爬虫工作量由小到大的思维转变---<第二十三章 Scrapy开始很快,越来越慢(医病篇)>
诊断篇![]() https://blog.csdn.net/m0_56758840/article/details/135170994?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170333243316800180644102%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=170333243316800180644102&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-1-135170994-null-null.142%5Ev96%5Epc_search_result_base7&utm_term=%E7%88%AC%E8%99%AB%E5%B7%A5%E4%BD%9C%E9%87%8F%E7%94%B1%E5%B0%8F%E5%88%B0%E5%A4%A7%E7%9A%84%E6%80%9D%E7%BB%B4%E8%BD%AC%E5%8F%98---%EF%BC%9C%E7%AC%AC%E4%BA%8C%E5%8D%81%E4%BA%8C%E7%AB%A0%20Scrapy%E5%BC%80%E5%A7%8B%E5%BE%88%E5%BF%AB%2C%E8%B6%8A%E6%9D%A5%E8%B6%8A%E6%85%A2%28%E8%AF%8A%E6%96%AD%E7%AF%87%29%EF%BC%9E&spm=1018.2226.3001.4187
https://blog.csdn.net/m0_56758840/article/details/135170994?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170333243316800180644102%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=170333243316800180644102&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-1-135170994-null-null.142%5Ev96%5Epc_search_result_base7&utm_term=%E7%88%AC%E8%99%AB%E5%B7%A5%E4%BD%9C%E9%87%8F%E7%94%B1%E5%B0%8F%E5%88%B0%E5%A4%A7%E7%9A%84%E6%80%9D%E7%BB%B4%E8%BD%AC%E5%8F%98---%EF%BC%9C%E7%AC%AC%E4%BA%8C%E5%8D%81%E4%BA%8C%E7%AB%A0%20Scrapy%E5%BC%80%E5%A7%8B%E5%BE%88%E5%BF%AB%2C%E8%B6%8A%E6%9D%A5%E8%B6%8A%E6%85%A2%28%E8%AF%8A%E6%96%AD%E7%AF%87%29%EF%BC%9E&spm=1018.2226.3001.4187
前言:
诊断篇已经讲了(链接在上面),如何分析出自己的scrapy出了什么问题! 一般来说,如果不是网络ip问题,大部分都是内存泄漏问题~
而在内存泄漏里面,普遍的现象就是request和item的处理,在一开始就出现了设计问题;本章,就来讲讲,这两个部位出现问题的`通治法`!
---------就像,看到发热流鼻涕的,就给他999感冒灵! 看到这两出现问题,我也先给开个`通药`!
正文:
问题分析:
当通过Telnet检测到Scrapy中有大量的请求(request)和数据项(item)堆积,并且最老的请求或数据项的时间戳显示为较长时间前(如几百秒前),是什么原因导致的呢?
答:
- 爬虫逻辑问题:可能的原因是爬虫逻辑中存在问题,导致爬虫无法及时处理或发送请求。这可能是由于某些错误的条件判断或复杂的逻辑流程导致的。例如,在处理请求时,可能发生了死循环或未正确处理返回的响应,导致请求无法完成并持续堆积。
- 下载或处理延迟:这个问题也可能由于下载或数据处理的延迟引起。如果某些请求需要较长时间才能完成下载或处理,而在此期间新的请求不断被添加到队列中,就会导致堆积的情况。这可能是由于目标网站的响应时间较慢、Scrapy设置的下载延迟较低或数据处理过程较为耗时等原因引起的。
- 并发设置不合理:Scrapy的并发设置可能会影响请求和数据项的堆积情况。如果并发设置过高,则会导致过多的请求同时发送和处理,可能会造成请求堆积。相反,如果并发设置过低,则处理速度可能无法跟上请求的生成速度,也会导致请求和数据项的堆积。
- 资源限制:Scrapy运行的系统资源限制(例如CPU、内存、网络带宽等)也可能是问题的原因。如果系统资源不足,Scrapy无法及时处理请求和数据项,导致堆积的情况发生。
剖析+解决:
既然已经知道了,可能是这4项解决影响的;那么怎么解决他们呢?
答:
爬虫逻辑问题:
- 仔细检查爬虫代码并进行逐行调试,查找可能导致请求堆积的逻辑错误。
- 检查条件判断和循环语句是否正确,确保它们能够正常终止和跳出。
- 确保在处理响应或生成请求时,正确地使用回调函数和管道等Scrapy机制。
下载或处理延迟:
- 增加下载延迟(DOWNLOAD_DELAY),使得请求之间有较长的时间间隔。
- 检查和优化爬虫中的数据处理过程,确保它们能够高效地处理数据项。
- 调整Scrapy的并发设置,适当限制同时发送和处理的请求数量。
并发设置不合理:
- 调整Scrapy的并发设置,适当增加并发请求和并发处理的数量,以提高处理能力。
- 分析系统资源使用情况,确保调整后的并发设置不会超出系统资源的限制。
- 根据目标网站的响应速度和服务器负载情况,动态调整并发设置。
资源限制:
- 增加系统资源,例如更强大的计算机、更高带宽的网络连接等。这样可以提供更多的处理能力以减轻请求堆积的压力。
- 使用分布式架构,如Scrapy-Redis或Scrapyd,将任务分发到多个节点上进行处理,以扩展处理能力。
- 优化爬虫代码和数据处理过程,提高其效率以减少资源占用。
问题通治法:
1. 增加并发限制:检查Scrapy的并发设置,例如`CONCURRENT_REQUESTS`和`CONCURRENT_ITEMS`。你可以尝试增加这些设置的值,以允许更多的同时请求和处理,从而减少请求和数据项的堆积。不过,你需要根据自己的网络和系统资源进行适当的调整,避免对服务器和网络造成过大的压力。
细讲:
- 打开Scrapy项目的设置文件(通常是settings.py),找到并发设置的相关项,例如CONCURRENT_REQUESTS和CONCURRENT_ITEMS。
- 增加这些设置的值,以允许更多的同时请求和处理。例如,将CONCURRENT_REQUESTS设置为10,CONCURRENT_ITEMS设置为100。
# settings.py
CONCURRENT_REQUESTS = 10
CONCURRENT_ITEMS = 100
2. 调整下载延迟:如果请求过多导致了堆积,你可以尝试调整下载延迟。通过增加`DOWNLOAD_DELAY`设置的值,可以让Scrapy在发送请求之间增加延迟,以减缓请求速率,防止过快地发送请求。这样有助于控制请求的堆积情况。
- 在Scrapy项目的设置文件中找到DOWNLOAD_DELAY设置项。
- 增加DOWNLOAD_DELAY的值,以减慢请求的发送速率。例如,将DOWNLOAD_DELAY设置为2秒。
# settings.py
DOWNLOAD_DELAY = 2
3. 优化爬虫逻辑:检查你的爬虫逻辑,确保它们高效而无死循环。确保你所写的爬虫逻辑能够在合理的时间内处理请求和数据项,不会由于错误的逻辑导致大量的堆积。
- 检查你的爬虫逻辑,确保它们高效而无死循环。
- 确保你的代码在处理每个请求时能够合理地执行必要的操作,而不会导致过度延迟或占用过多资源。
4. 使用分布式爬虫或调度器:如果以上方法无法解决问题,可以考虑使用分布式爬虫框架,如Scrapy-Redis或Scrapyd,以分散请求和数据项的处理负载。这样可以将请求和数据项分发到多个爬虫节点进行处理,从而减轻单个Scrapy进程的压力。
5. 调整资源配置:检查你的系统资源配置,确保Scrapy运行时有足够的CPU、内存和网络带宽。如果你的系统资源不足,可能会导致请求和数据项积压的问题。
总结:
在我们的Scrapy世界中,当遇到请求堆积和数据项积压的问题时,我们需要像一名智慧医生一样,找出病因并施以治疗。
首先,爬虫逻辑问题就像是食道中的狭窄,导致食物无法顺利通过。我们需要检查代码,确保没有死循环的陷阱,并确保正确处理返回的响应,避免请求不断堆积在那里。
其次,下载延迟问题就像是吞咽过快,导致食物堆积在胃里。调整下载延迟就像是调整我们的吃饭速度,减慢发送请求的速率,让Scrapy有足够的时间处理已下载的数据。
并发设置不合理就像是刚开的高速公路上交通堵塞。我们需要合理调整并发设置,增加交通流量的容量,使更多的请求能够顺畅通过。
最后,资源限制就像是我们缺乏能量和力量来处理大量请求和数据项。我们需要增加系统资源,就像补充营养和锻炼身体一样,让Scrapy拥有更强的处理能力。
通过综合利用这些治疗方法,就像一名医生调配药方一样,我们可以很好地解决Scrapy中的请求和数据项堆积问题,让我们的爬虫在网络世界中自由畅行。
相关文章:
爬虫工作量由小到大的思维转变---<第二十三章 Scrapy开始很快,越来越慢(医病篇)>
诊断篇https://blog.csdn.net/m0_56758840/article/details/135170994?ops_request_misc%257B%2522request%255Fid%2522%253A%2522170333243316800180644102%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id1703332433168001806441…...
.Net7.0 或更高版本 System.Drawing.Common 上传图片跨平台方案
项目升级.Net7.0以后,System.Drawing.Common开关已经被删除,且System.Drawing.Common仅在 Windows 上支持 ,于是想办法将原来上传图片验证文件名和获取图片扩展名方法替换一下,便开始搜索相关解决方案。 .Net6.0文档:…...

【MySQL】InnoDB和MyISAM区别
文章目录 一、索引不同1 InnoDB聚簇索引,MyISAM非聚簇索引1 InnoDB聚簇索引2 MyISAM非聚簇索引 2 InnoDB必须要有主键,MyISAM允许没有主键3 InnoDB支持外键4 InnoDB不支持全文索引5 索引保存位置不同 二、对事物的支持三、存储结构不同四、存储空间不同五…...

3分钟了解安全数据交换系统有什么用!
企业为了保护核心数据安全,都会采取一些措施,比如做网络隔离划分,分成了不同的安全级别网络,或者安全域,接下来就是需要建设跨网络、跨安全域的安全数据交换系统,将安全保障与数据交换功能有机整合在一起&a…...
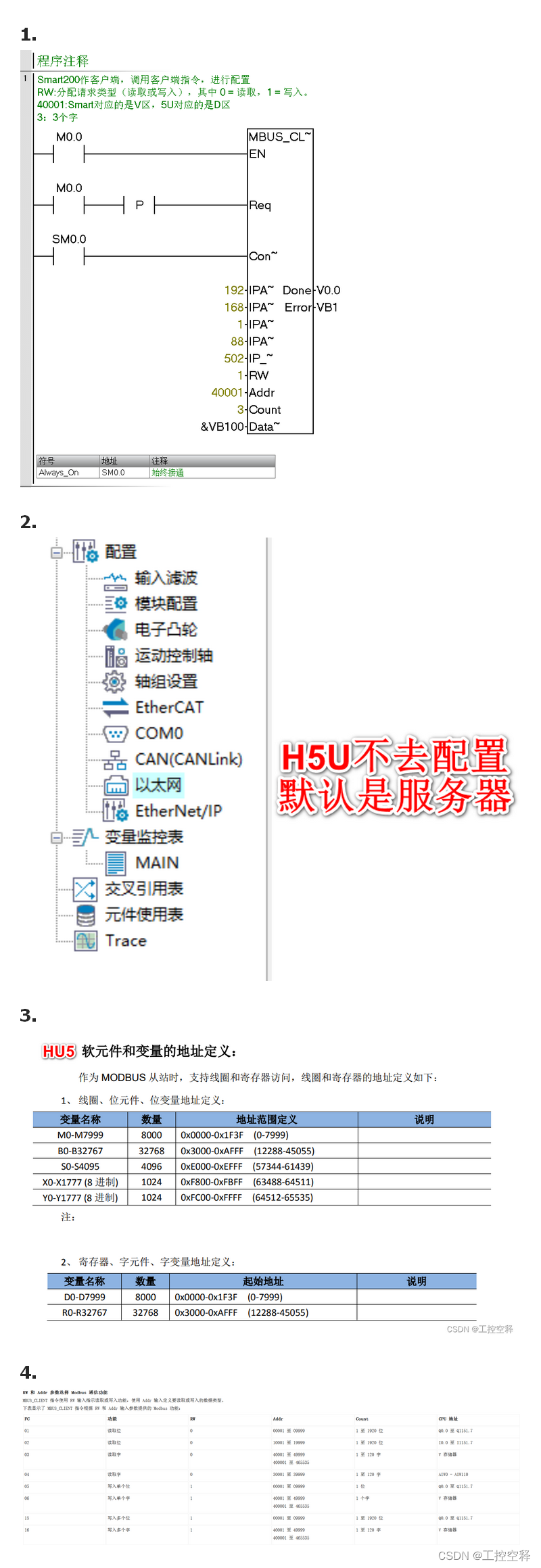
记录汇川:MODBUS TCP-梯形图
H5U的MODBUS通信不需要编写程序,通过组态MODBUS通信配置表,实现数据通信。 Modbus-TCP 主站即Modbus-TCP客户端,通过Modbus-TCP配置,可最多支持同时与31个 Modbus-TCP服务器(从站)进行通讯。 …...

electron + sqlite3 解决打包后无法写入数据库
前言 window环境。 electron28.0.0 sqlite35.1.6 使用 electron-builder 打包。 本文旨在解决打包后无法写入数据库的问题。 但如果你是打包后无法访问sqlite,且有报错弹窗,不妨也看看本文。 也许是同一种原因。 错误原因分析 打包后无法创建db文件&…...

【uniapp小程序-生成二维码+多个图片文字合并一张图】
<!-- 二维码 --><canvas id"qrcode" canvas-id"qrcode" width"120" ></canvas><!-- 生成带小程序码的分享图片 --><canvas canvas-id"shareCanvas" class"share-canvas"></canvas>#qrc…...
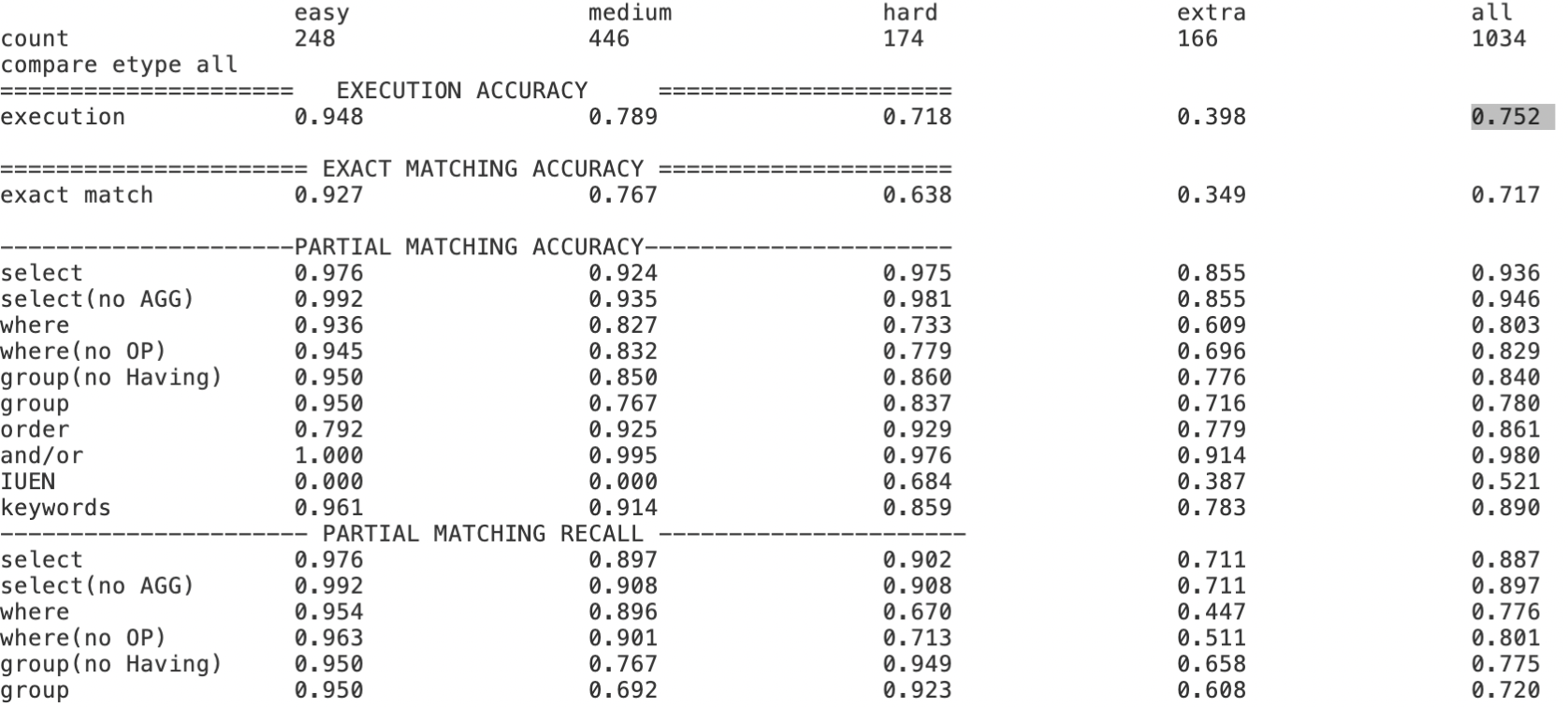
Text-to-SQL小白入门(十)RLHF在Text2SQL领域的探索实践
本文内容主要基于以下开源项目探索实践, Awesome-Text2SQL:GitHub - eosphoros-ai/Awesome-Text2SQL: Curated tutorials and resources for Large Language Models, Text2SQL, Text2DSL、Text2API、Text2Vis and more.DB-GPT-Hub:GitHub - eosphoros-ai…...
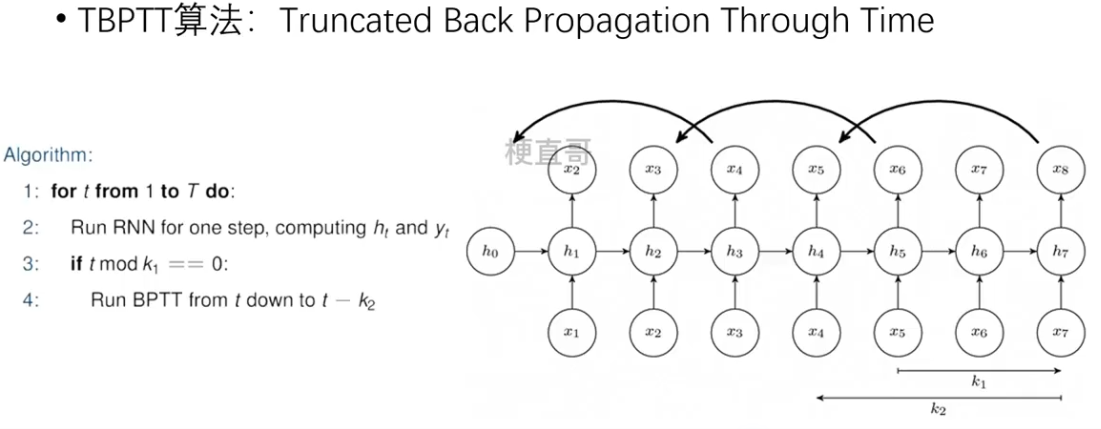
深度学习 | 基本循环神经网络
1、序列建模 1.1、序列数据 序列数据 —— 时间 不同时间上收集到的数据,描述现象随时间变化的情况。 序列数据 —— 文本 由一串有序的文本组成的序列,需要进行分词。 序列数据 —— 图像 有序图像组成的序列,后一帧图像可能会受前一帧的影响…...

VSCode 加Cortex-Debug嵌入式调试方法
简介 当使用ARM Cortex-M微控制器时,Cortex-Debug是一个Visual Studio Code的扩展,以简化调试过程。本文档介绍了如何编写启动配置(launch.json)。 settings.json配置 打开VSCode用户设置文件settings.json: 文件→偏好→设置选择用户设置: 在搜索栏中…...
etcd-workbench一款免费好用的ETCD客户端,支持SSHTunnel、版本对比等功能
介绍 今天推荐一款完全免费的ETCD客户端,可以私有化部署: etcd-workbench 开源地址:https://github.com/tzfun/etcd-workbench Gitee地址:https://gitee.com/tzfun/etcd-workbench 下载 本地运行 从 官方Release 下载最新版的 jar 包&am…...

华为ipv6配置之ospf案例
R1 ipv6 ospfv3 1 router-id 1.1.1.1 //必须要手动配置ospf id,它不会自动生成 interface GigabitEthernet0/0/0 ipv6 enable ipv6 address 2000::2/96 ospfv3 1 area 0.0.0.0 interface LoopBack0 ipv6 enable ipv6 address 2001::1/96 ospfv3 1 area 0.0.0.0 R2…...

Design patterns--装饰模式
设计模式之装饰模式 使用装饰模式来封装Nmea0183语句。 代码 #ifndef DATAPARSER_H #define DATAPARSER_H#include <string> #include <vector>class DataParser { public:DataParser();virtual std::string fieldAnalysis(std::vector<std::string> vecSt…...
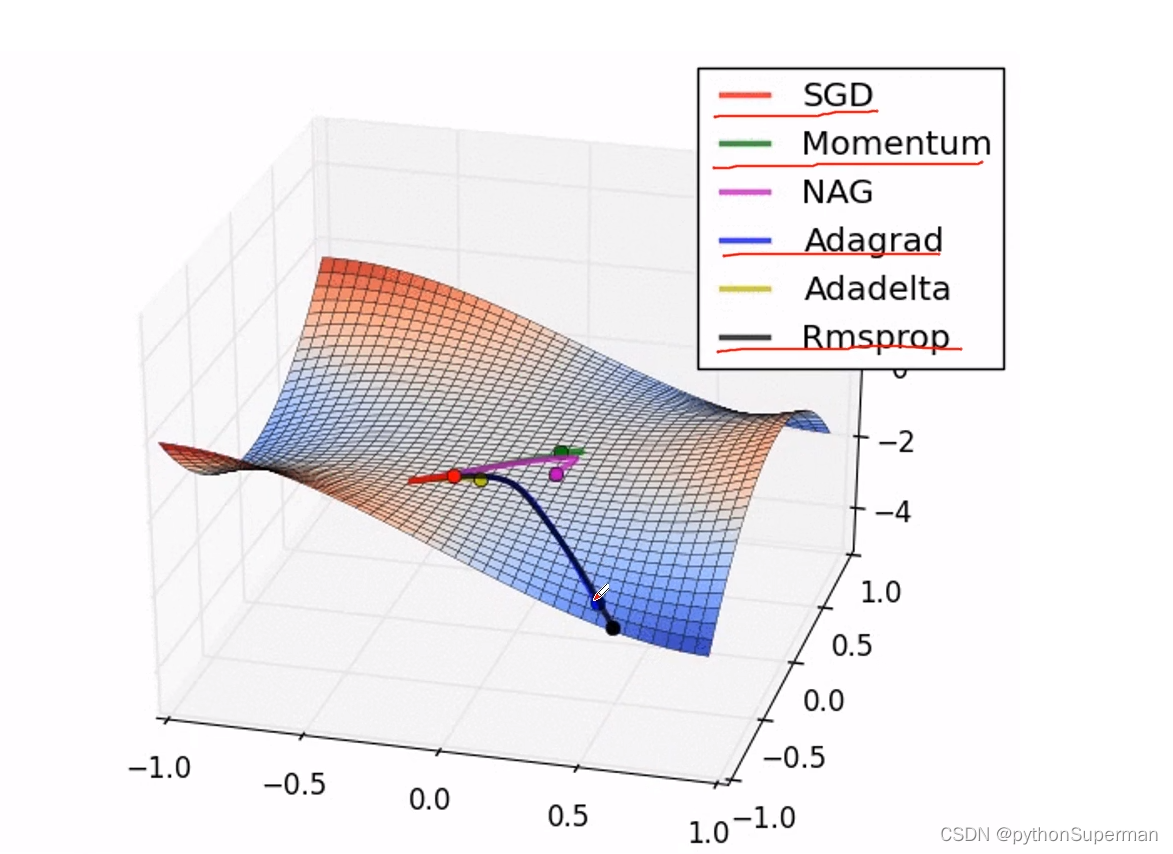
卷积神经网络 反向传播
误差的计算 softmax 经过softmax处理后所有输出节点概率和为1 损失(激活函数) 多分类问题:输出只可能归于某一个类别,不可能同时归于多个类别。 误差的反向传播 求w的误差梯度 权值的更新...

java面试题20
Java中的类加载机制可继续通过自定义类加载器来实现热部署、插件化和动态加载等功能,使得应用程序能够在运行时加载未知的类和资源。 什么是Java中的多线程(Multithreading)?它有什么作用? 答案:多线程是一…...

【Java面试题】redis的过期策略有哪些
redis通过设置过期时间来控制键值对的存活时长,过期时间可以通过expire , pexpire expireat , pexpireat 等命令设置,String 类型数据可以通过setex命令设置过期时间。 以下介绍三种redis的过期策略: 1. 定时删除 在设置键值对的过期时…...

for参数 命令语句 变量
for 参数f skip命令语句 命令说明: 跳过文本内容(行):skip 例子: for /f "skip1" %%i in(2.txt) do echo %%i for 参数f eol命令语句 命令说明: 怱略指定字符的文本内容(文本首部…...

CentOS 8的新特性
CentOS 8在2019年发布,带来了比CentOS 7更多的新特性和改进。以下是一些主要的变化和优化: 软件包更新:CentOS 8提供了更新的软件包和程序,包括但不限于Python 3、MySQL 8、PHP 7.2、Ruby 2.5、PostgreSQL 10等。 应用流…...

vue2、vue3状态管理之vuex、pinia
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、状态管理之vuex1.1 State调用:1.2 Mutation在vuex中定义:在组件中使用: 1.3 Action在vuex中定义:将上面的减…...
axios进行图片上传组件封装
文章目录 前言图片上传接口(axios通信)图片上传使用upload上传头像效果展示总结 前言 node项目使用 axios 库进行简单文件上传的模块封装。 图片上传接口(axios通信) 新建upload.js文件,定义一个函数,该函数接受一个上传路径和一…...

答辩前一天才慌?paperxie 帮我把毕业论文 PPT 的 “地狱副本” 打成了 “新手教程”
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ppt/createhttps://www.paperxie.cn/ppt/create 距离本科毕业论文答辩只剩 3 天,我对着空白的 PPT 页面,第 10 次删掉了刚写好的标题。 导师说我的内…...

对比官方原价Taotoken活动价带来的Token成本优化感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比官方原价与Taotoken活动价带来的Token成本优化感受 1. 引言:开发者视角下的模型调用成本 对于频繁使用大模型API进…...

Scratch 画笔模块全解析:从零到一绘制动态轨迹
1. 初识Scratch画笔模块:数字画布的神奇魔法 第一次接触Scratch的画笔功能时,我仿佛回到了小时候拿着彩色粉笔在水泥地上涂鸦的快乐时光。这个看似简单的模块,实际上藏着让角色"留下痕迹"的魔法——就像蜗牛爬过会留下闪亮的黏液轨…...

CP2K实战指南:CUTOFF与REL_CUTOFF参数的系统化调优策略
1. 理解CUTOFF与REL_CUTOFF的核心作用 刚开始用CP2K做材料计算时,最让我头疼的就是MGRID里这两个参数。记得第一次跑硅晶体能量优化,结果比文献值差了近10%,导师指着屏幕问:"你的网格精度设对了吗?"当时真是…...

5分钟学会:用SlopeCraft制作惊艳的Minecraft立体地图画终极指南
5分钟学会:用SlopeCraft制作惊艳的Minecraft立体地图画终极指南 【免费下载链接】SlopeCraft Map Pixel Art Generator for Minecraft 项目地址: https://gitcode.com/gh_mirrors/sl/SlopeCraft 你是否曾想将心爱的照片或艺术作品变成Minecraft世界中的立体艺…...

STM32CUBEMX+Keil AC6编译提速实战:解决LWIP和绝对地址警告的坑
STM32CUBEMXKeil AC6编译提速实战:解决LWIP和绝对地址警告的坑 当STM32开发者从Keil AC5编译器切换到AC6时,往往会遇到两个典型问题:LWIP编译错误和绝对地址警告。本文将深入分析这些问题的根源,并提供经过验证的解决方案…...

Qt C++ 集成 SQLite 实现本地数据持久化:从原理到宠物投喂器实战
1. 项目概述与核心需求解析最近在做一个宠物智能投喂器的数据管理后台,核心需求是把设备上传的各种运行数据持久化存储起来,方便后续分析和查看。设备会上传投喂间隔时间、水温、剩余重量这几个关键参数,我需要一个轻量、可靠且易于集成的本地…...

STM32串口调试玄学翻车?从XCOM 2.3到2.0的降级避坑实录
STM32串口调试的版本陷阱:当XCOM 2.3让你的开发板"沉默"时 调试嵌入式系统时,最令人抓狂的莫过于硬件一切正常,代码毫无问题,但串口就是拒绝工作。最近在STM32F103ZET6开发板上遇到了一个诡异现象:同一块板子…...

5步掌握AlienFX Tools:开源Alienware控制的终极指南
5步掌握AlienFX Tools:开源Alienware控制的终极指南 【免费下载链接】alienfx-tools Alienware systems lights, fans, and power control tools and apps 项目地址: https://gitcode.com/gh_mirrors/al/alienfx-tools 厌倦了Alienware Command Center&#…...

Keil C编译器字符串常量合并机制与内存优化
1. Keil C编译器中的字符串常量合并机制解析在嵌入式开发中,内存优化是一个永恒的话题。Keil C编译器(包括C51、C166和C251版本)提供了一项智能特性——自动合并重复的字符串常量。这个功能看似简单,但对资源受限的嵌入式系统而言…...