03|模型I/O:输入提示、调用模型、解析输出
03|模型I/O:输入提示、调用模型、解析输出
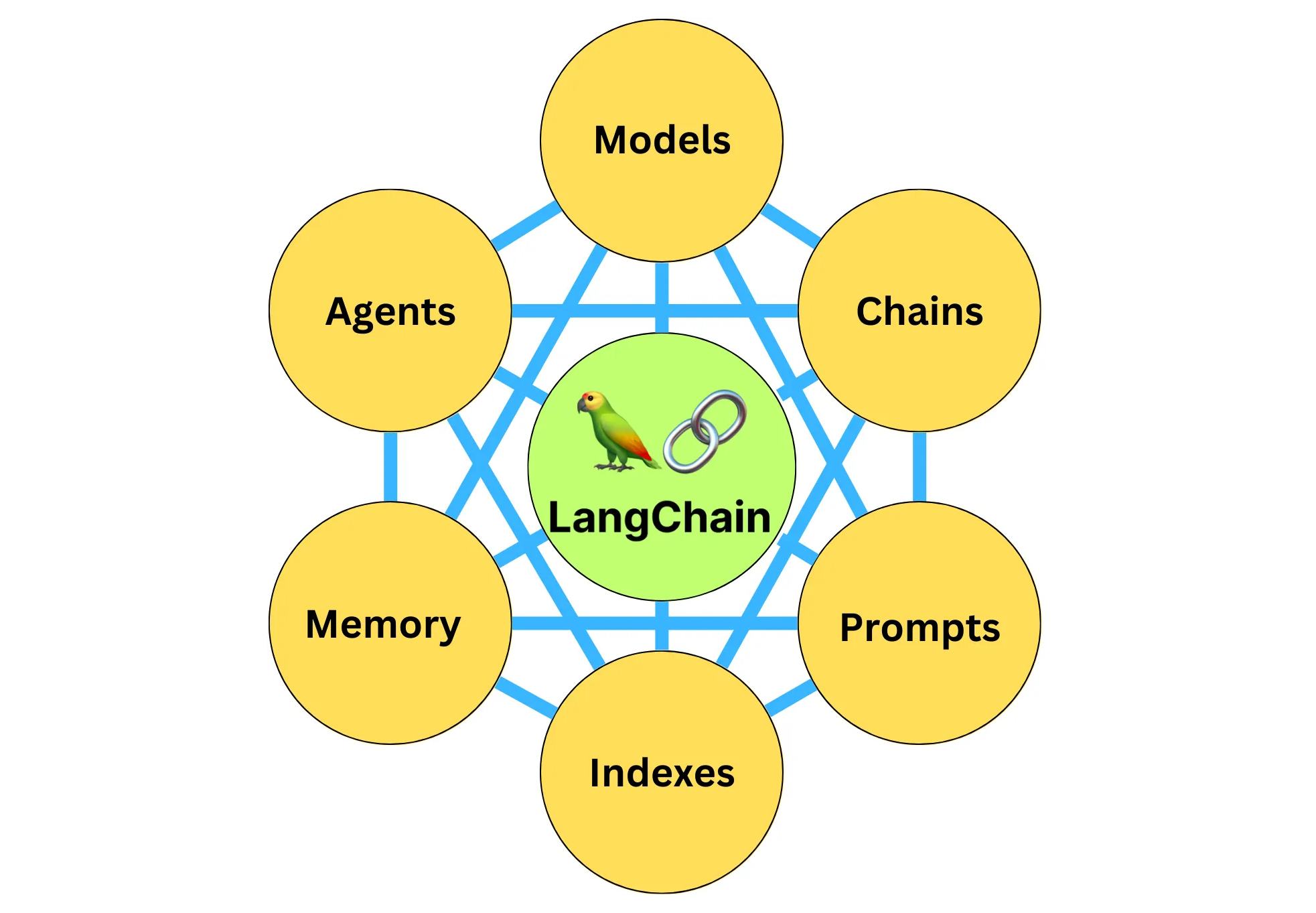
从这节课开始,我们将对 LangChain 中的六大核心组件一一进行详细的剖析。
模型,位于 LangChain 框架的最底层,它是基于语言模型构建的应用的核心元素,因为所谓 LangChain 应用开发,就是以 LangChain 作为框架,通过 API 调用大模型来解决具体问题的过程。
可以说,整个 LangChain 框架的逻辑都是由 LLM 这个发动机来驱动的。没有模型,LangChain 这个框架也就失去了它存在的意义。那么这节课我们就详细讲讲模型,最后你会收获一个能够自动生成鲜花文案的应用程序。
Model I/O
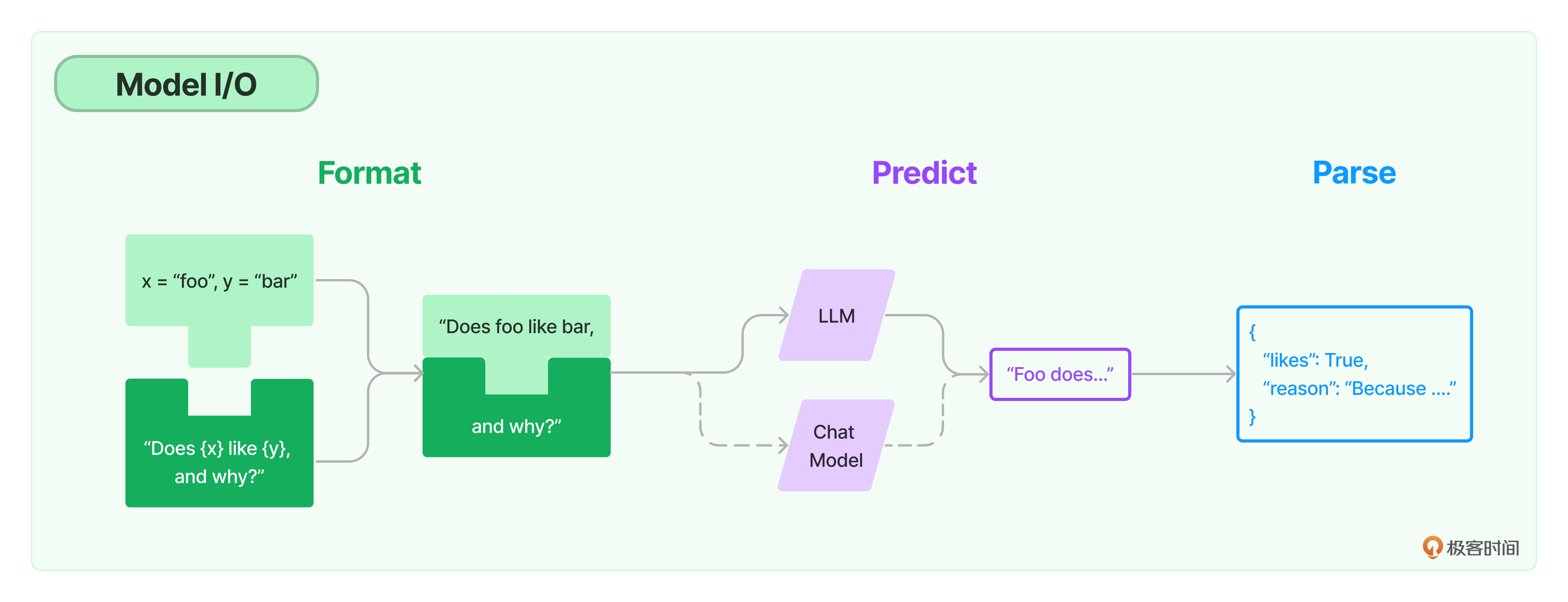
我们可以把对模型的使用过程拆解成三块,分别是输入提示(对应图中的 Format)、调用模型(对应图中的 Predict)和输出解析(对应图中的 Parse)。这三块形成了一个整体,因此在 LangChain 中这个过程被统称为 Model I/O(Input/Output)。
Model I/O:从输入到输出
在模型 I/O 的每个环节,LangChain 都为咱们提供了模板和工具,快捷地形成调用各种语言模型的接口。
- 提示模板:使用模型的第一个环节是把提示信息输入到模型中,你可以创建 LangChain 模板,根据实际需求动态选择不同的输入,针对特定的任务和应用调整输入。
- 语言模型:LangChain 允许你通过通用接口来调用语言模型。这意味着无论你要使用的是哪种语言模型,都可以通过同一种方式进行调用,这样就提高了灵活性和便利性。
- 输出解析:LangChain 还提供了从模型输出中提取信息的功能。通过输出解析器,你可以精确地从模型的输出中获取需要的信息,而不需要处理冗余或不相关的数据,更重要的是还可以把大模型给回的非结构化文本,转换成程序可以处理的结构化数据。
下面我们用示例的方式来深挖一下这三个环节。先来看看 LangChain 中提示模板的构建。
提示模板
语言模型是个无穷无尽的宝藏,人类的知识和智慧,好像都封装在了这个“魔盒”里面了。但是,怎样才能解锁其中的奥秘,那可就是仁者见仁智者见智了。所以,现在“提示工程”这个词特别流行,所谓 Prompt Engineering,就是专门研究对大语言模型的提示构建。
我的观点是,使用大模型的场景千差万别,因此肯定不存在那么一两个神奇的模板,能够骗过所有模型,让它总能给你最想要的回答。然而,好的提示(其实也就是好的问题或指示啦),肯定能够让你在调用语言模型的时候事半功倍。
那其中的具体原则,不外乎吴恩达老师在他的提示工程课程中所说的:
- 给予模型清晰明确的指示
- 让模型慢慢地思考
说起来很简单,对吧?是的,道理总是简单,但是如何具体实践这些原则,又是个大问题。让我从创建一个简单的 LangChain 提示模板开始。
这里,我们希望为销售的每一种鲜花生成一段简介文案,那么每当你的员工或者顾客想了解某种鲜花时,调用该模板就会生成适合的文字。
这个提示模板的生成方式如下:
# 导入LangChain中的提示模板
from langchain import PromptTemplate
# 创建原始模板
template = """您是一位专业的鲜花店文案撰写员。\n
对于售价为 {price} 元的 {flower_name} ,您能提供一个吸引人的简短描述吗?
"""
# 根据原始模板创建LangChain提示模板
prompt = PromptTemplate.from_template(template)
# 打印LangChain提示模板的内容
print(prompt)提示模板的具体内容如下:
input_variables=['flower_name', 'price']
output_parser=None partial_variables={}
template='/\n您是一位专业的鲜花店文案撰写员。
\n对于售价为 {price} 元的 {flower_name} ,您能提供一个吸引人的简短描述吗?\n'
template_format='f-string'
validate_template=True在这里,所谓“模板”就是一段描述某种鲜花的文本格式,它是一个 f-string,其中有两个变量 {flower_name} 和 {price} 表示花的名称和价格,这两个值是模板里面的占位符,在实际使用模板生成提示时会被具体的值替换。
代码中的 from_template 是一个类方法,它允许我们直接从一个字符串模板中创建一个 PromptTemplate 对象。打印出这个 PromptTemplate 对象,你可以看到这个对象中的信息包括输入的变量(在这个例子中就是 flower_name 和 price)、输出解析器(这个例子中没有指定)、模板的格式(这个例子中为'f-string')、是否验证模板(这个例子中设置为 True)。
因此 PromptTemplate 的 from_template 方法就是将一个原始的模板字符串转化为一个更丰富、更方便操作的 PromptTemplate 对象,这个对象就是 LangChain 中的提示模板。LangChain 提供了多个类和函数,也为各种应用场景设计了很多内置模板,使构建和使用提示变得容易。我们下节课还会对提示工程的基本原理和 LangChain 中的各种提示模板做更深入的讲解。
下面,我们将会使用这个刚刚构建好的提示模板来生成提示,并把提示输入到大语言模型中。
语言模型
LangChain 中支持的模型有三大类。
- 大语言模型(LLM) ,也叫 Text Model,这些模型将文本字符串作为输入,并返回文本字符串作为输出。Open AI 的 text-davinci-003、Facebook 的 LLaMA、ANTHROPIC 的 Claude,都是典型的 LLM。
- 聊天模型(Chat Model),主要代表 Open AI 的 ChatGPT 系列模型。这些模型通常由语言模型支持,但它们的 API 更加结构化。具体来说,这些模型将聊天消息列表作为输入,并返回聊天消息。
- 文本嵌入模型(Embedding Model),这些模型将文本作为输入并返回浮点数列表,也就是 Embedding。而文本嵌入模型如 OpenAI 的 text-embedding-ada-002,我们之前已经见过了。文本嵌入模型负责把文档存入向量数据库,和我们这里探讨的提示工程关系不大。
然后,我们将调用语言模型,让模型帮我们写文案,并且返回文案的结果。
# 设置OpenAI API Key
import os
os.environ["OPENAI_API_KEY"] = '你的Open AI API Key'# 导入LangChain中的OpenAI模型接口
from langchain import OpenAI
# 创建模型实例
model = OpenAI(model_name='text-davinci-003')
# 输入提示
input = prompt.format(flower_name=["玫瑰"], price='50')
# 得到模型的输出
output = model(input)
# 打印输出内容
print(output) input = prompt.format(flower_name=["玫瑰"], price='50') 这行代码的作用是将模板实例化,此时将 {flower_name} 替换为 "玫瑰",{price} 替换为 '50',形成了具体的提示:“您是一位专业的鲜花店文案撰写员。对于售价为 50 元的玫瑰,您能提供一个吸引人的简短描述吗?”
接收到这个输入,调用模型之后,得到的输出如下:
让你心动!50元就可以拥有这支充满浪漫气息的玫瑰花束,让TA感受你的真心爱意。
复用提示模板,我们可以同时生成多个鲜花的文案。
# 导入LangChain中的提示模板
from langchain import PromptTemplate
# 创建原始模板
template = """您是一位专业的鲜花店文案撰写员。\n
对于售价为 {price} 元的 {flower_name} ,您能提供一个吸引人的简短描述吗?
"""
# 根据原始模板创建LangChain提示模板
prompt = PromptTemplate.from_template(template)
# 打印LangChain提示模板的内容
print(prompt)# 设置OpenAI API Key
import os
os.environ["OPENAI_API_KEY"] = '你的Open AI API Key'# 导入LangChain中的OpenAI模型接口
from langchain import OpenAI
# 创建模型实例
model = OpenAI(model_name='text-davinci-003')# 多种花的列表
flowers = ["玫瑰", "百合", "康乃馨"]
prices = ["50", "30", "20"]# 生成多种花的文案
for flower, price in zip(flowers, prices):# 使用提示模板生成输入input_prompt = prompt.format(flower_name=flower, price=price)# 得到模型的输出output = model(input_prompt)# 打印输出内容print(output)模型的输出如下:
这支玫瑰,深邃的红色,传递着浓浓的深情与浪漫,令人回味无穷!百合:美丽的花朵,多彩的爱恋!30元让你拥有它!康乃馨—20元,象征爱的祝福,送给你最真挚的祝福。
你也许会问我,在这个过程中,使用 LangChain 的意义究竟何在呢?我直接调用 Open AI 的 API,不是完全可以实现相同的功能吗?
的确如此,让我们来看看直接使用 Open AI API 来完成上述功能的代码。
import openai # 导入OpenAI
openai.api_key = 'Your-OpenAI-API-Key' # API Keyprompt_text = "您是一位专业的鲜花店文案撰写员。对于售价为{}元的{},您能提供一个吸引人的简短描述吗?" # 设置提示flowers = ["玫瑰", "百合", "康乃馨"]
prices = ["50", "30", "20"]# 循环调用Text模型的Completion方法,生成文案
for flower, price in zip(flowers, prices):prompt = prompt_text.format(price, flower)response = openai.Completion.create(engine="text-davinci-003",prompt=prompt,max_tokens=100)print(response.choices[0].text.strip()) # 输出文案上面的代码是直接使用 Open AI 和带有 {} 占位符的提示语,同时生成了三种鲜花的文案。看起来也是相当简洁。
不过,如果你深入思考一下,你就会发现 LangChain 的优势所在。**我们只需要定义一次模板,就可以用它来生成各种不同的提示。**对比单纯使用 f-string 来格式化文本,这种方法更加简洁,也更容易维护。而 LangChain 在提示模板中,还整合了 output_parser、template_format 以及是否需要 validate_template 等功能。
更重要的是,使用 LangChain 提示模板,我们还可以很方便地把程序切换到不同的模型,而不需要修改任何提示相关的代码。
下面,我们用完全相同的提示模板来生成提示,并发送给 HuggingFaceHub 中的开源模型来创建文案。(注意:需要注册 HUGGINGFACEHUB_API_TOKEN)
# 导入LangChain中的提示模板
from langchain import PromptTemplate
# 创建原始模板
template = """You are a flower shop assitiant。\n
For {price} of {flower_name} ,can you write something for me?
"""
# 根据原始模板创建LangChain提示模板
prompt = PromptTemplate.from_template(template)
# 打印LangChain提示模板的内容
print(prompt)
import os
os.environ['HUGGINGFACEHUB_API_TOKEN'] = '你的HuggingFace API Token'
# 导入LangChain中的OpenAI模型接口
from langchain import HuggingFaceHub
# 创建模型实例
model= HuggingFaceHub(repo_id="google/flan-t5-large")
# 输入提示
input = prompt.format(flower_name=["rose"], price='50')
# 得到模型的输出
output = model(input)
# 打印输出内容
print(output)输出:
i love you
真是一分钱一分货,当我使用较早期的开源模型 T5,得到了很粗糙的文案 “i love you”(哦,还要注意 T5 还没有支持中文的能力,我把提示文字换成英文句子,结构其实都没变)。
当然,这里我想要向你传递的信息是:你可以重用模板,重用程序结构,通过 LangChain 框架调用任何模型。如果你熟悉机器学习的训练流程的话,这 LangChain 是不是让你联想到 PyTorch 和 TensorFlow 这样的框架——模型可以自由选择、自主训练,而调用模型的框架往往是有章法、而且可复用的。
因此,使用 LangChain 和提示模板的好处是:
- 代码的可读性:使用模板的话,提示文本更易于阅读和理解,特别是对于复杂的提示或多变量的情况。
- 可复用性:模板可以在多个地方被复用,让你的代码更简洁,不需要在每个需要生成提示的地方重新构造提示字符串。
- 维护:如果你在后续需要修改提示,使用模板的话,只需要修改模板就可以了,而不需要在代码中查找所有使用到该提示的地方进行修改。
- 变量处理:如果你的提示中涉及到多个变量,模板可以自动处理变量的插入,不需要手动拼接字符串。
- 参数化:模板可以根据不同的参数生成不同的提示,这对于个性化生成文本非常有用。
那我们就接着介绍模型 I/O 的最后一步,输出解析。
输出解析
LangChain 提供的解析模型输出的功能,使你能够更容易地从模型输出中获取结构化的信息,这将大大加快基于语言模型进行应用开发的效率。
为什么这么说呢?请你思考一下刚才的例子,你只是让模型生成了一个文案。这段文字是一段字符串,正是你所需要的。但是,在开发具体应用的过程中,很明显我们不仅仅需要文字,更多情况下我们需要的是程序能够直接处理的、结构化的数据。
比如说,在这个文案中,如果你希望模型返回两个字段:
- description:鲜花的说明文本
- reason:解释一下为何要这样写上面的文案
那么,模型可能返回的一种结果是:
A:“文案是:让你心动!50 元就可以拥有这支充满浪漫气息的玫瑰花束,让 TA 感受你的真心爱意。为什么这样说呢?因为爱情是无价的,50 元对应热恋中的情侣也会觉得值得。”
上面的回答并不是我们在处理数据时所需要的,我们需要的是一个类似于下面的 Python 字典。
B:{description: “让你心动!50 元就可以拥有这支充满浪漫气息的玫瑰花束,让 TA 感受你的真心爱意。” ; reason: “因为爱情是无价的,50 元对应热恋中的情侣也会觉得值得。”}
那么从 A 的笼统言语,到 B 这种结构清晰的数据结构,如何自动实现?这就需要 LangChain 中的输出解析器上场了。
下面,我们就通过 LangChain 的输出解析器来重构程序,让模型有能力生成结构化的回应,同时对其进行解析,直接将解析好的数据存入 CSV 文档。
# 通过LangChain调用模型
from langchain import PromptTemplate, OpenAI# 导入OpenAI Key
import os
os.environ["OPENAI_API_KEY"] = '你的OpenAI API Key'# 创建原始提示模板
prompt_template = """您是一位专业的鲜花店文案撰写员。
对于售价为 {price} 元的 {flower_name} ,您能提供一个吸引人的简短描述吗?
{format_instructions}"""# 创建模型实例
model = OpenAI(model_name='text-davinci-003')# 导入结构化输出解析器和ResponseSchema
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
# 定义我们想要接收的响应模式
response_schemas = [ResponseSchema(name="description", description="鲜花的描述文案"),ResponseSchema(name="reason", description="问什么要这样写这个文案")
]
# 创建输出解析器
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)# 获取格式指示
format_instructions = output_parser.get_format_instructions()
# 根据原始模板创建提示,同时在提示中加入输出解析器的说明
prompt = PromptTemplate.from_template(prompt_template, partial_variables={"format_instructions": format_instructions}) # 数据准备
flowers = ["玫瑰", "百合", "康乃馨"]
prices = ["50", "30", "20"]# 创建一个空的DataFrame用于存储结果
import pandas as pd
df = pd.DataFrame(columns=["flower", "price", "description", "reason"]) # 先声明列名for flower, price in zip(flowers, prices):# 根据提示准备模型的输入input = prompt.format(flower_name=flower, price=price)# 获取模型的输出output = model(input)# 解析模型的输出(这是一个字典结构)parsed_output = output_parser.parse(output)# 在解析后的输出中添加“flower”和“price”parsed_output['flower'] = flowerparsed_output['price'] = price# 将解析后的输出添加到DataFrame中df.loc[len(df)] = parsed_output # 打印字典
print(df.to_dict(orient='records'))# 保存DataFrame到CSV文件
df.to_csv("flowers_with_descriptions.csv", index=False)输出:
[{'flower': '玫瑰', 'price': '50', 'description': 'Luxuriate in the beauty of this 50 yuan rose, with its deep red petals and delicate aroma.', 'reason': 'This description emphasizes the elegance and beauty of the rose, which will be sure to draw attention.'},
{'flower': '百合', 'price': '30', 'description': '30元的百合,象征着坚定的爱情,带给你的是温暖而持久的情感!', 'reason': '百合是象征爱情的花,写出这样的描述能让顾客更容易感受到百合所带来的爱意。'},
{'flower': '康乃馨', 'price': '20', 'description': 'This beautiful carnation is the perfect way to show your love and appreciation. Its vibrant pink color is sure to brighten up any room!', 'reason': 'The description is short, clear and appealing, emphasizing the beauty and color of the carnation while also invoking a sense of love and appreciation.'}]
这段代码中,首先定义输出结构,我们希望模型生成的答案包含两部分:鲜花的描述文案(description)和撰写这个文案的原因(reason)。所以我们定义了一个名为 response_schemas 的列表,其中包含两个 ResponseSchema 对象,分别对应这两部分的输出。
根据这个列表,我通过 StructuredOutputParser.from_response_schemas 方法创建了一个输出解析器。
然后,我们通过输出解析器对象的 get_format_instructions() 方法获取输出的格式说明(format_instructions),再根据原始的字符串模板和输出解析器格式说明创建新的提示模板(这个模板就整合了输出解析结构信息)。再通过新的模板生成模型的输入,得到模型的输出。此时模型的输出结构将尽最大可能遵循我们的指示,以便于输出解析器进行解析。
对于每一个鲜花和价格组合,我们都用 output_parser.parse(output) 把模型输出的文案解析成之前定义好的数据格式,也就是一个 Python 字典,这个字典中包含了 description 和 reason 这两个字段的值。
parsed_output
{'description': 'This 50-yuan rose is... feelings.', 'reason': 'The description is s...y emotion.'}
len(): 2最后,把所有信息整合到一个 pandas DataFrame 对象中(需要安装 Pandas 库)。这个 DataFrame 对象中包含了 flower、price、description 和 reason 这四个字段的值。其中,description 和 reason 是由 output_parser 从模型的输出中解析出来的,flower 和 price 是我们自己添加的。
我们可以打印出 DataFrame 的内容,也方便地在程序中处理它,比如保存为下面的 CSV 文件。因为此时数据不再是模糊的、无结构的文本,而是结构清晰的有格式的数据。输出解析器在这个过程中的功劳很大。

相关文章:
03|模型I/O:输入提示、调用模型、解析输出
03|模型I/O:输入提示、调用模型、解析输出 从这节课开始,我们将对 LangChain 中的六大核心组件一一进行详细的剖析。 模型,位于 LangChain 框架的最底层,它是基于语言模型构建的应用的核心元素,因为所谓 …...
springcloud-gateway-2-鉴权
目录 一、跨域安全设置 二、GlobalFilter实现全局的过滤与拦截。 三、GatewayFilter单个服务过滤器 1、原理-官方内置过滤器 2、自定义过滤器-TokenAuthGatewayFilterFactory 3、完善TokenAuthGatewayFilterFactory的功能 4、每一个服务编写一个或多个过滤器,…...

实现一个最简单的内核
更好的阅读体验,请点击 YinKai s Blog | 实现一个最简单的内核。 这篇文章带大家实现一个最简单的操作系统内核—— Hello OS。 PC 机的引导流程 我们这里将借助 Ubuntu Linux 操纵系统上的 GRUB 引导程序来引导我们的 Hello OS。 首先我们得了解一下&a…...

2024华为OD机试真题指南宝典—持续更新(JAVAPythonC++JS)【彻底搞懂算法和数据结构—算法之翼】
PC端可直接搜索关键词 快捷键:CtrlF 年份关键字、题目关键字等等 注意看本文目录-快速了解本专栏 文章目录 🐱2024年华为OD机试真题(马上更新)🐹2023年华为OD机试真题(更新中)🐶新…...
【12.23】转行小白历险记-算法02
不会算法的小白不是好小白,可恶还有什么可以难倒我这个美女的,不做花瓶第二天! 一、螺旋矩阵 59. 螺旋矩阵 II - 力扣(LeetCode) 1.核心思路:确定循环的路线,左闭右开循环,思路简…...

k8s部署nginx-ingress服务
k8s部署nginx-ingress服务 经过大佬的拷打,终于把这块的内容配置完成了。 首先去 nginx-ingress官网查看相关内容。 核心就是这个: kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.8.2/deploy/static/prov…...
SpringBoot Elasticsearch全文搜索
文章目录 概念全文搜索相关技术Elasticsearch概念近实时索引类型文档分片(Shard)和副本(Replica) 下载启用SpringBoot整合引入依赖创建文档类创建资源库测试文件初始化数据创建控制器 问题参考 概念 全文搜索(检索),工作原理:计算…...

Python 常用模块re
Python 常用模块re 【一】正则表达式 【1】说明 正则表达式是一种强大的文本匹配和处理工具,主要用于字符串的模式匹配、搜索和替换。正则表达式测试网址:正则表达式在线测试 正则表达式手册:正则表达式手册 【2】字符组 字符转使用[]表…...

【华为OD题库-106】全排列-java
题目 给定一个只包含大写英文字母的字符串S,要求你给出对S重新排列的所有不相同的排列数。如:S为ABA,则不同的排列有ABA、AAB、BAA三种。 解答要求 时间限制:5000ms,内存限制:100MB 输入描述 输入一个长度不超过10的字符串S,确保都是大写的。…...
)
Three.js 详细解析(持续更新)
1、简介; Three.js依赖一些要素,第一是scene,第二是render,第三是carmea npm install --save three import * as THREE from "three"; import { GLTFLoader } from "three/examples/jsm/loaders/GLTFLoader.js&quo…...
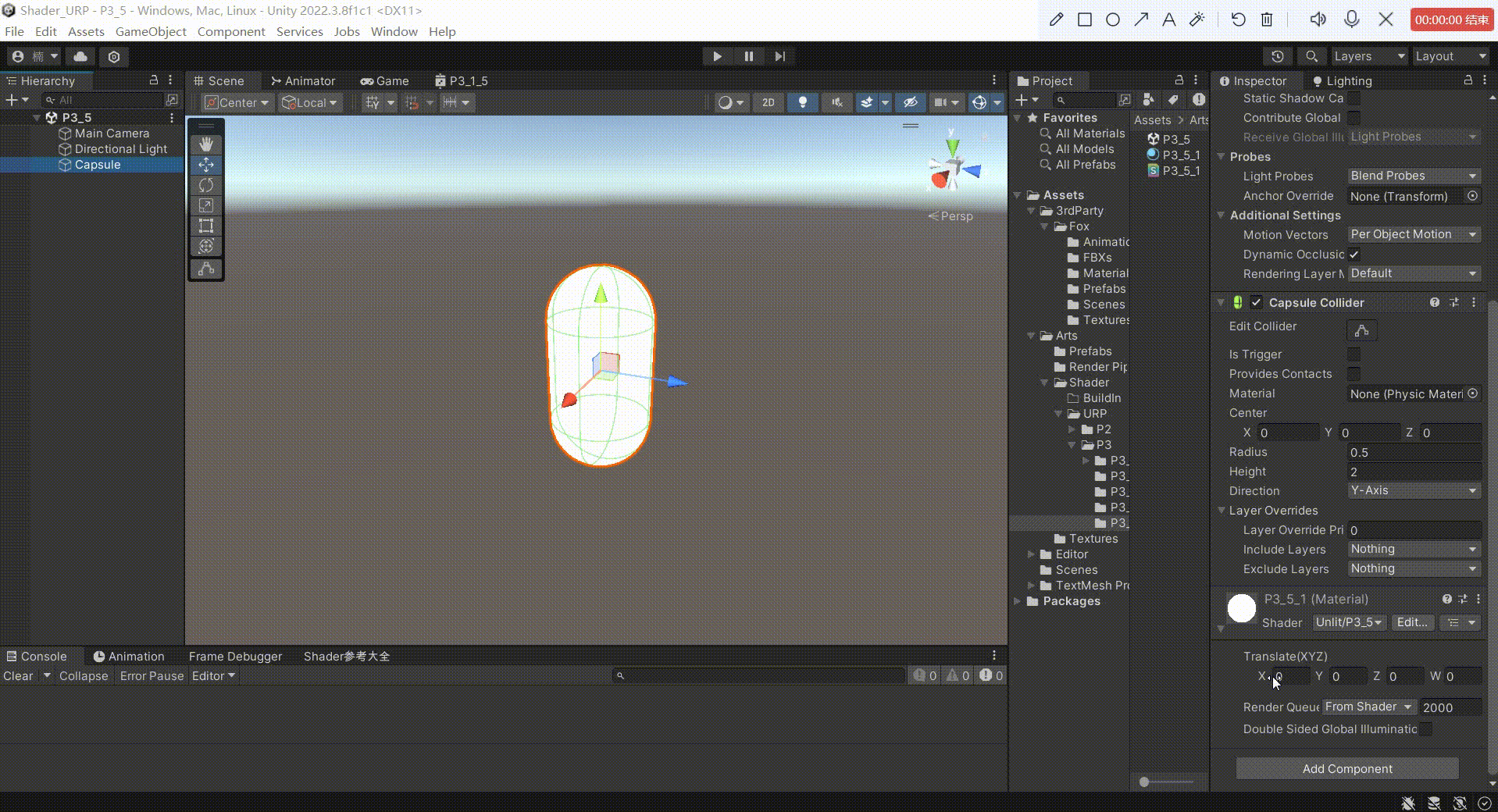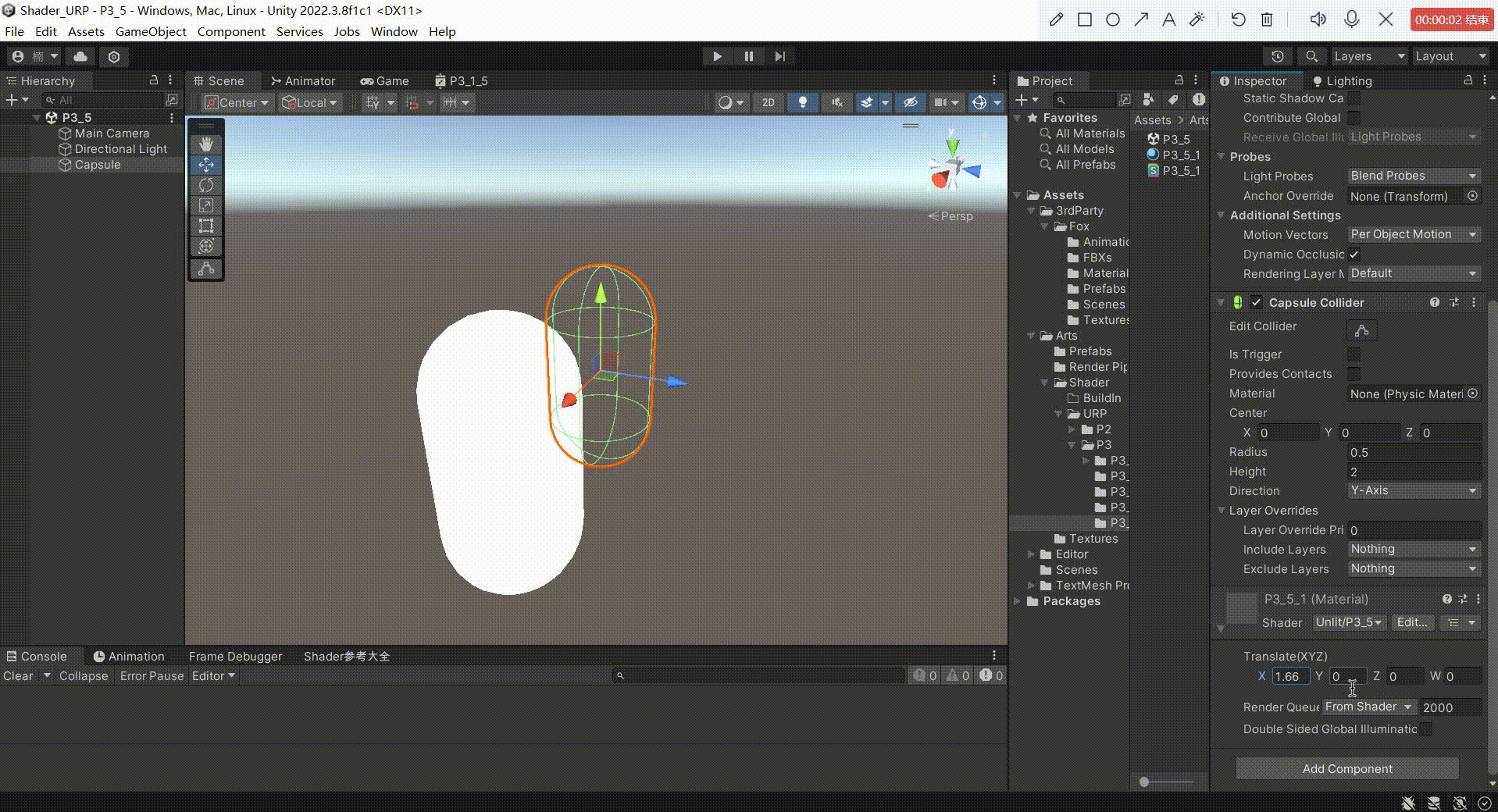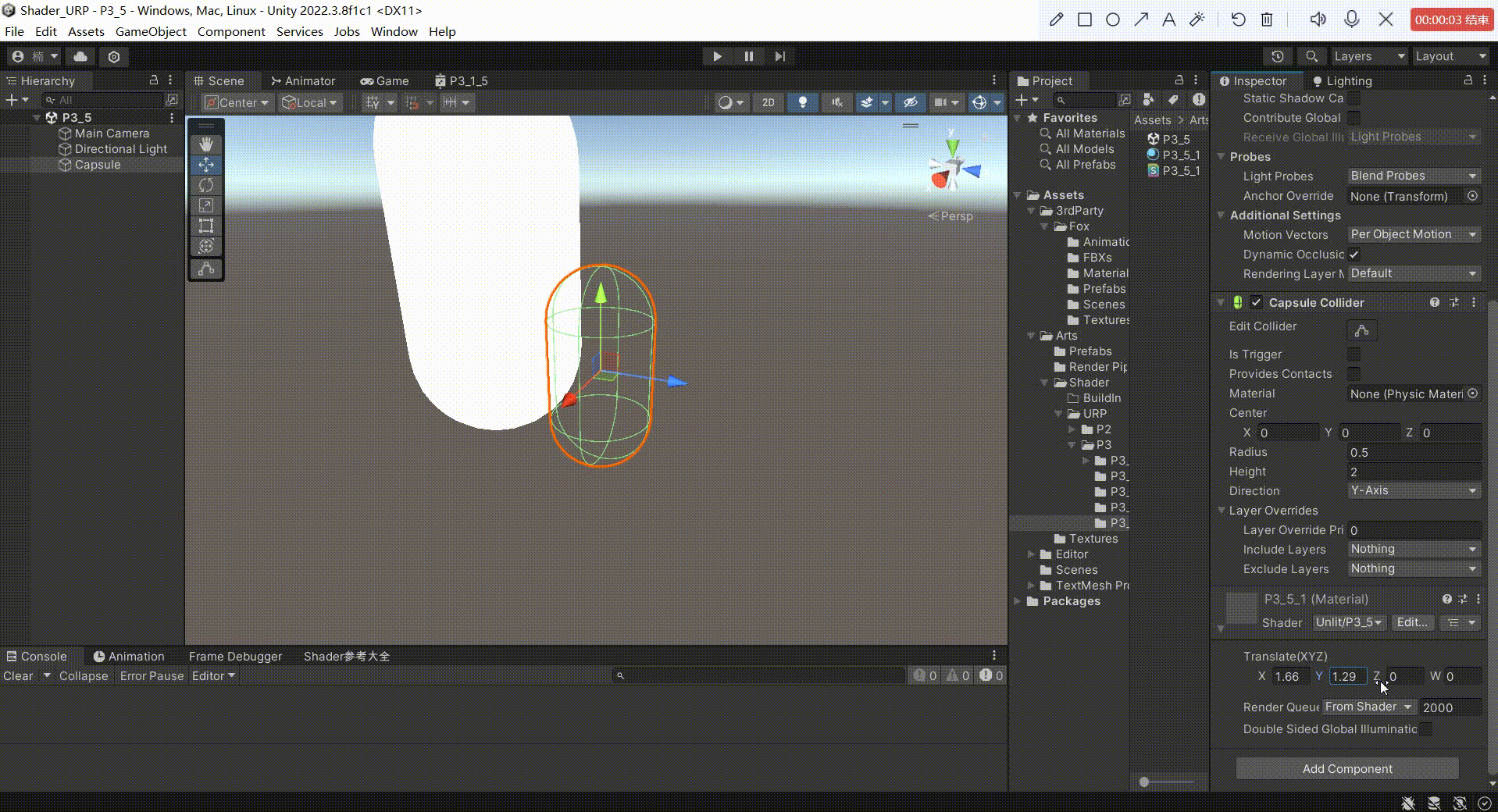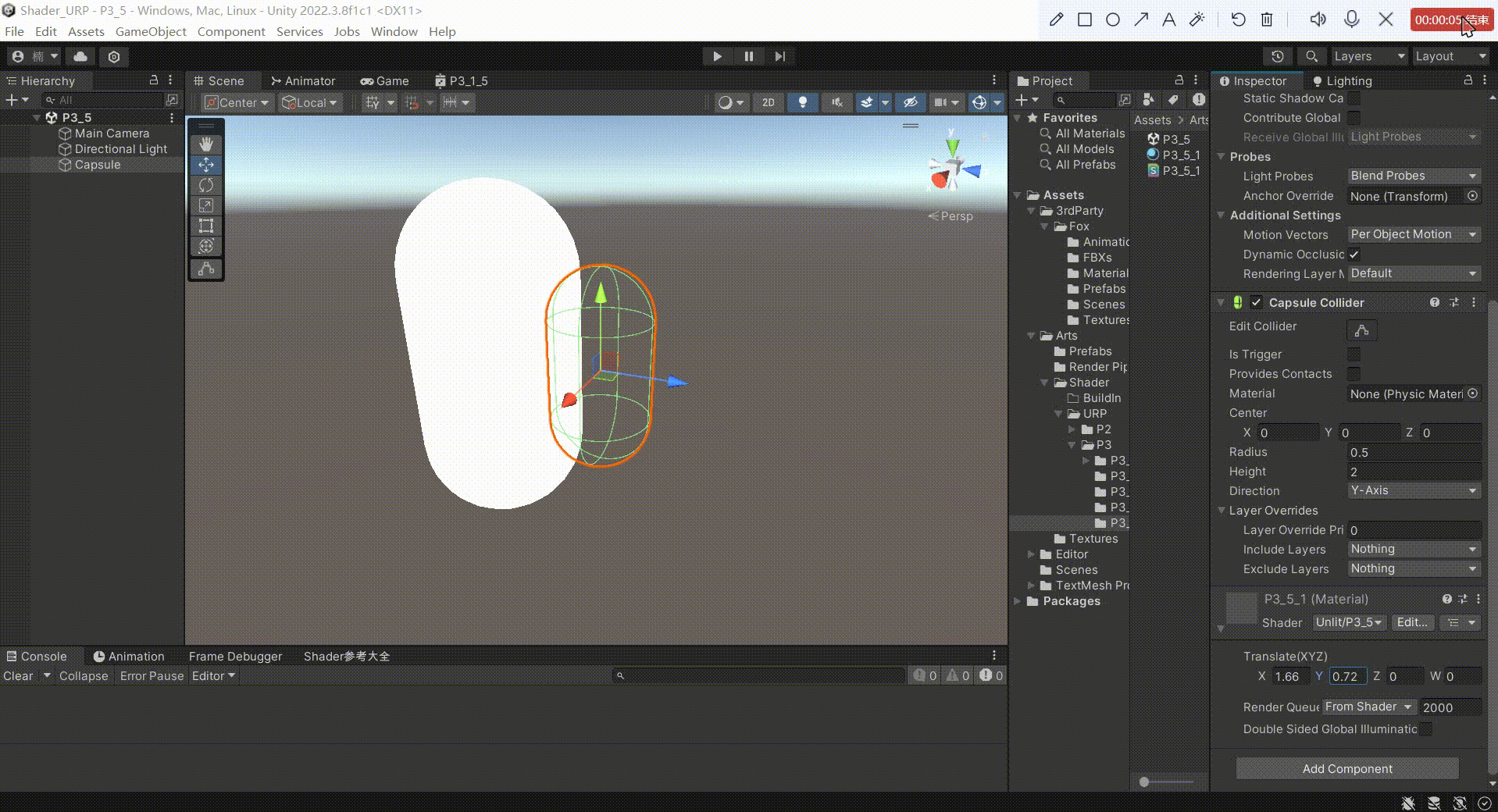
Unity中Shader平移矩阵
文章目录 前言方式一:对顶点本地空间下的坐标进行相加平移1、在属性面板定义一个四维变量记录在 xyz 上平移多少。2、在常量缓冲区进行申明3、在顶点着色器中,在进行其他坐标转化之前,对模型顶点本地空间下的坐标进行转化4、我们来看看效果 方…...

python dash 的学习笔记1
dash 用python开发web界面 https://dash.plotly.com/ 官方上支持jula F# python一类。当然我只会python只学习python中使用dash. 要做一个APP,用php,java以及.net都可以写,只所有选择python是因为最近在用这一个。同时也发现python除了慢全是优点。 资料…...

SQLITE如何同时查询出第一条和最后一条两条记录
一个时间记录表,需要同时得到整个表或一段时间内第一条和最后一条两条记录,按如下方法会提示错误:ORDER BY clause should come after UNION not before select * from sdayXX order by op_date asc limit 1 union select * from sday…...
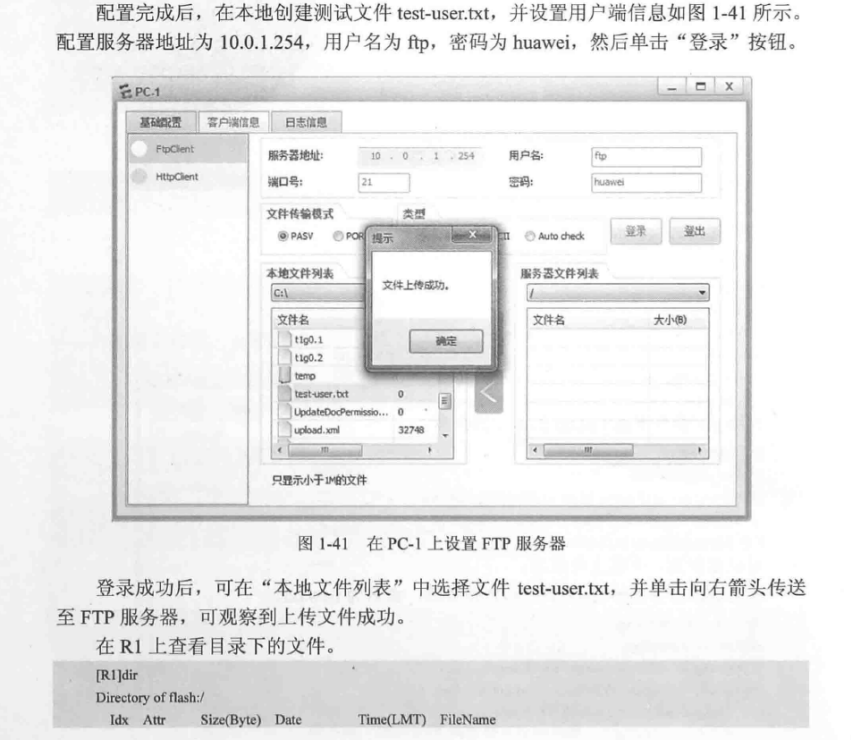
四、ensp配置ftp服务器实验
文章目录 实验内容实验拓扑操作步骤配置路由器为ftp server 实验内容 本实验模拟企业网络。PC-1为FTP 用户端设备,需要访问FTP Server,从服务器上下载或上传文件。出于安全角度考虑,为防止服务器被病毒文件感染,不允许用户端直接…...
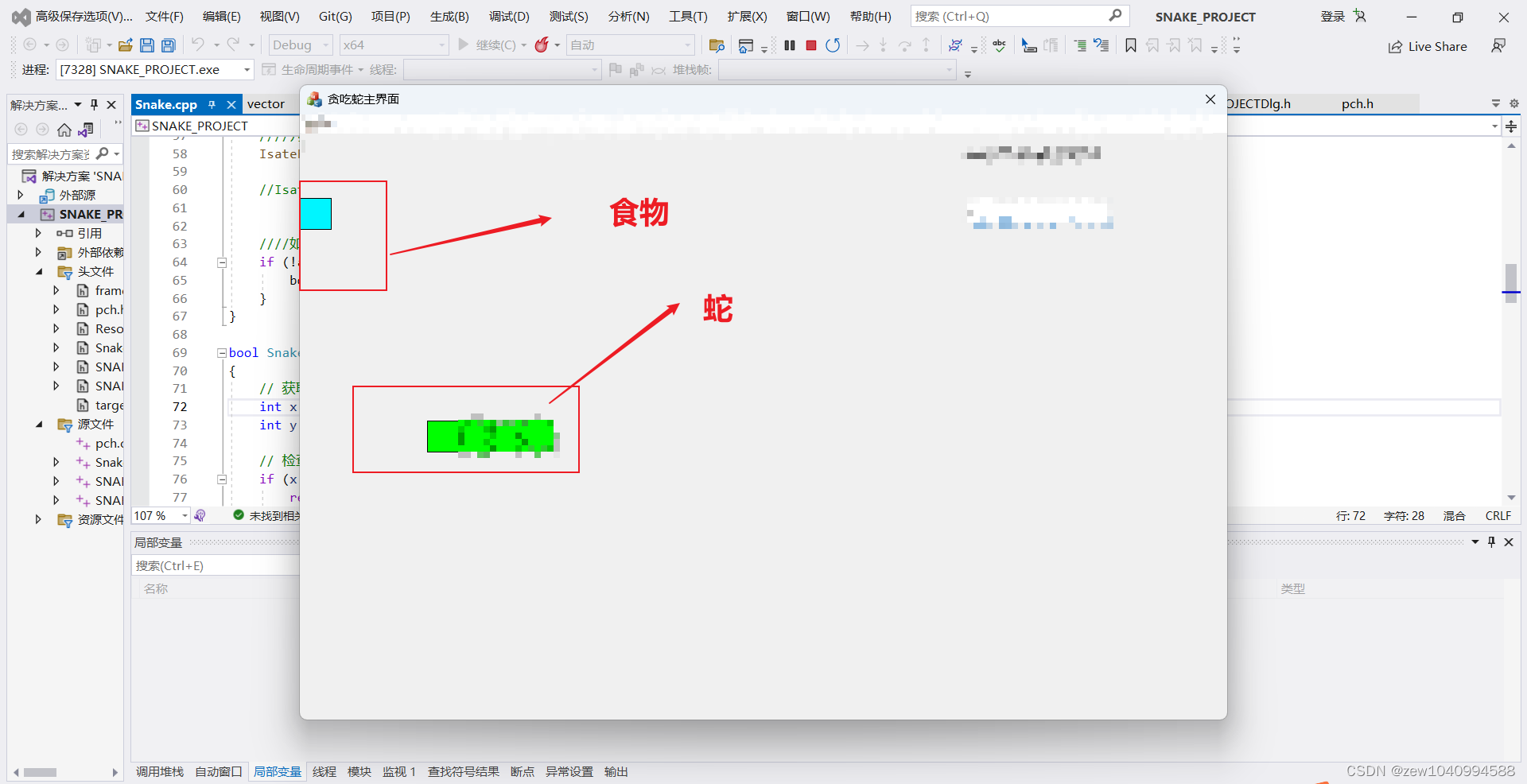
VS2020使用MFC开发一个贪吃蛇游戏
背景: 贪吃蛇游戏 按照如下步骤实现:。初始化地图 。通过键盘控制蛇运动方向,注意重新设置运动方向操作。 。制造食物。 。让蛇移动,如果吃掉食物就重新生成一个食物,如果会死亡就break。用蛇的坐标将地图中的空格替换为 #和”将…...

【经典LeetCode算法题目专栏分类】【第9期】深度优先搜索DFS与并查集:括号生成、岛屿问题、扫雷游戏
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能AI、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推荐--…...
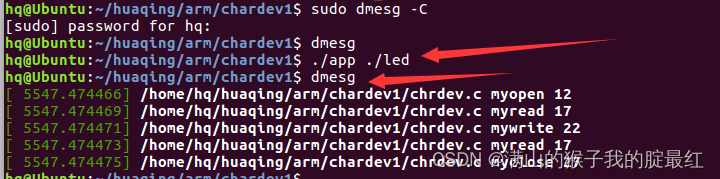
字符设备驱动开发-注册-设备文件创建
一、字符设备驱动 linux系统中一切皆文件 1、应用层: APP1 APP2 ... fd open("led驱动的文件",O_RDWR); read(fd); write(); close(); 2、内核层: 对灯写一个驱动 led_driver.c driver_open(); driver_read(); driver_write(…...
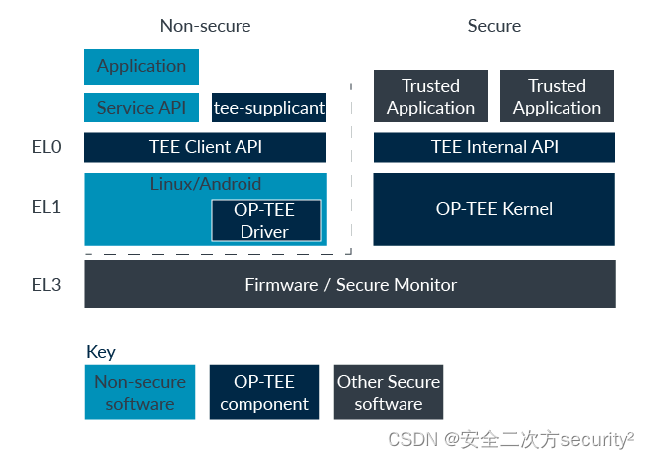
TrustZone之可信操作系统
有许多可信内核,包括商业和开源的。一个例子是OP-TEE,最初由ST-Ericsson开发,但现在是由Linaro托管的开源项目。OP-TEE提供了一个功能齐全的可信执行环境,您可以在OP-TEE项目网站上找到详细的描述。 OP-TEE的结构如下图所示&…...

java定义三套场景接口方案
一、背景 在前后端分离开发的背景下,后端java开发人员现在只需要编写接口接口。特别是使用微服务开发的接口。resful风格接口。那么一般后端接口被调用有下面三种场景。一、不需要用户登录的接口调用,第二、后端管理系统接口调用(需要账号密…...

idea连接数据库,idea连接MySQL,数据库驱动下载与安装
文章目录 普通Java工程先创建JAVA工程JDBC连接数据库测试连接 可视化连接数据库数据库驱动下载与安装常用的数据库驱动下载MySQL数据库Oracle数据库SQL Server 数据库PostgreSQL数据库 下载MySQL数据库驱动JDBC连接各种数据库的连接语句MySQL数据库Oracle数据库DB2数据库sybase…...

Go代码片段管理工具gocode:提升开发效率的CLI利器
1. 项目概述:一个为Go开发者量身定制的代码片段管理工具如果你和我一样,是个长期和Go语言打交道的开发者,那你肯定遇到过这样的场景:在多个项目间来回切换时,总有一些常用的代码片段——比如一个优雅的错误处理包装函数…...

告别玄学:给STM32/CH32V的SD卡SPI驱动加上超时、重试与状态机
从零构建工业级SD卡SPI驱动:超时重试与状态机设计实战 在嵌入式系统中,SD卡作为可靠的大容量存储介质被广泛应用。然而许多开发者都经历过这样的困境:实验室测试完美的SD卡驱动,一旦部署到真实环境中就频繁出现读写失败、卡死甚至…...

声明式应用编排框架Planifest:云原生时代应用交付新范式
1. 项目概述:一个面向未来的声明式应用编排框架如果你和我一样,在云原生和自动化运维领域摸爬滚打了几年,就会深刻体会到“编排”这个词的分量。从早期的Shell脚本,到Ansible、Terraform,再到Kubernetes的YAML海洋&…...

基于CircuitPython与伺服电机的自动调光眼镜制作指南
1. 项目概述与核心思路 最近在整理工作室的零件盒,翻出来一块Adafruit的Circuit Playground Express开发板和几个闲置的微伺服电机。看着窗外刺眼的阳光,我忽然想到,能不能用这些手头的“边角料”做个实用的小玩意儿?于是&#x…...

别再折腾Java环境了!用Docker一键部署BurpSuite社区版,5分钟开箱即用
用Docker容器化技术5分钟部署BurpSuite社区版:告别Java环境配置噩梦 在网络安全领域,BurpSuite无疑是Web应用渗透测试的瑞士军刀。但传统安装方式需要配置Java环境、处理兼容性问题,甚至不少用户为了功能完整而冒险使用破解版。现在…...

Linux内核构建自动化:jpoindexter/kern工具实战指南
1. 项目概述:一个被低估的Linux内核构建工具 如果你和我一样,长期在嵌入式开发、内核模块调试或者需要频繁定制Linux内核的岗位上工作,那么你一定对内核的配置、编译、打包这一套繁琐的流程感到又爱又恨。爱的是,这是深入理解操作…...

从零构建开源ADAS原型:车道检测、目标识别与PID控制实践
1. 项目概述:从零到一,构建一个开源的ADAS原型系统 最近几年,汽车行业最火的话题之一就是“智能驾驶”。无论是传统车企还是新势力,都在宣传自家的辅助驾驶功能,什么自适应巡航、车道保持、自动紧急制动,听…...

AI驱动的代码安全审计工具OpenClaw:原理、部署与实战调优
1. 项目概述:当AI成为代码审计的“利爪” 最近在安全圈和开源社区里,一个名为“OpenClaw”的项目引起了我的注意。它的全称是 zast-ai/openclaw-security-audit ,从名字就能嗅到一股“技术极客”的味道——“zast-ai”暗示着AI驱动…...
数字化IT架构蓝图规划设计方案(附下载方式))
(122页PPT)数字化IT架构蓝图规划设计方案(附下载方式)
篇幅所限,本文只提供部分资料内容,完整资料请看下面链接 https://download.csdn.net/download/2501_92796370/92683861 资料解读:数字化 IT 架构蓝图规划设计方案 详细资料请看本解读文章的最后内容 在数字化转型浪潮下,运营商…...

基于RAG与代码专用嵌入模型构建本地智能代码库问答系统
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的项目,叫“smart-codebase”。光看名字,你可能觉得这又是一个关于代码智能化的工具,但仔细研究其设计和实现思路,你会发现它瞄准的是一个非常具体且高频的痛点:如…...