Hive 数据倾斜
数据倾斜,即单个节点任务所处理的数据量远大于同类型任务所处理的数据量,导致该节点成为整个作业的瓶颈,这是分布式系统不可能避免的问题。从本质来说,导致数据倾斜有两种原因,一是任务读取大文件,二是任务需要处理大量相同键的数据 。
任务读取大文件,最常见的就是读取压缩的不可分割的大文件。任务需要处理大量相同键的数据,这种情况有以下4种表现形式:
-
数据含有大量无意义的数据,例如空值(NULL)、空字符串等
-
含有倾斜数据在进行聚合计算时无法聚合中间结果,大量数据都需要 经过Shuffle阶段的处理,引起数据倾斜
-
数据在计算时做多维数据集合,导致维度膨胀引起的数据倾斜
-
两表进行Join,都含有大量相同的倾斜数据键
1、不可拆分大文件引发的数据倾斜
当集群的数据量增长到一定规模,有些数据需要归档或者转储,这时候往往会对数据进行压缩;当对文件使用GZIP压缩等不支持文件分割操作的压缩方式,在日后有作业涉及读取压缩后的文件时,该压缩文件只会被一个任务所读取。如果该压缩文件很大,则处理该文件的Map需要花费的时间会 远多于读取普通文件的Map时间,该Map任务会成为作业运行的瓶颈。这种情况也就是Map读取文件的数据倾斜。例如存在这样一张表t_des_info 。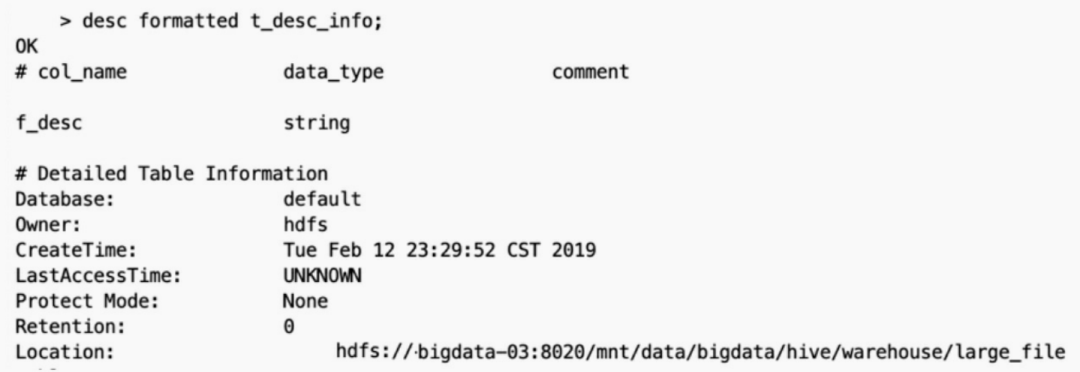 t_des_info表由3个GZIP压缩后的文件组成 。
t_des_info表由3个GZIP压缩后的文件组成 。 其中,
其中,large_file.gz文件约200MB,在计算引擎在运行时,预先设置每 个Map处理的数据量为128MB,但是计算引擎无法切分large_file.gz文件,所 以该文件不会交给两个Map任务去读取,而是有且仅有一个任务在操作 。
t_des_info表有3个gz文件,任何涉及处理该表的数据都只会使用3个 Map。
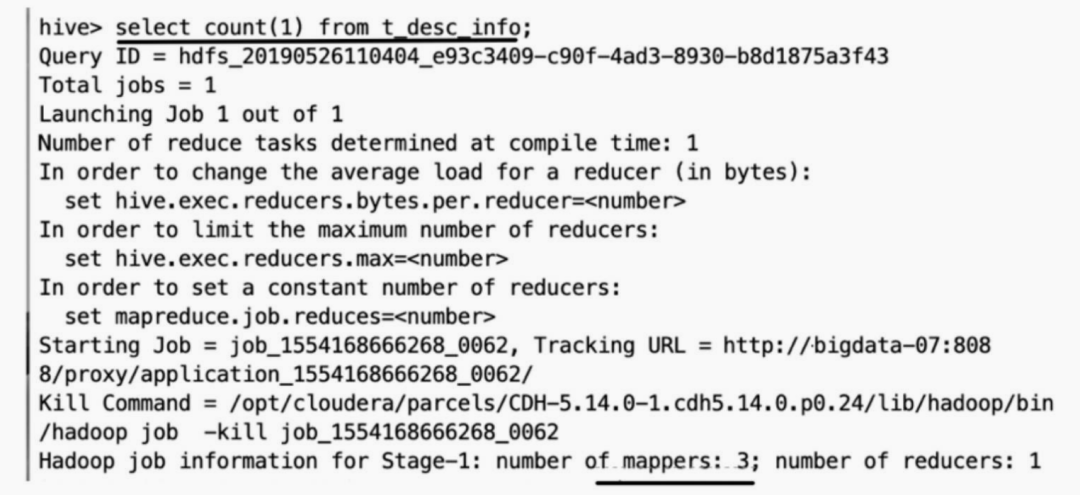 为避免因不可拆分大文件而引发数据读取的倾斜,在数据压缩的时 候可以采用
为避免因不可拆分大文件而引发数据读取的倾斜,在数据压缩的时 候可以采用bzip2和Zip等支持文件分割的压缩算法。
2、业务无关的数据引发的数据倾斜
实际业务中有些大量的NULL值或者一些无意义的数据参与到计算作业 中,这些数据可能来自业务未上报或因数据规范将某类数据进行归一化变成空值或空字符串等形式。这些与业务无关的数据引入导致在进行分组聚合或者在执行表连接时发生数据倾斜。对于这类问题引发的数据倾斜,在计算过 程中排除含有这类“异常”数据即可 。
3、 多维聚合计算数据膨胀引起的数据倾斜
在多维聚合计算时存在这样的场景:select a,b,c,count(1)from T group by a,b,c with rollup。对于上述的SQL,可以拆解成4种类型的键进行分组聚合,它们分别是(a,b,c)、(a,b,null)、(a,null,null) 和(null,null,null)。
如果T表的数据量很大,并且Map端的聚合不能很好地起到数据压缩的 情况下,会导致Map端产出的数据急速膨胀,这种情况容易导致作业内存溢 出的异常。如果T表含有数据倾斜键,会加剧Shuffle过程的数据倾斜 。
对上述的情况我们会很自然地想到拆解上面的SQL语句,将rollup拆解成如下多个普通类型分组聚合的组合。
select a, b, c, count(1) from T group by a, b, c; select a, b, null, count(1) from T group by a, b; select a, null, null, count(1) from T group by a; select null, null, null, count(1) from T; 这是很笨拙的方法,如果分组聚合的列远不止3个列,那么需要拆解的 SQL语句会更多。在Hive中可以通过参数 (hive.new.job.grouping.set.cardinality)配置的方式自动控制作业的拆解,该 参数默认值是30。该参数表示针对grouping sets/rollups/cubes这类多维聚合的 操作,如果最后拆解的键组合(上面例子的组合是4)大于该值,会启用新的任务去处理大于该值之外的组合。如果在处理数据时,某个分组聚合的列 有较大的倾斜,可以适当调小该值 。
4、无法削减中间结果的数据量引发的数据倾斜
在一些操作中无法削减中间结果,例如使用collect_list聚合函数,存在如下SQL:
SELECTs_age,collect_list(s_score) list_score
FROMstudent_tb_txt
GROUP BYs_age 在student_tb_txt表中,s_age有数据倾斜,但如果数据量大到一定的数 量,会导致处理倾斜的Reduce任务产生内存溢出的异常。针对这种场景,即 使开启hive.groupby.skewindata配置参数,也不会起到优化的作业,反而会拖累整个作业的运行。
启用该配置参数会将作业拆解成两个作业,第一个作业会尽可能将 Map 的数据平均分配到Reduce阶段,并在这个阶段实现数据的预聚合,以减少第二个作业处理的数据量;第二个作业在第一个作业处理的数据基础上进行结果的聚合。
hive.groupby.skewindata的核心作用在于生成的第一个作业能够有效减少数量。但是对于collect_list这类要求全量操作所有数据的中间结果的函数来说,明显起不到作用,反而因为引入新的作业增加了磁盘和网络I/O的负担,而导致性能变得更为低下 。
解决这类问题,最直接的方式就是调整Reduce所执行的内存大小,使用 mapreduce.reduce.memory.mb这个参数(如果是Map任务内存瓶颈可以调整 mapreduce.map.memory.mb)。但还存在一个问题,如果Hive的客户端连接 的HIveServer2一次性需要返回处理的数据很大,超过了启动HiveServer2设置的Java堆(Xmx),也会导致HiveServer2服务内存溢出。
5、两个Hive数据表连接时引发的数据倾斜
两表进行普通的repartition join时,如果表连接的键存在倾斜,那么在 Shuffle阶段必然会引起数据倾斜 。
遇到这种情况,Hive的通常做法还是启用两个作业,第一个作业处理没有倾斜的数据,第二个作业将倾斜的数据存到分布式缓存中,分发到各个 Map任务所在节点。在Map阶段完成join操作,即MapJoin,这避免了 Shuffle,从而避免了数据倾斜。
相关文章:
Hive 数据倾斜
数据倾斜,即单个节点任务所处理的数据量远大于同类型任务所处理的数据量,导致该节点成为整个作业的瓶颈,这是分布式系统不可能避免的问题。从本质来说,导致数据倾斜有两种原因,一是任务读取大文件,二是任务…...

2月刚上岸字节跳动测试岗面经
这时候发应该还不算太晚,金三银四找工作的小伙伴需要的可以看看。 一、测试工程师的工作是什么? 测试工程师简单点说就是找bug,然后反馈给开发人员,不要小看这个工作。 首先很明显的bug开发人员有时候自己就能找到,测…...
图解KMP算法
子串的定位操作通常称作串的模式匹配。你可以理解为在一篇英语文章中查找某个单词是否存在,或者说在一个主串中寻找某子串是否存在。朴素的模式匹配算法假设我们要从下面的主串S "goodgoogle" 中,找到T "google" 这个子串的位置。…...
Java Map和Set
目录1. 二叉排序树(二叉搜索树)1.1 二叉搜索树的查找1.2 二叉搜索树的插入1.3 二叉搜索树的删除(7种情况)1.4 二叉搜索树和TreeMap、TreeSet的关系2. Map和Set的区别与联系2.1 从接口框架的角度分析2.2 从存储的模型角度分析【2种模型】3. 关于Map3.1 Ma…...

【C/C++ 数据结构】-八大排序之 冒泡排序快速排序
作者:学Java的冬瓜 博客主页:☀冬瓜的主页🌙 专栏:【C/C数据结构与算法】 分享:那我便像你一样,永远躲在水面之下,面具之后! ——《画江湖之不良人》 主要内容:八大排序选…...

苹果ipa软件下载网站和软件的汇总
随着时间的流逝,做苹果版软件安装包下载网站和软件的渐渐多了起来。 当然,已经关站、停运、下架、倒闭的苹果软件下载网站和软件我就不说了,也不必多说那些关站停运下架倒闭的网站和软件了。 下面我统计介绍的就是苹果软件安装包下载网站和软…...
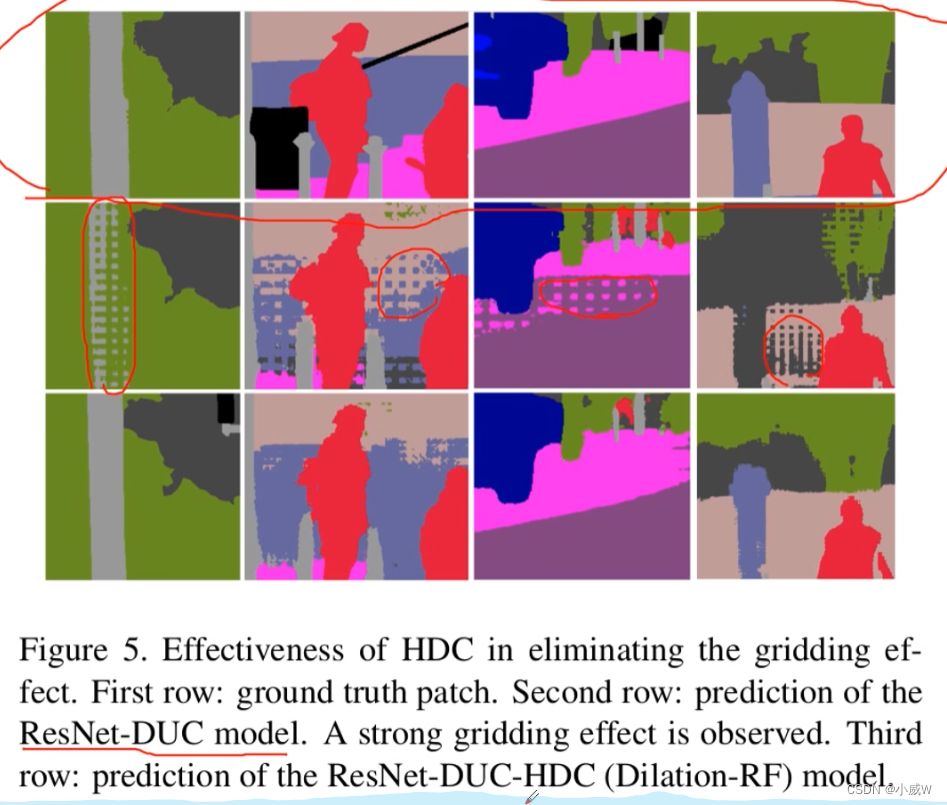
深度学习-【语义分割】学习笔记4 膨胀卷积(Dilated convolution)
文章目录膨胀卷积为什么需要膨胀卷积gridding effect连续使用三次膨胀卷积——1连续使用三次膨胀卷积——2连续使用三次膨胀卷积——3Understanding Convolution for Semantic Segmentation膨胀卷积 膨胀卷积,又叫空洞卷积。 左边是普通卷积,右边是膨胀…...

【10】SCI易中期刊推荐——工程技术-计算机:人工智能(中科院2区)
🚀🚀🚀NEW!!!SCI易中期刊推荐栏目来啦 ~ 📚🍀 SCI即《科学引文索引》(Science Citation Index, SCI),是1961年由美国科学信息研究所(Institute for Scientific Information, ISI)创办的文献检索工具,创始人是美国著名情报专家尤金加菲尔德(Eugene Garfield…...
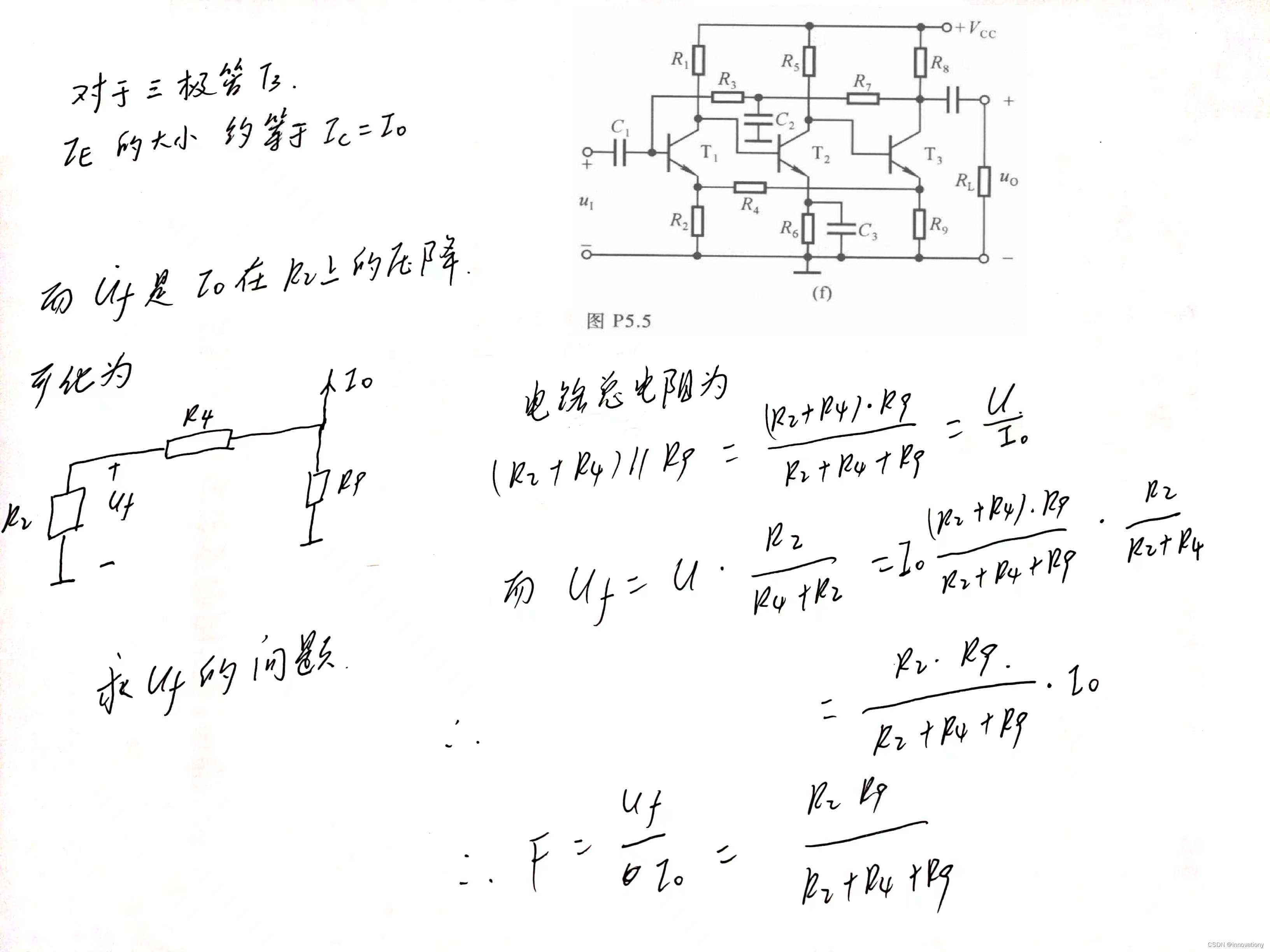
模电计算反馈系数,有时候转化为计算电阻分压的问题
模电计算反馈系数,有时候转化为计算电阻分压的问题 如果是电压反馈,F的除数是Uo 如果是电流反馈,F的除数是Io 串联反馈,F的分子是Uf 并联反馈,F的分子是If 点个赞呗,大家一起加油学习!...

专治Java底子差,不要再认为泛型就是一对尖括号了
文章目录一、泛型1.1 泛型概述1.2 集合泛型的使用1.2.1 未使用泛型1.2.2 使用泛型1.3 泛型类1.3.1 泛型类的使用1.2.2 泛型类的继承1.4 泛型方法1.5 泛型通配符1.5.1 通配符的使用1)参数列表带有泛型2)泛型通配符1.5.2 泛型上下边界1.6 泛型的擦除1.6.1 …...
PayPal轮询收款的那些事儿
想必做跨境电商独立站的小伙伴,对于PayPal是再熟悉不过了,PayPal是一个跨国际贸易的支付平台,对于做独立站的朋友来说跨境收款绝大部分都是依赖PayPal以及Stripe条纹了。简单来说PayPal跟国内的支付宝有点类似,但是PayPal它是跨国…...
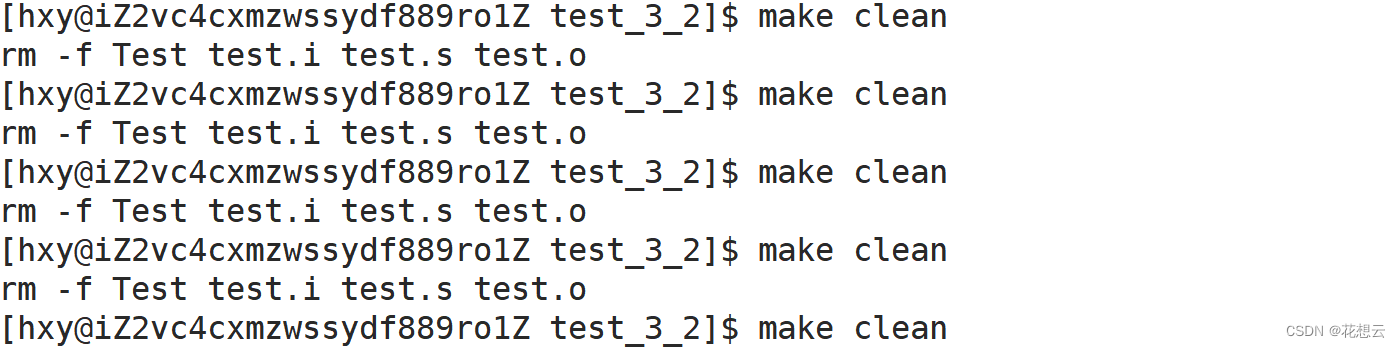
【Linux】项目自动化构建工具——make/Makefile
目录 1.make与Makefile的关系 Makefile make 项目清理 clean .PHONY 当我们编写一个较大的软件项目时,通常需要将多个源文件编译成可执行程序或库文件。为了简化这个过程,我们可以使用 make 工具和 Makefile 文件。Makefile 文件可以帮助我们自动…...

成本降低90%,OpenAI正式开放ChαtGΡΤ
今天凌晨,OpenAI官方发布ChαtGΡΤ和Whisper的接囗,开发人员现在可以通过API使用最新的文本生成和语音转文本功能。OpenAI称:通过一系列系统级优化,自去年12月以来,ChαtGΡΤ的成本降低了90%;现在OpenAI用…...

hls.js如何播放m3u8文件(实例)?
HLS(HTTP Live Streaming)是一种视频流传输协议,是苹果推出的适用于iOS与macOS平台的流媒体传输协议。它将视频分割成若干个小段,每个小段大小一般为2~10秒不等,并通过HTTP协议进行传输。通过在每个小段之间插入若干秒…...

大数据平台建设方法论集合
文章目录从0到1建设大数据解决方案大数据集群的方法论数据集成方法论机器学习算法平台方法论BI建设的方法论云原生大数据的方法论低代码数据中台的方法论大数据SRE运维方法论批流一体化建设的方法论数据治理的方法论湖仓一体化建设的方法论数据分析挖掘方法论数字化转型方法论数…...
25- 卷积神经网络(CNN)原理 (TensorFlow系列) (深度学习)
知识要点 卷积神经网络的几个主要结构: 卷积层(Convolutions): Valid :不填充,也就是最终大小为卷积后的大小. Same:输出大小与原图大小一致,那么N 变成了N2P. padding-零填充. 池化层(Subsampli…...

把数组里面数值排成最小的数
问题描述:输入一个正整数数组,将它们连接起来排成一个数,输出能排出的所有数字中最小的一个。例如输入数组{12, 567},则输出这两个能排成的最小数字12567。请给出解决问题的算法,并证明该算法。 思路:先将…...
云his系统源码 SaaS应用 基于Angular+Nginx+Java+Spring开发
云his系统源码 SaaS应用 功能易扩 统一对外接口管理 一、系统概述: 本套云HIS系统采用主流成熟技术开发,软件结构简洁、代码规范易阅读,SaaS应用,全浏览器访问前后端分离,多服务协同,服务可拆分ÿ…...

小红书场景营销怎么做?场景营销主要模式有哪些
小红书作为新兴媒体领域的佼佼者,凭借着生动,直观,代入感等元素的分享推荐收揽了巨额的流量。但是,随着时代的脚步逐渐加快,发展和变革随之涌来,传统的营销已经无法满足。所以场景营销就出现了。今天就来和…...

c++基础——数组
数组数组是存放相同类型对象的容器,数组中存放的对象没有名字,而是要通过其所在的位置访问。数组的大小是固定的,不能随意改变数组的长度。定义数组数组的声明形如 a[b],其中,a 是数组的名字,b 是数组中元素…...

JSON数据同步利器:深度解析ogre-software/json-synchronizer的核心原理与应用
1. 项目概述:一个被低估的JSON数据同步利器如果你经常和JSON数据打交道,尤其是在前后端分离、微服务架构或者多数据源集成的场景下,你肯定遇到过这样的烦恼:手头有两份甚至多份JSON数据,它们结构相似,但内容…...

Win11 22H2 打不开 IE?亲测有效!一行代码直接调出独立 IE 窗口
很多升级到 Windows 11 22H2 的用户都遇到过这样的困扰:明明银行、政务、企业内网等旧系统明确要求用 IE 浏览器登录,可系统里找不到 IE 入口,Edge 的 IE 兼容模式又频繁失效,直接打开 IE 还会强制跳转到 Edge,折腾半天…...

Apache Airflow 系列教程 | 第30课:Deadline 与 SLA 管理
导读(Introduction) 在生产环境中运行的数据管道,"按时完成"往往和"正确完成"同样重要。当一个关键的每日报表管道必须在早上 8 点前完成,或者当一个下游系统依赖的数据必须在特定时间窗口内准备就绪时,仅仅依靠"失败后告警"是不够的——我…...
)
别再死记公式了!用Python+LTspice快速搞定LC滤波器设计(附仿真文件)
用PythonLTspice实现LC滤波器设计的工程化实践 在传统电子工程教学中,LC滤波器设计往往陷入繁琐的公式推导和手工计算泥潭。当学生终于理解完所有理论公式,准备动手实践时,却发现自己被复杂的参数计算和反复的电路调试所困扰。这种理论与实践…...

JimuReport积木报表 — 实战API数据源动态参数与分页优化
1. 为什么API分页总让人头疼? 做过报表开发的朋友应该都遇到过这样的场景:后台接口明明提供了分页参数,但报表工具里就是没法正常翻页。要么点了下一页数据没变化,要么直接报错。我在第一次用JimuReport对接API数据源时࿰…...

InvestorFinder 技术架构深度解析:VC 合伙人真实投资行为数据挖掘与精准匹配底层实现
摘要在一级市场股权投资领域,创业者与风险投资机构合伙人的精准匹配长期存在信息壁垒、数据碎片化、背景信息不对称三大核心痛点。传统投融资对接模式依赖 FA 机构人脉、线下路演、投融资社群人工对接,存在效率低下、匹配维度单一、投资人真实投资行为数…...

ExDark低光照图像数据集技术架构:构建真实世界低光照计算机视觉解决方案
ExDark低光照图像数据集技术架构:构建真实世界低光照计算机视觉解决方案 【免费下载链接】Exclusively-Dark-Image-Dataset Exclusively Dark (ExDARK) dataset which to the best of our knowledge, is the largest collection of low-light images taken in very …...

5分钟打造专业音频可视化桌面:Lano Visualizer开源工具实战指南
5分钟打造专业音频可视化桌面:Lano Visualizer开源工具实战指南 【免费下载链接】Lano-Visualizer A simple but highly configurable visualizer with rounded bars. 项目地址: https://gitcode.com/gh_mirrors/la/Lano-Visualizer 你是否曾经想过ÿ…...

MCA Selector技术架构深度解析:Minecraft区块管理系统的实现原理
MCA Selector技术架构深度解析:Minecraft区块管理系统的实现原理 【免费下载链接】mcaselector A tool to select chunks from Minecraft worlds for deletion or export. 项目地址: https://gitcode.com/gh_mirrors/mc/mcaselector MCA Selector是一款专为M…...

ABAP 7.40+新语法实战:从传统代码到现代编程范式的重构
1. ABAP 7.40新语法带来的编程革命 十年前我刚接触ABAP时,代码风格还停留在SAP R/3时代的传统写法。每次看到满屏的DATA声明、LOOP...ENDLOOP和APPEND语句,就像在看上世纪90年代的编程教科书。直到ABAP 7.40版本发布,这个被称为"ABAP语言…...