Flink系列之:深入理解ttl和checkpoint,Flink SQL应用ttl案例
Flink系列之:深入理解ttl和checkpoint,Flink SQL应用ttl案例
- 一、深入理解Flink TTL
- 二、Flink SQL设置TTL
- 三、Flink设置TTL
- 四、深入理解checkpoint
- 五、Flink设置Checkpoint
- 六、Flink SQL关联多张表
- 七、Flink SQL使用TTL关联多表
一、深入理解Flink TTL
Flink TTL(Time To Live)是一种机制,用于设置数据的过期时间,控制数据在内存或状态中的存活时间。通过设置TTL,可以自动删除过期的数据,从而释放资源并提高性能。
在Flink中,TTL可以应用于不同的组件和场景,包括窗口、状态和表。
-
窗口:对于窗口操作,可以将TTL应用于窗口中的数据。当窗口中的数据过期时,Flink会自动丢弃这些数据,从而保持窗口中的数据只包含最新的和有效的内容。这样可以减少内存的使用,同时提高窗口操作的计算性能。
-
状态:对于有状态的操作,如键控状态或算子状态,可以为状态设置TTL。当状态中的数据过期时,Flink会自动清理过期的状态,释放资源。这对于长时间运行的应用程序特别有用,可以避免状态无限增长,消耗过多的内存。
-
表:在Flink中,TTL也可以应用于表。可以通过在CREATE TABLE语句的WITH子句中指定TTL的选项来设置表的过期时间。当表中的数据过期时,Flink会自动删除过期的数据行。这对于处理具有实效性(例如日志)的数据特别有用,可以自动清理过期的数据,保持表的内容的新鲜和有效。
TTL在实际应用中的作用主要体现在以下几个方面:
-
节省资源:通过设置合适的TTL,可以有效地管理和控制内存和状态的使用。过期的数据会被自动清理,释放资源。这样可以避免无效或过时的数据占用过多的资源,提高应用程序的性能和可扩展性。
-
数据清理:对于具有实效性的数据,如日志数据,可以使用TTL自动清理过期的数据。这可以减少手动管理和维护数据的工作量,保持数据的新鲜和有效。
-
数据一致性:通过设置合适的TTL,可以确保数据在一定时间内保持一致性。过期的数据不再被读取或使用,可以避免数据不一致性的问题。
-
性能优化:TTL可以通过自动清理过期数据来优化查询和计算的性能。只有最新和有效的数据被保留,可以减少数据的处理量,提高计算效率。
总而言之,TTL是Flink中一种重要的机制,用于控制数据的过期时间和生命周期。通过适当配置TTL,可以优化资源使用、提高系统性能,并保持数据的一致性和有效性。
二、Flink SQL设置TTL
Flink SQL中可以使用TTL(Time To Live)来设置数据的过期时间,以控制数据在内存或状态中的存留时间。通过设置TTL,可以自动删除过期的数据,从而节省资源并提高性能。
要在Flink SQL中设置TTL,可以使用CREATE TABLE语句的WITH选项来指定TTL的配置。以下是一个示例:
CREATE TABLE myTable (id INT,name STRING,eventTime TIMESTAMP(3),WATERMARK FOR eventTime AS eventTime - INTERVAL '5' MINUTE -- 定义Watermark
) WITH ('connector' = 'kafka','topic' = 'myTopic','properties.bootstrap.servers' = 'localhost:9092','format' = 'json','json.fail-on-missing-field' = 'false','json.ignore-parse-errors' = 'true','ttl' = '10m' -- 设置TTL为10分钟
);
在上述示例中,通过在CREATE TABLE语句的WITH子句中的’ttl’选项中指定TTL的值(10m),即设置数据在内存中的存活时间为10分钟。过期的数据会自动被删除。
需要注意的是,引入TTL机制会增加一定的性能和资源开销。因此,在使用TTL时需要权衡好过期时间和系统的性能需求。
三、Flink设置TTL
- 在需要设置TTL的数据源或状态上,使用相应的API(例如DataStream API或KeyedState API)设置TTL值。
// DataStream API dataStream.keyBy(<key_selector>).mapStateDescriptor.enableTimeToLive(Duration.ofMillis(<ttl_in_milliseconds>));// KeyedState API descriptor.enableTimeToLive(Duration.ofMillis(<ttl_in_milliseconds>)); - 在Flink作业中配置TTL检查间隔(默认值为每分钟一次):
state.backend.rocksdb.ttl.compaction.interval: <interval_in_milliseconds>
四、深入理解checkpoint
Flink的Checkpoint是一种容错机制,用于在Flink作业执行过程中定期保存数据的一致性检查点。它可以保证作业在发生故障时能够从检查点恢复,并继续进行。下面是一些深入介绍Checkpoint的关键概念和特性:
-
一致性保证:Flink的Checkpoint机制通过保存作业状态的快照来实现一致性保证。在Checkpoint期间,Flink会确保所有的输入数据都已经被处理,并将结果写入状态后再进行检查点的保存。这样可以确保在恢复时,从检查点恢复的作业状态仍然是一致的。
-
保存顺序:Flink的Checkpoint机制保证了保存检查点的顺序。检查点的保存是有序的,即在一个检查点完成之前,不会开始下一个检查点的保存。这种有序的保存方式能够保证在恢复时按照检查点的顺序进行恢复。
-
并行度一致性:Flink的Checkpoint机制能够保证在作业的不同并行任务之间保持一致性。即使在分布式的情况下,Flink也能够确保所有并行任务在某个检查点的位置上都能保持一致。这是通过分布式快照算法和超时机制来实现的。
-
可靠性保证:Flink的Checkpoint机制对于作业的故障恢复非常可靠。当一个任务发生故障时,Flink会自动从最近的检查点进行恢复。如果某个检查点无法满足一致性要求,Flink会自动选择前一个检查点进行恢复,以确保作业能够在一个一致的状态下继续执行。
-
容错机制:Flink的Checkpoint机制提供了容错机制来应对各种故障情况。例如,如果某个任务在保存检查点时失败,Flink会尝试重新保存检查点,直到成功为止。此外,Flink还支持增量检查点,它可以在不保存整个作业状态的情况下只保存修改的部分状态,从而提高了保存检查点的效率。
-
高可用性:Flink的Checkpoint机制还提供了高可用性的选项。可以将检查点数据保存在分布式文件系统中,以防止单点故障。此外,还可以配置备份作业管理器(JobManager)和任务管理器(TaskManager)以确保在某个节点发生故障时能够快速恢复。
总结起来,Flink的Checkpoint机制是一种强大且可靠的容错机制,它能够确保作业在发生故障时能够从一致性检查点恢复,并继续进行。通过保存作业状态的快照,Flink能够保证作业的一致性,并提供了高可用性和高效率的保存和恢复机制。
Checkpoint是Flink中一种重要的容错机制,用于保证作业在发生故障时能够从上一次检查点恢复,并继续进行处理,从而实现容错性。以下是Checkpoint的主要用途:
-
容错和故障恢复:Checkpoint可以将作业的状态和数据进行持久化,当发生故障时,Flink可以使用最近的检查点来恢复作业的状态和数据,从而避免数据丢失,并继续处理未完成的任务。
-
Exactly-Once语义:通过将检查点和事务(如果应用程序使用Flink的事务支持)结合起来,Flink可以实现Exactly-Once语义,确保结果的一致性和准确性。当作业从检查点恢复时,它将只会处理一次输入数据,并产生一次输出,避免了重复和丢失的数据写入。
-
冷启动和部署:可以使用检查点来实现作业的冷启动,即在作业启动时,从最近的检查点恢复状态和数据,并从上一次检查点的位置继续处理。这对于在作业启动或重新部署时非常有用,可以快速恢复到之前的状态,减少恢复所需的时间。
-
跨版本迁移:当使用不同版本的Flink或更改作业的代码时,可以使用检查点将作业从旧的版本转移到新的版本,从而实现跨版本迁移。
总之,Checkpoint是Flink中的关键机制,其用途包括容错和故障恢复、Exactly-Once语义、冷启动和部署以及跨版本迁移。通过使用Checkpoint,可以提高作业的可靠性、一致性和可恢复性。
五、Flink设置Checkpoint
要设置Flink的Checkpoint和TTL,可以按照以下步骤进行操作:
设置Checkpoint:
- 在Flink作业中启用Checkpoint:可以通过在Flink配置文件(flink-conf.yaml)中设置以下属性来开启Checkpoint:
execution.checkpointing.enabled: true - 设置Checkpoint间隔:可以通过以下属性设置Checkpoint的间隔时间(默认值为10秒):
execution.checkpointing.interval: <interval_in_milliseconds> - 设置Checkpoint保存路径:可以通过以下属性设置Checkpoint文件的保存路径(默认为jobmanager根路径):
state.checkpoints.dir: <checkpoint_directory_path>
六、Flink SQL关联多张表
在Flink SQL中,可以通过使用窗口操作来保证在一段时间内多张表的数据总能关联到。窗口操作可以用于基于时间的数据处理,将数据划分为窗口,并在每个窗口上执行关联操作。下面是一个示例,演示如何在一段时间内关联多张表的数据:```sql
-- 创建两个输入表
CREATE TABLE table1 (id INT,name STRING,eventTime TIMESTAMP(3),WATERMARK FOR eventTime AS eventTime - INTERVAL '1' SECOND
) WITH ('connector.type' = 'kafka','connector.version' = 'universal','connector.topic' = 'topic1','connector.startup-mode' = 'earliest-offset','format.type' = 'json'
);CREATE TABLE table2 (id INT,value STRING,eventTime TIMESTAMP(3),WATERMARK FOR eventTime AS eventTime - INTERVAL '1' SECOND
) WITH ('connector.type' = 'kafka','connector.version' = 'universal','connector.topic' = 'topic2','connector.startup-mode' = 'earliest-offset','format.type' = 'json'
);-- 执行关联操作
SELECT t1.id, t1.name, t2.value
FROM table1 t1
JOIN table2 t2 ON t1.id = t2.id AND t1.eventTime BETWEEN t2.eventTime - INTERVAL '5' MINUTE AND t2.eventTime + INTERVAL '5' MINUTE
在上面的例子中,首先创建了两个输入表table1和table2,并分别指定了输入源(此处使用了Kafka作为示例输入源)。然后,在执行关联操作时,使用了通过窗口操作进行时间范围的过滤条件,即"t1.eventTime BETWEEN t2.eventTime - INTERVAL ‘5’ MINUTE AND t2.eventTime + INTERVAL ‘5’ MINUTE",确保了在一段时间内两张表的数据能够关联到。
通过使用窗口操作,可以根据具体的时间范围来进行数据关联,从而保证在一段时间内多张表的数据总能关联到。
七、Flink SQL使用TTL关联多表
Flink还提供了Time-To-Live (TTL)功能,可以用于在表中定义数据的生存时间。当数据的时间戳超过定义的TTL时,Flink会自动将其从表中删除。这在处理实时数据时非常有用,可以自动清理过期的数据。
在Flink中使用TTL可以通过创建表时指定TTL属性来实现,如下所示:
CREATE TABLE myTable (id INT,name STRING,event_time TIMESTAMP(3),WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND,PRIMARY KEY (id) NOT ENFORCED,TTL (event_time) AS event_time + INTERVAL '1' HOUR
) WITH ('connector.type' = 'kafka',...
)
在这个例子中,表myTable定义了一个event_time列,并使用TTL函数指定了数据的生存时间为event_time加上1小时。当数据的event_time超过1小时时,Flink会自动删除这些数据。
通过在Flink SQL中同时使用JOIN和TTL,你可以实现多张表的关联,并根据指定的条件删除过期的数据,从而更灵活地处理和管理数据。
相关文章:

Flink系列之:深入理解ttl和checkpoint,Flink SQL应用ttl案例
Flink系列之:深入理解ttl和checkpoint,Flink SQL应用ttl案例 一、深入理解Flink TTL二、Flink SQL设置TTL三、Flink设置TTL四、深入理解checkpoint五、Flink设置Checkpoint六、Flink SQL关联多张表七、Flink SQL使用TTL关联多表 一、深入理解Flink TTL …...
)
Wails中js调用go函数(1种go写法,2种js调用方法)
官方js调用go方法文档:https://wails.io/zh-Hans/docs/howdoesitwork a)在app.go文件里写一个要js调用的go函数: func (a *App) JSCallGo(data1 string) string { return “test” } b)运行 wails dev 命令,…...
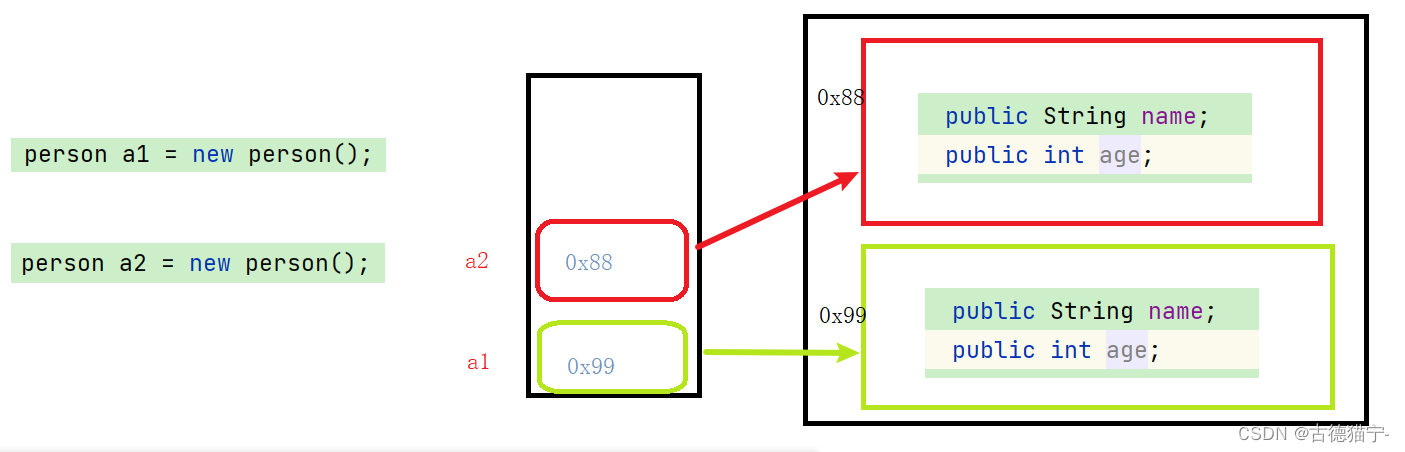
【我与java的成长记】之面向对象的初步认识
系列文章目录 能看懂文字就能明白系列 C语言笔记传送门 🌟 个人主页:古德猫宁- 🌈 信念如阳光,照亮前行的每一步 文章目录 系列文章目录🌈 *信念如阳光,照亮前行的每一步* 前言一、什么是面向对象面向过程…...

面试题之二HTTP和RPC的区别?
面试题之二 HTTP和RPC的区别? Ask范围:分布式和微服务 难度指数:4星 考察频率:70-80% 开发年限:3年左右 从三个方面来回答该问题: 一.功能特性 1)HTTP是属于应用层的协议:超文本传输协议…...

初试Kafka
Kafka 是一个分布式流处理平台,通常用作消息中间件,它可以处理大规模的实时数据流。以下是从零开始使用 Kafka 作为消息中间件的基本教程: 步骤 1: 下载和安装 Kafka 访问 Apache Kafka 官方网站:Apache Kafka下载最新的 Kafka …...

SuperMap Hi-Fi 3D SDK for Unity基础开发教程
作者:kele 一、背景 众所周知,游戏引擎(Unity)功能强大,可以做出很多炫酷的游戏和动画效果,这部分功能的实现往往不仅仅是靠可视化界面就能够实现的,还需要代码开发。SuperMap Hi-Fi SDKS for …...
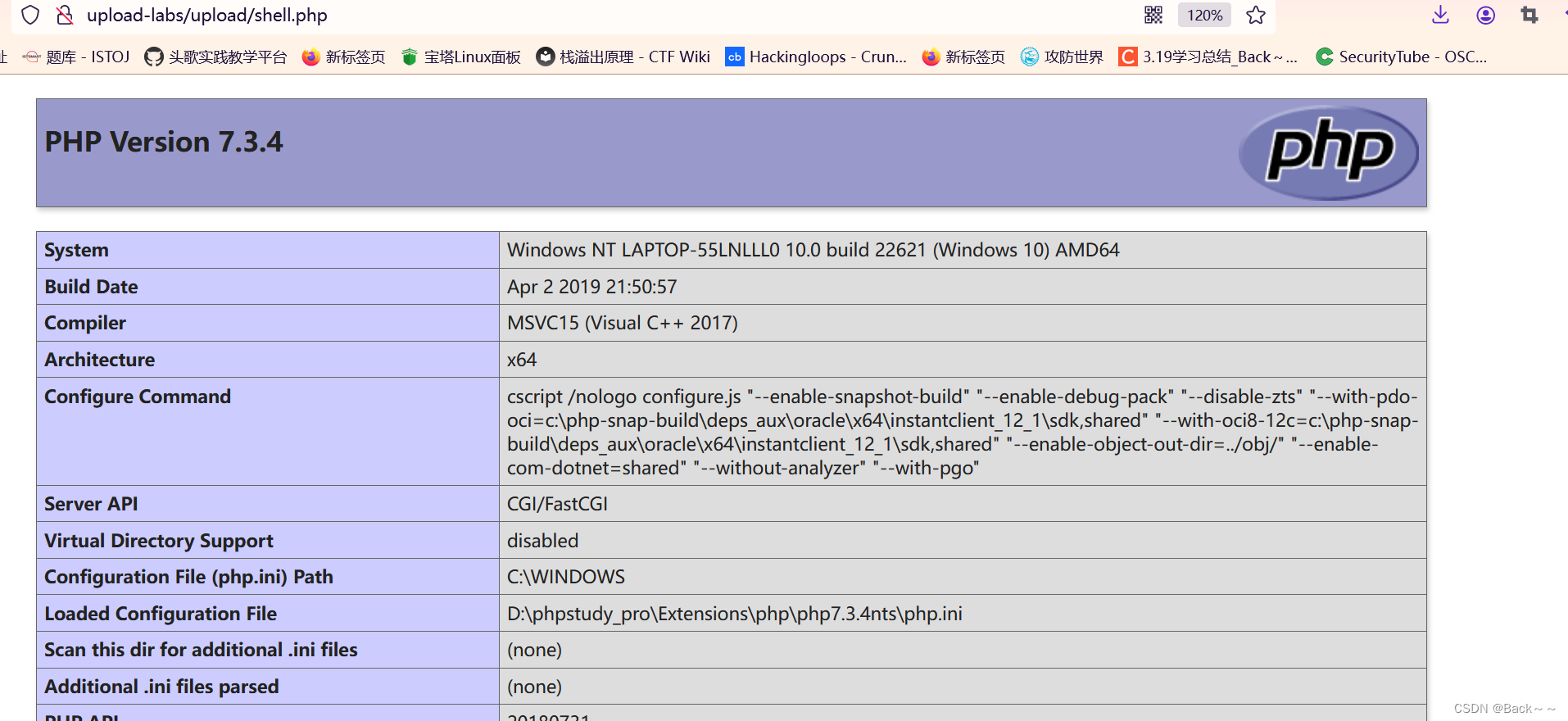
Upload-lab(pass1~2)
Pass-1-js检查 这里检验 因为是前端js校验,所以只用绕过js前端校验 用burp抓包修改文件类型 写一个简易版本的php Pass-2-只验证Content-type 仅仅判断content-type类型 因此上传shell.php抓包修改content-type为图片类型:image/jpeg、image/png、image/gif...

Linux:查询当前进程或线程的资源使用情况
目录 一、/proc/[PID]/下的各个文件1、proc简介2、/proc/[PID]/详解 二、通过Linux API获取当前进程或线程的资源使用情况1、getrusage2、sysinfo3、times 在工作中,我们排除app出现的一些性能/资源问题时,通常要先知道当前app的资源使用情况,…...
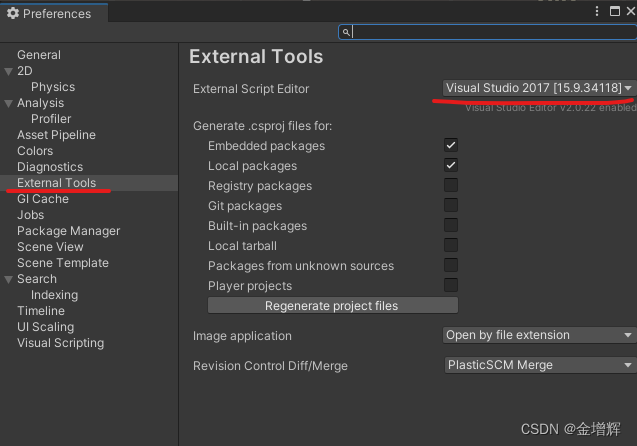
unityc用vs2017介绍
21版unity能用17vs,只要在unity的Edit/Preferences/ExternalTools里面改既可。...

单元测试实战
文章目录 为什么要做单元测试?单元测试的几个核心要点是:单元测试目标单元测试框架JUnitTestNG 单元测试工具: 为什么要做单元测试? 测试代码:通过编写和运行单元测试,开发者能够快速验证代码的各个部分是否…...

WebService
调试工具:Postman、SoapUI Soap WebService :.net WCF 、Java CFX WebService三要素: SOAP(Simple Object Access Protocol):用来描述传递信息的格式, 可以和现存的许多因特网协议和格式结合使用&#x…...

Nestjs使用log4j打印日志
众所周知,nest是自带日志的。但是好像没有log4j香,所以咱们来用log4j吧~ 我只演示最简单的用法,用具体怎么样用大家可以自己进行封装。就像前端封装自己的请求一样。 一、安装 yarn add log4js stacktrace-js 二、使用 主要就三个文件&a…...

Selenium - 自动化测试框架
Selenium 介绍 Selenium 是目前用的最广泛的 Web UI 自动化测试框架,核心功能就是可以在多个浏览器上进行自动化测试,支持多种编程语言,目前已经被 google,百度,腾讯等公司广泛使用。 开发步骤 1、配置 google 驱动…...

RFID技术在汽车制造:提高生产效率、优化物流管理和增强安全性
RFID技术在汽车制造:提高生产效率、优化物流管理和增强安全性 随着科技的进步,物联网技术已经深入到各个领域,尤其在制造业中,RFID技术以其独特的优势,如高精度追踪、实时数据收集和自动化操作,正在改变传统的生产方式…...

git异常
1.异常现象 换机新安装 Git 后,拉代码时出现问题: Unable to negotiate with 10.18.18.18 port 29418: no matching key exchange method found. Their offer: diffie-hellman-group14-sha1,diffie-hellman-group1-sha1 fatal: Could not read from rem…...
++这行代码(易懂版))
【C语言学习疑难杂症】第12期:如何从汇编角度深入理解y = (*--p)++这行代码(易懂版)
对于如下代码,思考一下输出结果是什么? int a[] = {5, 8, 7, 6, 2, 7, 3}; int y, *p = &a[1]; y = (*--p)++; printf("%d ",y); printf("%d",a[0]); 这个代码看似简单,但是在“y = (*--p)++;”这行代码里,编译器做了很多工作。 我们在vs2022的…...
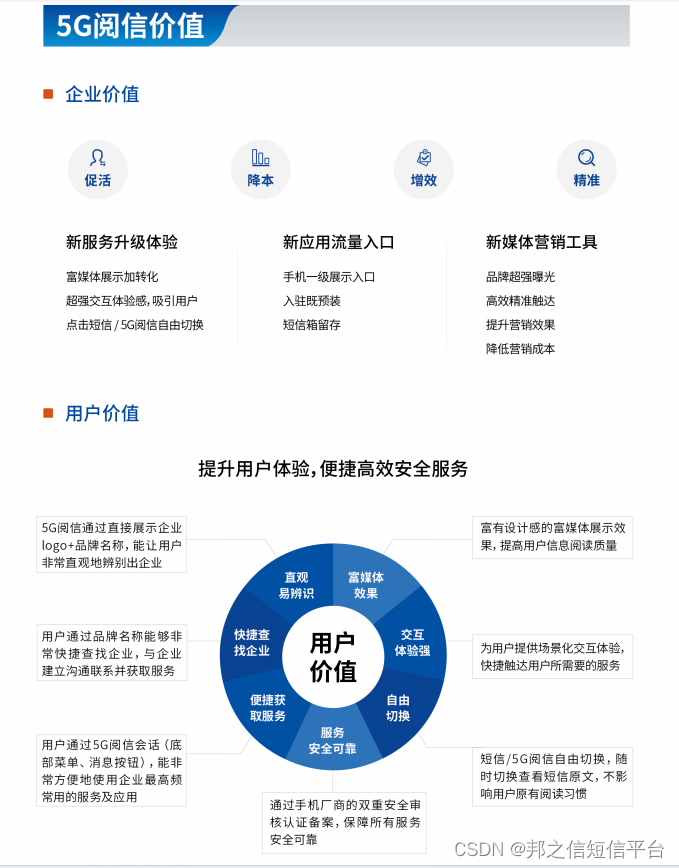
5G阅信应用场景有哪些?
5G阅信的应用场景非常广泛,以下是一些常见的应用场景: 1.工业自动化:5G阅信可以连接各种工业设备和传感器,实现设备之间的实时通信和控制,提高生产效率和自动化水平。 2.物联网和智能家居:5G阅信可以连接各…...

使用OpenSSL生成自签名SSL/TLS证书和私钥
使用OpenSSL生成自签名SSL/TLS证书和私钥 前提: 系统安装了OpenSSL; 系统:windows、linux都可; 1 生成私钥 创建一个名为 server.key 的私钥文件,并使用 RSA 算法生成一个 2048 位的密钥。 openssl genrsa -out s…...

pycharm2023.2激活和新建项目,python3.12安装永久换源
pycharm安装 安装版本选择链接 激活参考链接 python安装 Windows下载指定python链接 选择相应版本的64位即可。 安装可以自己选择安装位置,记得勾选,add path即可。其余下一步默认即可。 windows临时换源 pip install 模块包名字 -i https://pypi.…...

FPGA分频电路设计(2)
实验要求: 采用 4 个开关以二进制形式设定分频系数(1-10),实现对已知信号的分频。 类似实验我之前做过一次,但那次的方法实在是太笨了: 利用VHDL实现一定系数范围内的信号分频电路 需要重做以便将来应对更…...
)
直线模组选型别再“先选电机“了!导程才是起点(附正向推导五步法)
引言:一个高频"翻车"现场在直线模组(丝杆模组)选型中,有个环节经常出现逆向翻车——工程师先选好了电机,再去配丝杆导程,结果发现:❌ 速度上不去❌ 推力不够大❌ 电机严重发热问题的根…...

SkyWalking UI 保姆级使用指南:从仪表盘到告警,手把手教你排查线上问题
SkyWalking UI 实战指南:从异常告警到代码级优化的全链路排查 当凌晨三点的告警短信突然亮起屏幕,作为值班工程师的你该如何快速定位线上服务的性能瓶颈?SkyWalking UI 提供的不仅是数据看板,更是一套完整的分布式系统诊断工具箱。…...
-5月20日-第二题- LLM 多源语料分级清洗预算分配】(题目+思路+JavaC++Python解析+在线测试))
【2026年华为暑期实习(AI)-5月20日-第二题- LLM 多源语料分级清洗预算分配】(题目+思路+JavaC++Python解析+在线测试)
题目内容 某 L L M LLM LLM 预训练团队从 N N N 个数据源收集语料,每个数据源 i i...

InterSystems IntelliCare 成为首个获得欧盟医疗器械法规认证的 AI 原生EHR系统
监管里程碑重申了 InterSystems 作为企业级 AI 应用领先提供商的地位 中国 北京 为全球超过 10 亿份健康记录提供支持的创新数据技术提供商 InterSystems今日宣布,其电子健康记录(EHR)解决方案已根据 《欧盟法规 (EU) 2017/745》ÿ…...

重磅喜报!中国星坤入围东莞上规资助计划,政企携手共筑智造标杆
近日,东莞市工业和信息化局正式公布 2026 年支持工业企业上规发展做大做强项目拟资助计划,中国星坤(XKB Connection)凭借在电子连接器领域的技术实力与稳健发展,成功入选,成为东莞智造升级的标杆企业之一东…...

光猫拨号下,如何把二级路由器变成‘透明网桥’?一个设置让NAS、打印机全屋可见
光猫拨号下的家庭网络优化:二级路由器透明化实战指南 家里NAS里的电影在客厅电视上死活刷不出来?书房电脑找不到卧室的无线打印机?这些问题往往源于家庭网络中多台路由器形成的"局域网套娃"。本文将手把手教你如何将二级路由器转化…...

CANN/asc-devkit __hgtux2函数
__hgtux2 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/c…...

杰理微蓝牙芯片AC696系列入门
1.文章背景 此篇文章以ac696n_soundbox_sdk_v1.7.0版本进行入门讲解: 写这篇文章的目的是因为自己在尝试入门杰理微的时候遇到了好多的问题点,想尝试用买到的开发板来驱动一颗LED闪烁却一直没有按自己想象的逻辑成功跑出效果,在网上到处翻找手…...
)
实战:如何用OpenPCDet训练你自己的“树”检测模型(附完整数据集与配置文件)
实战:如何用OpenPCDet训练你自己的“树”检测模型(附完整数据集与配置文件) 激光雷达在林业资源调查中的应用正在快速普及。想象一下,你手持激光扫描设备走进一片森林,几分钟内就能获取每棵树的精确三维坐标和形态数据…...

从Excel到预测:5分钟搞定Python读取本地iris.csv文件并完成分类
从Excel到预测:5分钟搞定Python读取本地iris.csv文件并完成分类 当你第一次接触机器学习时,最令人沮丧的往往不是算法本身,而是那些看似简单却总出问题的数据准备环节。我至今记得自己对着一个简单的CSV文件折腾了整个下午的狼狈经历——列名…...