数据挖掘 K-Means聚类
未格式化之前的代码:
import pandas as pd#数据处理
from matplotlib import pyplot as plt#绘图
from sklearn.preprocessing import MinMaxScaler#归一化
from sklearn.cluster import KMeans#聚类
import os#处理文件os.environ["OMP_NUM_THREADS"] = '4'df = pd.read_excel("consumption_data.xls", usecols=["R", "F", "M"])#选取了“R”、“F”和“M”三列数据
df.dropna(inplace=True)#将缺失值删除
df_scale = MinMaxScaler().fit_transform(df)#归一化,使得数据在0到1的范围内
model = KMeans(n_clusters=3, random_state=0)#n_clusters参数设置为3,表示要将数据分成3个簇。random_state参数设置为0,以确保每次运行时都得到相同的结果
model.fit(df_scale)#训练模型
core = model.cluster_centers_#通过cluster_centers_属性获取聚类模型中心点的坐标,即每个簇的中心点
df["class"] = model.labels_#将每个数据点的簇标签保存在原始数据集的“class”列中,使用labels_属性获取每个数据点所属的簇的标签fig = plt.figure(figsize=(9, 9))#创建一个大小为9x9的图形窗口
ax = plt.axes(projection='3d')#创建一个3D坐标轴
center_x = []#创建空列表用于存储各个簇的中心点坐标。
center_y = []
center_z = []
for i, j in df.groupby(by="class"):#对数据集按簇标签进行分组ax.scatter3D(j["F"], j["R"], j["M"], label=i)#将每个簇的数据点在3D空间中绘制为散点图center_x.append(j["F"].mean())#计算每个簇的中心点坐标,并将其添加到相应的列表中。center_y.append(j["R"].mean())center_z.append(j["M"].mean())# ax.scatter3D(j["F"].mean(),j["R"].mean(),j["M"].mean(),marker="X") 使用scatter3D()函数将每个簇的中心点坐标(j["F"].mean(), j["R"].mean(), j["M"].mean())以"X"形状的标记绘制在图中。
ax.scatter3D(center_x, center_y, center_z, label='center', marker="X", alpha=1)#以“X”形状的标记绘制簇的中心点。alpha参数设置为1,表示散点图的透明度为完全不透明
plt.legend()#显示图例
plt.show()#显示图形for i, j in df.groupby(by="class"):#对数据集按簇标签进行分组。j[["R", "F", "M"]].plot(kind="kde", subplots=True, sharex=False)#对每个簇的三个特征绘制核密度图。kind="kde"指定绘制核密度图,subplots=True表示将三个子图绘制在同一画布上,sharex=False表示不共享x轴。plt.subplots_adjust(hspace=0.3) # 调整子图的纵向间隙,hspace=0.3将纵向间隔设置为子图高度的30%。这将使得每个子图之间有一定的空白间隔plt.show()#显示图形
格式化之后的代码:
import pandas as pd # 数据处理
from matplotlib import pyplot as plt # 绘图
from sklearn.preprocessing import MinMaxScaler # 归一化
from sklearn.cluster import KMeans # 聚类
import os # 处理文件os.environ["OMP_NUM_THREADS"] = '4'df = pd.read_excel("consumption_data.xls", usecols=["R", "F", "M"]) # 选取了“R”、“F”和“M”三列数据
df.dropna(inplace=True) # 将缺失值删除
df_scale = MinMaxScaler().fit_transform(df) # 归一化,使得数据在0到1的范围内
model = KMeans(n_clusters=3, random_state=0) # n_clusters参数设置为3,表示要将数据分成3个簇。random_state参数设置为0,以确保每次运行时都得到相同的结果
model.fit(df_scale) # 训练模型
core = model.cluster_centers_ # 通过cluster_centers_属性获取聚类模型中心点的坐标,即每个簇的中心点
df["class"] = model.labels_ # 将每个数据点的簇标签保存在原始数据集的“class”列中,使用labels_属性获取每个数据点所属的簇的标签fig = plt.figure(figsize=(9, 9)) # 创建一个大小为9x9的图形窗口
ax = plt.axes(projection='3d') # 创建一个3D坐标轴
center_x = [] # 创建空列表用于存储各个簇的中心点坐标。
center_y = []
center_z = []
for i, j in df.groupby(by="class"): # 对数据集按簇标签进行分组ax.scatter3D(j["F"], j["R"], j["M"], label=i) # 将每个簇的数据点在3D空间中绘制为散点图center_x.append(j["F"].mean()) # 计算每个簇的中心点坐标,并将其添加到相应的列表中。center_y.append(j["R"].mean())center_z.append(j["M"].mean())# ax.scatter3D(j["F"].mean(),j["R"].mean(),j["M"].mean(),marker="X") 使用scatter3D()函数将每个簇的中心点坐标(j["F"].mean(), j["R"].mean(), j["M"].mean())以"X"形状的标记绘制在图中。
ax.scatter3D(center_x, center_y, center_z, label='center', marker="X",alpha=1) # 以“X”形状的标记绘制簇的中心点。alpha参数设置为1,表示散点图的透明度为完全不透明
plt.legend() # 显示图例
plt.show() # 显示图形for i, j in df.groupby(by="class"): # 对数据集按簇标签进行分组。j[["R", "F", "M"]].plot(kind="kde", subplots=True,sharex=False) # 对每个簇的三个特征绘制核密度图。kind="kde"指定绘制核密度图,subplots=True表示将三个子图绘制在同一画布上,sharex=False表示不共享x轴。plt.subplots_adjust(hspace=0.3) # 调整子图的纵向间隙,hspace=0.3将纵向间隔设置为子图高度的30%。这将使得每个子图之间有一定的空白间隔plt.show() # 显示图形
相关文章:

数据挖掘 K-Means聚类
未格式化之前的代码: import pandas as pd#数据处理 from matplotlib import pyplot as plt#绘图 from sklearn.preprocessing import MinMaxScaler#归一化 from sklearn.cluster import KMeans#聚类 import os#处理文件os.environ["OMP_NUM_THREADS"] …...

医疗卫生行业网络安全需求发展
文章目录 一、行业安全建设需求分析1、等级保护2.0合规建设云计算技术大数据技术物联网技术移动互联网技术2、加强医疗数据安全保护加密存储与传输数据加强数据备份与恢复注重数据脱敏与分级保护3、强化网络安全制度管理完善应急预案与响应机制加强网络安全人员管理二、行业新技…...

【Unity热更新】学会AssetsBundle打包、加载、卸载
本教程详细讲解什么是AssetBundle压缩包机制!然后构建 AssetBundle、加载 AssetBundle 以及卸载 AssetBundle 的简要教程。这一个流程就是热更新! AssetBundles 简介 1.什么是AssetBundles? AssetBundles是Unity中一种用于打包和存储资源(如模型、纹理、声音等)的文件格…...

智能优化算法应用:基于指数分布算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于指数分布算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于指数分布算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.指数分布算法4.实验参数设定5.算法结果6.…...

vue 监听浏览器关闭或刷新事件
vue 监听浏览器关闭或刷新事件 需求 web项目中使用socket时,涉及到关闭刷新浏览器多次连接问题,其中一个解决方法是在关闭或刷新浏览器时,将连接断开。 代码 <script> export default {// 可以在created、beforeMount或mounted生命…...

VuePress-theme-hope 搭建个人博客 2【快速上手】 —— 安装、部署 防止踩坑篇
续👆VuePress、VuePress-theme-hope 搭建个人博客 1【快速上手】 项目常用命令 vuepress dev [dir] 会启动一个开发服务器,以便让你在本地开发你的 VuePress 站点。vuepress build [dir] 会将你的 VuePress 站点构建成静态文件,以便你进行后…...
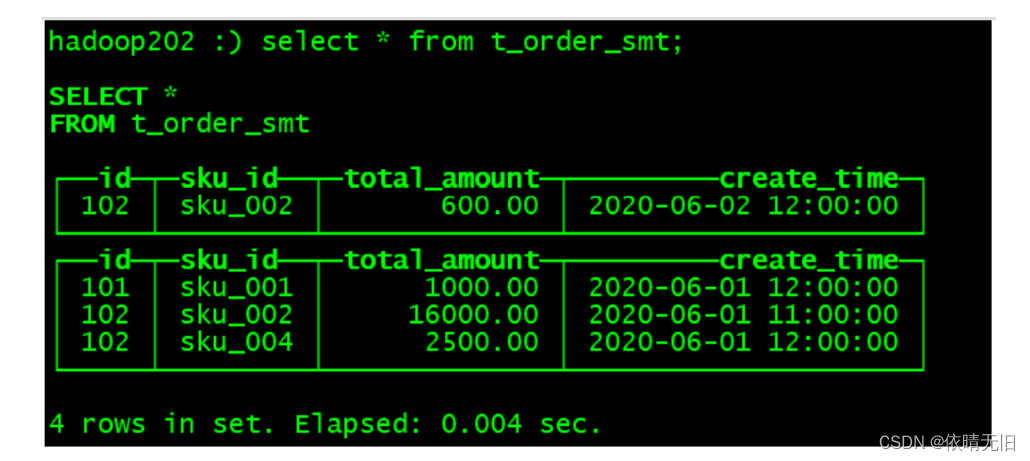
ClickHouse基础知识(四):ClickHouse 引擎详解
1. 表引擎的使用 表引擎是 ClickHouse 的一大特色。可以说, 表引擎决定了如何存储表的数据。包括: ➢ 数据的存储方式和位置,写到哪里以及从哪里读取数据。 默认存放在/var/lib/clickhouse/data ➢ 支持哪些查询以及如何支持。 ➢ 并发数…...
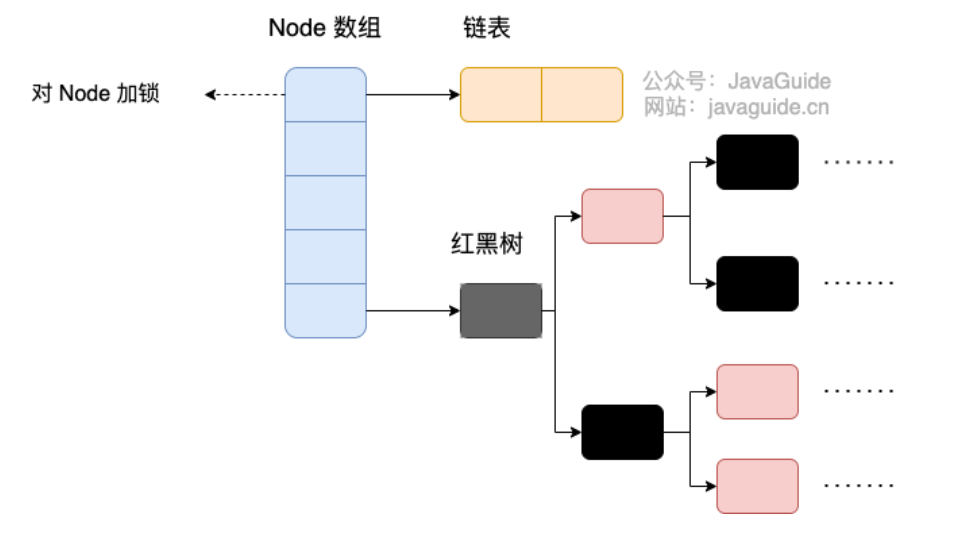
关于设计模式、Java基础面试题
前言 之前为了准备面试,收集整理了一些面试题。 本篇文章更新时间2023年12月27日。 最新的内容可以看我的原文:https://www.yuque.com/wfzx/ninzck/cbf0cxkrr6s1kniv 设计模式 单例共有几种写法? 细分起来就有9种:懒汉&#x…...

Python爱心光波完整代码
文章目录 环境需求完整代码详细分析环境需求 python3.11.4PyCharm Community Edition 2023.2.5pyinstaller6.2.0(可选,这个库用于打包,使程序没有python环境也可以运行,如果想发给好朋友的话需要这个库哦~)【注】 python环境搭建请见:https://want595.blog.csdn.net/arti…...

PowerShell Instal 一键部署gitea
gitea 前言 Gitea 是一个轻量级的 DevOps 平台软件。从开发计划到产品成型的整个软件生命周期,他都能够高效而轻松的帮助团队和开发者。包括 Git 托管、代码审查、团队协作、软件包注册和 CI/CD。它与 GitHub、Bitbucket 和 GitLab 等比较类似。 Gitea 最初是从 Gogs 分支而来…...
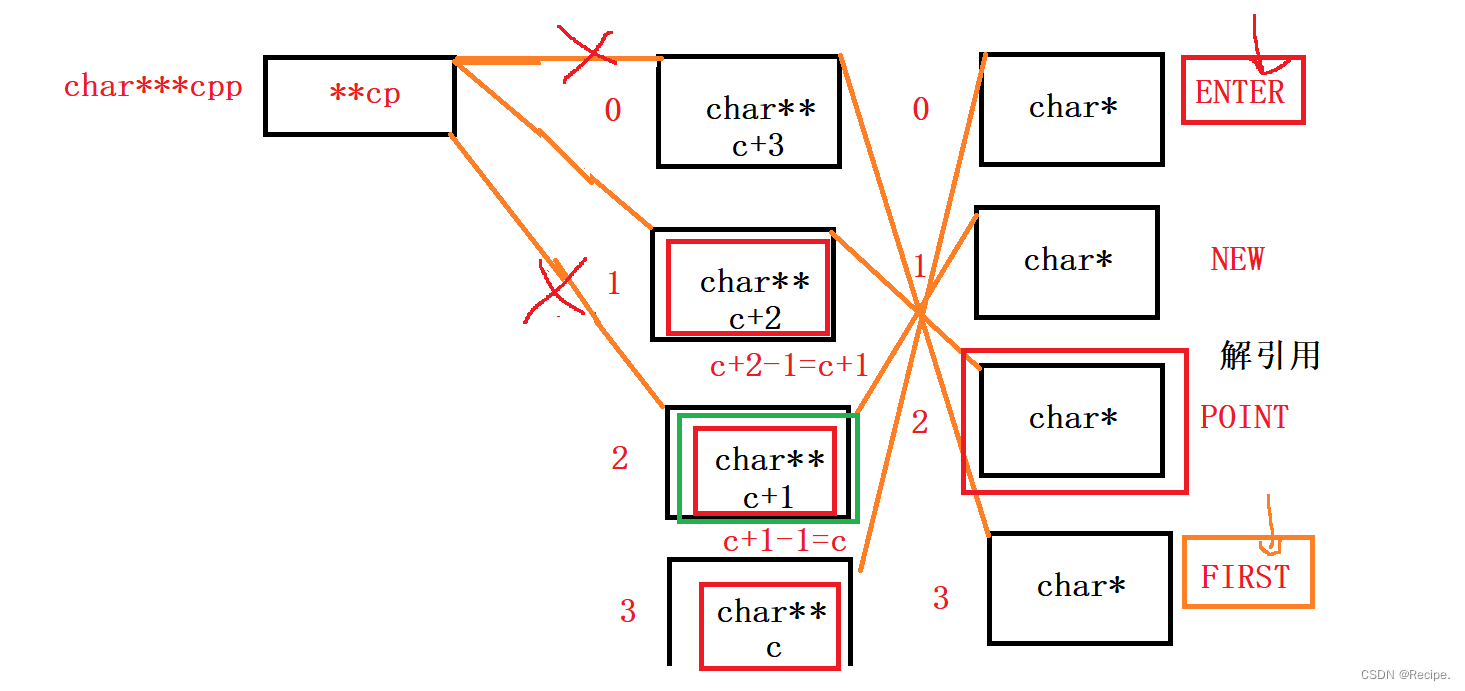
C语言——指针题目“指针探测器“
如果你觉得你指针学的自我感觉良好,甚至已经到达了炉火纯青的地步,不妨来试试这道题目? #include<stdio.h> int main() {char* c[] { "ENTER","NEW","POINT","FIRST" };char** cp[] { c 3…...
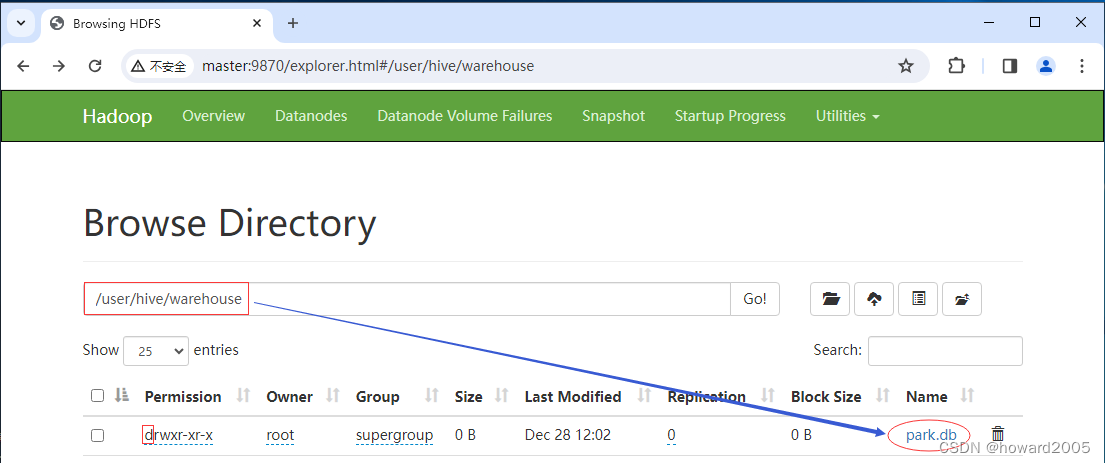
Hive讲课笔记:内部表与外部表
文章目录 一、导言二、内部表1.1 什么是内部表1.1.1 内部表的定义1.1.2 内部表的关键特性 1.2 创建与操作内部表1.2.1 创建并查看数据库1.2.2 在park数据库里创建student表1.2.3 在student表插入一条记录1.2.4 通过HDFS WebUI查看数据库与表 三、外部表2.1 什么是外部表2.2 创建…...

Docker本地部署开源浏览器Firefox并远程访问进行测试
文章目录 1. 部署Firefox2. 本地访问Firefox3. Linux安装Cpolar4. 配置Firefox公网地址5. 远程访问Firefox6. 固定Firefox公网地址7. 固定地址访问Firefox Firefox是一款免费开源的网页浏览器,由Mozilla基金会开发和维护。它是第一个成功挑战微软Internet Explorer浏…...

PHP:服务器端脚本语言的瑰宝
PHP(Hypertext Preprocessor)是一种广泛应用于服务器端编程的开源脚本语言,它以其简单易学、灵活性和强大的功能而成为Web开发的瑰宝。本文将深入介绍PHP的历史、特性、用途以及与生态系统的关系,为读者提供对这门语言全面的了解。…...

【MySQL】数据库并发控制:悲观锁与乐观锁的深入解析
🍎个人博客:个人主页 🏆个人专栏: 数 据 库 ⛳️ 功不唐捐,玉汝于成 目录 前言 正文 悲观锁(Pessimistic Locking): 乐观锁(Optimistic Locking): 总结&#x…...

作业--day38
1.定义一个Person类,包含私有成员,int *age,string &name,一个Stu类,包含私有成员double *score,Person p1,写出Person类和Stu类的特殊成员函数,并写一个Stu的show函数ÿ…...

pytest 的 fixture 固件机制
一、前置说明 固件(fixture)是一些函数,pytest 会在执行测试函数之前(或之后)加载运行它们。pytest 使用 fixture 固件机制来实现测试的前置和后置操作,可以方便地设置和共享测试环境。 二、操作步骤 1. 编写测试代码 atme/demos/demo_pytest_tutorials/test_pytest_…...

分布式技术之分布式计算Stream模式
文章目录 什么是 Stream?Stream 工作原理Storm 的工作原理 实时性任务主要是针对流数据的处理,对处理时延要求很高,通常需要有常驻服务进程,等待数据的随时到来随时处理,以保证低时延。处理流数据任务的计算模式&#…...

2023年12月GESP Python五级编程题真题解析
【五级编程题1】 【试题名称】:小杨的幸运数 【问题描述】 小杨认为,所有大于等于a的完全平方数都是他的超级幸运数。 小杨还认为,所有超级幸运数的倍数都是他的幸运数。自然地,小杨的所有超级幸运数也都是幸运数。 对于一个…...
探索Apache Commons Imaging处理图像
第1章:引言 大家好,我是小黑,咱们今天来聊聊图像处理。在这个数字化日益增长的时代,图像处理已经成为了一个不可或缺的技能。不论是社交媒体上的照片编辑,还是专业领域的图像分析,图像处理无处不在。而作为…...

OSI七层模型的意义:网络世界的工程思维密码
理解七层网络模型(OSI模型)的意义,不在于死记硬背哪一层叫什么名字,而在于它能帮你建立一套拆解复杂系统的思维框架。具体来说,学习它主要有以下几层价值:1. 建立“分而治之”的工程思维网络通信是一个极其…...

CTF逆向实战:从RC4到Base64,手把手拆解CTFshow赛题
1. RC4加密实战:从文件分析到密钥破解 第一次接触CTF逆向题时,看到RC4加密可能会觉得无从下手。但实际拆解后你会发现,这类题目往往藏着明显的突破口。就拿CTFshow这道re2赛题来说,整个解题过程就像在玩解谜游戏。 用IDA打开题目…...

如何跨越语言盲区,让学术表达精准落地
当我们完成了精妙的实验设计,获得了宝贵的数据,准备向世界展示科研成果时,却常常在“最后一公里”遭遇阻碍。这种阻碍并非源于科研本身的深度,而是来自于语言表达的信心不足与自查盲区。你是否也有过这样的经历:对着屏…...

【西瓜带你学设计模式 | 第四期 - 抽象工厂模式】抽象工厂模式 —— 定义、核心结构、实战示例、优缺点与适用场景及模式区别
文章目录前言1. 抽象工厂模式是什么?2. 解决什么问题?2.1 有多个“产品维度”,并且需要成套切换2.2 变化点分散导致代码难维护3. 核心结构4. 示例4.1 抽象产品:Slice(切片)4.2 抽象产品:Pulp&am…...

LangChain 1.0 中间件实战:5个钩子函数让你的Agent像专业工程师一样思考
LangChain 1.0中间件深度实践:5个钩子函数打造工程级Agent思维 当我们在2023年首次接触LangChain时,它还是一个以Chain为核心的实验性框架。如今,LangChain 1.0的发布标志着AI Agent开发正式进入生产就绪阶段。本文将带您深入探索其最具革命性…...

intv_ai_mk11效果对比:同一Prompt下intv_ai_mk11与Qwen2.5在代码生成任务表现
intv_ai_mk11效果对比:同一Prompt下intv_ai_mk11与Qwen2.5在代码生成任务表现 1. 测试背景与目的 在当今AI技术快速发展的背景下,代码生成已成为大语言模型的重要应用场景之一。本次测试旨在对比intv_ai_mk11与Qwen2.5两款模型在相同Prompt下的代码生成…...
)
【课后习题答案】SystemVerilog for Verification 3rd Edition第五章(绿皮书第三版)
1 解答class MemTrans;// a. 8位logic类型的data_inlogic [7:0] data_in;// b. 4位logic类型的addresslogic [3:0] address;// c. 打印data_in和address的void函数function void print();$display("data_in 0x%h, address 0x%h", data_in, address);endfunction// …...

Zotero重复条目智能处理指南:从混乱到有序的文献管理解决方案
Zotero重复条目智能处理指南:从混乱到有序的文献管理解决方案 【免费下载链接】ZoteroDuplicatesMerger A zotero plugin to automatically merge duplicate items 项目地址: https://gitcode.com/gh_mirrors/zo/ZoteroDuplicatesMerger 学术研究中ÿ…...

Cassandra在大数据图像存储中的应用探索
Cassandra在大数据图像存储中的应用探索关键词:Cassandra、大数据、图像存储、分布式系统、数据管理摘要:本文旨在深入探索Cassandra在大数据图像存储领域的应用。我们将先介绍Cassandra的基本概念和特点,再详细分析它与大数据图像存储的适配…...

AD20 原理图与PCB的协同设计:从单向更新到双向同步的进阶指南
1. AD20协同设计的基础概念 刚接触AD20时,最让我头疼的就是原理图和PCB之间的同步问题。记得第一次做多板卡项目,光是处理不同原理图之间的元件冲突就折腾了一整天。AD20的协同设计功能远比我们想象的强大,但要用好它,得先理解几个…...