sql server 分页查询
sql server 分页查询
[toc]
前言
SQL server 2012版本。下面都用pageIndex表示页数,pageSize表示一页包含的记录。并且下面涉及到具体例子的,设定查询第2页,每页含10条记录。
首先说一下SQL server的分页与MySQL的分页的不同,mysql的分页直接是用limit (pageIndex-1),pageSize就可以完成,但是SQL server 并没有limit关键字,只有类似limit的top关键字。所以分页起来比较麻烦。SQL server分页我所知道的就只有四种:三重循环、利用max(主键)、利用row_number关键字、offset/fetch next关键字
方法一:三重循环
1、思路
先取前20页,然后倒序,取倒序后前10条记录,这样就能得到分页所需要的数据,不过顺序反了,之后可以将再倒序回来,也可以不再排序了,直接交给前端排序。
还有一种方法也算是属于这种类型的,这里就不放代码出来了,只讲一下思路,就是先查询出前10条记录,然后用not in排除了这10条,再查询。
2、代码实现
-- 设置执行时间开始,用来查看性能的
set statistics time on ;
-- 分页查询(通用型)
select *
from (select top pageSize *from (select top (pageIndex * pageSize) *from studentorder by sNo asc) -- 其中里面这层,必须指定按照升序排序,省略的话,查询出的结果是错误的。as temp_sum_studentorder by sNo desc) temp_order
order by sNo asc-- 分页查询第2页,每页有10条记录
select *
from (select top 10 *from (select top 20 *from studentorder by sNo asc) -- 其中里面这层,必须指定按照升序排序,省略的话,查询出的结果是错误的。as temp_sum_studentorder by sNo desc) temp_order
order by sNo asc;方法二:利用max(主键)
先top前11条行记录,然后利用max(id)得到最大的id,之后再重新再这个表查询前10条,不过要加上条件,where id>max(id)。
1、代码实现
set statistics time on;-- 分页查询(通用型)
select top pageSize *
from student
where sNo >=(select max(sNo)from (select top ((pageIndex - 1) * pageSize + 1) sNofrom studentorder by sNo asc) temp_max_ids)
order by sNo;-- 分页查询第2页,每页有10条记录
select top 10 *
from student
where sNo >=(select max(sNo)from (select top 11 sNofrom studentorder by sNo asc) temp_max_ids)
order by sNo;方法三:利用row_number关键字
直接利用row_number() over(order by id)函数计算出行数,选定相应行数返回即可,不过该关键字只有在SQL server 2005版本以上才有。
1、SQL实现
set statistics time on;-- 分页查询(通用型)
select top pageSize *
from (select row_number()over (order by sno asc) as rownumber,*from student) temp_row
where rownumber > ((pageIndex - 1) * pageSize);set statistics time on;
-- 分页查询第2页,每页有10条记录
select top 10 *
from (select row_number()over (order by sno asc) as rownumber,*from student) temp_row
where rownumber > 10;方法四:offset /fetch next(2012版本及以上才有)
1、代码实现
set statistics time on;-- 分页查询(通用型)
select *
from student
order by sno
offset ((@pageIndex - 1) * @pageSize) rows fetch next @pageSize rows only;-- 分页查询第2页,每页有10条记录
select *
from student
order by sno
offset 10 rows fetch next 10 rows only;offset A rows ,将前A条记录舍去,fetch next B rows only ,向后在读取B条数据。
五、封装的存储过程
分页的时候,直接调用这个存储过程就可以了。
分页的存储过程
create procedure paging_procedure
( @pageIndex int, -- 第几页@pageSize int -- 每页包含的记录数
)
as
begin select top (select @pageSize) * -- 这里注意一下,不能直接把变量放在这里,要用selectfrom (select row_number() over(order by sno) as rownumber,* from student) temp_row where rownumber>(@pageIndex-1)*@pageSize;
end-- 到时候直接调用就可以了,执行如下的语句进行调用分页的存储过程
exec paging_procedure @pageIndex=2,@pageSize=10;六、总结
以上四种分页方法中,第二,第三,第三四种方法性能是差不多的,但是第一种性能很差,不推荐使用。
推荐第四种,毕竟第四种是SQL server公司升级后推出的新方法,所以应该理论上性能和可读性都会更加好。
相关文章:

sql server 分页查询
sql server 分页查询[toc]前言SQL server 2012版本。下面都用pageIndex表示页数,pageSize表示一页包含的记录。并且下面涉及到具体例子的,设定查询第2页,每页含10条记录。首先说一下SQL server的分页与MySQL的分页的不同,mysql的分…...

RV1126新增驱动IMX415 SENSOR,实现v4l2抓图
RV1126新增驱动IMX415 SENSOR,实现v4l2抓图。1:内核dts修改&csi_dphy0 {status "okay";ports {#address-cells <1>;#size-cells <0>;port0 {reg <0>;#address-cells <1>;#size-cells <0>;mipi_in_uca…...
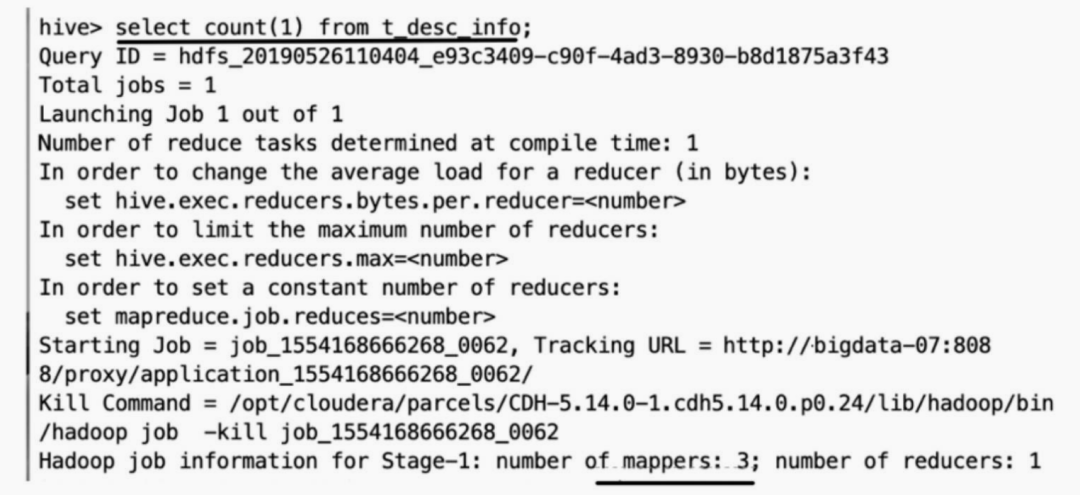
Hive 数据倾斜
数据倾斜,即单个节点任务所处理的数据量远大于同类型任务所处理的数据量,导致该节点成为整个作业的瓶颈,这是分布式系统不可能避免的问题。从本质来说,导致数据倾斜有两种原因,一是任务读取大文件,二是任务…...

2月刚上岸字节跳动测试岗面经
这时候发应该还不算太晚,金三银四找工作的小伙伴需要的可以看看。 一、测试工程师的工作是什么? 测试工程师简单点说就是找bug,然后反馈给开发人员,不要小看这个工作。 首先很明显的bug开发人员有时候自己就能找到,测…...
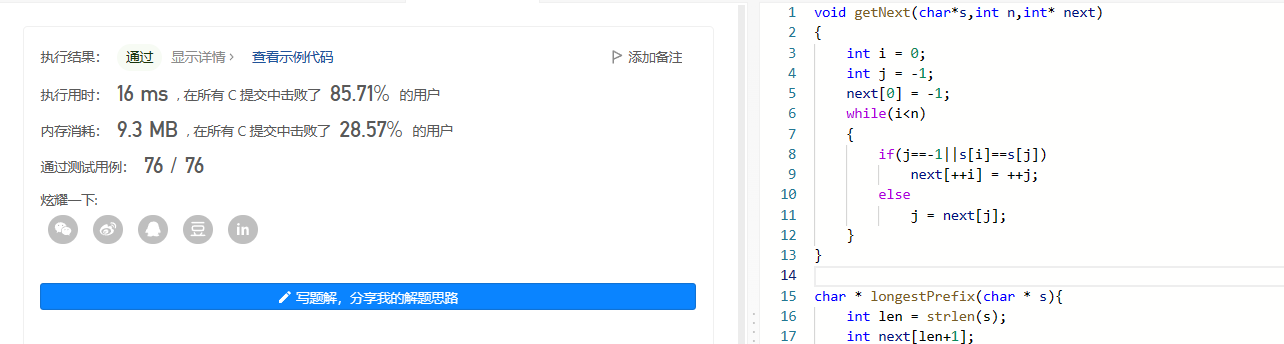
图解KMP算法
子串的定位操作通常称作串的模式匹配。你可以理解为在一篇英语文章中查找某个单词是否存在,或者说在一个主串中寻找某子串是否存在。朴素的模式匹配算法假设我们要从下面的主串S "goodgoogle" 中,找到T "google" 这个子串的位置。…...
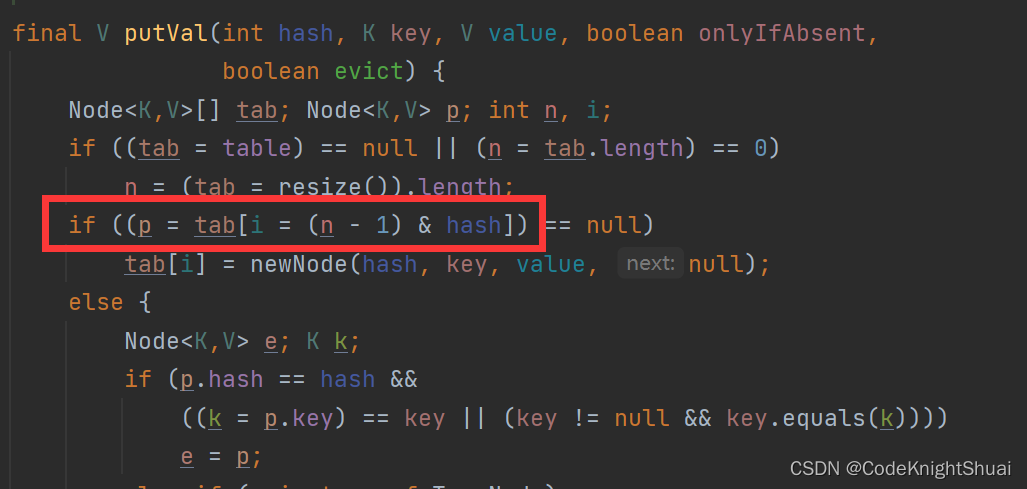
Java Map和Set
目录1. 二叉排序树(二叉搜索树)1.1 二叉搜索树的查找1.2 二叉搜索树的插入1.3 二叉搜索树的删除(7种情况)1.4 二叉搜索树和TreeMap、TreeSet的关系2. Map和Set的区别与联系2.1 从接口框架的角度分析2.2 从存储的模型角度分析【2种模型】3. 关于Map3.1 Ma…...

【C/C++ 数据结构】-八大排序之 冒泡排序快速排序
作者:学Java的冬瓜 博客主页:☀冬瓜的主页🌙 专栏:【C/C数据结构与算法】 分享:那我便像你一样,永远躲在水面之下,面具之后! ——《画江湖之不良人》 主要内容:八大排序选…...

苹果ipa软件下载网站和软件的汇总
随着时间的流逝,做苹果版软件安装包下载网站和软件的渐渐多了起来。 当然,已经关站、停运、下架、倒闭的苹果软件下载网站和软件我就不说了,也不必多说那些关站停运下架倒闭的网站和软件了。 下面我统计介绍的就是苹果软件安装包下载网站和软…...
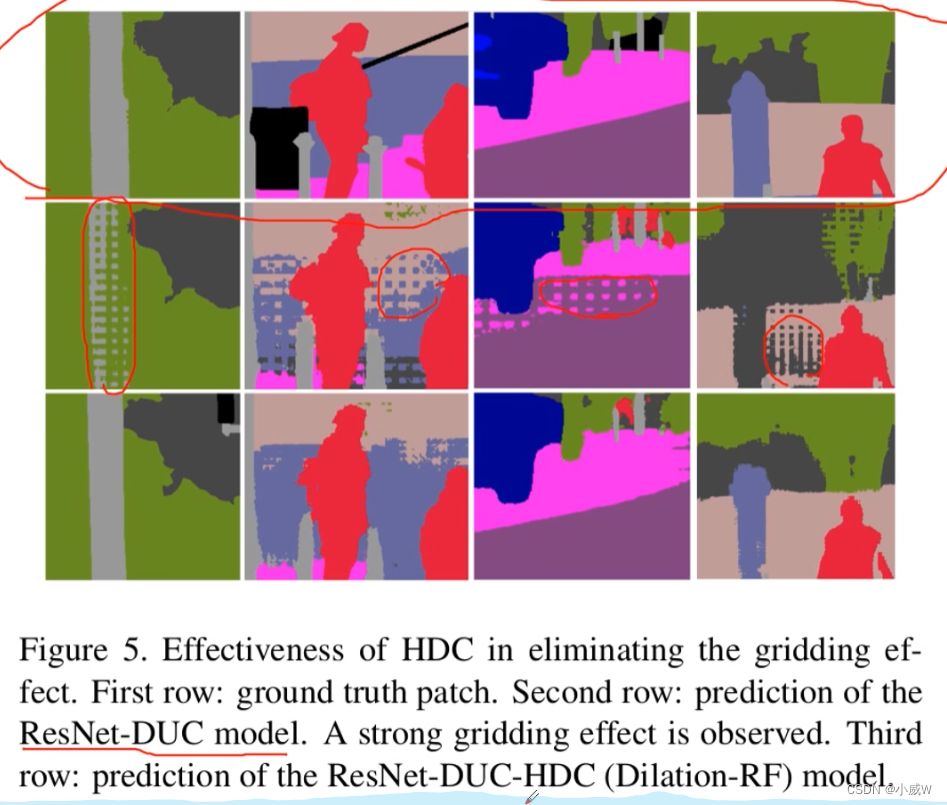
深度学习-【语义分割】学习笔记4 膨胀卷积(Dilated convolution)
文章目录膨胀卷积为什么需要膨胀卷积gridding effect连续使用三次膨胀卷积——1连续使用三次膨胀卷积——2连续使用三次膨胀卷积——3Understanding Convolution for Semantic Segmentation膨胀卷积 膨胀卷积,又叫空洞卷积。 左边是普通卷积,右边是膨胀…...

【10】SCI易中期刊推荐——工程技术-计算机:人工智能(中科院2区)
🚀🚀🚀NEW!!!SCI易中期刊推荐栏目来啦 ~ 📚🍀 SCI即《科学引文索引》(Science Citation Index, SCI),是1961年由美国科学信息研究所(Institute for Scientific Information, ISI)创办的文献检索工具,创始人是美国著名情报专家尤金加菲尔德(Eugene Garfield…...
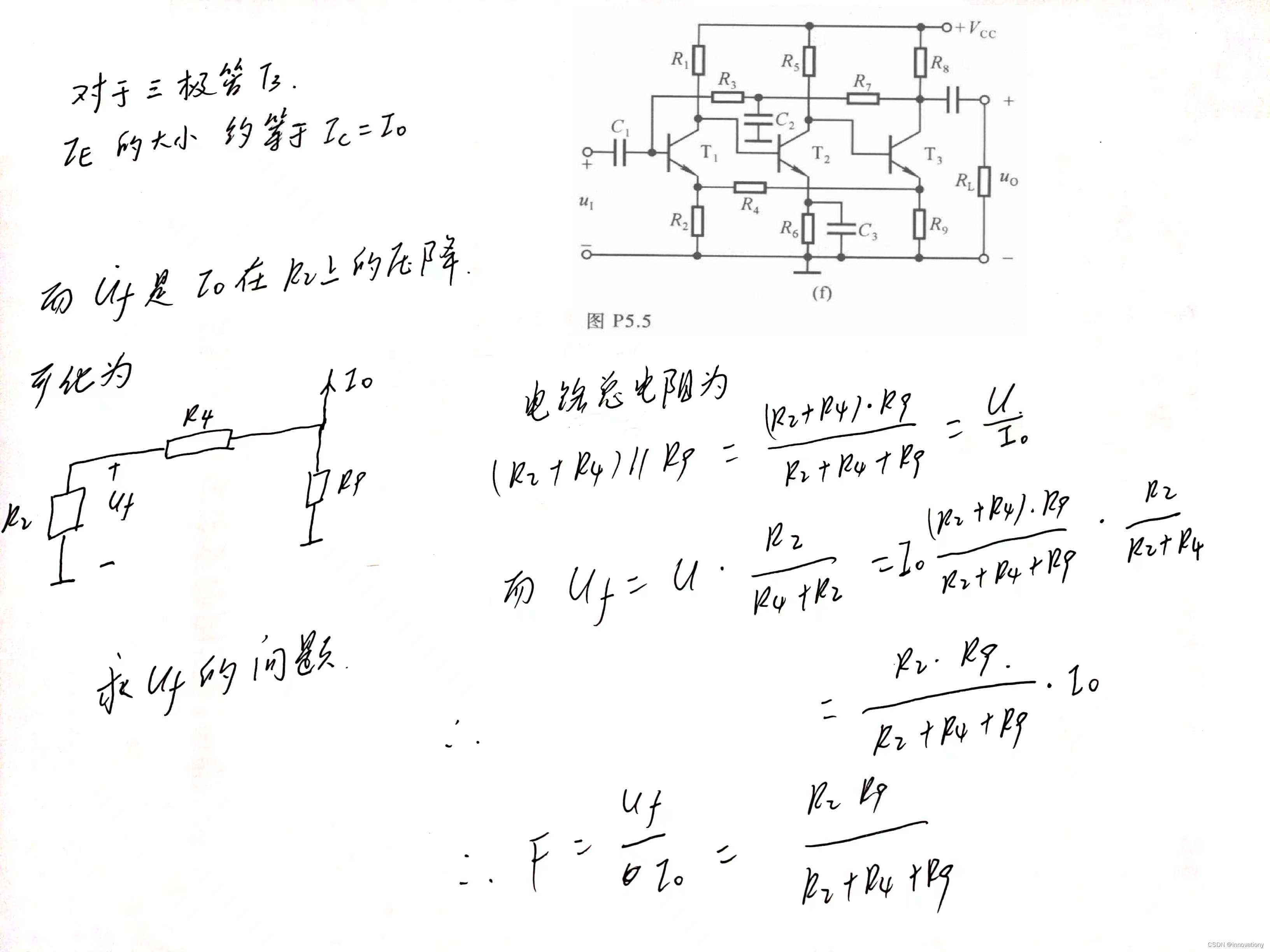
模电计算反馈系数,有时候转化为计算电阻分压的问题
模电计算反馈系数,有时候转化为计算电阻分压的问题 如果是电压反馈,F的除数是Uo 如果是电流反馈,F的除数是Io 串联反馈,F的分子是Uf 并联反馈,F的分子是If 点个赞呗,大家一起加油学习!...

专治Java底子差,不要再认为泛型就是一对尖括号了
文章目录一、泛型1.1 泛型概述1.2 集合泛型的使用1.2.1 未使用泛型1.2.2 使用泛型1.3 泛型类1.3.1 泛型类的使用1.2.2 泛型类的继承1.4 泛型方法1.5 泛型通配符1.5.1 通配符的使用1)参数列表带有泛型2)泛型通配符1.5.2 泛型上下边界1.6 泛型的擦除1.6.1 …...
PayPal轮询收款的那些事儿
想必做跨境电商独立站的小伙伴,对于PayPal是再熟悉不过了,PayPal是一个跨国际贸易的支付平台,对于做独立站的朋友来说跨境收款绝大部分都是依赖PayPal以及Stripe条纹了。简单来说PayPal跟国内的支付宝有点类似,但是PayPal它是跨国…...
【Linux】项目自动化构建工具——make/Makefile
目录 1.make与Makefile的关系 Makefile make 项目清理 clean .PHONY 当我们编写一个较大的软件项目时,通常需要将多个源文件编译成可执行程序或库文件。为了简化这个过程,我们可以使用 make 工具和 Makefile 文件。Makefile 文件可以帮助我们自动…...

成本降低90%,OpenAI正式开放ChαtGΡΤ
今天凌晨,OpenAI官方发布ChαtGΡΤ和Whisper的接囗,开发人员现在可以通过API使用最新的文本生成和语音转文本功能。OpenAI称:通过一系列系统级优化,自去年12月以来,ChαtGΡΤ的成本降低了90%;现在OpenAI用…...

hls.js如何播放m3u8文件(实例)?
HLS(HTTP Live Streaming)是一种视频流传输协议,是苹果推出的适用于iOS与macOS平台的流媒体传输协议。它将视频分割成若干个小段,每个小段大小一般为2~10秒不等,并通过HTTP协议进行传输。通过在每个小段之间插入若干秒…...

大数据平台建设方法论集合
文章目录从0到1建设大数据解决方案大数据集群的方法论数据集成方法论机器学习算法平台方法论BI建设的方法论云原生大数据的方法论低代码数据中台的方法论大数据SRE运维方法论批流一体化建设的方法论数据治理的方法论湖仓一体化建设的方法论数据分析挖掘方法论数字化转型方法论数…...
25- 卷积神经网络(CNN)原理 (TensorFlow系列) (深度学习)
知识要点 卷积神经网络的几个主要结构: 卷积层(Convolutions): Valid :不填充,也就是最终大小为卷积后的大小. Same:输出大小与原图大小一致,那么N 变成了N2P. padding-零填充. 池化层(Subsampli…...

把数组里面数值排成最小的数
问题描述:输入一个正整数数组,将它们连接起来排成一个数,输出能排出的所有数字中最小的一个。例如输入数组{12, 567},则输出这两个能排成的最小数字12567。请给出解决问题的算法,并证明该算法。 思路:先将…...
云his系统源码 SaaS应用 基于Angular+Nginx+Java+Spring开发
云his系统源码 SaaS应用 功能易扩 统一对外接口管理 一、系统概述: 本套云HIS系统采用主流成熟技术开发,软件结构简洁、代码规范易阅读,SaaS应用,全浏览器访问前后端分离,多服务协同,服务可拆分ÿ…...

一天怎么完成论文初稿
写论文这件事,从选题到完稿,哪一步都能卡掉你半条命。我身边不少读研读博的同学,白天泡实验室做实验,晚上挤时间写论文,熬了一两个月出初稿,结果格式不对、文献零散,还要和同门改来改去…...

VMware解锁macOS完整指南:3步免费运行苹果系统
VMware解锁macOS完整指南:3步免费运行苹果系统 【免费下载链接】unlocker VMware Workstation macOS 项目地址: https://gitcode.com/gh_mirrors/unloc/unlocker 你是否渴望在Windows或Linux电脑上体验macOS的魅力?无论你是开发者需要测试iOS应用…...

SAP供应商创建后,BP界面贸易伙伴字段不显示?手把手教你用FS_API_BP001_CHANGE补传数据
SAP供应商创建后BP界面贸易伙伴字段不显示的解决方案 在SAP系统中创建供应商时,经常会遇到一个令人困惑的问题:明明已经通过标准BAPI(如vmd_ei_api)将贸易伙伴信息成功写入数据库表LFA1的VBUND字段,但在业务伙伴(BP)界…...

Python 爬虫数据处理:富文本爬虫内容格式化还原
前言 互联网平台发布的文章、资讯、公众号推文、论坛帖子、商品详情、教程文案等内容,普遍以富文本形式存在,融合文字、段落层级、换行缩进、加粗引用、列表排版、超链接、分段结构等多种格式元素。普通爬虫仅能抓取原始 HTML 源码或纯文本内容…...

RSLinx OPC Server配置避坑指南:解决IP网段、Topic配置与标签读取的常见问题
RSLinx OPC Server实战排障手册:从IP冲突到标签解析的深度解决方案 当工业自动化系统遇上OPC Server通讯故障,工程师的调试时间往往以小时为单位流失。不同于基础配置教程,本文将直击RSLinx OPC Server部署中的七大高发故障场景,…...

3种方法修复ROG游戏本色彩配置文件丢失问题:G-Helper实战指南
3种方法修复ROG游戏本色彩配置文件丢失问题:G-Helper实战指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenb…...

英雄联盟智能助手League Akari:重新定义你的游戏体验边界
英雄联盟智能助手League Akari:重新定义你的游戏体验边界 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 在英雄联盟的竞技世界中&…...

Windows Cleaner终极指南:彻底告别C盘爆红的免费系统优化神器
Windows Cleaner终极指南:彻底告别C盘爆红的免费系统优化神器 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款专为Windows系统设…...

深度解析VisualCppRedist AIO:3种核心技术实现Windows运行时组件自动化管理
深度解析VisualCppRedist AIO:3种核心技术实现Windows运行时组件自动化管理 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist VisualCppRedist AIO项目…...

高效解决Visual C++运行库问题的终极方案实战指南
高效解决Visual C运行库问题的终极方案实战指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist Visual C运行库缺失或版本冲突是Windows开发者最常见的系统环境问…...