Python 常用模块re
Python 常用模块re
【一】正则表达式
【1】说明
- 正则表达式是一种强大的文本匹配和处理工具,主要用于字符串的模式匹配、搜索和替换。
- 正则表达式测试网址:正则表达式在线测试
- 正则表达式手册:正则表达式手册
【2】字符组
- 字符转使用
[]表示,并在方括号内列出允许匹配的字符 - 字符组中的字符之间的顺序没有特定意义,他们是等效的
- 匹配字符组其中的任意一个字符
(1)常用字符组
| 正则–字符组 | 说明 |
|---|---|
[aeiou] | 匹配任意一个小写元音字母 |
[0123456789] | 匹配任意一个数字 |
[0-9] | 匹配任意一个数字 |
[a-z] | 匹配任意一个小写字母 |
[a-zA-Z] | 匹配任意一个字母 |
[0-9a-zA-Z] | 匹配任意一个字母或者数字 |
【3】元字符
- 正则表达式中的元字符是具有特殊含义的字符,它们不仅仅匹配自身,还具有一些特殊的功能
(1)常用元字符
| 正则–元字符 | 说明 |
|---|---|
| · | 匹配任意一个除换行符(\n)以外的字符 要匹配包括“ \n”在内的任何字符,请使用像“`(. |
\w | 匹配任意一个字母、数字或下划线[A-Za-z0-9_] |
\W | 匹配任意一个非字母、数字或下划线[^A-Za-z0-9_] |
\s | 匹配一个空白符(包括空格、制表符、换页符等)[ \f\n\r\t\v] |
\S | 匹配一个非空白符(包括空格、制表符、换页符等)[^ \f\n\r\t\v] |
\d | 匹配任意一个数字[0-9] |
| \D | 匹配任意一个非数字[^0-9] |
| \t | 匹配一个制表符[\t] |
| \b | 匹配一个单词的结尾py\b可以匹配main.py的结尾py,但是不能匹配python的py |
| a|b | 匹配字符a或字符b |
| () | 匹配括号内的表达式,也表示一个组 |
| […] | 匹配字符组中的字符 |
| [^…] | 匹配除了字符组中字符的所有字符 |
【4】量词
- 正则表达式中的量词用于指定一个模式中某个元素的匹配次数
(1)常用量词
| 正则–量词 | 说明 |
|---|---|
* | 重复零次或更多次 |
+ | 重复一次或更多次 |
? | 重复零次或一次 |
{n} | 重复n次 |
{n,} | 重复n次或更多次, 贪婪匹配优先匹配多次 |
{n,m} | 重复n次到m次,贪婪匹配优先匹配m次 |
(2)非贪婪匹配
| 正则–量词 | 说明 |
|---|---|
{n,m}? | 重复n次到m次,非贪婪匹配优先匹配n次 |
【5】位置
- 正则表达式中的量词用于指定一个模式中某个元素的位置
(1)常用位置
| 正则–量词位置 | 说明 |
|---|---|
^ | 匹配字符串的开始 |
$ | 匹配字符串的结尾 |
【6】分组匹配
-
在正则表达式中,分组是用小括号
()括起来的部分,它允许你将一组字符当作一个单独的单元来处理 -
例如
(abc){2,4}表示匹配连续出现 2 到 4 次的abc
【7】转义符
- 在正则表达式中,转义字符用于取消字符的特殊含义,使其变成普通字符
- 例如:在正则表达式中,
.表示匹配任意字符。如果你想匹配实际的点号,需要使用\.
【8】模式修正符
- 正则表达式的模式修正符是一种在正则表达式模式中添加修正标志以改变匹配规则的方式。修正标志通常以字母形式添加到正则表达式的末尾,用于调整匹配的方式。
| 值 | 说明 |
|---|---|
re.I | 是匹配对大小写不敏感 |
re.L | 做本地化识别匹配 |
re.M | 多行匹配,影响到^和$ |
re.S | 使.匹配包括换行符在内的所有字符 |
re.U | 根据Unicode字符集解析字符,影响\w、\W、\b、\B |
re.X | 通过给予我们功能灵活的格式以便更好的理解正则表达式 |
(1)re.S代码讲解
- 使.匹配包括换行符在内的所有字符
- 代码目的:匹配<>中的所有内容
- 不使用模式修正符号,无法匹配到第二个<>
- 使用模式修正符号,匹配到所有<>
import retext = """
<age is 18>
<age is
18>
"""
pattern1 = re.compile(r"<.*>")
pattern2 = re.compile(r"<.*>", flags=re.S)
res = re.findall(pattern1, text)
print(res)
res = re.findall(pattern2, text)
print(res)# ['<age is 18>']
# ['<age is 18>', '<age is\n18>']
【二】re模块
【1】编译正则表达式compile
- 正则表达式编译之后会生成一个正则表达式对象,该对象可以被访问多次
- 避免了在每次匹配时都重新解析正则表达式
re.compile(pattern, flags=0)# pattern 正则表达式
# flags 用于指定匹配模式修正符
import repattern = re.compile(r"\d")
print(pattern, type(pattern))
# re.compile('\\d') <class 're.Pattern'>注意:模式修正符号
- 使用编译方法时,修正符号必须放在编译方法里面,不能放在后续的使用方法中
import retext = """
<age is 18>
<age is
18>
"""# 正确
pattern1 = re.compile(r"<.*>", re.S)
print(pattern1)
res = re.findall(pattern1, text)
print(res)# 错误
pattern1 = re.compile(r"<.*>")
print(pattern1)
res = re.findall(pattern1, text, re.S)
print(res)
【2】查找结果findall
- 所有满足匹配结果的内容,返回一个列表
- 避免了在每次匹配时都重新解析正则表达式
re.findall(pattern, string, flags=0)# pattern 正则表达式
# string 待匹配字符串
# flags 用于指定匹配模式修正符
import repattern = re.compile(r"\w+")
text = "my name is bruce"
res = re.findall(pattern, text)
print(res)
# ['my', 'name', 'is', 'bruce']注意:存在子组时
-
将只返回子组内容
-
需要使用非捕获分组
(?:...)
import repattern = re.compile(r"\d+@(qq|163).com")
text = "15846354@qq.com"
res = re.findall(pattern, text)
print(res)
# ['qq']pattern = re.compile(r"\d+@(?:qq|163).com")
text = "15846354@qq.com"
res = re.findall(pattern, text)
print(res)
# ['15846354@qq.com']
【3】查找结果search
- 搜索第一个第一个第一个匹配成功的对象
- 返回一个对象,为空则返回None
- 不像
findall一样存在子组的问题
re.search(pattern, string, flags=0)# pattern 正则表达式
# string 待匹配字符串
# flags 用于指定匹配模式修正符
注意:匹配对象的方法和属性
group() # 匹配的结果字符串
start() # 匹配成功的起始位置,从0开始
end() # 匹配成功的结束位置,结束的后一个位置
span() # 元组形式,开始和结束位置
import repattern = re.compile(r"\d+")
text = "age is 18"
res = re.search(pattern, text)
print(res, type(res)) # <re.Match object; span=(7, 9), match='18'> <class 're.Match'>
print(res.group()) # 18
print(res.start()) # 7
print(res.end()) # 9
print(res.span(), type(res.span())) # (7, 9) <class 'tuple'>
【3】查找结果match
- match和search基本相同
- 不同点:
- match从字符串开头位置开始匹配
- search在整个字符串中搜索第一个匹配结果
import repattern1 = re.compile(r"\w+")
pattern2 = re.compile(r"\d+")
text = "age is 18"
res = re.match(pattern1, text)
print(res) # <re.Match object; span=(0, 3), match='age'>
res = re.match(pattern2, text)
print(res) # None【4】切割split
- 用于根据正则表达式模式分割字符串
- 返回一个由分割后的子字符串组成的列表
re.split(pattern, string, maxsplit=0, flags=0)# pattern 正则表达式
# string 待匹配字符串
# maxsplit 指定最大分割次数,0表示不限制,从前往后开始切分
# flags 用于指定匹配模式修正符
import repattern = re.compile(r"\d+")
text = "aafa121ada021da12da"
res = re.split(pattern, text)
print(res) # ['aafa', 'ada', 'da', 'da']
res = re.split(pattern, text, maxsplit=1)
print(res) # ['aafa', 'ada021da12da']
注意:存在子组时
-
子组的内容也将保留在列表中
-
使用非捕获分组
(?:...),将不会保存在列表中
import repattern = re.compile(r"(qq|163)")
text = "15846354@qq.com"
res = re.split(pattern, text)
print(res)
# ['15846354@', 'qq', '.com']pattern = re.compile(r"(?:qq|163)")
text = "15846354@qq.com"
res = re.split(pattern, text)
print(res)
# ['15846354@', '.com']
【5】替换sub
- 在字符串中替换正则表达式模式的匹配项, 默认替换
re.sub(pattern, repl, string, count=0, flags=0)# pattern 正则表达式
# repl 替换匹配项的字符串或可调用对象
# string 待匹配字符串
# count 指定最大替换次数,0表示不限制,从前往后开始替换
# flags 用于指定匹配模式修正符
import repattern = re.compile(r"\d+")
text = "age is 18"
res = re.sub(pattern, "20", text)
print(res)
# age is 20
了解:repl是可调用对象
-
将只返回子组内容
-
需要使用非捕获分组
(?:...)
import redef to_upper(match):return match.group().upper()
text = "apple banana cherry date"
pattern = re.compile(r'\b\w{6}\b') # 匹配长度为6的单词
result = pattern.sub(to_upper, text)
print(result) # apple BANANA cherry datedef replace_adjacent(match):word = match.group()return f"{word} {word.upper()}"
text = "apple banana cherry date"
pattern = re.compile(r'\b\w{6}\b') # 匹配长度为6的单词
result = pattern.sub(replace_adjacent, text)
print(result) # apple apple BANANA cherry date
【6】替换subn
- sub和subn基本相同
- 不同点:
- sub返回替换后的字符串
- sunb返回一个包含替换后的字符串和替换次数的元组
import repattern = re.compile(r"\d+")
text = "age is 18, money 50"
res = re.subn(pattern, "20", text)
print(res)
# ('age is 20, money 20', 2)
【7】切割finditer
- 用于在字符串中查找正则表达式模式的所有匹配项
- 返回一个迭代器
re.finditer(pattern, string, flags=0)# pattern 正则表达式
# string 待匹配字符串
# flags 用于指定匹配模式修正符
import repattern = re.compile(r"\d+")
text = "age is 18, money 50"
res = re.finditer(pattern, text)
print(res, type(res))
for i in res:print(i)
# <callable_iterator object at 0x000002A4EC860D90> <class 'callable_iterator'>
# <re.Match object; span=(7, 9), match='18'>
# <re.Match object; span=(17, 19), match='50'>
【三】常用正则表达式
| 匹配内容 | 正则表达式 |
|---|---|
| 邮箱地址 | ^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$ |
| URL | `^(https? |
| 匹配日期(年-月-日) | ^\d{4}-\d{2}-\d{2}$ |
| 匹配手机号码 | ^1[3456789]\d{9}$ |
| 匹配身份证号码 | ^\d{17}[\dXx] |
IP 地址 | `/((2[0-4]\d |
| 匹配整数或浮点数 | ^[-+]?[0-9]*\.?[0-9]+$ |
| Unicode编码中的汉字范围 | /^[\u2E80-\u9FFF]+$/ |
【四】练习
- 获取金额,最小两位小数
import redef get_money():while True:money = input("请输入金额(最小单位0.01):>>>").strip()pattern = re.compile(r"^\d+(\.\d{1,2})?$")res = re.match(pattern, money)if not res:print(f"输入内容{money}不合法,请输入")continuereturn moneyprint(get_money())
相关文章:

Python 常用模块re
Python 常用模块re 【一】正则表达式 【1】说明 正则表达式是一种强大的文本匹配和处理工具,主要用于字符串的模式匹配、搜索和替换。正则表达式测试网址:正则表达式在线测试 正则表达式手册:正则表达式手册 【2】字符组 字符转使用[]表…...

【华为OD题库-106】全排列-java
题目 给定一个只包含大写英文字母的字符串S,要求你给出对S重新排列的所有不相同的排列数。如:S为ABA,则不同的排列有ABA、AAB、BAA三种。 解答要求 时间限制:5000ms,内存限制:100MB 输入描述 输入一个长度不超过10的字符串S,确保都是大写的。…...
)
Three.js 详细解析(持续更新)
1、简介; Three.js依赖一些要素,第一是scene,第二是render,第三是carmea npm install --save three import * as THREE from "three"; import { GLTFLoader } from "three/examples/jsm/loaders/GLTFLoader.js&quo…...
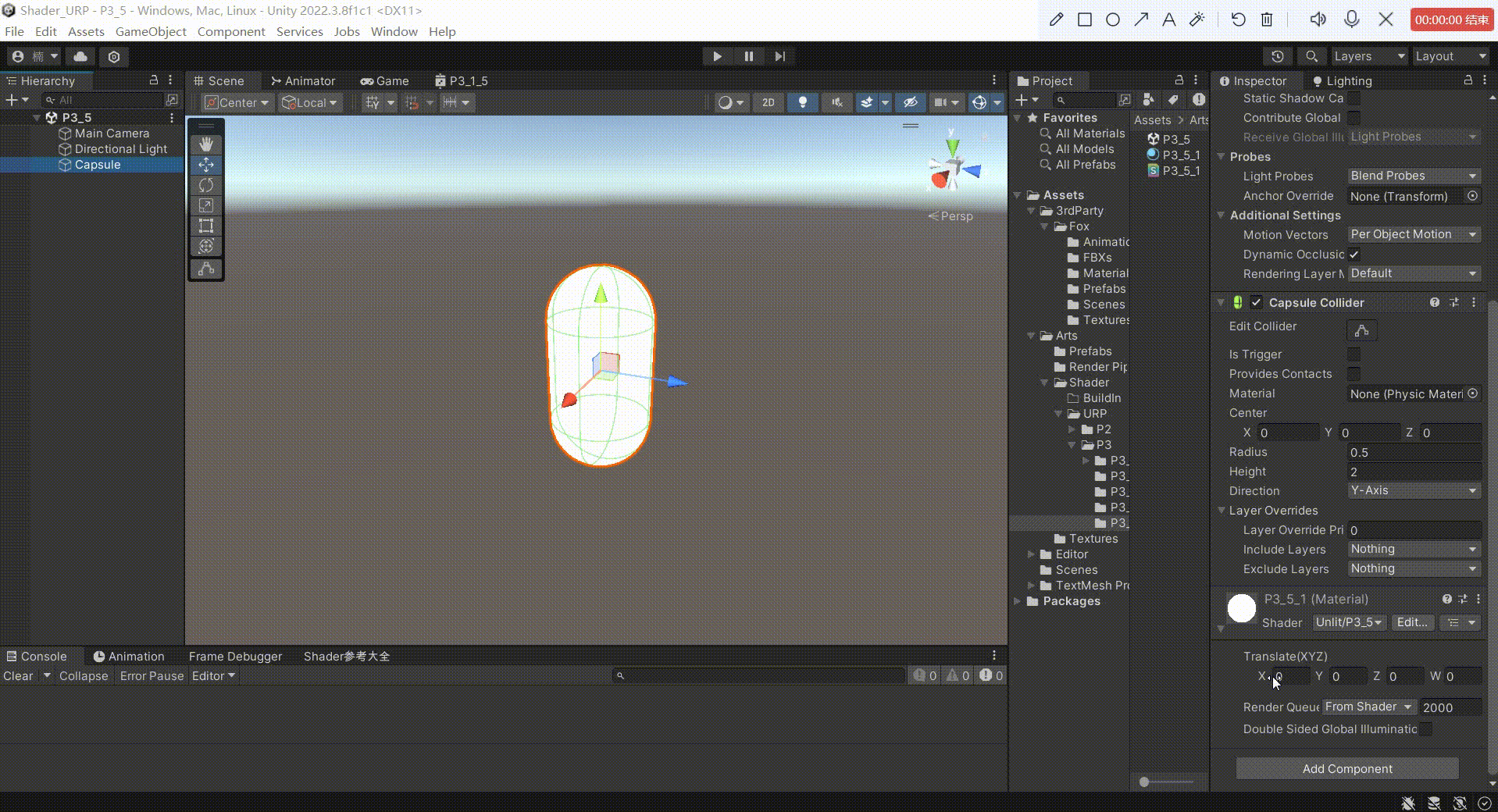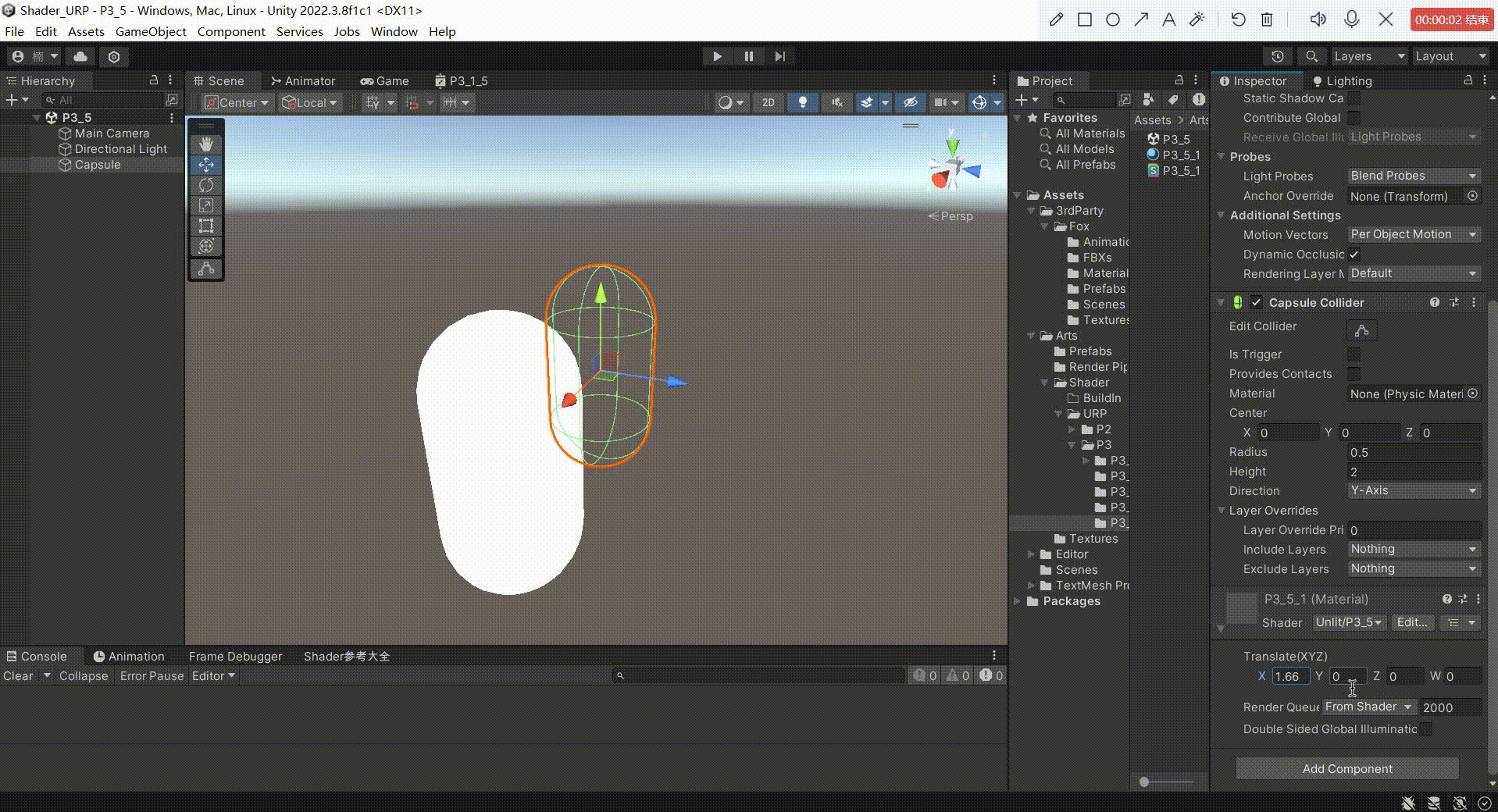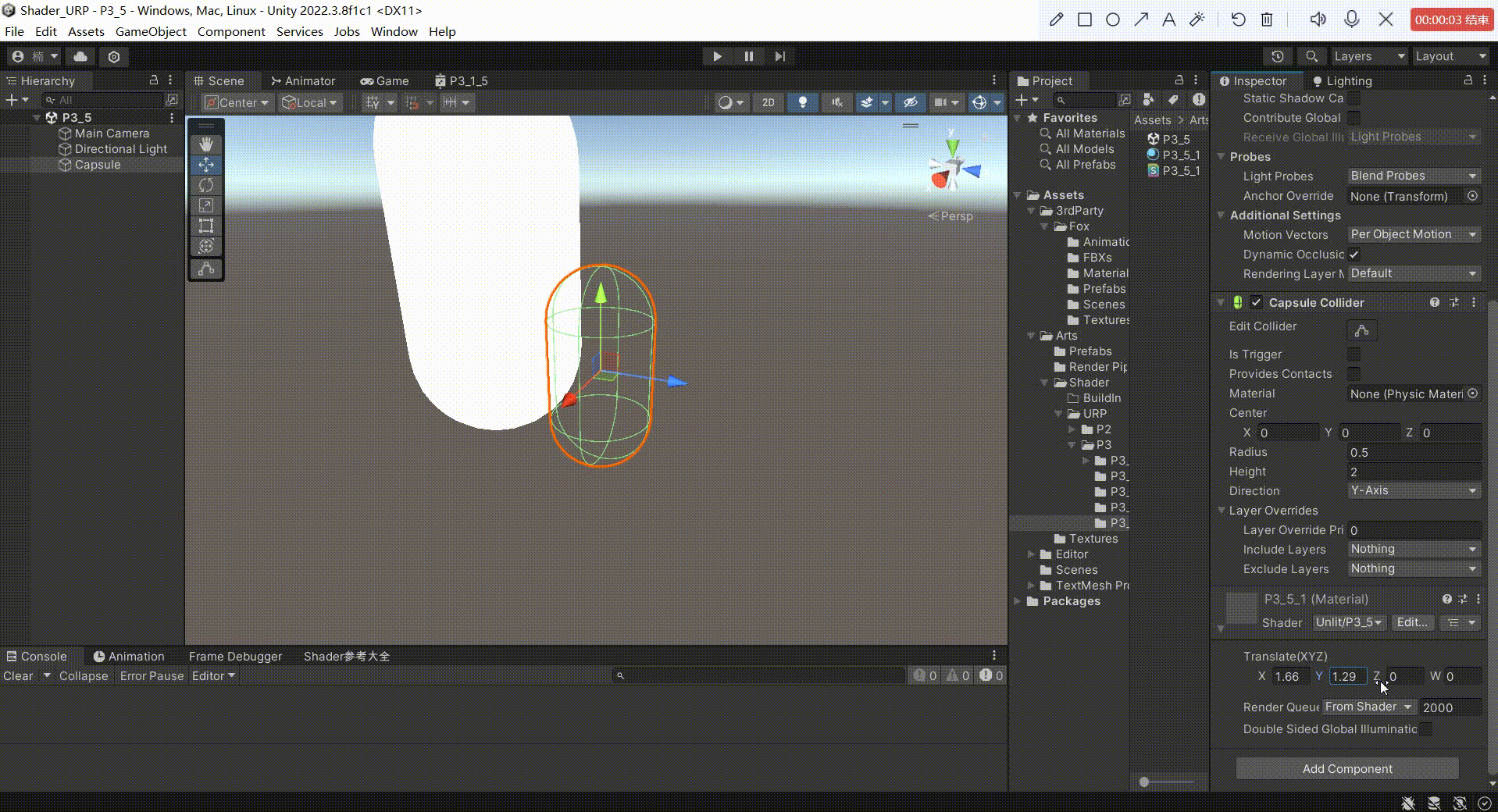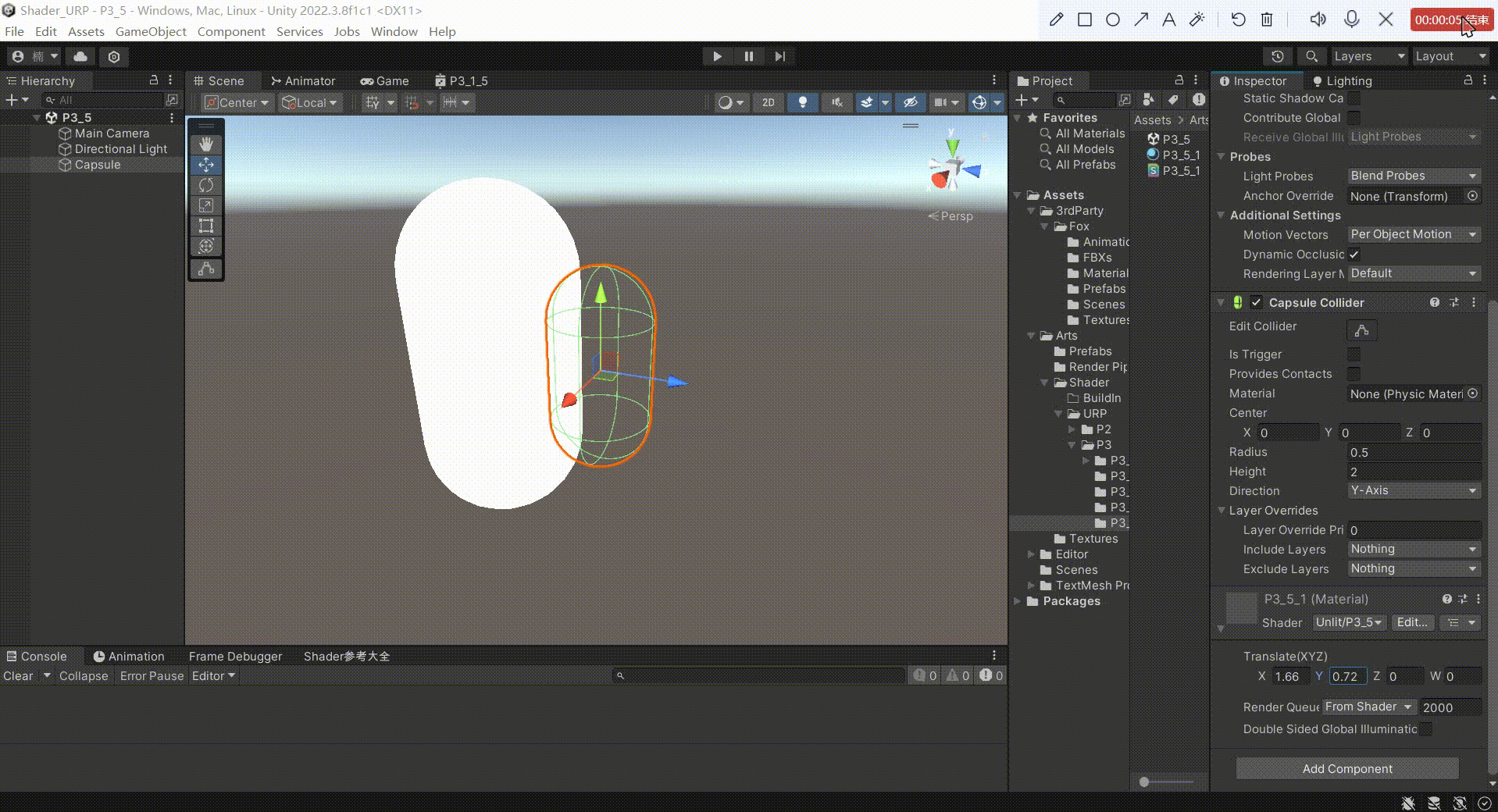
Unity中Shader平移矩阵
文章目录 前言方式一:对顶点本地空间下的坐标进行相加平移1、在属性面板定义一个四维变量记录在 xyz 上平移多少。2、在常量缓冲区进行申明3、在顶点着色器中,在进行其他坐标转化之前,对模型顶点本地空间下的坐标进行转化4、我们来看看效果 方…...

python dash 的学习笔记1
dash 用python开发web界面 https://dash.plotly.com/ 官方上支持jula F# python一类。当然我只会python只学习python中使用dash. 要做一个APP,用php,java以及.net都可以写,只所有选择python是因为最近在用这一个。同时也发现python除了慢全是优点。 资料…...

SQLITE如何同时查询出第一条和最后一条两条记录
一个时间记录表,需要同时得到整个表或一段时间内第一条和最后一条两条记录,按如下方法会提示错误:ORDER BY clause should come after UNION not before select * from sdayXX order by op_date asc limit 1 union select * from sday…...
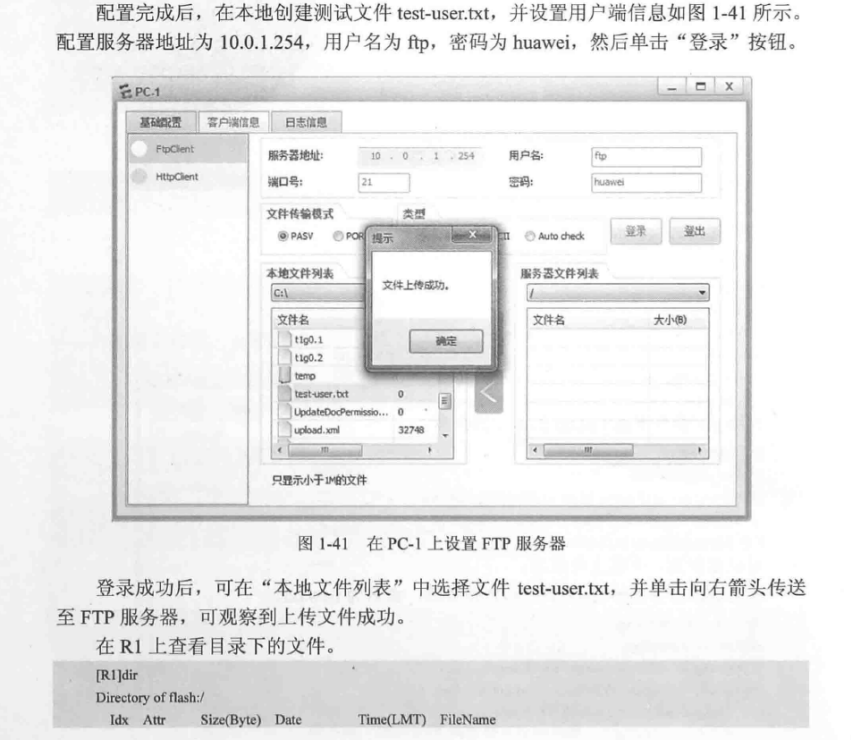
四、ensp配置ftp服务器实验
文章目录 实验内容实验拓扑操作步骤配置路由器为ftp server 实验内容 本实验模拟企业网络。PC-1为FTP 用户端设备,需要访问FTP Server,从服务器上下载或上传文件。出于安全角度考虑,为防止服务器被病毒文件感染,不允许用户端直接…...
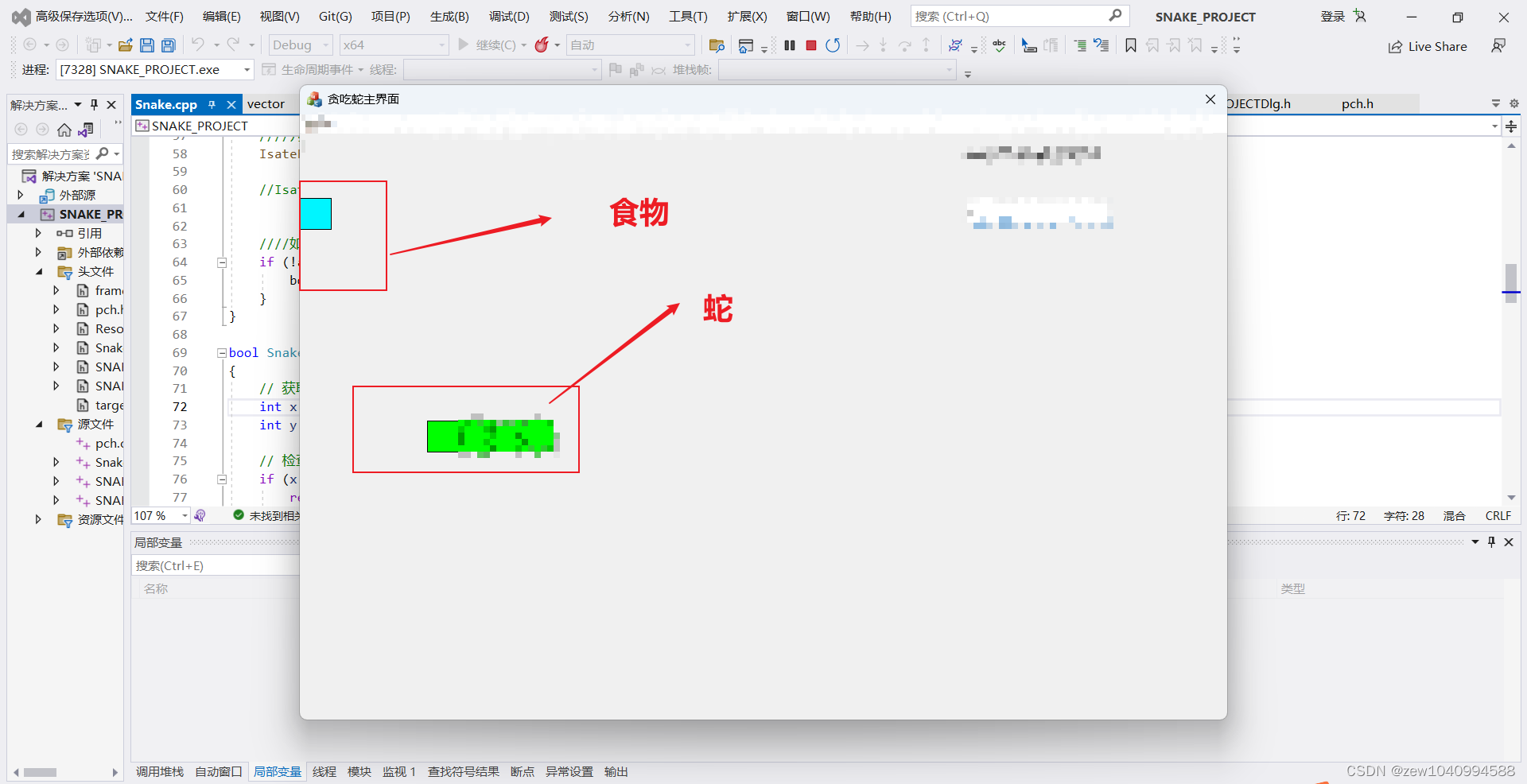
VS2020使用MFC开发一个贪吃蛇游戏
背景: 贪吃蛇游戏 按照如下步骤实现:。初始化地图 。通过键盘控制蛇运动方向,注意重新设置运动方向操作。 。制造食物。 。让蛇移动,如果吃掉食物就重新生成一个食物,如果会死亡就break。用蛇的坐标将地图中的空格替换为 #和”将…...

【经典LeetCode算法题目专栏分类】【第9期】深度优先搜索DFS与并查集:括号生成、岛屿问题、扫雷游戏
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能AI、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推荐--…...
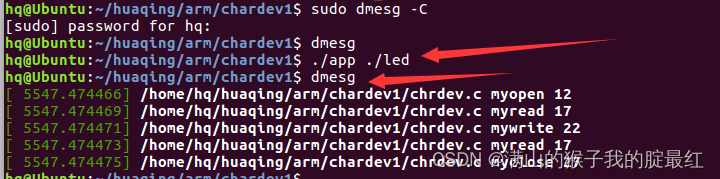
字符设备驱动开发-注册-设备文件创建
一、字符设备驱动 linux系统中一切皆文件 1、应用层: APP1 APP2 ... fd open("led驱动的文件",O_RDWR); read(fd); write(); close(); 2、内核层: 对灯写一个驱动 led_driver.c driver_open(); driver_read(); driver_write(…...
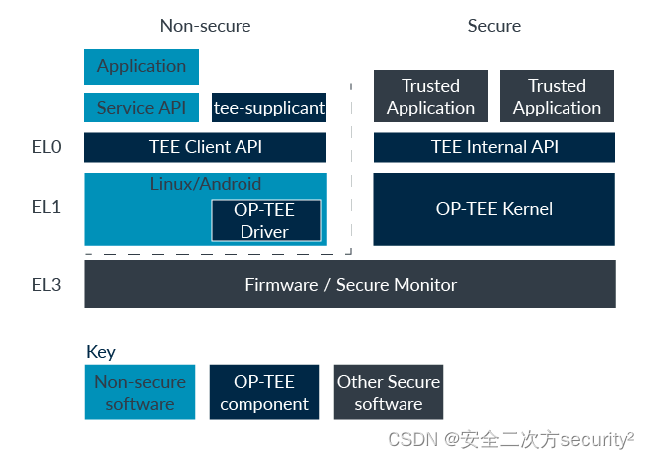
TrustZone之可信操作系统
有许多可信内核,包括商业和开源的。一个例子是OP-TEE,最初由ST-Ericsson开发,但现在是由Linaro托管的开源项目。OP-TEE提供了一个功能齐全的可信执行环境,您可以在OP-TEE项目网站上找到详细的描述。 OP-TEE的结构如下图所示&…...

java定义三套场景接口方案
一、背景 在前后端分离开发的背景下,后端java开发人员现在只需要编写接口接口。特别是使用微服务开发的接口。resful风格接口。那么一般后端接口被调用有下面三种场景。一、不需要用户登录的接口调用,第二、后端管理系统接口调用(需要账号密…...

idea连接数据库,idea连接MySQL,数据库驱动下载与安装
文章目录 普通Java工程先创建JAVA工程JDBC连接数据库测试连接 可视化连接数据库数据库驱动下载与安装常用的数据库驱动下载MySQL数据库Oracle数据库SQL Server 数据库PostgreSQL数据库 下载MySQL数据库驱动JDBC连接各种数据库的连接语句MySQL数据库Oracle数据库DB2数据库sybase…...

Redis-实践知识
转自极客时间Redis 亚风 原文视频:https://u.geekbang.org/lesson/535?article681062 Redis最佳实践 普通KEY Redis 的key虽然可以自定义,但是最好遵循下面几个实践的约定: 格式:[业务名称]:[数据名]:[id] 长度不超过44字节 不…...

多维时序 | MATLAB实现SSA-CNN-SVM麻雀算法优化卷积神经网络-支持向量机多变量时间序列预测
多维时序 | MATLAB实现SSA-CNN-SVM麻雀算法优化卷积神经网络-支持向量机多变量时间序列预测 目录 多维时序 | MATLAB实现SSA-CNN-SVM麻雀算法优化卷积神经网络-支持向量机多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 多维时序 | MATLAB实现…...

leetcode160相交链表思路解析
分别让tmp1以及tmp2的结点分别先指向headA以及headB,当遍历完成后,再让tmp1以及tmp2分别指向haedB和headA反转 此处有个问题:为什么if判断句中写tmp1!=nullptr,能够编译通过,但是写tmp1->ne…...

在线分析工具-日志优化
一、概述 针对于大日志文件,统计分析出日志文件的相关指标,帮助开发测试人员,优化日志打印。减少存储成本 二、日志分析指标 重复打印日志:统一请求reqId的重复打印日志打印最多的方法:检测出打印日志最多的方法…...

硬核实战!mysql 错误操作整个表全部数据后如何恢复?附解决过程、思路(百万行SQL,通过binlog日志恢复)
mysql 错误操作整个表全部数据后如何恢复?(百万行SQL,通过binlog日志恢复) 事件起因 事情起因:以为某个表里的数据都是系统配置的数据,没有用户数据,一个字段需要覆盖替换为新的url链接&#x…...

【什么是反射机制?为什么反射慢?】
✅ 什么是反射机制?为什么反射慢? ✅典型解析✅拓展知识仓✅反射常见的应用场景✅反射和Class的关系 ✅典型解析 反射机制指的是程序在运行时能够获取自身的信息。在iava中,只要给定类的名字,那么就可以通过反射机制来获得类的所有…...
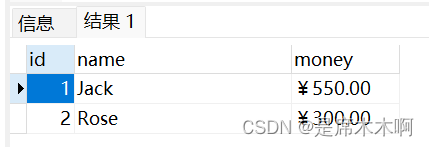
PostGreSQL:货币类型
货币类型:money money类型存储固定小数精度的货币数字,小数的精度由数据库的lc_monetary设置决定。windows系统下,该配置项位于/data/postgresql.conf文件中,默认配置如下, lc_monetary Chinese (Simplified)_Chi…...
)
RFSoC开发避坑指南:手把手教你理解并配置RF数据转换器的核心结构体(以XRFdc为例)
RFSoC开发实战:深度解析XRFdc结构体配置与避坑策略 第一次打开xrfdc.h头文件时,面对密密麻麻的结构体定义,我的鼠标滚轮不由自主地滑动了三分钟才看完所有内容。作为曾经在RFSoC项目上踩过无数坑的开发者,我完全理解那种面对数十个…...

当深度学习赋能异步电机矢量控制:从模型优化到性能跃迁
1. 异步电机矢量控制的传统挑战 我第一次接触异步电机矢量控制是在2015年做工业机器人项目时。当时为了调试一个简单的速度环,整整花了两周时间反复调整PI参数。这种经历让我深刻体会到传统控制方法的局限性——就像用螺丝刀修理精密手表,虽然最终能调好…...

SDLPAL图形渲染技术揭秘:OpenGL与Shader的完美结合
SDLPAL图形渲染技术揭秘:OpenGL与Shader的完美结合 【免费下载链接】sdlpal SDL-based reimplementation of the classic Chinese-language RPG known as PAL. 项目地址: https://gitcode.com/gh_mirrors/sd/sdlpal SDLPAL是一款基于SDL的经典中文RPG游戏重制…...

热门的牙齿矫正正畸李杨哪个好
在社交媒体上,关于“牙齿矫正哪家好”、“李杨医生靠谱吗”的讨论热度居高不下。许多粉丝在评论区留言,想知道这位在网络红人榜上经常出现的正畸专家,是否真的值得托付那长达一两年的矫正周期。作为一个长期关注口腔健康领域的观察者…...

思源宋体CN终极指南:7种字重免费商用中文字体快速上手完整教程
思源宋体CN终极指南:7种字重免费商用中文字体快速上手完整教程 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为商业项目中文字体版权问题而烦恼吗?思源宋…...

扣图操作方法完全指南:2026年最实用的AI一键抠图工具推荐
说起扣图,我相信很多人都有过这样的经历——花半天时间用PS的钢笔工具精心描绘边界,最后还是差强人意。或者为了给证件照换个背景,反复调整参数却效果一般。今天我就来分享一下2026年最实用的扣图操作方法,以及那些真正能救命的工…...
)
Simulink里三种TD微分器怎么选?用带噪声的正弦信号实测给你看(附模型)
Simulink中三种TD微分器的工程选型实战指南 从实验室到产线:为什么TD微分器如此重要 在电机控制、机器人导航和工业自动化领域,工程师们经常面临一个共同挑战:如何从带有噪声的传感器信号中准确提取速度信息。编码器、加速度计等传感器输出的…...

ChatGPT Web:5分钟快速搭建你的专属AI聊天室
ChatGPT Web:5分钟快速搭建你的专属AI聊天室 【免费下载链接】chatgpt-web A third-party ChatGPT Web UI page built with Express and Vue3, through the official OpenAI completion API. / 用 Express 和 Vue3 搭建的第三方 ChatGPT 前端页面, 基于 OpenAI 官方…...

网络通信调试难题的Qt解决方案:mNetAssist深度解析
网络通信调试难题的Qt解决方案:mNetAssist深度解析 【免费下载链接】mNetAssist mNetAssist - A UDP/TCP Assistant 项目地址: https://gitcode.com/gh_mirrors/mn/mNetAssist 网络协议调试过程中,开发者常面临协议兼容性、数据传输验证和连接状态…...

番茄小说下载器终极指南:如何轻松构建个人离线图书馆
番茄小说下载器终极指南:如何轻松构建个人离线图书馆 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否经常在地铁、高铁或飞机上想要阅读番茄小说,…...