Hive和Spark生产集群搭建(spark on doris)
1.环境准备
1.1 版本选择
| 序号 | bigdata-001 | bigdata-002 | bigdata-003 | bigdata-004 | bigdata-005 |
|---|---|---|---|---|---|
| MySQL-8.0.31 | mysql | ||||
| Datax | Datax | Datax | Datax | Datax | Datax |
| Spark-3.3.1 | Spark | Spark | Spark | Spark | Spark |
| Hive-3.1.3 | Hive | Hive |
1.2 主要组件官网
hive官网: https://hive.apache.org/
hive安装包下载:http://archive.apache.org/dist/hive/
spark官网:https://spark.apache.org/
spark安装包下载:https://www.apache.org/dyn/closer.lua/spark/spark-3.3.1/
注意:官网下载的Hive3.1.3和Spark3.3.1默认是不兼容的。因为Hive3.1.3支持的Spark版本是2.4.5,所以需要我们重新编译Hive3.1.3版本。
Hadoop环境安装详见本博客最全Hadoop实际生产集群高可用搭建
2.Hive安装部署
2.1 环境配置
- 解压apache-hive-3.1.3-bin.tar.gz到/data/module/目录下面
[hadoop@hadoop1 software]$ tar -zxvf /data/software/apache-hive-3.1.3-bin.tar.gz -C /data/module/
- 修改apache-hive-3.1.3-bin.tar.gz的名称为hive
[hadoop@hadoop1 software]$ mv /data/module/apache-hive-3.1.3-bin/ /data/module/hive-3.1.3
- 修改/etc/profile.d/my_env.sh,添加环境变量
[hadoop@hadoop1 software]$ sudo vim /etc/profile.d/my_env.sh
- 添加内容
#HIVE_HOME
export HIVE_HOME=/data/module/hive-3.1.3
export PATH=$PATH:$HIVE_HOME/bin
export PATH JAVA_HOME HADOOP_HOME HIVE_HOME
2.2 Hive元数据配置到MySQL
- 拷贝mysql的jdbc驱动(mysql-connector-java-5.1.48.jar)到hive的lib目录下
[hadoop@hadoop1 software]$ cp /data/software/mysql-connector-java-5.1.48.jar $HIVE_HOME/lib
- 配置Metastore到MySql
在$HIVE_HOME/conf目录下新建hive-site.xml文件
[hadoop@hadoop1 software]$ vim $HIVE_HOME/conf/hive-site.xml
添加如下内容
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><!-- jdbc连接的URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://xxx:3306/metastore?useSSL=false&createDatabaseIfNotExist=true&characterEncoding=UTF-8</value>
</property><!-- jdbc连接的Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value>
</property><!-- jdbc连接的username--><property><name>javax.jdo.option.ConnectionUserName</name><value>xxx</value></property><!-- jdbc连接的password --><property><name>javax.jdo.option.ConnectionPassword</name><value>xxx</value>
</property><!-- Hive默认在HDFS的工作目录 --><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><!-- Hive元数据存储的验证 --><property><name>hive.metastore.schema.verification</name><value>false</value></property>
<!-- hive表元数据读取不到--><property><name>metastore.storage.schema.reader.impl</name><value>org.apache.hadoop.hive.metastore.SerDeStorageSchemaReader</value></property><!-- 元数据存储授权 --><property><name>hive.metastore.event.db.notification.api.auth</name><value>false</value>
</property>
<!-- 打印当前库和表头 -->
<property><name>hive.cli.print.header</name><value>true</value>
</property>
<property><name>hive.cli.print.current.db</name><value>true</value>
</property>
<!-- 指定存储元数据要连接的地址 --><property><name>hive.metastore.uris</name><value>thrift://xxx:9083,thrift://xxx1:9083</value></property>
<!-- 指定hiveserver2连接的host --><property><name>hive.server2.thrift.bind.host</name><value>xxx</value></property><!-- 指定hiveserver2连接的端口号 --><property><name>hive.server2.thrift.port</name><value>10000</value></property><property>
<name>hive.server2.enable.doAs </name>
<value>false</value>
</property><!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property><name>spark.yarn.jars</name><value>hdfs://hadoopcluster/spark-jars/*</value>
</property><!--Hive执行引擎-->
<property><name>hive.execution.engine</name><value>spark</value>
</property>
<!--配置动态分配spark资源-->
<property><name>spark.dynamicAllocation.enabled</name><value>true</value>
</property>
<!--Hive和Spark连接超时时间-->
<property><name>hive.spark.client.connect.timeout</name><value>100000ms</value>
</property><property><name>hive.zookeeper.client.port</name><value>2181</value></property><property><name>hive.zookeeper.quorum</name><value>xxxxx</value></property><property><name>hive.server2.support.dynamic.service.discovery</name><value>true</value>
</property><property><name>hive.server2.zookeeper.namespace</name><value>hiveserver2_zk</value>
</property><!--
<property><name>hive.exec.post.hooks</name><value>org.apache.atlas.hive.hook.HiveHook</value>
</property>
-->
<!--hiveserver2启动等待时间-->
<property><name>hive.server2.sleep.interval.between.start.attempts</name><value>2s</value><description>Expects a time value with unit (d/day, h/hour, m/min, s/sec, ms/msec, us/usec, ns/nsec), which is msec if not specified.The time should be in between 0 msec (inclusive) and 9223372036854775807 msec (inclusive).Amount of time to sleep between HiveServer2 start attempts. Primarily meant for tests</description></property>
<!--不显示 info 信息-->
<property><name>hive.server2.logging.operation.enabled</name><value>false</value>
</property>
<!--<property><name>hive.tez.container.size</name><value>10240</value>
</property><property><name>hive.server2.enable.doAs</name><value>true</value>
</property>
-->
<property><name>hive_timeline_logging_enabled</name><value>true</value>
</property><!--添加钩子,采集数据到tez-ui -->
<!--
<property><name>hive.exec.failure.hooks</name><value>org.apache.hadoop.hive.ql.hooks.ATSHook</value></property>
<property><name>hive.exec.post.hooks</name><value>org.apache.hadoop.hive.ql.hooks.ATSHook</value></property><property><name>hive.exec.pre.hooks</name><value>org.apache.hadoop.hive.ql.hooks.ATSHook</value></property>
-->
<property><name>hive.reloadable.aux.jars.path</name><value>/data/module/hive-3.1.3/jars</value>
</property><!--配置hiveserver2密码验证 -->
<!--
<property><name>hive.security.authorization.enabled</name><value>true</value>
</property><property><name>hive.server2.authentication</name><value>CUSTOM</value>
</property>
-->
<!--这是hive超级用户 -->
<property><name>hive.users.in.admin.role</name><value>hadoop</value>
</property>
</configuration>
2.3 初始化元数据库
- 登陆MySQL
[hadoop@hadoop1 software]$ mysql -uroot -pxxx
- 新建Hive元数据库
mysql> create database metastore;
mysql> quit;
- 初始化Hive元数据库
[hadoop@hadoop1 software]$ schematool -initSchema -dbType mysql -verbose
4) 修改元数据库字符集
Hive元数据库的字符集默认为Latin1,由于其不支持中文字符,故若建表语句中包含中文注释,会出现乱码现象。如需解决乱码问题,须做以下修改。
修改Hive元数据库中存储注释的字段的字符集为utf-8
//字段注释
mysql> alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
//表注释
mysql> alter table TABLE_PARAMS modify column PARAM_VALUE mediumtext character set utf8;
//退出
quit;
- hadoop的配置文件core-site.xml和hdfs-site.xml复制到hive的conf中
2.4 启动metastore和hiveserver2
- 启动hiveserver2
[hadoop@hadoop1 hive]$ bin/hive --service hiveserver2
- 启动beeline客户端(需要多等待一会)
[hadoop@hadoop1 hive]$ bin/beeline -u jdbc:hive2://hadoop1:10000 -n hadoop
- 看到如下界面
Connecting to jdbc:hive2://hadoop1:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.2 by Apache Hive
0: jdbc:hive2://hadoop1:10000>
3.Spark安装
3.1 解压缩文件
将spark-3.3.1-bin-hadoop3.tgz文件上传到Linux并解压缩,放置在指定位置,路径中不要包含中文或空格
tar -zxvf spark-3.3.1-bin-hadoop3.tgz -C /data/module
cd /data/module
mv spark-3.3.1-bin-hadoop3.2 spark-3.3.1
3.2 启动环境
1)进入解压缩后的路径,执行如下指令
bin/spark-shell
- 启动成功后,可以输入网址进行Web UI监控页面访问
http://hadoop1:4040
3.3 Hive on Spark配置
3.3.1 配置SPARK_HOME环境变量
[hadoop@hadoop1 software]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容
# SPARK_HOME
export SPARK_HOME=/data/module/spark-3.3.1
export PATH=$PATH:$SPARK_HOME/bin
source 使其生效
[hadoop@hadoop1 software]$ source /etc/profile.d/my_env.sh
3.3.2 创建spark配置文件并复制到hive中
[hadoop@hadoop1 software]$ vim /data/module/spark-3.3.1
/conf/spark-defaults.conf
添加如下内容(在执行任务时,会根据如下参数执行)
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://yourhadoopcluster/spark-history
spark.executor.cores 1
spark.executor.memory 4g
spark.executor.memoryOverhead 2g
spark.driver.memory 4g
spark.driver.memoryOverhead 2g
spark.dynamicAllocation.enabled true
spark.shuffle.service.enabled true
spark.dynamicAllocation.executorIdleTimeout 60s
spark.dynamicAllocation.initialExecutors 1
spark.dynamicAllocation.minExecutors 1
spark.dynamicAllocation.maxExecutors 12
spark.dynamicAllocation.schedulerBacklogTimeout 1s
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout 5s
spark.dynamicAllocation.cachedExecutorIdleTimeout 30s
spark.shuffle.useOldFetchProtocol true
spark.history.fs.cleaner.enabled true
spark.history.fs.cleaner.interval 1d
spark.history.fs.cleaner.maxAge 7d
spark.hadoop.orc.overwrite.output.file true
spark.executor.extraJavaOptions=-Dfile.encoding=UTF-8 -Dsun.jnu.encoding=UTF-8
spark.driver.extraJavaOptions=-Dfile.encoding=UTF-8 -Dsun.jnu.encoding=UTF-8
在HDFS创建如下路径,用于存储历史日志
[hadoop@hadoop1 software]$ hadoop fs -mkdir /spark-history
3.3.4 向HDFS上传Spark纯净版jar包
说明1:由于Spark3.3.1非纯净版默认支持的是hive2.3.7版本,直接使用会和安装的Hive3.1.2出现兼容性问题。所以采用Spark纯净版jar包,不包含hadoop和hive相关依赖,避免冲突。
说明2:Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到。
① 上传并解压spark-3.3.1-bin-without-hadoop.tgz
[hadoop@hadoop1 software]$ tar -zxvf /data/software/spark-3.3.1-bin-without-hadoop.tgz
② 上传Spark纯净版jar包到HDFS
[hadoop@hadoop1 software]$ hadoop fs -mkdir /spark-jars[hadoop@hadoop1 software]$ hadoop fs -put spark-3.3.1-bin-without-hadoop/jars/* /spark-jarscp /data/module/spark-3.3.1/yarn/spark-3.3.1-yarn-shuffle.jar /data/module/hadoop-3.3.4/share/hadoop/yarn/lib/
6)将spark的jar包拷贝到yarn中
cp /data/module/spark-3.3.1/yarn/spark-3.3.1-yarn-shuffle.jar /data/module/hadoop-3.3.4/share/hadoop/yarn/lib/
3.3.5 修改hive-site.xml文件(以上已配置)
[hadoop@hadoop1 ~]$ vim /data/module/hive/conf/hive-site.xml
添加如下内容
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property><name>spark.yarn.jars</name><value>hdfs://xxx:8020/spark-jars/*</value>
</property><!--Hive执行引擎-->
<property><name>hive.execution.engine</name><value>spark</value>
</property>
3.3.6 spark-sql操作doris
下载git代码库的spark代码:https://github.com/apache/doris-spark-connector
按照readme介绍打包自己的适配版连接器jar包
将jar包复制到spark的jars目录下,同时hdfs上的spark包目录也上传一份
cp /your_path/spark-doris-connector/target/spark-doris-connector-3.1_2.12-1.0.0-SNAPSHOT.jar $SPARK_HOME/jars
hadoop fs -put /your_path/spark-doris-connector/target/spark-doris-connector-3.1_2.12-1.0.0-SNAPSHOT.jar /spark-jars
运行spark-sql 测试:
//测试
CREATE
TEMPORARY VIEW spark_doris1
USING doris
OPTIONS('table.identifier'='demo.t1','fenodes'='xxx:8030','user'='xxx','password'='xxx'
);
CREATE
TEMPORARY VIEW spark_doris2
USING doris
OPTIONS('table.identifier'='demo.t2','fenodes'='xxx:8030','user'='xxx','password'='xxx'
);INSERT INTO spark_doris1
select * from spark_doris2;
相关文章:
)
Hive和Spark生产集群搭建(spark on doris)
1.环境准备 1.1 版本选择 序号bigdata-001bigdata-002bigdata-003bigdata-004bigdata-005MySQL-8.0.31mysqlDataxDataxDataxDataxDataxDataxSpark-3.3.1SparkSparkSparkSparkSparkHive-3.1.3HiveHive 1.2 主要组件官网 hive官网: https://hive.apache.org/ hive…...
VuePress、VuePress-theme-hope 搭建个人博客 1【快速上手】 —— 防止踩坑篇
vuePress官网地址 👉 首页 | VuePress 手动安装 这一章节会帮助你从头搭建一个简单的 VuePress 文档网站。如果你想在一个现有项目中使用 VuePress 管理文档,从步骤 3 开始。 步骤 1: 创建并进入一个新目录 mkdir vuepress-starter cd vuepress-star…...
数据类型-复合类型)
【PostgreSQL】从零开始:(三十一)数据类型-复合类型
复合类型 复合类型是一种由其他类型组成的类型。它可以是数组、结构体、联合体或指向这些类型的指针。复合类型允许将多个值组合成单个实体,以便更方便地处理和使用。复合类型在C语言中非常常见,用于表示复杂的数据结构和组织数据的方式。 数组是一种由…...
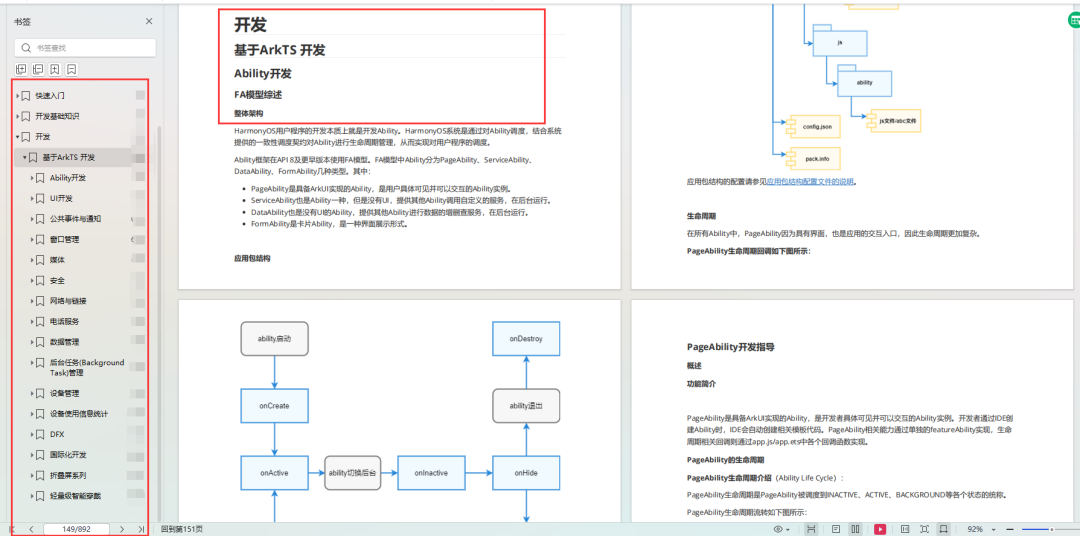
基于鸿蒙OS开发一个前端应用
创建JS工程:做鸿蒙应用开发到底学习些啥? 若首次打开DevEco Studio,请点击Create Project创建工程。如果已经打开了一个工程,请在菜单栏选择File > New > Create Project来创建一个新工程。选择HarmonyOS模板库,…...
PIC单片机项目(7)——基于PIC16F877A的智能灯光设计
1.功能设计 使用PIC16F877A单片机,检测环境关照,当光照比阈值低的时候,开灯。光照阈值可以通过按键进行设置,同时阈值可以保存在EEPROM中,断电不丢失。使用LCD1602进行显示,第一行显示测到的实时光照强度&a…...
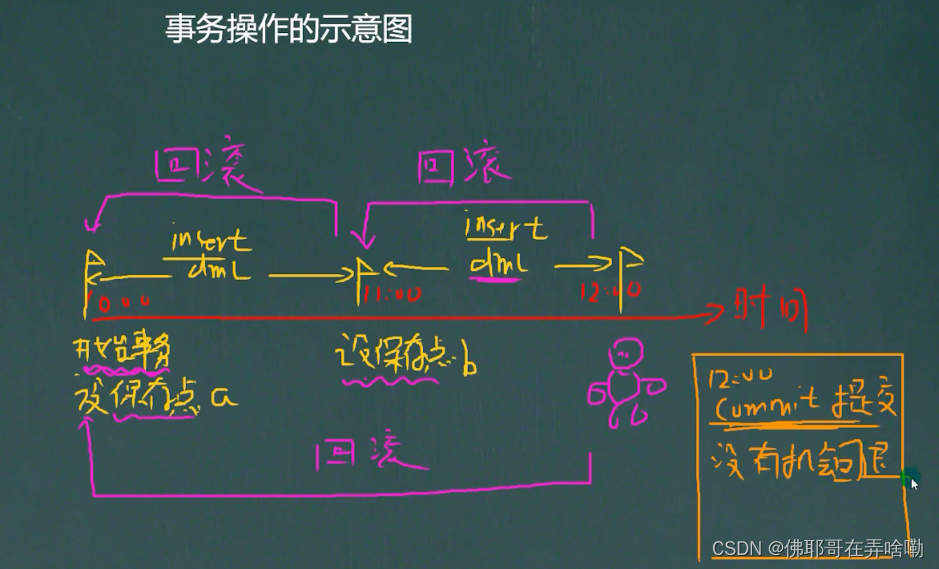
Mysql For Navicate (老韩)
Navicate创建数据库 先创建一个数据库;然后在数据库中创建一张表;在表格当中填入相应的属性字段;打开表, 然后填入相应的实例字段; – 使用数据库图形化App和使用指令来进行操作各有各的好处和利弊; 数据库的三层结构(破除MySQL神秘) 所谓安装Mysql数据库, 就是在主机安装一…...

设计模式之-建造者模式通俗易懂理解,以及建造者模式的使用场景和示列代码
系列文章目录 设计模式之-6大设计原则简单易懂的理解以及它们的适用场景和代码示列 设计模式之-单列设计模式,5种单例设计模式使用场景以及它们的优缺点 设计模式之-3种常见的工厂模式简单工厂模式、工厂方法模式和抽象工厂模式,每一种模式的概念、使用…...

Redis分布式锁进阶源码分析
Redis分布式锁进阶源码分析 1、如何写一个商品秒杀代码?2、加上Java锁3、使用redis setnx命令获取锁4、增加try和finally5、给锁设置过期时间6、增长过期时间,并setnx增加唯一value7、使用redisson8、源码分析a、RedissonLock.tryLockInnerAsyncb、Redis…...
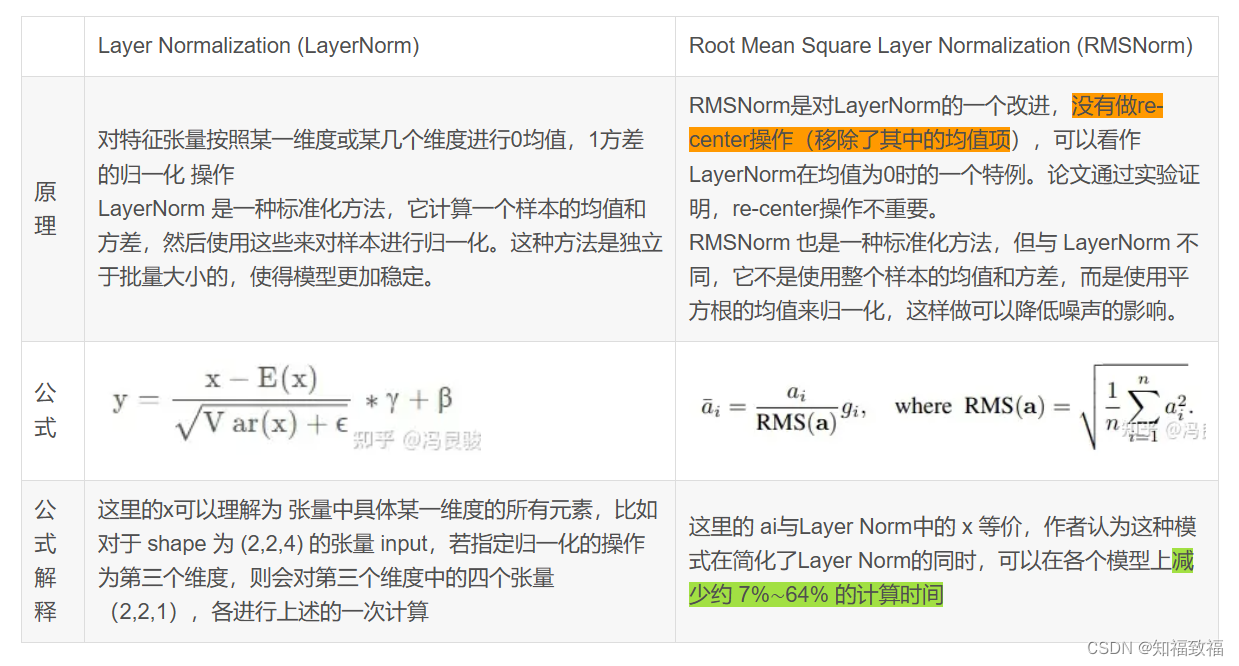
lag-llama源码解读(Lag-Llama: Towards Foundation Models for Time Series Forecasting)
Lag-Llama: Towards Foundation Models for Time Series Forecasting 文章内容: 时间序列预测任务,单变量预测单变量,基于Llama大模型,在zero-shot场景下模型表现优异。创新点,引入滞后特征作为协变量来进行预测。 获得…...

Three.js基础入门介绍——Three.js学习三【借助控制器操作相机】
在Three.js基础入门介绍——Three.js学习二【极简入门】中介绍了如何搭建Three.js开发环境并实现一个包含旋转立方体的场景示例,以此为前提,本篇将引进一个控制器的概念并使用”轨道控制器”(OrbitControls)来达到从不同方向展示场…...

【日志系列】什么是分布式日志系统?
✔️什么是分布式日志系统? 现在,很多应用都是集群部署的,一次请求会因为负载均衡而被路由到不同的服务器上面,这就导致一个应用的日志会分散在不同的服务器上面。 当我们要向通过日志做数据分析,问题排查的时候&#…...

[卷积神经网络]FCOS--仅使用卷积的Anchor Free目标检测
项目源码: FCOShttps://github.com/tianzhi0549/FCOS/ 一、概述 作为一种Anchor Free的目标检测网络,FCOS并不依赖锚框,这点类似于YOLOx和CenterNet,但CenterNet的思路是寻找目标的中心点,而FCOS则是寻找每个像素点&…...

Ubuntu fcitx Install
ubuntu经常出现键盘失灵的问题 查询资料得知应该是Ibus框架的问题 于是需要安装fcitx框架和搜狗拼音 sudo apt update sudo apt install fcitx 设置fcitx开机自启动(建议) sudo cp /usr/share/applications/fcitx.desktop /etc/xdg/autostart/ 然后…...

【Makefile/GNU Make】知识总结
文章目录 1. 总体认识2. 编写Makefile2.1. Makefile的组成2.2. Makefile文件名2.3. 包含其他Makefile 3. 编写规则4. 编写规则中的构建命令5. 如何使用变量6. 条件判断7. 转换文本的函数8. 如何运行make9. 使用模糊规则10. 使用make来更新存档文件11. 扩展GNU make12. 集成GNU …...

腾讯云轻量服务器和云服务器CVM该怎么选?区别一览
腾讯云轻量服务器和云服务器CVM该怎么选?不差钱选云服务器CVM,追求性价比选择轻量应用服务器,轻量真优惠呀,活动 https://curl.qcloud.com/oRMoSucP 轻量应用服务器2核2G3M价格62元一年、2核2G4M价格118元一年,540元三…...
MySQL定时备份实现
一、备份数据库 –all-databases 备份所有数据库 /opt/mysqlcopy/all_$(date “%Y-%m-%d %H:%M:%S”).sql 备份地址 docker exec -it 容器名称 sh -c "mysqldump -u root -ppassword --all-databases > /opt/mysqlcopy/all_$(date "%Y-%m-%d %H:%M:%S").sq…...
Nginx 不同源Https请求Http 报strict-origin-when-cross-origin
原因: nginx代理配置url指向只开放了/* 而我/*/*多了一层路径 成功:...

openGauss学习笔记-175 openGauss 数据库运维-备份与恢复-导入数据-管理并发写入操作示例
文章目录 openGauss学习笔记-175 openGauss 数据库运维-备份与恢复-导入数据-管理并发写入操作示例175.1 相同表的INSERT和DELETE并发175.2 相同表的并发INSERT175.3 相同表的并发UPDATE175.4 数据导入和查询的并发 openGauss学习笔记-175 openGauss 数据库运维-备份与恢复-导入…...

pnpm、npm、yarn是什么?怎么选择?
pnpm、npm、yarn三者是前端常用的包管理器,那么他们有什么区别呢? 1. npm (Node Package Manager) npm是Node.js的默认包管理器。自Node.js发布以来,npm就一直作为它的一个组成部分存在,因此,安装Node.js时也会自动安…...

MySQL8 一键部署
#!/bin/bash ### 定义变量 mysql_download_urlhttps://cdn.mysql.com//Downloads/MySQL-8.0/mysql-8.0.33-linux-glibc2.12-x86_64.tar.xz mysql_package_namemysql-8.0.33-linux-glibc2.12-x86_64.tar.xz mysql_dec_namemysql-8.0.33-linux-glibc2.12-x86_64 mysql_download_…...

深入T100系统腹地:拆解标准区、测试区与客制开发的协作逻辑
深入T100系统腹地:拆解标准区、测试区与客制开发的协作逻辑 在企业管理系统的复杂生态中,T100以其独特的四区架构和多环境协作机制,为企业的数字化转型提供了稳健的技术支撑。这套架构不仅关乎代码的流转,更是企业业务流程标准化与…...
)
Java十道高频面试题(一)
Java基础与集合1. HashMap的底层数据结构是什么?(JDK 1.7 vs 1.8)考察点:数据结构演进、哈希冲突解决、扩容死循环问题。参考答案:HashMap在JDK 1.7和1.8中有着本质的区别,主要体现在底层结构和扩容机制上&…...

认知神经科学研究报告【20260055】
文章目录VAR 平稳向量自回归任务:L3 自适应涌现与 L4 经验迁移实验报告一、实验目标二、实验设计三、核心成果3.1 自主模型发现3.2 L4 跨任务经验迁移3.3 自主因果推断四、涌现层级评估六、结论VAR 平稳向量自回归任务:L3 自适应涌现与 L4 经验迁移实验报…...

Qt 批量读取Excel数据:从性能瓶颈到优化实践
1. 为什么Qt读取Excel会卡成PPT? 第一次用Qt操作Excel表格时,我兴冲冲写了个循环读取单元格的代码。结果打开包含5000行数据的文件后,进度条像蜗牛爬坡,鼠标指针转成彩色圆圈,程序直接卡成PPT幻灯片模式——这场景估计…...

5分钟掌握飞书文档高效转换:开源浏览器扩展的完整解决方案
5分钟掌握飞书文档高效转换:开源浏览器扩展的完整解决方案 【免费下载链接】cloud-document-converter Convert Lark Doc to Markdown 项目地址: https://gitcode.com/gh_mirrors/cl/cloud-document-converter 还在为飞书文档格式转换而头疼吗?复…...

QProcess::FailedToStart “No program defined“。qtcreator用的好好的,然后就不能调试了
点击 项目-》运行-》执行档根本原因:执行档:路径为空 解决办法:添加这样执行档 就有路径了。就可以用了...

【Midjourney Gouache风格终极指南】:20年AI绘画专家亲授7大参数黄金组合与3类易踩翻车点
更多请点击: https://intelliparadigm.com 第一章:Gouache风格的本质解构与AI绘画语境迁移 Gouache(水粉画)并非简单意义上的“不透明水彩”,其本质在于颜料颗粒的物理遮盖性、媒介乳化稳定性与干湿叠压响应的三重耦合…...

从一次失败的模型交付说起:我是如何用random_state拯救项目复现的
从一次失败的模型交付说起:我是如何用random_state拯救项目复现的 那是一个周五的下午,团队群里的消息突然炸开了锅。"你确定这是同一个模型?测试集AUC从0.92跌到0.68了!"看着同事发来的对比截图,我的后背瞬…...

番茄小说下载器完整指南:如何轻松搭建个人离线图书馆
番茄小说下载器完整指南:如何轻松搭建个人离线图书馆 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 还在为网络不稳定无法畅读番茄小说而烦恼吗?番茄小…...

5分钟快速上手:XUnity.AutoTranslator游戏实时翻译插件终极指南
5分钟快速上手:XUnity.AutoTranslator游戏实时翻译插件终极指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为语言障碍而无法畅玩海外Unity游戏吗?XUnity.AutoTranslator正…...