[字符编码]windwos下使用libiconv转换编码格式(二)
在http://t.csdnimg.cn/PLUuz笔记中实现了常用编码格式转换的功能,但这还是一个demo。因为代码中向libiconv库函数传递的字符串是存放在堆空间中的(我也是从网上找例子测试,是否一定要开辟堆空间存放还有待考证),如果一次性转换的字节数很巨大的话,就会导致内存空间不足,进而引发功能异常。
所以,对于需要大量转换的数据,应该采取分段多次转换的方法。
经过观察,有的编码格式每个字符对应的字节是固定的,这样分段是容易的。比如GB2312格式,一个字符占两个字节,那么每次处理的字节数就是2的整倍数即可。
除了上面说的字节数固定的情况,还有向utf8这种字符字节数会变化的情况,这种转换则需要复杂些的处理。
#include <iostream>#include <fstream> #include <string> #include <bitset> #include "iconv.h" //包函libiconv库头文件//导入libiconv库#pragma comment(lib,"libiconv.lib")bool readfile(const std::string& _filepath, std::string& _filecontent){bool res = false;std::ifstream file(_filepath);if (!file.is_open()) { // 检查文件是否成功打开 std::cerr << "无法打开文件" << _filepath << std::endl;}else {std::string line;while (std::getline(file, line)) { // 逐行读取文件内容 _filecontent += line;}res = true;}file.close(); // 关闭文件return res;}//使用 libiconv 进行int TransCore(const char* _pdesc, const char* _psrc, const char* _pstrin, size_t ilen, char* _pstrout, size_t* _polen){const char** ppin = &_pstrin;char** ppout = &_pstrout;iconv_t cd = iconv_open(_pdesc, _psrc);if (cd == (iconv_t)-1) {return -1;}memset(_pstrout, 0, *_polen);int res = iconv(cd, ppin, &ilen, ppout, _polen);std::cout <<__FUNCTION__<< " exec res = " << res << std::endl;iconv_close(cd);return res;}/*desc 目标编码字符串src 源编码字符串_strin 转换前内容_strout 转换后内容*/bool TransEncodeFormat(const char* _desc, const char* _src, const std::string& _strin, std::string& _strout) {bool res = false;if (_desc == nullptr || _src == nullptr || _strin.empty()) {std::cout << "入参不符合要求" << std::endl;return res;}size_t inlen = _strin.length();#ifdef LOGstd::cout << "需要转换的内容 : [" << _strin << "]" << std::endl;std::cout << "需要转换的字节数 : [" << inlen << "]" << std::endl;#endifsize_t outlen = inlen * 10;char* tempout = new char[outlen];if (TransCore(_desc, _src, _strin.c_str(), inlen, tempout, &outlen) == 0 && tempout != nullptr) {res = true;}#ifdef LOGstd::cout << "转换后的内容 : [" << tempout << "]" << std::endl;#endifstd::string temp(tempout);_strout = tempout;delete[] tempout;tempout = nullptr;return res;}/*描述 : 在_strin字符串是正确的utf8格式的情况下,分段将utf8字符转换成其他编码格式内容_desc : 目标编码格式_strin : 被转换的uft8字符串内容_strout: 转换后字符串内容_segnum: 一段字符串字节个数,默认是100字节返回值 : true 转换成功 false转换失败*/bool SegmentTransUtf8ToOther(const char* _desc, const std::string& _strin, std::string& _strout, const int& _segnum = 100) {const char* _src = "UTF-8";size_t _transcounter = 0;if (_strin.size() == 0) {//没有内容就返回_strout.clear();return true;}if (_segnum <= 0) {return false;}if (_strin.size() <= _segnum) {//字符串小于等于_segnumstd::cout << "第" << ++_transcounter << "段转换" <<",转换字节数"<< _strin.size() << std::endl;if (TransEncodeFormat(_desc, _src, _strin, _strout) == false) {return false;}}else {//字符串大于_segnumint leftpos = 0; //左边界位置int endpos = _strin.size() - 1; // 结束位置while (leftpos <= endpos) { int rightpos = 0;//右边界位置int remainingbytes = endpos - leftpos + 1; //左边界到结束剩余的字节数std::string outemp;if (remainingbytes <= _segnum) {//剩余字节数小于_segnumrightpos = endpos;std::string temp = _strin.substr(leftpos, remainingbytes); std::cout << "第" << ++_transcounter << "段转换" << ",转换字节数" << temp.size() << std::endl;if (TransEncodeFormat(_desc, _src, temp, outemp) == false) {return false;}_strout += outemp;} else {rightpos = leftpos + (_segnum - 1);const char lastbyte = _strin[rightpos];//通过要截取的最后一个字节 判断截取字符串是否完整if (((char)(lastbyte | 0x7f) == (char)0x7f) && ((char)(lastbyte & 0x00) == (char)0x00)) {//最后一个字节是 0XXX XXXXstd::string temp = _strin.substr(leftpos, rightpos - leftpos + 1);std::cout << "第" << ++_transcounter << "段转换" << ",转换字节数" << temp.size() << std::endl;if (TransEncodeFormat(_desc, _src, temp, outemp) == false) {return false;}_strout += outemp;} else if (((char)(lastbyte | 0xbf) == (char)0xbf) && ((char)(lastbyte & 0x80) == (char)0x80)) {//最后一个字节是 10XX XXXXwhile (1) {rightpos = rightpos + 1;if (rightpos > endpos) {//判断rightpos是否超出边界return false;}const char lastbytetemp = _strin[rightpos];if (((char)(lastbytetemp | 0xbf) == (char)0xbf) && ((char)(lastbytetemp & 0x80) == (char)0x80)) {//最后一个字节是 10XX XXXX}else {//最后一个字节不是 10XX XXXX 那么就少截取一个并跳出while循环rightpos = rightpos - 1;break;}}//whileif (rightpos < 0 || rightpos < leftpos) {//rightpos 上面进行了减法所以判断一下return false;}std::string temp = _strin.substr(leftpos, rightpos - leftpos + 1);std::cout << "第" << ++_transcounter << "段转换" << ",转换字节数" << temp.size() << std::endl;if (TransEncodeFormat(_desc, _src, temp, outemp) == false) {return false;}_strout += outemp;} else if (((char)(lastbyte | 0xdf) == (char)0xdf) && ((char)(lastbyte & 0xc0) == (char)0xc0)) {//最后一个字节是 110X XXXXrightpos = rightpos + 1;if (rightpos > endpos) {//判断rightpos是否超出边界return false;}std::string temp = _strin.substr(leftpos, rightpos - leftpos + 1);std::cout << "第" << ++_transcounter << "段转换" << ",转换字节数" << temp.size() << std::endl;if (TransEncodeFormat(_desc, _src, temp, outemp) == false) {return false;}_strout += outemp;} else if (((char)(lastbyte | 0xef) == (char)0xef) && ((char)(lastbyte & 0xe0) == (char)0xe0)) {//最后一个字节是 1110 XXXXrightpos = rightpos + 2;if (rightpos > endpos) {//判断rightpos是否超出边界return false;}std::string temp = _strin.substr(leftpos, rightpos - leftpos + 1);std::cout << "第" << ++_transcounter << "段转换" << ",转换字节数" << temp.size() << std::endl;if (TransEncodeFormat(_desc, _src, temp, outemp) == false) {return false;}_strout += outemp;} else if (((char)(lastbyte | 0xf7) == (char)0xf7) && ((char)(lastbyte & 0xf0) == (char)0xf0)) {//最后一个字节是 1111 0XXXrightpos = rightpos + 3;if (rightpos > endpos) {//判断rightpos是否超出边界return false;}std::string temp = _strin.substr(leftpos, rightpos - leftpos + 1);std::cout << "第" << ++_transcounter << "段转换" << ",转换字节数" << temp.size() << std::endl;if (TransEncodeFormat(_desc, _src, temp, outemp) == false) {return false;}_strout += outemp;}}leftpos = rightpos + 1;}}std::cout << __FUNCTION__ << " exec success" << std::endl;return true;}int main(int argc, char* argv[]){{std::string filecontent;std::string transcontent;std::string gbkfilepath = "./test-file/utf-8.txt";readfile(gbkfilepath, filecontent);std::cout << " ./test-file/utf-8.txt 内容字节数 = " << filecontent.size() << std::endl;bool res = SegmentTransUtf8ToOther("GBK", filecontent, transcontent, 1000);std::cout << " transcontent 内容字节数 = " << transcontent.size() << std::endl;std::cout << " transcontent GBK 内容[" << transcontent <<"]" << std::endl;std::cout << "====================================================" << std::endl;}{std::string filecontent;std::string transcontent;std::string gbkfilepath = "./test-file/utf-8.txt";readfile(gbkfilepath, filecontent);std::cout << " ./test-file/utf-8.txt 内容字节数 = " << filecontent.size() << std::endl;bool res = SegmentTransUtf8ToOther("GB18030", filecontent, transcontent, 1000);std::cout << " transcontent 内容字节数 = " << transcontent.size() << std::endl;std::cout << " transcontent GB18030 内容[" << transcontent << "]" << std::endl;std::cout << "====================================================" << std::endl;}{std::string filecontent;std::string transcontent;std::string gbkfilepath = "./test-file/utf-8.txt";readfile(gbkfilepath, filecontent);std::cout << " ./test-file/utf-8.txt 内容字节数 = " << filecontent.size() << std::endl;bool res = SegmentTransUtf8ToOther("GB2312", filecontent, transcontent, 1000);std::cout << " transcontent 内容字节数 = " << transcontent.size() << std::endl;std::cout << " transcontent GB2312 内容[" << transcontent << "]" << std::endl;std::cout << "====================================================" << std::endl;}return 0;}相关文章:
)
[字符编码]windwos下使用libiconv转换编码格式(二)
在http://t.csdnimg.cn/PLUuz笔记中实现了常用编码格式转换的功能,但这还是一个demo。因为代码中向libiconv库函数传递的字符串是存放在堆空间中的(我也是从网上找例子测试,是否一定要开辟堆空间存放还有待考证),如果一次性转换的字节数很巨大的话,就会导致内存空间不足,进而引…...

textile 语法
1、文字修饰 修饰行内文字 字体样式textile 语法对应的 XHTML 语法实际显示效果加强*strong*<strong>strong</strong>strong强调_emphasis_<em>emphasis</em>emphasis加粗**bold**<b>bold</b>bold斜体__italics__<i>italics</i…...

【快速开发】使用SvelteKit
自我介绍 做一个简单介绍,酒架年近48 ,有20多年IT工作经历,目前在一家500强做企业架构.因为工作需要,另外也因为兴趣涉猎比较广,为了自己学习建立了三个博客,分别是【全球IT瞭望】,【…...

【docker笔记】docker常用命令
1、帮助启动类命令 1.1 启动、重启、查询当前状态、停止 systemctl start docker systemctl stop docker systemctl restart docker systemctl status docker1.2 设置开机启动 systemctl enable docker1.3 查看docker概要信息 docker info1.4 查看docker帮助文档 docker -…...

API 接口怎样设计才安全?
设计安全的API接口是确保应用程序和数据安全的重要方面之一。下面是一些设计安全的API接口的常见实践: 1. 身份验证和授权: 使用适当的身份验证机制,如OAuth、JWT或基本身份验证,以确保只有经过身份验证的用户可以访问API。实施…...
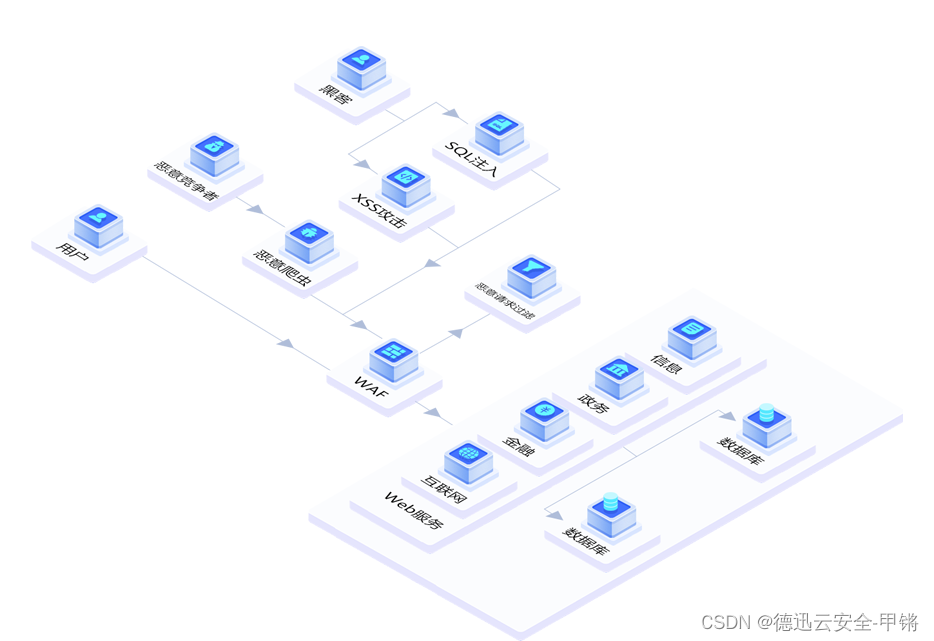
网站被CC攻击了怎么办?CC攻击有什么危害
网络爆炸性地发展,网络环境也日益复杂和开放,同时各种各样的恶意威胁和攻击日益增多,其中网站被CC也是常见的情况。 CC攻击有什么危害呢? 被CC会导致: 1.访问速度变慢:网站遭受CC攻击后,由于…...

Docker - 镜像 | 容器 日常开发常用指令 + 演示(一文通关)
目录 Docker 开发常用指令汇总 辅助命令 docker version docker info docker --help 镜像命令 查看镜像信息 下载镜像 搜索镜像 删除镜像 容器命令 查看运行中的容器 运行容器 停止、启动、重启、暂停、恢复容器 杀死容器 删除容器 查看容器日志 进入容器内部…...
要参加微软官方 Copilot 智能编程训练营了
GitHub Copilot 是由 GitHub、OpenAI 和 Microsoft 联合开发的生成式 AI 模型驱动的。 GitHub Copilot 分析用户正在编辑的文件及相关文件的上下文,并在编写代码时提供自动补全式的建议。 刚好下周要参加微软官方组织的 GitHub Copilot 工作坊-智能编程训练营&…...

Python入门学习篇(五)——列表字典
1 列表 1.1 定义 ①有序可重复的元素集合 ②可以存放不同类型的数据 ③个人理解:类似于java中的数组1.2 相关方法 1.2.1 获取列表长度 a 语法 len(列表名)b 示例代码 list2 [1, 2, "hello", 4] print(len(list2))c 运行结果 1.2.2 获取列表值 a 语法 列表名…...

React尝鲜
组件 React的组件就是一个js函数,函数内部return一个由jsx语法创建的html代码片段。 //MyComp.js export default function MyComp(){return (<h1>我是新组件MyComp</h1>) } 在需要引入组件的地方import导入组件,并放在相应位置 //App.js…...

锯齿云服务器租赁使用教程
首先登陆锯齿云账号 网盘上传数据集与代码 随后我们需要做的是将所需要的数据集与代码上传到网盘(也可以直接在租用服务器后将数据集与代码传到服务器的硬盘上,但这样做会消耗大量时间,造成资源浪费) 点击工作空间:…...

HarmonyOS和OpenHarmony的区别
1.概要 众所周知,鸿蒙是华为开发的一款分布式操作系统。因为开发系统,最重要的是集思广益,大家共同维护。为了在IOS和Android之间生存,鸿蒙的茁壮成长一定是需要开源,各方助力才能实现。 在这种思想上,…...

Redis Stream消息队列之基本语法与使用方式
前言 本文的主角是Redis Stream,它是Redis5.0版本新增加的数据结构,主要用于消息队列,提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证…...

制造行业定制软件解决方案——工业信息采集平台
摘要:针对目前企业在线检测数据信号种类繁多,缺乏统一监控人员和及时处置措施等问题。蓝鹏测控开发针对企业工业生产的在线数据的集中采集分析平台,通过该工业信息采集平台可将企业日常各种仪表设备能够得到数据进行集中分析处理存储…...

[python]用python实现对arxml文件的操作
目录 关键词平台说明一、背景二、方法2.1 库2.2 code 关键词 python、excel、DBC、openpyxl 平台说明 项目Valuepython版本3.6 一、背景 有时候需要批量处理arxml文件(ARXML 文件符合 AUTOSAR 4.0 标准),但是工作量太大,阔以考虑用python。 二、方…...
pdf 在线编辑
https://smallpdf.com/edit-pdf#rapp 参考 https://zh.wikihow.com/%E5%B0%86%E5%9B%BE%E5%83%8F%E6%8F%92%E5%85%A5PDF...

自然语言处理(NLP):理解语言,赋能未来
目录 前言1 什么是NLP2 NLP的用途3 发展历史4 NLP的基本任务4.1 词性标注(Part-of-Speech Tagging)4.2 命名实体识别(Named Entity Recognition)4.3 共指消解(Co-reference Resolution)4.4 依存关系分析&am…...

FastAPI使用loguru时,出现重复日志打印的解决方案
首先看图,发现每个日志都被打印了3条。其实这个和uvicorn日志打印的设计有关,在uvicorn中有多个logger,分别是uvicorn、uvicorn.error、uvicorn.access 而LOGGING默认有一个属性propagate,这个属性为True时,子日志记录…...

构建每个聚类的profile和deletion_mean特征
通过summarize_clusters函数构建每个聚类的protein[cluster_profile]和protein[cluster_deletion_mean]特征。目的是把extra_msa信息反映到msa中。 集成函数数据处理流程: sample_msa ->make_masked_msa -> nearest_neighbor_clusters -> summarize_clu…...
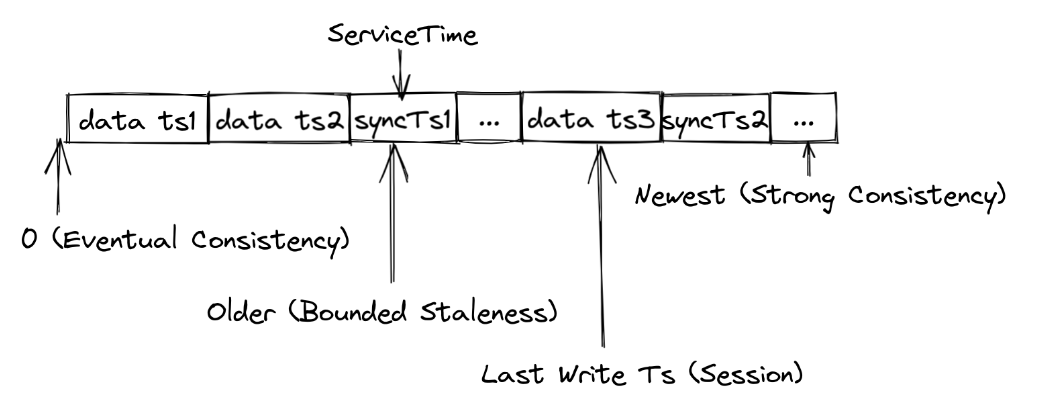
Milvus数据一致性介绍及选择方法
1、Milvus 时钟机制 Milvus 通过时间戳水印来保障读链路的一致性,如下图所示,在往消息队列插入数据时, Milvus 不光会为这些插入记录打上时间戳,还会不间断地插入同步时间戳,以图中同步时间戳 syncTs1 为例࿰…...

米尔RK3576开发板评测:工业AI与边缘计算的性能甜点方案
1. 项目概述:当RK3576遇上米尔开发板,工业AI的新选择最近在嵌入式圈子里,瑞芯微的RK3576这颗SoC讨论热度挺高。作为一枚常年混迹在工控、边缘计算和AIoT项目里的老工程师,我对这类新平台的发布总是格外敏感。米尔电子作为国内老牌…...

如何快速配置阅读APP书源:26个高质量小说资源一键导入指南
如何快速配置阅读APP书源:26个高质量小说资源一键导入指南 【免费下载链接】Yuedu 📚「阅读」自用书源分享 项目地址: https://gitcode.com/gh_mirrors/yu/Yuedu 阅读APP作为一款开源的小说阅读工具,本身不提供小说内容,而…...

Sunshine游戏串流服务器:打造你的私人云游戏平台
Sunshine游戏串流服务器:打造你的私人云游戏平台 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 想要在客厅电视、笔记本电脑甚至手机上玩高性能PC游戏吗?S…...

SmartNIC与DPU技术解析:计算卸载与性能优化实践
1. SmartNIC与DPU技术概述在数据中心和高性能计算领域,网络瓶颈一直是制约系统性能的关键因素。传统网卡仅负责简单的数据包收发,而现代计算密集型应用需要更智能的网络处理能力。这就是SmartNIC(智能网卡)和DPU(数据处…...

通过curl命令直接测试Taotoken聊天补全接口的简易方法
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令直接测试Taotoken聊天补全接口的简易方法 在开发或调试过程中,有时我们希望在无需引入完整SDK的轻量级环境…...

Codex 上下文提供详解与操作指南
1. 文档目标 这份文档解决的是一个非常实际的问题: 怎么给 Codex 足够完整的上下文什么信息是必须给的,什么信息是可选但高价值的怎样让 Codex 在一次任务里快速进入正确状态怎样避免“我已经说了很多,但结果还是不对”怎样把上下文提供方式变…...

终极免费文档下载指南:kill-doc让你轻松保存百度文库等30+平台内容
终极免费文档下载指南:kill-doc让你轻松保存百度文库等30平台内容 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚…...

深入TEA5767数据手册:51单片机I²C驱动FM收音模块的避坑指南与调试心得
深入解析TEA5767:51单片机驱动FM收音模块的实战技巧 在嵌入式开发领域,能够独立解读芯片手册并实现功能驱动是工程师的核心能力之一。TEA5767作为一款经典的FM收音芯片,因其低功耗、高集成度和简单的IC接口而广受欢迎。本文将从一个实际开发者…...

从数字臃肿到高效存储:开源视频图片压缩解决方案深度解析
从数字臃肿到高效存储:开源视频图片压缩解决方案深度解析 【免费下载链接】compressO Convert any video/image into a tiny size. 100% free & open-source. Available for Mac, Windows & Linux. 项目地址: https://gitcode.com/gh_mirrors/co/compress…...

在Nodejs服务中集成多模型API实现智能客服场景
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Nodejs服务中集成多模型API实现智能客服场景 智能客服是当前许多在线服务提升用户体验的关键组件。对于Node.js后端开发者而言&a…...