大创项目推荐 深度学习OCR中文识别 - opencv python
文章目录
- 0 前言
- 1 课题背景
- 2 实现效果
- 3 文本区域检测网络-CTPN
- 4 文本识别网络-CRNN
- 5 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 **基于深度学习OCR中文识别系统 **
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题背景
在日常生产生活中有大量的文档资料以图片、PDF的方式留存,随着时间推移 往往难以检索和归类 ,文字识别(Optical Character
Recognition,OCR )是将图片、文档影像上的文字内容快速识别成为可编辑的文本的技术。
高性能文档OCR识别系统是基于深度学习技术,综合运用Tensorflow、CNN、Caffe
等多种深度学习训练框架,基于千万级大规模文字样本集训练完成的OCR引擎,与传统的模式识别的技术相比,深度学习技术支持更低质量的分辨率、抗干扰能力更强、适用的场景更复杂,文字的识别率更高。
本项目基于Tensorflow、keras/pytorch实现对自然场景的文字检测及OCR中文文字识别。
2 实现效果
公式检测

纯文字识别

3 文本区域检测网络-CTPN
对于复杂场景的文字识别,首先要定位文字的位置,即文字检测。
简介
CTPN是在ECCV
2016提出的一种文字检测算法。CTPN结合CNN与LSTM深度网络,能有效的检测出复杂场景的横向分布的文字,效果如图1,是目前比较好的文字检测算法。由于CTPN是从Faster
RCNN改进而来,本文默认读者熟悉CNN原理和Faster RCNN网络结构。

相关代码
def main(argv):pycaffe_dir = os.path.dirname(__file__)parser = argparse.ArgumentParser()# Required arguments: input and output.parser.add_argument("input_file",help="Input txt/csv filename. If .txt, must be list of filenames.\If .csv, must be comma-separated file with header\'filename, xmin, ymin, xmax, ymax'")parser.add_argument("output_file",help="Output h5/csv filename. Format depends on extension.")# Optional arguments.parser.add_argument("--model_def",default=os.path.join(pycaffe_dir,"../models/bvlc_reference_caffenet/deploy.prototxt.prototxt"),help="Model definition file.")parser.add_argument("--pretrained_model",default=os.path.join(pycaffe_dir,"../models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel"),help="Trained model weights file.")parser.add_argument("--crop_mode",default="selective_search",choices=CROP_MODES,help="How to generate windows for detection.")parser.add_argument("--gpu",action='store_true',help="Switch for gpu computation.")parser.add_argument("--mean_file",default=os.path.join(pycaffe_dir,'caffe/imagenet/ilsvrc_2012_mean.npy'),help="Data set image mean of H x W x K dimensions (numpy array). " +"Set to '' for no mean subtraction.")parser.add_argument("--input_scale",type=float,help="Multiply input features by this scale to finish preprocessing.")parser.add_argument("--raw_scale",type=float,default=255.0,help="Multiply raw input by this scale before preprocessing.")parser.add_argument("--channel_swap",default='2,1,0',help="Order to permute input channels. The default converts " +"RGB -> BGR since BGR is the Caffe default by way of OpenCV.")parser.add_argument("--context_pad",type=int,default='16',help="Amount of surrounding context to collect in input window.")args = parser.parse_args()mean, channel_swap = None, Noneif args.mean_file:mean = np.load(args.mean_file)if mean.shape[1:] != (1, 1):mean = mean.mean(1).mean(1)if args.channel_swap:channel_swap = [int(s) for s in args.channel_swap.split(',')]if args.gpu:caffe.set_mode_gpu()print("GPU mode")else:caffe.set_mode_cpu()print("CPU mode")# Make detector.detector = caffe.Detector(args.model_def, args.pretrained_model, mean=mean,input_scale=args.input_scale, raw_scale=args.raw_scale,channel_swap=channel_swap,context_pad=args.context_pad)# Load input.t = time.time()print("Loading input...")if args.input_file.lower().endswith('txt'):with open(args.input_file) as f:inputs = [_.strip() for _ in f.readlines()]elif args.input_file.lower().endswith('csv'):inputs = pd.read_csv(args.input_file, sep=',', dtype={'filename': str})inputs.set_index('filename', inplace=True)else:raise Exception("Unknown input file type: not in txt or csv.")# Detect.if args.crop_mode == 'list':# Unpack sequence of (image filename, windows).images_windows = [(ix, inputs.iloc[np.where(inputs.index == ix)][COORD_COLS].values)for ix in inputs.index.unique()]detections = detector.detect_windows(images_windows)else:detections = detector.detect_selective_search(inputs)print("Processed {} windows in {:.3f} s.".format(len(detections),time.time() - t))# Collect into dataframe with labeled fields.df = pd.DataFrame(detections)df.set_index('filename', inplace=True)df[COORD_COLS] = pd.DataFrame(data=np.vstack(df['window']), index=df.index, columns=COORD_COLS)del(df['window'])# Save results.t = time.time()if args.output_file.lower().endswith('csv'):# csv# Enumerate the class probabilities.class_cols = ['class{}'.format(x) for x in range(NUM_OUTPUT)]df[class_cols] = pd.DataFrame(data=np.vstack(df['feat']), index=df.index, columns=class_cols)df.to_csv(args.output_file, cols=COORD_COLS + class_cols)else:# h5df.to_hdf(args.output_file, 'df', mode='w')print("Saved to {} in {:.3f} s.".format(args.output_file,time.time() - t))
CTPN网络结构

4 文本识别网络-CRNN
CRNN 介绍
CRNN 全称为 Convolutional Recurrent Neural Network,主要用于端到端地对不定长的文本序列进行识别,不用
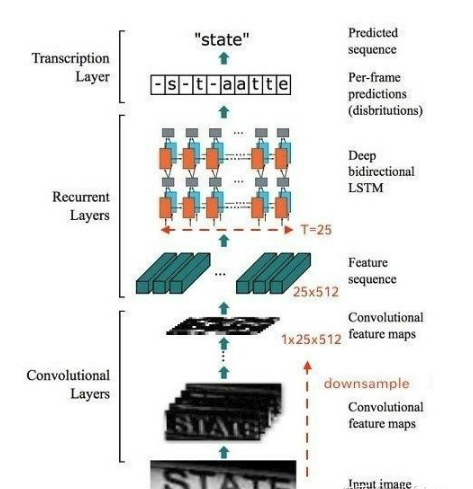
整个CRNN网络结构包含三部分,从下到上依次为:
- CNN(卷积层),使用深度CNN,对输入图像提取特征,得到特征图;
- RNN(循环层),使用双向RNN(BLSTM)对特征序列进行预测,对序列中的每个特征向量进行学习,并输出预测标签(真实值)分布;
- CTC loss(转录层),使用 CTC 损失,把从循环层获取的一系列标签分布转换成最终的标签序列。
CNN
卷积层的结构图:
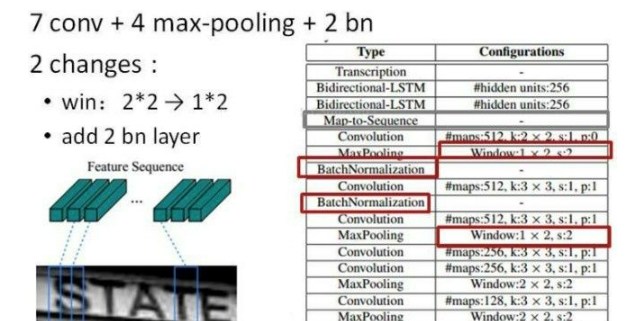
这里有一个很精彩的改动,一共有四个最大池化层,但是最后两个池化层的窗口尺寸由 2x2 改为 1x2,也就是图片的高度减半了四次(除以 2^4
),而宽度则只减半了两次(除以2^2),这是因为文本图像多数都是高较小而宽较长,所以其feature
map也是这种高小宽长的矩形形状,如果使用1×2的池化窗口可以尽量保证不丢失在宽度方向的信息,更适合英文字母识别(比如区分i和l)。
CRNN 还引入了BatchNormalization模块,加速模型收敛,缩短训练过程。
输入图像为灰度图像(单通道);高度为32,这是固定的,图片通过 CNN
后,高度就变为1,这点很重要;宽度为160,宽度也可以为其他的值,但需要统一,所以输入CNN的数据尺寸为 (channel, height,
width)=(1, 32, 160)。
CNN的输出尺寸为 (512, 1, 40)。即 CNN 最后得到512个特征图,每个特征图的高度为1,宽度为40。
Map-to-Sequence
我们是不能直接把 CNN 得到的特征图送入 RNN 进行训练的,需要进行一些调整,根据特征图提取 RNN 需要的特征向量序列。
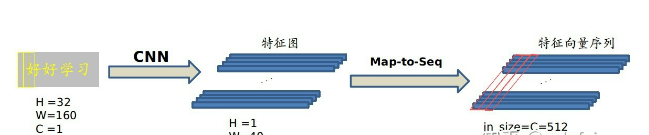
现在需要从 CNN 模型产生的特征图中提取特征向量序列,每一个特征向量(如上图中的一个红色框)在特征图上按列从左到右生成,每一列包含512维特征,这意味着第
i 个特征向量是所有的特征图第 i 列像素的连接,这些特征向量就构成一个序列。
由于卷积层,最大池化层和激活函数在局部区域上执行,因此它们是平移不变的。因此,特征图的每列(即一个特征向量)对应于原始图像的一个矩形区域(称为感受野),并且这些矩形区域与特征图上从左到右的相应列具有相同的顺序。特征序列中的每个向量关联一个感受野。
如下图所示:

这些特征向量序列就作为循环层的输入,每个特征向量作为 RNN 在一个时间步(time step)的输入。
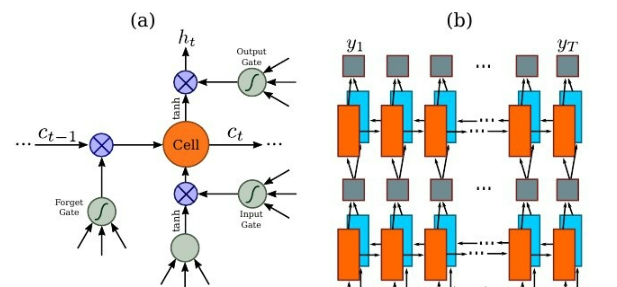
RNN
因为 RNN 有梯度消失的问题,不能获取更多上下文信息,所以 CRNN 中使用的是 LSTM,LSTM
的特殊设计允许它捕获长距离依赖,不了解的话可以看一下这篇文章 对RNN和LSTM的理解。
LSTM
是单向的,它只使用过去的信息。然而,在基于图像的序列中,两个方向的上下文是相互有用且互补的。将两个LSTM,一个向前和一个向后组合到一个双向LSTM中。此外,可以堆叠多层双向LSTM,深层结构允许比浅层抽象更高层次的抽象。
这里采用的是两层各256单元的双向 LSTM 网络:
通过上面一步,我们得到了40个特征向量,每个特征向量长度为512,在 LSTM 中一个时间步就传入一个特征向量进行分
我们知道一个特征向量就相当于原图中的一个小矩形区域,RNN
的目标就是预测这个矩形区域为哪个字符,即根据输入的特征向量,进行预测,得到所有字符的softmax概率分布,这是一个长度为字符类别数的向量,作为CTC层的输入。
因为每个时间步都会有一个输入特征向量 x^T ,输出一个所有字符的概率分布 y^T ,所以输出为 40 个长度为字符类别数的向量构成的后验概率矩阵。
如下图所示:

然后将这个后验概率矩阵传入转录层。
CTC loss
这算是 CRNN 最难的地方,这一层为转录层,转录是将 RNN
对每个特征向量所做的预测转换成标签序列的过程。数学上,转录是根据每帧预测找到具有最高概率组合的标签序列。
端到端OCR识别的难点在于怎么处理不定长序列对齐的问题!OCR可建模为时序依赖的文本图像问题,然后使用CTC(Connectionist Temporal
Classification, CTC)的损失函数来对 CNN 和 RNN 进行端到端的联合训练。
相关代码
def inference(self, inputdata, name, reuse=False):"""Main routine to construct the network:param inputdata::param name::param reuse::return:"""with tf.variable_scope(name_or_scope=name, reuse=reuse):# centerlized datainputdata = tf.divide(inputdata, 255.0)#1.特征提取阶段# first apply the cnn feature extraction stagecnn_out = self._feature_sequence_extraction(inputdata=inputdata, name='feature_extraction_module')#2.第二步, batch*1*25*512 变成 batch * 25 * 512# second apply the map to sequence stagesequence = self._map_to_sequence(inputdata=cnn_out, name='map_to_sequence_module')#第三步,应用序列标签阶段# third apply the sequence label stage# net_out width, batch, n_classes# raw_pred width, batch, 1net_out, raw_pred = self._sequence_label(inputdata=sequence, name='sequence_rnn_module')return net_out
5 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
大创项目推荐 深度学习OCR中文识别 - opencv python
文章目录 0 前言1 课题背景2 实现效果3 文本区域检测网络-CTPN4 文本识别网络-CRNN5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 **基于深度学习OCR中文识别系统 ** 该项目较为新颖,适合作为竞赛课题方向,…...
Python经典游戏 唤醒你童年记忆
这些游戏你玩过几个? 1.贪吃蛇2.吃豆人3.加农炮4.四子棋5. Fly Bird<font color #f3704ab>6.记忆:数字对拼图游戏(欢迎挑战!用时:2min)7.乒乓球8.上课划水必备-井字游戏(我敢说100%的人都…...

什么是骨传导耳机?骨传导能保护听力吗?
骨传导耳机是一种非常特殊的蓝牙耳机,它通过骨传导技术将声音直接传送到内耳。这种技术不同于传统耳机,它不通过空气传送声音,而是通过头骨的振动来传送声音。 并且骨传导耳机能够在一定程度上起到保护听力的作用,主要是因为它们不…...
使用electron属性实现保存图片并获取图片的磁盘路径
在普通的网页开发中,JavaScript由于安全性的考虑,通常是无法直接获取到客户端的磁盘路径的。浏览器出于隐私和安全原因对此类信息进行了限制。 在浏览器环境下,JavaScript主要通过Web APIs来与浏览器进行交互,而这些API通常受到浏…...

进击的奶牛
题目 进击的奶牛 题意 通过二分查找算法找到一个最小间距x,使得在数组a中选出的k个数两两之间的间距都不小于x,并且x尽可能大。最后输出这个最大的x值。 思路 程序通过循环依次获取了n个整数,存储在数组a中。.然后,程序对数组a进…...

12月27日,每日信息差
以下是2023年12月27日的8条信息差 第一、小米公司:小米汽车正式加入小米“人车家全生态”,随着小米汽车的即将发布,小米“人车家全生态”也实现了真正闭环 第二、吉利将于2024年初发射11颗卫星,吉利银河E8率先搭载卫星通信技术。…...

【赠书第14期】AI短视频制作一本通:文本生成视频+图片生成视频+视频生成视频
文章目录 前言 1 前期准备 2 拍摄与录制 3 后期编辑 4 技巧与注意事项 5 推荐图书 6 粉丝福利 前言 随着智能技术的迅猛发展,AI 短视频制作成为了一种新兴而创新的表达方式,广泛应用于社交媒体、广告营销、教育培训等领域。本文将介绍 AI 短视频…...
)
简单工厂设计模式(计算器实例优化)
简单工厂设计模式(计算器实例优化) 介绍为什么采用面向对象编程而不是面向过程呢?实例讲解业务层划分出来逻辑层继承简单工厂:(多态)业务层:(解耦合)主控制台 总结 介绍 …...
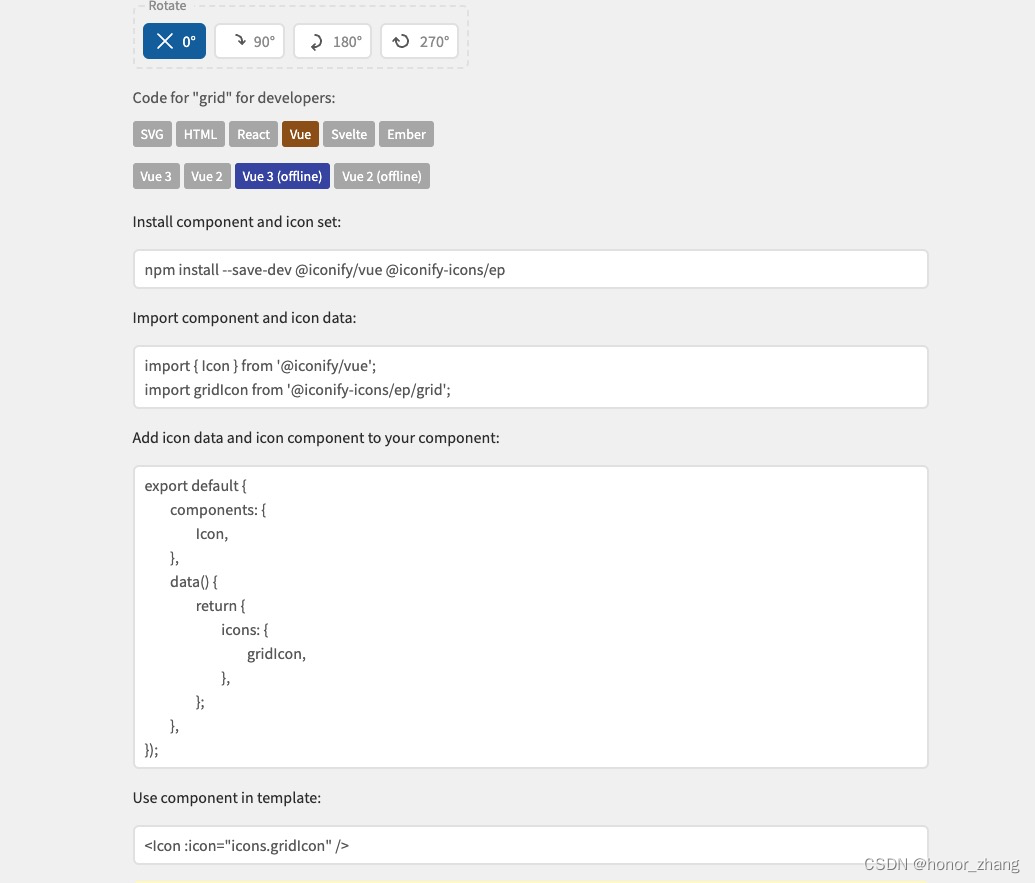
iconify图标集离线使用方案简介
1.需求描述 前端项目,技术栈使用Vue3Element Plus,参考了ruoyi-vue-pro项目与vue-element-plus-admin项目,封装了一个Icon组件,图标使用的是iconify,项目部署在内网环境,不能连接互联网,需要部署一套iconi…...

java基础之理解多态
目录 简单理解 满足多态的三个条件 有类继承或者接口实现 子类要重写父类的方法 父类的引用指向子类的对象。 代码示例 动态多态 静态多态 个人观点 简单理解 简单理解就是,同一操作作用于不同的对象,可以有不同的解释,产生不同的执…...
第二证券:A股市场放量反弹 跨年行情或启动
沪指日线等级放量反弹,周四收中阳线成功站上20日均线,底部结构或可树立。创业板指大涨近4%,日线MACD出现底违反,多方动能较强,中等级反弹行情或在酝酿。月线来看,12月创业板指探底上升出现较长下影…...

web漏洞与修复
一、web漏洞 检测到目标X-Content-Type-Options响应头缺失 详细描述X-Content-Type-Options HTTP 消息头相当于一个提示标志,被服务器用来提示客户端一定要遵循在 Content-Type 首部中对 MIME 类型 的设定,而不能对其进行修改。这就禁用了客户端的 MIM…...

基于Java+SpringBoot+vue实现图书借阅管理系统
基于JavaSpringBootvue实现图书借阅和销售商城一体化系统 🍅 作者主页 程序设计 🍅 欢迎点赞 👍 收藏 ⭐留言 📝 🍅 文末获取源码联系方式 📝 文章目录 基于JavaSpringBootvue实现图书借阅和销售商城一体化…...
可扩展标记语言(Extensible Markup Language))
xml文件学习(xml格式)可扩展标记语言(Extensible Markup Language)
XML 教程 文章目录 XML 文件学习1. XML 概述1.1 什么是 XML?1.2 XML 有什么作用? 2. XML 基本结构1. 声明2. 元素3. 属性4. 文本5. 注释 3. XML 高级知识3.1 XML 命名空间3.2 XML 架构3.3 XML 工具3.4 XML 技术 4. XML 应用实例 XML 文件学习 XML&#…...
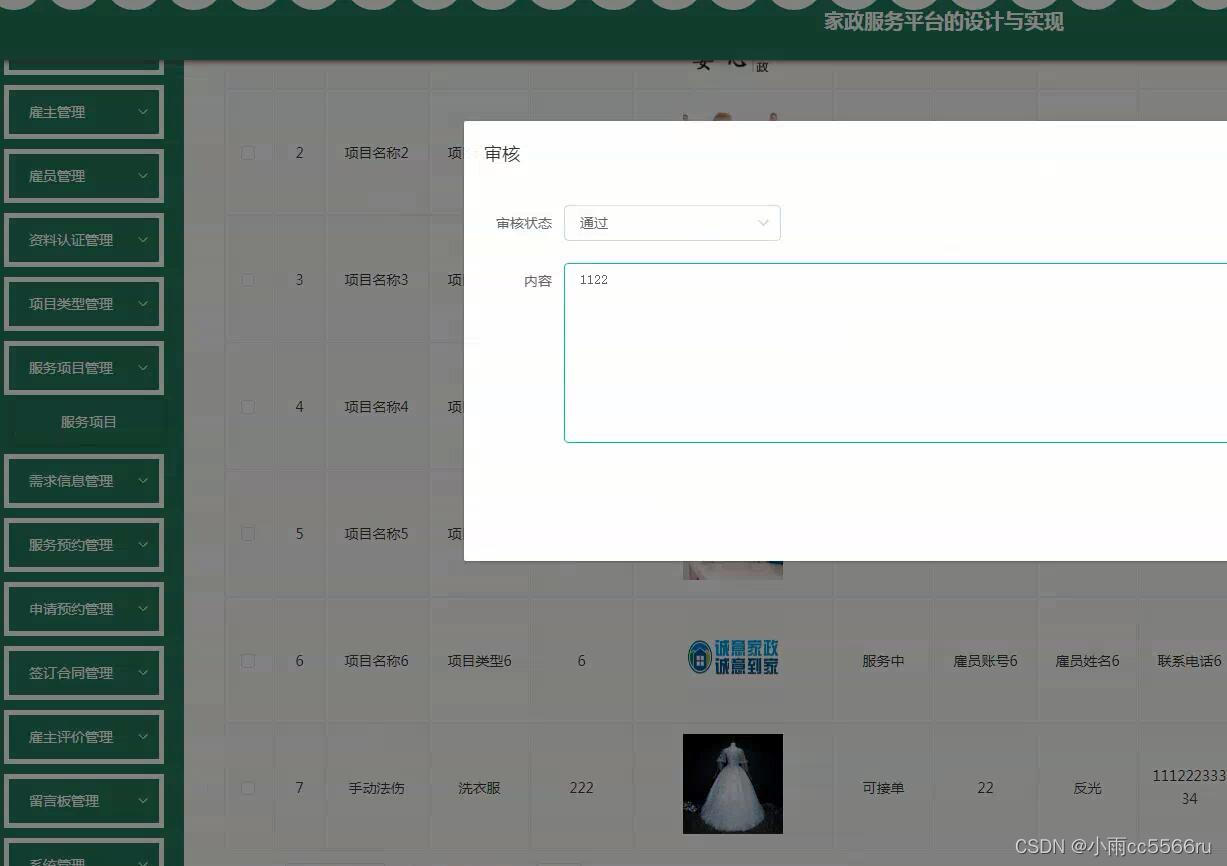
nodejs+vue+ElementUi家政服务系统c90g5
项目中登录模块用到token家政服务平台有管理员,雇主,雇员三个角色。管理员功能有个人中心,雇主管理,雇员管理,资料认证管理,项目类型管理,服务项目管理,需求信息管理,服务…...

数据库(Database)基础知识
什么是数据库 数据库是按照数据结构来组织、存储和管理数据的仓库,用户可以通过数据库管理系统对存储的数据进行增删改查操作。 数据库实际上是一个文件集合,本质就是一个文件系统,以文件的方式,将数据保存在电脑上。 什么是数据…...

QT应用篇 二、QML用Image组件实现Progress Bar 的效果
QT应用篇 一、QT上位机串口编程 二、QML用Image组件实现Progress Bar 的效果 三、QML自定义显示SpinBox的加减按键图片及显示值效果 文章目录 QT应用篇前言一、qml需求二、使用组件1.Image组件2.Image中fillMode的使用例子 总结 前言 记录自己学习QML的一些小技巧方便日后查找…...

SElinux工作原理简介并演示chcon、semanage、restorecon的使用方法
目录 一.SElinux工作原理简介 1.system_u 2.object_r 3.httpd_sys_content_t 4.s0 二.SElinux策略的具体使用详情 1.restorecon 2.semanage 3.chcon 一.SElinux工作原理简介 通过mac方式管理进程,管理的目标是进程是否具有读取权限的文件(文件…...

表情串转换
前言 NWAFU 2021阶段二 D 一、题目描述 题目描述 在一个字符串中,设置了由‘/’前导字符和某些特定字母构成的转义子字符串,如“/s”、“/f”、“/c”等用于表示特殊表情符号。现要求编写一个函数,将给定字符串中的转义字符串转换为表情字…...
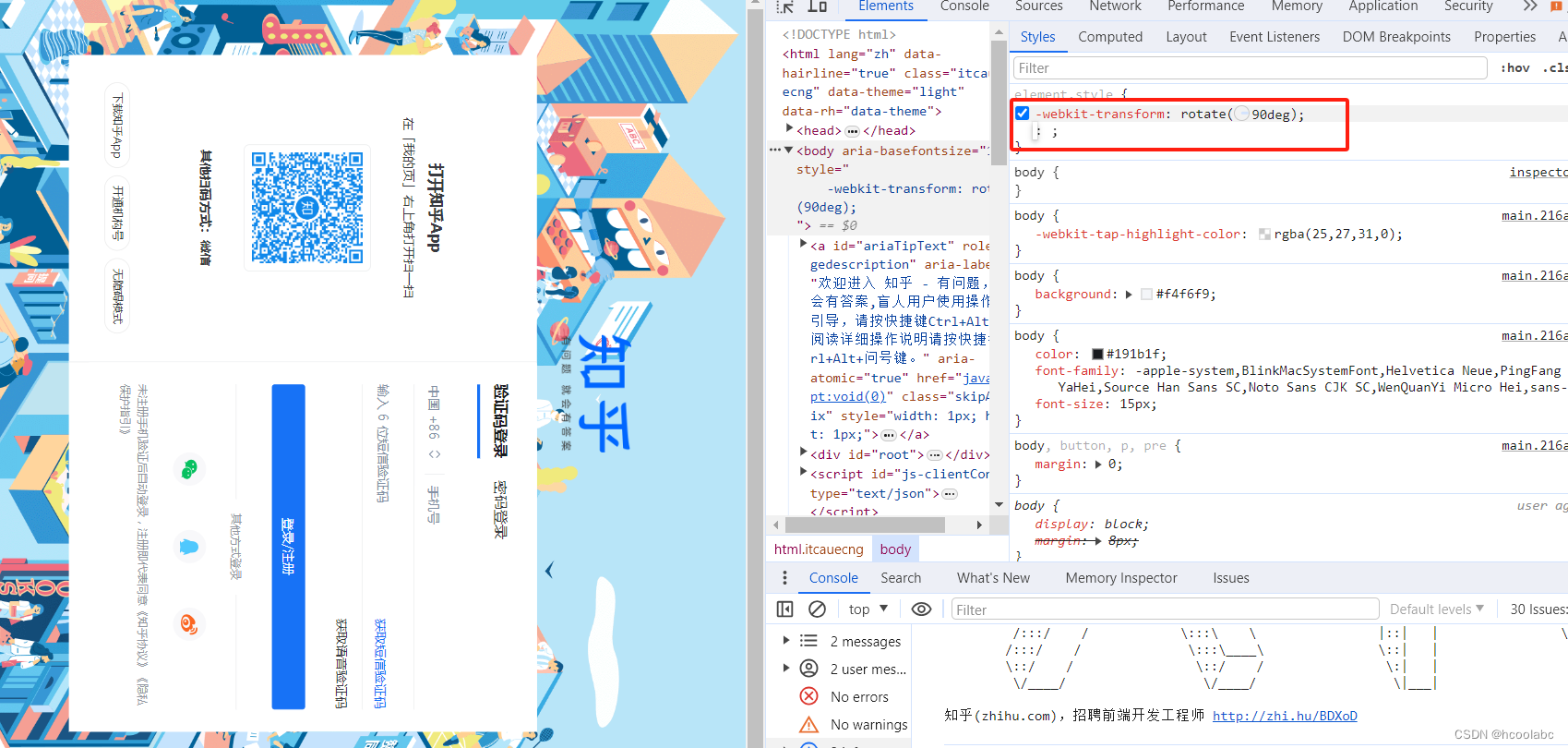
【娱乐小技巧】网页旋转90° 3步搞定
一、按F12,打开控制台; 二、点击号; 插入新body; 三、粘贴代码 -webkit-transform: rotate(90deg);小结,角度值可以自选; 代码的效果:...

告别60帧束缚:《原神》帧率解锁终极指南,轻松实现120帧流畅体验
告别60帧束缚:《原神》帧率解锁终极指南,轻松实现120帧流畅体验 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 还在为《原神》60帧的限制而烦恼吗?想…...

OpenVSP参数化飞机设计:3个技巧让你从零开始打造专业飞行器
OpenVSP参数化飞机设计:3个技巧让你从零开始打造专业飞行器 【免费下载链接】OpenVSP A parametric aircraft geometry tool 项目地址: https://gitcode.com/gh_mirrors/ope/OpenVSP 你是否梦想设计自己的飞机,却被复杂的CAD软件吓退?…...

谷歌排名算法有哪些? 解决AI生成内容不收录的3个操作方案
2024年3月5日,谷歌启动了一场持续45天的核心算法更新。这次调整导致互联网上超过40%的低质量内容被清除。许多依靠软件大批量产出文章的站点,网页收录量在短时间内缩减了九成。单纯依靠算法堆砌出来的文字,在目前的搜索环境下很难获得生存空间…...

从强化学习视角看HDP:ADP中的Actor-Critic框架到底怎么工作的?
从强化学习视角看HDP:ADP中的Actor-Critic框架到底怎么工作的? 在控制理论与机器学习交叉领域,自适应动态规划(ADP)与强化学习(RL)的融合正催生新一代智能控制范式。当我们以RL从业者熟悉的Act…...
)
STM32+RS485实战:用Modbus RTU协议读取液压传感器数据(附自动收发电路避坑)
STM32与RS485实战:从电路设计到Modbus RTU协议解析 液压传感器数据采集在工业自动化领域有着广泛应用,而RS485总线因其抗干扰能力强、传输距离远等优势成为首选通信方式。本文将深入探讨如何基于STM32微控制器搭建RS485硬件电路,并通过Modbus…...

Java开发者收藏必看:转型AI领域,解锁高薪职业新机遇!
本文探讨了Java开发者向AI领域转型的可行性、优势及所需知识。文章指出,Java开发者具备转型AI的独特优势,AI领域岗位需求旺盛且薪资高于Java开发。转型者需补充数学、Python等知识,并通过实践项目积累经验。掌握AI技术能显著提升个人竞争力&a…...
)
别再硬算公式了!用Excel搞定STM32 NTC测温的ADC查表法(附完整表格)
用Excel玩转STM32 NTC测温:查表法实战指南 嵌入式开发中,温度测量是个永恒的话题。NTC热敏电阻因其成本低廉、响应迅速,成为工程师们的首选传感器。但每次项目都要重新推导温度计算公式,不仅耗时费力,还容易在数学转换…...

Intel RealSense D435i 标定实战:从工具安装到VINS配置全流程解析
1. 准备工作:认识D435i与标定原理 第一次拿到Intel RealSense D435i时,我盯着这个火柴盒大小的设备看了半天——它凭什么能实现三维感知?拆开包装后发现,这玩意儿居然集成了双目红外相机、RGB彩色相机和IMU惯性测量单元。但问题来…...
)
文献管理软件//Zotero文献导入实战:从新手到高手的五种核心路径(九)
1. 从零开始:Zotero文献导入的底层逻辑与核心价值 第一次接触Zotero时,我盯着空荡荡的文献库发呆了半小时——就像刚搬进新家的人面对空房间,明明知道需要填满它,却不知从何下手。文献管理软件的核心价值在于建立个人知识库&#…...

一键解锁B站缓存视频:从平台依赖到个人数字资产管理的智能方案
一键解锁B站缓存视频:从平台依赖到个人数字资产管理的智能方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 在数字内容瞬息万变的…...