[PyTorch][chapter 8][李宏毅深度学习][DNN 训练技巧]
前言:
DNN 是神经网络的里面基础核心模型之一.这里面结合DNN 介绍一下如何解决
深度学习里面过拟合,欠拟合问题
目录:
- DNN 训练常见问题
- 过拟合处理
- 欠拟合处理
- keras 项目
一 DNN 训练常见问题
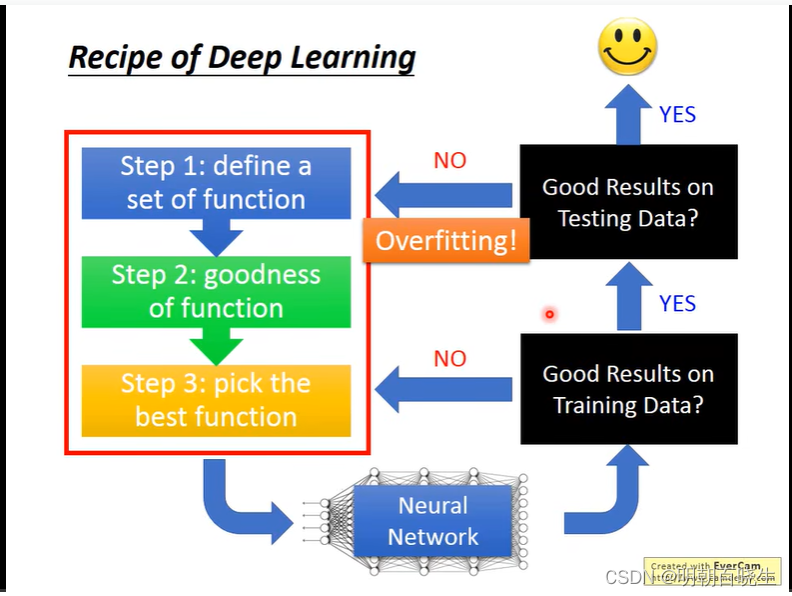
我们在深度学习网络训练的时候经常会遇到下面两类问题:
1: 训练集上面很差 : 欠拟合
2: 训练集上面很好, 测试集上面很差: 过拟合
二 过拟合解决
| 过拟合解决方案 |
| 主要有以下三个处理思路 |
| 1 Early Stopped |
| 2 L1 L2 正规化 |
| 3 Dropout 4: 增加训练集上面的数据量 |
2.1 Early Stopping
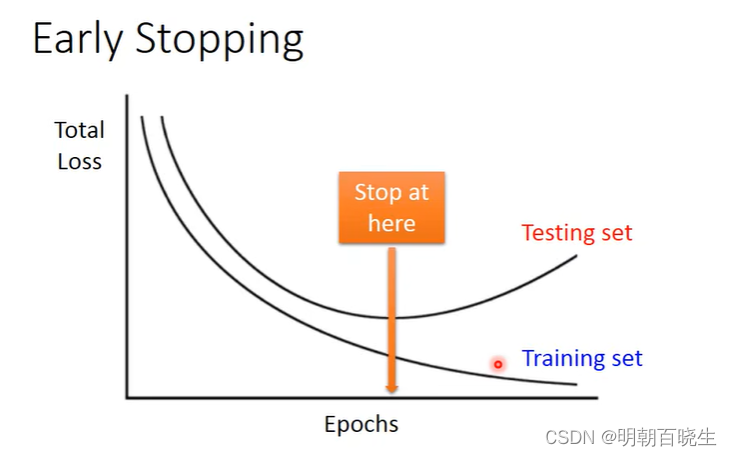
方案
这个数据集分为3部分: Training Data,validation data,Test Data
1 将训练的数据分为Training Data 和validation data
2 每个epoch结束后(或每N个epoch后):计算validation data 的 accuracy
3: 更新 最优 validation data accuracy 对应的网络参数
3 随着epoch的增加,如果validation data 连续多次没有提升,则停止训练;
4 将之前validation data 准确率最高时的权重作为网络的最终参数。
2.2 正规化
分为L1,L2 正规化.


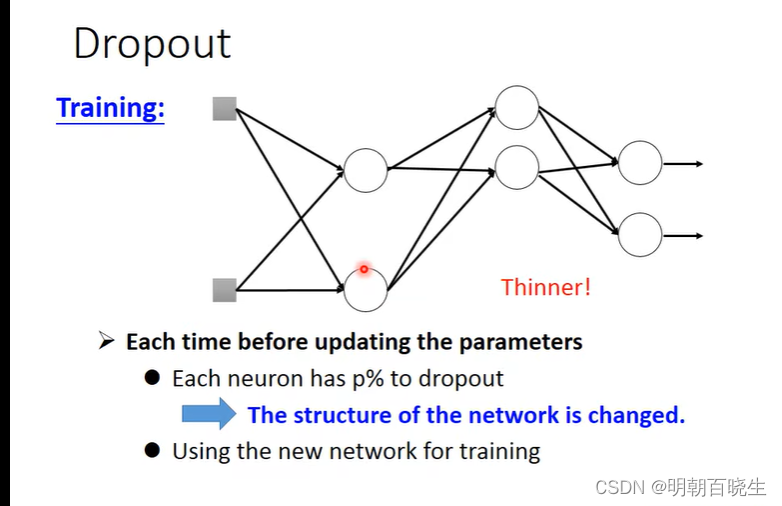
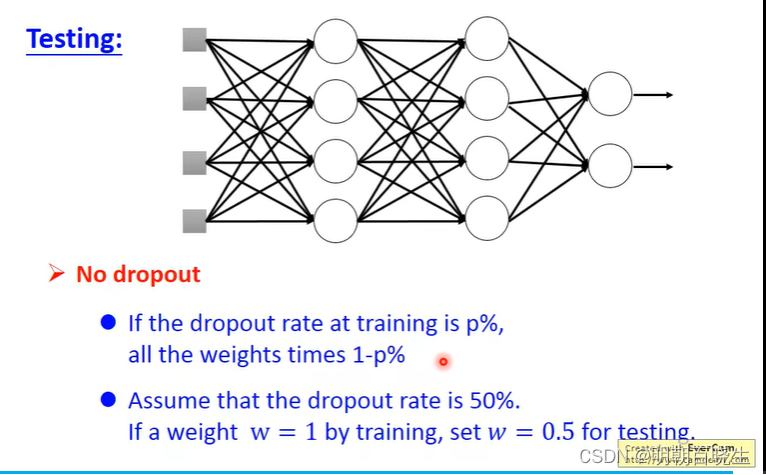
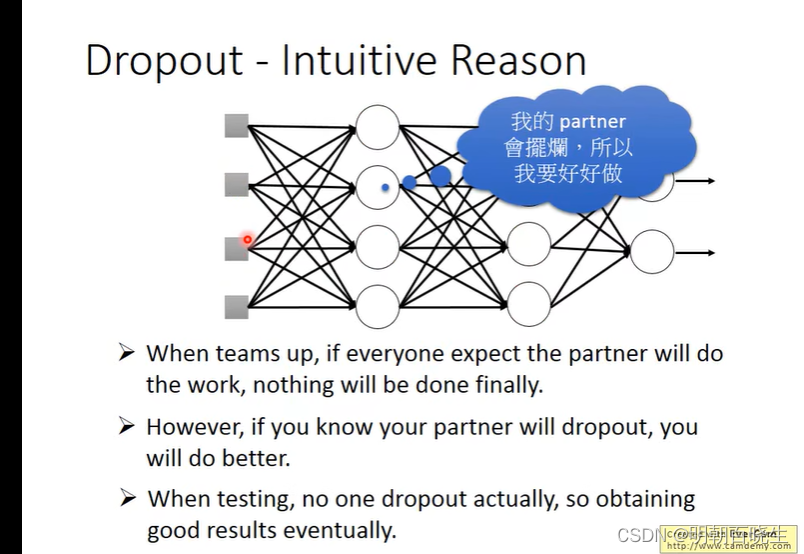
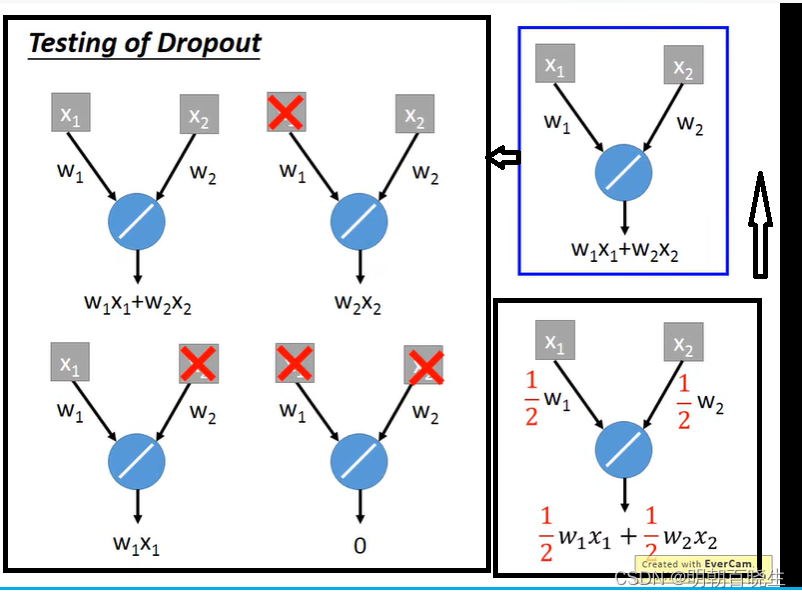
2.3 Dropout
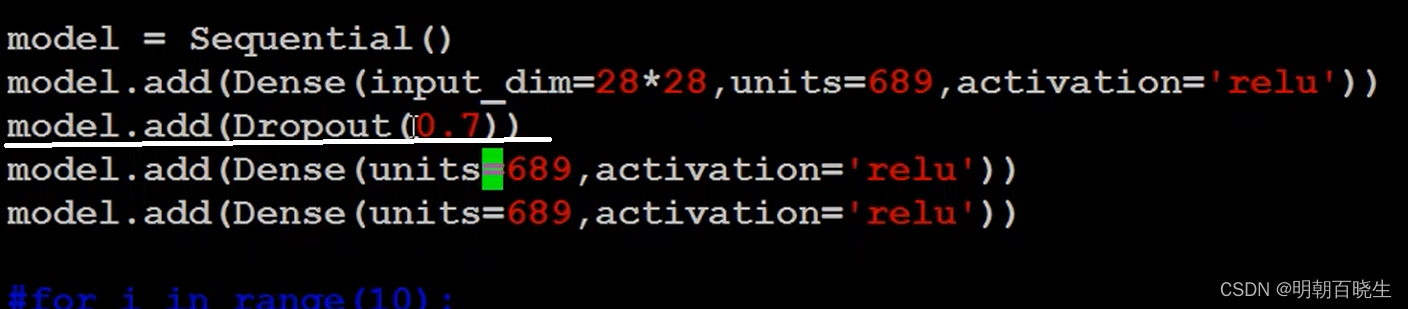
原网络结构
训练:
Dropout
: 上面每个输入值以p%的概率变为0
测试:
权重系数
一般p 设置为0.5
、
4 增加数据集上面数据量
作用 降低方差
三 欠拟合
| 欠拟合处理方案 |
| 主要有下面5个处理思路: |
| 1 超参数调节: 学习率 训练轮次,batch_size 2 更换激活函数 |
| 3 梯度更新算法优化 4 网络模型优化 5 损失函数 更换 |
3.1 超参数调参
主要更换学习率,增加迭代轮数等

3.2 更换激活函数
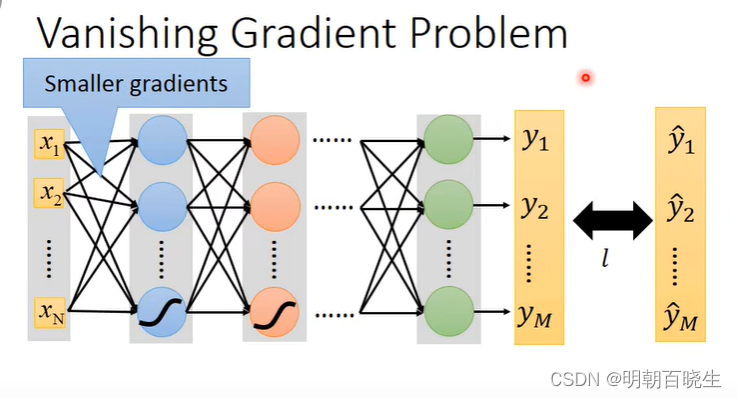
DNN 随着网络层数的增加会出现梯度弥散现象,可以通过把激活函数sigmod 更换为
ReLu 一定程度上面优化该方案。
更换激活函数 ReLu(导数为1,链式求导的时候连乘不会减少)


增加,减少 网络层数(梯度弥散,梯度爆炸)
3.3 梯度更新优化算法

方案1 SGD 随机梯度下降
当梯度为0,参数无法更新容易陷入到局部极小值点
学习率太大: 不容易进入到极小值点,容易发生网络震荡
学习率太小: 收敛速度慢

方案2 Momentum: 当前的梯度 = 当前的梯度+历史梯度
SGD 会发生震荡而迟迟不能接近极小值,所以对更新梯度引入Momentum概念,加速SGD,并抑制震荡(也就是在SGD基础上引入了一阶动量)
初始化动量:
: 动量
: 动量
整个思想: 有点跟马尔科夫链时序链相似,当前输出值不仅仅跟当前的
输入相关,也跟历史值相关。
方案3:Adagrad (Adaptive Gradient,自适应梯度)
不同参数进行不同程度的更新 - 逐参数适应学习率方法
方案:
在Adagrad算法中,每个参数的学习率各不相同。计算某参数的学习率时需将该参数前面所有时间步的梯度平方求和,随着时间步的增加,学习率将减小.
二阶动量,权重系数里面的每个系数单独计算
: 当前权重系数的梯度
Adgrad方法中,学习率一直在衰减,所以可以起到抑制震荡的作用,
对于频繁更新的参数,它们的二阶动量比较大,学习率小;
对于不怎么更新的参数,它们的二阶动量比较小,学习率就大。
但因为那个分母是单调递增的,会使得学习率单调递减至0,可能会使得训练过程提前结束,即便后续还有数据也无法学到必要的知识
方案4 RMSProp:
Root Mean Square Propagation,自适应学习率方法,由Geoff Hinton提出,是梯度下降优化算法的扩展。在AdaGrad的基础上,对二阶动量的计算进行了改进:即有历史梯度的信息,但是我又不想让信息一直膨胀,那么只要让历史信息一直衰减就好了。因此得到RMSProp的二阶动量计算公式:
如下图所示,截图来自:https://arxiv.org/pdf/1609.04747.pdf

方案4 Adam算法即自适应时刻估计方法(Adaptive Moment Estimation)
算法思想 moment+Adagrad
同时考虑了动量 和二阶动量

3.4 更换损失函数
比如mse 更换成CRE

3.5 更换模型
增加网络层次,参数例如

或者
RNN 用LSTM
CNN 里面的ResNet
解决梯度弥散问题
四 keras
Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化 [1]。
Keras在代码结构上由面向对象方法编写,完全模块化并具有可扩展性,其运行机制和说明文档有将用户体验和使用难度纳入考虑,并试图简化复杂算法的实现难度 [1]。Keras支持现代人工智能领域的主流算法,包括前馈结构和递归结构的神经网络,也可以通过封装参与构建统计学习模型 [2]。在硬件和开发环境方面,Keras支持多操作系统下的多GPU并行计算,可以根据后台设置转化为Tensorflow、Microsoft-CNTK等系统下的组件 [3]。
Keras的主要开发者是谷歌工程师François Chollet,此外其GitHub项目页面包含6名主要维护者和超过800名直接贡献者 [4]。Keras在其正式版本公开后,除部分预编译模型外,按MIT许可证开放源代码 [1]
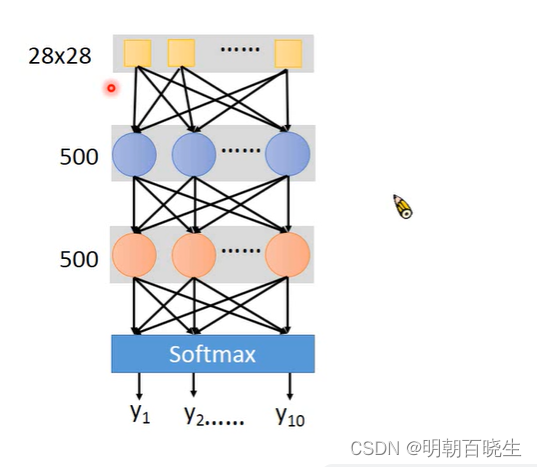
keras 创建一个神经网络,训练,测试主要流程如下
| model | 模型搭建 |
| compile | 损失函数,loss, batch_size |
| fit | 训练 |
| evaluate | 验证测试集 |
| predict | 预测 |
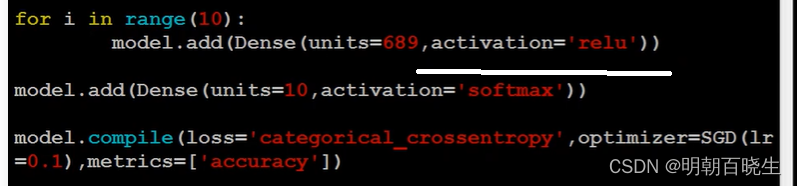
model = Sequential()#输入层
model.add(Dense(input_dim=28*28,
units = 500,
activation='relu'))#1 隐藏层
model.add(Dense(units=500,
activation='relu'))#2 输出层
model.add(Dense(units=10,
activation='softmax'))model.compile(loss='categorical_crossentropy',
optimizer='adam'
metrics =['accuracy'])#3 pick the best function ,完成训练工作
model.fit(x_train, y_train, batch_size=100, epochs=20)#4 使用该模型
score = model.evaluate(x_test,y_test)
result = model.predict(x_test)参考:
9-1: Tips for Training DNN_哔哩哔哩_bilibili
【优化算法】一文搞懂RMSProp优化算法 - 知乎
神经网络-优化器篇-从梯度下降到Adam方法 - 知乎
https://www.cnblogs.com/picassooo/p/12347927.html
相关文章:
[PyTorch][chapter 8][李宏毅深度学习][DNN 训练技巧]
前言: DNN 是神经网络的里面基础核心模型之一.这里面结合DNN 介绍一下如何解决 深度学习里面过拟合,欠拟合问题 目录: DNN 训练常见问题 过拟合处理 欠拟合处理 keras 项目 一 DNN 训练常见问题 我们在深度学习网络训练的时候经常会遇到下面…...
Nginx快速入门:实现企业安全防护|nginx部署https,ssl证书(七)
0. 引言 之前我们讲到nginx的一大核心作用就是实现企业安全防护,而实现安全防护的原理就是通过部署https证书,以此实现参数加密访问,从而加强企业网站的安全能力。 nginx作为各类服务的统一入口,只需要在入口处部署一个证书&…...
将Go语言开发的Web程序部署到K8S
搭建K8S基础环境 如果已经有K8S环境的同学可以跳过,如果没有,推荐你看看我的《Ubuntu22加Minikue搭建K8S环境》,课程目录如下: Ubuntu22安装Vscode 下载:https://code.visualstudio.com/Download 安装命令&#…...

Python发送数据到Unity实现
Unity设置: 打开Unity项目。创建一个空的GameObject,并附加一个新的脚本TCPReceiver using System.Net; using System.Net.Sockets; using System.Text; using UnityEngine; using System.Threading;public class MyListener : MonoBehaviour {Thread thread;pub…...
)
Unity 渲染顺序受哪些影响(相机depth、SortingLayer、Render Queue、透明)
目录 相机深度(Camera Depth) Clear Flags 多相机渲染不同部分 SortingLayer 先后顺序 Render Queue Render Queue的作用 Render Queue的分类 GeometryLast(值为2500) 渲染顺序总结 相机深度(Camera Depth&am…...
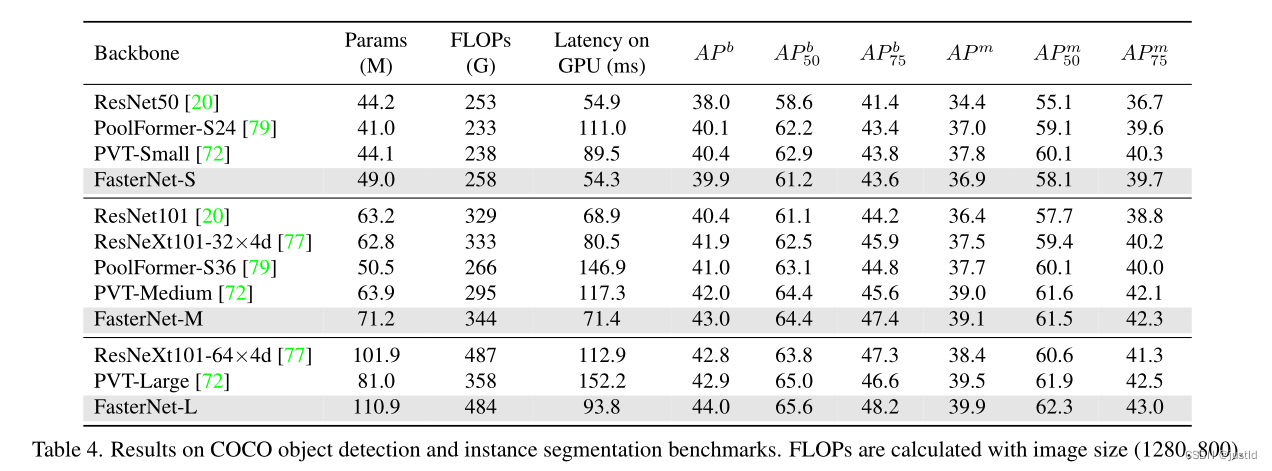
【论文笔记】Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks
论文地址:Run, Dont Walk: Chasing Higher FLOPS for Faster Neural Networks 代码地址:https://github.com/jierunchen/fasternet 该论文主要提出了PConv,通过优化FLOPS提出了快速推理模型FasterNet。 在设计神经网络结构的时候ÿ…...

python常用函数汇总
python常用函数汇总 对准蓝字按下左键可以跳转哦 类型函数数值相关函数abs() divmod() max() min() pow() round() sum()类型转换函数ascii() bin() hex() oct() bool() bytearray() bytes() chr() complex() float() int() 迭代和循环函数iter() next() e…...
阶段十-物业项目
可能遇到的错误: 解决jdk17javax.xml.bind.DatatypeConverter错误 <!--解决jdk17javax.xml.bind.DatatypeConverter错误--><dependency><groupId>javax.xml.bind</groupId><artifactId>jaxb-api</artifactId><version>…...
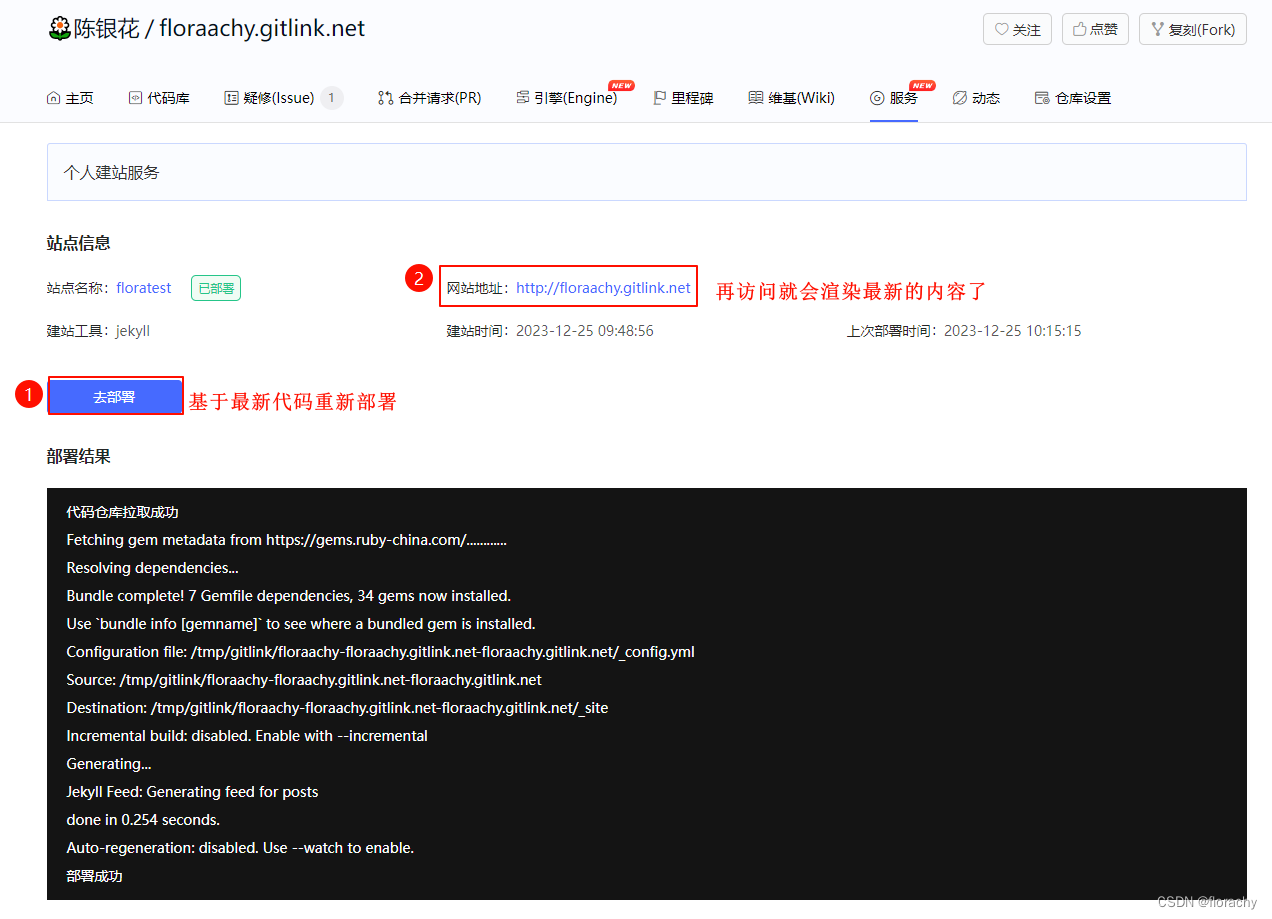
使用 Jekyll 构建你的网站 - 初入门
文章目录 一、Jekyll介绍二、Jekyll安装和启动2.1 配置Ruby环境1)Windows2)macOS 2.2 安装 Jekyll2.3 构建Jekyll项目2.4 启动 Jekyll 服务 三、Jekyll常用命令四、目录结构4.1 主要目录4.2 其他的约定目录 五、使用GitLink构建Jekyll博客5.1 生成Jekyll…...

【数据库】postgressql设置数据库执行超时时间
在这篇文章中,我们将深入探讨PostgreSQL数据库中的一个关键设置:SET statement_timeout。这个设置对于管理数据库性能和优化查询执行时间非常重要。让我们一起来了解它的工作原理以及如何有效地使用它。 什么是statement_timeout? statemen…...

SQL语言之DDL
目录结构 SQL语言之DDLDDL操作数据库查询数据库创建数据库删除数据库使用某个数据库案例 DDL操作表创建表查看表结构查询表修改表添加字段删除字段修改字段的类型修改字段名和字段类型 修改表名删除表案例 SQL语言之DDL DDL:数据定义语言,用来定义数…...
)
hive高级查询(2)
-- 分组查询 SELECT sex,SUM(mark) sum_mark FROM score GROUP BY sex HAVING sum_mark > 555; SELECT sex,sum_mark FROM( SELECT sex,SUM(mark) sum_mark FROM score GROUP BY sex ) t WHERE sum_mark > 555; SELECT AVG(gid),SUM(gid)/COUNT(gid) FROM …...
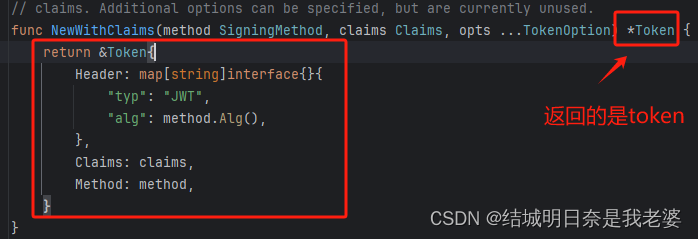
golang的jwt学习笔记
文章目录 初始化项目加密一步一步编写程序另一个参数--加密方式关于StandardClaims 解密解析出来的怎么用关于`MapClaims`上面使用结构体的全代码实战项目关于验证这个项目的前端初始化项目 自然第一步是暗转jwt-go的依赖啦 #go get github.com/golang-jwt/jwt/v5 go get githu…...

第十五节TypeScript 接口
1、简介 接口是一系列抽象方法的声明,是一些方法特征的集合,这些方法都应该是抽象的,需要有由具体的类去实现,然后第三方就可以通过这组抽象方法调用,让具体的类执行具体的方法。 2、接口的定义 interface interface_…...
【hadoop】解决浏览器不能访问Hadoop的50070、8088等端口?!
【hadoop】解决浏览器不能访问Hadoop的50070、8088等端口?!😎 前言🙌【hadoop】解决浏览器不能访问Hadoop的50070、8088等端口?!查看自己的配置文件:最终成功访问如图所示: 总结撒花…...

14.bash shell中的for/while/until循环
文章目录 shell循环语句for命令**读取列表中的值****读取列表中的复杂值****从变量读取列表**迭代数组**从命令读取值****用通配符读取目录**C语言风格的shell for循环 shell循环while命令shell 循环的until命令shell循环跳出的break/continue命令break命令continue命令trick 欢…...
RPC(6):RMI实现RPC
1RMI简介 RMI(Remote Method Invocation) 远程方法调用。 RMI是从JDK1.2推出的功能,它可以实现在一个Java应用中可以像调用本地方法一样调用另一个服务器中Java应用(JVM)中的内容。 RMI 是Java语言的远程调用,无法实现跨语言。…...

strlen和sizeof的初步理解
大家好我是Beilef,一个美好的下我接触到编程并且逐渐喜欢。我虽然不是科班出身但是我会更加努力地去学,有啥不对的地方请斧正 文章目录 目录 文章目录 前言 想必大家对sizeof肯定很了解,那对strlen又了解多少。其实这个问题应该让不少人困扰。…...
纯CSS的华为充电动画,它来了
📢 鸿蒙专栏:想学鸿蒙的,冲 📢 C语言专栏:想学C语言的,冲 📢 VUE专栏:想学VUE的,冲这里 📢 Krpano专栏:想学Krpano的,冲 🔔…...

在架构设计中,前后端分离有什么好处?
前后端分离是一种架构设计模式,将前端和后端的开发分别独立进行,它带来了多方面的好处: 1、独立开发和维护: 前后端分离允许前端和后端开发团队独立进行工作。这意味着两个团队可以并行开发,提高了整体的开发效率。前…...

多语种语音合成新突破,ElevenLabs维吾尔语TTS上线即受限?3类企业正在紧急迁移替代方案
更多请点击: https://kaifayun.com 第一章:ElevenLabs维吾尔语TTS上线即受限的技术真相 ElevenLabs在2024年3月宣布支持维吾尔语(ug)文本转语音,但实际调用API时立即触发服务端策略拦截——即便请求头携带合法API密钥…...
)
【仅剩最后47份】盐印相风格训练数据集泄露报告(含原始Agfa APX 400扫描底片参数+Midjourney反向蒸馏权重)
更多请点击: https://codechina.net 第一章:盐印相风格的视觉基因与数字重生 盐印相(Salted Paper Print)作为19世纪早期摄影术的奠基性工艺,其独特颗粒质感、柔和影调过渡与温润泛黄基底,构成了不可复制的…...

G-ratio Overload
重力加速度比(G-ratio)、过载(Overload)教改最大的特点就是知识与实际相结合,如果在实际生活的体现和应用。 世界一级方程式竞标赛 (F1)...

Taotoken API Key管理与访问控制功能在团队大赛中的协作应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken API Key管理与访问控制功能在团队大赛中的协作应用 1. 场景概述:团队协作中的API资源管理需求 当团队共同参…...

PPTist:重新定义在线演示文稿创作的Web应用革命
PPTist:重新定义在线演示文稿创作的Web应用革命 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, allowing for the …...

Taotoken 稳定直连全球大模型在高峰期业务中的实际表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 稳定直连全球大模型在高峰期业务中的实际表现 在需要持续、稳定调用大模型能力的业务场景中,服务的可靠性是核…...

Windows 11终极优化指南:使用Win11Debloat免费提升系统性能 [特殊字符]
Windows 11终极优化指南:使用Win11Debloat免费提升系统性能 🚀 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes …...
)
游戏开发团队必须立即升级的语音合成栈:Llama-3-TTS开源模型实测对比(RTX 4090 vs. Snapdragon 8 Gen3)
更多请点击: https://codechina.net 第一章:AI语音合成在游戏开发中的应用 AI语音合成(Text-to-Speech, TTS)正深刻重塑游戏叙事、角色交互与本地化工作流。相比传统预录语音,实时TTS可动态生成符合上下文语境、情绪状…...
)
告别内核恐慌:用UIO在用户空间为Zynq PS-PL通信写驱动(附设备树配置)
告别内核恐慌:用UIO在用户空间为Zynq PS-PL通信写驱动(附设备树配置) 在嵌入式系统开发中,安全性和稳定性始终是首要考虑的因素。当涉及到FPGA与ARM处理器协同工作时,传统的内核驱动开发方式往往带来不小的风险——一个…...

如何彻底释放华硕笔记本性能:G-Helper轻量控制工具终极指南
如何彻底释放华硕笔记本性能:G-Helper轻量控制工具终极指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenboo…...