推荐算法架构7:特征工程(吊打面试官,史上最全!)
系列文章,请多关注
推荐算法架构1:召回
推荐算法架构2:粗排
推荐算法架构3:精排
推荐算法架构4:重排
推荐算法架构5:全链路专项优化
推荐算法架构6:数据样本
推荐算法架构7:特征工程
1 概述
特征工程[1](Feature Engineering)是推荐算法的基础,它对收集到的原始数据进行解析和变换,从而提取出模型所需要的信息。通过挖掘丰富和高质量的特征,并对其进行合理的处理,可以提升模型预估准确度,从而提升推荐系统业务效果。特征工程是一项需要重点掌握的技术。
本文先讲解特征类目体系,分析推荐系统中一般会有哪些特征。然后讲解特征处理范式,分析如何对特征进行离散化、归一化、池化和缺失值填充等处理。最后讲解特征重要性评估,从而提升特征可解释性,并对其进行筛选,以及进一步挖掘更多高质量特征。特征工程的技术架构如图1所示。
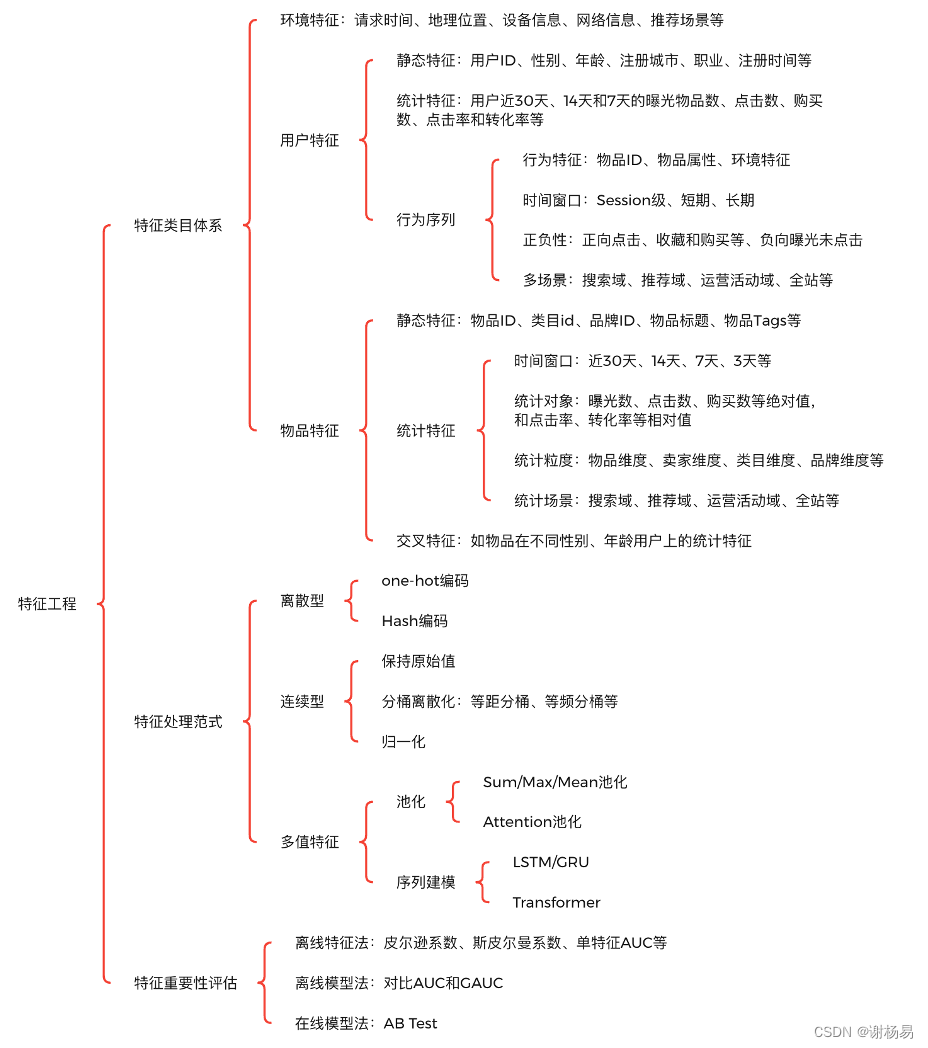
图1 特征工程技术架构
2 特征类目体系
掌握特征类目体系,有利于提升特征丰富度,完善特征工程体系。在具体的业务场景中,可以将自己想象为一个真实用户,思考哪些特征对用户点击和转化有比较大的影响。深度学习赋予了特征自动交叉的能力,降低了对领域知识的要求,但不代表不需要加强业务理解能力。
一般来说主要包括环境特征(Context Feature)、用户特征(User Feature)和物品特征(Item Feature)三大类。环境特征一般需要用户授权才能获取,不同业务场景所需的环境特征会有一定区别,可以枚举如下:
-
请求时间:如请求发生在周几,是否节假日,发生在几点,当前季节等。
-
地理位置:如用户当前所在的国家、省份、城市,以及当地天气和温度等。
-
设备信息:如手机机型、手机厂商、操作系统(Android/IOS)等。
-
网络信息:如运营商渠道、网络类型(WIFI/5G/4G)等。
-
客户端信息:如请求渠道(APP/小程序/H5/PC等)、APP版本号等
-
推荐场景:如首页推荐、相关推荐、详情页推荐等
用户特征通常也称用户画像,主要包括用户静态特征、统计特征和行为序列特征三大类,一般也需要用户授权才能获取和使用。用户特征有利于提高个性化分发能力,可以枚举如下:
-
静态特征:如用户ID、性别、年龄、注册城市、职业、注册时间、是否VIP、是否新用户、是否已婚,以及是否有小孩等。静态特征通常区分度很高,是推荐系统中的强信号。比如不同性别和年龄的用户,其兴趣差异会很大。是否有小孩,会直接决定用户是否对母婴类目商品有兴趣。静态特征一般很少变动,适用范围广,可以应用到多个不同业务场景中。其难点在于不好收集,需要用户主动提供且授权,才能使用。另外一般需要加密存储,防止用户隐私信息泄露。
-
统计特征:如用户近30天、14天和7天的曝光物品数、点击数、购买数、点击率和转化率等。统计特征包括绝对值和相对值两大类,绝对值用来刻画流量信息,相对值则可以刻画效率信息。相对值需要注意其置信度,例如“曝光数2次、点击数1次”,和“曝光数200次、点击数100次”两组特征,点击率虽然同为0.5,但前者置信度明显不足。统计特征大多为后验特征,经过了真实场景充分验证,对模型帮助很大。最后需要注意的是,统计特征容易出现数据穿越问题,生产时要小心。例如构造天级样本时,千万不要把当天的统计数据也计算进去了。
-
行为序列特征:目前,针对用户行为序列特征的研究很多,它是当前算法模型效果提升的关键。一个历史行为,可以包括被行为(如被点击)物品的ID,还可以包括其类目ID、品牌ID和卖家ID等物品属性特征,以及历史行为距离当前时间间隔等环境特征。按时间窗口划分,有Session级行为序列、短期行为序列和长期行为序列。按用户反馈正负性划分,有点击、购买和收藏等正反馈序列,和曝光未点击等负反馈序列。构建全面而丰富的用户行为序列,可以充分挖掘用户兴趣,有利于提升模型效果和用户体验。
物品特征主要包括物品静态特征、统计特征和交叉特征三大类。物品是推荐这一行为的实体,充分挖掘其特征有助于筛选出高质量,且用户喜欢的物品。物品特征可以枚举如下:
-
静态特征:如物品ID、类目ID、品牌ID、卖家ID、价格、标题和上架时间等。其在不同场景下有一定的区别,比如电商场景和短视频场景。这些特征可由机器识别、运营标注和卖家(或创作者)填写等多种方式产出。
-
统计特征:如物品近30天、14天和7天的曝光数、点击数、购买数、点击率和转化率等。统计特征可以表征物品的热度、质量和转化效率等信息,重要性很高。按时间窗口划分,有近30天、近14天、近7天和近3天等构造方法。按统计对象划分,有曝光数、点击数、购买数等绝对值,和点击率、转化率等相对值。按统计粒度划分,既可以统计物品本身数据,还可以统计物品的卖家、对应类目、对应品牌的各项数据。按统计场景划分,可以对推荐、搜索、运营活动和全站等多个场景分别统计。跟用户侧一样,物品统计特征也要注意数据穿越问题。
-
交叉特征:物品与用户交叉特征,比如物品在不同性别、年龄用户上的统计特征。有利于挖掘物品在不同人群上的流量和效率表现情况,缓解“辛普森悖论”问题,从而让个性化分发更准确。虽然深度模型可以实现自动特征交叉,但交叉不一定充分。另外交叉特征是强信号特征,可以降低模型学习难度,从而让它将精力用在其他更需要学习的地方。因此,手工构造关键的交叉特征,目前仍然有重要意义。一般来说,用户特征与物品特征间交叉,比用户特征之间,或物品特征之间交叉,更为重要。
3 特征处理范式
收集到原始特征后,还需要进一步进行离散化、归一化、池化和缺失值填充等处理,才能输入到模型中。特征处理有助于让模型学习更高效,更鲁棒,因此同样十分重要。针对不同类型的特征,会有不同的处理方法。特征类型主要有离散型、连续型和多值特征三大类。
离散型特征,一般也称为类别型特征,如物品ID、类目ID和品牌ID等。类别型特征枚举值多,区分度高,是推荐系统中的强信号。而且大多是静态特征,不需要后验数据,冷启动效果好。离散型特征主要有如下处理方法:
-
one-hot编码:每个类别为一个二进制向量,向量中每个维度代表一个类别取值,只有一个维度的值为1,其余均为0。one-hot编码简单易用,是机器学习中经常采用的编码方法。但当特征类别值较多时,会遇到“维度灾难”问题。
-
Hash编码:利用Hash函数,对原始值进行变换和降维。有较强的压缩能力,特别适合于类别值很多的特征。同时其计算速度很快,额外开销小。但有一定概率会将不同原始值Hash为同一值,存在Hash冲突问题,可能影响算法准确度。另外Hash编码会导致原始值难以识别,可解释性降低。
连续型特征,如用户侧和物品侧的各项统计特征。它可以有效表征用户活跃度、物品质量、物品转化效率等信息,因此十分重要。另外很多连续型特征同时也是后验特征,经过了大量真实用户检验,可以提升模型预估准确性。连续型特征主要有如下处理方法:
-
保持原始值:可以将连续型特征,直接与类别型特征的Embedding编码向量,拼接起来,然后输入到模型中。DeepCrossing[2]等早期深度模型通常采用这一方案。它操作简单,容易实现,但泛化能力差,且容易受异常值影响。
-
分桶离散化:目前常用的方法,利用预先定义的分桶边界值,将连续值归入对应桶内。这种方法有利于提升模型泛化能力,降低过拟合问题,同时对异常值不敏感,因此应用十分广泛。有等距分桶和等频分桶等多种具体实现方式,一般来说正样本等频分桶效果较好。分桶法的缺点是位于分桶边界附近的数值,即使差距很小,也有可能会被归入不同的桶内。最后,分桶法需要注意尽量让每个桶内都有充足样本,且样本不要集中于个别桶内。
-
归一化:有最大最小值归一化、对数函数转换、区间缩放法等多种方法。归一化有利于降低个别特征的主导地位,让模型学习更平稳,并加快收敛速度。
多值特征,最典型的就是用户行为序列,以及用户Tag、物品Tag和物品标题等特征。推荐系统中,绝大多数的特征都是单值的,比如用户性别和年龄。但有部分特征是数组等多值形式,比如物品标题由多个字组成,用户行为序列由多个历史行为组成等。多值特征的数组长度不固定,无法直接输入到模型中,因此需要转换为固定长度,主要方法有:
-
池化:如最大值池化、求和池化和平均池化等方法。先利用离散型特征或连续型特征的处理方法,对多值特征中的每个特征值进行转换,并进行Embedding编码。然后对它们求最大值、求和或求平均,将其压缩为一个单值Embedding向量。这种方法比较简单,计算耗时低,但没有考虑不同特征值之间的重要性差别。为了解决这一问题,Attention[3]池化被提出。它先计算每个特征值的权重,然后再加权求和。目前物品标题等普通多值特征常使用平均池化,而用户行为序列则可以使用Attention池化。
-
序列建模:常用在用户行为序列特征的处理中。它利用LSTM[4]或GRU[5]等循环神经网络,或Transformer[6]网络进行信息抽取,并将不定长的原始序列转换为一个定长向量,然后再输入到模型上层网络中。Transformer表达能力强,并行计算快,目前已经成为了行为序列建模的主流方案。
特征工程中,还经常碰到缺失值和异常值问题。对于缺失值,可以用平均值、固定值、中位数或近邻值进行填充,也可以看做一种普通数值而不填充。对于异常值,可以做最值截断、平滑或直接去除等操作。
4 特征重要性评估
特征重要性评估,一方面可以用来做特征筛选,精简不必要的特征,从而减少离线和在线计算和存储压力。另一方面可以提高算法可解释性,帮助卖家(或创作者)高效运营。另外还可以为特征挖掘寻找方向,方便后续构造出更多重要特征。
特征重要性评估,有离线特征法、离线模型法和在线模型法三大类。
离线特征法,计算待评估特征与标签(如点击、购买)间的相关性,从而衡量是否是强特征。计算方法有皮尔逊系数、斯皮尔曼系数、单特征AUC[7]等。AUC常用来衡量模型排序能力,应用最多。离线特征法不用训练模型,简单易用,但无法刻画特征经过交叉后的重要性,故准确率不高。
离线模型法,可以训练待评估特征剔除前和剔除后两个模型,然后对比它们的AUC和GAUC[8]等指标。剔除特征后,离线指标下降越多,则说明该特征越重要。离线模型法可以充分考虑待评估特征与其他特征交叉后的重要性,其准确性较高。
在线模型法,则将特征剔除前和剔除后两个模型,进行在线AB测试。其准确性最高,但同时成本也最高。另外由于需要用到真实流量,因此一定要谨慎操作。
5 参考文献
[1] Turner, C.R., Fuggetta, A., Lavazza, L., Wolf, A.L.: A conceptual basis for feature engineering. Journal of Systems and Software 49(1), 3–15 (1999)
[2] Ying Shan, T Ryan Hoens, et al. 2016. Deep crossing: Web-scale modeling without manually crafted combinatorial features. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 255–262.
[3] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural machine translation by jointly learning to align and translate. In Proceedings of the 3rd International Conference on Learning Representations (ICLR’15)
[4] Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long short-term memory. Neural Comput. 9, 8 (1997), 1735–1780.
[5] Kyunghyun Cho, Bart van Merrienboer, C¸ aglar Gulc¸ehre, ¨ Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proc. of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014.
[6] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems. 5998–6008.
[7] T. Fawcett, ‘‘An introduction to ROC analysis,’’ Pattern Recognit. Lett., vol. 27, no. 8, pp. 861–874, Jun. 2006.
[8] Guorui Zhou, Xiaoqiang Zhu, et al. 2018. Deep Interest Network for Click-Through Rate Prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. ACM, 1059–1068.
系列文章,请多关注
推荐算法架构1:召回
推荐算法架构2:粗排
推荐算法架构3:精排
推荐算法架构4:重排
推荐算法架构5:全链路专项优化
推荐算法架构6:数据样本
推荐算法架构7:特征工程
相关文章:
推荐算法架构7:特征工程(吊打面试官,史上最全!)
系列文章,请多关注 推荐算法架构1:召回 推荐算法架构2:粗排 推荐算法架构3:精排 推荐算法架构4:重排 推荐算法架构5:全链路专项优化 推荐算法架构6:数据样本 推荐算法架构7:特…...
Web前端 ---- 【Vue】vue路由守卫(全局前置路由守卫、全局后置路由守卫、局部路由path守卫、局部路由component守卫)
目录 前言 全局前置路由守卫 全局后置路由守卫 局部路由守卫之path守卫 局部路由守卫之component守卫 前言 本文介绍Vue2最后的知识点,关于vue的路由守卫。也就是鉴权,不是所有的组件任何人都可以访问到的,需要权限,而根据权限…...

uniapp点击tabbar之前做判断
在UniApp中,可以通过监听 tabBar 的 click 事件来在点击 tabBar 前做判断。具体步骤如下: 在 pages.json 文件中配置 tabBar,例如: {"pages":[{"path":"pages/home/home","name":"h…...
DLLNotFoundException:xxx tolua... 错误打印
DLLNotFoundException:xxx tolua... 错误打印 一、DLLNotFoundException介绍二、Plugins文件夹文件目录结构如下: 三、Plugins中的Android文件夹四、Plugins中的IOS文件夹这里不说了没测试过不过原理应该也是选择对应的平台即可五、Plugins中的x86和X86_64文件夹 一…...
Python量化投资——金融数据最佳实践: 使用qteasy+tushare搭建本地金融数据仓库并定期批量更新【附源码】
用qteasytushare实现金融数据本地化存储及访问 目的什么是qteasy什么是tushare为什么要本地化使用qteasy创建本地数据仓库qteasy支持的几种本地化仓库类型配置本地数据仓库配置tushare 的API token 配置本地数据源 —— 用MySQL数据库作为本地数据源下载金融历史数据 数据的定期…...
)
【投稿】北海 - Rust与面向对象(二)
模板方法 Rust提供了trait,类似于面向对象的接口,不同的是,将传统面向对象的虚函数表从对象中分离出来,trait仍然是一个函数表,只不过是独立的,它的参数self指针可以指向任何实现了该trait的结构。 从对象中…...
HarmonyOS构建第一个ArkTS应用(FA模型)
构建第一个ArkTS应用(FA模型) 创建ArkTS工程 若首次打开DevEco Studio,请点击Create Project创建工程。如果已经打开了一个工程,请在菜单栏选择File > New > Create Project来创建一个新工程。 选择Application应用开发&a…...
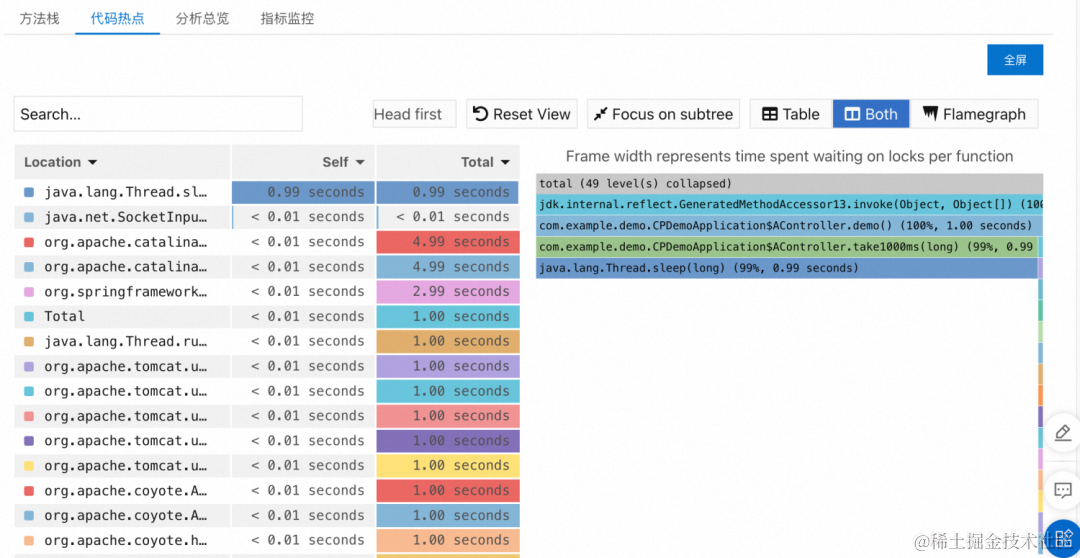
阿里云 ARMS 应用监控重磅支持 Java 21
作者:牧思 & 山猎 前言 今年的 9 月 19 日,作为最新的 LTS (Long Term Support) Java 版本,Java 21 正式 GA,带来了不少重量级的更新,详情请参考 The Arrival of Java 21 [ 1] 。虽然目前 Java 11 和 Java 17 都…...

C++ 类的析构函数和构造函数
构造函数 类的构造函数是类的一种特殊的成员函数,它会在每次创建类的新对象时执行。主要用来在创建对象时初始化对象即为对象成员变量赋初始值。 构造函数的名称与类的名称是完全相同的,并且不会返回任何类型,也不会返回 void。构造函数可用…...

STM32——CAN协议
文章目录 一.CAN协议的基本特点1.1 特点1.2 电平标准1.3 基本的五个帧1.4 数据帧 二.数据帧解析2.1 帧起始和仲裁段2.2 控制段2.3 数据段和CRC段2.4 ACK段和帧结束 三.总线仲裁四.位时序五.STM32CAN控制器原理与配置5.1 STM32CAN控制器介绍5.2 CAN的模式5.3 CAN框图 六 手册寄存…...

数据结构-如何巧妙实现一个栈?逐步解析与代码示例
文章目录 引言1.栈的基本概念2.选择数组还是链表?3. 定义栈结构4.初始化栈5.压栈操作6.弹栈操作7.查看栈顶和判断栈空9.销毁栈操作10.测试并且打印栈内容栈的实际应用结论 引言 栈是一种基本但强大的数据结构,它在许多算法和系统功能中扮演着关键角色。…...

web前端之拖拽API、vue3实现图片上传拖拽排序、拖放、投掷、复制、若依、vuedraggable
MENU vue2html5原生dom原生JavaScript实现跨区域拖放vue2实现跨区域拖放vue2mousedown实现全屏拖动,全屏投掷vue3element-plusvuedraggable实现图片上传拖拽排序vue2transition-group实现拖动排序原生拖拽排序 vue2html5原生dom原生JavaScript实现跨区域拖放 关键代…...
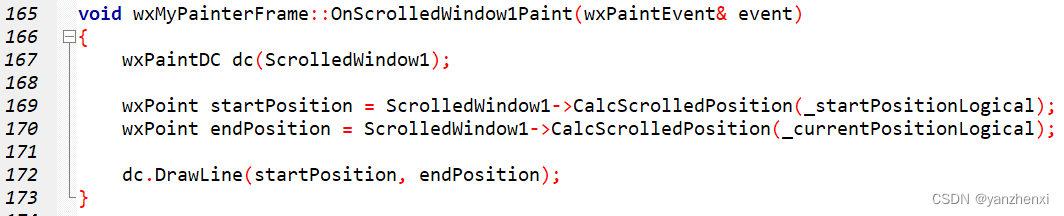
第11章 GUI Page403~405 步骤三 设置滚动范围
运行效果: 源代码: /**************************************************************** Name: wxMyPainterApp.h* Purpose: Defines Application Class* Author: yanzhenxi (3065598272qq.com)* Created: 2023-12-21* Copyright: yanzhen…...

【Spring Security】打造安全无忧的Web应用--使用篇
🥳🥳Welcome Huihuis Code World ! !🥳🥳 接下来看看由辉辉所写的关于Spring Security的相关操作吧 目录 🥳🥳Welcome Huihuis Code World ! !🥳🥳 一.Spring Security中的授权是…...
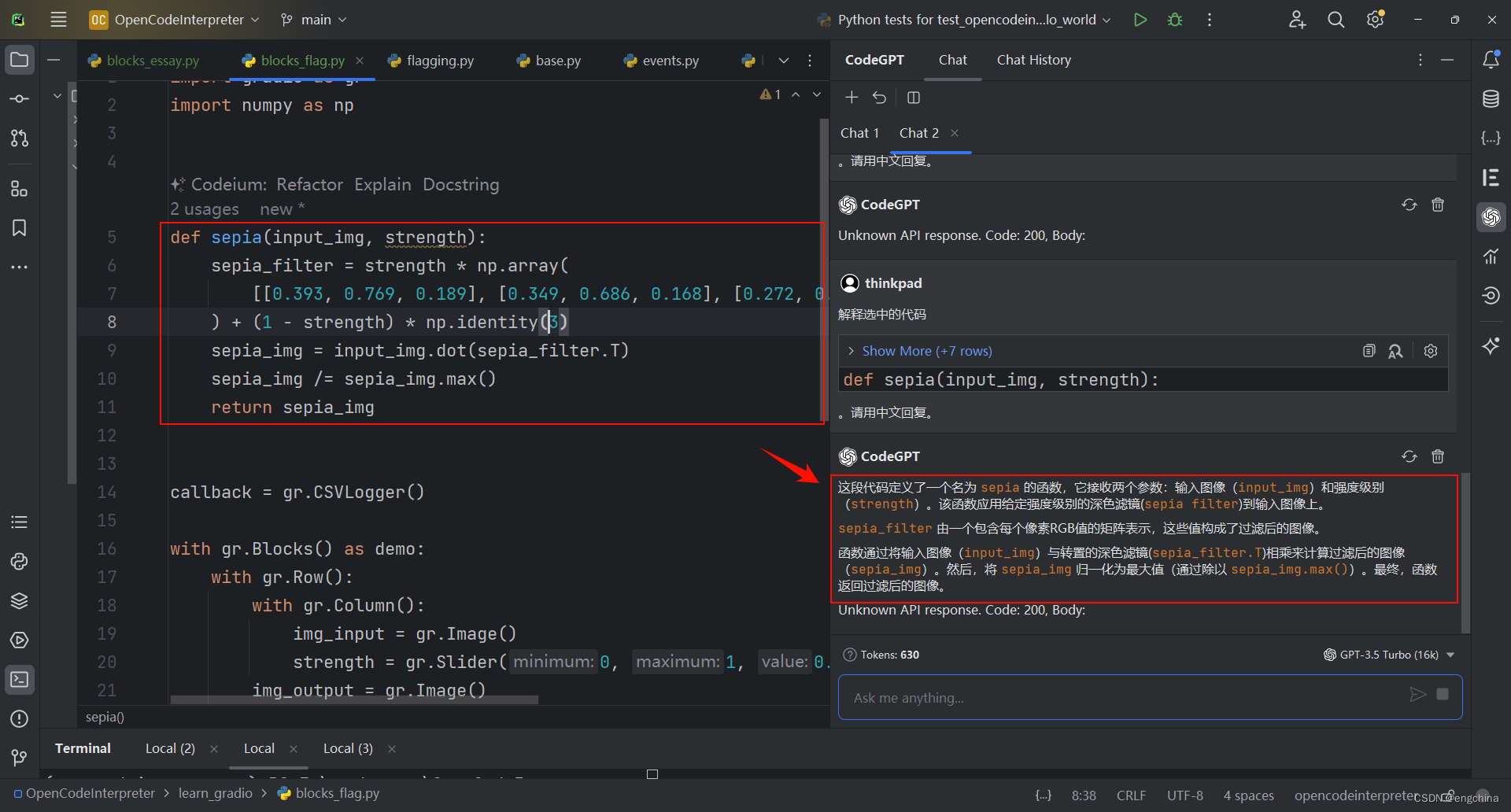
体验一下 CodeGPT 插件
体验一下 CodeGPT 插件 0. 背景1. CodeGPT 插件安装2. CodeGPT 插件基本配置3. (可选)CodeGPT 插件预制提示词原始配置(英文)4. CodeGPT 插件预制提示词配置(中文)5. 简单验证一下 0. 背景 看到B站Up主 “wwwzhouhui” 一个关于 CodeGPT 的视频,感觉挺有意思&#…...
深度学习 | 基础卷积神经网络
卷积神经网络是人脸识别、自动驾驶汽车等大多数计算机视觉应用的支柱。可以认为是一种特殊的神经网络架构,其中基本的矩阵乘法运算被卷积运算取代,专门处理具有网格状拓扑结构的数据。 1、全连接层的问题 1.1、全连接层的问题 “全连接层”的特点是每个…...
)
[字符编码]windwos下使用libiconv转换编码格式(二)
在http://t.csdnimg.cn/PLUuz笔记中实现了常用编码格式转换的功能,但这还是一个demo。因为代码中向libiconv库函数传递的字符串是存放在堆空间中的(我也是从网上找例子测试,是否一定要开辟堆空间存放还有待考证),如果一次性转换的字节数很巨大的话,就会导致内存空间不足,进而引…...

textile 语法
1、文字修饰 修饰行内文字 字体样式textile 语法对应的 XHTML 语法实际显示效果加强*strong*<strong>strong</strong>strong强调_emphasis_<em>emphasis</em>emphasis加粗**bold**<b>bold</b>bold斜体__italics__<i>italics</i…...

【快速开发】使用SvelteKit
自我介绍 做一个简单介绍,酒架年近48 ,有20多年IT工作经历,目前在一家500强做企业架构.因为工作需要,另外也因为兴趣涉猎比较广,为了自己学习建立了三个博客,分别是【全球IT瞭望】,【…...

【docker笔记】docker常用命令
1、帮助启动类命令 1.1 启动、重启、查询当前状态、停止 systemctl start docker systemctl stop docker systemctl restart docker systemctl status docker1.2 设置开机启动 systemctl enable docker1.3 查看docker概要信息 docker info1.4 查看docker帮助文档 docker -…...

从稀疏重构到精准定位:OMP-CS算法在DOA估计中的实战解析
1. 从稀疏信号到空间定位:OMP-CS算法的核心逻辑 第一次接触OMP-CS算法时,我盯着那堆数学公式发呆了半小时。直到把天线阵列想象成麦克风阵列,事情突然变得简单——这不就是通过多个麦克风判断声音方向的升级版吗?在雷达和通信系统…...

MobaXterm远程桌面实战:在Ubuntu上配置与连接RDP服务
1. 为什么选择MobaXterm连接Ubuntu远程桌面 作为一名常年和Linux服务器打交道的开发者,我深知纯命令行操作有时会遇到效率瓶颈。特别是当需要处理图形界面应用或者进行复杂配置时,SSH终端就显得力不从心了。这时候,RDP远程桌面协议就成了救命…...
Transformer在CV领域的新秀:拆解TransWeather如何用‘天气查询’一招解决多任务难题
Transformer在CV领域的新秀:拆解TransWeather如何用‘天气查询’一招解决多任务难题 计算机视觉领域正经历一场由Transformer架构引领的革命。从最初的图像分类任务到如今的复杂场景理解,Transformer以其强大的全局建模能力不断刷新着各项基准。而在天气…...

本地AI小镇Alicization-Town部署指南:从零搭建多智能体模拟环境
1. 项目概述与核心价值最近在社区里看到不少朋友在讨论一个名为“Alicization-Town”的项目,它源自GitHub上的一个仓库ceresOPA/Alicization-Town。这个名字听起来有点二次元,但别被它迷惑了,这其实是一个相当硬核的、面向开发者和技术爱好者…...

终极MifareOneTool使用指南:如何零基础玩转MIFARE经典卡的Windows图形化神器
终极MifareOneTool使用指南:如何零基础玩转MIFARE经典卡的Windows图形化神器 【免费下载链接】MifareOneTool A GUI Mifare Classic tool on Windows(停工/最新版v1.7.0) 项目地址: https://gitcode.com/gh_mirrors/mi/MifareOneTool …...

【独家首发】Midjourney像素艺术训练数据集反向推演报告:基于12,843张高质量样本的风格迁移规律白皮书
更多请点击: https://intelliparadigm.com 第一章:Midjourney像素艺术风格的定义与边界判定 像素艺术(Pixel Art)在 Midjourney 中并非原生风格类别,而是一种通过提示词工程、参数约束与后处理协同达成的视觉范式。其…...

3分钟掌握网页视频下载:Chrome扩展VideoDownloadHelper完全指南
3分钟掌握网页视频下载:Chrome扩展VideoDownloadHelper完全指南 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 你是否曾经遇到想…...

Cool-Request终极指南:如何高效配置全局请求头提升API测试效率
Cool-Request终极指南:如何高效配置全局请求头提升API测试效率 【免费下载链接】cool-request IDEA API、Java Method debug tools 项目地址: https://gitcode.com/gh_mirrors/co/cool-request 在Java API开发和调试过程中,Cool-Request作为一款强…...

开发者技能图谱实战指南:从结构化知识到可执行代码的进阶之路
1. 项目概述:一个面向开发者的技能图谱与实战仓库最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫GuDaStudio/skills。乍一看名字,你可能会觉得这又是一个普通的“技能清单”或者“学习路线图”项目。但点进去仔细研究后…...

从视频到文字:我的学习效率革命之旅
从视频到文字:我的学习效率革命之旅 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 还记得那个周末的下午,我正对着B站上一个两小时的…...