数据挖掘 聚类度量
格式化之前的代码:
import numpy as np#计算
import pandas as pd#处理结构化表格
import matplotlib.pyplot as plt#绘制图表和可视化数据的函数,通常与numpy和pandas一起使用。
from sklearn import metrics#聚类算法的评估指标。
from sklearn.cluster import KMeans#K均值聚类算法
from hopkins_test import hopkins_statistic
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号data = pd.read_csv('city.txt')#读数据########################检测是否有类结构###################### h_value = hopkins_statistic(data.values) 评估数据集的聚类倾向性,越接近于 0.5 表示数据集具有良好的聚类倾向性,越接近于 1 表示数据集的聚类倾向性较差。########################判定是否有最优簇数目#####################SSE = []
for i in range(1, 11): # k取1-10,计算簇内误差平方和model = KMeans(n_clusters=i)#创建一个 KMeans 对象 model,使用当前的簇数量 i 初始化该对象model.fit(data)#对数据集 data 进行拟合和聚类。SSE.append(model.inertia_)#获取当前模型的簇内误差平方和,并将其添加到 SSE 列表中。
plt.plot(range(1, 11), SSE, marker='.')#plt.plot() 函数绘制折线图,横坐标为簇数量(1-10),纵坐标为簇内误差平方和(SSE)。
plt.xticks(ticks= range(1, 11))#设置横坐标刻度为 1-10
plt.xlabel('k值',)
plt.ylabel('簇内误差平方和SSE')
plt.show()########################确定最优簇数目#####################
opt = 0
for k in [5,6]:#遍历簇数量列表 [5, 6]kmeans_model = KMeans(n_clusters=k, random_state=1).fit(data)#创建一个 KMeans 对象 kmeans_model,使用当前的簇数量 k 和随机种子 random_state=1 初始化该对象,对数据集 data 进行拟合和聚类labels = kmeans_model.labels_#获取每个样本所属的簇标签value = metrics.silhouette_score(data, labels, metric='euclidean')#计算当前聚类结果的轮廓系数,其中指定使用欧氏距离作为度量方式。print(value)#打印输出当前轮廓系数的值if value >= opt:#如果当前轮廓系数大于等于 opt 变量的值,则更新 opt、opt_k 和 opt_labels 分别为当前轮廓系数、簇数量 k 和对应的簇标签。opt = value#opt 存储了最佳轮廓系数的值,opt_k 存储了具有最佳轮廓系数的簇数量,opt_labels 存储了对应的簇标签。opt_k = kopt_labels = labels########################聚类结果显示#####################colors = ['r', 'c', 'b', 'y', 'g']#创建一个颜色列表 colors,用于指定每个簇的颜色。
plt.figure()#创建一个新的图形窗口
for j in range(5):#遍历簇标签的取值范围(0-4)index_set = np.where(opt_labels == j)#获取属于当前簇标签的样本的索引集合。cluster = data.iloc[index_set]#使用这些索引从数据集 data 中提取属于当前簇的样本,并赋值给变量 clusterplt.scatter(cluster.iloc[:, 0], cluster.iloc[:, 1], c=colors[j], marker='.')#绘制当前簇的样本点,横坐标为 cluster 的第一列,纵坐标为 cluster 的第二列,颜色为 colors[j],标记为小圆点 '.'。plt.show()
格式化之后的代码:
import numpy as np # 计算
import pandas as pd # 处理结构化表格
import matplotlib.pyplot as plt # 绘制图表和可视化数据的函数,通常与numpy和pandas一起使用。
from sklearn import metrics # 聚类算法的评估指标。
from sklearn.cluster import KMeans # K均值聚类算法
from hopkins_test import hopkins_statisticplt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号data = pd.read_csv('city.txt') # 读数据########################检测是否有类结构###################### h_value = hopkins_statistic(data.values) 评估数据集的聚类倾向性,越接近于 0.5 表示数据集具有良好的聚类倾向性,越接近于 1 表示数据集的聚类倾向性较差。########################判定是否有最优簇数目#####################SSE = []
for i in range(1, 11): # k取1-10,计算簇内误差平方和model = KMeans(n_clusters=i) # 创建一个 KMeans 对象 model,使用当前的簇数量 i 初始化该对象model.fit(data) # 对数据集 data 进行拟合和聚类。SSE.append(model.inertia_) # 获取当前模型的簇内误差平方和,并将其添加到 SSE 列表中。
plt.plot(range(1, 11), SSE, marker='.') # plt.plot() 函数绘制折线图,横坐标为簇数量(1-10),纵坐标为簇内误差平方和(SSE)。
plt.xticks(ticks=range(1, 11)) # 设置横坐标刻度为 1-10
plt.xlabel('k值', )
plt.ylabel('簇内误差平方和SSE')
plt.show()########################确定最优簇数目#####################
opt = 0
for k in [5, 6]: # 遍历簇数量列表 [5, 6]kmeans_model = KMeans(n_clusters=k, random_state=1).fit(data) # 创建一个 KMeans 对象 kmeans_model,使用当前的簇数量 k 和随机种子 random_state=1 初始化该对象,对数据集 data 进行拟合和聚类labels = kmeans_model.labels_ # 获取每个样本所属的簇标签value = metrics.silhouette_score(data, labels, metric='euclidean') # 计算当前聚类结果的轮廓系数,其中指定使用欧氏距离作为度量方式。print(value) # 打印输出当前轮廓系数的值if value >= opt: # 如果当前轮廓系数大于等于 opt 变量的值,则更新 opt、opt_k 和 opt_labels 分别为当前轮廓系数、簇数量 k 和对应的簇标签。opt = value # opt 存储了最佳轮廓系数的值,opt_k 存储了具有最佳轮廓系数的簇数量,opt_labels 存储了对应的簇标签。opt_k = kopt_labels = labels########################聚类结果显示#####################colors = ['r', 'c', 'b', 'y', 'g'] # 创建一个颜色列表 colors,用于指定每个簇的颜色。
plt.figure() # 创建一个新的图形窗口
for j in range(5): # 遍历簇标签的取值范围(0-4)index_set = np.where(opt_labels == j) # 获取属于当前簇标签的样本的索引集合。cluster = data.iloc[index_set] # 使用这些索引从数据集 data 中提取属于当前簇的样本,并赋值给变量 clusterplt.scatter(cluster.iloc[:, 0], cluster.iloc[:, 1], c=colors[j],marker='.') # 绘制当前簇的样本点,横坐标为 cluster 的第一列,纵坐标为 cluster 的第二列,颜色为 colors[j],标记为小圆点 '.'。plt.show()
霍普金斯统计代码
格式化之前:
import numpy as np#计算
from sklearn.neighbors import NearestNeighbors#最近邻搜索的算法实现,可用于在数据集中查找最接近给定样本的邻居。
from sklearn.datasets import load_iris#load_iris函数是一个用于加载鸢尾花数据集的辅助函数
import pandas as pd#数据分析
from random import sample#随机抽样和洗牌操作
from numpy.random import uniform#均匀分布的随机数
def hopkins_statistic(X):#输入参数X是一个二维数组,表示原始数据集sample_size = int(X.shape[0]*0.05) #0.05 (5%) based on paper by Lawson and Jures #计算样本大小,占原始数据集大小的5%。这个样本将用于生成均匀随机样本。#原始数据空间的均匀随机样本X_uniform_random_sample = uniform(X.min(axis=0), X.max(axis=0) ,(sample_size , X.shape[1]))#X.min(axis=0)和X.max(axis=0)会计算原始数据集X每一列的最小值和最大值。这将返回一个包含每列最小值的一维数组和一个包含每列最大值的一维数组uniform函数将使用这些最小值和最大值来指定随机样本的取值范围。指定了生成的随机样本的形状,即一个元组(sample_size, X.shape[1]),其中sample_size表示样本大小,X.shape[1]表示每个样本的特征数。#从原始数据中随机抽取一个样本random_indices=sample(range(0, X.shape[0], 1), sample_size)#从原始数据集X中随机选择一个子集。具体而言,range(0, X.shape[0], 1)将返回一个从0到X.shape[0]的整数序列,步长为1。sample函数将从该序列中随机选择sample_size个不重复的整数,这些整数将用于从X中抽取对应的样本。X_sample = X[random_indices]#根据随机选择的索引从原始数据集中抽取一部分样本#初始化无监督学习器以实现NN搜索neigh = NearestNeighbors(n_neighbors=2)#NearestNeighbors是一个用于寻找最近邻的非监督学习算法。在这里,n_neighbors=2参数指定了要查找的最近邻的数量,即每个样本要找到的最近的两个邻居。nbrs=neigh.fit(X)#u_distances = 均匀随机样本的最近邻距离u_distances , u_indices = nbrs.kneighbors(X_uniform_random_sample , n_neighbors=2)#计算均匀随机样本X_uniform_random_sample在原始数据集X中的最近邻距离,并返回距离和对应的索引。这里将返回每个均匀随机样本的两个最近邻距离,其中第一个最近邻是样本本身,距离为0,因此只保留第二个最近邻的距离。u_distances = u_distances[: , 0] #到第一个最近邻居的距离#仅保留到第一个最近邻的距离#w_distances = 来自原始数据X的点样本的最近邻距离w_distances , w_indices = nbrs.kneighbors(X_sample , n_neighbors=2)#计算从原始数据集中抽取的样本X_sample的最近邻距离,并返回距离和对应的索引。同样,只保留第二个最近邻的距离。#到第二个最近邻居的距离(因为第一个邻居将是点本身,距离= 0)w_distances = w_distances[: , 1]#仅保留到第二个最近邻的距离u_sum = np.sum(u_distances)#计算均匀随机样本的最近邻距离之和w_sum = np.sum(w_distances)#计算来自原始数据集的样本的最近邻距离之和#计算并返回霍普金斯统计数据H = u_sum/ (u_sum + w_sum)#计算霍普金斯统计数据return H#返回计算得到的霍普金斯统计量
if __name__=="__main__":#if __name__=="__main__":是一个条件语句,它判断当前脚本是否作为主程序直接运行。只有当脚本作为主程序运行时,才会执行if语句块中的代码。iris=load_iris().data#iris = load_iris().data加载了一个名为iris的数据集,数据集是鸢尾花数据集。.data属性返回数据集的特征部分。h_value=hopkins_statistic(iris)#h_value = hopkins_statistic(iris)调用了名为hopkins_statistic的函数,计算了数据集的Hopkins统计量,并将结果赋值给变量h_value。
格式化之后的代码:
import numpy as np # 计算
from sklearn.neighbors import NearestNeighbors # 最近邻搜索的算法实现,可用于在数据集中查找最接近给定样本的邻居。
from sklearn.datasets import load_iris # load_iris函数是一个用于加载鸢尾花数据集的辅助函数
import pandas as pd # 数据分析
from random import sample # 随机抽样和洗牌操作
from numpy.random import uniform # 均匀分布的随机数def hopkins_statistic(X): # 输入参数X是一个二维数组,表示原始数据集sample_size = int(X.shape[0] * 0.05) # 0.05 (5%) based on paper by Lawson and Jures #计算样本大小,占原始数据集大小的5%。这个样本将用于生成均匀随机样本。# 原始数据空间的均匀随机样本X_uniform_random_sample = uniform(X.min(axis=0), X.max(axis=0), (sample_size, X.shape[1])) # X.min(axis=0)和X.max(axis=0)会计算原始数据集X每一列的最小值和最大值。这将返回一个包含每列最小值的一维数组和一个包含每列最大值的一维数组uniform函数将使用这些最小值和最大值来指定随机样本的取值范围。指定了生成的随机样本的形状,即一个元组(sample_size, X.shape[1]),其中sample_size表示样本大小,X.shape[1]表示每个样本的特征数。# 从原始数据中随机抽取一个样本random_indices = sample(range(0, X.shape[0], 1),sample_size) # 从原始数据集X中随机选择一个子集。具体而言,range(0, X.shape[0], 1)将返回一个从0到X.shape[0]的整数序列,步长为1。sample函数将从该序列中随机选择sample_size个不重复的整数,这些整数将用于从X中抽取对应的样本。X_sample = X[random_indices] # 根据随机选择的索引从原始数据集中抽取一部分样本# 初始化无监督学习器以实现NN搜索neigh = NearestNeighbors(n_neighbors=2) # NearestNeighbors是一个用于寻找最近邻的非监督学习算法。在这里,n_neighbors=2参数指定了要查找的最近邻的数量,即每个样本要找到的最近的两个邻居。nbrs = neigh.fit(X)# u_distances = 均匀随机样本的最近邻距离u_distances, u_indices = nbrs.kneighbors(X_uniform_random_sample,n_neighbors=2) # 计算均匀随机样本X_uniform_random_sample在原始数据集X中的最近邻距离,并返回距离和对应的索引。这里将返回每个均匀随机样本的两个最近邻距离,其中第一个最近邻是样本本身,距离为0,因此只保留第二个最近邻的距离。u_distances = u_distances[:, 0] # 到第一个最近邻居的距离#仅保留到第一个最近邻的距离# w_distances = 来自原始数据X的点样本的最近邻距离w_distances, w_indices = nbrs.kneighbors(X_sample,n_neighbors=2) # 计算从原始数据集中抽取的样本X_sample的最近邻距离,并返回距离和对应的索引。同样,只保留第二个最近邻的距离。# 到第二个最近邻居的距离(因为第一个邻居将是点本身,距离= 0)w_distances = w_distances[:, 1] # 仅保留到第二个最近邻的距离u_sum = np.sum(u_distances) # 计算均匀随机样本的最近邻距离之和w_sum = np.sum(w_distances) # 计算来自原始数据集的样本的最近邻距离之和# 计算并返回霍普金斯统计数据H = u_sum / (u_sum + w_sum) # 计算霍普金斯统计数据return H # 返回计算得到的霍普金斯统计量if __name__ == "__main__": # if __name__=="__main__":是一个条件语句,它判断当前脚本是否作为主程序直接运行。只有当脚本作为主程序运行时,才会执行if语句块中的代码。iris = load_iris().data # iris = load_iris().data加载了一个名为iris的数据集,数据集是鸢尾花数据集。.data属性返回数据集的特征部分。h_value = hopkins_statistic(iris) # h_value = hopkins_statistic(iris)调用了名为hopkins_statistic的函数,计算了数据集的Hopkins统计量,并将结果赋值给变量h_value。相关文章:

数据挖掘 聚类度量
格式化之前的代码: import numpy as np#计算 import pandas as pd#处理结构化表格 import matplotlib.pyplot as plt#绘制图表和可视化数据的函数,通常与numpy和pandas一起使用。 from sklearn import metrics#聚类算法的评估指标。 from sklearn.clust…...
[Angular] 笔记 24:ngContainer vs. ngTemplate vs. ngContent
请说明 Angular 中 ngContainer, ngTemplate 和 ngContent 这三者之间的区别。 chatgpt 回答: 这三个在 Angular 中的概念是关于处理和组织视图的。 1. ngContainer: ngContainer 是一个虚拟的 HTML 容器,它本身不会在最终渲染…...

❀My排序算法学习之插入排序❀
目录 插入排序(Insertion Sort):) 一、定义 二、基本思想 三、示例 时间复杂度 空间复杂度 bash C++ 四、稳定性分析...

【算法题】30. 串联所有单词的子串
题目 给定一个字符串 s 和一个字符串数组 words。 words 中所有字符串 长度相同。 s 中的 串联子串 是指一个包含 words 中所有字符串以任意顺序排列连接起来的子串。 例如,如果 words ["ab","cd","ef"], 那么 "…...

SAP-FI模块 处理自动生成会计凭证增强
ENHANCEMENT 2 ZEHENC_SAPMF05A. "active version * FI 20221215:固定资产业务过渡科目摘要增强功能 WAIT UP TO 1 SECONDS.READ TABLE xbseg WITH KEY hkont 1601990001. IF sy-subrc 0.DATA: lt_bkdf TYPE TABLE OF bkdf,lt_bkpf TYPE TABLE OF bkpf,…...
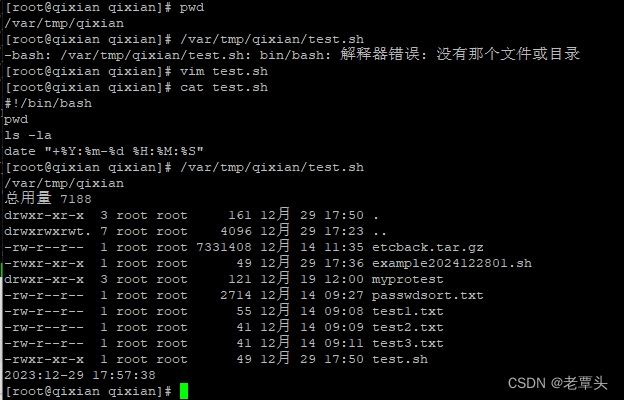
Shell脚本-bin/bash: 解释器错误: 没有那个文件或目录-完整路径执行-“/”引发的脑裂
引起该不适的一种可能以及解决方案,网上较多,比如: 但按以上方式操作,并经过查看,发现仍然未能解决问题。 因为两种方式执行,有一种能成功,有一种不能,刚开始未怀疑是文件问题&…...
详细使用)
React MUI(版本v5.15.2)详细使用
使用React MUI(版本v5.15.2)的详细示例。请注意,由于版本可能会有所不同,因此建议您查阅官方文档以获取最新的信息和示例。但是,我将根据我的知识库为您提供一些基本示例。 首先,确保您已经按照之前的说明…...
用CSS中的动画效果做一个转动的表
<!DOCTYPE html> <html lang"en"><head><meta charset"utf-8"><title></title><style>*{margin:0;padding:0;} /*制作表的样式*/.clock{width: 500px;height: 500px;margin:0 auto;margin-top:100px;border-rad…...
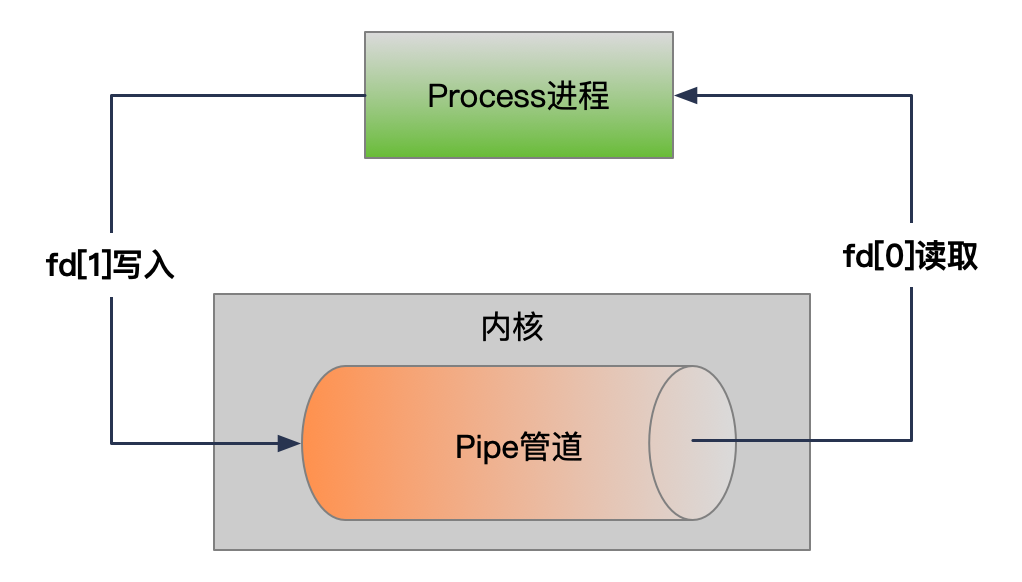
【linux】Linux管道的原理与使用场景
Linux管道是Linux命令行界面中一种强大的工具,它允许用户将多个命令链接起来,使得一个命令的输出可以作为另一个命令的输入。这种机制使得我们可以创建复杂的命令链,并在处理数据时提供了极大的灵活性。在本文中,我们将详细介绍Li…...

nvidia jetson xavier nx developer kit version emmc版重装系统
一、将开发板上的外置硬盘取下来格式化 二、在双系统ubuntu安装SDK Manager(.deb文件) SDK Manager | NVIDIA Developer sudo apt install ./sdkmanager_1.9.2-10884_amd64.deb 报错直接百度错误,执行相应命令即可 三、 运行SDK Manager …...

命令模式-实例使用
未使用命令模式的UML 使用命令模式后的UML public abstract class Command {public abstract void execute(); }public class Invoker {private Command command;/*** 为功能键注入命令* param command*/public void setCommand(Command command) {this.command command;}/***…...

将网页变身移动应用:网址封装成App的完全指南
什么是网址封装? 网址封装是一个将你的网站或网页直接嵌入到一个原生应用容器中的过程。用户可以通过下载你的App来访问网站,而无需通过浏览器。这种方式不仅提升了用户体验,还可利用移动设备的功能,如推送通知和硬件集成。 小猪…...
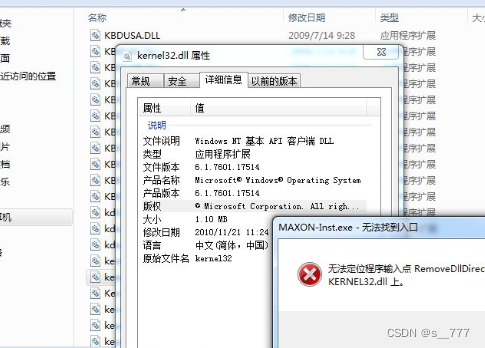
探讨kernel32.dll文件是什么,有效解决kernel32.dll丢失
在使用电脑时,你是否遇到过kernel32.dll丢失的困扰?面对这个问题,我们需要及时去解决kernel32.dll丢失的问题。接下来,我们将深入探讨kernel32.dll的功能以及其在操作系统和应用程序中的具体应用领域,相信这将对你解决…...
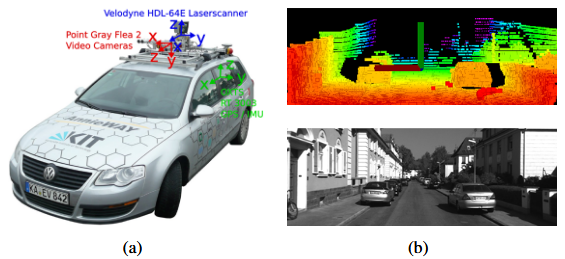
LOAM: Lidar Odometry and Mapping in Real-time 论文阅读
论文链接 LOAM: Lidar Odometry and Mapping in Real-time 0. Abstract 提出了一种使用二维激光雷达在6自由度运动中的距离测量进行即时测距和建图的方法 距离测量是在不同的时间接收到的,并且运动估计中的误差可能导致生成的点云的错误配准 本文的方法在不需要高…...
如何使用Docker将.Net6项目部署到Linux服务器(三)
目录 四 安装nginx 4.1 官网下载nginx 4.2 下载解压安装nginx 4.3 进行configure 4.4 执行make 4.5 查看nginx是否安装成功 4.6 nginx的一些常用命令 4.6.1 启动nginx 4.6.2 通过命令查看nginx是否启动成功 4.6.3 关闭Nginx 4.6.5 重启Nginx 4.6.6 杀掉所有Nginx进程 4.…...
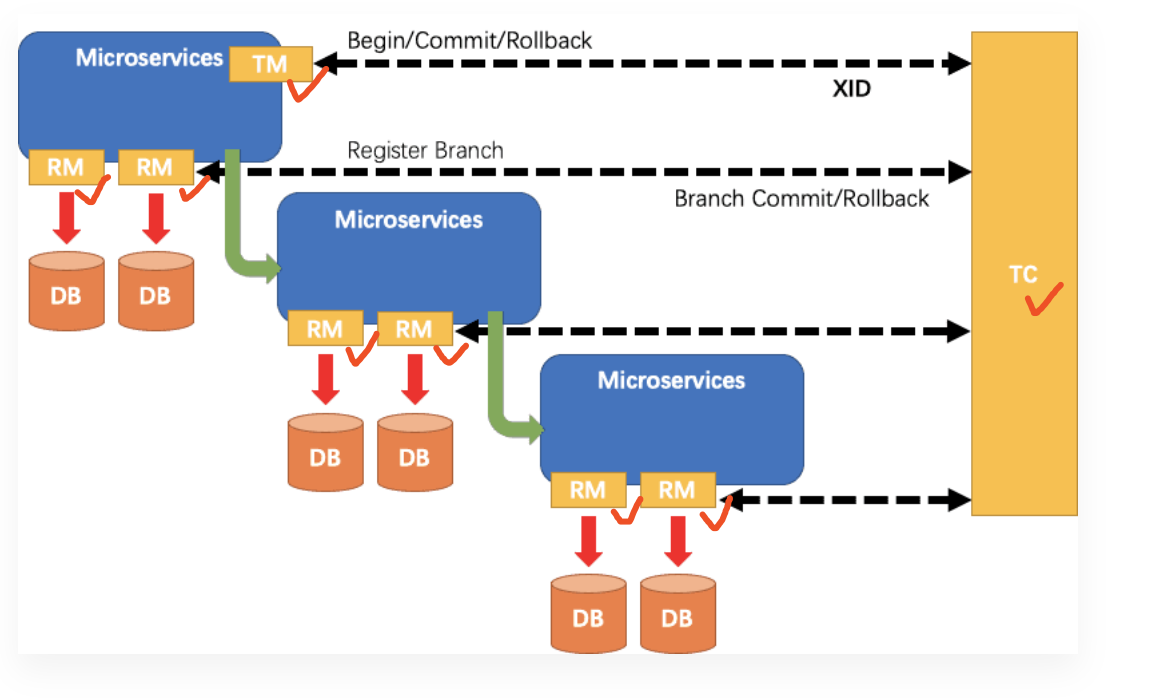
《Spring Cloud学习笔记:分布式事务Seata》
解决分布式事务的方案有很多,但实现起来都比较复杂,因此我们一般会使用开源的框架来解决分布式事务问题。 在众多的开源分布式事务框架中,功能最完善、使用最多的就是阿里巴巴在2019年开源的Seata了。 1. 初识Seata Seata是 2019 年 1 月…...
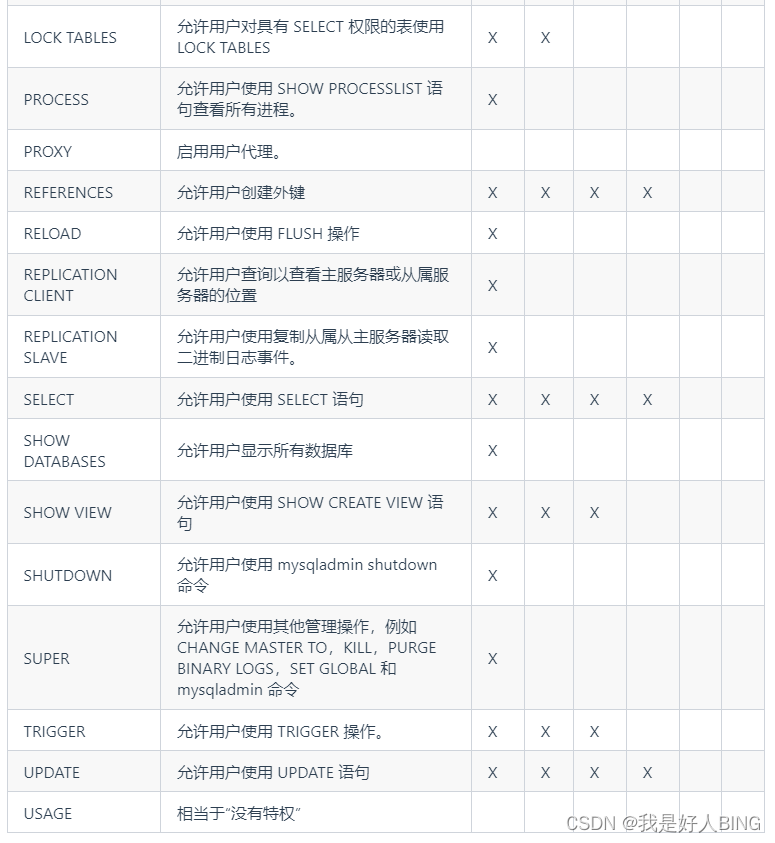
MySQL:权限控制
要授予用户帐户权限,可以用GRANT命令。有撤销用户的权限,可以用REVOKE命令。这里以 MySQl 为例,介绍权限控制实际应用。 GRANT授予权限语法: GRANT privilege,[privilege],.. ON privilege_level TO user [IDENTIFIED BY passwo…...

安全生产知识竞赛活动方案
为进一步普及安全生产法律法规知识,增强安全意识,提高安全技能,经研究,决定举办以“加强安全法治、保障安全生产”为主题的新修订《安全生产法》知识竞赛活动,现将有关事项通知如下: 一、活动时间…...

2023 IoTDB Summit:天谋科技 CTO 乔嘉林《IoTDB 企业版 V1.3: 时序数据管理一站式解决方案》...
12 月 3 日,2023 IoTDB 用户大会在北京成功举行,收获强烈反响。本次峰会汇集了超 20 位大咖嘉宾带来工业互联网行业、技术、应用方向的精彩议题,多位学术泰斗、企业代表、开发者,深度分享了工业物联网时序数据库 IoTDB 的技术创新…...

LangChain.js 实战系列:如何统计大模型使用的 token 使用量和花费
📝 LangChain.js 是一个快速开发大模型应用的框架,它提供了一系列强大的功能和工具,使得开发者能够更加高效地构建复杂的应用程序。LangChain.js 实战系列文章将介绍在实际项目中使用 LangChain.js 时的一些方法和技巧。 统计调用大模型的 to…...

开源入门踩坑全实录:从PR被拒到核心贡献者的全周期避坑指南
根据中国开源软件推进联盟2025年发布的《中国开源开发者生态报告》,国内开源开发者规模已突破1200万,但入门1年内就停止贡献的开发者占比高达78.6%。换句话说,每5个尝试入门开源的新手,就有4个会在一年内彻底放弃。 作为从0起步&a…...

极域电子教室突破技术:从系统控制到自主操作的攻防对抗
极域电子教室突破技术:从系统控制到自主操作的攻防对抗 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 一、核心痛点:极域电子教室的控制枷锁 在信息化教…...

终极指南:如何用F3工具快速检测U盘和SD卡真实容量
终极指南:如何用F3工具快速检测U盘和SD卡真实容量 【免费下载链接】f3 F3 - Fight Flash Fraud 项目地址: https://gitcode.com/gh_mirrors/f3/f3 在数字时代,存储设备容量造假已成为普遍问题,许多U盘、SD卡通过软件修改显示虚假容量&…...

SlopeCraft:Minecraft地图艺术创作的高效解决方案
SlopeCraft:Minecraft地图艺术创作的高效解决方案 【免费下载链接】SlopeCraft Map Pixel Art Generator for Minecraft 项目地址: https://gitcode.com/gh_mirrors/sl/SlopeCraft 在Minecraft的方块世界中,将现实中的图像转化为立体地图艺术一直…...
)
RK3568开发板烧录避坑指南:Maskrom和Loader模式切换失败?手把手教你排查(附串口调试技巧)
RK3568开发板烧录模式切换全攻略:从原理到实战排查 刚拿到RK3568开发板的开发者们,往往会在第一个环节就遭遇"拦路虎"——开发板死活进不了Maskrom或Loader模式。看着官方文档里简单的按键操作说明,实际操作时却像在玩一场没有规则…...

Uvicorn终极指南:如何快速构建高性能Python异步Web服务器
Uvicorn终极指南:如何快速构建高性能Python异步Web服务器 【免费下载链接】uvicorn An ASGI web server, for Python. 🦄 项目地址: https://gitcode.com/GitHub_Trending/uv/uvicorn Uvicorn是一款专为Python设计的轻量级ASGI Web服务器…...
)
Minikube国内环境配置全攻略:从安装到Dashboard镜像加速(含阿里云镜像源)
Minikube国内环境高效配置指南:从零搭建到Dashboard可视化 对于国内开发者而言,在本地环境中快速搭建Kubernetes学习平台往往面临镜像拉取缓慢甚至失败的困扰。本文将系统性地介绍如何利用Minikube在国内网络环境下构建稳定的单机Kubernetes环境…...

避坑指南:用STM32CubeMX配置SPI驱动MAX7219数码管的几个关键细节
STM32CubeMX实战:避开MAX7219数码管驱动的5个致命配置误区 第一次用STM32CubeMX配置SPI驱动MAX7219数码管时,我盯着屏幕上闪烁不定的数字差点崩溃——明明按照教程一步步操作,为什么显示总是错乱?后来才发现,那些看似简…...

如何高效解决Calibre中文路径翻译问题:完整实用指南
如何高效解决Calibre中文路径翻译问题:完整实用指南 【免费下载链接】calibre-do-not-translate-my-path Switch my calibre library from ascii path to plain Unicode path. 将我的书库从拼音目录切换至非纯英文(中文)命名 项目地址: htt…...
结合:风格迁移与质量增强)
国风美学模型与卷积神经网络(CNN)结合:风格迁移与质量增强
国风美学模型与卷积神经网络(CNN)结合:风格迁移与质量增强 最近在尝试用AI生成国风图像时,我遇到了两个挺实际的问题。一个是生成的图片虽然意境不错,但风格上总觉得少了点传统水墨丹青的韵味;另一个是&am…...