【数据结构入门精讲 | 第十篇】考研408排序算法专项练习(二)
在上文中我们进行了排序算法的判断题、选择题的专项练习,在这一篇中我们将进行排序算法中编程题的练习。

目录
- 编程题
- R7-1 字符串的冒泡排序
- R7-1 抢红包
- R7-1 PAT排名汇总
- R7-2 统计工龄
- R7-1 插入排序还是堆排序
- R7-2 龙龙送外卖
- R7-3 家谱处理
编程题
R7-1 字符串的冒泡排序
我们已经知道了将N个整数按从小到大排序的冒泡排序法。本题要求将此方法用于字符串序列,并对任意给定的K(<N),输出扫描完第K遍后的中间结果序列。
输入格式:
输入在第1行中给出N和K(1≤K<N≤100),此后N行,每行包含一个长度不超过10的、仅由小写英文字母组成的非空字符串。
输出格式:
输出冒泡排序法扫描完第K遍后的中间结果序列,每行包含一个字符串。
输入样例:
6 2
best
cat
east
a
free
day
输出样例:
best
a
cat
day
east
free
这里要知道一个知识点:先比较两个字符串的第一个字符的ASCII码值),如果第一个字符串的第一个字符大于第二个字符串的第一个字符,则返回1;反之,则返回-1;若两个字符相等,则进行下一对字符的比较,(下面的比较均是ASCII码值的比较)直到出现有一对字符不同则返回相应的值(1或-1)。若两个字符串所有的字符都相同,则返回数字0。
#include <stdio.h>
#include <string.h>
int main()
{int n,k;scanf("%d%d",&n,&k);char a[100][11]={0},x[11];for(int i=0;i<n;i++)//用二维数组存储{scanf("%s",&a[i]);}for(int i=0;i<k;i++)//对于每个元素而言{for(int j=0;j<n-i-1;j++)//每个元素都比较n-i-1次{if(strcmp(a[j],a[j+1])>0)//交换{strcpy(x,a[j]);strcpy(a[j],a[j+1]);strcpy(a[j+1],x);}}}for(int i=0;i<n;i++)printf("%s\n",a[i]);}
R7-1 抢红包
没有人没抢过红包吧…… 这里给出N个人之间互相发红包、抢红包的记录,请你统计一下他们抢红包的收获。
输入格式:
输入第一行给出一个正整数N(≤104),即参与发红包和抢红包的总人数,则这些人从1到N编号。随后N行,第i行给出编号为i的人发红包的记录,格式如下:
K N1 P1 ⋯ NK PK
其中K(0≤K≤20)是发出去的红包个数,Ni是抢到红包的人的编号,Pi(>0)是其抢到的红包金额(以分为单位)。注意:对于同一个人发出的红包,每人最多只能抢1次,不能重复抢。
输出格式:
按照收入金额从高到低的递减顺序输出每个人的编号和收入金额(以元为单位,输出小数点后2位)。每个人的信息占一行,两数字间有1个空格。如果收入金额有并列,则按抢到红包的个数递减输出;如果还有并列,则按个人编号递增输出。
输入样例:
10
3 2 22 10 58 8 125
5 1 345 3 211 5 233 7 13 8 101
1 7 8800
2 1 1000 2 1000
2 4 250 10 320
6 5 11 9 22 8 33 7 44 10 55 4 2
1 3 8800
2 1 23 2 123
1 8 250
4 2 121 4 516 7 112 9 10
输出样例:
1 11.63
2 3.63
8 3.63
3 2.11
7 1.69
6 -1.67
9 -2.18
10 -3.26
5 -3.26
4 -12.32
#include <iostream>
#include <algorithm>
#include <cstdio>using namespace std;// 定义结构体redbag,用于存储每个人的红包信息
struct redbag{int id; // 编号int count = 0; // 收到红包的个数int money = 0; // 最终收到的金额
};// 自定义比较函数cmp,用于sort排序时指定排序规则
bool cmp(redbag &r1, redbag &r2){if(r1.money != r2.money){ // 按照最终收到的金额从大到小排序return r1.money > r2.money;}else if(r1.count != r2.count){ // 如果最终收到金额相等,则按照收到红包的个数从大到小排序return r1.count > r2.count;}else{ // 如果最终收到金额和收到红包的个数都相等,则按照编号从小到大排序return r1.id < r2.id;}
}int main(){int n; // 总人数cin >> n;redbag red[n+1]; // 定义数组red,用于存储每个人的信息int k, card, mon; // k表示某个人发出的红包数,card表示发红包的人的编号,mon表示红包金额for(int i = 1; i <= n; i++){cin >> k;red[i].id = i;for(int j = 1; j <= k; j++){cin >> card >> mon;red[i].money -= mon; // 发出红包的人需要减掉红包金额red[card].money += mon; // 收到红包的人需要加上红包金额red[card].count++; // 收到红包的人收到红包数加1}}sort(red+1, red+n+1, cmp); // 使用sort排序,按照指定的cmp规则排序for(int i = 1; i <= n; i++){printf("%d %.2lf\n", red[i].id, red[i].money / 100.0); // 输出每个人最终获得的金额,需要将单位从分转换为元,并保留两位小数}return 0;
}
R7-1 PAT排名汇总
计算机程序设计能力考试(Programming Ability Test,简称PAT)旨在通过统一组织的在线考试及自动评测方法客观地评判考生的算法设计与程序设计实现能力,科学的评价计算机程序设计人才,为企业选拔人才提供参考标准。
每次考试会在若干个不同的考点同时举行,每个考点用局域网,产生本考点的成绩。考试结束后,各个考点的成绩将即刻汇总成一张总的排名表。
现在就请你写一个程序自动归并各个考点的成绩并生成总排名表。
输入格式:
输入的第一行给出一个正整数N(≤100),代表考点总数。随后给出N个考点的成绩,格式为:首先一行给出正整数K(≤300),代表该考点的考生总数;随后K行,每行给出1个考生的信息,包括考号(由13位整数字组成)和得分(为[0,100]区间内的整数),中间用空格分隔。
输出格式:
首先在第一行里输出考生总数。随后输出汇总的排名表,每个考生的信息占一行,顺序为:考号、最终排名、考点编号、在该考点的排名。其中考点按输入给出的顺序从1到N编号。考生的输出须按最终排名的非递减顺序输出,获得相同分数的考生应有相同名次,并按考号的递增顺序输出。
输入样例:
2
5
1234567890001 95
1234567890005 100
1234567890003 95
1234567890002 77
1234567890004 85
4
1234567890013 65
1234567890011 25
1234567890014 100
1234567890012 85
输出样例:
9
1234567890005 1 1 1
1234567890014 1 2 1
1234567890001 3 1 2
1234567890003 3 1 2
1234567890004 5 1 4
1234567890012 5 2 2
1234567890002 7 1 5
1234567890013 8 2 3
1234567890011 9 2 4
#include<bits/stdc++.h>
using namespace std;struct student {string s; // 考生姓名int score; // 考生成绩int id; // 考场编号int rank; // 考场内排名int zrank; // 总体排名} a[30000]; // 存储考生信息的数组bool cmp(student x,student y)
{if(x.score != y.score) return x.score > y.score; // 根据成绩从高到低排序elsereturn x.s < y.s; // 成绩相同时,按照姓名的字典序排序}int main() {int n, cnt = 0, k; // n为考生人数,cnt为考生总数,k为每个考场的考生人数cin >> n; // 输入考生人数for(int i = 0; i < n; i++){cin >> k; // 输入每个考场的考生人数for(int j = 0; j < k; j++) {cin >> a[j + cnt].s >> a[j + cnt].score; // 输入考生姓名和成绩a[j + cnt].id = i + 1; // 设置考场编号}sort(a + cnt, a + cnt + k, cmp); // 对当前考场的考生按照成绩从高到低排序a[cnt].rank = 1; // 第一名考生的排名为1for(int j = 1; j < k; j++) {if(a[cnt + j - 1].score == a[cnt + j].score)a[cnt + j].rank = a[cnt + j - 1].rank; // 成绩相同的考生排名相同elsea[cnt + j].rank = j + 1; // 不同成绩的考生排名递增}cnt = cnt + k; // 更新考生总数}sort(a, a + cnt, cmp); // 对所有考生按照成绩从高到低排序a[0].zrank = 1; // 总体排名第一名考生的排名为1for(int j = 1; j < cnt; j++){if(a[j - 1].score == a[j].score)a[j].zrank = a[j - 1].zrank; // 成绩相同的考生总体排名相同elsea[j].zrank = j + 1; // 不同成绩的考生总体排名递增}cout << cnt << endl; // 输出考生总数for(int i = 0; i < cnt; i++) cout << a[i].s << " " << a[i].zrank << " " << a[i].id << " " << a[i].rank << endl; // 输出每个考生的姓名、总体排名、考场编号和考场排名return 0;
}
R7-2 统计工龄
给定公司N名员工的工龄,要求按工龄增序输出每个工龄段有多少员工。
输入格式:
输入首先给出正整数N(≤105),即员工总人数;随后给出N个整数,即每个员工的工龄,范围在[0, 50]。
输出格式:
按工龄的递增顺序输出每个工龄的员工个数,格式为:“工龄:人数”。每项占一行。如果人数为0则不输出该项。
输入样例:
8
10 2 0 5 7 2 5 2
输出样例:
0:1
2:3
5:2
7:1
10:1
#include <stdio.h> // 包含标准输入输出头文件int main()
{int n;scanf("%d", &n); // 输入待排序数字的个数int a[51] = {0}; // 初始化一个长度为 51 的整型数组,并初始化所有元素为 0// 循环读入待排序的数字,统计各个年龄出现的次数for (int i = 0; i < n; i++){int age;scanf("%d", &age); // 输入当前数字a[age]++; // 对应年龄出现次数加一}// 输出统计结果for (int i = 0; i <= 50; i++){if (a[i] != 0) // 如果该年龄出现次数不为 0printf("%d:%d\n", i, a[i]); // 输出该年龄及其出现次数}
}R7-1 插入排序还是堆排序
根据维基百科的定义:
插入排序是迭代算法,逐一获得输入数据,逐步产生有序的输出序列。每步迭代中,算法从输入序列中取出一元素,将之插入有序序列中正确的位置。如此迭代直到全部元素有序。
堆排序也是将输入分为有序和无序两部分,迭代地从无序部分找出最大元素放入有序部分。它利用了大根堆的堆顶元素最大这一特征,使得在当前无序区中选取最大元素变得简单。
现给定原始序列和由某排序算法产生的中间序列,请你判断该算法究竟是哪种排序算法?
输入格式:
输入在第一行给出正整数 N (≤100);随后一行给出原始序列的 N 个整数;最后一行给出由某排序算法产生的中间序列。这里假设排序的目标序列是升序。数字间以空格分隔。
输出格式:
首先在第 1 行中输出Insertion Sort表示插入排序、或Heap Sort表示堆排序;然后在第 2 行中输出用该排序算法再迭代一轮的结果序列。题目保证每组测试的结果是唯一的。数字间以空格分隔,且行首尾不得有多余空格。
输入样例 1:
10
3 1 2 8 7 5 9 4 6 0
1 2 3 7 8 5 9 4 6 0
输出样例 1:
Insertion Sort
1 2 3 5 7 8 9 4 6 0
输入样例 2:
10
3 1 2 8 7 5 9 4 6 0
6 4 5 1 0 3 2 7 8 9
输出样例 2:
Heap Sort
5 4 3 1 0 2 6 7 8 9
#include<stdio.h>// 插入排序函数
void insert_sort(int *am,int n)
{int i,j;// 找到第一个逆序的元素位置for(i=2; i<=n&&am[i-1]<=am[i]; i++);// 将该元素插入到合适的位置int key=am[i];for(j=i-1;j>=1;j--){if(am[j]>key) am[j+1]=am[j];else break;}am[j+1]=key;
}// 交换两个数的值
void swap(int *a,int *b)
{int t=*a;*a=*b;*b=t;
}// 最大堆调整函数
void maxheapify(int *am,int i,int n)
{int l,r,max;while(1){l=i<<1;r=i<<1|1;// 找到左右子节点中的最大值if(l<=n&&am[l]>am[i]) max=l;else max=i;if(r<=n&&am[r]>am[max]) max=r;// 如果最大值是当前节点,则满足最大堆性质,结束循环if(max==i) return;// 否则,交换当前节点与最大值节点的值,并继续调整swap(&am[i],&am[max]);i=max;}
}// 堆排序函数
void heap_sort(int *am,int n)
{int i,size;// 找到第一个逆序的元素位置for(i=n;i>1&&am[i]>am[i-1];i--);// 交换第一个元素与最后一个元素,并调整堆size=i-1;swap(&am[1],&am[i]);maxheapify(am,1,size);
}int main(void)
{int n;scanf("%d",&n);int num[120]={0};int am[120]={0};// 输入数字序列for(int i=1;i<=n;i++)scanf("%d",num+i);// 输入比较的数字序列for(int i=1;i<=n;i++)scanf("%d",am+i);// 根据第一个数字的大小选择排序算法if(am[1]<am[2]){printf("Insertion Sort\n");// 使用插入排序算法进行排序insert_sort(am,n);// 输出排序结果for(int i=1;i<=n;i++){if(i!=n) printf("%d ",am[i]);else printf("%d\n",am[i]);}}else{printf("Heap Sort\n");// 使用堆排序算法进行排序heap_sort(am,n);// 输出排序结果for(int i=1;i<=n;i++){if(i!=n) printf("%d ",am[i]);else printf("%d\n",am[i]);}}return 0;
}R7-2 龙龙送外卖
龙龙是“饱了呀”外卖软件的注册骑手,负责送帕特小区的外卖。帕特小区的构造非常特别,都是双向道路且没有构成环 —— 你可以简单地认为小区的路构成了一棵树,根结点是外卖站,树上的结点就是要送餐的地址。
每到中午 12 点,帕特小区就进入了点餐高峰。一开始,只有一两个地方点外卖,龙龙简单就送好了;但随着大数据的分析,龙龙被派了更多的单子,也就送得越来越累……
看着一大堆订单,龙龙想知道,从外卖站出发,访问所有点了外卖的地方至少一次(这样才能把外卖送到)所需的最短路程的距离到底是多少?每次新增一个点外卖的地址,他就想估算一遍整体工作量,这样他就可以搞明白新增一个地址给他带来了多少负担。
输入格式:
输入第一行是两个数 N 和 M (2≤N≤105, 1≤M≤105),分别对应树上节点的个数(包括外卖站),以及新增的送餐地址的个数。
接下来首先是一行 N 个数,第 i 个数表示第 i 个点的双亲节点的编号。节点编号从 1 到 N,外卖站的双亲编号定义为 −1。
接下来有 M 行,每行给出一个新增的送餐地点的编号 Xi。保证送餐地点中不会有外卖站,但地点有可能会重复。
为了方便计算,我们可以假设龙龙一开始一个地址的外卖都不用送,两个相邻的地点之间的路径长度统一设为 1,且从外卖站出发可以访问到所有地点。
注意:所有送餐地址可以按任意顺序访问,且完成送餐后无需返回外卖站。
输出格式:
对于每个新增的地点,在一行内输出题目需要求的最短路程的距离。
输入样例:
7 4
-1 1 1 1 2 2 3
5
6
2
4
输出样例:
2
4
4
6
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+5;
int n,m,t,a[N],maxx,dis[N],sum,k,vis[N],s;
vector<int>e[N];// DFS函数,用于计算每个节点到根节点的距离
void dfs(int x,int d){dis[x]=d; // 记录节点x到根节点的距离为dfor(int i=0;i<e[x].size();i++) dfs(e[x][i],d+1); // 递归计算子节点到根节点的距离
}int main(){cin>>n>>m;for(int i=1;i<=n;i++){scanf("%d",&a[i]); // 输入每个节点的父节点编号if(a[i]==-1) s=i; // 找到根节点的编号else e[a[i]].push_back(i); // 将节点i加入到其父节点a[i]的子节点列表中}dfs(s,0); // 从根节点开始进行DFS,计算每个节点到根节点的距离vis[s]=1; // 标记根节点已经访问过for(int i=0;i<m;i++){scanf("%d",&t),k=t;while(!vis[k]) vis[k]=1,k=a[k]; // 从节点t一直向上找,直到找到已经访问过的节点maxx=max(maxx,dis[t]); // 更新最大距禝sum+=dis[t]-dis[k]; // 累加每次找到的路径长度printf("%d\n",sum*2-maxx); // 输出结果}return 0;
}R7-3 家谱处理
人类学研究对于家族很感兴趣,于是研究人员搜集了一些家族的家谱进行研究。实验中,使用计算机处理家谱。为了实现这个目的,研究人员将家谱转换为文本文件。下面为家谱文本文件的实例:
JohnRobertFrankAndrewNancyDavid
家谱文本文件中,每一行包含一个人的名字。第一行中的名字是这个家族最早的祖先。家谱仅包含最早祖先的后代,而他们的丈夫或妻子不出现在家谱中。每个人的子女比父母多缩进2个空格。以上述家谱文本文件为例,John这个家族最早的祖先,他有两个子女Robert和Nancy,Robert有两个子女Frank和Andrew,Nancy只有一个子女David。
在实验中,研究人员还收集了家庭文件,并提取了家谱中有关两个人关系的陈述语句。下面为家谱中关系的陈述语句实例:
John is the parent of Robert
Robert is a sibling of Nancy
David is a descendant of Robert
研究人员需要判断每个陈述语句是真还是假,请编写程序帮助研究人员判断。
输入格式:
输入首先给出2个正整数N(2≤N≤100)和M(≤100),其中N为家谱中名字的数量,M为家谱中陈述语句的数量,输入的每行不超过70个字符。
名字的字符串由不超过10个英文字母组成。在家谱中的第一行给出的名字前没有缩进空格。家谱中的其他名字至少缩进2个空格,即他们是家谱中最早祖先(第一行给出的名字)的后代,且如果家谱中一个名字前缩进k个空格,则下一行中名字至多缩进k+2个空格。
在一个家谱中同样的名字不会出现两次,且家谱中没有出现的名字不会出现在陈述语句中。每句陈述语句格式如下,其中X和Y为家谱中的不同名字:
X is a child of Y
X is the parent of Y
X is a sibling of Y
X is a descendant of Y
X is an ancestor of Y
输出格式:
对于测试用例中的每句陈述语句,在一行中输出True,如果陈述为真,或False,如果陈述为假。
输入样例:
6 5
JohnRobertFrankAndrewNancyDavid
Robert is a child of John
Robert is an ancestor of Andrew
Robert is a sibling of Nancy
Nancy is the parent of Frank
John is a descendant of Andrew
输出样例:
True
True
True
False
False
#include<iostream>
#include<vector>
#include<map>
#include<algorithm>
using namespace std;
const int MAX=105;
vector<string>name(MAX); // 存储每个人的姓名
map<string,string>parent; // 存储每个人与其父母的关系
string anc="anc"; // 用于表示祖先节点的字符串int main(){int N,M;cin>>N>>M;getchar(); // 读取换行符string s;while(N--){getline(cin,s); // 逐行读取输入int count1=count(s.begin(),s.end(),' '); // 统计该行中空格的个数s=s.substr(count1); // 截取出姓名if(count1==0){parent[s]=anc; // 如果没有空格,说明是祖先节点name[0]=s; // 将祖先节点的姓名存入name[0]}else{parent[s]=name[count1/2-1]; // 否则,将该节点与其父母的关系存入parent中name[count1/2]=s; // 将该节点的姓名存入name中}}while(M--){string a,b,c,d;cin>>a>>d>>d>>b>>d>>c; // 依次读取查询的条件if(b=="child"){ // 如果查询条件是childif(parent[a]==c)cout<<"True"<<endl; // 如果a的父亲是c,则输出Trueelse cout<<"False"<<endl; // 否则输出False}if(b=="ancestor"){ // 如果查询条件是ancestorwhile(parent[c]!=a&&parent[c]!=anc)c=parent[c]; // 从c开始向上查找,直到找到a或者祖先节点if(parent[c]==anc)cout<<"False"<<endl; // 如果找到祖先节点,则输出Falseelse cout<<"True"<<endl; // 否则输出True}if(b=="sibling"){ // 如果查询条件是siblingif(parent[a]==parent[c])cout<<"True"<<endl; // 如果a和c的父母相同,则输出Trueelse cout<<"False"<<endl; // 否则输出False}if(b=="parent"){ // 如果查询条件是parentif(parent[c]==a)cout<<"True"<<endl; // 如果c的父亲是a,则输出Trueelse cout<<"False"<<endl; // 否则输出False}if(b=="descendant"){ // 如果查询条件是descendantwhile(parent[a]!=c&&parent[a]!=anc)a=parent[a]; // 从a开始向上查找,直到找到c或者祖先节点if(parent[a]==anc)cout<<"False"<<endl; // 如果找到祖先节点,则输出Falseelse cout<<"True"<<endl; // 否则输出True}} return 0;
}以上就是排序算法编程题的专项练习,在下一篇文章中我们将介绍树的相关知识点。
相关文章:
【数据结构入门精讲 | 第十篇】考研408排序算法专项练习(二)
在上文中我们进行了排序算法的判断题、选择题的专项练习,在这一篇中我们将进行排序算法中编程题的练习。 目录 编程题R7-1 字符串的冒泡排序R7-1 抢红包R7-1 PAT排名汇总R7-2 统计工龄R7-1 插入排序还是堆排序R7-2 龙龙送外卖R7-3 家谱处理 编程题 R7-1 字符串的冒…...

【ES实战】Elasticsearch6开始的CCR
【ES实战】学习使用Elasticsearch6开始的CCR 本文涉及官网文章地址 OverviewRequirements for leader indicesAutomatically following indicesGetting started with cross-cluster replicationUpgrading clusters CCR > Cross-cluster replication 文章目录 【ES实战】学…...
Deployment Pay
axure watermark...

MySQL创建member表失败
最近在做一个项目,在台式机上可以跑通,也测试了各个已完成的接口,提交到了GitHub后想着用宿舍的电脑跑一下,在测试member表相关接口时就出错了。报了SQL语法错误,但SQL语句很简单,就根据手机号查询不至于出…...
使用minio实现大文件断点续传
部署 minio 拉取镜像 docker pull minio/minio docker images新建映射目录 新建下面图片里的俩个目录 data(存放对象-实际的数据) config 存放配置开放对应端口 我使用的是腾讯服务器所以 在腾讯的安全页面开启 9000,9090 两个端口就可以了(根据大家实际…...

插入排序之C++实现
描述 插入排序是一种简单直观的排序算法。它的基本思想是将一个待排序的数据序列分为已排序和未排序两部分,每次从未排序序列中取出一个元素,然后将它插入到已排序序列的适当位置,直到所有元素都插入完毕,即完成排序。 实现思路…...
Tomcat日志乱码了怎么处理?
【前言】 tomacat日志有三个地方,分别是Output(控制台)、Tomcat Localhost Log(tomcat本地日志)、Tomcat Catalina Log。 启动日志和大部分报错日志、普通日志都在output打印;有些错误日志,在Tomcat Localhost Log。 三个日志显示区,都可能…...

[node] Node.js的路由
[node] Node.js的路由 路由 & 路由解析路由信息的整合URL信息路由处理逻辑路由逻辑与URL信息的整合路由的使用 路由 & 路由解析 路由需要提供请求的 URL 和其他需要的 GET/POST 参数,随后路由需要根据这些数据来执行相应的代码。 因此,根据 HT…...
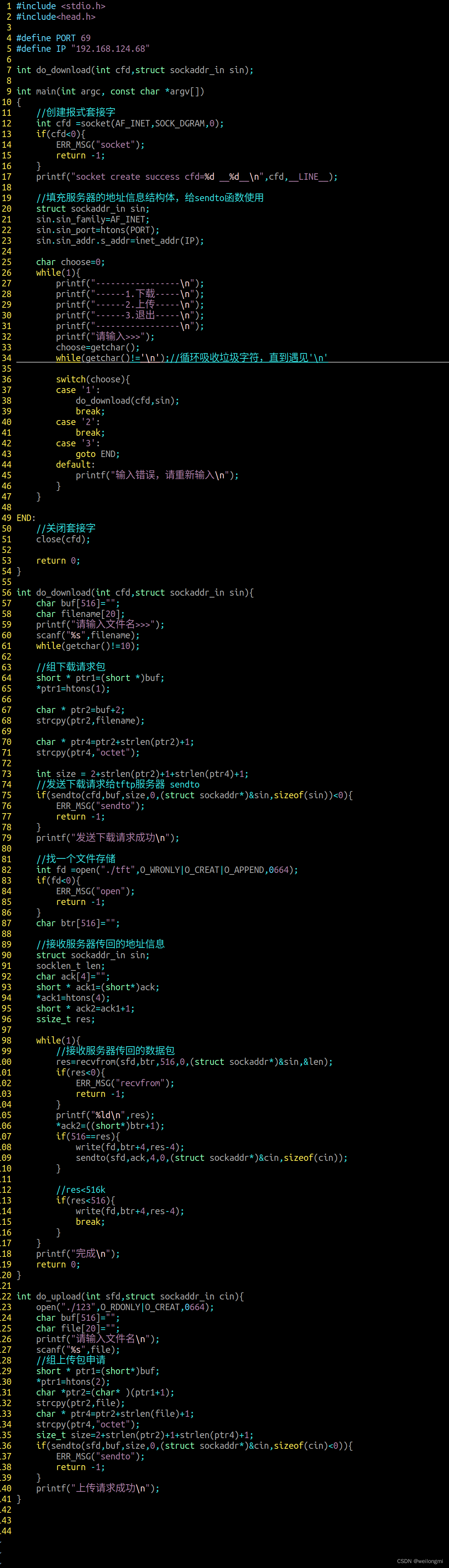
网络编程第三天作业
...
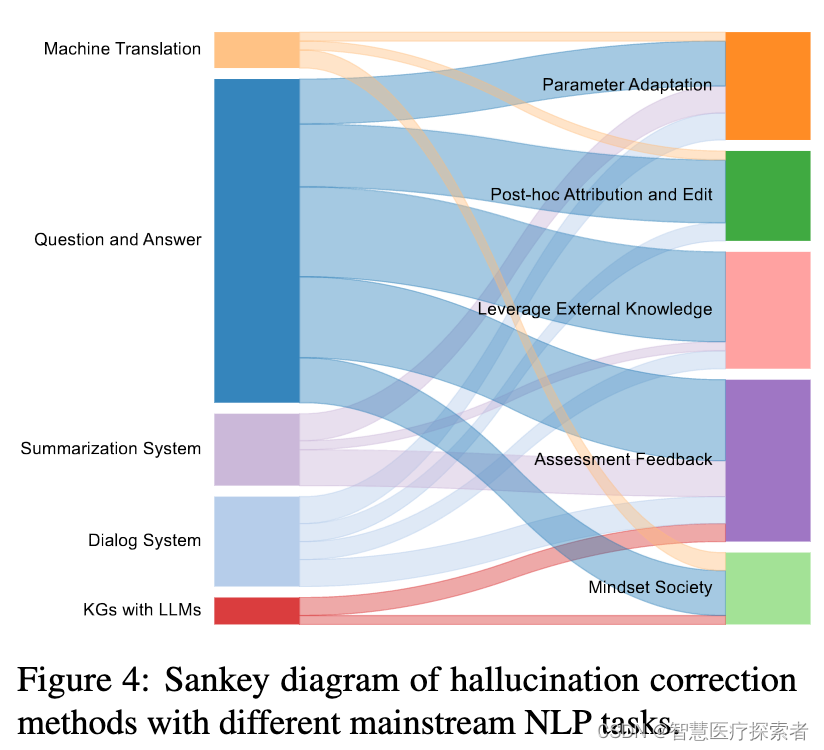
AIGC:大语言模型LLM的幻觉问题
引言 在使用ChatGPT或者其他大模型时,我们经常会遇到模型答非所问、知识错误、甚至自相矛盾的问题。 虽然大语言模型(LLMs)在各种下游任务中展示出了卓越的能力,在多个领域有广泛应用,但存在着幻觉的问题:…...
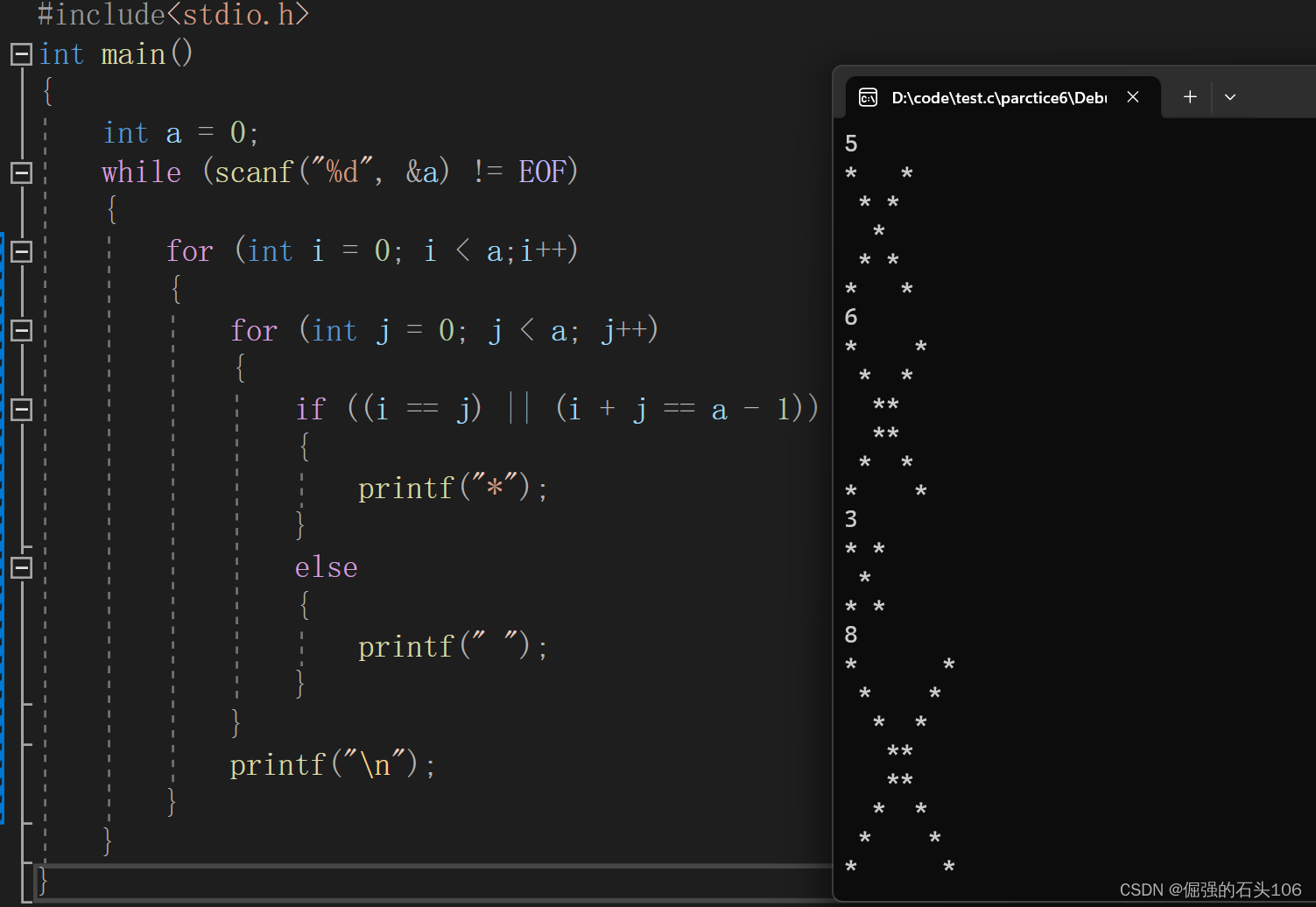
【C语言刷题每日一题#牛客网BC68】——X形图案
问题描述 思路分析 首先根据输入的描述,多组输入需要将scanf放在循环中来实现 #include<stdio.h> int main() {int a 0;while (scanf("%d", &a) ! EOF){} } 完成了输入之后,再来分析输出——输出的是一个由“*”组成的对称的X形…...

阻断血缘关系以及checkpoint文件清理
spark-sql读写同一张表,报错Cannot overwrite a path that is also being read from 1. 增加checkpoint,设置检查点阻断血缘关系 sparkSession.sparkContext.setCheckpointDir("/tmp/spark/job/OrderOnlineSparkJob")val oldOneIdTagSql s&…...
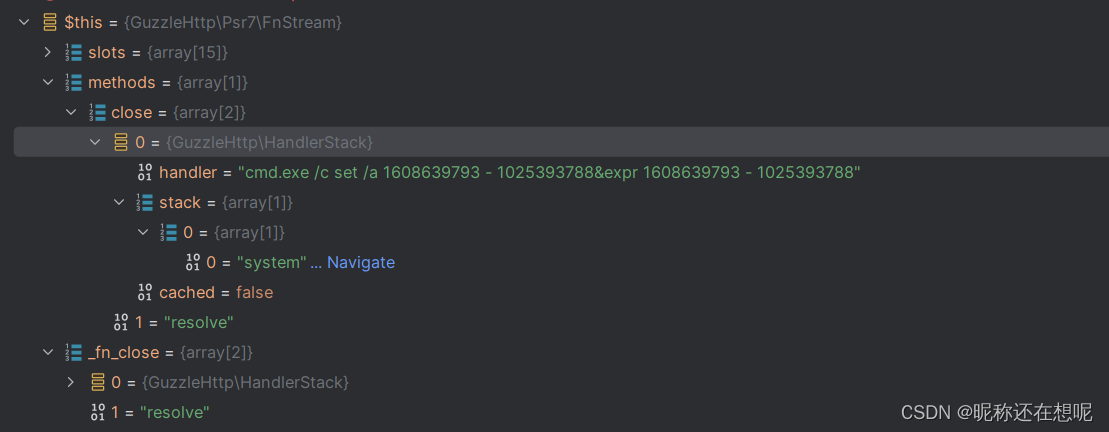
PHP代码审计之反序列化攻击链CVE-2019-6340漏洞研究
关键词 php 反序列化 cms Drupal CVE-2019-6340 DrupalKernel 前言 简简单单介绍下php的反序列化漏洞 php反序列化漏洞简单示例 来看一段简单的php反序列化示例 <?phpclass pingTest {public $ipAddress "127.0.0.1";public $isValid False;public $output…...

PyTorch之线性回归
1.定义: 回归分析是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。线性回归是利用称为线性回归方程的最小二乘函数,对一个或多个自变量和因变量之间关系,进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参…...

SSTI模板注入基础(Flask+Jinja2)
文章目录 一、前置知识1.1 模板引擎1.2 渲染 二、SSTI模板注入2.1 原理2.2 沙箱逃逸沙箱逃逸payload讲解其他重要payload 2.3 过滤绕过点.被过滤下划线_被过滤单双引号 "被过滤中括号[]被过滤关键字被过滤 三、PasecaCTF-2019-Web-Flask SSTI参考文献 一、前置知识 1.1 模…...

React网页转换为pdf并下载|使用jspdf html2canvas
checkout 分支后突然报错,提示: Cant resolve jspdf in ... Cant resolve html2canvas in ... 解决方法很简单,重新 yarn install 就好了,至于为什么,我暂时也不知道,总之解决了。 思路来源: 先…...
)
EASYEXCEL导出表格(有标题、单元格合并)
EASYEXCEL导出表格(有标题、单元格合并) xlsx格式报表的导出,导出的数据存在父子关系,即相当于树形数据,有单元格合并和标题形式的要求,查阅了一些资料,总算是弄出来了,这里另写一个…...

pytest 断言异常
一、前置说明 在 pytest 中,断言异常是通过 pytest 内置的 pytest.raises 上下文管理器来实现的。通过使用 pytest.raises,可以捕获并断言代码中引发的异常。 二、操作步骤 1. 编写测试代码 atme/demos/demo_pytest_tutorials/test_pytest_raises.py import pytest# 示例…...

听GPT 讲Rust源代码--src/tools(22)
File: rust/src/tools/tidy/src/lib.rs rust/src/tools/tidy/src/lib.rs是Rust编译器源代码中tidy工具的实现文件之一。tidy工具是Rust项目中的一项静态检查工具,用于确保代码质量和一致性。 tidy工具主要有以下几个作用: 格式化代码:tidy工具…...

OD Linux发行版本
题目描述: Linux操作系统有多个发行版,distrowatch.com提供了各个发行版的资料。这些发行版互相存在关联,例如Ubuntu基于Debian开发,而Mint又基于Ubuntu开发,那么我们认为Mint同Debian也存在关联。 发行版集是一个或多…...

模块四-数据转换与操作——28. 分组变换与过滤
28. 分组变换与过滤 1. 概述 除了聚合(agg)之外,groupby 还支持**变换(transform)和过滤(filter)**操作。transform 用于在组内进行元素级运算,filter 用于根据组属性筛选组。 impor…...

智能健身器材核心技术解析:从光学编码器到电机驱动的安华高方案
1. 项目概述:当健身器材遇上“芯”动力如果你拆开一台近两年新出的智能动感单车、划船机或者高端跑步机,大概率会在其控制主板的核心位置,发现一枚印着“Avago”或“Broadcom”标志的芯片。这不是偶然。安华高科技(Avago Technolo…...

2026届最火的AI论文助手解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在人工智能生成内容(AIGC)技术迅猛发展之际,它一方面提升…...

【职场】聪明人,从不在公司交朋友
聪明人,从不在公司交朋友“你以为你们是朋友。但有一天你会发现,你们之间站着一个共同的雇主。”一、那个"最懂你"的同事 你们一起骂过同一个领导。 一起在茶水间吐槽过公司文化。 一起在深夜加班时互相打气。 你告诉他你想离职,告…...

8岁小学生idea直接变应用,秒哒3.0刚刚把AI应用门槛打没了
允中 发自 凹非寺量子位 | 公众号 QbitAI“做应用”这件事,现在真的老少咸宜了:一个二年级小朋友,做了个“拼伞小程序”和操作系统。一个4人团队,没写过代码,7天搭出了覆盖9万老人的智慧养老平台。还有人靠AI做依恋类型…...

从数据云到ArcGIS:一站式掌握DEM影像的获取、拼接与裁剪实战
1. DEM影像基础与数据源选择 数字高程模型(DEM)是地理信息系统中描述地表形态的基础数据,广泛应用于地形分析、水文模拟、工程建设等领域。对于刚接触GIS的朋友来说,最常见的困惑就是:从哪里获取DEM数据?不…...

Notemd Pro:基于Web技术栈的开源个人知识管理应用深度解析
1. 项目概述:一个面向未来的笔记应用如果你和我一样,常年混迹在程序员、产品经理和知识工作者的圈子里,那你一定对“笔记软件”这个赛道又爱又恨。爱的是,它确实是我们整理思路、记录灵感、构建知识体系的刚需;恨的是&…...

如何快速清理Windows驱动存储:Driver Store Explorer完整使用指南
如何快速清理Windows驱动存储:Driver Store Explorer完整使用指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer Driver Store Explorer(简称RAPR)是…...

Steam Deck Windows控制器驱动终极配置指南:5步实现完美游戏体验
Steam Deck Windows控制器驱动终极配置指南:5步实现完美游戏体验 【免费下载链接】steam-deck-windows-usermode-driver A windows usermode controller driver for the steam deck internal controller. 项目地址: https://gitcode.com/gh_mirrors/st/steam-deck…...

教育机构搭建AI辅助教学系统时如何通过Taotoken统一接口
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 教育机构搭建AI辅助教学系统时如何通过Taotoken统一接口 构建一个服务于师生的AI辅助教学系统,通常需要集成多种能力&a…...