批量归一化
目录
一、BN层介绍
1、深层神经网络存在的问题
2、批量归一化公式的数学推导
3、BN层的作用位置
4、 预测过程中的批量归一化
5、BN层加速模型训练的原因
6、总结
二、批量归一化从零实现
1、实现批量归一化操作
2、创建BN层
3、对LeNet加入批量归一化
4、开始训练
三、简明实现
1、对LeNet加入批量归一化
2、开始训练
一、BN层介绍
批量归一化(Batch Normalization)是一种用于深度神经网络的常用技术,旨在加快模型的训练速度、提高模型的稳定性和泛化能力。
1、深层神经网络存在的问题
在深度神经网络中,反向传播算法用于计算网络参数的梯度,以便通过梯度下降等优化算法来更新参数。损失函数在神经网络的上层计算损失,梯度在反向传播过程中会逐层传递,通过链式法则计算每一层的梯度,就导致上层梯度大而下层梯度小。当网络层数很深时,梯度在传递过程中可能会变得非常小,甚至趋近于零,这就是梯度消失问题。
梯度消失问题会导致深层网络的参数难以更新,因为梯度信息无法有效地传播回浅层网络。这会导致浅层网络的参数在训练过程中几乎不会得到更新,导致收敛速度较慢,从而影响了整个网络的训练效果。
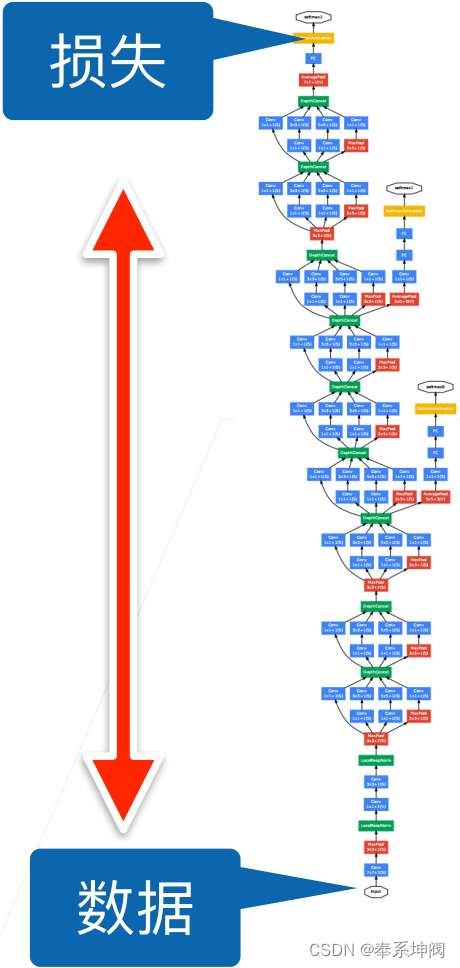
2、批量归一化公式的数学推导
请注意,我们在方差估计值中添加一个小的常量 ,以确保我们永远不会尝试除以零。应用标准化(
)后,生成的小批量的平均值为0和单位方差为1。由于单位方差是一个主观的选择,因此需要重新学习一个新的拉伸参数(scale)
和偏移参数(shift)
。

因此的均值为
,方差为
。
因此的均值为0,方差为1。
因此的均值为
,方差为
。
样本减去其均值后除以方差的操作被称为标准化或归一化。这种操作常用于统计分析和机器学习中。
3、BN层的作用位置

4、 预测过程中的批量归一化
批量规一化在训练模式和预测模式下的行为通常不同。在预测模式下,我们使用训练时得到的移动平均均值(moving_mean)和方差(moving_var)来进行归一化,而不是使用验证集的数据重新计算。批量归一化在训练模式和预测模式下的行为不同,这一点和暂退法(丢弃法)有点像。
5、BN层加速模型训练的原因
批量归一化(Batch Normalization)在深度学习中能够加快模型训练速度的原因主要有以下几点:
缓解梯度消失问题:在深层神经网络中,梯度消失是一个常见的问题,导致较深层的梯度信息无法有效地传播回浅层网络。批量归一化通过对每一层的输入进行标准化,使得输入数据的均值接近0,方差接近1,从而使得激活函数的输入范围更加适中,避免了输入数据过大或过小,激活函数在其有效范围内具有较大的导数值,从而使得梯度能够更好地通过网络传播。这样,即使在深层网络中,梯度仍然可以有效地反向传播,从而保持参数的更新,缓解梯度消失问题,加速模型的训练过程。
加速收敛:批量归一化通过标准化每一层的输入,将数据分布调整为接近标准正态分布,使得网络的参数更容易学习。这有助于加快模型的收敛速度,减少训练的迭代次数,从而加速模型的训练过程。
增加学习率:批量归一化使得网络中的各层输入具有相对较小的变化范围,从而增加了模型对学习率的鲁棒性。较大的学习率可以加速模型的收敛,同时避免了因为学习率过大导致的不稳定性。
正则化效果:批量归一化本质上对每一层的输入进行了规范化处理,类似于一种正则化的效果。它在一定程度上减少了模型对输入数据的依赖,增强了模型的泛化能力,有助于防止过拟合。
总的来说,批量归一化通过标准化每一层的输入数据,缓解梯度消失问题,加快模型的收敛速度,增加学习率和正则化效果,从而有效地加快模型的训练速度。
6、总结
- 批量归一化固定小批量中的均值和方差,然后学习出适合的偏移和缩放
- 可以加速收敛速度,但一般不改变模型精度
二、批量归一化从零实现
1、实现批量归一化操作
下面,我们从头开始实现一个具有张量的批量规范化层。
import torch
from torch import nn
from d2l import torch as d2ldef batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum): # X:输入 gamma,beta:可学习参数γ,β moving_mean,moving_var:全局均值和方差,做推理时用 eps:避免除0的东西 momentum:用来更新γ,β的参数# 通过is_grad_enabled来判断当前模式是训练模式还是预测模式if not torch.is_grad_enabled():# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)else:assert len(X.shape) in (2, 4) # 等于2的话就是全连接层,等于4的话就是卷积层if len(X.shape) == 2:# 使用全连接层的情况,计算特征维上的均值和方差mean = X.mean(dim=0) # 二维的话第一维是批量大小(行),第二维是特征(列),dim=0表示每一列算出一个均值var = ((X - mean) ** 2).mean(dim=0)else:# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。# 这里我们需要保持X的形状以便后面可以做广播运算mean = X.mean(dim=(0, 2, 3), keepdim=True)var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)# 训练模式下,用当前的均值和方差做标准化X_hat = (X - mean) / torch.sqrt(var + eps)# 更新移动平均的均值和方差moving_mean = momentum * moving_mean + (1.0 - momentum) * meanmoving_var = momentum * moving_var + (1.0 - momentum) * varY = gamma * X_hat + beta # 缩放和移位return Y, moving_mean.data, moving_var.datamomentum 是一个介于 0 和 1 之间的超参数,用于控制移动平均的更新速度。在批量归一化中,为了减少每个批次数据的波动对均值和方差的影响,通常会计算移动平均的均值和方差。这样可以提供更稳定的均值和方差估计,从而使得批量归一化在测试阶段也能够起到归一化的效果。在测试阶段,使用移动平均的均值和方差来对数据进行归一化,以保持与训练阶段的一致性。
self.moving_mean 和 self.moving_var 需要在前向传播过程中与输入数据 X 在相同的设备上进行计算,所以需要使用 .to(X.device) 进行设备转移操作。而 self.gamma 和 self.beta 是可学习参数,已经被定义为 nn.Parameter,会自动根据模型所在的设备进行初始化,所以不需要额外的设备转移操作。
在全连接层中,输入数据的维度通常为两个,分别是:
- 批量大小(Batch Size):表示一次输入的样本数量,即一批数据的大小。通常用于同时处理多个样本,以利用并行计算的优势。
- 特征维度(Feature Dimension):表示每个样本在全连接层中的特征表示。这个维度的大小可以根据任务和网络设计进行调整,通常是通过将输入数据展平(flatten)为一维向量来实现。展平操作将多维的输入数据转换为一维的特征向量,作为全连接层的输入。
例如,如果输入数据的维度为[batch_size, num_features],其中batch_size表示批量大小,num_features表示每个样本的特征维度,那么全连接层的两个维度就分别是batch_size和num_features。
2、创建BN层
我们现在可以创建一个正确的`BatchNorm`层。这个层将保持适当的参数:拉伸`gamma`和偏移`beta`,这两个参数将在训练过程中更新。此外,我们的层将保存均值和方差的移动平均值,以便在模型预测期间随后使用。
撇开算法细节,注意我们实现层的基础设计模式。通常情况下,我们用一个单独的函数定义其数学原理,比如说`batch_norm`。然后,我们将此功能集成到一个自定义层中,其代码主要处理数据移动到训练设备(如GPU)、分配和初始化任何必需的变量、跟踪移动平均线(此处为均值和方差)等问题。为了方便起见,我们并不担心在这里自动推断输入形状,因此我们需要指定整个特征的数量。
class BatchNorm(nn.Module):# num_features:全连接层的输出数量或卷积层的输出通道数。# num_dims:2表示完全连接层,4表示卷积层def __init__(self, num_features, num_dims):super().__init__()if num_dims == 2:shape = (1, num_features) # (batch_size, num_features)else:shape = (1, num_features, 1, 1) # (batch_size, channel, height, width)# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成1和0self.gamma = nn.Parameter(torch.ones(shape))self.beta = nn.Parameter(torch.zeros(shape))# 非模型参数的变量初始化为0和1self.moving_mean = torch.zeros(shape)self.moving_var = torch.ones(shape)def forward(self, X):# 如果X不在内存上,将moving_mean和moving_var# 复制到X所在显存上if self.moving_mean.device != X.device:self.moving_mean = self.moving_mean.to(X.device)self.moving_var = self.moving_var.to(X.device)# 保存更新过的moving_mean和moving_var,等待下一个批量进来继续更新,直到整个训练过程完全结束Y, self.moving_mean, self.moving_var = batch_norm(X, self.gamma, self.beta, self.moving_mean,self.moving_var, eps=1e-5, momentum=0.9) # 预测模式下不更新self.moving_mean和self.moving_var,只在训练模式下更新return Y在PyTorch中,nn.Parameter是一个特殊的张量,它被用作模型的可学习参数。当我们使用nn.Parameter包装一个张量时,PyTorch会自动将其标记为模型参数,使得在模型的训练过程中可以对其进行自动求导和更新。
在这段代码中,self.gamma和self.beta是可学习参数,它们用于缩放(gamma)和偏移(beta)归一化后的数据。因此,我们需要使用nn.Parameter将这两个张量标记为模型参数,以便可以对它们进行自动求导和更新。
而self.moving_mean和self.moving_var是批量归一化层中的非模型参数。它们用于保存移动平均的均值和方差,在训练过程中会被更新。但是它们不是模型的可学习参数,因此不需要使用nn.Parameter进行标记。
3、对LeNet加入批量归一化
为了更好理解如何应用`BatchNorm`,下面我们将其应用于LeNet模型。批量规范化是在卷积层或全连接层之后、相应的激活函数之前应用的。
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5), BatchNorm(6, num_dims=4), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), BatchNorm(16, num_dims=4), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),nn.Linear(16*4*4, 120), BatchNorm(120, num_dims=2), nn.Sigmoid(),nn.Linear(120, 84), BatchNorm(84, num_dims=2), nn.Sigmoid(),nn.Linear(84, 10))4、开始训练
和以前一样,我们将在Fashion-MNIST数据集上训练网络。这个代码与我们第一次训练LeNet时几乎完全相同,主要区别在于学习率大得多。
lr, num_epochs, batch_size = 1.0, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())loss 0.273, train acc 0.899, test acc 0.807
32293.9 examples/sec on cuda:0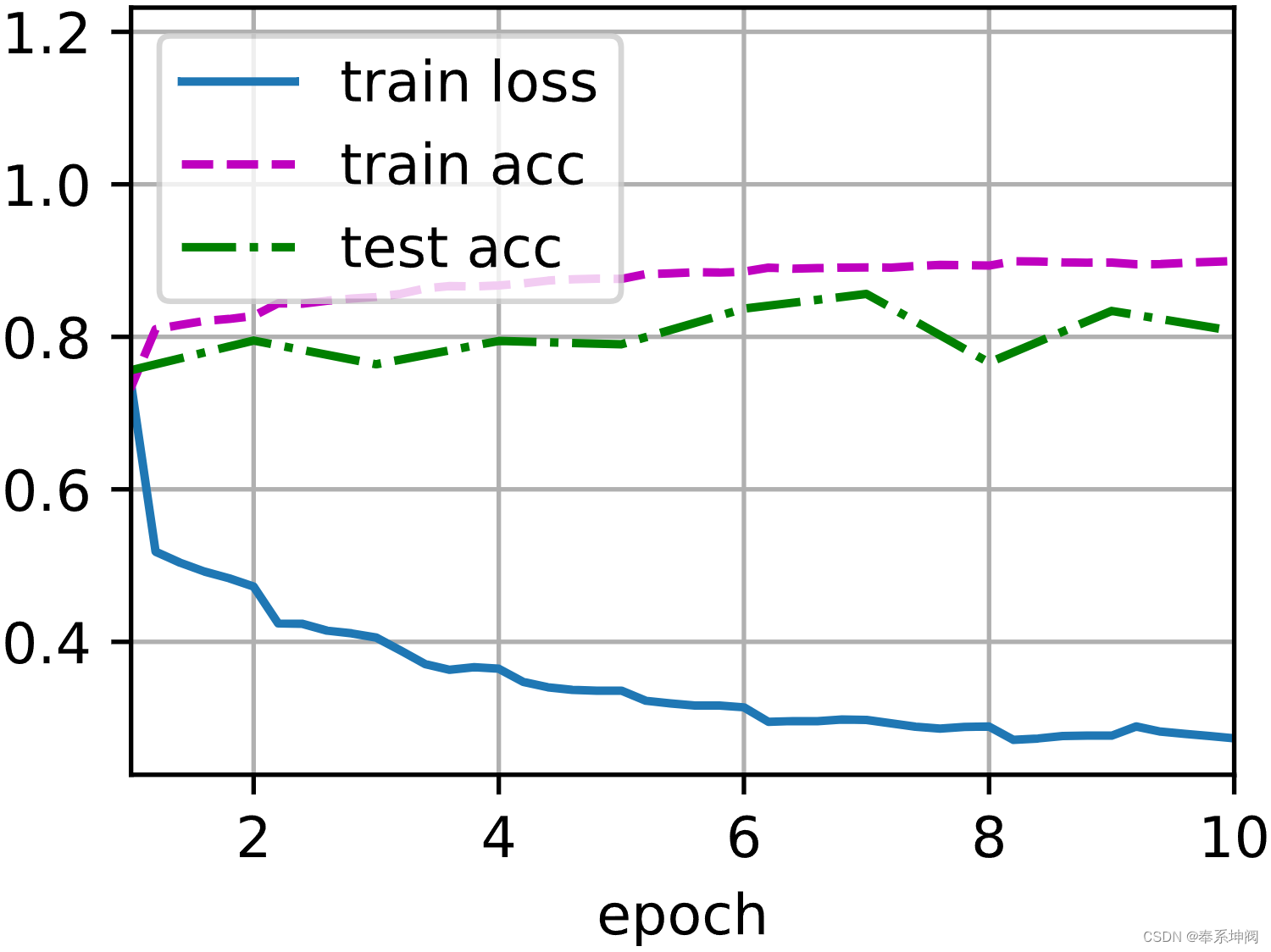
让我们来看看从第一个批量规范化层中学到的拉伸参数`gamma`和偏移参数`beta`。
net[1].gamma.reshape((-1,)), net[1].beta.reshape((-1,))(tensor([0.4863, 2.8573, 2.3190, 4.3188, 3.8588, 1.7942], device='cuda:0',grad_fn=<ReshapeAliasBackward0>),tensor([-0.0124, 1.4839, -1.7753, 2.3564, -3.8801, -2.1589], device='cuda:0',grad_fn=<ReshapeAliasBackward0>))三、简明实现
1、对LeNet加入批量归一化
除了使用我们刚刚定义的`BatchNorm`,我们也可以直接使用深度学习框架中定义的`BatchNorm`。该代码看起来几乎与我们上面的代码相同。
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5), nn.BatchNorm2d(6), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.BatchNorm2d(16), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),nn.Linear(256, 120), nn.BatchNorm1d(120), nn.Sigmoid(),nn.Linear(120, 84), nn.BatchNorm1d(84), nn.Sigmoid(),nn.Linear(84, 10))2、开始训练
下面,我们使用相同超参数来训练模型。通常高级API变体运行速度快得多,因为它的代码已编译为C++或CUDA,而我们的自定义代码由Python实现。
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())loss 0.267, train acc 0.902, test acc 0.708
50597.3 examples/sec on cuda:0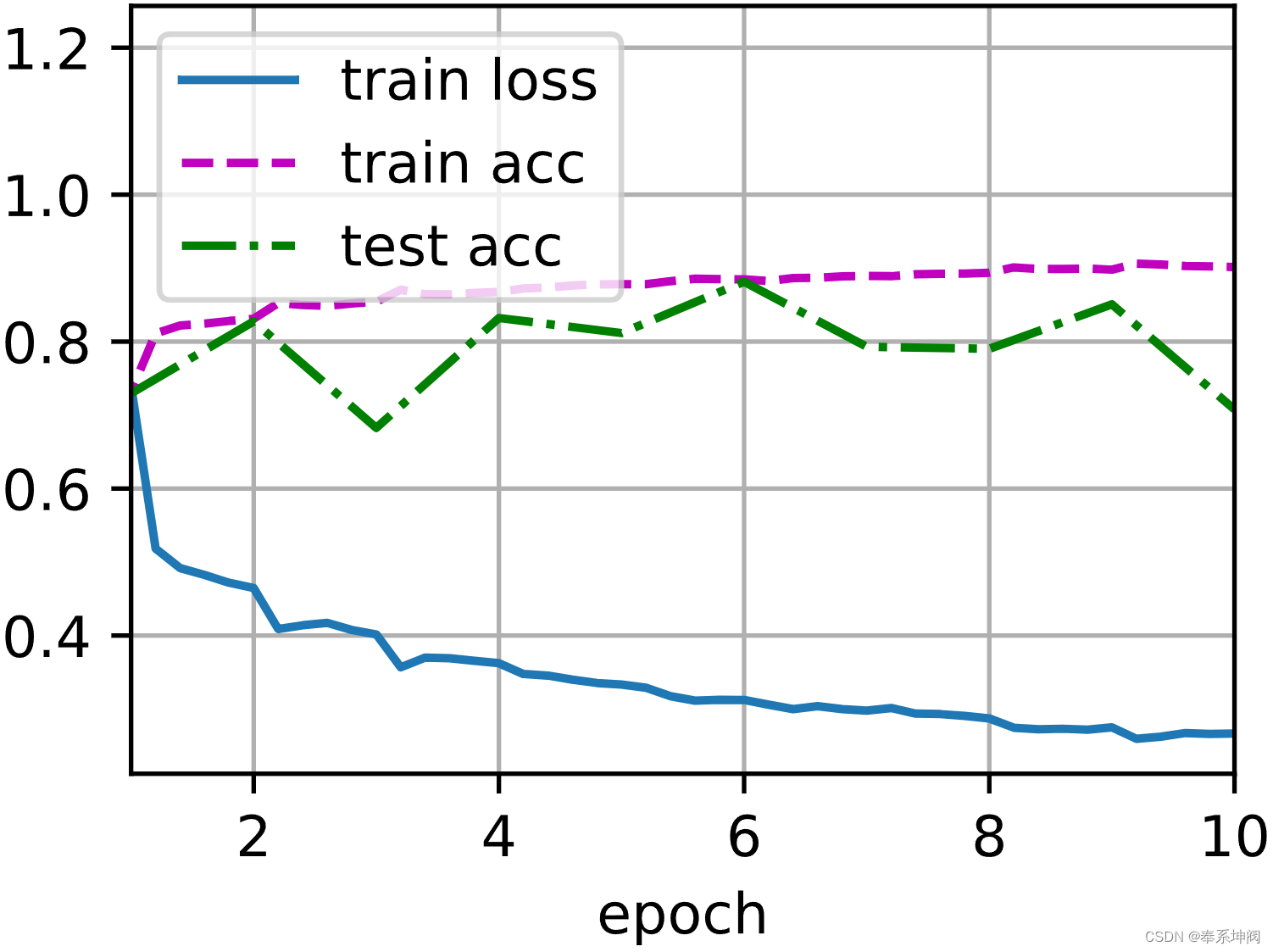
相关文章:
批量归一化
目录 一、BN层介绍 1、深层神经网络存在的问题 2、批量归一化公式的数学推导 3、BN层的作用位置 4、 预测过程中的批量归一化 5、BN层加速模型训练的原因 6、总结 二、批量归一化从零实现 1、实现批量归一化操作 2、创建BN层 3、对LeNet加入批量归一化 4、开始训练…...
C语言:字符串字面量及其保存位置
相关阅读 C语言https://blog.csdn.net/weixin_45791458/category_12423166.html?spm1001.2014.3001.5482 虽然C语言中不存在字符串类型,但依然可以通过数组或指针的方式保存字符串,但字符串字面量却没有想象的这么简单,本文就将对此进行讨论…...

【开源】基于Vue+SpringBoot的新能源电池回收系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 用户档案模块2.2 电池品类模块2.3 回收机构模块2.4 电池订单模块2.5 客服咨询模块 三、系统设计3.1 用例设计3.2 业务流程设计3.3 E-R 图设计 四、系统展示五、核心代码5.1 增改电池类型5.2 查询电池品类5.3 查询电池回…...

共享和独享的区别是什么?有必要用独享IP吗?
通俗地讲,共享IP就像乘坐公共汽车一样,您可以到达目的地,但将与其他乘客共享旅程,座位很可能是没有的。独享IP就像坐出租车一样,您可以更快到达目的地,由于车上只有您一个人,座位是您一个人专用…...
leetcode——打家劫舍问题汇总
本章汇总一下leetcode中的打家劫舍问题,使用经典动态规划算法求解。 1、梦开始的地方——打家劫舍(★) 本题关键点就是不能在相邻房屋偷东西。 采用常规动态规划做法: 根据题意设定dp数组,dp[i]的含义为:…...
Java经典框架之Spring MVC
Spring MVC Java 是第一大编程语言和开发平台。它有助于企业降低成本、缩短开发周期、推动创新以及改善应用服务。如今全球有数百万开发人员运行着超过 51 亿个 Java 虚拟机,Java 仍是企业和开发人员的首选开发平台。 课程内容的介绍 1. Spring MVC 入门案例 2. 基…...

Golang make vs new
文章目录 1.简介2.区别3.new 可以初始化 slice,map 和 channel 吗?4.make 可以初始化其他类型吗?5.小结参考文献 1.简介 在 Go 语言中,make 和 new 是两个用于创建对象的内建函数,但它们有着不同的用途和适用范围。 …...

Arthas
概述 Arthas(阿尔萨斯) 能为你做什么? Arthas 是Alibaba开源的Java诊断工具,深受开发者喜爱。 当你遇到以下类似问题而束手无策时,Arthas可以帮助你解决: 这个类从哪个 jar 包加载的?为什么会…...

IP代理科普| 共享IP还是独享IP?两者的区别与优势
通俗地讲,共享IP就像乘坐公共汽车一样,您可以到达目的地,但将与其他乘客共享旅程,座位很可能是没有的。独享IP就像坐出租车一样,您可以更快到达目的地,由于车上只有您一个人,座位是您一个人专用…...
龙芯loongarch64服务器编译安装tensorflow-io-gcs-filesystem
前言 安装TensorFlow的时候,会出现有些包找不到的情况,直接使用pip命令也无法安装,比如tensorflow-io-gcs-filesystem,安装的时候就会报错: 这个包需要自行编译,官方介绍有限,这里我讲解下 编译 准备 拉取源码:https://github.com/tensorflow/io.git 文章中…...

开源持续测试平台Linux MeterSphere本地部署与远程访问
文章目录 前言1. 安装MeterSphere2. 本地访问MeterSphere3. 安装 cpolar内网穿透软件4. 配置MeterSphere公网访问地址5. 公网远程访问MeterSphere6. 固定MeterSphere公网地址 前言 MeterSphere 是一站式开源持续测试平台, 涵盖测试跟踪、接口测试、UI 测试和性能测试等功能&am…...

Kubernetes(K8S)快速入门
概述 在本门课程中,我们将会学习K8S一些非常重要和核心概念,已经操作这些核心概念对应组件的相关命令和方式。比如Deploy部署,Pod容器,调度器,Service服务,Node集群节点,Helm包管理器等等。 在…...
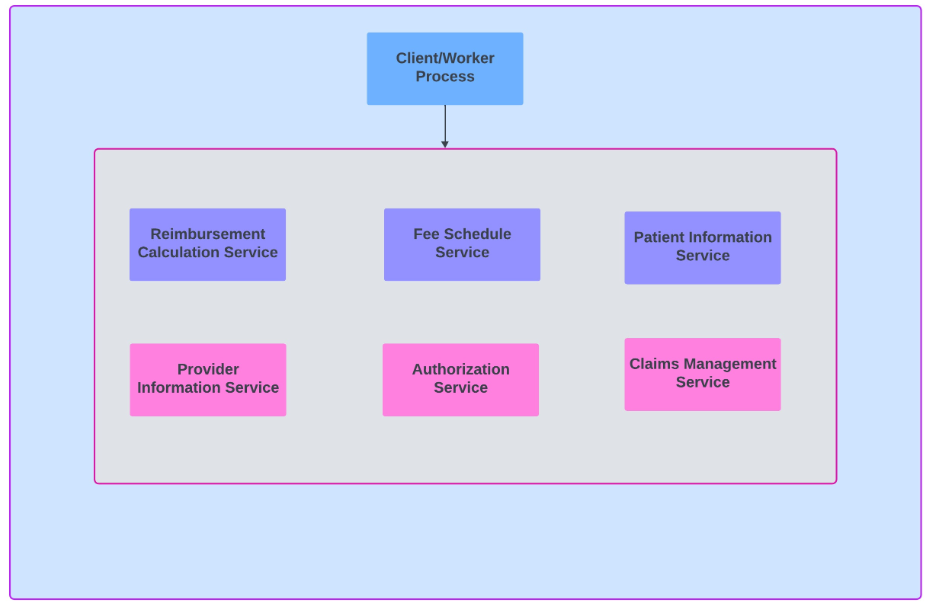
将遗留系统分解为微服务:第 2 部分
在当今不断发展的技术环境中,从整体架构向微服务的转变对于许多企业来说都是一项战略举措。这在报销计算系统领域尤其重要。正如我在上一篇文章第 1 部分应用 Strangler 模式将遗留系统分解为微服务-CSDN博客中提到的,让我们探讨如何有效管理这种转变。 …...

RK3588平台开发系列讲解(AI 篇)RKNN-Toolkit2 模型的加载转换
文章目录 一、Caffe 模型加载接口二、TensorFlow 模型加载接口三、TensorFlowLite 模型加载接口四、ONNX 模型加载五、DarkNet 模型加载接口六、PyTorch 模型加载接口沉淀、分享、成长,让自己和他人都能有所收获!😄 📢 RKNN-Toolkit2 目前支持 Caffe、TensorFlow、Tensor…...
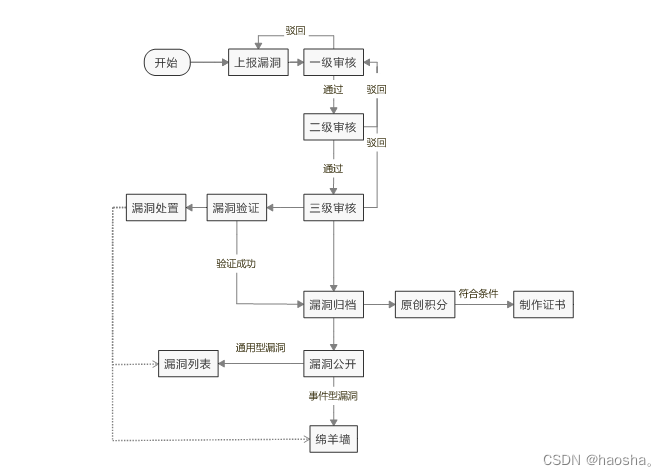
CNVD原创漏洞审核和处理流程
一、CNVD原创漏洞审核归档和发布主流程 (一)审核和归档流程 审核流程分为一级、二级、三级审核,其中一级审核主要对提交的漏洞信息完整性进行审核,漏洞符合可验证(通用型漏洞有验证代码信息或多个互联网实例、事件型…...
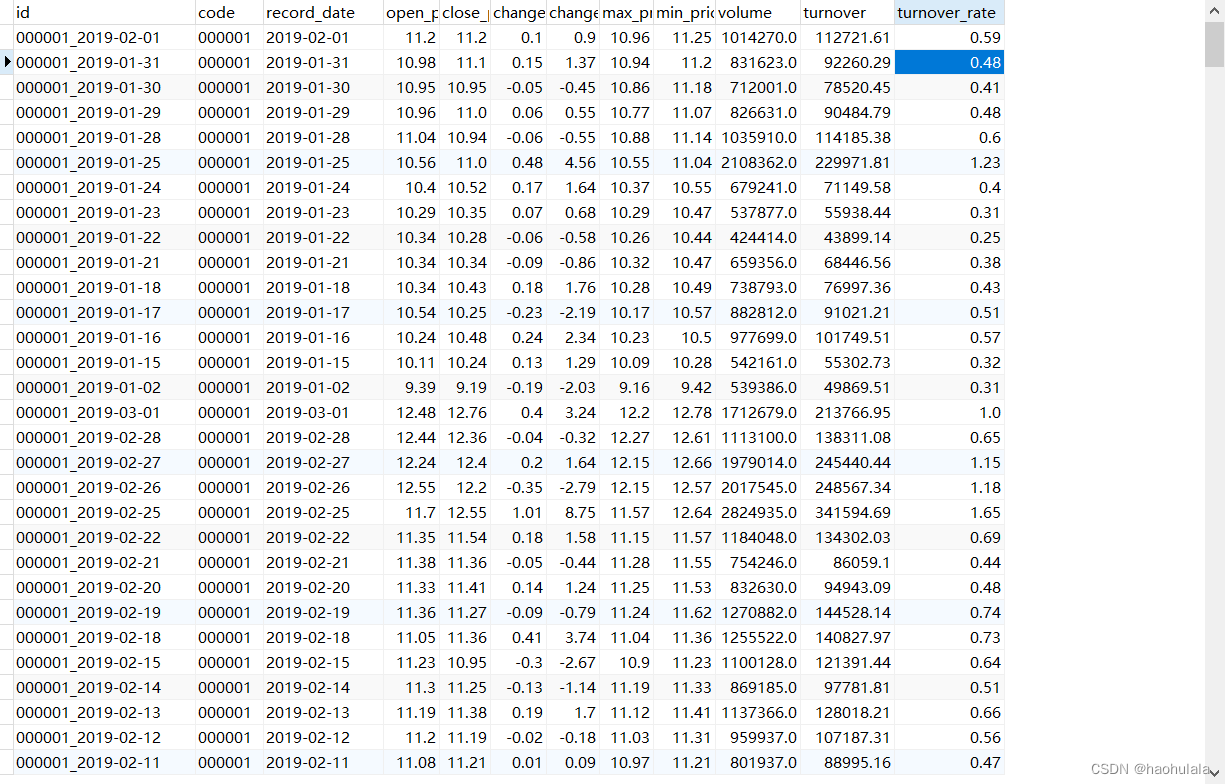
【java爬虫】基于springboot+jdbcTemplate+sqlite+OkHttp获取个股的详细数据
注:本文所用技术栈为:springbootjdbcTemplatesqliteOkHttp 前面的文章我们获取过沪深300指数的成分股所属行业以及权重数据,本文我们来获取个股的详细数据。 我们的数据源是某狐财经,接口的详细信息在下面的文章中,本…...

智能优化算法应用:基于人工兔算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于人工兔算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于人工兔算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.人工兔算法4.实验参数设定5.算法结果6.参考文…...
【ubuntu 22.04】安装vscode并配置正常访问应用商店
注意:要去vscode官网下载deb安装包,在软件商店下载的版本不支持输入中文 在ubuntu下用火狐浏览器无法访问vscode官网,此时可以手动进行DNS解析,打开DNS在线查询工具,解析以下主机地址(复制最后一个IP地址&a…...

K8s出现问题时,如何排查解决!
K8s问题的排查 1. POD启动异常、部分节点无法启动pod2. 审视集群状态3. 追踪事件日志4. 聚焦Pod状态5. 检查网络连通性6. 审视存储配置7. 研究容器日志8. K8S集群网络通信9. 问题:Service 是否通过 DNS 工作?10. 总结1、POD启动异常、部分节点无法启动p…...

2015年第四届数学建模国际赛小美赛B题南极洲的平均温度解题全过程文档及程序
2015年第四届数学建模国际赛小美赛 B题 南极洲的平均温度 原题再现: 地表平均温度是反映气候变化和全球变暖的重要指标。然而,在以前的估计中,在如何界定土地平均数方面存在一些方法上的差异。为简单起见,我们只考虑南极洲。请建…...

rebar3最佳实践清单:避免常见陷阱的20个专业建议
rebar3最佳实践清单:避免常见陷阱的20个专业建议 【免费下载链接】rebar3 Erlang build tool that makes it easy to compile and test Erlang applications and releases. 项目地址: https://gitcode.com/gh_mirrors/re/rebar3 rebar3是Erlang生态系统中最流…...

太空算力产业正崛起
未来,渔民只需通过手机App向卫星发起查询,卫星便可借助高光谱相机精准定位金枪鱼位置,再通过在轨“智慧大脑”分析处理,将鱼群坐标、渔具使用建议及销售渠道指导等实用信息,精准传回渔民手中。这一充满“黑科技”色彩的…...
)
【往届均已完成EI检索!】第三届遥感测绘与全球定位算法国际学术会议(RSGPA 2026)
第三届遥感测绘与全球定位算法国际学术会议(RSGPA 2026)将于2026年6月13日举办线上会议。会议主要围绕遥感测绘与定位算法等研究领域展开讨论。本次会议旨在为相关领域的研究人员提供一个权威的国际交流平台,交流全球相关领域科技学术最新发展…...

如何三步实现AI虚拟试衣:OOTDiffusion从安装到实战的完整指南
如何三步实现AI虚拟试衣:OOTDiffusion从安装到实战的完整指南 【免费下载链接】OOTDiffusion [AAAI 2025] Official implementation of "OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on" 项目地址: https://…...

Cursor AI助手功能扩展技术实现:5步实现永久免费使用的完整方案
Cursor AI助手功能扩展技术实现:5步实现永久免费使用的完整方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached…...

Python量化投资利器:5步掌握pywencai获取同花顺问财数据
Python量化投资利器:5步掌握pywencai获取同花顺问财数据 【免费下载链接】pywencai 获取同花顺问财数据 项目地址: https://gitcode.com/gh_mirrors/py/pywencai 在金融数据分析和量化投资领域,获取高质量、实时的A股市场数据一直是开发者和分析师…...

番茄小说下载器:3分钟打造个人专属离线图书馆
番茄小说下载器:3分钟打造个人专属离线图书馆 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 番茄小说下载器是一款专为小说爱好者设计的强大开源工具,…...

不止于指路,智慧导览如何重构公共空间价值
在过去很长一段时间里,公共空间的价值被简单地等同于功能性。一个公园只要有绿化和座椅,一个商场只要有商铺和电梯,一个政务大厅只要有窗口和座位,就被认为是合格的公共空间。然而,随着人们生活水平的提高和消费观念的…...
如何免费解决BT下载速度慢问题?终极trackerslist配置指南
如何免费解决BT下载速度慢问题?终极trackerslist配置指南 【免费下载链接】trackerslist Updated list of public BitTorrent trackers 项目地址: https://gitcode.com/GitHub_Trending/tr/trackerslist 你是否曾为BT下载的龟速而烦恼?种子明明显…...

供应链管理在管什么?终于有人把供应链管理讲明白了
我发现大家都把供应链管理想简单了,觉得它就是管采购砍价、或者管仓库理货,又或者是找物流发货。 你是不是也这么认为? 说白了,供应链管理根本不是单一环节的事,是从客户提出需求到最终签收的全流程的把控。这流程里…...