ConcurrentHashMap-Java八股面试(五)
系列文章目录
第一章 ArrayList-Java八股面试(一)
第二章 HashMap-Java八股面试(二)
第三章 单例模式-Java八股面试(三)
第四章 线程池和Volatile关键字-Java八股面试(四)
提示:动态每日更新算法题,想要学习的可以关注一下
文章目录
- 系列文章目录
- 一、ConcurrentHashMap是什么?
- 1 jdk1.7
- 1. put方法
- 2. HashEntry扩容
- 3 Segment的数量和下标的计算
- 4.HashEntry的初始化
- 5.HashEntry的下标计算
- 2. jdk1.8
- 1. 扩容机制
- 2. 初始化机制(capacity和factor)
- 3. put方法
- 4. 扩容机制
- 5. 扩容时的put和get操作
- 总结和细节
- 1.JDK1.7 与 JDK1.8 中ConcurrentHashMap 的区别
- 2.ConcurrentHashMap 的并发度是什么?
- 3. ConcurrentHashMap 迭代器是强一致性还是弱一致性
- 4.ConcurrentHashMap 和 Hashtable 的效率哪个更高?为什么?
一、ConcurrentHashMap是什么?
1 jdk1.7
JDK1.7 中的 ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成,即 ConcurrentHashMap 把哈希桶数组切分成小数组(Segment ),每个小数组有 n 个 HashEntry 组成。
和普通的HashMap相比,ConcurrentHashMap其实就解决了多线程下安全的问题,其构造和HashMap相差不大,也是需要计算二次哈希值,唯一需要说明的是segment下标和小数组的问题。

Segment的数量决定了ConcurrentHashMap的并发度,因为在同一时刻只有一把锁可以访问,一旦Segment初始化之后就无法扩容,能扩容的是Segment下面的小数组。
而每个小数组则是HashEntry。
1. put方法
每一个元素先进行二次哈希值的计算,然后计算得到Segment下标,而后再进算桶下标,最后会以头插法的方式加入到链表中。

2. HashEntry扩容
一旦HashEntry下的节点个数大于HashEntry数量的3/4时就会发生扩容
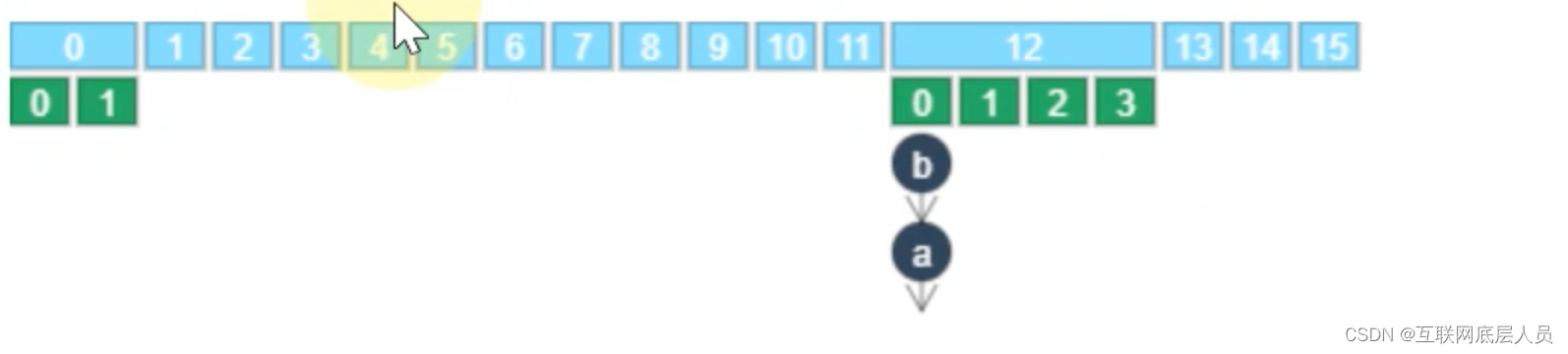
3 Segment的数量和下标的计算
segment的数量是初始化时给的参数(clevel).
而segment的下标计算时根据如下图所示是二次哈希值的二进制编码的高4位得出12。
4.HashEntry的初始化
一旦初始化ConcurrentHashMap后,第一个HashEntry也会随之初始化,HashEntry的数量计算时:capacity/Segment(clevel),当然最小为2.第一次创建之后这个也就会作为模板,后面任意一个Segment对HashEntry初始化时都会以这个长度,而不是第一个HashEntry扩容后的长度(此时的长度)。注意这里的capacity只在这一步计算中用到,我们看到的数组长度其实是segment的长度。

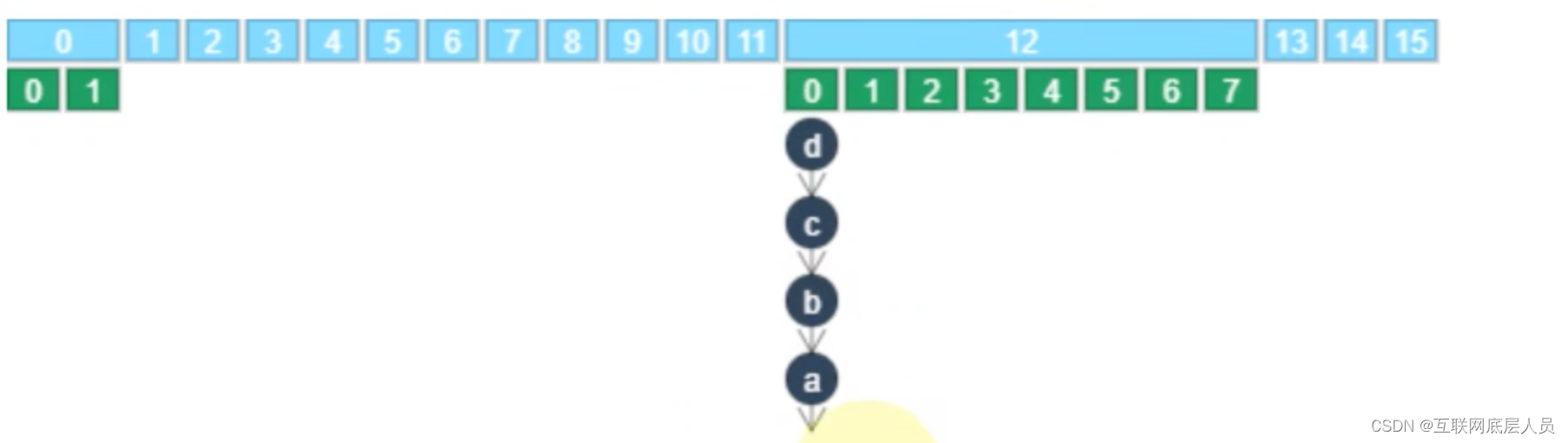
5.HashEntry的下标计算
二次哈希值的二进制编码的最低位,如下图为0,则在索引为0的地方。
2. jdk1.8
与jdk1.7不同的是没有了Segment,也没有了HashEntry,和原始的HashMap在结构上有一些类似。初始化方式为懒汉式,只有在调用时才会初始化整个ConcurrentHashMap.在数据结构上, JDK1.8 中的ConcurrentHashMap 选择了与 HashMap 相同的Node数组+链表+红黑树结构;在锁的实现上,抛弃了原有的 Segment 分段锁,采用CAS + synchronized实现更加细粒度的锁。
将锁的级别控制在了更细粒度的哈希桶数组元素级别,也就是说只需要锁住这个链表头节点(红黑树的根节点),就不会影响其他的哈希桶数组元素的读写,大大提高了并发度。
1. 扩容机制
与1.7不同的是,当容量到达3/4时就会发生扩容,而不是超过3/4。

2. 初始化机制(capacity和factor)
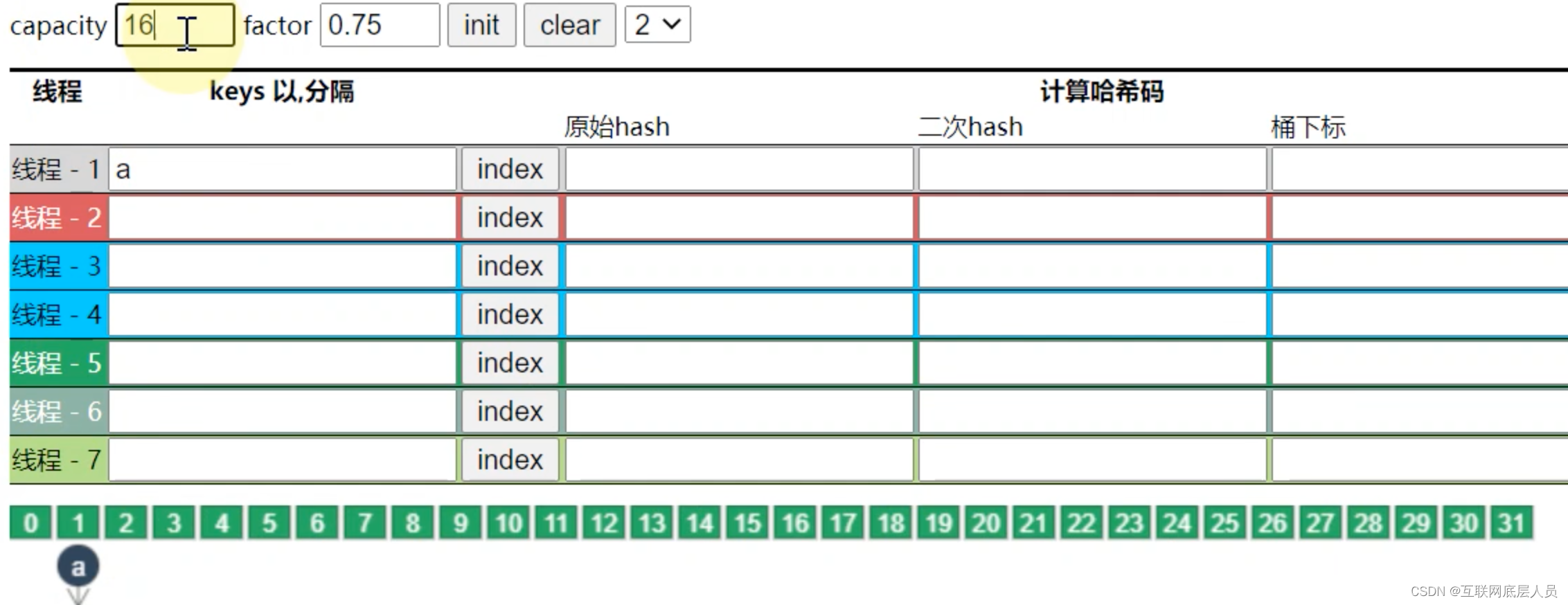
capacity的意思并不再指初始化数组的容量,而是指一开始会往ConcurrentHashMap中放几个元素。
如上图所示,放16个元素,扩容因子为3/4,假如map长度为16,那么长度在12就会扩容,因此还需要在16的基础上继续扩容成32.尽管capacity设置为16,但并不意味着必须要放16个元素,并且capacity和factor只会在第一次初始化时有效。后续就算factor设置为0.5或者其他值,都是按默认的0.75计算。
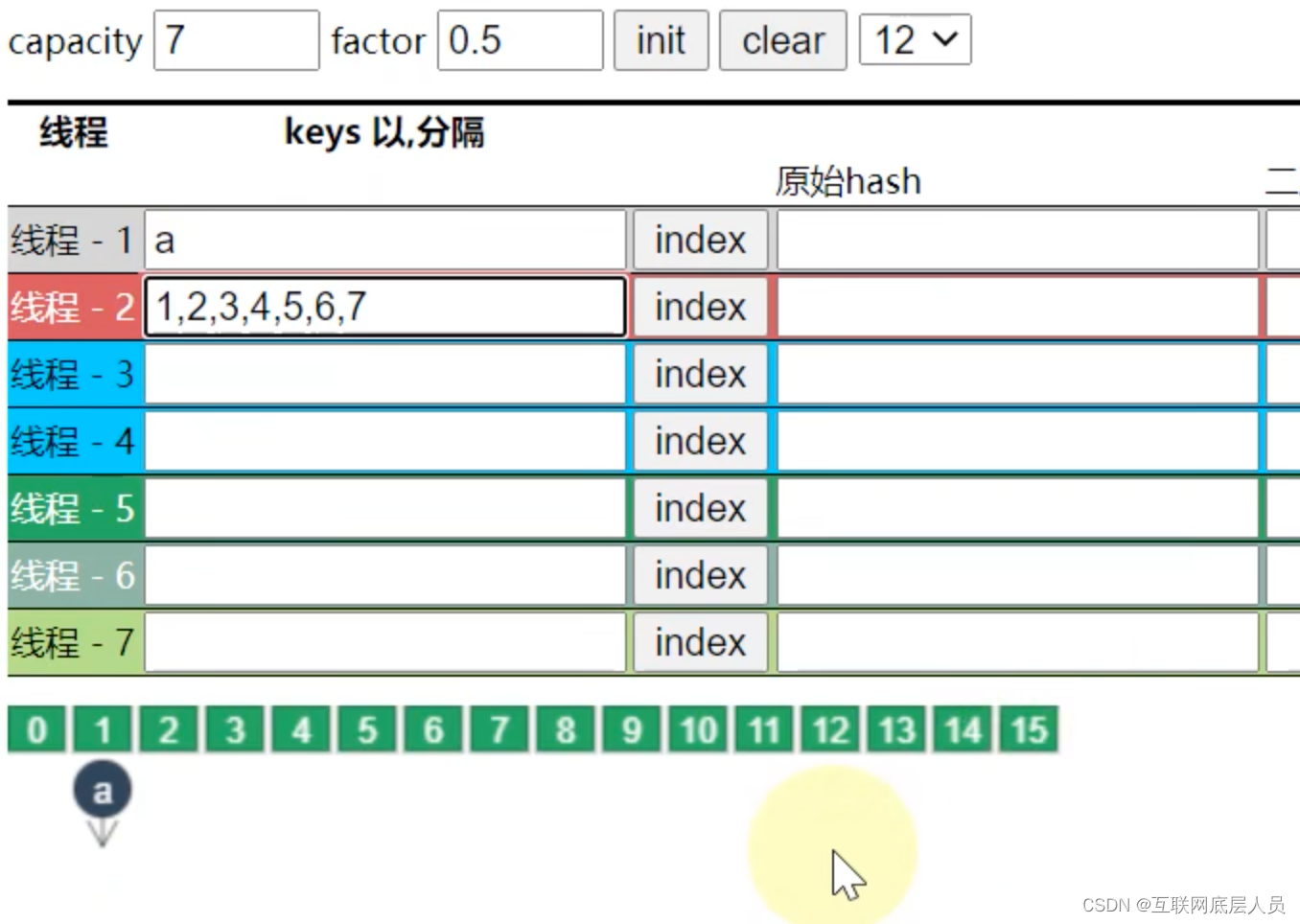
值得说明的是,ConcurrentHashMap的容量只能是2的n次方。如上所示放7个元素,那么先考虑8是否能行,因为factor为0.5,所以必须要扩容成16.
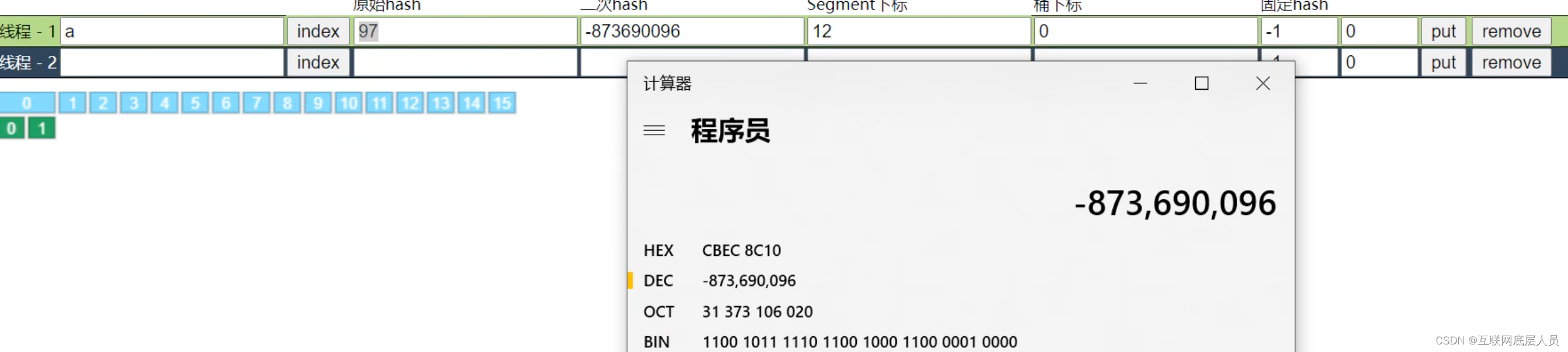
3. put方法
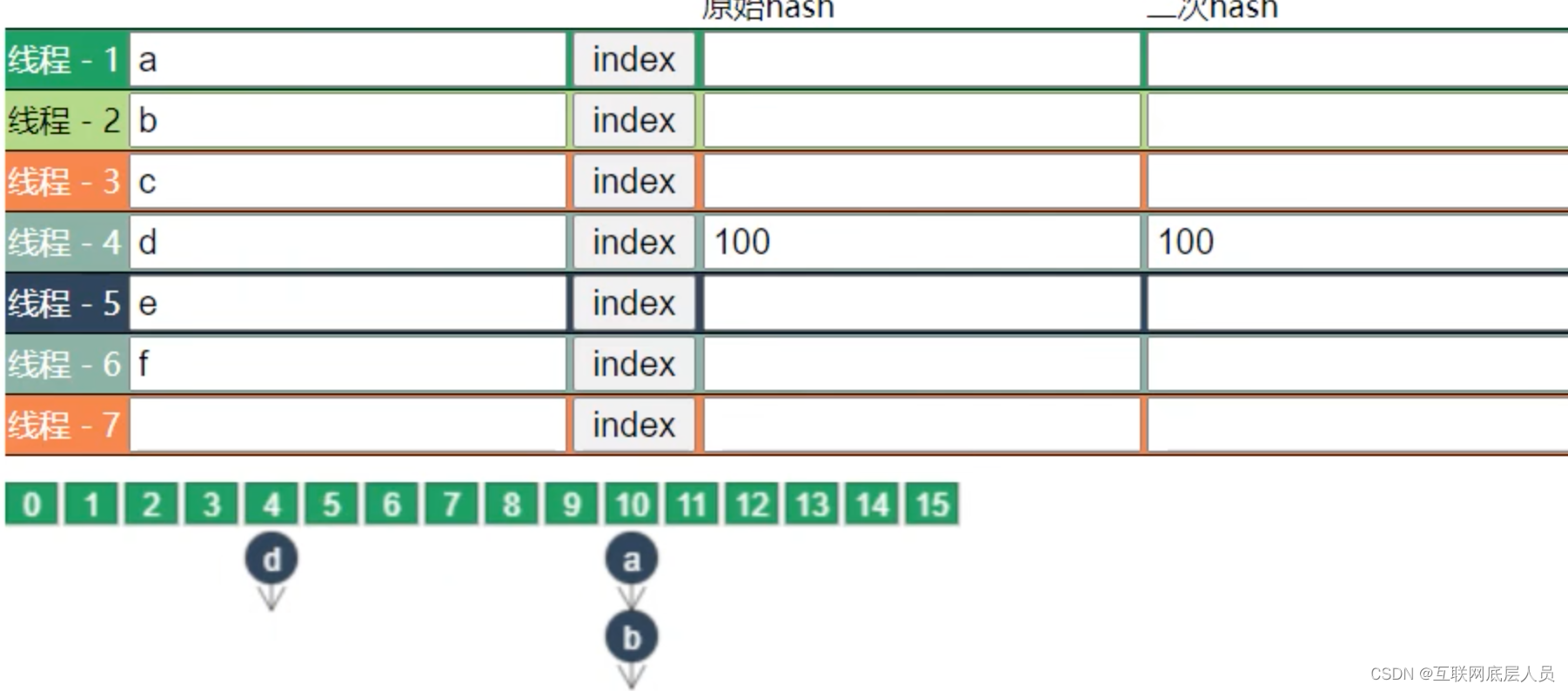
根据二次哈希值先定位到数组索引处,然后占锁,再进行put。数组的大小决定了
ConcurrentHashMap的并发度,也就是说不同索引的Node互不干扰,d的put和ab的put互不影响。但是a和b的put需要占锁释放锁的步骤。
4. 扩容机制
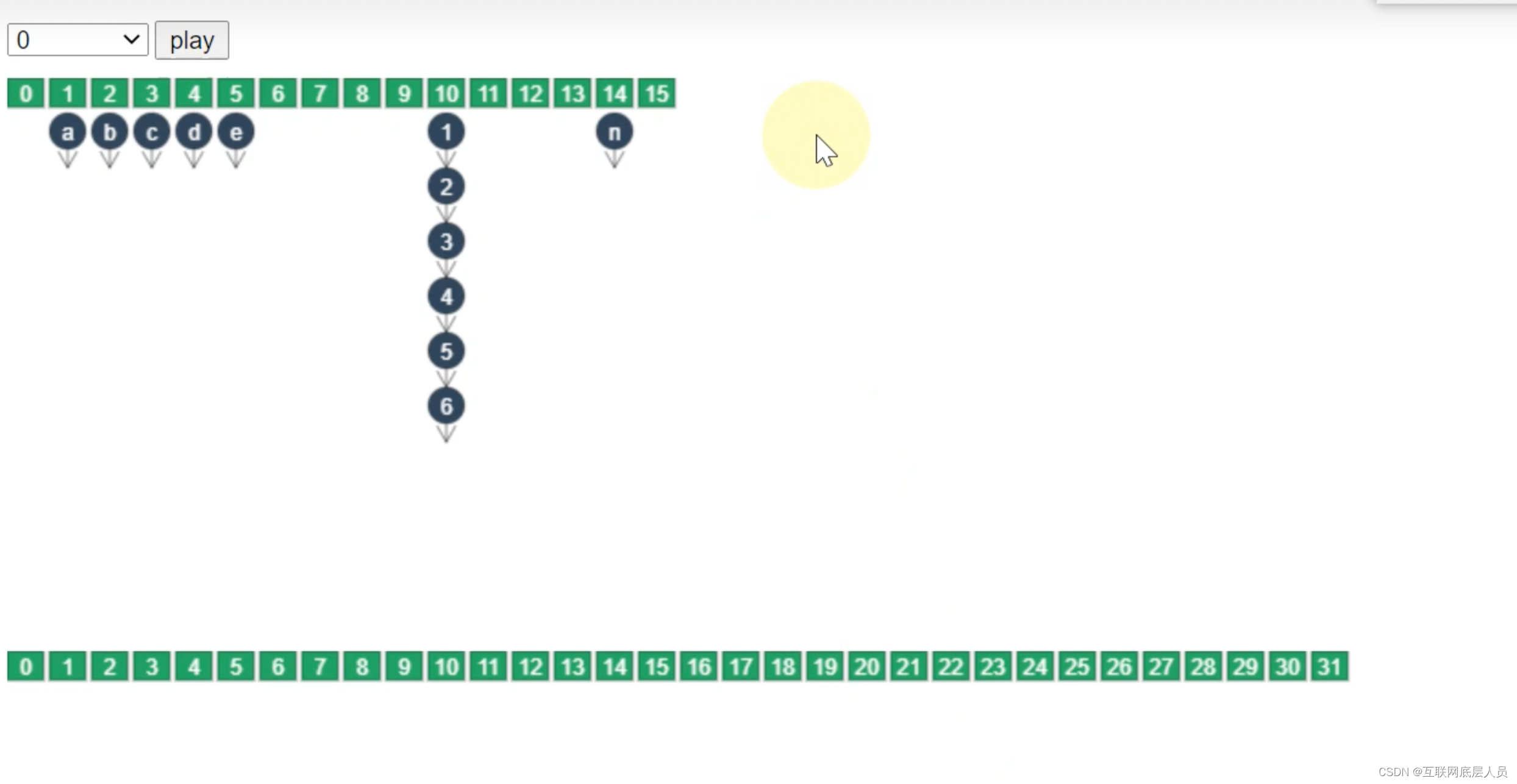
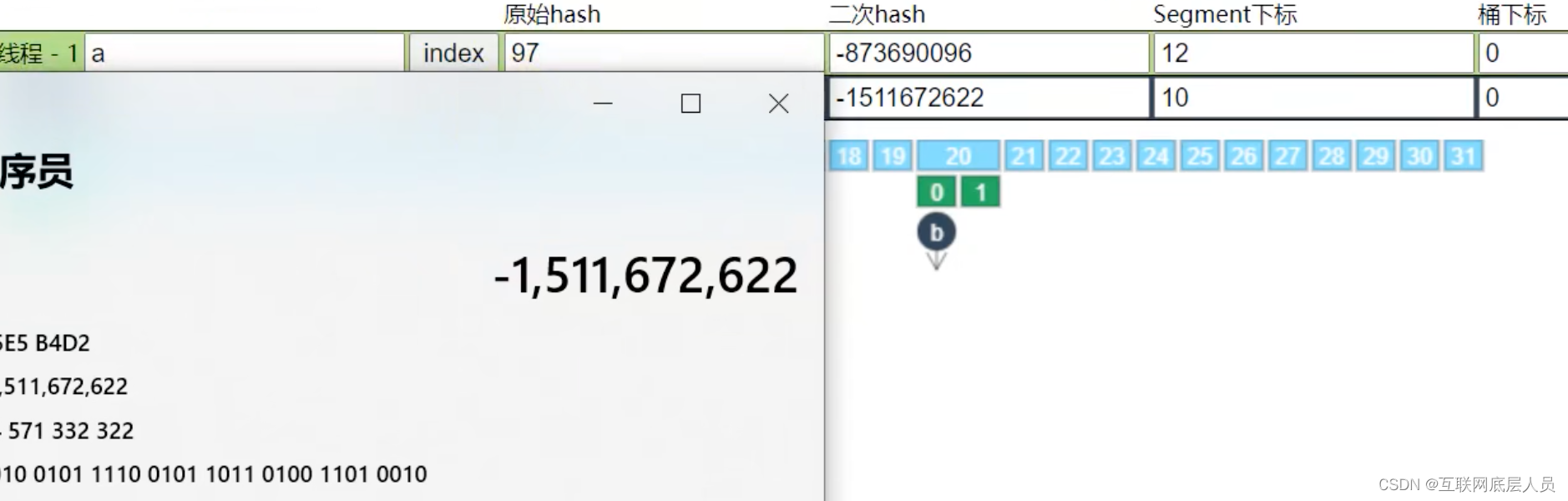
假设n为临界节点,也就是put了n之后就会扩容,与数组方式相同,新建一个容量为2倍的新数组,然后进行数据迁移。
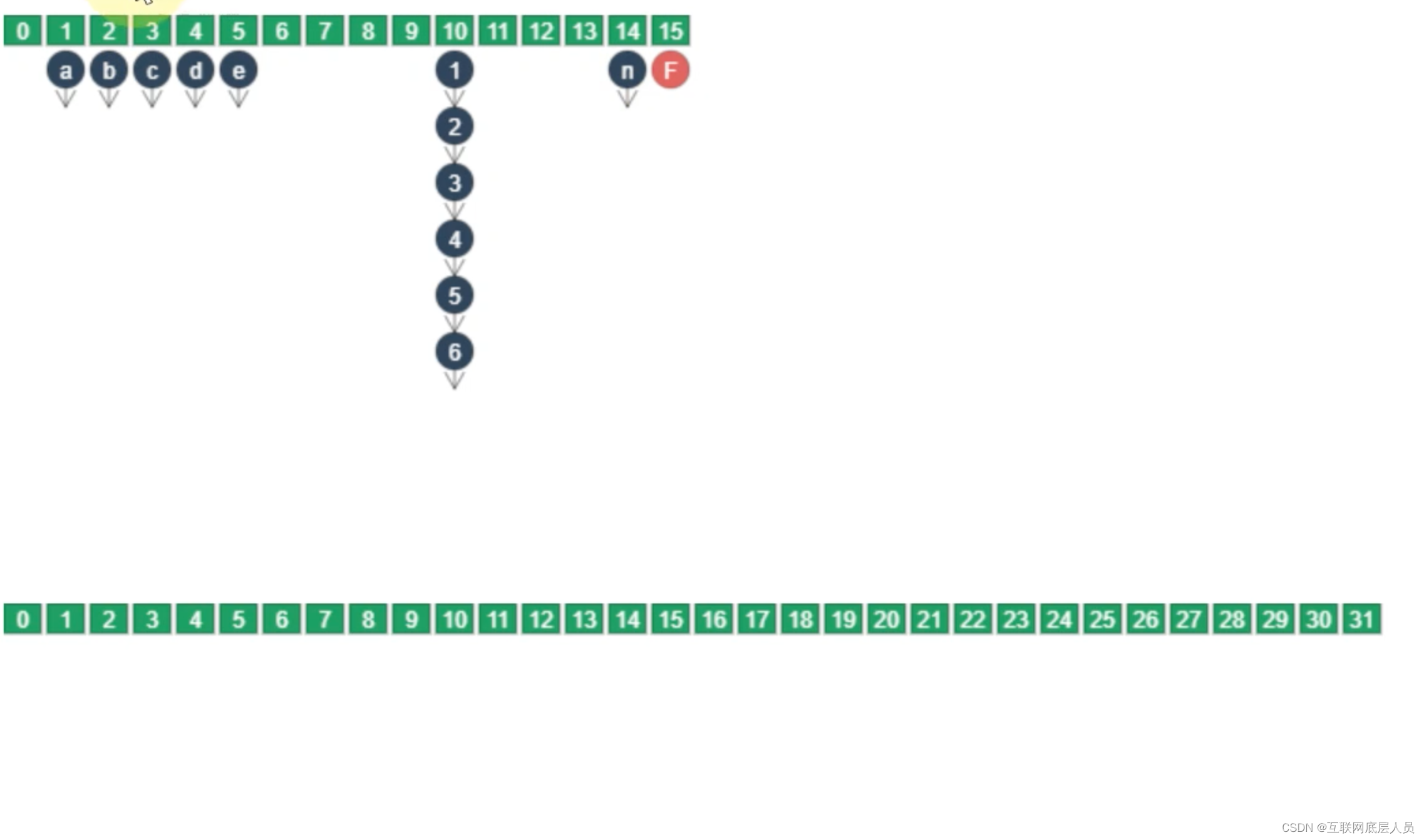
迁移顺序是从后往前进行迁移,每次迁移一个索引的链表或者红黑树。一旦该索引处完成迁移,就会变成Forwarding Node 认为是已完成的Node。
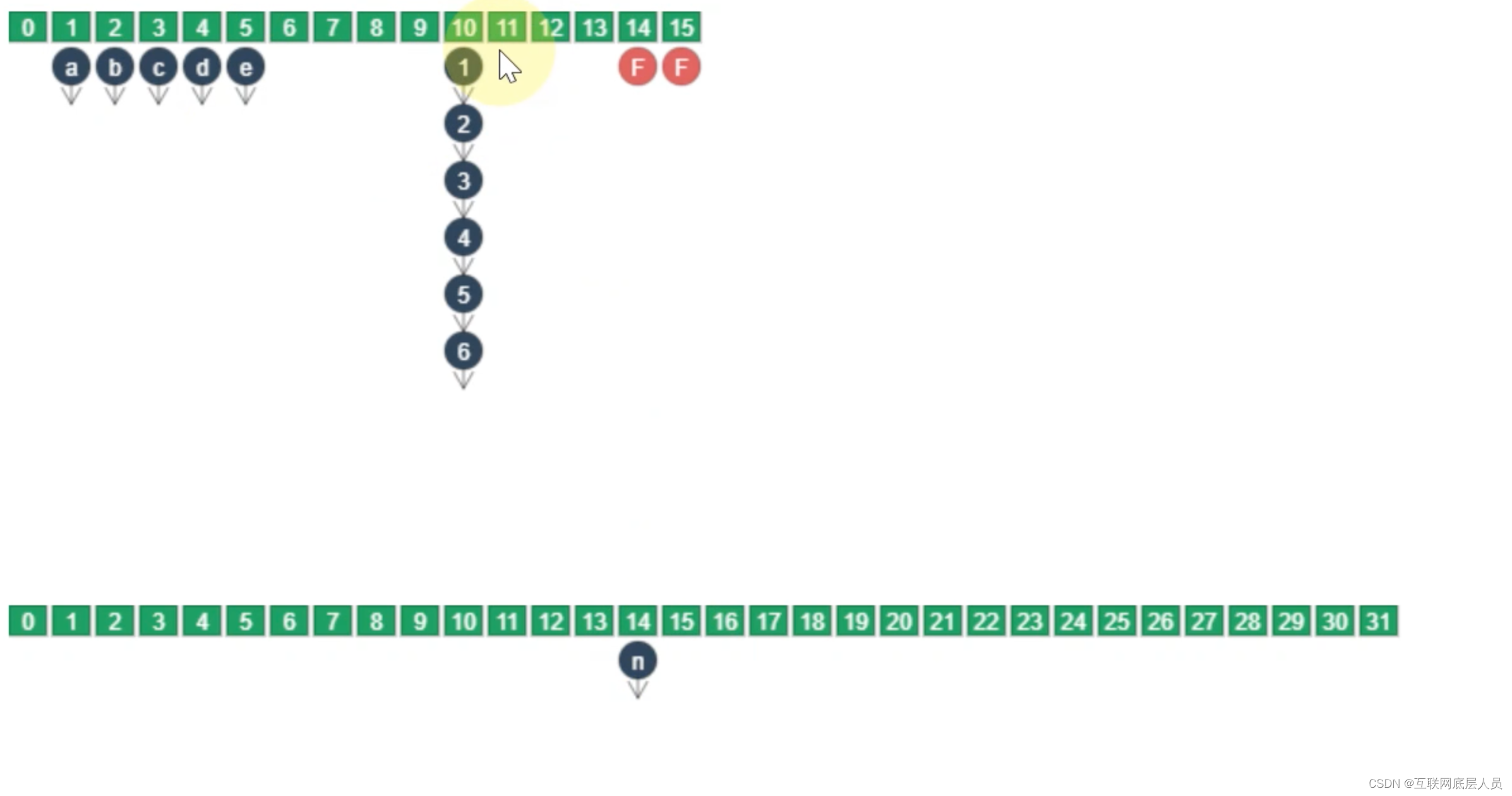
在迁移过程中,需要重新计算二次哈希值,一般情况下会重新创建新的节点,并将该节点插入新的数组中。
在这里为什么需要重新创建新的节点需要说明一下,如上图1这个节点的next指针为2,一旦哈希值重新计算之后,在新的数组中,它的next不一定是2.
当然也有一种情况可以直接引用,不需要再创建节点的情况就是,比如说456三个节点,在新的数组中仍然是该顺序情况,那么就不需要新创建节点。
5. 扩容时的put和get操作
- get的索引在forwarding node之前
那么正常get,并不会影响。
2.get的索引已经变成forwarding
那么直接去新数组中取得get
3.get的索引正在迁移
由上所述,因为扩容之后的节点的next指针可能会变化,所以该线程会等待该索引完成迁移查询新的节点。
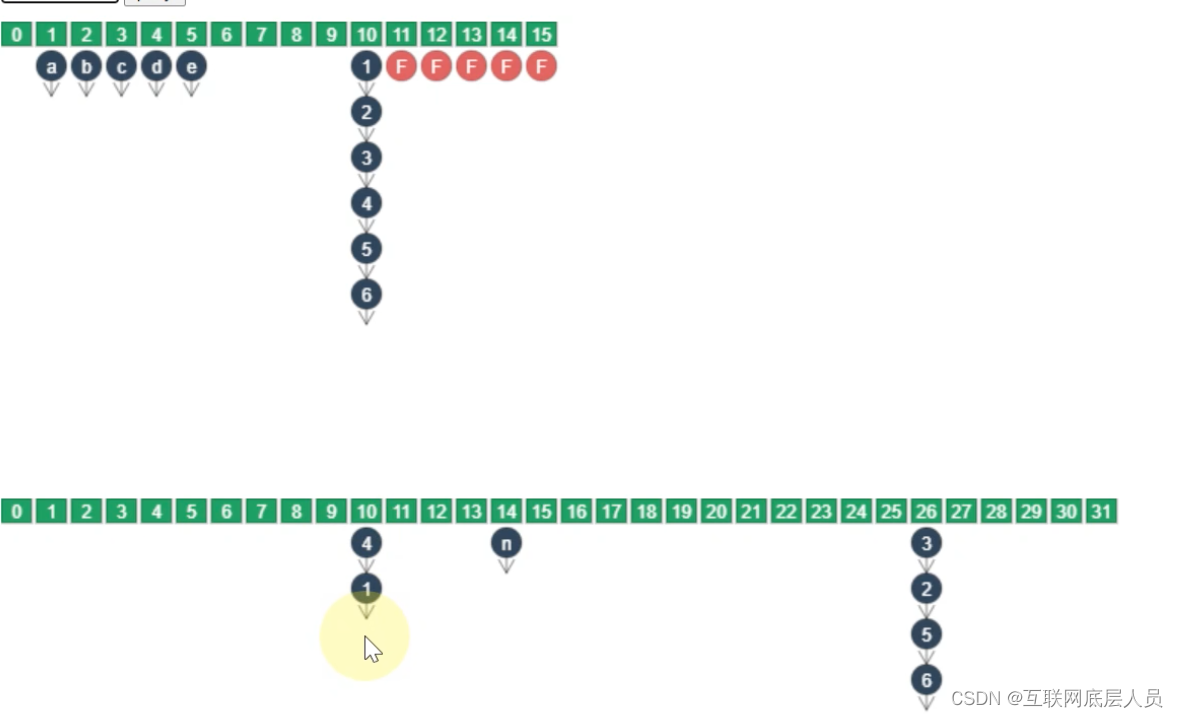
- put的索引在forwarding node之前
同样,正常的并发执行。
2.put的索引已经变成forwarding node
线程会阻塞并帮助前面的node一起进行迁移,因为新的节点只有在所有旧的节点都完成迁移之后才能进行put,这时线程就会帮助前面未完成的索引一起进行迁移。
3.put的索引正在迁移
只能阻塞。
总结和细节
1.JDK1.7 与 JDK1.8 中ConcurrentHashMap 的区别
数据结构:取消了 Segment 分段锁的数据结构,取而代之的是数组+链表+红黑树的结构。
保证线程安全机制:JDK1.7 采用 Segment 的分段锁机制实现线程安全,其中 Segment 继承自 ReentrantLock 。JDK1.8 采用CAS+synchronized保证线程安全。
锁的粒度:JDK1.7 是对需要进行数据操作的 Segment 加锁,JDK1.8 调整为对每个数组元素加锁(Node)。
链表转化为红黑树:定位节点的 hash 算法简化会带来弊端,hash 冲突加剧,因此在链表节点数量大于 8(且数据总量大于等于 64)时,会将链表转化为红黑树进行存储。
查询时间复杂度:从 JDK1.7的遍历链表O(n), JDK1.8 变成遍历红黑树O(logN)。
2.ConcurrentHashMap 的并发度是什么?
并发度可以理解为程序运行时能够同时更新 ConccurentHashMap且不产生锁竞争的最大线程数。在JDK1.7中,实际上就是ConcurrentHashMap中的分段锁个数,即Segment[]的数组长度,默认是16,这个值可以在构造函数中设置。
在JDK1.8中,已经摒弃了Segment的概念,选择了Node数组+链表+红黑树结构,并发度大小依赖于数组的大小。
3. ConcurrentHashMap 迭代器是强一致性还是弱一致性
与 HashMap 迭代器是强一致性不同,ConcurrentHashMap 迭代器是弱一致性。
ConcurrentHashMap 的迭代器创建后,就会按照哈希表结构遍历每个元素,但在遍历过程中,内部元素可能会发生变化,如果变化发生在已遍历过的部分,迭代器就不会反映出来,而如果变化发生在未遍历过的部分,迭代器就会发现并反映出来,这就是弱一致性。
4.ConcurrentHashMap 和 Hashtable 的效率哪个更高?为什么?
ConcurrentHashMap 的效率要高于 Hashtable,因为 Hashtable 给整个哈希表加了一把大锁从而实现线程安全。而ConcurrentHashMap 的锁粒度更低,在 JDK1.7 中采用分段锁实现线程安全,在 JDK1.8 中采用CAS+synchronized实现线程安全。
相关文章:
ConcurrentHashMap-Java八股面试(五)
系列文章目录 第一章 ArrayList-Java八股面试(一) 第二章 HashMap-Java八股面试(二) 第三章 单例模式-Java八股面试(三) 第四章 线程池和Volatile关键字-Java八股面试(四) 提示:动态每日更新算法题,想要学习的可以关注一下 文章目录系列文章目录一、…...

互联网衰退期,测试工程师35岁的路该怎么走...
国内的互联网行业发展较快,所以造成了技术研发类员工工作强度比较大,同时技术的快速更新又需要员工不断的学习新的技术。因此淘汰率也比较高,超过35岁的基层研发类员工,往往因为家庭原因、身体原因,比较难以跟得上工作…...

Windows Cannot Initialize Data Bindings 问题的解决方法
前言 拿到一个调试程序, 怎么折腾都打不开, 在客户那边, 尝试了几个系统版本, 发现Windows 10 21H2 版本可以正常运行。 尝试 系统篇 系统结果公司电脑 Windows 8有问题…下载安装 Windows10 22H2问题依旧下载安装 Windows10 21H2问题依旧家里的 笔记本Window 11正常 网上…...

Leetcode每日一题 1487. 保证文件名唯一
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法......感兴趣就关注我吧!你定不会失望。 🌈个人主页:主页链接 🌈算法专栏:专栏链接 我会一直往里填充内容哒! &…...

Linux常用命令——lsusb命令
在线Linux命令查询工具(http://www.lzltool.com/LinuxCommand) lsusb 显示本机的USB设备列表信息 补充说明 lsusb命令用于显示本机的USB设备列表,以及USB设备的详细信息。 lsusb命令是一个学习USB驱动开发,认识USB设备的助手,推荐大家使用…...

Python——我愿称之为最简单的语言
Python——我愿称之为最简单的语言开发工具基础语法变量和数据类型列表和元组字典if语句while语句函数类文件与异常测试代码参考书籍:《python编程从入门到实践》 开发工具 python编程环境分为两个部分:python解释器和文本编辑器。运行.py文件时&#…...

java.io.IOException: Broken pipe
1、问题出现的场景 线上环境,拉取对账单,走的接口的形式,当天单量比较大,就出现了,拉取订单超时,报了个错java.io.IOException: Broken pipe。 2、解决方案 我们设置的超时时间是100S,由于当…...

Python——列表排序和赋值
(1)列表排序: 列表排序方法 ls.sort() 对列表ls 中的数据在原地进行排序 ls [13, 5, 73, 4, 9] ls.sort()ls.sort(reverseFalse) 默认升序,reverseTrue,降序 ls [13, 5, 73, 4, 9] ls.sort(reverseTrue)key指定排序时…...

python+pytest接口自动化(7)-cookie绕过登录(保持登录状态)
在编写接口自动化测试用例或其他脚本的过程中,经常会遇到需要绕过用户名/密码或验证码登录,去请求接口的情况,一是因为有时验证码会比较复杂,比如有些图形验证码,难以通过接口的方式去处理;再者,…...
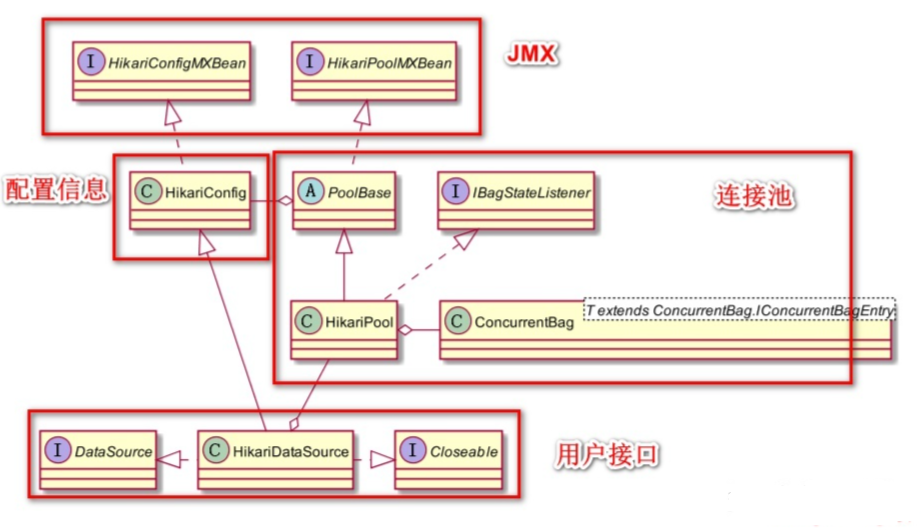
【连接池】什么是HikariCP?HikariCP 解决了哪些问题?为什么要使用 HikariCP?
文章目录什么是连接池什么是HikariCPHikariCP 解决了哪些问题?为什么要使用 HikariCP?HikariCP 的使用Maven支持数据库什么是连接池 数据库连接池负责分配、管理和释放数据库的连接。 数据库连接复用:重复使用现有的数据库长连接࿰…...

Tapdata Cloud 基础课:新功能详解之「微信告警」,更及时的告警通知渠道
【前言】作为中国的 “Fivetran/Airbyte”, Tapdata 是一个以低延迟数据移动为核心优势构建的现代数据平台,内置 60 数据连接器,拥有稳定的实时采集和传输能力、秒级响应的数据实时计算能力、稳定易用的数据实时服务能力,以及低代码可视化操作…...

【巨人的肩膀】JAVA面试总结(四)
💪、JVM 目录💪、JVM1、说一下JVM的主要组成部分及其作用2、什么是JVM内存结构(谈谈对运行时数据区的理解)3、堆和栈的区别是什么4、堆中存什么?栈中存什么?5、为什么不把基本类型放堆中呢?6、为…...

攒了一冬的甜,米易枇杷借力新电商走出川西大山
“绿暗初迎夏,红残不及春。魏花非老伴,卢橘是乡人。”苏轼文中的卢橘,就是枇杷,在苏轼看来,相较于姚黄魏紫,来自故乡四川的枇杷更为亲近。 四川省攀枝花市米易县是全国枇杷早熟产区之一,得益于…...

python-测试相关基础知识-补充
文章目录 1.面向对象1.1 基础概念1.2 面向对象关键字1.2.1 class关键字1.2.2 __init__初始化方法1.2.3 __del__销毁方法1.2.4 __str__输出字符串方法1.3 面向对象三大特点1.3.1 封装1.3.2 继承1.3.3 多态1.4 类属性和类方法1.5 静态方法2.文件操作2.1 文件基本操作2.2 按行读取…...
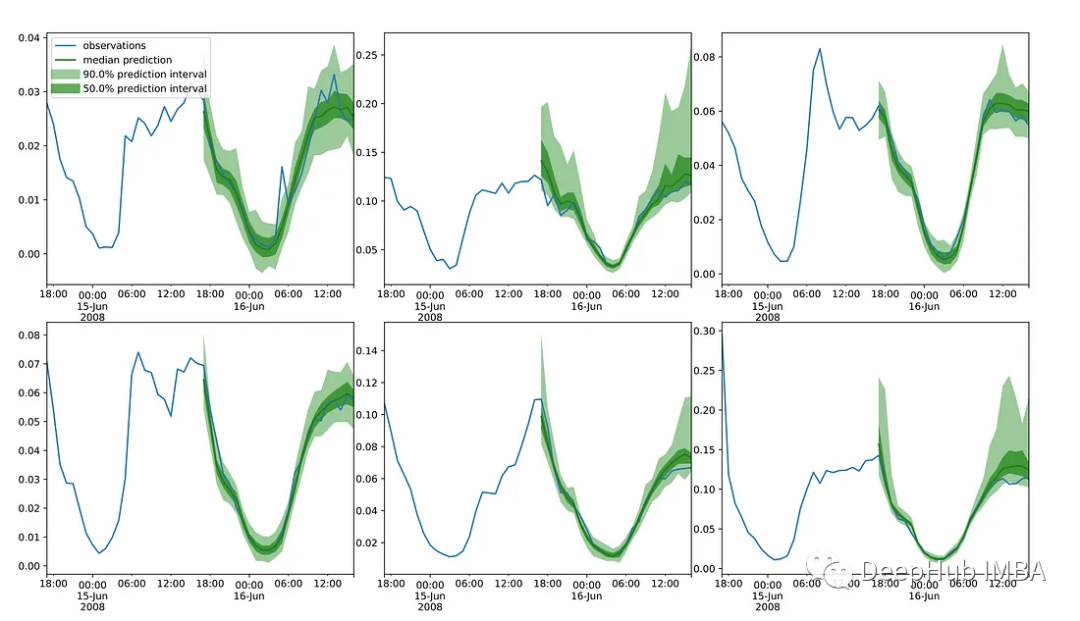
论文推荐:ScoreGrad,基于能量模型的时间序列预测
能量模型(Energy-based model)是一种以自监督方式执行的生成式模型,近年来受到了很多关注。本文将介绍ScoreGrad:基于连续能量生成模型的多变量概率时间序列预测。如果你对时间序列预测感兴趣,推荐继续阅读本文。 为什…...
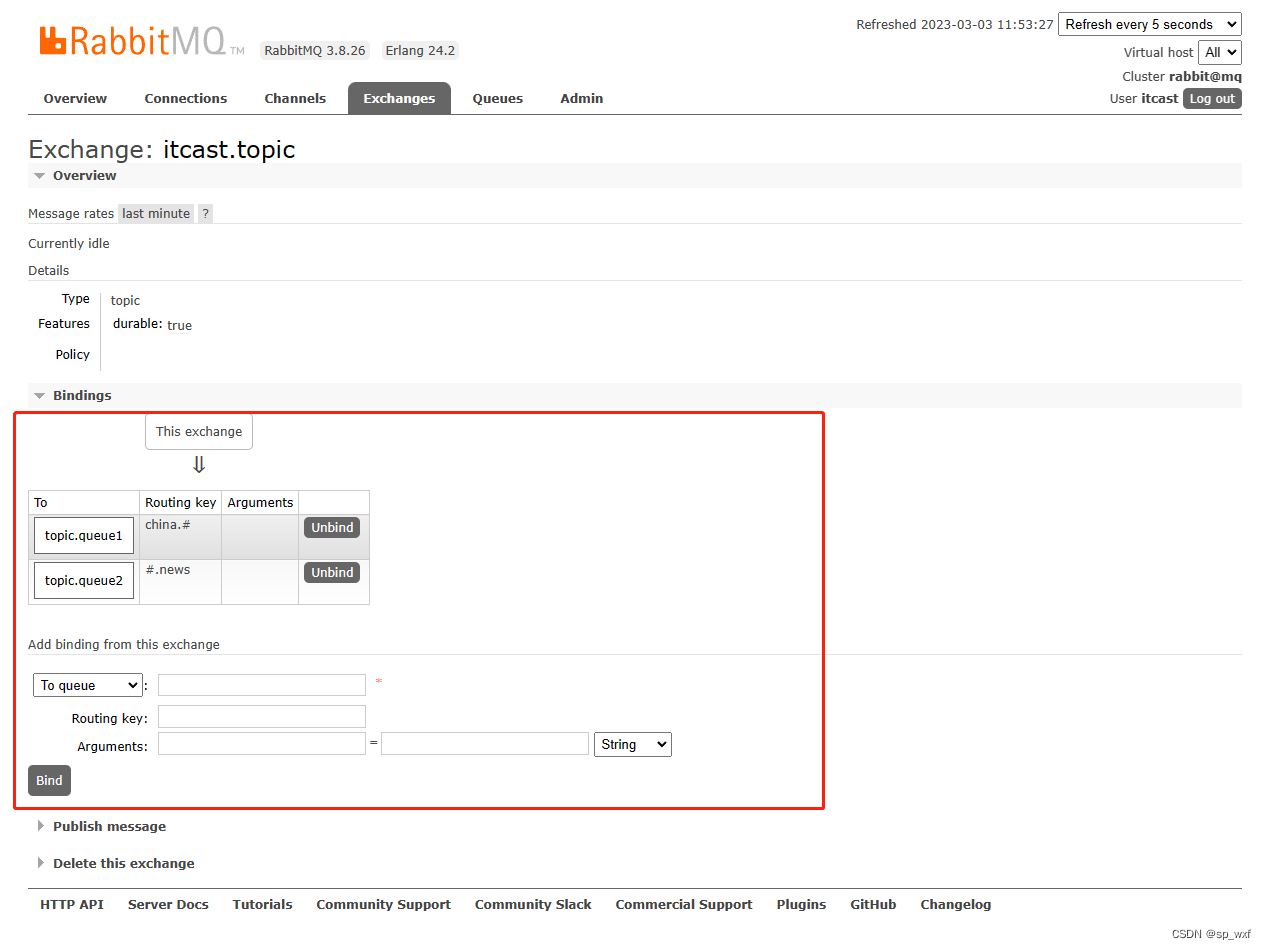
RabbitMq(具体怎么用,看这一篇即可)
RabbitMq汇总1.RabbitMq的传统实现方式2.SpringAMQP简化RabbitMq开发2.1 基本消息队列(BasicQueue)2.2 工作消息队列(WorkQueue)2.3 发布订阅 -- 广播(Fanout)2.4 发布订阅 -- 路由(Direct&…...
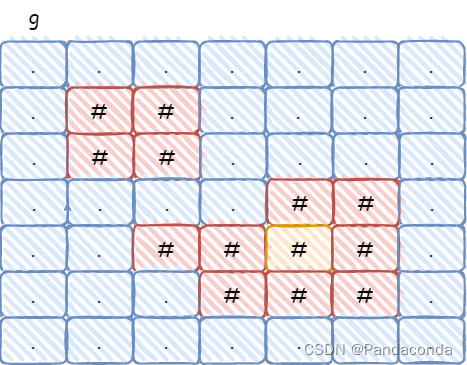
第九届蓝桥杯省赛 C++ A/B组 - 全球变暖
✍个人博客:https://blog.csdn.net/Newin2020?spm1011.2415.3001.5343 📚专栏地址:蓝桥杯题解集合 📝原题地址:全球变暖 📣专栏定位:为想参加蓝桥杯的小伙伴整理常考算法题解,祝大家…...

Leetcode.2359 找到离给定两个节点最近的节点
题目链接 Leetcode.2359 找到离给定两个节点最近的节点 Rating : 1715 题目描述 给你一个 n个节点的 有向图 ,节点编号为 0到 n - 1,每个节点 至多 有一条出边。 有向图用大小为 n下标从 0开始的数组 edges表示,表示节点 i有一条…...
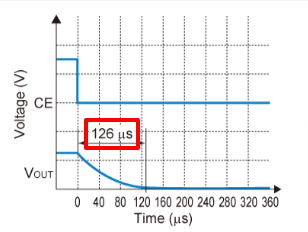
DCDC/LDO Auto-Discharge
1、概念 When using a capacitor with large capacity value in VOUT side, the VOUT pin voltage might not immediately fall to the ground level when the EN(CE,CONTROL) pin is switched from the active mode to the standby mode. By adding N-channel transistor to …...

linux 中的log
linux 中的log 由于内核的特殊性,我们不能使用常规的方法查看内核的信息。下面介绍几种方法。 1 printk()打印内核消息。 2 管理内核内存的daemon(守护进程) Linux系统当中最流行的日志记录器是Sysklogd,Sysklogd 日志记录器由…...

基于MCP协议构建本地AI短信分析工具:mac_messages_mcp项目详解
1. 项目概述:一个让AI“读懂”你Mac短信的桥梁如果你正在折腾AI智能体,尤其是那些能帮你处理日常信息的自动化工具,你可能会遇到一个核心痛点:如何让AI安全、便捷地访问你设备上的原生应用数据?比如,Mac上的…...

知识竞赛的“复活”机制:给落后者第二次机会
🔄 知识竞赛的“复活”机制:给落后者第二次机会包容偶然 挖掘潜力 见证逆袭🎯 引言在知识竞赛中,胜负往往取决于临场发挥、题型适应甚至运气。一次抢答失误、一道冷门题目,都可能让准备充分的选手遗憾离场。…...
)
从“瞎猜”到“精准打击”:我的Qt项目Debug效率提升笔记(附GDB命令行技巧)
从“瞎猜”到“精准打击”:我的Qt项目Debug效率提升笔记(附GDB命令行技巧) 在大型Qt/C项目中,调试往往像在迷宫中摸索——图形化界面提供了便利,但当问题隐藏在动态库或第三方代码深处时,频繁点击"下一…...

构建工程化提示词库:提升AI开发效率与代码质量
1. 项目概述:一个面向开发者的提示词库如果你和我一样,在过去的几年里深度参与了AI应用开发,尤其是基于大语言模型(LLM)的各类项目,那你一定对“提示工程”这个词又爱又恨。爱的是,一段精心设计…...

LSTM时间序列预测实战:从数据预处理到模型调优全解析
1. 项目概述:当时间序列遇上LSTM在数据分析与预测的领域里,时间序列预测一直是个既经典又充满挑战的课题。无论是金融市场的股价波动、电商平台的销量起伏,还是工业设备的传感器读数、城市交通的流量变化,这些按时间顺序排列的数据…...

Airbyte线程管理:10个提升数据同步效率的并发处理优化技巧
Airbyte线程管理:10个提升数据同步效率的并发处理优化技巧 【免费下载链接】airbyte Open-source data movement for ELT pipelines and AI agents — from APIs, databases & files to warehouses, lakes, and AI applications. Both self-hosted and Cloud. …...

重新定义游戏体验:Atmosphere稳定版如何重塑Switch生态系统
重新定义游戏体验:Atmosphere稳定版如何重塑Switch生态系统 【免费下载链接】Atmosphere-stable 大气层整合包系统稳定版 项目地址: https://gitcode.com/gh_mirrors/at/Atmosphere-stable 🔍 传统方案的三大痛点与Atmosphere的突破性解决方案 对…...

Claude Code 模型特定调优与 A/B 测试全解析:Feature Flag、灰度发布、Undercover、安全门控、Prompt 调优与 AI Agent 工程化实战
一、先说结论:AI Agent 真正难的不是“会调用模型”,而是“能持续驾驭模型”很多人做 AI 编码助手、企业智能体、研发提效工具时,第一反应是接入一个更强的大模型:换成更大的参数、更新的版本、更长的上下文,似乎问题就…...

[IdeaLoop · 灵感回路] 独立开发者创业/副业灵感日报 · 2026-05-14
灵感日报 2026年05月14日 从今日全网热点提炼,精选 5 个值得关注的商业方向。— 灵感回路 IdeaLoop 完整报告(含竞品分析、MVP 规划、冷启动策略):idealoop.top 🏆 #1 胶片一键调色助手 综合评分:65 / 10…...

EnigmaVB封包实战:如何为你的Qt小工具制作一个‘绿色单文件版’?
EnigmaVB封包实战:打造极致便携的Qt单文件应用 每次分享自己开发的Qt小工具时,你是否也厌倦了那些繁琐的依赖文件?想象一下,当你的同事或朋友收到一个双击即可运行的独立exe文件时,他们的表情会有多惊喜。这就是Enigma…...