DeamonSet详解
目录
1.1 何为DaemonSet
1.2 DaemonSet 的 API 对象的定义
1.3 DaemonSet实践
1.3.1 创建 DaemonSet 对象
1.3.2 查看 DaemonSet 对象
1.3.3 DaemonSet 版本管理
1.3.4 DaemonSet 的容器镜像版本到 v2.2.0
1.1 何为DaemonSet
介绍DaemonSet我们先来思考一个问题:相信大家都接触过监控系统比如zabbix,监控系统需要在被监控机安装一个agent,安装agent通常会涉及到以下几个场景:
- 所有节点都必须安装agent以便采集监控数据 - 新加入的节点需要配置agent,手动或者运行脚本
k8s中经常涉及到在node上安装部署应用,它是如何解决上述的问题的呢?答案是DaemonSet。DaemonSet守护进程简称DS,适用于在所有节点或部分节点运行一个daemon守护进程。
DaemonSet 的主要作用,是让你在 k8s 集群里,运行一个 Daemon Pod。
这个 Pod 有如下三个特征:
这个 Pod 运行在 k8s 集群里的每一个节点(Node)上;
每个节点上只有一个这样的 Pod 实例;
当有新的节点加入 Kubernetes 集群后,该 Pod 会自动地在新节点上被创建出来;而当旧节点被删除后,它上面的 Pod 也相应地会被回收掉。
举例:
各种网络插件的 Agent 组件,都必须运行在每一个节点上,用来处理这个节点上的容器网络;
各种存储插件的 Agent 组件,也必须运行在每一个节点上,用来在这个节点上挂载远程存储目录,操作容器的 Volume 目录;
各种监控组件和日志组件,也必须运行在每一个节点上,负责这个节点上的监控信息和日志搜集。
1.2 DaemonSet 的 API 对象的定义
所有node节点分别下载镜像
# docker pull daocloud.io/daocloud/fluentd-elasticsearch:1.20 # docker pull daocloud.io/daocloud/fluentd-elasticsearch:v2.2.0
fluentd-elasticsearch 镜像功能:
通过 fluentd 将每个node节点上面的Docker 容器里的日志转发到 ElasticSearch 中。
编写daemonset配置文件
Yaml文件内容如下
[root@k8s-master ~]# mkdir set
[root@k8s-master ~]# cd set/
[root@k8s-master set]# vim fluentd-elasticsearch.yaml # DaemonSet 没有 replicas 字段
apiVersion: apps/v1
kind: DaemonSet #创建资源的类型
metadata:name: fluentd-elasticsearchnamespace: kube-systemlabels:k8s-app: fluentd-logging
spec:selector:matchLabels:name: fluentd-elasticsearchtemplate:metadata:labels:name: fluentd-elasticsearchspec:tolerations: #容忍污点- key: node-role.kubernetes.io/master #污点effect: NoSchedule #描述污点的效应containers:- name: fluentd-elasticsearchimage: daocloud.io/daocloud/fluentd-elasticsearch:1.20resources: #限制使用资源limits: #定义使用内存的资源上限memory: 200Mirequests: #实际使用cpu: 100mmemory: 200MivolumeMounts:- name: varlogmountPath: /var/log- name: varlibdockercontainersmountPath: /var/lib/docker/containersreadOnly: truevolumes:- name: varloghostPath: #定义卷使用宿主机目录path: /var/log- name: varlibdockercontainershostPath:path: /var/lib/docker/containersDaemonSet 没有 replicas 字段
selector :
选择管理所有携带了 name=fluentd-elasticsearch 标签的 Pod。
Pod 的模板用 template 字段定义:
定义了一个使用 fluentd-elasticsearch:1.20 镜像的容器,而且这个容器挂载了两个 hostPath 类型的 Volume,分别对应宿主机的 /var/log 目录和 /var/lib/docker/containers 目录。
fluentd 启动之后,它会从这两个目录里搜集日志信息,并转发给 ElasticSearch 保存。这样,通过 ElasticSearch 就可以很方便地检索这些日志了。Docker 容器里应用的日志,默认会保存在宿主机的 /var/lib/docker/containers/{{. 容器 ID}}/{{. 容器 ID}}-json.log 文件里,这个目录正是 fluentd 的搜集目标。
DaemonSet 如何保证每个 Node 上有且只有一个被管理的 Pod ?
DaemonSet Controller,首先从 Etcd 里获取所有的 Node 列表,然后遍历所有的 Node。这时,它就可以很容易地去检查,当前这个 Node 上是不是有一个携带了 name=fluentd-elasticsearch 标签的 Pod 在运行。
检查结果有三种情况:
1. 没有这种 Pod,那么就意味着要在这个 Node 上创建这样一个 Pod;指定的 Node 上创建新 Pod 用 nodeSelector,选择 Node 的名字即可。 2. 有这种 Pod,但是数量大于 1,那就说明要把多余的 Pod 从这个 Node 上删除掉;删除节点(Node)上多余的 Pod 非常简单,直接调用 Kubernetes API 就可以了。 3. 正好只有一个这种 Pod,那说明这个节点是正常的。
tolerations:
DaemonSet 还会给这个 Pod 自动加上另外一个与调度相关的字段,叫作 tolerations。这个字段意思是这个 Pod,会"容忍"(Toleration)某些 Node 的"污点"(Taint)。
tolerations 字段,格式如下:
apiVersion: v1 kind: Pod metadata:name: with-toleration spec:tolerations:- key: node.kubernetes.io/unschedulable #污点的keyoperator: Exists #将会忽略value;只要有key和effect就行effect: NoSchedule #污点的作用
含义是:"容忍"所有被标记为 unschedulable"污点"的 Node;"容忍"的效果是允许调度。可以简单地把"污点"理解为一种特殊的 Label。
正常情况下,被标记了 unschedulable"污点"的 Node,是不会有任何 Pod 被调度上去的(effect: NoSchedule)。可是,DaemonSet 自动地给被管理的 Pod 加上了这个特殊的 Toleration,就使得这些 Pod 可以忽略这个限制,保证每个节点上都会被调度一个 Pod。如果这个节点有故障的话,这个 Pod 可能会启动失败,DaemonSet 会始终尝试下去,直到 Pod 启动成功。
DaemonSet 的"过人之处",其实就是依靠 Toleration 实现的
DaemonSet 是一个控制器。在它的控制循环中,只需要遍历所有节点,然后根据节点上是否有被管理 Pod 的情况,来决定是否要创建或者删除一个 Pod。
更多种类的Toleration
可以在 Pod 模板里加上更多种类的 Toleration,从而利用 DaemonSet 实现自己的目的。
比如,在这个 fluentd-elasticsearch DaemonSet 里,给它加上了这样的 Toleration:
tolerations: - key: node-role.kubernetes.io/mastereffect: NoSchedule
这是因为在默认情况下,Kubernetes 集群不允许用户在 Master 节点部署 Pod。因为,Master 节点默认携带了一个叫作node-role.kubernetes.io/master的"污点"。所以,为了能在 Master 节点上部署 DaemonSet 的 Pod,就必须让这个 Pod"容忍"这个"污点"。
1.3 DaemonSet实践
1.3.1 创建 DaemonSet 对象
[root@k8s-master set] # kubectl create -f fluentd-elasticsearch.yamlDaemonSet 上一般都加上 resources 字段,来限制它的 CPU 和内存使用,防止它占用过多的宿主机资源。
创建成功后,如果有 3 个节点,就会有 3 个 fluentd-elasticsearch Pod 在运行
[root@k8s-master set]# kubectl get pod -n kube-system -l name=fluentd-elasticsearch
NAME READY STATUS RESTARTS AGE
fluentd-elasticsearch-6lmnb 1/1 Running 0 21m
fluentd-elasticsearch-9fd7k 1/1 Running 0 21m
fluentd-elasticsearch-vz4n4 1/1 Running 0 21m1.3.2 查看 DaemonSet 对象
[root@k8s-master set]# kubectl get ds -n kube-system fluentd-elasticsearch
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
fluentd-elasticsearch 3 3 3 3 3 <none> 22m注:k8s 里比较长的 API 对象都有短名字,比如 DaemonSet 对应的是 ds,Deployment 对应的是 deploy。
1.3.3 DaemonSet 版本管理
[root@k8s-master set]# kubectl rollout history daemonset fluentd-elasticsearch -n kube-system
daemonset.apps/fluentd-elasticsearch
REVISION CHANGE-CAUSE
1 <none>1.3.4 DaemonSet 的容器镜像版本到 v2.2.0
[root@k8s-master set]# kubectl set image ds/fluentd-elasticsearch fluentd-elasticsearch=daocloud.io/daocloud/fluentd-elasticsearch:v2.2.0 --record -n=kube-system
daemonset.apps/fluentd-elasticsearch image updated这个 kubectl set image 命令里,第一个 fluentd-elasticsearch 是 DaemonSet 的名字,第二个 fluentd-elasticsearch 是容器的名字。
--record 参数:
升级使用到的指令会自动出现在 DaemonSet 的 rollout history 里面,如下所示:
[root@k8s-master set]# kubectl rollout history daemonset fluentd-elasticsearch -n kube-system
daemonset.apps/fluentd-elasticsearch
REVISION CHANGE-CAUSE
1 <none>
2 kubectl set image ds/fluentd-elasticsearch fluentd-elasticsearch=daocloud.io/daocloud/fluentd-elasticsearch:v2.2.0 --record=true --namespace=kube-system有了版本号,也就可以像 Deployment 一样,将 DaemonSet 回滚到某个指定的历史版本了。
相关文章:

DeamonSet详解
目录 1.1 何为DaemonSet 1.2 DaemonSet 的 API 对象的定义 1.3 DaemonSet实践 1.3.1 创建 DaemonSet 对象 1.3.2 查看 DaemonSet 对象 1.3.3 DaemonSet 版本管理 1.3.4 DaemonSet 的容器镜像版本到 v2.2.0 1.1 何为DaemonSet 介绍DaemonSet我们先来思考一个问题&#x…...

TwIST算法MALTLAB主程序详解
TwIST算法MALTLAB主程序详解 关于TwIST算法的具体原理可以参考: 链接: https://ieeexplore.ieee.org/abstract/document/4358846 链接: https://blog.csdn.net/jbb0523/article/details/52193209 该算法的MATLAB源代码: 链接: http://www.lx.it.pt/~bi…...

Flutter 三: Dart
1 数据类型 数字(number) int double 字符串转换成 num int.parse(“1”) double.parse(“1”);double 四舍五入保留两位小数 toStringAsFixed(2) 返回值为stringdouble 直接舍弃小数点后几位的数据 可使用字符串截取的方式 字符串(string) 单引号 双引号 三引号三引号 可以输…...
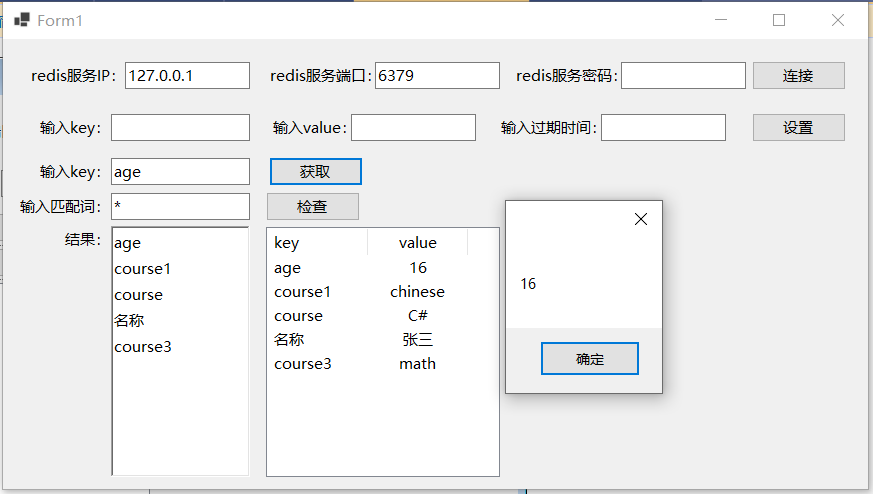
redis基本用法学习(C#调用FreeRedis操作redis)
FreeRedis属于常用的基于.net的redis客户端,EasyCaching中也提供适配FreeRedis的包。根据参考文献4中的说法,FreeRedis和CsRedis算是近亲(都是GitHub中账号为2881099下的开源项目),因此其用法特别相似。FreeRedis的主要…...
Postman接口测试(超详细整理)
常用的接口测试工具主要有以下几种 Postman:简单方便的接口调试工具,便于分享和协作。具有接口调试,接口集管理,环境配置,参数化,断言,批量执行,录制接口,Mock Server, …...

【深入解析spring cloud gateway】12 gateway参数调优与分析
本节主要对网关主要的一些参数做一些解释说明,并用压测工具测试一下网关的接口,通过压测来验证参数配置是否合理 一、连接池参数 参数示例 spring:application:name: gatewaycloud:gateway:# http连接设置httpclient:# 全局的响应超时时间,…...

Java继承,父类没有无参构造方法时,子类必须要显式调用父类的构造方法
在Java中,如果一个类没有定义任何构造函数,那么编译器会默认为这个类提供一个无参的构造函数。 这个隐式的构造函数在继承的时候,子类会在自己的构造方法里面默认的调用这个构造函数。 但是,如果我们在父类中定义了一个有参构造…...
Ubuntu 20.04使用Livox Mid-360
参考文章: Ubuntu 20.04使用Livox mid 360 测试 FAST_LIO-CSDN博客 一:Livox mid 360驱动安装与测试 前言: Livox mid360需要使用Livox-SDK2,而非Livox-SDK,以及对应的livox_ros_driver2 。并需要修改FAST_LIO中部…...

C语言之冒泡排序
其实排序有很多的方法,比如:冒泡排序,插入排序,快速排序,归并排序,选择排序等。今天来讲一下最简单的排序:冒泡排序。这种排序的方法效率极其低下。 假设有一个整型数组: int arr[…...
)
在Linux上安装NVM(Node Version Manager)
在Linux系统上,使用NVM(Node Version Manager)是管理和切换Node.js版本的一种便捷方式。以下是在Linux上安装NVM的步骤: 1. 下载并安装NVM 使用curl或wget下载并运行NVM的安装脚本。选择一种方式执行以下命令之一: …...

常用两种Linux命令生成器
在Linux中,可以使用多种命令来生成随机密码。以下是其中两种常用的命令: 1.pwgen:这个命令可以生成随机、无意义的但容易发音的密码。生成的密码可以只包含小写字母、大小写混合或数字。大写字母和数字会以一种便于记忆的方式放置࿰…...

【OAuth2】授权框架的四种授权方式详解
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《OAuth 2》。🎯🎯 …...

AI数字人不间断直播是什么?数字人直播带货如何搭建?
随着电商行业的崛起,数字人直播成为了最为热门的直播方式之一。数字人直播利用AI技术创建出的数字人进行直播,给观众带来了全新的视觉体验。 一、AI数字人无限播(数字人SaaS系统VX:zhibo175)是什么? AI数字…...
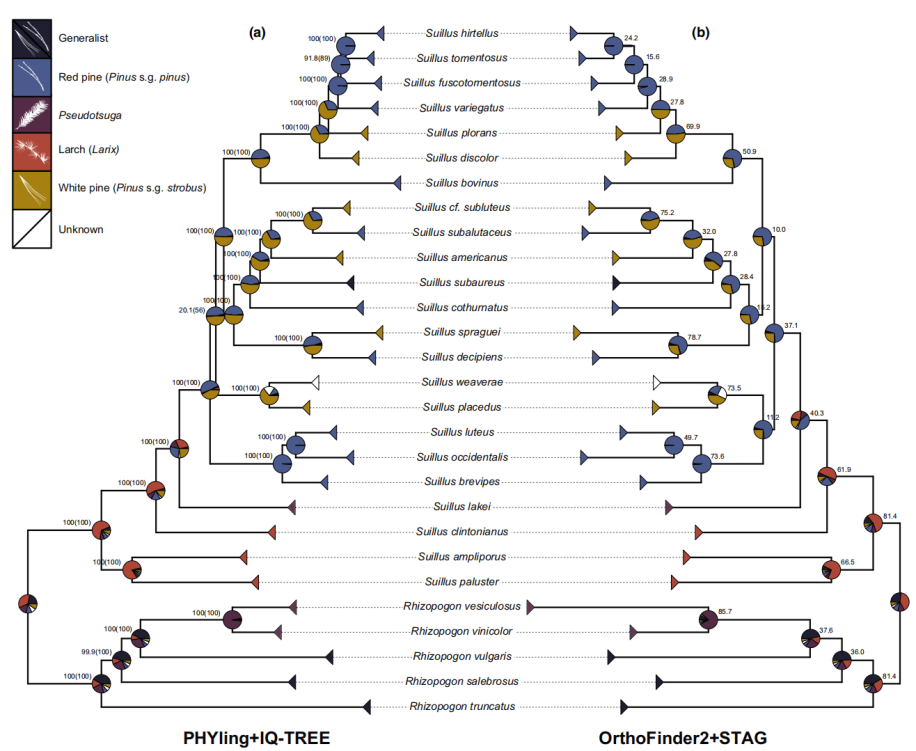
真菌基因组研究高分策略(二):比较基因组揭示寄主外生菌根真菌基因组的动态进化
在表征外生菌根(ECM)真菌的“共生工具包”方面的研究已经取得了重大进展,但宿主特异性如何被编码到ECM真菌基因组中仍知之甚少。2021年发表于《New Phytologist》期刊的文章对ECM真菌宿主特异性和通用性进行了比较基因组分析,重点…...
uni-app之HelloWorld实现
锋哥原创的uni-app视频教程: 2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中..._哔哩哔哩_bilibili2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中...共计23条视频,包括:第1讲 uni…...
CVE-2023-49898 Apache incubator-streampark 远程命令执行漏洞
项目介绍 Apache Flink 和 Apache Spark 被广泛用作下一代大数据流计算引擎。基于大量优秀经验结合最佳实践,我们将任务部署和运行时参数提取到配置文件中。这样,带有开箱即用连接器的易于使用的 RuntimeContext 将带来更轻松、更高效的任务开发体验。它…...

即将来临的2024年,汽车战场再起波澜?
我们来简要概况一下11月主流车企的销量表现: 根据数据显示,11月吉利集团总销量29.32万辆,同比增长28%。这在当月国内主流车企中综合实力凌厉,可谓表现得体。而与吉利直接竞争的比亚迪,尽管数据未公布,但我们…...

Python 爬虫之下载视频(二)
爬取某Y的视频链接和标题 文章目录 爬取某Y的视频链接和标题前言一、基本思路二、程序解析阶段三、程序处理阶段总结 前言 这篇内容就简单给大家写个如何从网页上爬取某B主 主页 页面上所有的视频链接和视频标题。 这篇是基础好好看,下篇会根据这篇的结果做一个批…...

智能优化算法应用:基于原子轨道搜索算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于原子轨道搜索算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于原子轨道搜索算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.原子轨道搜索算法4.实验参数设定…...

[机器人-2]:开源MIT Min cheetah机械狗设计(二):机械结构设计
目录 1、四肢朝向的选择 2、电机布局形式的选择 3、电机的选型及测试(非常重要) 4、结构优化 5、尺寸效应 6、其他 1、四肢朝向的选择 机械狗的结构设计,第一个摆在我们面前的就说四肢的朝向问题,如下图,我们是…...

Windows上的革命性文件系统:WinBtrfs完整指南与实用教程
Windows上的革命性文件系统:WinBtrfs完整指南与实用教程 【免费下载链接】btrfs WinBtrfs - an open-source btrfs driver for Windows 项目地址: https://gitcode.com/gh_mirrors/bt/btrfs WinBtrfs是一个开源的Windows驱动程序,为Windows用户带…...

鸿蒙与Kotlin跨平台开发中的性能与功耗深度优化实践
摘要:本文聚焦KMP(Kotlin Multiplatform)与鸿蒙(ArkTS)集成开发中的性能与功耗优化,结合架构设计、系统级调优及实战案例,提供可落地的解决方案。全文涵盖核心优化领域:内存管理、渲染管线、跨进程通信、功耗模型分析等,适用于中大型项目迁移与重构。 一、KMP跨平台模…...

3步解锁Cursor Pro永久免费使用:告别试用限制的终极指南
3步解锁Cursor Pro永久免费使用:告别试用限制的终极指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your t…...

RP2040内置温度传感器:零成本实现精准温度监测与校准
1. 项目概述:为什么要在Pico上折腾内置温度传感器?如果你手头有一块树莓派Pico,或者任何基于RP2040芯片的开发板,你可能已经用它点亮过LED、驱动过电机,甚至玩过一些简单的通信协议。但你是否知道,就在这块…...

免费跨平台绘图神器:draw.io桌面版终极使用指南
免费跨平台绘图神器:draw.io桌面版终极使用指南 【免费下载链接】drawio-desktop Official electron build of draw.io 项目地址: https://gitcode.com/GitHub_Trending/dr/drawio-desktop 还在为不同系统间的图表文件兼容性而烦恼吗?ᾑ…...

免ROOT实现安卓摄像头HOOK:探索微信QQ等主流App虚拟视频替换方案
1. 免ROOT实现安卓摄像头HOOK的核心原理 安卓系统的摄像头调用流程其实就像是一个快递配送系统。当你在微信里点击视频通话按钮时,应用程序会向系统发出一个"取快递"请求(Camera.open()),系统会分配一个快递员ÿ…...

构建智能工单协同系统:Agent技术驱动研发效能提升
1. 项目概述:一个面向开发者的智能工单与任务协同系统最近在梳理团队内部的工作流时,我一直在思考一个问题:如何让代码仓库(比如 GitHub、GitLab)里的 Issues、Pull Requests 这些“待办事项”,不再只是静态…...

跨镜追踪技术・十大核心应用场景
镜像视界浙江科技有限公司以无感空间重构 全域跨镜追踪为核心,依托全栈自研引擎与权威资质背书,构建自成体系、无同类对标、无可替代的空间智能应用矩阵。技术原生适配复杂实景,在无 GPS、无标签、无穿戴、无基站条件下,实现厘米…...

Linux微信小程序开发终极指南:从零搭建完整开发环境
Linux微信小程序开发终极指南:从零搭建完整开发环境 【免费下载链接】wechat-web-devtools-linux 适用于微信小程序的微信开发者工具 Linux移植版 项目地址: https://gitcode.com/gh_mirrors/we/wechat-web-devtools-linux 还在为Linux系统无法进行微信小程序…...

Mybatis-Plus条件构造器实战:QueryWrapper与UpdateWrapper的进阶应用与避坑指南
1. 为什么需要条件构造器? 在日常开发中,数据库操作是绕不开的话题。记得我刚入行时,每次写SQL都要手动拼接字符串,不仅容易出错,还经常被SQL注入漏洞困扰。后来接触到MyBatis,虽然解决了安全问题…...