最优化方法Python计算:无约束优化应用——逻辑分类模型
逻辑回归模型更多地用于如下例所示判断或分类场景。
例1 某银行的贷款用户数据如下表:
| 欠款(元) | 收入(元) | 是否逾期 | |
|---|---|---|---|
| 1 | 7000 | 800 | Yes |
| 2 | 2000 | 2500 | No |
| 3 | 5000 | 3000 | Yes |
| 4 | 4000 | 4000 | No |
| 5 | 2000 | 3800 | No |
显然,客户是否逾期(记为 y y y)与其欠款额(记为 x 1 x_1 x1)和收入(记为 x 2 x_2 x2)相关。如果将客户逾期还款记为1,未逾期记为0,我们希望根据表中数据建立 R 2 → { 0 , 1 } \text{R}^2\rightarrow\{0,1\} R2→{0,1}的拟合函数
y = F ( x ) y=F(\boldsymbol{x}) y=F(x)
使得 F ( x i ) ≈ y i , i = 1 , 2 , ⋯ , 5 F(\boldsymbol{x}_i)\approx y_i,i=1,2,\cdots,5 F(xi)≈yi,i=1,2,⋯,5,并用 F ( x ) F(\boldsymbol{x}) F(x)根据新客户的欠款额与收入数据
| 欠款(元) | 收入(元) | 是否逾期 |
|---|---|---|
| 3500 | 3500 | ? |
| 3000 | 2100 | ? |
进行预测分类。
要用回归模型分类,关键在于如何将预测值 y y y离散化为0,1,或一般地离散化为连续的 n n n个整数 N 1 , N 1 + 1 , ⋯ , N 1 + n − 1 , N 2 N_1, N_1+1,\cdots,N_1+n-1,N_2 N1,N1+1,⋯,N1+n−1,N2。解决之道是设置阈值,譬如,设 μ 1 = N 1 + 0.5 , μ 2 = N 1 + 1.5 , ⋯ , μ n − 1 = N 1 + n − 0.5 \mu_1=N_1+0.5,\mu_2=N_1+1.5,\cdots,\mu_{n-1}=N_1+n-0.5 μ1=N1+0.5,μ2=N1+1.5,⋯,μn−1=N1+n−0.5,对 y < μ 1 y<\mu_1 y<μ1, y y y转换为 N 1 N_1 N1; μ i ≤ y < μ i + 1 \mu_i\leq y<\mu_{i+1} μi≤y<μi+1,将其转化为 N 1 + i N_1+i N1+i; y ≥ μ n − 1 y\geq\mu_{n-1} y≥μn−1,转换为 N 2 N_2 N2。
其次,对分类模型的评价指标应该是分类正确率:设 ( x i , y i ) (\boldsymbol{x}_i,y_i) (xi,yi), i = 1 , 2 , ⋯ , m i=1,2,\cdots,m i=1,2,⋯,m为测试数据。用训练所得的最优模式 w 0 \boldsymbol{w}_0 w0,得预测值 y i ′ y'_i yi′, i = 1 , 2 , ⋯ , m i=1,2,\cdots,m i=1,2,⋯,m。记 y = ( y 1 y 2 ⋮ y m ) \boldsymbol{y}=\begin{pmatrix}y_1\\y_2\\\vdots\\y_m\end{pmatrix} y= y1y2⋮ym , y t = ( y 1 ′ y 2 ′ ⋮ y m ′ ) \boldsymbol{y}_t=\begin{pmatrix}y'_1\\y'_2\\\vdots\\y'_m\end{pmatrix} yt= y1′y2′⋮ym′ ,计算 y i = y i ′ y_i=y'_i yi=yi′成立的个数 m 1 m_1 m1,则正确率为 m 1 m × 100 \frac{m_1}{m}\times100 mm1×100。
下列代码实现用于分类的Classification类。
import numpy as np #导入numpy
class Classification(): #分类模型def threshold(self, x): #阈值函数N1 = x.min().astype(int) - 1 #最小阈值整数部分N2 = np.round(x.max()).astype(int) + 1 #最大阈值整数部分y = np.array([N1] * x.size) #因变量数组for n in range(N1, N2): #对每个可能的函数值d = np.where((x >= n - 0.5)&(x < n + 0.5)) #取值区间y[d] = n #函数值if(y.size == 1): #单值情形y = y[0]return ydef predict(self, X): #重载预测函数yp = RegressModel.predict(self, X) #计算预测值return self.threshold(yp) #转换为离散值def accuracy(self, y1, y2): #正确率m = y1.sizeacc=np.where(y1 == y2)[0].size #计算两者相等的元素个数return acc / m * 100def test(self, x, y): #测试函数yp = self.predict(x)return yp, self.accuracy(y, yp)
class LogicClassifier(Classification, LogicModel):'''逻辑分类模型'''
程序中第2~22行定义了用于分类的Classification辅助类。其中第3~12行定义阈值函数threshold。第13~15行在预测函数predict外“套上”阈值函数threshold,筛选出分类值返回。第16~19行定义计算两个等长整数数组y1,y2中对应元素相等的比率函数accuracy。第20~22行定义测试函数test,对测试数据x和y,计算x的预测值yp,然后调用accuracy计算y和yt的相等比率返回。第23~24行联合Classification类和LogicModel类(详见博文《最优化方法Python计算:无约束优化应用——逻辑回归模型》)实现逻辑分类模型类LogicClassifier。下面我们来小试牛刀:用逻辑分类模型LogicClassifier计算例1中的问题。
import numpy as np #导入numpy
x = np.array([[7000, 800], #设置训练、测试数据[2000, 2500],[5000, 3000],[4000, 4000],[2000, 3800]])
y = np.array([1, 0, 1, 0, 0])
title = np.array(['No', 'Yes']) #预测值标签
np.random.seed(2024) #随机种子
credit = LogicClassifier() #创建逻辑分类模型
credit.fit(x,y) #训练
_, acc=credit.test(x,y) #测试
print('准确率:%.1f'%acc + '%')
x1 = np.array([[3500, 3500], #设置预测数据[3000, 2100]])
print('对测试数据:')
print(x1)
Y = credit.predict(x1) #计算预测值
print('归类为:')
print([title[y] for y in Y])
看官可借助代码内注释信息理解程序,需要提请注意的是第9行设置随机种子是为了使看官的运行结果与下列的输出一致。运行程序,输出
训练中...,稍候
3次迭代后完成训练。
准确率:100.0%
对测试数据:
[[3500 3500][3000 2100]]
归类为:
['No', 'Yes']
开胃菜后,上正餐。
综合案例
文件iris.csv(来自UC Irvine Machine Learning Repository)是统计学家R. A. Fisher在1936年采集的一个小型经典数据集,这是用于评估分类方法的最早的已知数据集之一。该数据集含有150例3种鸢尾花:setosa、versicolour和virginica的数据
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species | |
|---|---|---|---|---|---|
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 2 | 4.9 | 3 | 1.4 | 0.2 | setosa |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| ⋯ \cdots ⋯ | ⋯ \cdots ⋯ | ⋯ \cdots ⋯ | ⋯ \cdots ⋯ | ⋯ \cdots ⋯ | ⋯ \cdots ⋯ |
| 51 | 7 | 3.2 | 4.7 | 1.4 | versicolor |
| 52 | 6.4 | 3.2 | 4.5 | 1.5 | versicolor |
| 53 | 6.9 | 3.1 | 4.9 | 1.5 | versicolor |
| ⋯ \cdots ⋯ | ⋯ \cdots ⋯ | ⋯ \cdots ⋯ | ⋯ \cdots ⋯ | ⋯ \cdots ⋯ | ⋯ \cdots ⋯ |
| 148 | 6.5 | 3 | 5.2 | 2 | virginica |
| 149 | 6.2 | 3.4 | 5.4 | 2.3 | virginica |
| 150 | 5.9 | 3 | 5.1 | 1.8 | virginica |
五个数据属性的意义分别为
- Sepal.Length:花萼长度;
- Sepal.Width:花萼宽度;
- Petal.Length:花瓣长度;
- Petal.Width:花瓣宽度;
- Species:种类。
下列代码从文件中读取数据,将花的种类数字化。
import numpy as np #导入numpy
data = np.loadtxt('iris.csv', delimiter=',', dtype=str) #读取数据文件
X = np.array(data) #转换为数组
X = X[:, 1:] #去掉编号
title = X[0, :4] #读取特征名称
X = X[1:, :] #去掉表头
Y = X[:, 4] #读取标签数据
X = X[:, :4].astype(float)
m = X.shape[0] #读取样本个数
print('共有%d个数据样本'%m)
print('鸢尾花特征数据:')
print(X)
Y = np.array([0 if y == 'setosa' else #类别数值化1 if y == 'versicolor' else2 for y in Y])
print('鸢尾花种类数据:')
print(Y)
运行程序,输出
共有150个数据样本
鸢尾花特征数据:
[[5.1 3.5 1.4 0.2][4.9 3. 1.4 0.2][4.7 3.2 1.3 0.2]
...[6.5 3. 5.2 2. ][6.2 3.4 5.4 2.3][5.9 3. 5.1 1.8]]
鸢尾花种类数据:
[0 0 0 ... 2 2 2]
花萼的长度、宽度,花瓣的长度、宽度对鸢尾花的种类有明显的相关性。接下来我们要从数据集中随机选取一部分作为训练数据,训练LogicClassifier分类模型,然后用剩下的数据进行测试,评价训练效果。在前面的程序后添加以下代码
……
a = np.arange(m) #数据项下标
np.random.seed(2024)
index = np.random.choice(a,m//3,replace=False) #50个随机下标
Xtrain = X[index] #训练数据
Ytrain = Y[index]
index1 = np.setdiff1d(a,index) #测试数据下标
Xtest = X[index1] #测试数据
Ytest = Y[index1]
iris = LogicClassifier() #创建模型
print('随机抽取%d个样本作为训练数据。'%(m//3))
iris.fit(Xtrain,Ytrain) #训练模型
_, accuracy = iris.test(Xtest,Ytest) #测试
print('对其余%d个数据测试,分类正确率为%.2f'%(m-m//3,accuracy)+'%')
运行程序输出
……
随机抽取50个样本作为训练数据。
训练中...,稍候
23次迭代后完成训练。
对其余100个数据测试,分类正确率为99.00%
第1行的省略号表示前一程序的输出。从测试结果可见训练效果效果不错!
相关文章:

最优化方法Python计算:无约束优化应用——逻辑分类模型
逻辑回归模型更多地用于如下例所示判断或分类场景。 例1 某银行的贷款用户数据如下表: 欠款(元)收入(元)是否逾期17000800Yes220002500No350003000Yes440004000No520003800No 显然,客户是否逾期ÿ…...
springboot定时执行某个任务
springboot定时执行某个任务 要定时执行的方法加上Schedule注解 括号内跟 cron表达式 “ 30 15 10 * * ?” 代表秒 分 时 日 月 周几 启动类上加上EnableScheduling 注释...

Java EE Servlet之Servlet API详解
文章目录 1. HttpServlet1.1 核心方法 2. HttpServletRequest3. HttpServletResponse 接下来我们来学习 Servlet API 里面的详细情况 1. HttpServlet 写一个 Servlet 代码,都是要继承这个类,重写里面的方法 Servlet 这里的代码,只需要继承…...

neo4j运维管理
管理数据库 概念 Neo4j 5(从v4.0),可以同时创建和使用多个活动数据库。 DBMS Neo4j是一个数据库管理系统(DBMS),能够管理多个数据库。DBMS可以管理一个独立的服务器,也可以管理集群中的一组服务器。 实例 Neo4j实例是运行Neo4j服务器代…...
【MYSQL】-函数
💖作者:小树苗渴望变成参天大树🎈 🎉作者宣言:认真写好每一篇博客💤 🎊作者gitee:gitee✨ 💞作者专栏:C语言,数据结构初阶,Linux,C 动态规划算法🎄 如 果 你 …...
传统船检已经过时?AR智慧船检来助力!!
想象一下,在茫茫大海中,一艘巨型货轮正缓缓驶过。船上的工程师戴着一副先进的AR眼镜,他们不再需要反复翻阅厚重的手册,一切所需信息都实时显示在眼前。这不是科幻电影的场景,而是智慧船检技术带来的现实变革。那么问题…...

JAVA进化史: JDK11特性及说明
JDK 11(Java Development Kit 11)是Java平台的一个版本,于2018年9月发布。这个版本引入了一些新特性和改进,以下是其中一些主要特性。 HTTP Client(标准化) JDK 11引入了一个新的HTTP客户端,用…...
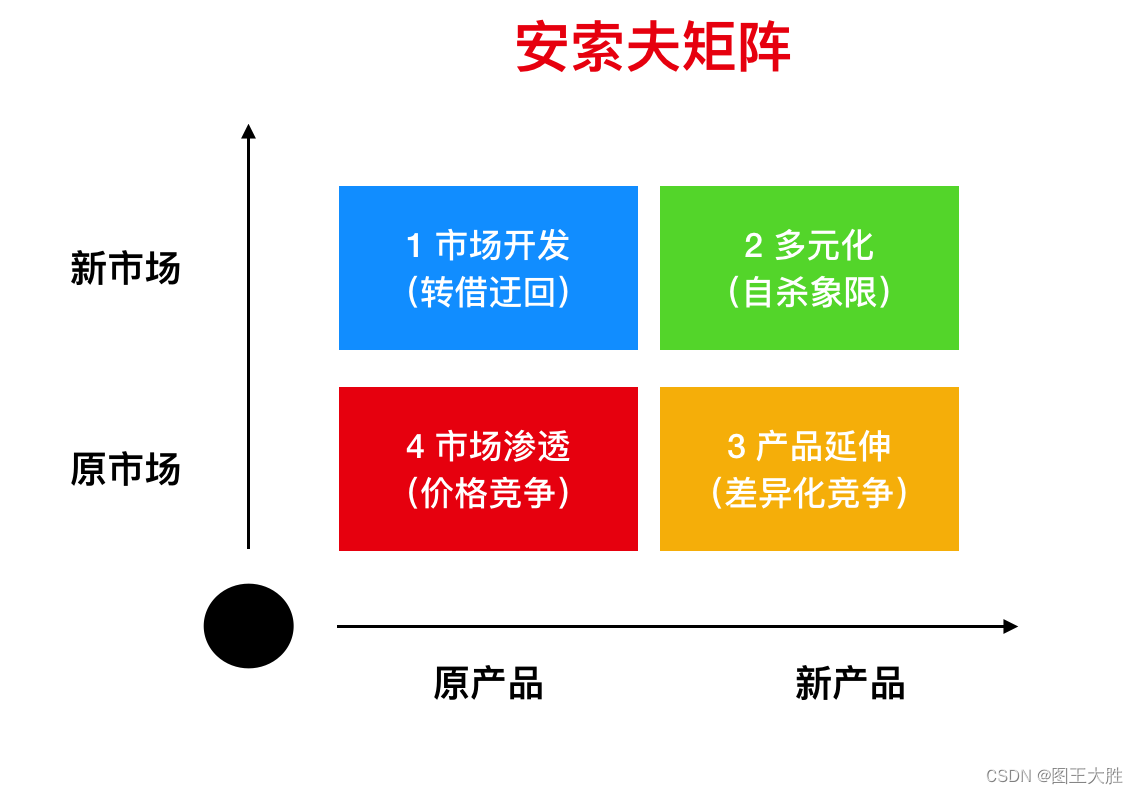
模型 安索夫矩阵
本系列文章 主要是 分享模型,涉及各个领域,重在提升认知。产品市场战略。 1 安索夫矩阵的应用 1.1 江小白的多样化经营策略 使用安索夫矩阵来分析江小白市场战略。具体如下: 根据安索夫矩阵,江小白的现有产品是其白酒产品&…...

性能手机新标杆,一加 Ace 3 发布会定档 1 月 4 日
12 月 27 日,一加宣布将于 1 月 4 日发布新品一加 Ace 3。一加 Ace 系列秉持「产品力优先」理念,从一加 Ace 2、一加 Ace 2V 到一加 Ace 2 Pro,款款都是现象级爆品,得到了广大用户的认可与支持。作为一加 2024 开年之作࿰…...

Vue 框架前导:详解 Ajax
Ajax Ajax 是异步的 JavaScript 和 XML。简单来说就是使用 XMLHttpRequest 对象和服务器通信。可以使用 JSON、XML、HTML 和 text 文本格式来发送和接收数据。具有异步的特性,可在不刷新页面的情况下实现和服务器的通信,交换数据或者更新页面 01. 体验 A…...

3分钟快速安装 ClickHouse、配置服务、设置密码和远程登录以及修改数据目录
下面是一个完整的 ClickHouse 安装和配置流程,包括安装 ClickHouse、配置服务、设置密码和远程登录以及修改数据目录。 安装 ClickHouse 安装 YUM 工具包: sudo yum install -y yum-utils添加 ClickHouse YUM 仓库: sudo yum-config-manager…...

PHP8使用PDO对象增删改查MySql数据库
PDO简介 PDO(PHP Data Objects)是一个PHP扩展,它提供了一个数据库访问层,允许开发人员使用统一的接口访问各种数据库。PDO 提供了一种用于执行查询和获取结果的简单而一致的API。 以下是PDO的一些主要特点: 统一接口…...
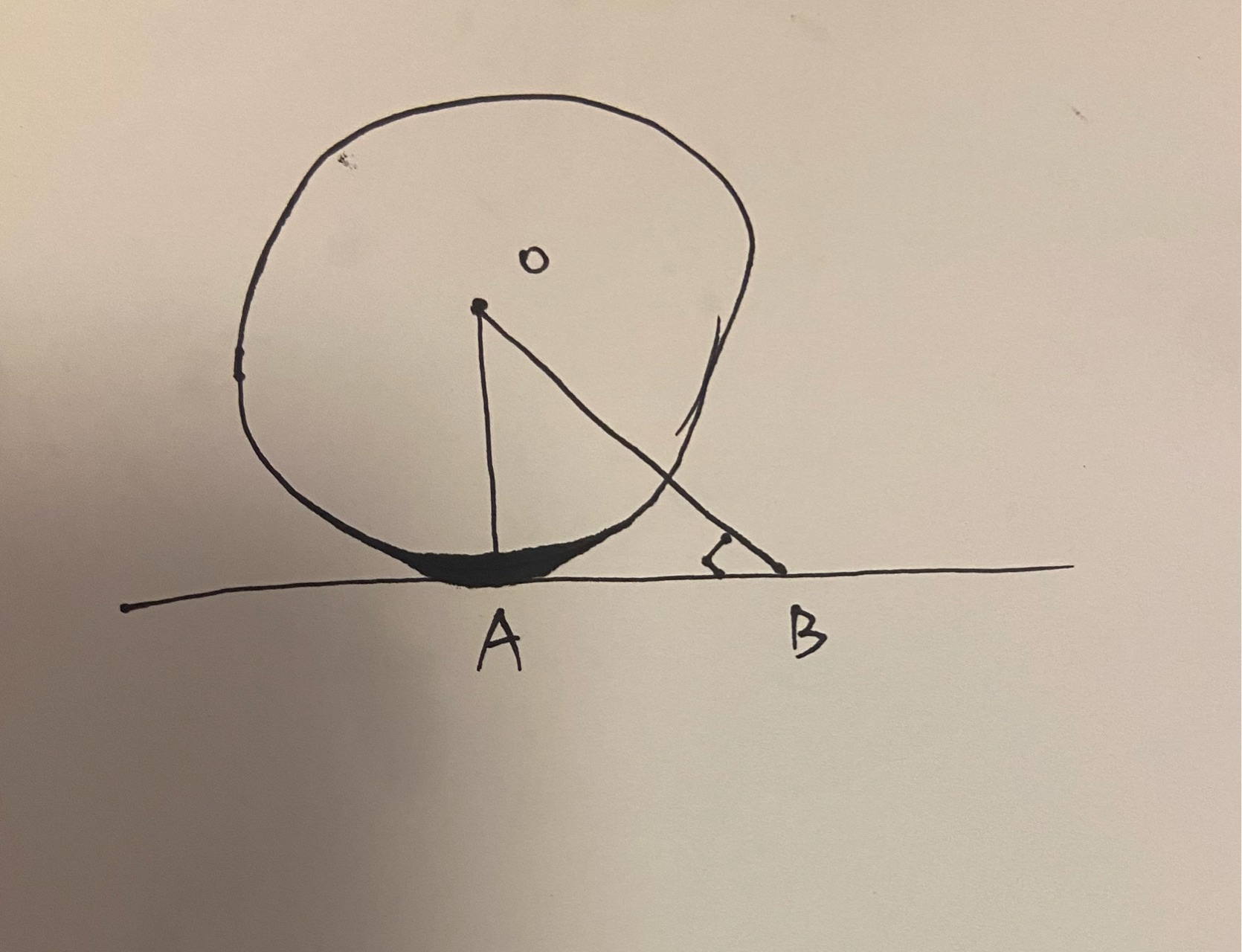
证明:切线垂直于半径
证明: 切线垂直于过切点的半径。 下面是网上最简单的证明方法。 证明: 利用反证法。 如下图所示,直线AB和圆O切于点A,假设OA 不垂直于 AB,而 O B ⊥ A B OB \perp AB OB⊥AB,则 ∠ O B A 90 \angle OB…...
普中STM32-PZ6806L开发板(STM32CubeMX创建项目并点亮LED灯)
简介 搭建一个用于驱动 STM32F103ZET6 GPIO点亮LED灯的任务;电路原理图 LED电路原理图 芯片引脚连接LED驱动引脚原理图 创建一个点亮LED灯的Keil 5项目 创建STM32CubeMX项目 New Project -> 单击 -> 芯片搜索STM32F103ZET6->双击创建 初始化时钟 调试设置 一…...
【Windows】共享文件夹拍照还原防火墙设置(入站,出站设置)---图文并茂详细讲解
目录 一 共享文件夹(两种形式) 1.1 普通共享与高级共享区别 1.2 使用 二 拍照还原 2.1 是什么 2.2 使用 三 防火墙设置(入栈,出站设置) 3.1 引入 3.2 入站出站设置 3.2.1入站出站含义 3.3入站设置 3.4安装jdk 3.5使用tomcat进行访…...
1.决策树
目录 1. 什么是决策树? 2. 决策树的原理 2.1 如何构建决策树? 2.2 构建决策树的数据算法 2.2.1 信息熵 2.2.2 ID3算法 2.2.2.1 信息的定义 2.2.2.2 信息增益 2.2.2.3 ID3算法举例 2.2.2.4 ID3算法优缺点 2.2.3 C4.5算法 2.2.3.1 C4.5算法举例 2.2.4 CART算法 2.2.4…...

基于微信小程序的停车预约系统设计与实现
基于微信小程序的停车预约系统设计与实现 项目概述 本项目旨在结合微信小程序、后台Spring Boot和MySQL数据库,打造一套高效便捷的停车预约系统。用户通过微信小程序进行注册、登录、预约停车位等操作,而管理员和超级管理员则可通过后台管理系统对停车…...

再见2023,你好2024
再见2023,你好2024 生活1月 悲伤与治愈2~4月 运动与偏爱5月 体验与美食6月 婚礼与热爱7~8月 就医与别离9~11月 陪伴与暖房12月 体验&新生 运动追剧读书总结 生活 生活是一个修罗场,来世间一场,要经历丰腴有趣的人生。去体验各种滋味&…...

年度总结|存储随笔2023年度最受欢迎文章榜单TOP15-part1
原创 古猫先生 存储随笔 2023-12-31 08:31 发表于上海 回首2023 2-8月份有近半年时间基本处于断更状态 好在8月份后小编没有松懈 (虽然2023年度总结,更像是近4个月总结) 本年度顺利加V啦! 感谢各位粉丝朋友的一路支持与陪伴 …...

微信小程序 手机号授权登录 偶尔后端解密失败
微信小程序wx.login获取code要在手机号授权前触发 <button:id"code":open-type"hasGetPrivacySetting ? getPhoneNumber|agreePrivacyAuthorization : getPhoneNumber"getphonenumber"onGetPhoneNumber"class"btn"click"cli…...

数字合成器d-FORMANT:从模拟经典到数字复刻的工程实践
1. 项目概述:从模拟经典到数字复刻如果你对合成器稍有了解,或者对电子音乐制作背后的硬件感兴趣,那么“FORMANT”这个名字你一定不陌生。它最初是上世纪70年代由《Elektor》杂志发布的一款模拟单音合成器,以其清晰的模块化设计和出…...

从XAI到HXAI:构建以人为中心的可解释AI框架与实践
1. 项目概述:从“黑箱”到“白盒”,构建可信AI的演进之路在机器学习项目里摸爬滚打了十几年,我见过太多因为模型“说不清道不明”而引发的信任危机。一个在测试集上表现完美的信用评分模型,可能因为无法向风控专家解释“为什么拒绝…...

终极艾尔登法环存档迁移指南:3分钟学会角色无损转移
终极艾尔登法环存档迁移指南:3分钟学会角色无损转移 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档迁移而烦恼吗?当游戏版本更新后,你辛辛苦苦培…...

让B站缓存视频重获自由:一个简单实用的格式转换工具
让B站缓存视频重获自由:一个简单实用的格式转换工具 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 还记得那个周末的下午吗…...

抖音下载器深度解析:零基础轻松批量下载无水印视频
抖音下载器深度解析:零基础轻松批量下载无水印视频 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...

KMS智能激活工具:如何一键永久激活Windows和Office的完整指南
KMS智能激活工具:如何一键永久激活Windows和Office的完整指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows和Office激活问题而烦恼吗?每次系统重装后都要…...

基于心理生理测试数据的认知年龄预测:从数据清洗到集成学习实战
1. 项目概述:从心理生理测试数据中预测认知年龄在认知科学和健康老龄化研究领域,我们常常面临一个核心挑战:如何客观、量化地评估一个人的“认知年龄”。这个概念不同于生理年龄,它反映的是个体基于其当前认知功能表现(…...

Unity背包拖拽实战:三坐标系映射与跨Panel交互原理
1. 这不是“拖一拖就完事”的UI小功能,而是Unity UI系统能力的实战压力测试 在Unity项目里,“背包装备拖拽”这六个字,新手常以为只是给Image加个DragHandler接口、写几行OnBeginDrag/OnDrag/OnEndDrag回调——结果上线前一周,策划…...

架构师的一天:开会、画图、背锅?真实工作大揭秘
架构师的一天:开会、画图、背锅?真实工作大揭秘 一、写在前面 很多程序员对架构师的工作充满好奇,也充满误解: “架构师是不是整天就画图?” “架构师不用写代码,太爽了吧?” “架构师就是开会的,多轻松” 今天我用一个架构师的一天,带你看看真实的架构师工作是什么…...

DS4Windows终极指南:5分钟让PS手柄在Windows电脑上完美运行
DS4Windows终极指南:5分钟让PS手柄在Windows电脑上完美运行 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PS4/PS5手柄在Windows电脑上无法识别而烦恼吗?DS…...