Spark任务调度与数据本地性
Apache Spark是一个分布式计算框架,用于处理大规模数据。了解Spark任务调度与数据本地性是构建高效分布式应用程序的关键。本文将深入探讨Spark任务调度的流程、数据本地性的重要性,并提供丰富的示例代码来帮助大家更好地理解这些概念。
Spark任务调度的流程
Spark任务调度是将作业的任务分配给工作节点以执行的过程。Spark使用了一种称为DAG(有向无环图)调度器的方式来执行这个过程。下面是任务调度的流程简要概述:
-
驱动程序解析作业的逻辑,包括转换操作和行动操作。这些操作构成了一个DAG。
-
驱动程序将DAG提交给调度器,并将DAG中的任务分配给工作节点。任务通常是对RDD的转换操作。
-
工作节点接收任务并执行计算。每个工作节点会将任务的结果存储在本地,并将中间结果缓存到内存中以供后续任务使用。
-
一旦任务完成,工作节点将结果返回给驱动程序。
-
驱动程序收集所有任务的结果,完成行动操作,将最终结果返回给用户。
任务调度的流程是分布式计算框架的核心,Spark通过DAG调度器实现了高效的任务分配和执行。
数据本地性的重要性
在Spark任务调度过程中,数据本地性是一个关键概念。数据本地性指的是任务执行时,尽可能将数据与执行任务的工作节点放在同一台物理节点上。这样做的好处是可以最大程度地减少数据的网络传输开销,提高任务的执行效率。
Spark支持三种数据本地性级别:
-
数据本地性(Data Locality):任务执行节点与数据块在同一台物理节点上。
-
部分数据本地性(Partial Data Locality):任务执行节点与部分数据块在同一台物理节点上,但还需要从其他节点获取一部分数据。
-
无数据本地性(No Data Locality):任务执行节点与数据块不在同一台物理节点上,需要通过网络传输获取数据。
数据本地性对于Spark作业的性能具有重要影响。最大程度地利用数据本地性可以显著降低作业的执行时间。
示例:数据本地性的重要性
下面将演示一个示例,来说明数据本地性的重要性。假设有一个大型文本文件,我们要统计其中每个单词的出现次数。首先,将展示没有数据本地性的情况,然后展示数据本地性的优化。
1 无数据本地性示例
from pyspark import SparkContext# 创建SparkContext
sc = SparkContext("local", "NoDataLocalityExample")# 读取大型文本文件
text_file = sc.textFile("large_text_file.txt")# 切分文本为单词并计数
words = text_file.flatMap(lambda line: line.split(" "))
word_counts = words.countByValue()# 打印结果
for word, count in word_counts.items():print(f"{word}: {count}")# 停止SparkContext
sc.stop()
在这个示例中,首先创建了一个SparkContext,然后使用textFile方法读取大型文本文件,切分文本为单词并计算每个单词的出现次数。然而,由于没有考虑数据本地性,任务执行节点与数据块不在同一台物理节点上,需要通过网络传输获取数据,导致任务执行效率低下。
2 有数据本地性示例
from pyspark import SparkContext# 创建SparkContext
sc = SparkContext("local", "DataLocalityExample")# 读取大型文本文件,并使用repartition操作进行数据本地性优化
text_file = sc.textFile("large_text_file.txt").repartition(4)# 切分文本为单词并计数
words = text_file.flatMap(lambda line: line.split(" "))
word_counts = words.countByValue()# 打印结果
for word, count in word_counts.items():print(f"{word}: {count}")# 停止SparkContext
sc.stop()
在这个示例中,首先创建了一个SparkContext,然后使用textFile方法读取大型文本文件,并通过repartition操作进行数据本地性优化,将数据均匀分布到多个物理节点上。这样做可以最大程度地减少数据的网络传输开销,提高任务执行效率。
性能优化和注意事项
在编写Spark作业时,性能优化是一个重要的考虑因素。以下是一些性能优化和注意事项:
1 数据本地性优化
尽可能地考虑数据本地性,通过repartition等操作来优化数据的分布,减少网络传输开销。
2 持久化(Persistence)
在迭代计算中,可以使用persist操作将RDD的中间结果缓存到内存中,以避免重复计算。这可以显著提高性能。
rdd.persist()
3 数据倾斜处理
处理数据倾斜是一个重要的性能优化问题。可以使用
reduceByKey的变体来减轻数据倾斜。
word_counts = words.map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
总结
了解Spark任务调度与数据本地性是构建高效分布式应用程序的关键。本文深入探讨了任务调度的流程、数据本地性的重要性,并提供了示例代码来帮助大家更好地理解这些概念。
希望本文帮助大家更好地理解Spark任务调度与数据本地性的概念,并为您构建和优化Spark应用程序提供了一些有用的指导。
相关文章:
Spark任务调度与数据本地性
Apache Spark是一个分布式计算框架,用于处理大规模数据。了解Spark任务调度与数据本地性是构建高效分布式应用程序的关键。本文将深入探讨Spark任务调度的流程、数据本地性的重要性,并提供丰富的示例代码来帮助大家更好地理解这些概念。 Spark任务调度的…...

【论文阅读】Self-Paced Curriculum Learning
论文下载 代码 Supplementary Materials bib: INPROCEEDINGS{,title {Self-Paced Curriculum Learning},author {Lu Jiang and Deyu Meng and Qian Zhao and Shiguang Shan and Alexander Hauptmann},booktitle {AAAI},year {2015},pages {2694--2700} }1. 摘…...

C++简易线程池
原理说明: 1. 线程池创建时,指定线程池的大小thread_size。当有新的函数任务通过函数addFunction ()添加进来后,其中一个线程执行函数。一个线程一次执行一个函数。如果函数数量大与线程池数量,则后来的函数等待。 2. 线程池内部…...
【MATLAB】PSO粒子群优化LSTM(PSO_LSTM)的时间序列预测
有意向获取代码,请转文末观看代码获取方式~也可转原文链接获取~ 1 基本定义 PSO粒子群优化LSTM(PSO-LSTM)是一种将粒子群优化算法(PSO)与长短期记忆神经网络(LSTM)相结合的混合模型。该算法通过…...
产品经理学习-怎么写PRD文档
目录 瀑布流方法论介绍 产品需求文档(PRD)介绍 产品需求文档的基本要素 撰写产品需求文档 优先产品需求文档的特点 其他相关文档 瀑布流方法论介绍 瀑布流模型是一种项目的开发和管理的方法论,是敏捷的开发管理方式相对应的另一种方法…...

第3课 获取并播放音频流
本课对应源文件下载链接: https://download.csdn.net/download/XiBuQiuChong/88680079 FFmpeg作为一套庞大的音视频处理开源工具,其源码有太多值得研究的地方。但对于大多数初学者而言,如何快速利用相关的API写出自己想要的东西才是迫切需要…...
Spark编程实验四:Spark Streaming编程
目录 一、目的与要求 二、实验内容 三、实验步骤 1、利用Spark Streaming对三种类型的基本数据源的数据进行处理 2、利用Spark Streaming对Kafka高级数据源的数据进行处理 3、完成DStream的两种有状态转换操作 4、把DStream的数据输出保存到文本文件或MySQL数据库中 四…...

Flink去重计数统计用户数
1.数据 订单表,分别是店铺id、用户id和支付金额 "店铺id,用户id,支付金额", "shop-1,user-1,1", "shop-1,user-2,1", "shop-1,user-2,1", "shop-1,user-3,1", "shop-1,user-3,1", "shop-1,user…...
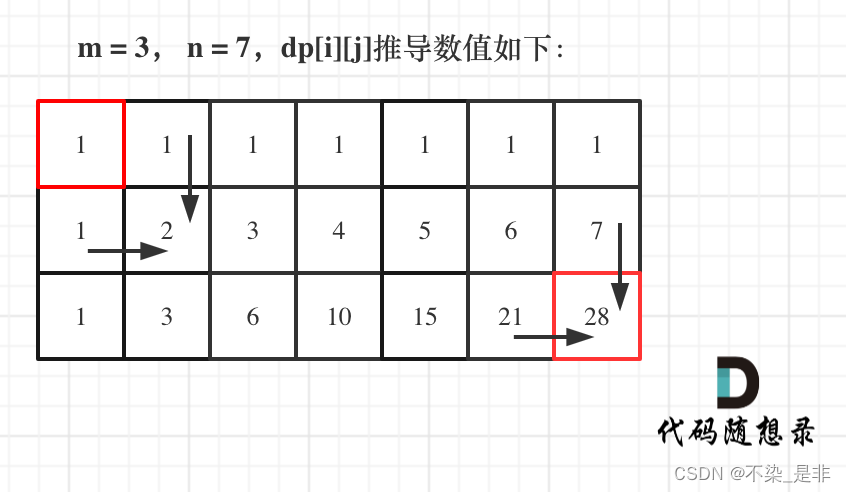
力扣:62. 不同路径(动态规划,附python二维数组的定义)
题目: 一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。 问总共有多少条不同的路径&…...
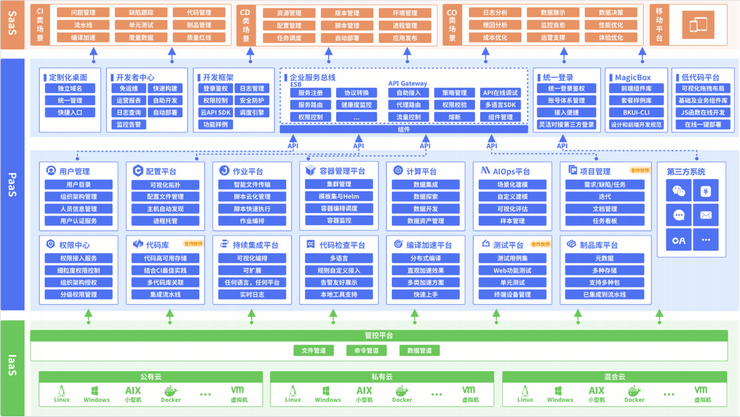
2022年全球运维大会(GOPS深圳站)-核心PPT资料下载
一、峰会简介 GOPS 主要面向运维行业的中高端技术人员,包括运维、开发、测试、架构师等群体。目的在于帮助IT技术从业者系统学习了解相关知识体系,让创新技术推动社会进步。您将会看到国内外知名企业的相关技术案例,也能与国内顶尖的技术专家…...

8868体育助力意甲罗马俱乐部 迪巴拉有望付出
8868体育助力意甲罗马俱乐部 迪巴拉有望付出 意甲罗马俱乐部是8868体育合作球队之一,本赛季,在意甲第14轮的比赛中,罗马客场2-1战胜萨索洛,积分上升到意甲第4位。 有报道称,迪巴拉在对阵佛罗伦萨的比赛中受伤ÿ…...

java设计模式实战【策略模式+观察者模式+命令模式+组合模式,混合模式在支付系统中的应用】
引言 在代码开发的世界里,理论知识的重要性毋庸置疑,但实战经验往往才是知识的真正试金石。正所谓,“读万卷书不如行万里路”,理论的学习需要通过实践来验证和深化。设计模式作为软件开发中的重要理论,其真正的价值在…...

小程序wx:if 和hidden的区别?
在小程序中,wx:if 和 hidden 是用于条件渲染的两种不同方式。 选择使用哪种方式取决于具体情况。如果条件变化频繁或节点包含复杂的子节点,可以考虑使用 wx:if 进行条件渲染;如果条件变化较少且节点结构简单,可以使用 hidden 控制…...
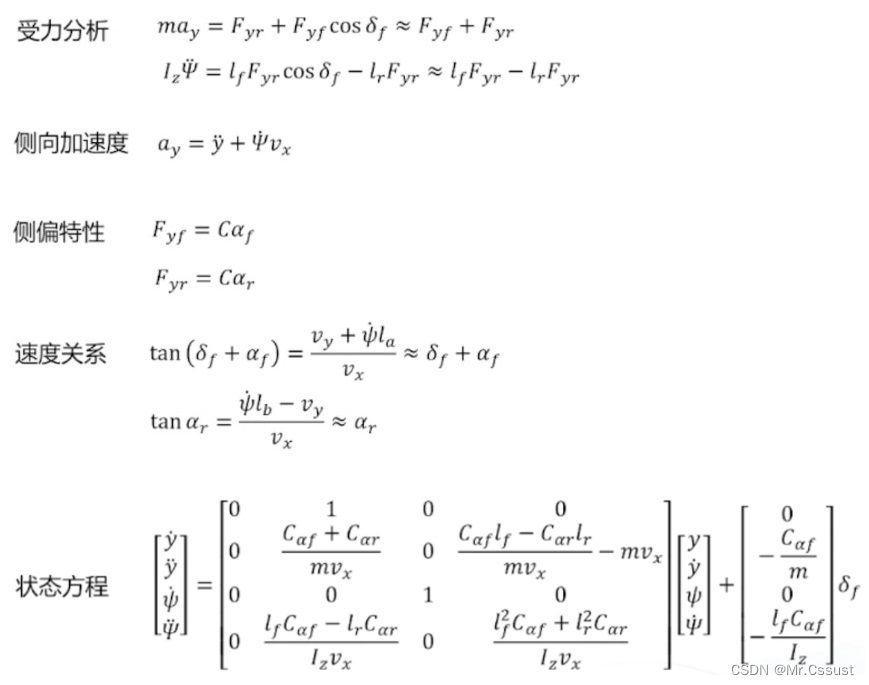
自动驾驶学习笔记(二十三)——车辆控制模型
#Apollo开发者# 学习课程的传送门如下,当您也准备学习自动驾驶时,可以和我一同前往: 《自动驾驶新人之旅》免费课程—> 传送门 《Apollo开放平台9.0专项技术公开课》免费报名—>传送门 文章目录 前言 运动学模型 动力学模型 总结…...

Linux Shell 015-文本双向覆盖重定向工具tee
Linux Shell 015-文本双向覆盖重定向工具tee 本节关键字:Linux、Bash Shell、文本双向覆盖重定向工具 相关指令:tee、echo、cat tee介绍 tee工具是从标准输入读取并写入到标准输出和文件,即:双向覆盖重定向(屏幕输出…...

【PyQt】(自定义类)QIcon派生,更易用的纯色Icon
嫌Qt自带的icon太丑,自己写了一个,主要用于纯色图标的自由改色。 当然,图标素材得网上找。 Qt原生图标与现代图标对比: 没有对比就没有伤害 Qt图标 网络素材图标 自定义类XJQ_Icon: from PyQt5.QtGui import QIc…...

【mysql】数据处理格式化、转换、判断
数据处理 判断是否超时,时间是否大于当前时间计算分钟数时间格式化处理如果数值类型进行转换字符类型字符拼接case-when代替if-else判断数据空(特殊:含空数据、空字符处理) select /*判断是否超时,时间是否大于当前…...

深入探索Java中的UDP网络通信机制
在网络通信中,UDP(User Datagram Protocol,用户数据报协议)是一种无连接的协议,它在某些情况下比TCP更适合,尤其是在要求速度快、对数据准确性要求相对较低的场景下。本文将介绍如何使用Java进行UDP网络通信…...

List常见方法和遍历操作
List集合的特点 有序: 存和取的元素顺序一致有索引:可以通过索引操作元素可重复:存储的元素可以重复 List集合的特有方法 Collection的方法List都继承了List集合因为有索引,所以有了很多操作索引的方法 ublic static void main…...
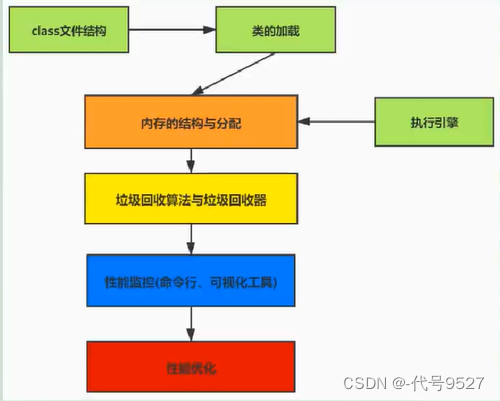
【基础篇】一、认识JVM
文章目录 1、虚拟机2、Java虚拟机3、JVM的整体结构4、Java代码的执行流程5、JVM的三大功能6、JVM的分类7、JVM的生命周期 1、虚拟机 虚拟机,Virtual Machine,一台虚拟的计算机,用来执行虚拟计算机指令。分为: 系统虚拟机&#x…...

阿里云RocketMQ LiteTopic:破解高并发智能语音交互消息链路难题
【导语:随着AI Agent从文本交互走向语音交互,高并发场景下消息链路瓶颈凸显。阿里云基于RocketMQ LiteTopic构建实时语音消息链路架构,解决传统架构难题,提升业务价值。】高并发语音交互的技术瓶颈当AI Agent语音交互进入高并发场…...

Nanbeige 4.1-3B Streamlit WebUI实战:游戏剧情生成与角色对话工具
Nanbeige 4.1-3B Streamlit WebUI实战:游戏剧情生成与角色对话工具 1. 引言:当AI模型遇上二次元聊天室 如果你玩过《蔚蓝档案》这类二次元游戏,一定对里面那个清爽、可爱的手机短信式聊天界面印象深刻。现在,有个好消息是&#…...

从零到一:基于LLaMA-Factory与Ollama的本地大模型定制化实战
1. 为什么需要本地定制化大模型? 最近两年,大语言模型的发展速度简直让人瞠目结舌。从最初的GPT-3到现在的Llama 3,模型能力越来越强,但随之而来的问题是:这些通用大模型真的能满足我们每个人的特定需求吗?…...

终极BewlyBewly插件指南:5分钟打造个性化Bilibili界面
终极BewlyBewly插件指南:5分钟打造个性化Bilibili界面 【免费下载链接】BewlyBewly Improve your Bilibili homepage by redesigning it, adding more features, and personalizing it to match your preferences. 项目地址: https://gitcode.com/gh_mirrors/be/B…...

如何优化A-to-Z-Resources-for-Students文档的行距与段距:提升阅读体验的完整指南
如何优化A-to-Z-Resources-for-Students文档的行距与段距:提升阅读体验的完整指南 【免费下载链接】A-to-Z-Resources-for-Students ✅ Curated list of resources for college students 项目地址: https://gitcode.com/GitHub_Trending/at/A-to-Z-Resources-for…...

服装设计降本增效:Nano-Banana软萌拆拆屋缩短打样周期实证
服装设计降本增效:Nano-Banana软萌拆拆屋缩短打样周期实证 在服装设计行业,从创意草图到实物样衣,打样环节往往是成本最高、耗时最长的“拦路虎”。设计师需要反复与版师、样衣工沟通,绘制复杂的工艺图,一个款式来回修…...

告别Date混乱:kotlinx-datetime 0.6.0版本完全避坑指南
告别Date混乱:kotlinx-datetime 0.6.0版本完全避坑指南 如果你曾在Kotlin项目中处理过跨时区生日提醒、电商促销倒计时或航班时刻转换,大概率体验过被java.util.Date支配的恐惧——隐式时区转换、毫秒值溢出、不可变性问题如同定时炸弹般散落在代码各处。…...

图像处理中的频域魔法:用傅里叶变换消除噪点与增强细节的3种技巧
图像处理中的频域魔法:用傅里叶变换消除噪点与增强细节的3种技巧 当你在处理一张模糊的医学影像或卫星图片时,是否想过那些隐藏在像素背后的频率秘密?傅里叶变换就像一台精密的频谱分析仪,能将图像从空间域转换到频域,…...

E-Hentai-Downloader:高效漫画资源本地化解决方案
E-Hentai-Downloader:高效漫画资源本地化解决方案 【免费下载链接】E-Hentai-Downloader Download E-Hentai archive as zip file 项目地址: https://gitcode.com/gh_mirrors/eh/E-Hentai-Downloader 核心价值:重新定义漫画资源管理 E-Hentai-Do…...

数据标注技术指南:高效标注与数据质量优化实践
数据标注技术指南:高效标注与数据质量优化实践 【免费下载链接】cvat Annotate better with CVAT, the industry-leading data engine for machine learning. Used and trusted by teams at any scale, for data of any scale. 项目地址: https://gitcode.com/Git…...