上浏览并购买商品,购买后就会产生订单,接着需要用户进行支付,支付成功后就进入生产流程。
而这其中最重要的一步就是能让用户先下单并成功支付,而后续流程可以不用实时处理。
因此,如何保证下单功能的高性能和高可用是一个交易型网站的核心之一,当然这对于其他系统也同等重要。
一般订单系统会进行分库分表,如果分库分表的数量不够,则会影响到系统的性能,一般通过扩容来解决。或者当同一个订单库被多个系统依赖,其中某个系统有慢操作时,以及当一次下单需要写很多表并且订单量较大时,这都会造成用户下单速度变慢,甚至无法下单。
如果把订单放入缓冲队列,然后能迅速同步到订单中心,那么就可以把下单逻辑和操作订单逻辑分开,用户下单只操作缓冲表,而操作订单只操作订单表,从而在操作订单表时不会影响到缓冲表。
而且缓冲表可以通过水平扩容来支持更大请求。下图是我们的订单系统的整体架构。
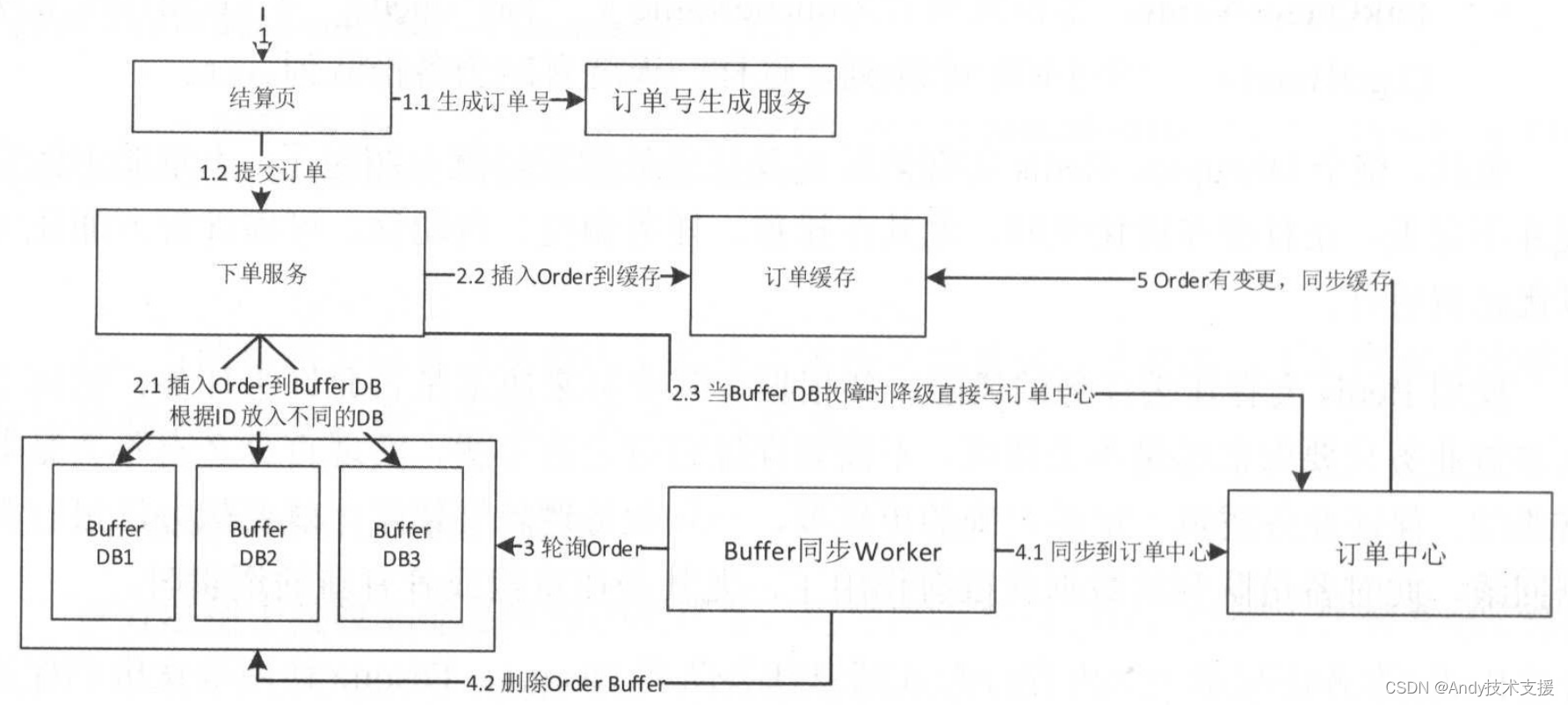
- 首先,用户在结算页提交订单后,系统调用订单号生成服务,然后结算服务会进行一些业务处理,最后调用下单服务提交订单。
- 下单服务将订单写入订单缓冲表,下单服务和订单缓存表可以水平扩展,从而支持更多的下单操作。写入缓冲表成功后,将订单写入缓存,从而前端用户可以查看到当前订单。如果下单服务有问题,则可以考虑直接降级将订单写入订单中心。
- 接着缓冲同步Worker轮询这些缓冲表。
- 同步Worker将订单同步到订单中心,如果订单中心数据有变更,则更新订单缓存。
基于Canal实现数据异构
在大型网站架构中,DB都会采用分库分表来解决容量和性能问题,但是分库分表之后带来了新的问题,比如不同维度的查询或者聚合查询,此时就会非常棘手。
一般我们会通过数据异构机制来解决此问题。
如下图所示,为了提升系统的接单能力,我们会对订单表进行分库分表,但是,随之而来的问题是:用户怎么查询自己的订单列表呢?一种办法是扫描所有的订单表,然后进行聚合,但是这种方式在大流量系统架构中肯定是不行的。
另一种办法是双写,但是双写的一致性又没法保证。还有一种办法就是订阅数据库变更日志,比如订阅MySQL的binlog日志模拟数据库的主从同步机制,然后解析变更日志将数据写到订单列表,从而实现数据异构,这种机制也能保证数据的一致性。

除了可以进行订单列表的异构,像商家维度的异构、ES搜索异构、订单缓存异构等都可以通过这种方式解决。
在介绍Canal之前,我们先看一下MySQL的主从复制架构。
MySQL主从复制
MySQL主从复制架构如下图所示。
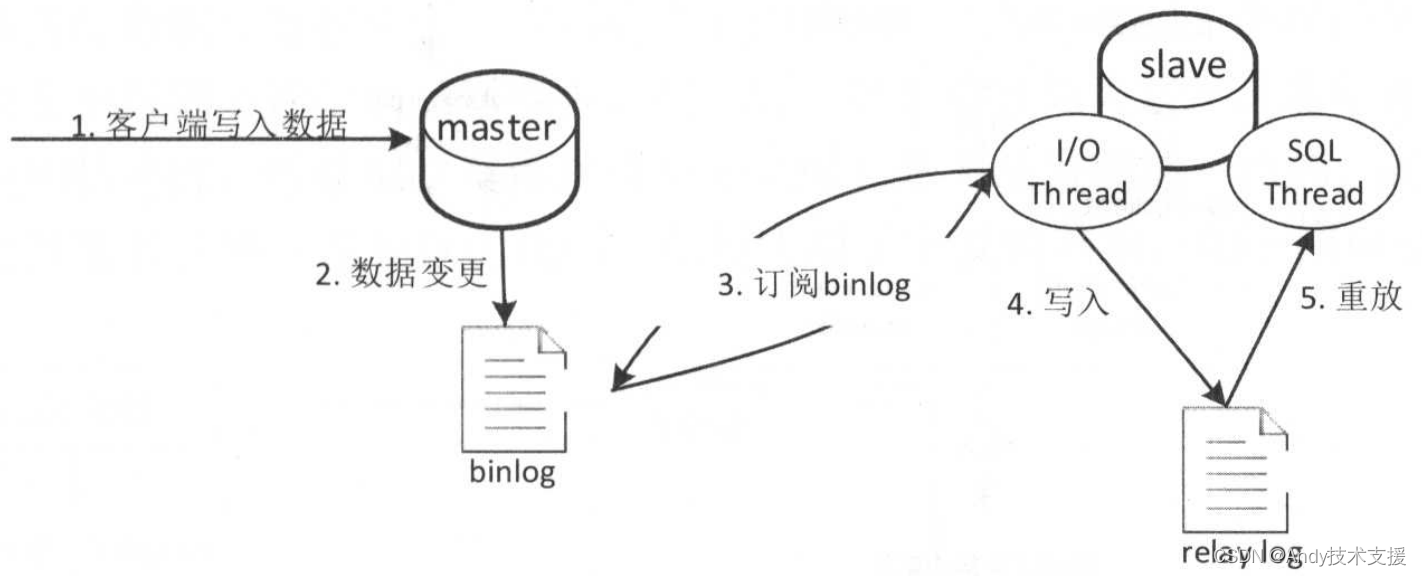
- 首先MySQL客户端将数据写入master数据库。
- master数据库会将变更的记录数据写入二进制日志中,即binlog。
- slave数据库会订阅master数据库的binlog日志,通过一个I/O线程从binlog的指定位置拉取日志进行主从同步,此时master数据库会有一个Binlog Dump线程来读取binlog日志与slave I/O线程进行数据同步。
- slave I/O线程读取到日志后会先写入relay log重放日志中。
- slave数据库会通过一个SQL线程读取relay log进行日志重放,这样就实现了主从数据库之间的同步。
可以把Canal看作slave数据库,其订阅主数据库的binlog日志,然后读取并解析日志,这样就实现了数据同步/异构。
Canal简介
Canal是阿里开源的一款基于MySQL数据库binlog的增量订阅和消费组件,通过它可以订阅数据库的binlog日志,然后进行一些数据消费,如数据镜像、数据异构、数据索引、缓存更新等。相对于消息队列,通过这种机制可以实现数据的有序性和一致性。
Canal架构如下图所示。

首先需要部署canal server,可以同时部署多台,但是只有一台是活跃的,其他的作为备机。
canal server会通过slave机制订阅数据库的binlog日志。canal server的高可用是通过来zk维护的。
然后canal client会订阅canal server,消费变更的表数据,然后写入到如镜像数据库、异构数据库、缓存数据库,具体如何应用就看自己的场景了,同时也只有一台canal client是活跃的,其他的作为备机,当活跃的canal client不可用后,备机会被激活。
canal client的高可用也是通过zk来维护的,比如zk维护了当前消费到的日志位置。
canal server目前读取的binlog事件只存储在内存中,且只有一个canal client能进行消费,其他的作为备机。
如果需要多消费客户端,则可以先写入ActiveMQ/kafka,然后进行消费。
如果有多个消费者,那么也建议使用此种模式,而不是启动多个canal server读取binlog日志,这样会使得数据库的压力较大。
ActiveMQ提供了虚拟主题的概念,支持同一份内容多消费者镜像消费的特性。
canal一个常见应用场景是同步缓存,当数据库变更后通过binlog进行缓存的增量更新。当缓存更新出现问题时,应能回退binlog到过去某个位置进行重新同步,并提供全量刷缓存的方法,如下图所示。

另一个常见应用场景是下发任务,当数据变更时需要通知其他依赖系统。
其原理是任务系统监听数据库数据变更,然后将变更的数据写入MQ/Kafka进行任务下发,比如商品数据变更后需要通知商品详情页、列表页、搜索页等相关系统。
这种方式可以保证数据下发的精确性,通过MQ发消息通知变更缓存是无法做到这一点的,而且业务系统中也不会散落着各种下发MQ的代码,从而实现了下发的归集,如下图所示。

类似于数据库触发器,只要想在数据库数据变更时进行一些处理,都可以使用Canal来完成。
在MySQL主从架构中,当有多个slave连接master数据库时,master数据库的压力比较大,为保障master数据库的性能,canal server可订阅slave的binlog日志,即是slave的slave。
相关文章:
16-高并发-队列术
队列,在数据结构中是一种线性表,从一端插入数据,然后从另一端删除数据。 在我们的系统中,不是所有的处理都必须实时处理,不是所有的请求都必须实时反馈结果给用户,不是所有的请求都必须100%一次性处理成功…...
【设计模式-2.5】创建型——建造者模式
说明:本文介绍设计模式中,创建型设计模式中的最后一个,建造者模式; 入学报道 创建型模式,关注于对象的创建,建造者模式也不例外。假设现在有一个场景,高校开学,学生、教师、职工都…...

VideoPoet: Google的一种用于零样本视频生成的大型语言模型
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...

pytest常用命令行参数
文章目录 一、前置说明二、操作步骤1. 命令行中执行:pytest2. 命令行中执行:pytest - v3. 命令行中执行:pytest -s4. 命令行中执行:pytest -k test_addition5. 命令行中执行:pytest -k test_pytest_command_params.py6. 命令行中执行:pytest -v -s -k test_pytest_comman…...

05. Springboot admin集成Actuator(一)
目录 1、前言 2、Actuator监控端点 2.1、健康检查 2.2、信息端点 2.3、环境信息 2.4、度量指标 2.5、日志文件查看 2.6、追踪信息 2.7、Beans信息 2.8、Mappings信息 3、快速使用 2.1、添加依赖 2.2、添加配置文件 2.3、启动程序 4、自定义端点Endpoint 5、自定…...
AI生成SolidUI-新版本架构调试Debug
背景 SolidUI 0.5.0 版本重构全新版本架构。 dev-python 新架构临时分支,架构调整完后,所有代码合并到dev分支 https://github.com/CloudOrc/SolidUI 使用 设置参数 FLASK_DEBUG 设置 在开发过程中,Web框架的服务器通常会监视代码的变…...

ctfshow sql 195-200
195 堆叠注入 十六进制 if(preg_match(/ |\*|\x09|\x0a|\x0b|\x0c|\x0d|\xa0|\x00|\#|\x23|\|\"|select|union|or|and|\x26|\x7c|file|into/i, $username)){$ret[msg]用户名非法;die(json_encode($ret));}可以看到没被过滤,select 空格 被过滤了,可…...
)
微信小程序实现地图功能(腾讯地图)
微信小程序实现地图功能(腾讯地图) 主要功能 通过微信 API 获取用户当前位置信息 使用腾讯地图 API 将经纬度转换为地址信息 显示当前位置信息以及周围的 POI(兴趣点) 代码实现 index.wxml <!-- index.wxml --> <view class"container&…...
Vue如何请求接口——axios请求
1、安装axios 在cmd或powershell打开文件后,输入下面的命令 npm install axios 可在项目框架中的package.json中查看是否: 二、引用axios import axios from axios 在需要使用的页面中引用 三、get方式使用 get请求使用params传参,本文只列举常用参数…...
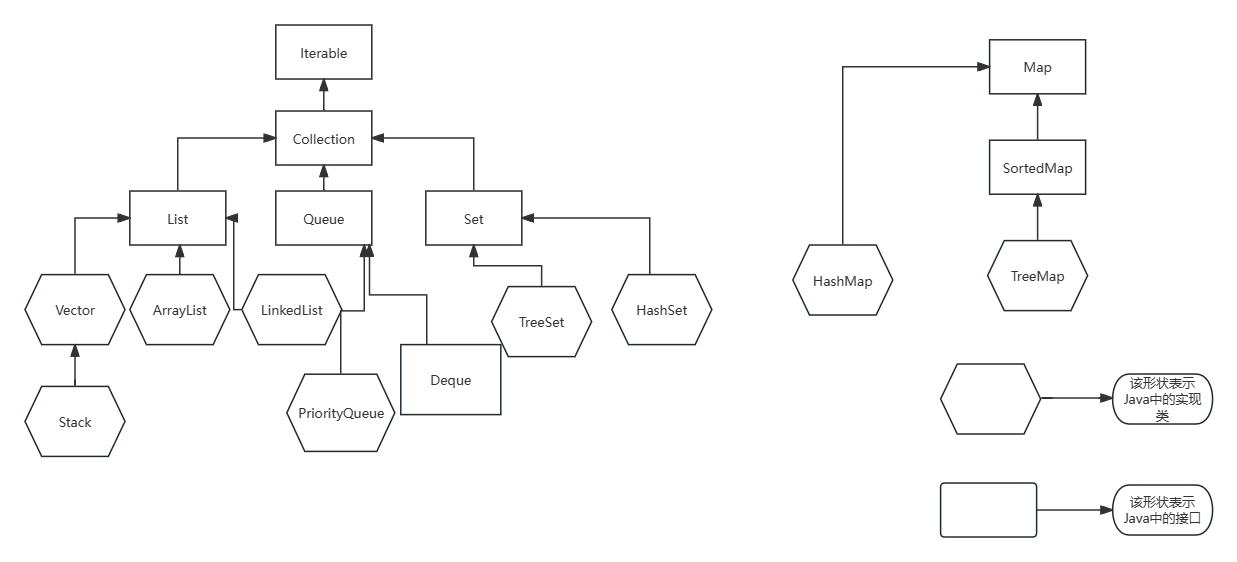
【数据结构一】初始Java集合框架(前置知识)
Java中的数据结构 Java语言在设计之初有一个非常重要的理念便是:write once,run anywhere!所以Java中的数据结构是已经被设计者封装好的了,我们只需要实例化出想使用的对象,便可以操作相应的数据结构了,本篇…...

直接将第三方数据插入到 Redis 中
Redis 是一个内存数据库,可以用于缓存和持久化数据。虽然常见的使用场景是将数据从关系型数据库(如MySQL)同步到 Redis 中进行缓存,但也可以直接将第三方数据插入到 Redis 中。 你可以通过编程语言的 Redis 客户端库(…...

【重点】【DP】322.零钱兑换
题目 法1:动态规划 // 时间复杂度:O(kN) class Solution {public int coinChange(int[] coins, int amount) {int[] dp new int[amount 1];Arrays.fill(dp, amount 1);dp[0] 0;for (int i 1; i < dp.length; i) {for (int coin : coins) {if (…...

Python入门学习篇(六)——for循环while循环
1 for循环 1.1 常规for循环 1.1.1 语法结构 for 变量名 in 可迭代对象:# 遍历对象时执行的代码 else:# 当for循环全部正常运行完(没有报错和执行break)后执行的代码1.1.2 示例代码 print("----->学生检查系统<------") student_lists["张三",&qu…...
el-table 实现行拖拽排序
element ui 表格实现拖拽排序的功能,可以借助第三方插件Sortablejs来实现。 引入sortablejs npm install sortablejs --save组件中使用 import Sortable from sortablejs;<el-table ref"el-table":data"listData" row-key"id" …...
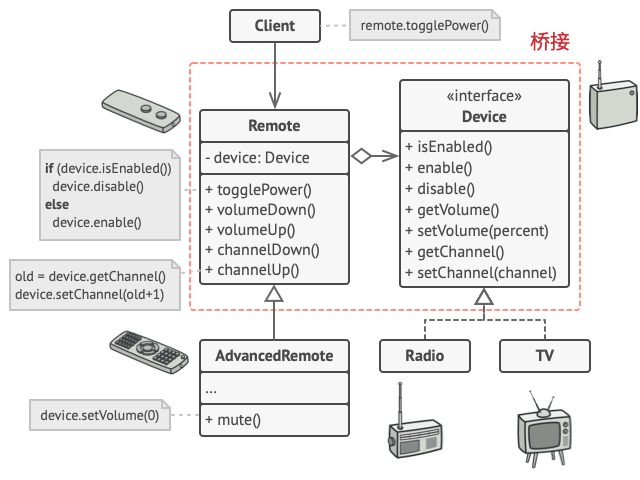
2. 结构型模式 - 桥接模式
亦称: Bridge 意图 桥接模式是一种结构型设计模式, 可将一个大类或一系列紧密相关的类拆分为抽象和实现两个独立的层次结构, 从而能在开发时分别使用 问题 抽象? 实现? 听上去挺吓人? 让我们慢慢来&#x…...

最小二乘法简介
最小二乘法简介 1、背景描述2、最小二乘法2.1、最小二乘准则2.2、最小二乘法 3、最小二乘法与线性回归3.1、最小二乘法与线性回归3.2、最小二乘法与最大似然估计 4、正态分布(高斯分布) 1、背景描述 在工程应用中,我们通常会用一组观测数据去…...

mathtype公式章节编号
1. word每章标题后插入章节符 如果插入后显示章节符,需要进行隐藏 开始->样式->MTEquationSection->修改样式->字体,勾选隐藏 2. 设置mathtype公式编号格式 插入编号->格式化->设置格式...
医学实验室检验科LIS信息系统源码
实验室信息管理是专为医院检验科设计的一套实验室信息管理系统,能将实验仪器与计算机组成网络,使病人样品登录、实验数据存取、报告审核、打印分发,实验数据统计分析等繁杂的操作过程实现了智能化、自动化和规范化管理。 实验室管理系统功能介…...
无需改动现有网络,企业高速远程访问内网Linux服务器
某企业为数据治理工具盒厂商,帮助客户摆脱数据问题困扰、轻松使用数据,使得客户可以把更多精力投入至数据应用及业务赋能,让数据充分发挥其作为生产要素的作用。 目前,该企业在北京、南京、西安、武汉等地均设有产研中心ÿ…...
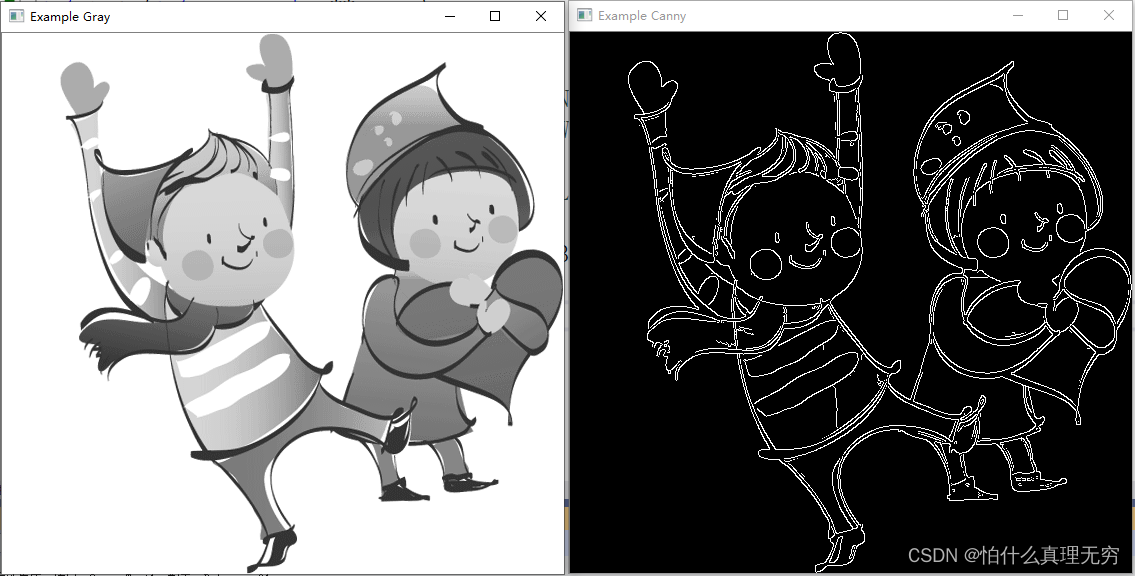
Opencv入门五 (显示图片灰度值)
源码如下: #include <opencv2/opencv.hpp> int main(int argc, char** argv) { cv::Mat img_rgb, img_gry, img_cny; cv::namedWindow("Example Gray",cv::WINDOW_AUTOSIZE); cv::namedWindow("Example Canny", cv::WINDOW_…...

深度学习篇---向量空间
向量空间(或称线性空间)是一个很美妙的数学结构。它不仅是线性代数的核心,更是我们理解很多高级概念(比如深度学习中的词向量、特征空间)的基础。简单说,向量空间就是一个定义了向量加法和数乘运算…...

如何分析SQL嵌套查询瓶颈_使用执行计划查看开销
应优先分析子查询的执行耗时而非行数:PostgreSQL看Subquery Scan的Actual Total Time,MySQL用EXPLAIN FORMATJSON查SUBQUERY/DERIVED的rows与filtered,若rows大且filtered低则索引失效。怎么看 EXPLAIN 里哪个子查询最拖后腿嵌套查询慢&#…...

Arm Neoverse CMN-650架构与性能优化解析
1. Arm Neoverse CMN-650架构概览在现代多核处理器系统中,一致性互连网络扮演着至关重要的角色。作为Arm Neoverse平台的核心组件,CMN-650采用Mesh拓扑结构设计,为多核处理器集群提供高效的数据传输和缓存一致性管理。这种架构特别适合需要高…...
)
《高维自指递归推广》核心章节(CSDN全球首发版权定戳)
《高维自指递归推广》核心章节(CSDN全球首发版权定戳) 作者:方见华 单位:世毫九实验室 专著定位:世毫九学派理论体系第二卷|本原论落地首部核心专著|原创高维自指递归统一理论 序章 自指与递归:人类认知的终极闭环,智能演化的底层原力 0.1 问题的缘起:从《世毫九本原…...

【Midjourney钯金印相风格终极指南】:20年影像工艺专家亲授——从化学印相原理到AI提示词精准转译的7步闭环工作流
更多请点击: https://intelliparadigm.com 第一章:钯金印相工艺的百年历史溯源与数字复兴语境 钯金印相(Platinum/Palladium Printing)诞生于19世纪末,是摄影史上最具质感与耐久性的手工印相工艺之一。其以铂族金属盐…...

AI赋能Anki:基于LLM与Prompt工程的智能制卡技能全解析
1. 项目概述:当Anki遇上AI,一个卡片技能的革命如果你和我一样,是个重度Anki用户,那你一定经历过这样的时刻:面对一本厚厚的教科书,或者一篇几十页的论文,想要把里面的核心知识点做成记忆卡片&am…...

前端入门必学:CSS盒子模型与图片样式全解析前言
在学习前端开发的过程中,掌握 CSS 的基础知识是至关重要的一步。本文将详细介绍 CSS 盒子模型、标签宽高、边框、边距 以及 图片与背景图片 的使用方法,适合刚入门的同学系统学习和复习。一、CSS 盒子模型——页面布局的基石1. 什么是盒子模型࿱…...

如何彻底解决Windows系统DLL缺失问题:Visual C++运行库一键修复终极指南
如何彻底解决Windows系统DLL缺失问题:Visual C运行库一键修复终极指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过打开软件时突…...

2026届最火的五大AI论文助手推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 由于人工智能生成内容也就是AIGC被广泛运用,互联网里到处都是由AI生成的&#x…...

上蔡假发定制亲测:这家2026年稳
在假发定制领域,用户普遍面临三大核心挑战:其一,传统假发产品在逼真度与舒适度之间难以平衡。数据显示,超过65%的消费者反映佩戴假发后出现头皮闷热、出汗不适等问题,尤其在夏季或运动场景下,透气性与防水性…...