模式识别与机器学习(九):Adaboost
1.原理
AdaBoost是Adaptive Boosting(自适应增强)的缩写,它的自适应在于:被前一个基本分类器误分类的样本的权值会增大,而正确分类的样本的权值会减小,并再次用来训练下一个基本分类器。同时,在每一轮迭代中,加入一个新的弱分类器,直到达到某个预定的足够小的错误率或预先指定的最大迭代次数再确定最后的强分类器。
1.算法步骤
首先,是初始化训练数据的权值分布D1。假设有N个训练样本数据,则每一个训练样本最开始时,都会被赋予相同的权值:w1 = 1/N。
训练弱分类器Ci。具体训练过程:如果某个训练样本点,被弱分类器Ci准确地分类,那么再构造下一个训练集中,它对应的权值要减小;相反,如果某个训练样本点被错误分类,那么它的权值就应该增大。权值的更新过的样本被用于训练下一个弱分类器,整个过程如此迭代下去。
最后,将各个训练得到的弱分类器组合成一个强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。
换而言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
2.算法过程
(1).首先,初始化训练集的权值分布。每个训练样本最开始都被赋予相同的权值: w i = 1 N w_{i}=\frac{1}{N} wi=N1这样样本集的权值初始分布为 D 1 ( i ) = ( w 1 , w 2 , ⋯ w N ) = ( 1 N , 1 N , ⋯ 1 N ) D_{1}(i)=(w_{1},w_{2},\cdots w_{N})=\left(\frac{1}{N},\frac{1}{N},\cdots\frac{1}{N}\right) D1(i)=(w1,w2,⋯wN)=(N1,N1,⋯N1)
(2).进行迭代 t = 1 , 2 , ⋯ , T t=1,2,\cdots,T t=1,2,⋯,T
(a).选取一个当前误差率最低的分类器h作为第t个基分类器H_t,并计算弱分类器h_t在训练集上的分类误差率: e t = ∑ i = 1 m w t , i I ( h t ( x i ) ≠ f ( x i ) ) e_{t}=\sum_{i=1}^{m}w_{t,i}I\big(h_{t}(x_{i})\neq f(x_{i})\big) et=i=1∑mwt,iI(ht(xi)=f(xi))
(b).计算该分类器在最终分类器中所占的权重:
∂ t = 1 2 ln 1 − e t e t \partial_t=\frac{1}{2}\ln\frac{1-e_t}{e_t} ∂t=21lnet1−et
©.更新样本的权重分布:
D t + 1 = D t e x p ( − ∂ t f ( x ) h t ( x ) ) Z t D_{t+1}=\frac{D_texp(-\partial_tf(x)h_t(x))}{Z_t} Dt+1=ZtDtexp(−∂tf(x)ht(x))
其中: Z t = ∑ i = 1 m w t , i e x p ( − ∂ t f ( x i ) h t ( x i ) ) Z_t=\sum_{i=1}^mw_{t,i}exp\bigl(-\partial_tf(x_i)h_t(x_i)\bigr) Zt=i=1∑mwt,iexp(−∂tf(xi)ht(xi))
(3).最后按照弱分类器权重\partial_t组成各个弱分类器:
f ( x ) = ∑ i = 1 T ∂ i H i ( x ) \mathrm{f(x)=\sum_{i=1}^T\partial_iH_i(x)} f(x)=i=1∑T∂iHi(x)
通过符号函数sign最终得到一个强分类器:
H f i n a l = s i g n ( f ( x ) ) = s i g n ( ∑ i = 1 T ∂ i H i ( x ) ) H_{final}=sign\big(\mathrm{f(x)}\big)=sign\bigg(\sum_{\mathrm{i}=1}^{\mathrm{T}}\partial_i\operatorname{H_i(x)}\bigg) Hfinal=sign(f(x))=sign(i=1∑T∂iHi(x))
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建AdaBoost分类器
clf = AdaBoostClassifier(n_estimators=50, learning_rate=1.0)# 训练模型
clf.fit(X_train, y_train)# 预测测试集
y_pred = clf.predict(X_test)# 打印预测结果
print(y_pred)
我们使用了鸢尾花数据集,这是一个常用的多类别分类数据集。我们首先加载数据,然后划分为训练集和测试集。然后,我们创建一个AdaBoost分类器,并使用训练集对其进行训练。最后,我们使用训练好的模型对测试集进行预测,并打印出预测结果。
AdaBoostClassifier的参数n_estimators表示弱学习器的最大数量,learning_rate表示学习率,这两个参数都可以根据需要进行调整。在scikit-learn的AdaBoostClassifier中,默认的弱学习器是一个最大深度为1的决策树桩。你也可以通过base_estimator参数来指定其他类型的弱学习器。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn import svm# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建朴素贝叶斯分类器作为弱学习器的AdaBoost分类器
clf_nb = AdaBoostClassifier(base_estimator=GaussianNB(), n_estimators=50, learning_rate=1.0)
clf_nb.fit(X_train, y_train)
y_pred_nb = clf_nb.predict(X_test)
print(y_pred_nb)# 创建SVM作为弱学习器的AdaBoost分类器
clf_svm = AdaBoostClassifier(base_estimator=svm.SVC(probability=True, kernel='linear'), n_estimators=50, learning_rate=1.0)
clf_svm.fit(X_train, y_train)
y_pred_svm = clf_svm.predict(X_test)
print(y_pred_svm)
我们首先创建了一个使用朴素贝叶斯分类器作为弱学习器的AdaBoost分类器,然后创建了一个使用SVM作为弱学习器的AdaBoost分类器。注意,对于SVM,我们需要设置probability=True,因为AdaBoost需要使用类别概率。
相关文章:
:Adaboost)
模式识别与机器学习(九):Adaboost
1.原理 AdaBoost是Adaptive Boosting(自适应增强)的缩写,它的自适应在于:被前一个基本分类器误分类的样本的权值会增大,而正确分类的样本的权值会减小,并再次用来训练下一个基本分类器。同时,在…...
【JAVA】分布式链路追踪技术概论
目录 1.概述 2.基于日志的实现 2.1.实现思想 2.2.sleuth 2.2.可视化 3.基于agent的实现 4.联系作者 1.概述 当采用分布式架构后,一次请求会在多个服务之间流转,组成单次调用链的服务往往都分散在不同的服务器上。这就会带来一个问题:…...
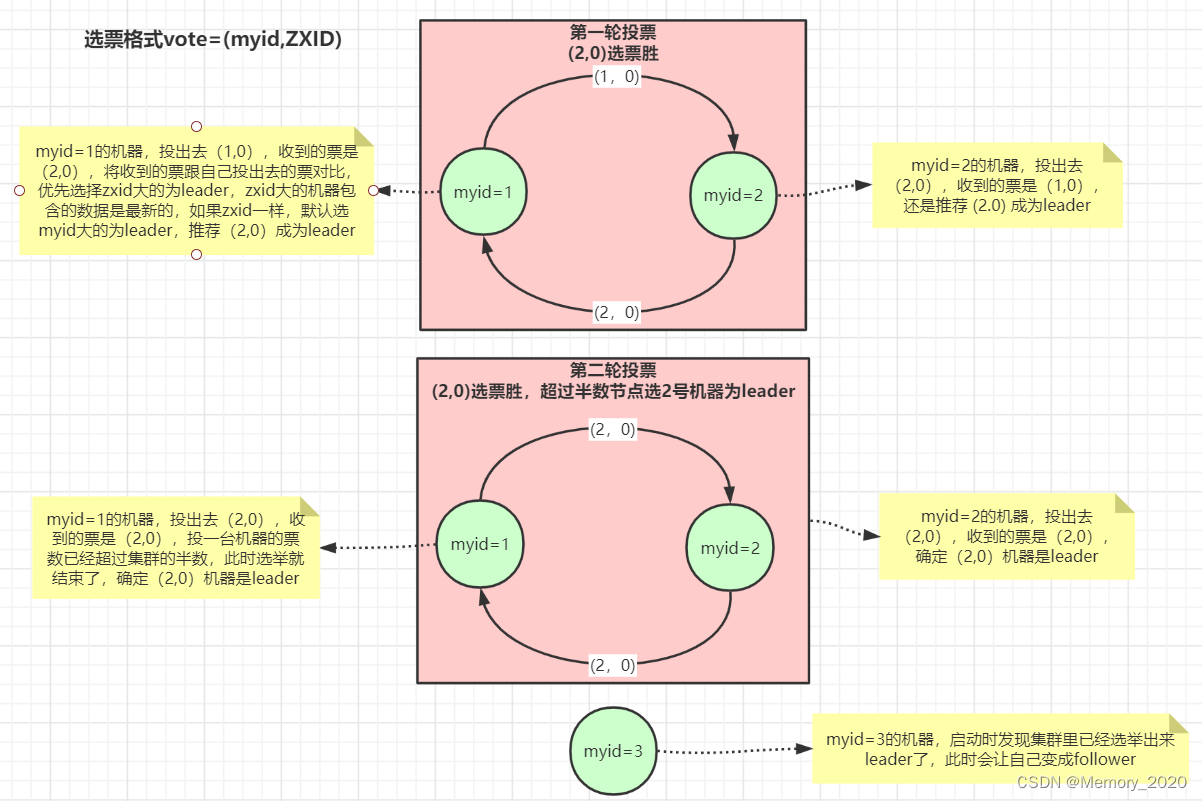
ZooKeeper 使用介绍和原理详解
目录 1. 介绍 重要性 应用场景 2. ZooKeeper 架构 服务角色 数据模型 工作原理 3. 安装和配置 下载 ZooKeeper 安装和配置 启动 ZooKeeper 验证和管理 停止和关闭 4. ZooKeeper 数据模型 数据结构和层次命名空间: 节点类型和 Watcher 机制ÿ…...
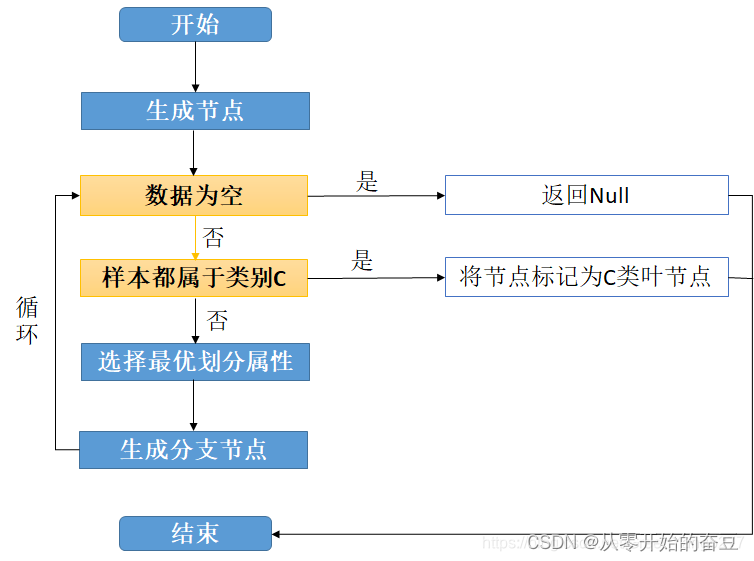
模式识别与机器学习(八):决策树
1.原理 决策树(Decision Tree),它是一种以树形数据结构来展示决策规则和分类结果的模型,作为一种归纳学习算法,其重点是将看似无序、杂乱的已知数据,通过某种技术手段将它们转化成可以预测未知数据的树状模…...
Pinely Round 3 (Div. 1 + Div. 2)(A~D)(有意思的题)
A - Distinct Buttons 题意: 思路:模拟从(0,0)到每个位置需要哪些操作,如果总共需要4种操作就输出NO。 // Problem: A. Distinct Buttons // Contest: Codeforces - Pinely Round 3 (Div. 1 Div. 2) // URL: https…...

在Linux下探索MinIO存储服务如何远程上传文件
🌈个人主页:聆风吟 🔥系列专栏:网络奇遇记、Cpolar杂谈 🔖少年有梦不应止于心动,更要付诸行动。 文章目录 📋前言一. 创建Buckets和Access Keys二. Linux 安装Cpolar三. 创建连接MinIO服务公网地…...

持续集成交付CICD:Linux 部署 Jira 9.12.1
目录 一、实验 1.环境 2.K8S master节点部署Jira 3.Jira 初始化设置 4.Jira 使用 一、实验 1.环境 (1)主机 表1 主机 主机架构版本IP备注master1K8S master节点1.20.6192.168.204.180 jenkins slave (从节点) jira9.12.1…...

Linux命令-查看内存、GC情况及jmap 用法
查看进程占用内存、CPU使用情况 1、查看进程 #jps 查看所有java进程 #top 查看cpu占用高进程 输入m :根据内存排序 topMem: 16333644k total, 9472968k used, 6860676k free, 165616k buffers Swap: 0k total, 0k used, 0k free, 6…...

nginx安装letsencrypt证书
1.安装推荐安装letsencrypt证书的客户端工具 官方推荐通过cerbot客户端安装letsencrypt 官方推荐使用snap客户端安装cerbot客户端 apt install snapd snap install --classic certbot 建立certbot软链接:ln -s /snap/bin/certbot /usr/bin/certbot 2.开始安装letse…...
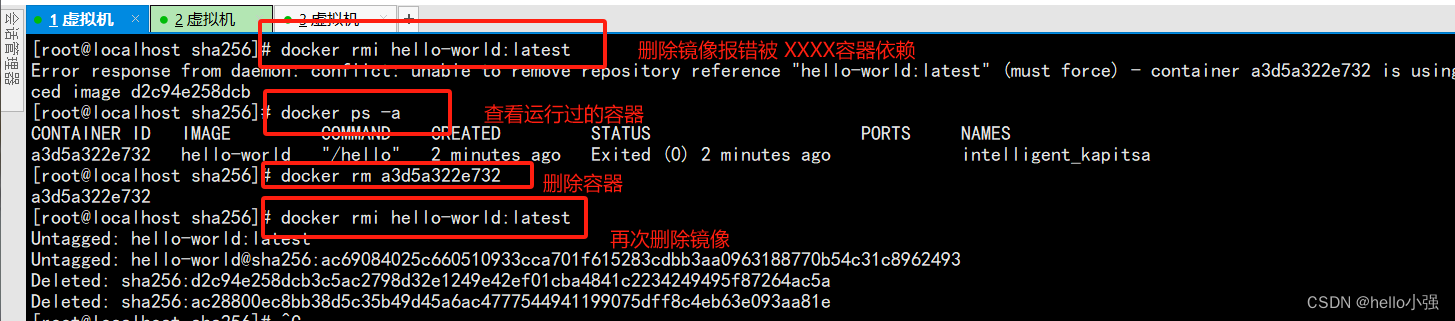
docker笔记1-安装与基础命令
docker的用途: 可以把应用程序代码及运行依赖环境打包成镜像,作为交付介质,在各种环境部署。可以将镜像(image)启动成容器(container),并提供多容器的生命周期进行管理(…...
VSCode软件与SCL编程
原创 NingChao NCLib 博途工控人平时在哪里技术交流博途工控人社群 VSCode简称VSC,是Visual studio code的缩写,是由微软开发的跨平台的轻量级编辑器,支持几乎所有主流的开发语言的语法高亮、代码智能补全、插件扩展、代码对比等,…...
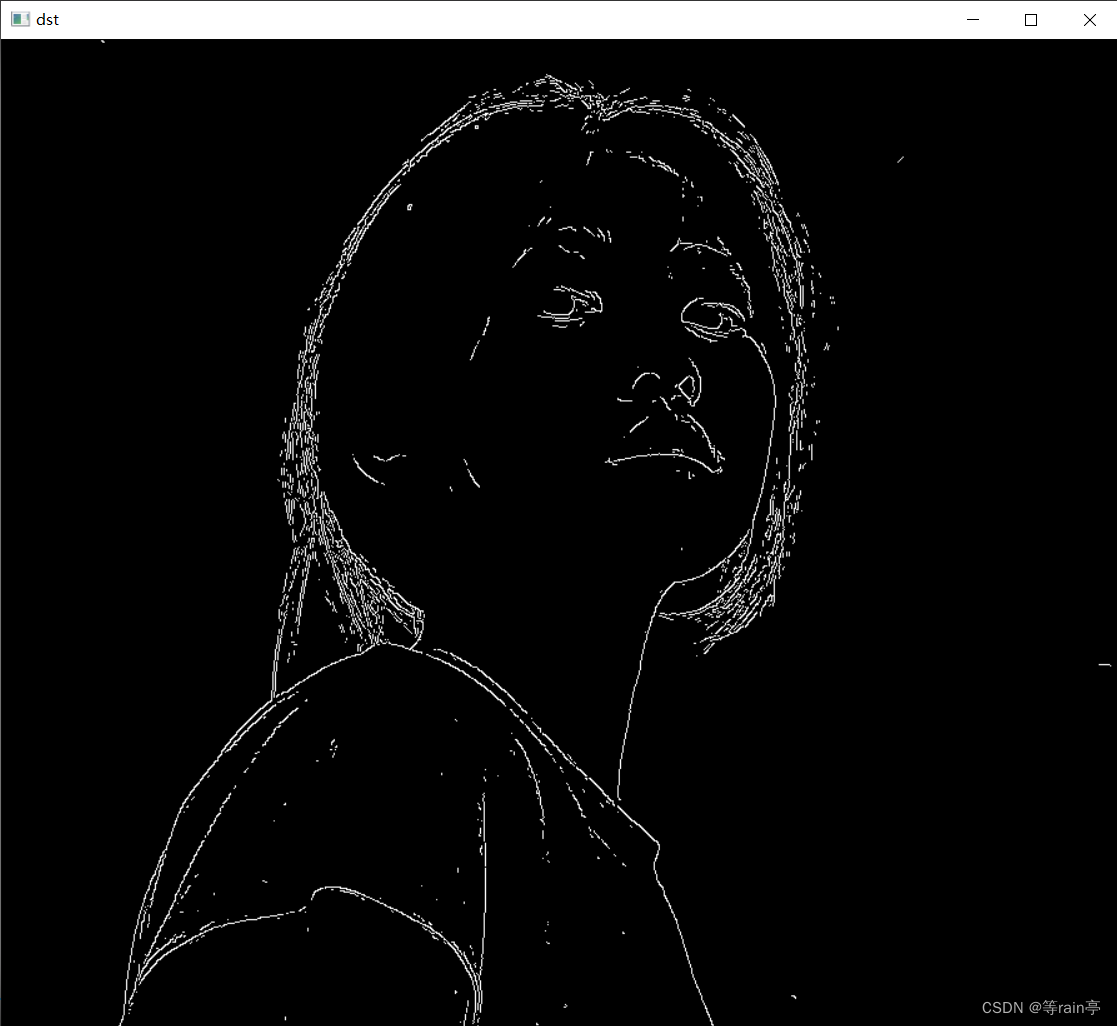
Opencv中的滤波器
一副图像通过滤波器得到另一张图像,其中滤波器又称为卷积核,滤波的过程称之为卷积。 这就是一个卷积的过程,通过一个卷积核得到另一张图片,明显发现新的到的图片边缘部分更加清晰了(锐化)。 上图就是一个卷…...

<JavaEE> 基于 TCP 的 Socket 通信模型
目录 一、认识相关API 1)ServerSocket 2)Socket 二、TCP字节流套接字通信模型概述 三、回显客户端-服务器 1)服务器代码 2)客户端代码 一、认识相关API 1)ServerSocket ServerSocket 常用构造方法ServerSocke…...
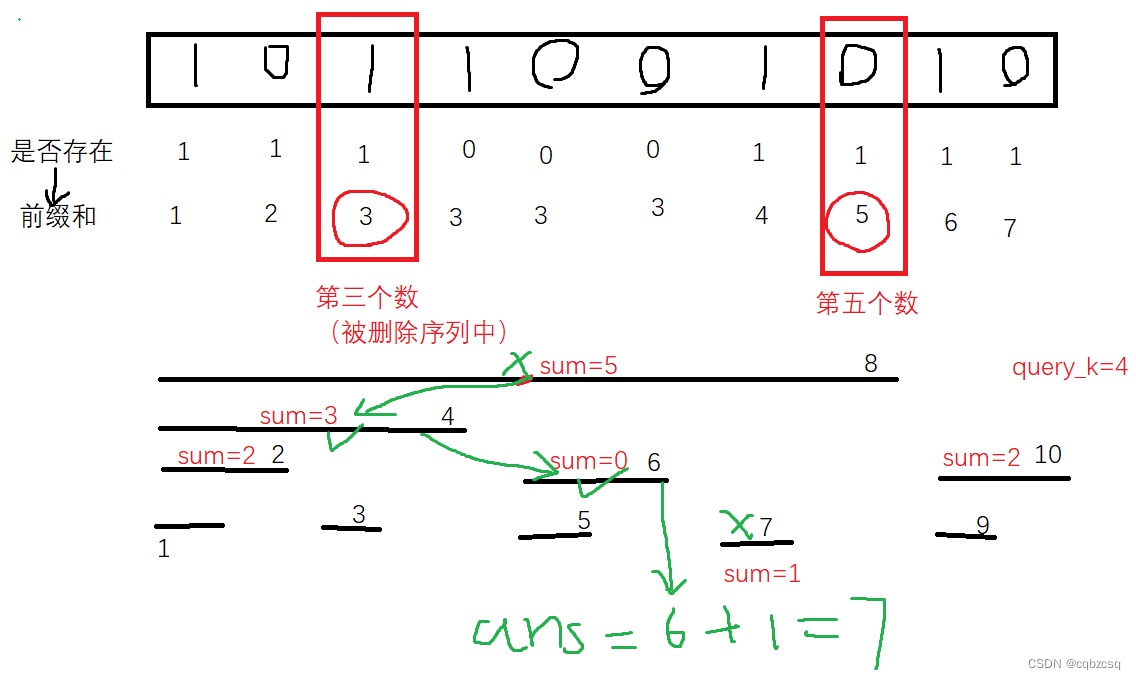
[THUPC 2024 初赛] 二进制 (树状数组单点删除+单点查询)(双堆模拟set)
题解 题目本身不难想 首先注意到所有查询的序列长度都是小于logn级别的 我们可以枚举序列长度len,然后用类似滑动窗口的方法,一次性预处理出每种字串的所有出现位置,也就是开N个set去维护所有的位置。预处理会进行O(logn)轮,每…...
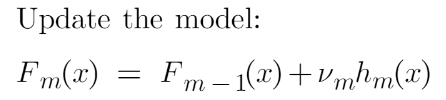
机器学习算法(11)——集成技术(Boosting——梯度提升)
一、说明 在在这篇文章中,我们学习了另一种称为梯度增强的集成技术。这是我在机器学习算法集成技术文章系列中与bagging一起介绍的一种增强技术。我还讨论了随机森林和 AdaBoost 算法。但在这里我们讨论的是梯度提升,在我们深入研究梯度提升之前…...

使用GBASE南大通用负载均衡连接池
若要使用负载均衡连接池功能,需要在连接串中配置相关的关键字。有关更详细的关键字信息在 GBASE南大通用 连接参数表‛中介绍。假设存在如下场景: 现有集群中存在 4 个节点: 192.168.9.173, 192.168.9.174, 192.168.9.175, 192.168.9.17…...
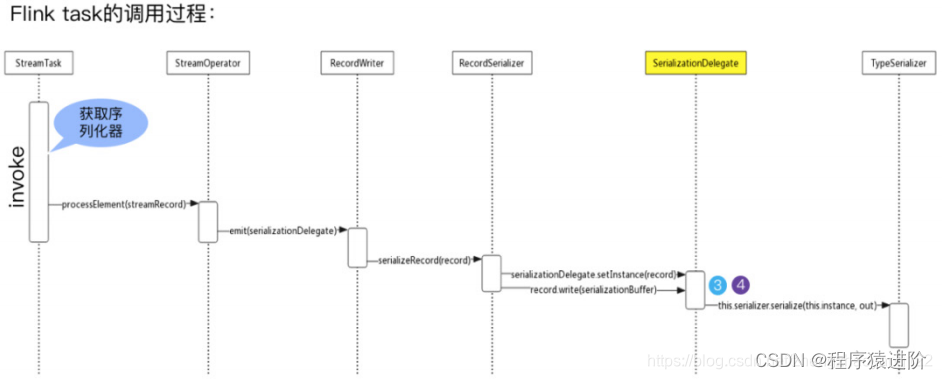
Flink 数据序列化
为 Flink 量身定制的序列化框架 大家都知道现在大数据生态非常火,大多数技术组件都是运行在JVM上的,Flink也是运行在JVM上,基于JVM的数据分析引擎都需要将大量的数据存储在内存中,这就不得不面临JVM的一些问题,比如Ja…...
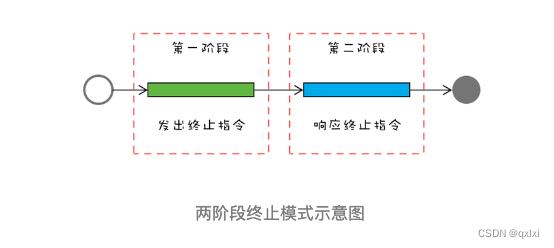
【并发设计模式】聊聊两阶段终止模式如何优雅终止线程
在软件设计中,抽象出了23种设计模式,用以解决对象的创建、组合、使用三种场景。在并发编程中,针对线程的操作,也抽象出对应的并发设计模式。 两阶段终止模式- 优雅停止线程避免共享的设计模式- 只读、Copy-on-write、Thread-Spec…...
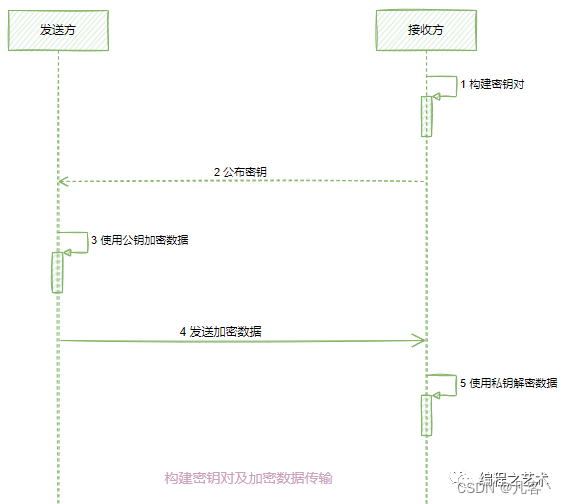
Java实现非对称加密【详解】
Java实现非对称加密 1. 简介2. 非对称加密算法--DH(密钥交换)3. 非对称加密算法--RSA非对称加密算法--EIGamal5. 总结6 案例6.1 案例16.2 案例2 1. 简介 公开密钥密码学(英语:Public-key cryptography)也称非对称式密…...

simulinkveristandlabview联合仿真——模型导入搭建人机界面
目录 1.软件版本 2.搭建simulink仿真模型 编译错误 3.导入veristand并建立工程 4.veristand导入labview labview显示veristand工程数据 labview设置veristand工程数据 运行labview工程 1.软件版本 matlab2020a,veristand2020 R4,labview2020 SP…...

【力扣100题】48.乘积最大子数组
题目描述 给你一个整数数组 nums,请你找出数组中乘积最大的非空连续子数组(该子数组中至少包含一个数字),并返回该子数组所对应的乘积。 测试用例的答案是一个 32 位整数。注意,一个只包含一个元素的数组的乘积就是这个…...

米尔MYS-8MMX开发板实战:从交叉编译到网络视频监控系统搭建
1. 开箱与初体验:米尔MYS-8MMX开发板印象作为一名在嵌入式领域摸爬滚打多年的开发者,拿到一块新的开发板,那种感觉就像老木匠看到一块上好的木料,总想立刻上手试试它的“成色”。米尔电子这次推出的MYS-8MMX开发板,基于…...

如何用Xenia Canary模拟器重温Xbox 360经典游戏?终极配置与优化指南
如何用Xenia Canary模拟器重温Xbox 360经典游戏?终极配置与优化指南 【免费下载链接】xenia-canary Xbox 360 Emulator Research Project 项目地址: https://gitcode.com/gh_mirrors/xe/xenia-canary Xenia Canary是一款免费开源的Xbox 360游戏模拟器&#…...

百度网盘秒传链接终极指南:免费在线转存、生成与转换全攻略
百度网盘秒传链接终极指南:免费在线转存、生成与转换全攻略 【免费下载链接】baidupan-rapidupload 百度网盘秒传链接转存/生成/转换 网页工具 (全平台可用) 项目地址: https://gitcode.com/gh_mirrors/bai/baidupan-rapidupload 还在为百度网盘文件分享的繁…...

如何快速上手CircuitJS1桌面版:离线电路仿真的终极指南
如何快速上手CircuitJS1桌面版:离线电路仿真的终极指南 【免费下载链接】circuitjs1 Standalone (offline) version of the Circuit Simulator with small modifications based on modified NW.js. 项目地址: https://gitcode.com/gh_mirrors/circ/circuitjs1 …...

ARMv8浮点运算单元与MVFR寄存器深度解析
1. ARMv8浮点运算单元架构解析在移动计算和嵌入式系统领域,ARMv8架构已经成为事实上的行业标准。作为其核心计算能力的重要组成部分,浮点运算单元(FPU)和高级SIMD(Neon)扩展的性能直接影响着机器学习、图形处理、科学计算等关键应用的执行效率。与x86架构…...

基于RAG与本地LLM的智能代码库管理工具部署与优化指南
1. 项目概述:一个为开发者打造的智能代码库管理工具最近在整理自己过去几年的项目代码时,我遇到了一个几乎所有开发者都会头疼的问题:代码库越来越多,但想快速找到某个特定功能的实现、或者想复用一段之前写过的优质代码时&#x…...

告别‘鬼影’与模糊:深入解读RangeNet++如何用高效kNN后处理搞定LiDAR语义分割的边界难题
RangeNet:用GPU加速的kNN后处理破解LiDAR语义分割的边界模糊难题 当自动驾驶车辆以每小时60公里的速度行驶时,每100毫秒的决策延迟意味着1.67米的盲区——这恰好是许多交通事故发生的临界距离。在LiDAR语义分割领域,传统方法在点云投影与反投…...

教育大模型EduChat:从部署到应用的全链路实践指南
1. 项目概述:当教育遇上大语言模型 作为一名长期关注教育技术与人工智能交叉领域的研究者和实践者,我见证过太多“AI教育”的概念从喧嚣到沉寂。直到最近几年,以ChatGPT为代表的大语言模型(LLM)横空出世,才…...

GitHub个人访问令牌实战:告别密码认证,安全推送代码与创建PR
1. 项目概述与核心痛点如果你刚开始接触开源贡献,或者最近在尝试向GitHub推送代码时,大概率会遇到一个令人困惑的拦路虎:在终端执行git push命令后,系统提示你输入用户名和密码。你很自然地输入了登录GitHub网站用的账号密码&…...