用通俗易懂的方式讲解大模型:基于 Langchain 和 ChatChat 部署本地知识库问答系统
之前写了一篇文章介绍基于 LangChain 和 ChatGLM 打造自有知识库问答系统,最近该项目更新了0.2新版本,这个版本与之前的版本差别很大,底层的架构发生了很大的变化。
该项目最早是基于 ChatGLM 这个 LLM(大语言模型)来搭建的,但后来集成的 LLM 越来越多, 我估计项目团队也借此机会将项目名称改成了Langchain-Chatchat。版本更新之后,项目的部署方式也发生了变化,之前的部署方式已经不适用了,这里我将介绍一下新版本的部署方式。
机器配置
项目的部署需要一台 GPU 服务器,不管是云服务器还是本地服务器都可以,但是需要注意的是,服务器至少需要16G 的显存,太低的话项目会运行不起来。
关于云 GPU 服务器的选择可以参考我之前的文章这里不再赘述。
我选择的是在 AutoDL 服务器上部署。
通俗易懂讲解大模型系列
- 用通俗易懂的方式讲解大模型:使用 Docker 部署大模型的训练环境
- 用通俗易懂的方式讲解大模型:在 Ubuntu 22 上安装 CUDA、Nvidia 显卡驱动、PyTorch等大模型基础环境
- 用通俗易懂的方式讲解大模型:Llama2 部署讲解及试用方式
- 用通俗易懂的方式讲解大模型:LangChain 知识库检索常见问题及解决方案
- 用通俗易懂的方式讲解大模型:基于 LangChain 和 ChatGLM2 打造自有知识库问答系统
- 用通俗易懂的方式讲解大模型:代码大模型盘点及优劣分析
- 用通俗易懂的方式讲解大模型:Prompt 提示词在开发中的使用
技术交流
建了大模型技术交流群! 想要学习、技术交流、获取如下原版资料的同学,可以直接加微信号:mlc2060。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流

项目更新内容
Langchain-Chatchat 项目的更新内容可以参考这里[3],主要有以下几点:
使用 FastChat 提供开源 LLM 模型的 API
FastChat[4]是一个用于训练和评估遵循指令 LLM 的框架,可以将 LLM 部署为带有标准应用程序编程接口(API)的软件服务。
这个改动带来的最大变化就是,原来是部署 1 个服务(WebUI),现在需要部署 3 个服务,分别是 LLM API 服务、 Langchain Chatchat 本身的 API 服务和 WebUI 服务,这样的好处是可以将原先的内部服务都解耦出来,用户可以选择不同的服务来构建自己的应用。比如你的项目只需要用到 LLM,那么你只需要部署 LLM API 服务就可以了;或者是你想用自己的前端服务,那么你只需要部署 2 个 API 服务,然后自己写一个前端服务就可以。
接口参数根据 OpenAI API 接口形式接入
接口参数根据 OpenAI API 接口形式接入,让请求参数更加合理。比如以前对话 API 中的对话历史参数是一个二维数组,跟我们熟悉的 OpenAI API 参数差别很大,可以看下面的例子:
# 原 Langchain ChatGLM 的对话历史参数
history: [["你好", "你好,有什么可以帮到你"], ["1 加 1 等于几", "2"]]# OpenAI 的对话历史参数
messages: [{ "role": "user", "content": "你好" }, { "role": "assistant", "content": "你好,有什么可以帮到你" }]# 新版 Langchain Chatchat 的对话历史参数
history: [{ "role": "user", "content": "你好" }, { "role": "assistant", "content": "你好,有什么可以帮到你" }]
可以看到原来的参数形式是一个二维数组,每轮对话都会放到一个子数组中,包含用户和 AI 的对话信息,而 OpenAI 的参数形式是一个对象数组,每个对象包含对话的角色和对话的内容,这样的数据结构程序会更容易处理,新版的参数形式改成了 OpenAI 的这种形式,虽然字段名有些不一样。
使用 Streamlit 提供 WebUI 服务
原先是用Gadio来编写 WebUI 页面的,现在改成了Streamlit,Streamlit提供了创建更复杂应用程序的能力,而且它提供了丰富的组件库,并支持自定义组件,可以看到新版的页面更加美观。
项目中默认 LLM 模型改为 CHATGLM2-6B
原来默认用的 LLM 是 ChatGLM-6B,现在改成了 ChatGLM2-6B,ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,增加了更强大的性能,更长的上下文,更高效的推理和更开发的协议。
默认 Embedding 模型改为 M3E-BASE
原来的 Embedding 模型是 GanymedeNil/text2vec-large-chinese[5],现在改成了moka-ai/m3e-base[6],TEXT2VEC 和 M3E-BASE 都支持中文,但 M3E-BASE 对英文的支持更好,文件加载方式与文段划分方式也有调整,后续将重新实现上下文扩充,并增加可选设置。
项目部署
下面我们开始来部署 Langchain-Chatchat 项目。
项目初始化
下载项目代码,同时安装依赖,注意新版的依赖文件有 3 个,一个是 API 服务的依赖文件 requirements_api.txt,一个是 WebUI 服务的依赖文件 requirements_webui.txt,还有一个是整个项目的依赖文件 requirements.txt,因为我们前后端都要部署,所以我们要用整个项目的依赖文件来安装依赖:
git clone https://github.com/chatchat-space/Langchain-Chatchat.git
cd Langchain-Chatchat
pip install -r requirements.txt -i https://mirror.baidu.com/pypi/simple # 照例加上百度源提高下载速度
如果是第一次运行本项目,需要通过以下命令来初始化知识库:
$ python init_database.py --recreate-vs
模型下载
下载 ChatGLM2-6B 和 M3E-BASE 模型,这两个模型都在 HuggingFace 上,可以直接克隆仓库:
# 开启大文件下载
git lfs install
# 下载 ChatGLM2-6B
git clone https://huggingface.co/THUDM/chatglm2-6b
# 下载 M3E-BASE
git clone https://huggingface.co/moka-ai/m3e-base
项目配置修改
模型下载完成后接着修改配置文件,新版的项目提供了一个配置文件模板model_config.py.example文件,需要将其复制一份并重命名为model_config.py,然后修改里面的配置项:
cd Langchain-Chatchat
cp configs/model_config.py.example configs/model_config.py
然后修改model_config.py文件中的配置项,将模型的路径改成你自己的路径:
embedding_model_dict = {
- "m3e-base": "moka-ai/m3e-base",
+ "m3e-base": "/你的下载路径/m3e-base",llm_model_dict = {"chatglm2-6b": {
- "local_model_path": "THUDM/chatglm2-6b",
+ "local_model_path": "/你的下载地址/chatglm2-6b",
LLM API 服务部署
执行以下命令启动 LLM API 服务:
python server/llm_api.py
注意: llm_api.py 中的openai_api_port端口要和configs/model_config.py中 LLM 的服务端口保持一致,否则接口调用会报错。另外如果你是在 AutoDL 的服务器上部署的话,服务器的8888端口会被Juypter服务占用,建议改成其他端口,代码实例如下:
# llm_api.py
openai_api_port = 7777 # 如果你是用AutoDL服务器的话,这个端口不要用8888# configs/model_config.py"chatglm-6b": {"local_model_path": "/你的下载地址/chatglm-6b","api_base_url": "http://localhost:7777/v1", # 这里的端口要和上面的openai_api_port保持一致"api_key": "EMPTY"
},
服务启动后,实际会启动 3 个子服务,端口分别是8888(上面我们改成了7777)、20001、20002,其中8888端口的服务是 LLM 的接口服务,里面提供了文本推理、embedding、token 检查等接口,跟 OpenAI 的接口十分相似。其他 2 个端口的服务我理解是对 LLM 服务的一些监控和管理。
如果启动服务后发现调用接口异常,可以在本地通过 curl 命令对8888端口的服务进行测试。
API 服务部署
执行以下命令启动 API 服务:
python server/api.py
这个服务主要提供了 Langchain Chatchat 的功能接口,包括 LLM 问答、知识库问答、知识库管理等接口。同样地,我们也可以通过 curl 命令对该服务进行测试,服务的端口默认是 7861。
WebUI 服务部署
最后是启动 WebUI 服务,执行以下命令启动 WebUI 服务,默认的端口号是8501,可以通过--server.port参数来修改端口:
streamlit run webui.py --server.port 6006
我在启动 WebUI 服务时还遇到一个问题,就是启动服务时报了protobuf这个依赖包版本不对的错误,导致 Web 服务启动失败,后面我将protobuf的版本降级成了3.20.3就可以正常启动了。
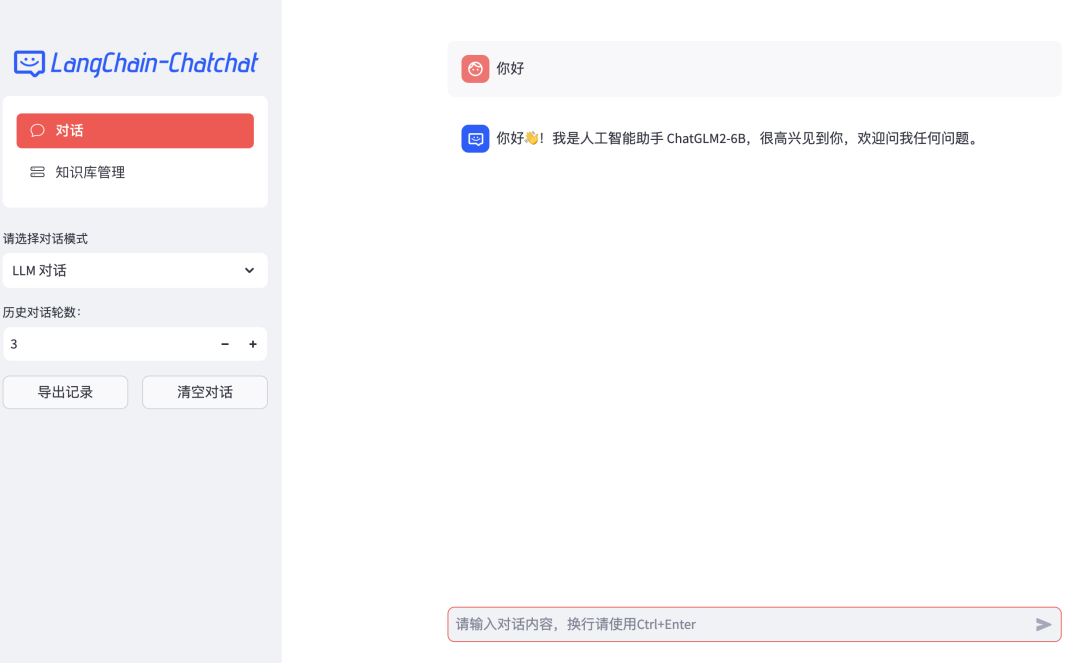
启动后可以通过浏览器访问 WebUI 服务,界面如下所示:
其他未测试的部署方式
因为项目新版本才刚发布,我还没有对所有部署方式进行试用,比如对于 API 服务,除了单独启动服务外,还有一个api_allinone.py的文件,我理解是用来同时启动 LLM API 服务和 API 服务的。还有一个webui_allinone.py的文件,应该是用来同时启动所有服务的。这些功能可以让我们更加方便的部署项目,大家可以自行验证这些部署方式。
由于新版本刚发布,新版本的功能可能存在不少问题,在项目的 issue 区可以看到大量新版本的问题,包括服务启动不起来,或者是启动起来之后 Web 页面没有反应等问题,这些问题应该都是可以解决的,只是需要再给项目团队一些时间。
总结
AI 知识库问答系统是一个很有前景的方向,它是对传统知识库系统的一种升级,相信在未来会有很多垂直领域的公司会用到这个技术。从 Langchain Chatchat 项目的发展过程上来看,项目从原来的一个 demo 级别的项目,逐渐向一个完整的产品迈进,在架构、UI 界面、LLM 集成方面也在不断完善,我相信这是一个未来可期的项目。而对于那些还在用老版本的小伙伴,建议尽快升级到新版本,因为项目团队以后的主要精力都会放在新版本的开发上,老版本的功能可能不会再更新了。
关注我,一起学习各种人工智能和 AIGC 新技术,欢迎交流,如果你有什么想问想说的,欢迎在评论区留言。
参考:
[3] https://github.com/chatchat-space/Langchain-Chatchat/releases/tag/v0.2.0_
[4]FastChat: https://github.com/lm-sys/FastChat
[5]GanymedeNil/text2vec-large-chinese: https://huggingface.co/GanymedeNil/text2vec-large-chinese
[6]moka-ai/m3e-base: https://huggingface.co/moka-ai/m3e-base
相关文章:
用通俗易懂的方式讲解大模型:基于 Langchain 和 ChatChat 部署本地知识库问答系统
之前写了一篇文章介绍基于 LangChain 和 ChatGLM 打造自有知识库问答系统,最近该项目更新了0.2新版本,这个版本与之前的版本差别很大,底层的架构发生了很大的变化。 该项目最早是基于 ChatGLM 这个 LLM(大语言模型)来…...

YOLO训练results.csv文件可视化(原模型与改进模型对比可视化)
一、单独一个文件可视化(源码对应utils文件夹下的plots.py文件的plot_results类) from pathlib import Path import matplotlib.pyplot as plt import pandas as pd def plot_results(fileruns/train/exp9/results.csv, dir):# Plot training results.c…...
uni-appcss语法
锋哥原创的uni-app视频教程: 2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中..._哔哩哔哩_bilibili2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中...共计23条视频,包括:第1讲 uni…...
java在线票务系统(选座)Myeclipse开发mysql数据库web结构java编程计算机网页项目
一、源码特点 java servlet 在线票务系统(选座)管理系统是一套完善的java web信息管理系统 系统采用serlvetdaobean(mvc模式),对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要…...

Python 简易图形界面库easygui 对话框大全(续)
目录 EasyGUI库 主要特点 使用场景 对话框样式 10. 文件打开框 fileopenbox 11. 文件保存框 filesavebox 12. 目录打开框 diropenbox 13. 索引对话框 indexbox 14. 例外报告框 exceptionbox 15. 代码文本框 codebox 16. 密码输入框 passwordbox 17. 多重文本框 mul…...

电容器50ZLH56MEFC6.3X11
电容器 常用电子元器件类型 50ZLH56MEFC6.3X11 文章目录 电容器前言一、电容器二、50ZLH56MEFC6.3X11总结前言 电容器在电子电路中有许多重要的应用,如滤波、耦合、储能、定时等。不同类型的电容器具有不同的性能特点,例如电容量、工作电压、频率响应等。在选择和使用电容…...

vscode 支持c,c++编译调试方法
概述:tasks.jason launch.json settings.json一定要有,没有就别想跑。还有就是c 和c配置有区别,切记,下文有说 1.安装扩展插件。 2.安装编译器,gcc.我用的是x86_64-8.1.0-release-win32-seh-rt_v6-rev0.7z …...
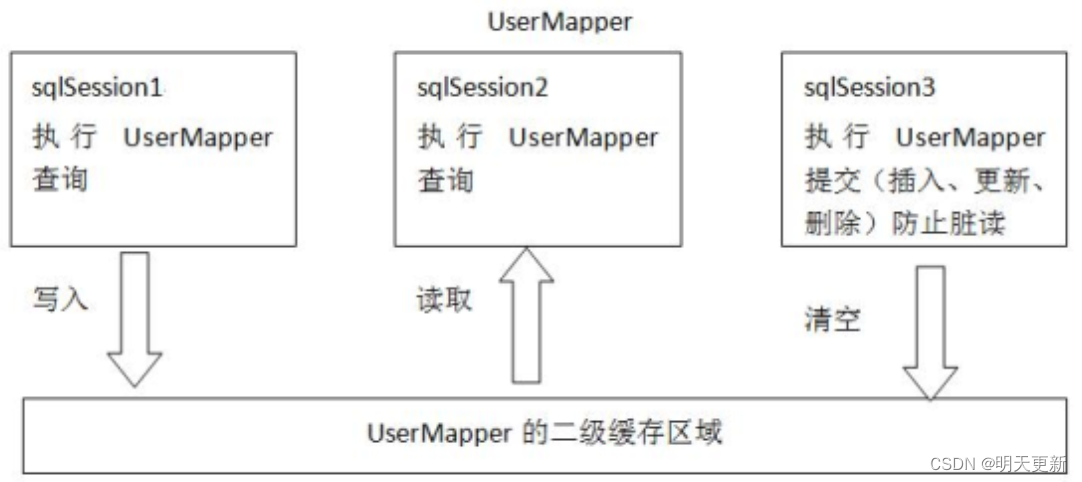
MyBatis的缓存!!!!
为什么使用缓存? 首次访问时,查询数据库,并将数据存储到内存中;再次访问时直接访问缓存,减少IO、硬盘读写次数、提高效率 Mybatis中的一级缓存和二级缓存? 一级缓存: 它指的是mybatis中的SqlSession对象的…...

ToB还是ToC?工业级与消费级AR眼镜都能干什么?
随着科技的飞速发展,增强现实(AR)技术逐渐融入我们的日常生活。我国AR眼镜消费市场分为消费级和工业级应用。其中消费级主要分为游戏、影视、直播以及社交购物与旅游;工业级主要应用于医疗、汽车、工业、船舶、电力和仓储等专业领…...
设计模式-Java版本
文章目录 前言设计原则单一职责原则开闭原则里氏替换原则迪米特法则接口隔离原则依赖倒置原则 设计模式构建类型工厂模式抽象工厂建造者模式原型模式单例模式 结构型适配器模式桥接模式组合模式装饰器模式代理模式外观模式享元模式 行为模式责任链模式命令模式迭代器模式中介模…...

数据库中如何修改和删除字段
PS:在"[ ]"中的所有数据都是可修改的 添加表字段 ALTER TABLE [表名] add [添加的新字段名] [添加新的数据类型] COMMENT [昵称] alter:修改(后面一般加table表示修改表) add:添加一个字段 在这个里面c…...

在 Golang 应用程序中管理多个数据库
掌握在 Golang 项目中处理多个数据库的艺术 在当前软件开发领域中,处理单个应用程序内的多个数据库的需求越来越普遍。具有强大功能的 Golang 是处理此类任务的绝佳解决方案,无论您是与多个数据源合作还是仅为增强组织和可扩展性而分隔数据。在本文中&a…...

理解开源协议GPL、MIT、BSD、Apache License
开源协议是一种法律文件,规定了使用、修改和分享开源软件的规则和条件。以下是一些常见的开源协议及其相同点和区别:GPL(GNU General Public License):GPL 是一种比较严格的开源协议,要求使用者如果对开源软…...

Talk | 北京大学博士生汪海洋:通向3D感知大模型的前置方案
本期为TechBeat人工智能社区第559期线上Talk。 北京时间12月28日(周四)20:00,北京大学博士生—汪海洋的Talk已准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “通向3D感知大模型的前置方案”,介绍了他的团队在3D视觉大模型的前置方…...
【C语言数组传参】规则详解
目录 数组传参介绍 数组传参规则 数组传参的实参 特殊情况一:sizeof(数组名) 特殊情况二:&数组名 数组传参的形参 数组传参使用数组名作为形参接收 形参如果是⼀维数组 形参如果是⼆维数组 数组传参使用指针作为形参…...

【Linux】Ubuntu22.04版本下实现gcc版本的快速切换
本文将介绍如何在Ubuntu22.04版本下实现gcc版本的快速切换。 本文首发于 ❄️慕雪的寒舍 前言 有的时候,不同版本的gcc会造成一些细微的差异,导致相关的一些工具不兼容,比如用于单元测试覆盖率生成的gcov/lcov工具,在不同的gcc版…...
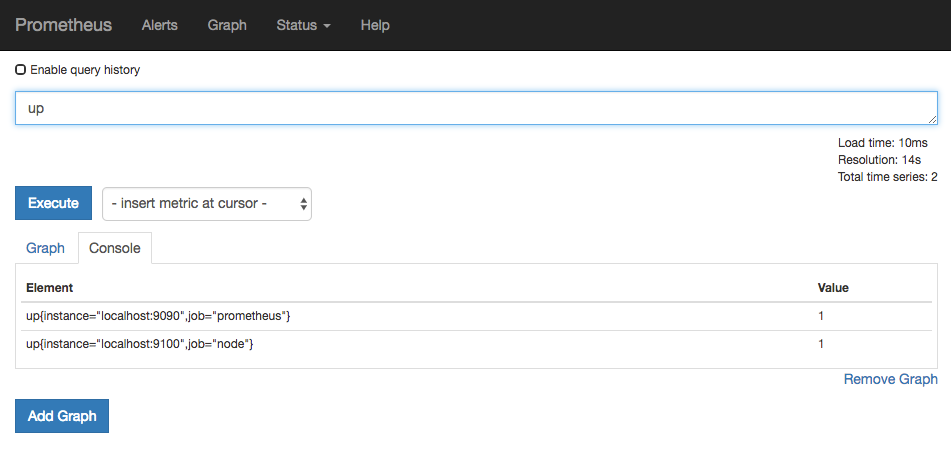
使用Node Exporter采集主机数据
安装 Node Exporter 在 Prometheus 的架构设计中,Prometheus Server 并不直接服务监控特定的目标,其主要任务负责数据的收集,存储并且对外提供数据查询支持。因此为了能够能够监控到某些东西,如主机的 CPU 使用率,我们…...
Django 文件上传(十二)
当 Django 处理文件上传时,文件数据最终会被放置在 request.FILES 。 查看文档:文件上传 | Django 文档 | Django Django工程如下: 创建本地存储目录 在static/应用目录下创建uploads目录用于存储接收上传的文件 在settings.py 配置静态目…...

k8s的陈述式资源管理
k8s的陈述式资源管理: 命令行:kubectl命令行工具 优点:90%以上的场景都可以满足 对资源的增,删,查比较方便,对改不是很友好 缺点: 命令比较冗长,复杂,难记 声明式&…...

electron-builder 打包exe后白屏
项目用的是An Electron application with Vue3 and TypeScript。 Debug运行项目没问题,可以显示页面。不过有浏览器控制台显示错误: Unable to load preload script:preload/index.js Unable to load preload script 翻译后:无法…...

3分钟高效恢复Windows 11 LTSC微软商店:完整解决方案指南
3分钟高效恢复Windows 11 LTSC微软商店:完整解决方案指南 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 你是否在使用Windows 11 24H2 LT…...

纯视觉纵深无感管控,落地硐室无人少人化透明值守模式技术白皮书
纯视觉纵深无感管控,落地硐室无人少人化透明值守模式技术白皮书副标题:摒弃井下繁杂传感布设,依靠暗光三维实景重构、深部空间无感感知、盲区跨镜无痕跟踪、身体指纹生物核验,实现井下 24 小时无人值守、全域透明运维前言矿山井下…...

碧蓝航线自动化脚本:让游戏管理变得轻松高效
碧蓝航线自动化脚本:让游戏管理变得轻松高效 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 你是否厌倦了每天重…...

Arm Morello平台模型与CHERI安全扩展开发指南
1. Arm Morello平台模型概述Morello是Arm公司推出的实验性处理器架构,基于CHERI(Capability Hardware Enhanced RISC Instructions)安全扩展技术。这个平台模型本质上是一个功能准确的虚拟硬件环境,允许开发者在物理芯片问世前18-…...

怎么找到一个行业的源头工厂、绕开中间商?一套五步识别流程
你下了单,货到了,质量也还行。但心里一直有个疙瘩:这家供应商到底是自己在生产,还是从别处转手赚了你一道差价? 这个问题对采购方和跨境卖家不是洁癖,是真金白银。同一款产品,源头工厂和中间商的…...

药物发现自动化:FEP计算工作流引擎faah的设计原理与实战
1. 项目概述:一个面向药物发现的自动化工作流引擎 最近在药物研发的自动化工具领域,一个名为 kiron0/faah 的项目引起了我的注意。这并非一个简单的脚本集合,而是一个设计精巧、旨在为药物发现中的自由能微扰计算提供端到端自动化解决方案的…...
)
保姆级教程:INCA 7.2.3 从新建工程到观测标定的完整流程(附A2L文件处理技巧)
INCA 7.2.3 全流程实战指南:从工程搭建到参数标定的深度解析 在汽车电子开发领域,标定工具链的掌握程度直接影响开发效率。作为行业标准的INCA软件,其7.2.3版本在工程管理、实时观测和参数标定方面提供了更完善的解决方案。本文将采用"操…...

免费开源鼠标连点器终极指南:5分钟掌握高效自动化技巧
免费开源鼠标连点器终极指南:5分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...

认识Python数据包套接字
如你所知,数据包格式套接字(Datagram Sockets)也叫“无连接的套接字”,在代码中使用 SOCK_DGRAM 表示。可以将 SOCK_DGRAM 比喻成高速移动的摩托车快递,它有以下特征:强调快速传输而非传输顺序;…...

AI智能体操作安卓设备:基于agent-droid-bridge的自动化实践
1. 项目概述:连接AI与安卓设备的桥梁 最近在折腾AI智能体(Agent)和自动化流程时,遇到了一个挺有意思的需求:如何让运行在服务器上的AI程序,直接去操作一台真实的安卓手机或模拟器,完成一些复杂的…...