Linux:查询当前进程或线程的资源使用情况
目录
- 一、/proc/[PID]/下的各个文件
- 1、proc简介
- 2、/proc/[PID]/详解
- 二、通过Linux API获取当前进程或线程的资源使用情况
- 1、getrusage
- 2、sysinfo
- 3、times
在工作中,我们排除app出现的一些性能/资源问题时,通常要先知道当前app的资源使用情况,方能进一步思考改进措施。获取这些信息的途径有很多,我这里简单分享下两种:1)从proc文件系统;2)通过Linux 的API函数。
一、/proc/[PID]/下的各个文件
1、proc简介
/proc 目录是一个特殊的虚拟文件系统,它提供了对内核运行时信息的访问,包括进程、设备、网络、文件系统等各个方面的信息。它不是一个真正的文件系统,而是基于内核数据结构的一个接口,通过这个接口可以获取系统的运行时状态。
下面是 /proc 目录的一些重要子目录和关键内容的说明:
-
/proc/[PID]:此目录以进程的 ID(PID)命名,并包含与该进程有关的文件和目录,如之前所讲的 /proc/pid/目录。
-
/proc/cpuinfo:该文件包含有关 CPU(处理器)的信息,如厂商、型号、频率、缓存等。
-
/proc/meminfo:该文件包含有关系统内存的信息,如总内存、可用内存、缓存、交换分区等。
-
/proc/mounts:此文件列出了系统上已挂载的文件系统,包括文件系统类型、挂载点、挂载选项等信息。
-
/proc/net:此目录包含有关网络协议、接口和连接的信息,如 /proc/net/tcp、/proc/net/udp 等文件。
-
/proc/sys:此目录包含与内核参数和系统配置相关的文件。可以通过读写这些文件来修改内核的运行时行为。
-
/proc/version:该文件包含了当前正在运行的内核版本信息。
-
/proc/cmdline:此文件包含了系统引导时传递给内核的命令行参数。
-
/proc/uptime:该文件包含自系统开机以来的运行时间和空闲时间。
-
/proc/sys/kernel/hostname:此文件包含主机的名称(hostname)。
除了上述目录和文件,/proc 目录下还有很多其他文件和目录,涵盖了系统和进程的各个方面的信息。
需要注意的是,/proc 目录下的文件是动态生成的,信息在进程运行时改变。读取这些文件时,请确保有足够的权限,并理解每个文件的含义和用途。此外,不要轻易对 /proc 目录下的文件进行修改,因为这可能会导致系统不稳定或损坏。
2、/proc/[PID]/详解

-
arch_status:
该文件包含了有关进程所运行的指令集架构的信息。例如,它可以显示进程在x86或ARM架构上运行。 -
attr:
此目录包含与进程关联的文件、目录和进程的访问控制列表(ACL)信息。这些文件和目录的访问权限可以在这里进行管理和修改。 -
autogroup:
这个文件显示了进程是否被自动控制分组,以限制对CPU资源的访问。如果进程分配给自动控制分组,则该文件中的值为"1";否则,为"0"。 -
auxv:
此文件包含了进程的辅助向量信息,这些信息在加载动态链接器时向其传递参数。辅助向量为动态链接器提供有关进程环境和运行状态的信息。 -
cgroup:
该文件显示了进程所属的控制组(cgroup)的路径。控制组是一种组织和限制进程资源使用的方式。 -
cmdline:
该文件包含了启动进程时使用的命令行参数,以null字符分隔各个参数。可以通过读取该文件来获取进程的命令行参数信息。 -
comm:
进程的命令名可以通过这个文件获得。它可以是可执行文件名或进程自描述。 -
coredump_filter:
这个文件决定了进程在发生崩溃时生成核心转储(core dump)的内容。通过修改该文件的值,可以控制生成核心转储时包含的内容,这对于调试崩溃问题非常有用。可以使用 echo 命令将特定的值写入这个文件中,以修改核心转储的行为。 -
cpu_resctrl_groups:
这个文件是与 CPU 资源控制(Resource Control)相关的,用于管理进程对CPU资源的使用。通过这个文件,可以查询或配置进程关联的 CPU ResCtrl(CPU资源控制)组的信息。CPU资源控制是用于管理和限制进程对CPU资源的访问的一种技术,可以实现资源隔离、分配和监控。 -
cwd:
这是一个符号链接,指向进程的当前工作目录(current working directory)。 -
environ:
该文件包含了进程的环境变量,以null字符分隔各个环境变量。通过读取该文件,可以获取进程的环境变量信息。 -
cpuset:
这个文件包含了进程所属的 cpuset(CPU affinity)的信息,可以用于管理进程所能使用的 CPU 核心。 通过这个文件,可以查询或设置进程所在的 cpuset。 -
exe:
这是一个符号链接,指向进程正在执行的可执行文件。通过读取这个符号链接,可以获取进程当前正在执行的可执行文件的路径。 -
fdinfo:
这个目录包含了关于进程打开的文件描述符(file descriptor)的详细信息,如文件的偏移量(offset)等。 -
gid_map:
这个文件用于表示进程的实际组ID(GID)与其用户命名空间中的GID之间的映射关系。 -
io:
这个文件包含了有关进程的输入/输出统计信息,如读取和写入的字节数、I/O操作次数等。 -
limits:
这个文件包含了对进程资源限制的报告,显示了一些限制项目的值,比如内存限制、文件大小限制等。 -
loginuid:
这个文件记录了与进程关联的登录用户ID(login UID)。 -
map_files:
这个目录包含了进程打开的映射文件的相关信息,可以用于查询进程当前使用的文件映射情况。 -
fd:
此目录包含了进程打开的文件描述符(file descriptor)的符号链接。可以通过查看这些符号链接来获取进程打开的文件等信息。 -
maps:
该文件包含有关进程内存映射的信息,包括进程的内存地址范围、映射的文件等。 -
mounts:
此文件显示了进程的挂载点信息,包括进程当前挂载的各个文件系统的详细数据。 -
mem:
这个文件允许对进程的内存空间进行直接访问,可以用于调试、内存分析等目的。 -
mountinfo:
这个文件提供了有关进程所挂载的文件系统的详细信息,包括挂载点、挂载选项等。 -
mountstats:
此文件包含了有关挂载点的统计信息,如 I/O 统计等。 -
net:
目录包含了一系列与网络相关的文件和子目录,可以用于查询进程的网络连接、端口等信息。 -
ns:
这个目录包含了进程的各种命名空间相关的符号链接,可以用于查询和操作进程的命名空间。 -
numa_maps:
这个文件包含了有关进程内存使用和NUMA节点分布情况的信息,对于了解进程的NUMA相关性非常有用。 -
oom_adj:
这个文件包含了与进程的OOM(Out Of Memory)分级相关的信息,用于调整进程在内存不足情况下被系统杀死的优先级。 -
oom_score:
这个文件包含了进程的OOM分数,用于在系统内存不足时选择性地终止进程。 -
oom_score_adj:
与 oom_adj 类似,这个文件也用于调整进程在内存不足情况下被系统杀死的优先级。 -
pagemap:
这个文件提供了有关进程虚拟内存页面到物理内存帧的映射信息,对于内存管理方面的深入了解非常有用。 -
patch_state:
这个文件包含了有关进程的内核安全补丁状态的信息,通常用于安全审计和补丁管理。 -
personality:
这个文件包含了与进程的运行环境和虚拟机架构相关的信息,用于指定进程的特定行为。 -
projid_map:
在用户命名空间中使用的文件,用于表示进程实际项目ID(Project ID)与其用户命名空间中的项目ID之间的映射关系。 -
root:
这是一个符号链接,指向进程的根目录。 -
sched:
这个文件提供了与进程调度策略和优先级相关的信息,包括当前调度策略、优先级等。 -
schedstat:
这个文件包含了与进程调度统计相关的信息,如运行时间、等待时间等。 -
sessionid:
这个文件记录了与进程关联的会话ID。 -
setgroups:
这个文件包含了与进程的附加组(supplementary group)相关的信息。 -
smaps:
这个文件提供了详细的进程内存映射信息,包括每个内存区域的权限、大小、映射文件等。 -
smaps_rollup:
类似于 smaps 文件,但提供了按文件和库合并的内存映射信息,用于更简洁的内存分析。 -
stack:
这个文件记录了进程的当前栈的内容。 -
stat:
这个文件提供了与进程状态相关的信息,如进程ID、父进程ID、运行状态等。 -
statm:
这个文件提供了与进程内存使用量相关的信息,包括进程的总内存、共享内存、库内存、堆内存等。 -
status:
这个文件提供了有关进程的多种信息,包括进程状态、内存使用、文件描述符等。 -
syscall:
这个目录包含与进程相关的系统调用信息,可以用于跟踪和分析进程的系统调用。 -
task:
这个目录包含了进程的所有线程(task)的信息。 -
timens_offsets:
这个文件提供了与进程关联的时间命名空间偏移量的信息,用于跟踪进程的时间命名空间变化。 -
timers:
这个目录包含了与进程相关的定时器的信息,如定时器ID、时间值等。 -
timerslack_ns:
这个文件包含了与进程的定时器松弛值(timerslack)有关的信息,用于调整进程的定时行为。 -
uid_map:
这个文件用于表示进程的实际用户ID(UID)与其用户命名空间中的UID之间的映射关系。 -
wchan:
是一个用于描绘一个进程在等待什么的内核函数指针。它表示了进程当前正在等待的内核函数或系统调用。可用于调试和分析进程的等待状态。
这些文件和目录提供了关于特定进程的多种信息,如进程状态、资源使用情况、环境变量等,通常被用于性能调优、调试以及资源管理方面,对于普通用户来说可能并不经常需要直接操作这些文件。通过读取这些文件,可以了解并监视系统中各个进程的情况。请注意,有些文件是符号链接,需要使用readlink或ls -l等命令来获取其指向的真实路径。
知识补充:
命名空间(Namespace)在Linux系统中是一种用于隔离系统资源的机制。它允许在同一台物理机上创建多个隔离的环境,每个环境可以拥有自己独立的资源实例,例如进程ID、挂载点、网络、用户等。这种隔离使得不同的进程能够在同一系统上运行,而彼此之间互不干扰。
在Linux中,有多种类型的命名空间,包括但不限于以下几种:
-
PID 命名空间(PID Namespace):使得进程拥有自己独立的进程ID空间,进程在不同的PID命名空间中可以拥有相同的PID而不会相互影响。
-
挂载命名空间(Mount Namespace):使得进程拥有独立的文件系统挂载点,不同的挂载命名空间中可以有不同的文件系统视图。
-
网络命名空间(Network Namespace):允许每个命名空间中拥有独立的网络设备、IP地址等网络资源,实现网络隔离。
-
IPC 命名空间(IPC Namespace):用于隔离进程间通信资源,如消息队列和共享内存等。
-
UTS 命名空间(UTS Namespace):用于隔离系统标识,如主机名等。
-
用户命名空间(User Namespace):允许分配不同的用户和组ID给进程,从而实现用户隔离。
通过使用命名空间,容器技术得以实现,并且不同的容器可以在相互隔离的环境中运行,从而实现更高效的资源利用和更好的安全性。
二、通过Linux API获取当前进程或线程的资源使用情况
要获取当前进程或线程的资源使用情况,可以使用Linux提供的一些系统调用或API。以下是一些常用的方法:
1、getrusage
getrusage 是一个用于获取进程或线程的资源使用情况的系统调用函数,在 Linux 系统中的头文件 <sys/resource.h> 中定义。
#include <sys/time.h>
#include <sys/resource.h>int getrusage(int who, struct rusage *usage);
参数who用于指定获取资源使用情况的对象,包括以下两个选项:
- RUSAGE_SELF: 获取当前进程的资源使用情况。
- RUSAGE_CHILDREN: 获取当前进程创建的所有子进程的资源使用情况的汇总信息。
参数 usage 是一个指向 struct rusage 结构体的指针,用于存储获取到的资源使用情况信息。
//struct rusage 结构体包含了一系列字段,用于表示不同类型的资源使用情况
struct rusage {struct timeval ru_utime; /* user CPU time used */struct timeval ru_stime; /* system CPU time used */long ru_maxrss; /* maximum resident set size */long ru_ixrss; /* integral shared memory size */long ru_idrss; /* integral unshared data size */long ru_isrss; /* integral unshared stack size */long ru_minflt; /* page reclaims (soft page faults) */long ru_majflt; /* page faults (hard page faults) */long ru_nswap; /* swaps */long ru_inblock; /* block input operations */long ru_oublock; /* block output operations */long ru_msgsnd; /* IPC messages sent */long ru_msgrcv; /* IPC messages received */long ru_nsignals; /* signals received */long ru_nvcsw; /* voluntary context switches */long ru_nivcsw; /* involuntary context switches */
};
ru_utime:用户级别的 CPU 时间(执行用户程序的时间)。ru_stime:系统级别的 CPU 时间(执行系统调用的时间)。ru_maxrss:进程最大的常驻内存大小(以 KB 为单位)。ru_ixrss:进程的共享内存大小。ru_idrss:进程的非共享数据段的大小。ru_isrss:进程的栈大小。ru_minflt:产生的次缺页错误(对不存在的内存页面发生的访问,需要从硬盘加载)。ru_majflt:产生的主缺页错误(必须从硬盘加载数据)。ru_nswap:发生的交换次数(从内存到磁盘或反之)。ru_inblock:从块设备读取的次数。ru_oublock:向块设备写入的次数。ru_msgsnd:发送的消息数。ru_msgrcv:接收的消息数。ru_nsignals:发出的信号数。ru_nvcsw:从等待状态唤醒的上下文切换次数(通过虚拟终端 I/O、文件系统路径名查找、等待 CPU 时间等方式)。ru_nivcsw:无法满足进程需求而导致的上下文切换次数。
这些资源使用情况信息对于进程性能分析和系统监控非常有用。getrusage 函数返回的资源使用情况是关于当前进程或线程的信息。要获取其他进程的资源使用情况,需要使用相应的进程相关的系统调用(如 wait4),并将返回的 rusage 结构体作为参数传递给 wait4。
wait4 是一个用于等待子进程结束并获取其状态信息的系统调用函数。在 Linux 系统中的头文件 <sys/wait.h> 中定义。wait4 函数的原型为:
pid_t wait4(pid_t pid, int *status, int options, struct rusage *rusage);
其中参数含义如下:
pid:指定要等待的子进程的 ID。传入-1表示等待任意子进程结束。status:用于获取子进程的退出状态信息。options:用于指定等待的选项,包括一些控制子进程状态获取行为的选项。rusage:用于获取子进程的资源使用情况信息,即上一条回答中提到的struct rusage结构体。
wait4 函数会阻塞父进程,直到指定的子进程结束。当子进程结束后,父进程将获得子进程的退出状态信息存储在 status 中,并且如果传入了 rusage 参数,则会获取子进程的资源使用情况信息。
通常情况下,wait4 函数与 fork 函数结合使用,父进程通过 fork 创建子进程,然后通过 wait4 等待子进程结束,并获取其状态信息。这样可以实现父子进程之间的同步和协作。
#include <sys/resource.h>int main() {struct rusage usage;getrusage(RUSAGE_SELF, &usage);// 打印CPU时间printf("CPU时间: %ld.%06ld 秒\n", usage.ru_utime.tv_sec, usage.ru_utime.tv_usec);// 打印最大使用的内存printf("最大内存使用量: %ld 字节\n", usage.ru_maxrss);// 其他资源使用情况,可以在usage结构体中查看// ...return 0;
}
2、sysinfo
sysinfo 是一个用于获取系统信息的系统调用函数,在 Linux 系统中的头文件 <sys/sysinfo.h> 中定义。函数原型如下:
int sysinfo(struct sysinfo *info);
参数 info 是一个指向 struct sysinfo 结构体的指针,用于存储获取到的系统信息。
//Since Linux 2.3.23 (i386) and Linux 2.3.48 (all architectures) the structure is:
struct sysinfo {long uptime; /* Seconds since boot */unsigned long loads[3]; /* 1, 5, and 15 minute load averages */unsigned long totalram; /* Total usable main memory size */unsigned long freeram; /* Available memory size */unsigned long sharedram; /* Amount of shared memory */unsigned long bufferram; /* Memory used by buffers */unsigned long totalswap; /* Total swap space size */unsigned long freeswap; /* Swap space still available */unsigned short procs; /* Number of current processes */unsigned long totalhigh; /* Total high memory size */unsigned long freehigh; /* Available high memory size */unsigned int mem_unit; /* Memory unit size in bytes */char _f[20-2*sizeof(long)-sizeof(int)]; /* Padding to 64 bytes */
};
long uptime:系统已经运行的时间(以秒为单位)。unsigned long loads[3]:系统的平均负载值,分别代表过去1分钟、5分钟和15分钟的平均负载。这些值是无符号长整型数,表示了负载值乘以 2^16 的结果。unsigned long totalram:系统总共的物理内存大小(以字节为单位)。unsigned long freeram:系统可用的物理内存大小(以字节为单位)。unsigned long sharedram:被共享的物理内存大小(以字节为单位)。unsigned long bufferram:被用作缓冲区的物理内存大小(以字节为单位)。unsigned long totalswap:交换空间的总大小(以字节为单位)。unsigned long freeswap:可用的交换空间大小(以字节为单位)。unsigned short procs:当前进程数量。unsigned long totalhigh:可用的高位内存大小(以字节为单位)。unsigned long freehigh:空闲的高位内存大小(以字节为单位)。unsigned int mem_unit:内存单元大小(以字节为单位)。
sysinfo 函数的返回值为 0 表示成功,-1 表示失败,并且可以通过 errno 来获取具体错误信息。
#include <sys/sysinfo.h>
#include <stdio.h>int main(int argc, char *argv[]) {struct sysinfo info;sysinfo(&info);// 打印总内存大小printf("总内存大小: %ld 字节\n", info.totalram * info.mem_unit);// 打印已使用内存大小printf("已使用内存大小: %ld 字节\n", (info.totalram - info.freeram) * info.mem_unit);// 其他资源使用情况,可以在info结构体中查看// ...return 0;
}
在struct sysinfo 结构体中,loads 数组中的数值表示了负载值乘以 2^16 的结果,这是因为 sysinfo 结构体中的 loads 数组使用了 unsigned long 类型。
在 Linux 内核中,负载值是以固定点数的格式表示的,使用了定点数表示方式来保留小数部分。在这里,每个负载值都被乘以了 2^16(65536),以便将小数部分转换为整数。
这种表示方式的好处在于,它可以比较精确地表示系统的负载情况,同时又不需要使用浮点数来表示,因为浮点数的运算会耗费相对更多的 CPU 时间。通过将负载值乘以一个固定的倍数(2^16),可以在不牺牲太多精度的情况下,使用整数进行表示和计算,这样会更高效。
当我们从 struct sysinfo 结构体中获取负载值时,需要将其除以 2^16 来得到真实的负载值。例如,在上面的示例代码中,打印负载值时并没有除以 2^16,因此实际的负载值应当是 info.loads[x] / 65536 才能得到系统的实际负载情况。
总之,通过将负载值乘以 2^16 来表示,Linux 内核可以在保持较高精度的同时,使用更高效的整数表示方式,用于存储和计算系统的负载情况。
3、times
times 函数是一个用于获取进程和子进程的系统和用户 CPU 时间的系统调用,其原型如下:
#include <sys/times.h>clock_t times(struct tms *buf);
buf是一个指向tms结构的指针,它用来存储 CPU 时间的信息。
struct tms 结构包含了进程和子进程的 CPU 时间信息,其定义如下:
struct tms {clock_t tms_utime; // 进程在用户态花费的时间clock_t tms_stime; // 进程在内核态花费的时间clock_t tms_cutime; // 所有已终止子进程在用户态花费的时间clock_t tms_cstime; // 所有已终止子进程在内核态花费的时间
};
tms_utime表示进程在用户态花费的 CPU 时间。tms_stime表示进程在内核态花费的 CPU 时间。tms_cutime表示所有已终止子进程在用户态花费的 CPU 时间。tms_cstime表示所有已终止子进程在内核态花费的 CPU 时间。
示例代码如下所示,演示了如何使用 times 函数来获取进程的 CPU 时间信息:
#include <stdio.h>
#include <sys/times.h>
#include <time.h>
#include <unistd.h>int main() {struct tms tms_buf;clock_t start, end;// 获取起始时间start = times(&tms_buf);printf("Starting time: %ld\n", start);// 模拟一些工作for (int i = 0; i < 100000000; ++i) {// do something}// 获取结束时间end = times(&tms_buf);printf("Ending time: %ld\n", end);// 计算 CPU 时间消耗clock_t user_time = tms_buf.tms_utime;clock_t sys_time = tms_buf.tms_stime;printf("User CPU time: %ld\n", user_time);printf("System CPU time: %ld\n", sys_time);return 0;
}
这个示例代码中,我们首先调用 times 函数获取了进程的 CPU 时间信息,并输出了起始时间。然后进行了一些模拟工作,之后再次调用 times 函数获取了结束时间,最后计算了用户态和内核态的 CPU 时间消耗。
相关文章:
Linux:查询当前进程或线程的资源使用情况
目录 一、/proc/[PID]/下的各个文件1、proc简介2、/proc/[PID]/详解 二、通过Linux API获取当前进程或线程的资源使用情况1、getrusage2、sysinfo3、times 在工作中,我们排除app出现的一些性能/资源问题时,通常要先知道当前app的资源使用情况,…...
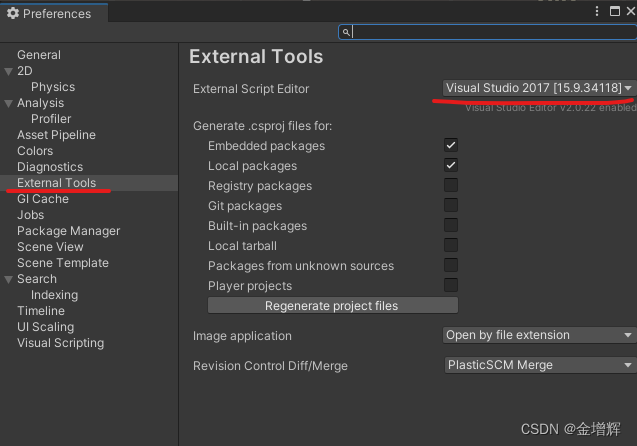
unityc用vs2017介绍
21版unity能用17vs,只要在unity的Edit/Preferences/ExternalTools里面改既可。...

单元测试实战
文章目录 为什么要做单元测试?单元测试的几个核心要点是:单元测试目标单元测试框架JUnitTestNG 单元测试工具: 为什么要做单元测试? 测试代码:通过编写和运行单元测试,开发者能够快速验证代码的各个部分是否…...

WebService
调试工具:Postman、SoapUI Soap WebService :.net WCF 、Java CFX WebService三要素: SOAP(Simple Object Access Protocol):用来描述传递信息的格式, 可以和现存的许多因特网协议和格式结合使用&#x…...

Nestjs使用log4j打印日志
众所周知,nest是自带日志的。但是好像没有log4j香,所以咱们来用log4j吧~ 我只演示最简单的用法,用具体怎么样用大家可以自己进行封装。就像前端封装自己的请求一样。 一、安装 yarn add log4js stacktrace-js 二、使用 主要就三个文件&a…...

Selenium - 自动化测试框架
Selenium 介绍 Selenium 是目前用的最广泛的 Web UI 自动化测试框架,核心功能就是可以在多个浏览器上进行自动化测试,支持多种编程语言,目前已经被 google,百度,腾讯等公司广泛使用。 开发步骤 1、配置 google 驱动…...

RFID技术在汽车制造:提高生产效率、优化物流管理和增强安全性
RFID技术在汽车制造:提高生产效率、优化物流管理和增强安全性 随着科技的进步,物联网技术已经深入到各个领域,尤其在制造业中,RFID技术以其独特的优势,如高精度追踪、实时数据收集和自动化操作,正在改变传统的生产方式…...

git异常
1.异常现象 换机新安装 Git 后,拉代码时出现问题: Unable to negotiate with 10.18.18.18 port 29418: no matching key exchange method found. Their offer: diffie-hellman-group14-sha1,diffie-hellman-group1-sha1 fatal: Could not read from rem…...
++这行代码(易懂版))
【C语言学习疑难杂症】第12期:如何从汇编角度深入理解y = (*--p)++这行代码(易懂版)
对于如下代码,思考一下输出结果是什么? int a[] = {5, 8, 7, 6, 2, 7, 3}; int y, *p = &a[1]; y = (*--p)++; printf("%d ",y); printf("%d",a[0]); 这个代码看似简单,但是在“y = (*--p)++;”这行代码里,编译器做了很多工作。 我们在vs2022的…...
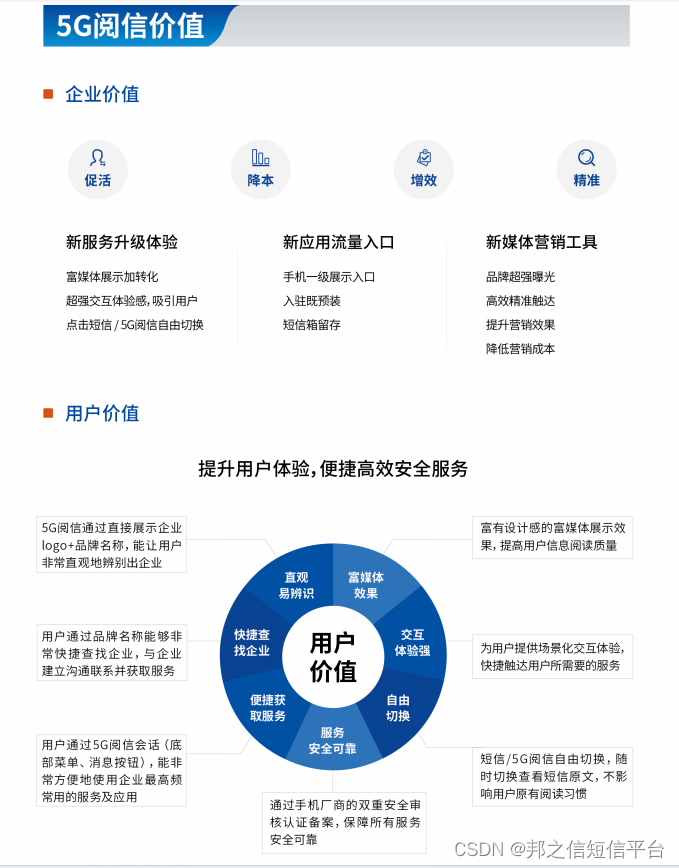
5G阅信应用场景有哪些?
5G阅信的应用场景非常广泛,以下是一些常见的应用场景: 1.工业自动化:5G阅信可以连接各种工业设备和传感器,实现设备之间的实时通信和控制,提高生产效率和自动化水平。 2.物联网和智能家居:5G阅信可以连接各…...

使用OpenSSL生成自签名SSL/TLS证书和私钥
使用OpenSSL生成自签名SSL/TLS证书和私钥 前提: 系统安装了OpenSSL; 系统:windows、linux都可; 1 生成私钥 创建一个名为 server.key 的私钥文件,并使用 RSA 算法生成一个 2048 位的密钥。 openssl genrsa -out s…...

pycharm2023.2激活和新建项目,python3.12安装永久换源
pycharm安装 安装版本选择链接 激活参考链接 python安装 Windows下载指定python链接 选择相应版本的64位即可。 安装可以自己选择安装位置,记得勾选,add path即可。其余下一步默认即可。 windows临时换源 pip install 模块包名字 -i https://pypi.…...

FPGA分频电路设计(2)
实验要求: 采用 4 个开关以二进制形式设定分频系数(1-10),实现对已知信号的分频。 类似实验我之前做过一次,但那次的方法实在是太笨了: 利用VHDL实现一定系数范围内的信号分频电路 需要重做以便将来应对更…...
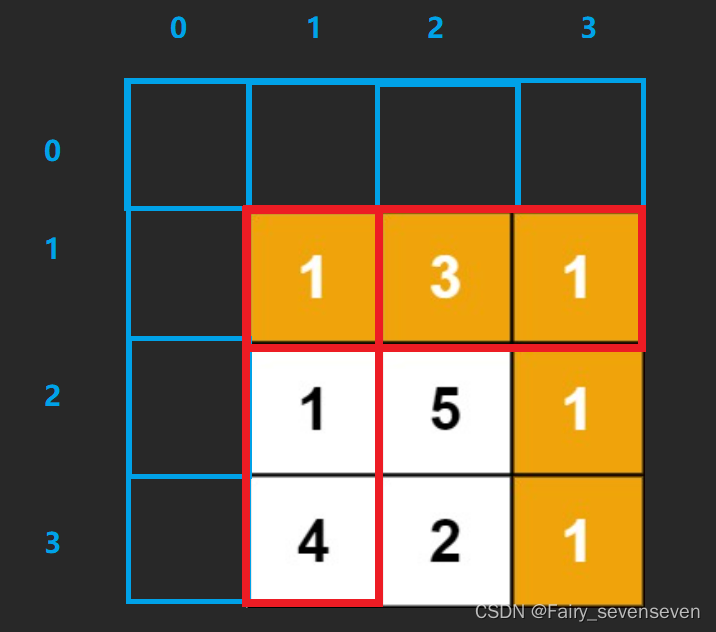
【三】【C语言\动态规划】珠宝的最高价值、下降路径最小和、最小路径和,三道题目深度解析
动态规划 动态规划就像是解决问题的一种策略,它可以帮助我们更高效地找到问题的解决方案。这个策略的核心思想就是将问题分解为一系列的小问题,并将每个小问题的解保存起来。这样,当我们需要解决原始问题的时候,我们就可以直接利…...
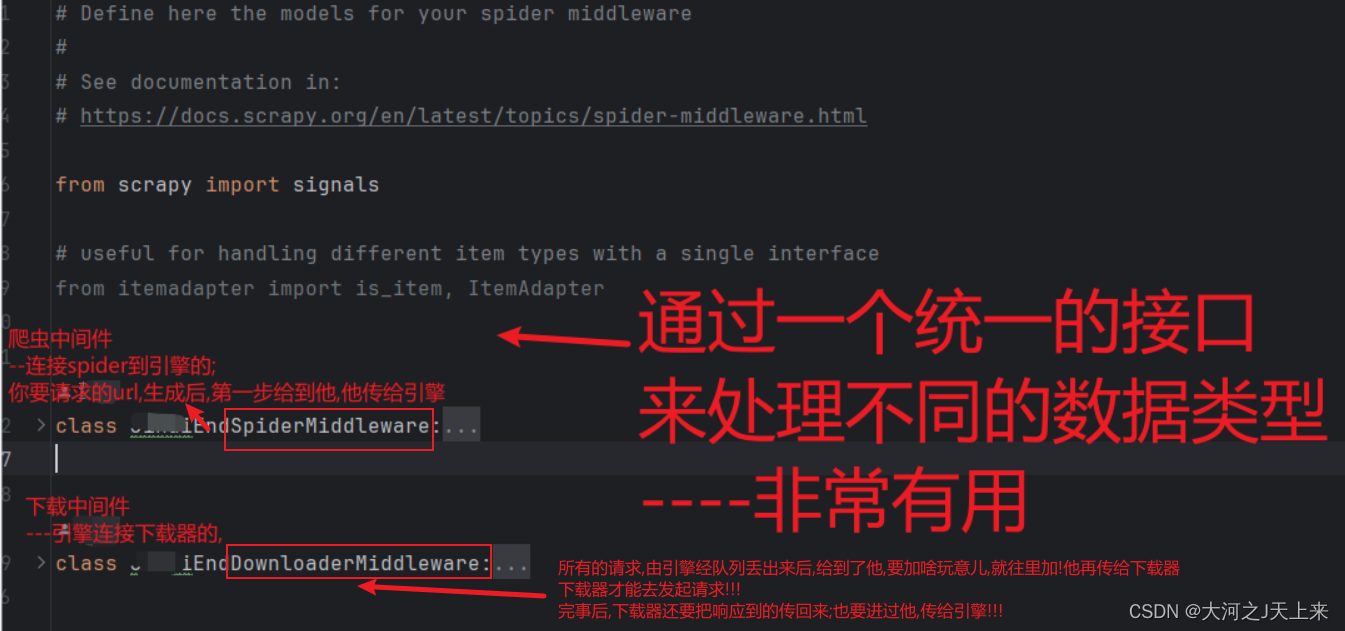
爬虫工作量由小到大的思维转变---<第二十八章 Scrapy中间件说明书>
爬虫工作量由小到大的思维转变---<第二十六章 Scrapy通一通中间件的问题>-CSDN博客 前言: (书接上面链接)自定义中间件玩不明白? 好吧,写个翻译的文档点笔记,让中间件更通俗一点!!! 正文: 全局图: 爬虫中间件--->翻译笔记: from scrapy import s…...
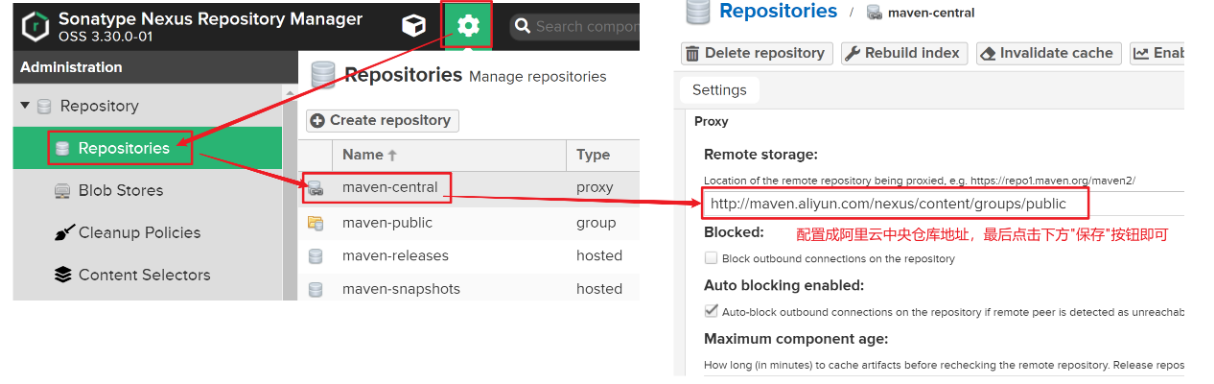
从Maven初级到高级
一.Maven简介 Maven 是 Apache 软件基金会组织维护的一款专门为 Java 项目提供构建和依赖管理支持的工具。 一个 Maven 工程有约定的目录结构,约定的目录结构对于 Maven 实现自动化构建而言是必不可少的一环,就拿自动编译来说,Maven 必须 能…...

orangepi--开发板配置网络SSH登录
常用指令: ifconfig-------------------------------------查看网络地址 sudo passwd orangepi-------------------------改密码 nmcli dev wifi-------------------------------查看wifi nmcli dev wifi connect xx password xx--------连接网络 ip addr show wla…...

简单通讯录管理系统第4关:简单通讯录管理系统之修改通讯录用户信息
任务描述 本关任务:实现修改通讯录用户电话号码的功能。 编程要求 仔细阅读右侧编辑区内给出的代码框架及注释,在 Begin-End 中实现通讯录管理系统中修改用户信息的功能,具体要求如下: 在 PhoneManage.java 类定义一个 changeP…...

macOS编译ckb-next
macOS x86 成功,下一步,测试:m1、m2、m3 。 1、Homebrew # 三选一 /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" # /bin/bash -c "$(curl -fsSL https://raw.gith…...
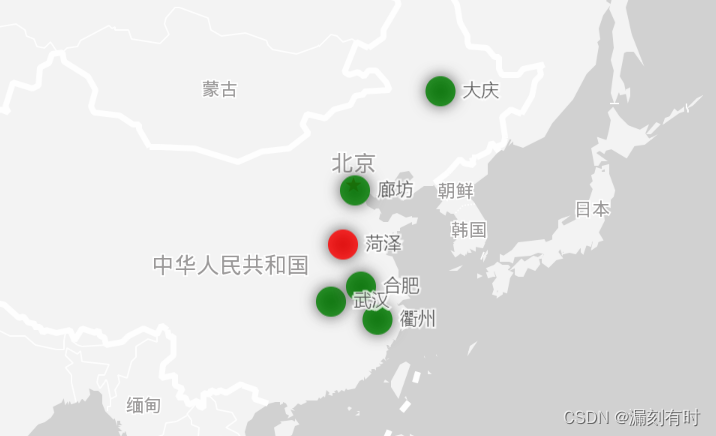
漏刻有时数据可视化Echarts组件开发(46)散点图颜色判断
series组件 series: [{name: Top 5,type: scatter,coordinateSystem: bmap,data: convertData(data.sort(function (a, b) {return b.value - a.value;}).slice(0, 6)),symbolSize: 20,encode: {value: 2},showEffectOn: render,rippleEffect: {brushType: stroke},label: {fo…...

安全视角:AI Agent Harness Engineering 权限控制体系
安全视角:AI Agent Harness Engineering 权限控制体系 本文作者:资深云原生安全工程师、AI Agent落地技术专家,累计帮助12家企业完成AI Agent安全体系搭建,避免了超过5000万的潜在安全损失 一、引言 (Introduction) 钩子 (The Hook) 你是否见过这样的场景:公司花了上百万…...

避坑指南:合宙ESP32-C3连接MPU6050时常见的I2C通信失败与数据跳变问题
ESP32-C3与MPU6050实战避坑手册:从I2C通信失败到数据稳定的全链路解决方案 当你在深夜调试ESP32-C3与MPU6050的组合时,突然发现串口监视器不断弹出"not find MPU6050"的红色警告,或者读取到的加速度数据像过山车一样疯狂跳动——这…...

Kali 系统 Burp Suite 安装教程 零基础轻松上手
目录 安装环境 一、Kali Linux系统信息 编辑 二、安装及配置 1.下载Burp Suite 2.安装 3.配置proxy代理 安装环境 主机:MacBooPro 2021 M1 Pro 系统:Ventura 13.1 虚拟机软件:Parallels Desktop 虚拟机系统:Kali Linux…...

从PostgreSQL老手视角:快速上手华为GaussDB极简版,这些操作习惯几乎一样
从PostgreSQL老手视角:快速上手华为GaussDB极简版的10个关键习惯迁移 如果你已经习惯了PostgreSQL的命令行操作和配置逻辑,第一次接触华为GaussDB时会有种奇妙的熟悉感——就像走进一间重新装修过的老房子,家具摆放的位置几乎没变,…...

保姆级教程:手把手教你用Python搭建HTTP服务器,为安信可BL602模组OTA升级铺路
从零构建Python HTTP服务器:物联网开发者的OTA升级基石 在物联网设备开发中,固件升级(OTA)是产品生命周期管理的关键环节。想象一下这样的场景:当您需要为部署在数百公里外的设备更新功能时,无需物理接触设备,只需通过…...

终极AMD Ryzen调试指南:5个场景掌握SMUDebugTool硬件调优
终极AMD Ryzen调试指南:5个场景掌握SMUDebugTool硬件调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:/…...
- 5月20日-第一题- 服务器处理计算任务】(题目+思路+JavaC++Python解析+在线测试))
【2026年华为暑期实习-非AI方向(通软嵌软测试算法数据科学)- 5月20日-第一题- 服务器处理计算任务】(题目+思路+JavaC++Python解析+在线测试)
题目内容 服务器集群中有 nnn 个待处理的计算任务,第 iii 个任务需要的总计算量为 tasks[i]tasks[i]...

一文搞懂 MySQL:一条 SQL 语句的完整执行之旅
你是否每天都在写 SQL,却从未想过它在 MySQL 内部是如何一步步执行的?今天我们就通过这张经典的 MySQL 执行流程图,带你拆解一条 SQL 从客户端发送到结果返回的完整过程,搞懂这个过程,你就能轻松理解 SQL 优化、事务原…...
)
手把手教你用W25Q32 SPI Flash:从波形图看懂擦除、写入和读取(附完整代码)
手把手教你用W25Q32 SPI Flash:从波形图看懂擦除、写入和读取(附完整代码) 在嵌入式开发中,SPI Flash存储器因其高性价比、大容量和简单接口而广受欢迎。W25Q32作为一款32Mb的SPI Flash芯片,被广泛应用于物联网设备、消…...

用K210开发板驱动HUB75E点阵屏:从SPI时序到S型排列的完整避坑指南
用K210开发板驱动HUB75E点阵屏:从SPI时序到S型排列的完整避坑指南 在嵌入式开发领域,驱动LED点阵屏一直是兼具挑战性和实用性的课题。当K210这款高性能RISC-V开发板遇上HUB75E接口的大尺寸点阵屏,开发者往往会在SPI时序优化、内存管理和独特的…...