Python中的数据序列
Python中的数据序列
一、作业回顾
1、求幸运数字6
幸运数字6(只要是6的倍数):输入任意数字,如数字8,生成nums列表,元素值为1~8,从中选取幸运数字移动到新列表lucky,打印nums与lucky。
# 第一步:定义二个空列表
nums = []
lucky = []
# 第二步:提示用户输入数字
num = int(input('请输入您要输入的数字:'))
# 第三步:生成nums列表(把1到num)所有的数据都追加到nums列表中
for i in range(1, num+1):nums.append(i)
# 第四步:对nums进行遍历操作,获取幸运数字
for i in nums:if i % 6 == 0:# 幸运数字从nums中删除nums.remove(i)# 把幸运数字写入到lucky列表中lucky.append(i)
# 第五步:打印nums和lucky
print(nums)
print(lucky)
2、把8名讲师随机分配到3个教室
列表嵌套:有3个教室[[],[],[]],8名讲师[‘A’,‘B’,‘C’,‘D’,‘E’,‘F’,‘G’,‘H’],将8名讲师随机分配到3个教室中。
分析:
思考1:我们第一间教室、第二间教室、第三间教室,怎么表示
rooms = [[],[],[]]
# 第一间教室
rooms[0]
# 第二间教室
rooms[1]
# 第三间教室
rooms[2]
思考2:我们如何一次从8名老师中,读出一个人
答:使用while或for进行遍历操作
思考3:我们如何在每次循环读取讲师的过程中,将其随机写入到某个教室?
rooms[0或1或2] = 读取的讲师信息
综合代码:
import random# 1、定义3间教室以及8名讲师
rooms = [[], [], []]
teachers = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H']
# 2、对所有的讲师进行遍历操作
for teacher in teachers:# 3、生成随机数index = random.randint(0, 2)rooms[index].append(teacher)
# 3、输出每个教室的讲师信息
# print(rooms)
i = 1
for room in rooms:print(f'第{i}个教室中的讲师:{room}')i += 1
3、知识点补充
字符串:split()方法
作用:根据指定字符对字符串进行分割操作,其返回一个列表
fruit = 'apple-banana-orange'
print(fruit.split('-'))
字符串:join()方法
作用:和split()方法正好相反,其主要功能是把序列拼接为字符串
字符串.join(数据序列)
案例:把水果列表[‘apple’, ‘banana’, ‘orange’]拼接成’apple-banana-orange’
list1 = ['apple', 'banana', 'orange']
print('-'.join(list1))
二、元组的定义与使用
1、为什么需要元组
思考:如果想要存储多个数据,但是这些数据是不能修改的数据,怎么做?
答:列表?列表可以一次性存储多个数据,但是列表中的数据允许更改。
num_list = [10, 20, 30]
num_list[0] = 100
那这种情况下,我们想要存储多个数据且数据不允许更改,应该怎么办呢?
答:使用元组,元组可以存储多个数据且元组内的数据是不能修改的。
2、元组的定义
元组特点:定义元组使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据类型。
基本语法:
# 多个数据元组
tuple1 = (10, 20, 30)# 单个数据元组
tuple2 = (10,)
注意:如果定义的元组只有一个数据,那么这个数据后面也要添加逗号,否则数据类型为唯一的这个数据的数据类型。
3、元组的相关操作方法
由于元组中的数据不允许直接修改,所以其操作方法大部分为查询方法。
| 编号 | 函数 | 作用 |
|---|---|---|
| 1 | 元组[索引] | 根据索引下标查找元素 |
| 2 | index() | 查找某个数据,如果数据存在返回对应的下标,否则报错,语法和列表、字符串的index方法相同 |
| 3 | count() | 统计某个数据在当前元组出现的次数 |
| 4 | len() | 统计元组中数据的个数 |
案例1:访问元组中的某个元素
nums = (10, 20, 30)
print(nums[2])
案例2:查找某个元素在元组中出现的位置,存在则返回索引下标,不存在则直接报错
nums = (10, 20, 30)
print(nums.index(20))
案例3:统计某个元素在元组中出现的次数
nums = (10, 20, 30, 50, 30)
print(nums.count(30))
案例4:len()方法主要就是求数据序列的长度,字符串、列表、元组
nums = (10, 20, 30, 50, 30)
print(len(nums))
三、字典——Python中的查询神器
1、为什么需要字典
思考1:比如我们要存储一个人的信息,姓名:Tom,年龄:20周岁,性别:男,如何快速存储。
person = ['Tom', '20', '男']
思考2:在日常生活中,姓名、年龄以及性别同属于一个人的基本特征。但是如果使用列表对其进行存储,则分散为3个元素,这显然不合逻辑。我们有没有办法,将其保存在同一个元素中,姓名、年龄以及性别都作为这个元素的3个属性。
答:使用Python中的字典
2、Python中字典(dict)的概念
特点:
① 符号为大括号(花括号) => {}
② 数据为键值对形式出现 => {key:value},key:键名,value:值,在同一个字典中,key必须是唯一(类似于索引下标)
③ 各个键值对之间用逗号隔开
定义:
# 有数据字典
dict1 = {'name': 'Tom', 'age': 20, 'gender': '男'}# 空字典
dict2 = {}dict3 = dict()
3、字典的增操作
基本语法:
字典名称[key] = value
注:如果key存在则修改这个key对应的值;如果key不存在则新增此键值对。
案例:定义一个空字典,然后添加name、age以及address这样的3个key
# 1、定义一个空字典
person = {}
# 2、向字典中添加数据
person['name'] = '刘备'
person['age'] = 40
person['address'] = '蜀中'
# 3、使用print方法打印person字典
print(person)
注意:列表、字典为可变类型
相关文章:

Python中的数据序列
Python中的数据序列 一、作业回顾 1、求幸运数字6 幸运数字6(只要是6的倍数):输入任意数字,如数字8,生成nums列表,元素值为1~8,从中选取幸运数字移动到新列表lucky,打印nums与lucky。 # 第一步:定义二个空列表 nums = [] lucky = [] # 第二步:提示用户输入数字 n…...

带您了解目前AI在测试领域能够解决的那些问题
AI在测试领域主要应用场景 话不多说,直接给结论: 接口测试脚本的自动生成和校验(依赖研发ai工具)测试用例的自动生成UI自动化测试脚本的自动生成和校验测试文档的自动生成快速了解初涉的业务领域 关于ai对研发和测试的整体影响…...
——时间参数化time)
Jmeter学习总结(2)——时间参数化time
13位的时间戳精确都毫秒级别。 常用的时间定义格式如下: log.info("${__time(,ts)}"); log.info("${ts}"); log.info(vars.get("ts")); //136232232232log.info("${__time(yyyy-MM-dd,)}"); //当前年月日2023-12-2…...

Leetcode 746 使用最小花费爬楼梯
题意理解: 给你一个整数数组 cost ,其中 cost[i] 是从楼梯第 i 个台阶向上爬需要支付的费用。 一旦你支付此费用,即可选择向上爬一个或者两个台阶。 你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯 目标:使用最小的花…...

2023/12/21作业
思维导图 代码 .text .global _start _start: 灯1 gpio时钟使能 [4]->1 0x5000A28 LDR R0,0x50000A28 指定寄存器地址 LDR R1,[R0]将寄存器取出放到R1 ORR R1,R1,#(0x1<<4)将第四位设置为1 STR R1,[R0]读取R0寄存器到R1 PE…...
)
Python 数据类型 (2)
1 集合类型:一维数组的集合 List列表是一个有序且可变的集合。允许重复成员。 turple元组是一个有序且不可更改的集合。允许重复成员。 Set集合是一个无序且无索引的集合。没有重复的成员。 dict字典是一个有序*且可变的集合。没有重复的成员。 !&#x…...

【教程】自动检测和安装Python脚本依赖的第三方库
转载请注明出处:小锋学长生活大爆炸[xfxuezhang.cn] 背景说明 对于新python环境,要运行某个脚本,可能需要安装很多库,一般可以通过提供的requirements.txt来自动安装。但如果没有这个txt,那就得手动一个一个安装&#…...
0开始配置Cartographer建图和导航定位
0开始配置Cartographer 日期:12-19 硬件:激光雷达IMU 小车的tf变换: 建图配置 lua文件配置:my_robot.lua include "map_builder.lua" include "trajectory_builder.lua"options {map_builder MAP_BUILDE…...

Python中使用SQLite数据库的方法2-2
3.3.2 创建表单及字段 通过“3.2 创建Cursor类的对象”中创建的Cursor类的对象cur创建表单及字段,代码如图5所示。 图5 创建表单及字段 从图5中可以看出,通过Cursor类的对象cur调用了Cursor类的execute()方法来执行SQL语句。该方法的参数即为要指定的S…...

零代码也能玩出花:Mugeda在H5设计中的魔法力量
文章目录 一、Mugeda零代码可视化H5设计工具简介二、Mugeda零代码可视化H5设计实战案例1. 注册并登录Mugeda账号2. 选择模板3. 编辑页面内容4. 添加动画效果5. 预览和发布 三、Mugeda零代码可视化H5设计的优势《Mugeda零代码可视化H5设计实战》内容简介作者简介目录前言/序言 随…...
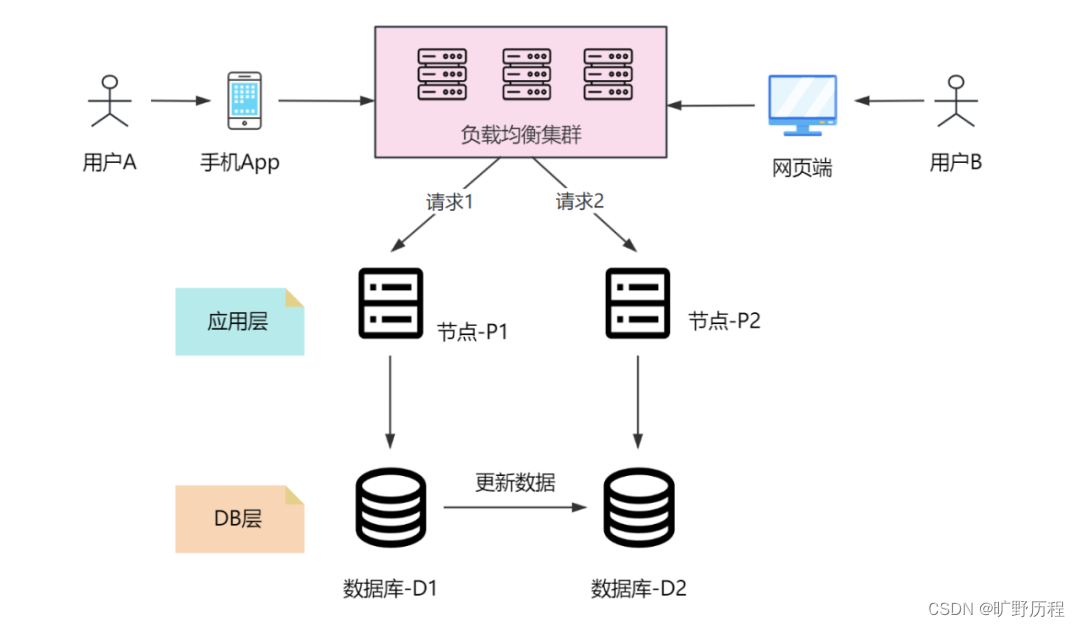
分布式、CAP 和 BASE 理论
在计算机科学领域,分布式系统是一门极具挑战性的研究方向,也是互联网应用中必不可少的优化实践,而 CAP 理论和 BASE 理论则是分布式系统中的两个关键的概念。 什么是分布式系统 首先,让我们来谈谈分布式系统。你可以将分布式系统…...

django之drf框架(两个视图基类、5个扩展视图类、9个视图子类)
两个视图基类 APIView和GenericAPIView drf提供的最顶层的父类就是APIView,以后所有的类都继承自他 GenericAPIView继承自APIView,他里面封装了一些工能 基于APIViewModelSerializerResposne写5个接口 子路由:app01>>>urls.py …...

23种设计模式学习
设计模式的分类 总体来说设计模式分为三大类: 创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。 结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合…...

php 8.4 xdebug扩展编译安装方法
最新版php8.4 xdebug扩展只能通过编译方式安装, pecl是安装不了的, 编译方法如下 下载最新版xdebug git clone https://github.com/xdebug/xdebug.git 却换入xdebug目录执行编译安装xdebug cd xdebug phpize./configure --enable-xdebugmakemake install3. 配置启用xdebug 这…...

66biolinks v42.0.0 已注册 – 生物短链接、URL 缩短器、QR 码和 Web 工具 (SAAS) 源码
66biolinks v42.0.0:全能生物短链接与网络工具平台 一、开篇介绍 66biolinks v42.0.0是一款集生物链接、URL缩短器、二维码和网络工具于一体的综合性软件解决方案。作为社交生物链接平台的佼佼者,66biolinks提供了全方位的功能,旨在满足用户…...

《Vue2.X 进阶知识点》- 防 ElementUI Divider 分割线
前言 使用 el-divider 背景为白色是没问题的。 但当背景换成其它颜色,问题就出现了!! 仔细看原来是两层,默认背景色是白色。 想着把背景色改为透明应该能用,结果发现背面是一条实线,难怪要用白色遮挡…不符…...

【第十二课】KMP算法(acwing-831 / c++代码 / 思路 / 视频+博客讲解推荐)
目录 暴力做法 代码如下 KMP算法 不同的next求法-----视频讲解/博客推荐 视频推荐 博客推荐 课本上的方法- prefix的方法- 求next数组思路---next数组存放前缀表的方式 s和p匹配思路 代码如下 暴力做法 遍历s主串中每一个元素,如果该元素等于模板串p中…...

JSON 简介
JSON是什么?(了解) JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,常用于Web应用程序之间的数据传输。 JSON格式是一种文本格式,用于描述数据的结构和内容。它由两种基本元素组成:键值对和…...

Impala4.x源码阅读笔记(三)——Impala如何管理Iceberg表元数据
前言 本文为笔者个人阅读Apache Impala源码时的笔记,仅代表我个人对代码的理解,个人水平有限,文章可能存在理解错误、遗漏或者过时之处。如果有任何错误或者有更好的见解,欢迎指正。 上一篇文章Impala4.x源码阅读笔记࿰…...

Ubuntu2204配置samba
0.前情说明 samba服务器主要是用来局域网共享文件的,如果想公网共享可能行不通,我已经踩坑一天了 所以说如果你想满足公网samba共享你就可以不要看下去了 1.参考连接 Ubuntu 安装 Samba 服务器_ubuntu安装samba服务器-CSDN博客 2.安装samba服务 sud…...

Navicat导入Excel实战:从数据准备到成功入库的完整避坑指南
1. 数据准备:Excel规范整理实战 第一次用Navicat导入Excel时,我对着报错提示整整折腾了两小时。后来才发现,90%的问题都出在数据准备阶段。就像做饭前要洗菜切配,数据导入前也需要做好这些准备工作: 字段命名要像给变量…...

BetterRTX终极指南:三步免费提升Minecraft画质的完整方案
BetterRTX终极指南:三步免费提升Minecraft画质的完整方案 【免费下载链接】BetterRTX-Installer The Powershell Installer for BetterRTX! BetterRTX is a Ray-Tracing mod for Minecraft Bedrock. 项目地址: https://gitcode.com/gh_mirrors/be/BetterRTX-Insta…...

嵌入式固件安全更新与密钥管理实践
1. 嵌入式固件安全更新概述在嵌入式系统开发中,固件更新是设备生命周期管理的关键环节。不同于传统PC软件的更新,嵌入式设备的固件更新面临更多挑战:受限的计算资源、不稳定的通信环境、严苛的安全要求等。我曾参与过多个工业控制设备的OTA升…...
)
【Sora 2视频集成终极指南】:ChatGPT原生调用、API对接、帧级控制与多模态工作流落地实录(2024官方SDK首曝)
更多请点击: https://intelliparadigm.com 第一章:ChatGPT Sora 2视频集成功能详解 ChatGPT Sora 2 并非官方发布的模型名称,而是社区对 OpenAI 视频生成能力演进方向的一种泛称。当前(截至 2024 年中),O…...

PyTorch数据集加载进阶:除了CIFAR10,你的自定义数据该怎么准备?
PyTorch数据集加载进阶:从CIFAR10到自定义数据的深度实践 在深度学习项目中,数据准备往往比模型构建更耗时。许多开发者能熟练使用torchvision.datasets加载标准数据集,却对自定义数据束手无策。本文将带你深入PyTorch数据加载机制ÿ…...
:支持128K上下文+动态摘要锚点+引用溯源追踪)
大模型长文档理解新拐点已至(2026年Claude专项能力解密):支持128K上下文+动态摘要锚点+引用溯源追踪
更多请点击: https://intelliparadigm.com 第一章:大模型长文档理解新拐点已至:Claude 2026能力演进全景图 随着长上下文窗口突破200万token、原生支持跨页语义锚定与结构化元数据感知,Claude 2026标志着大模型对长文档的理解正式…...

掌握智能游戏存档管理:实现高效跨平台游戏进度迁移
掌握智能游戏存档管理:实现高效跨平台游戏进度迁移 【免费下载链接】XGP-save-extractor Python script to extract savefiles out of Xbox Game Pass for PC games 项目地址: https://gitcode.com/gh_mirrors/xg/XGP-save-extractor 你是否曾在Xbox Game Pa…...

实战指南:从零开始掌握Visual C++运行库一键修复的高效用法
实战指南:从零开始掌握Visual C运行库一键修复的高效用法 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist Visual C运行库是Windows系统中至关重要的组…...

激活沉睡用户:WPF应用的唤醒策略
在现代软件开发中,如何有效地激活沉睡用户是每个应用开发者都需要面对的问题。特别是对于WPF(Windows Presentation Foundation)应用来说,如何在用户不活跃一段时间后,重新唤醒他们的兴趣并引导他们回到应用中使用,是一个既有挑战又有策略性的任务。本文将介绍如何通过邮…...
)
嵌入式Linux开发:手把手教你交叉编译全套WiFi工具链(iwconfig, iw, wpa_supplicant, hostapd)
嵌入式Linux WiFi工具链深度实战:从交叉编译到系统集成 在嵌入式Linux开发中,WiFi功能实现往往是最具挑战性的环节之一。不同于桌面环境,嵌入式设备需要从底层开始构建完整的无线网络栈,这涉及到多个工具的协同工作。本文将带你深…...