【并行计算】GPU,CUDA
一、CUDA层次结构
1.kernel核函数
一个CUDA程序是一个kernel核函数被GPU的多个计算单元并行执行的过程,CUDA给了如下抽象
dim3 threadsPerBlock(4, 3, 1);
dim3 numBlocks(3, 2, 1);
matrixAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
2.Grid,Block,Thread
这样启动核函数,根据CUDA的抽象,就会有下面这样的运行模式,<<<>>>中间的两个参数numblocks和threadsPerBlock都是三维的变量,给予程序员设计的便利。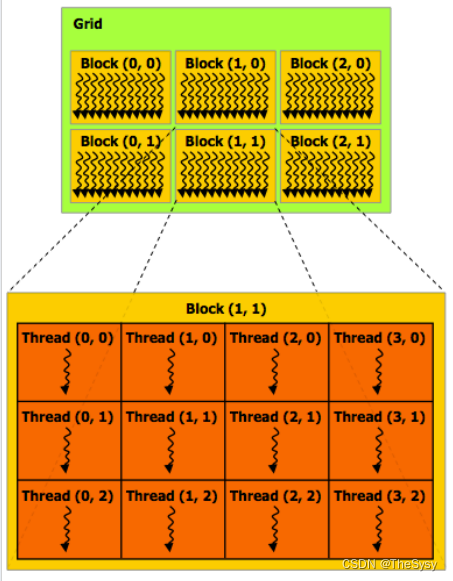
每个thread就是一个实际的核函数在运行,核函数可以根据当前的blockIdx,threadIdx来获得当前核函数所在的三维坐标位置。
int index = blockIdx.x * blockDim.x + threadIdx.x;
3.Streaming Multiprocessor(SM),warp
每个Block会分给一个SM(Streaming Multiprocessor),一个SM可以理解成一个有很多核的处理单元,并且有一个共享内存,下面看看一个SM内部如何工作。

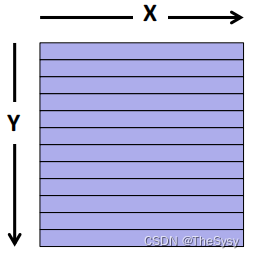
下面这个图是一个典型的SM内部,每个黄方框都是一个SIMD单元,他们共享一个内存,左边的warp是实际分配给这些SIMD单元的任务,一个warp是一些线程的集合,CUDA用行优先的逻辑将一个block里的thread分配给warp,注意CUDA这里dim这个东西横纵坐标跟别的不太一样,如下图,他是Y是行号,X是列号。
在CUDA文档中,有讲到是根据线程id来顺序连续分配的,线程id计算方式如下
对于1维的来说,1维的x就是线程id
对于2维的来说,id是x + y Dx,y是行号,x是列号,所以就是行号乘一行的数量再加上列号。
对于3维的来说,id是x + y Dx + z Dx Dy,那就是高(z)乘上一个面的线程数,再加上y乘上行长在加上x。
所以总结来说,就是先分配面,然后在面上行优先分配。
一个warp通常是32个thread来执行SIMD指令,因为每个线程都是同样的核函数。但这里其实会有一个问题,那就是条件分支可能会不一样,最大的效率在这32个线程都执行相同的条件分支时达到,因为不同的分支会导致simd单元先执行一部分,而另一部分会等这部分执行完在执行。
所以一个warp才类似于操作系统中的一个线程,GPU会将warp视为线程来做硬件多线程调度。
看左边这一堆warp,存的就是每个warp的运行时状态,这里面包含了每个warp独立的寄存器、PC等东西,所以这里GPU做的硬件多线程就类似于一种超线程技术,使用多套上下文,使上下文切换没有开销。

二、CUDA内存层次结构

从最快的每个thread私有的内存,然后是整个块共享的一片内存,然后到整个GPU共享的全局内存。
一个值得注意的点,当一个warp访问内存中连续的地址时,会做块读取/写入,一次性将一个块内容读取/写入,所以如果让一个warp内的线程具有连续的内存访问模式,是比较好的,结合刚才的,如果也有同样的条件分支,那更好了。
三、一个矩阵乘法的优化例子
1.最基本的

直接A的行乘B的列相加,这会导致B的内存访问模式是跳跃的,不缓存友好。
2.预转置
那么就把B提前转置了,这样A和B都可以一行一行的访问了。
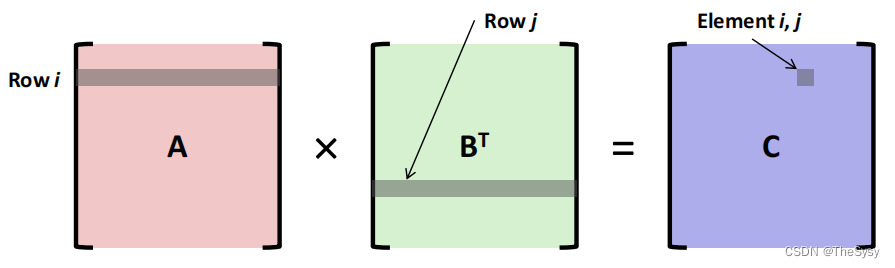
可以看到有一定的优化了

3.变成CUDA代码
最基础的版本,我们让C结果矩阵的每一个元素都用一个核函数来算结果,i和j就是C矩阵的i和j,我们直接将整个grid,映射成一个二维矩阵,那么横坐标i就是先拿块id的y乘上块的长度再加上块里面线程的横坐标y。纵坐标也类似。
___global__ void CUDASimpleKernel(int N, float *dmatA, float *dmatB, float *dmatC)
{int i = blockIdx.y * blockDim.y + threadIdx.y;int j = blockIdx.x * blockDim.x + threadIdx.x;if (i >= N || j >= N)return;float sum = 0.0;for (int k = 0; k < N; k++){sum += dmatA[RM(i, k, N)] * dmatB[RM(k, j, N)];}dmatC[RM(i, j, N)] = sum;
}
然后i,j确定下来后,就去用k遍历A矩阵的一行和B矩阵的一列来计算结果元素。

当然,要变成CUDA代码还需要一些初始化的host代码。
首先要在GPU上分配内存,然后Memcpy过去
然后初始化块的数量和块的大小,就可以启动核函数了
然后算完之后再Memcpy回CPU
最后别忘了free掉GPU上用的内存
void CUDAMultMatrixSimple(int N, float *dmatA, float *dmatB, float *dmatC)
{dim3 threadsPerBlock(LBLK, LBLK);dim3 blocks(updiv(N, LBLK), updiv(N, LBLK));CUDASimpleKernel<<<blocks, threadsPerBlock>>>(N, dmatA, dmatB, dmatC);
}void CUDAMultiply(int N, float *aData, float *bData, float *cData)
{float *aDevData, *bDevData, *cDevData;CUDAMalloc((void **)&aDevData, N * N * sizeof(float));CUDAMalloc((void **)&bDevData, N * N * sizeof(float));CUDAMalloc((void **)&cDevData, N * N * sizeof(float));CUDAMemcpy(aDevData, aData, N * N * sizeof(float), CUDAMemcpyHostToDevice);CUDAMemcpy(bDevData, bData, N * N * sizeof(float), CUDAMemcpyHostToDevice);CUDAMultMatrixSimple(N, aDevData, bDevData, cDevData);CUDAMemcpy(cData, cDevData, N * N * sizeof(float), CUDAMemcpyDeviceToHost);CUDAFree(aDevData);CUDAFree(bDevData);CUDAFree(cDevData);
}好的,这有一个巨额的提升。
4. 考虑一个情况
刚才的i和j计算的代码变成这样,效果会变差十多倍。为什么呢
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y
想想内存访问模式的变化。刚才的代码,一个block里的一个warp是横着连续的,

横着连续说明他们的i一样,j连续,这说明,在对A矩阵的访问上,一直用的都是同一行,是内存中同一个连续的位置,可以进行块读。对B矩阵的访问上,是一列一列访问的,但是整个warp所需要访问的内存是连续的,所以也可以进行块读。
然后,对于写,是写C的连续的位置,因为是横着的,所以可以进行块写。
而新的代码
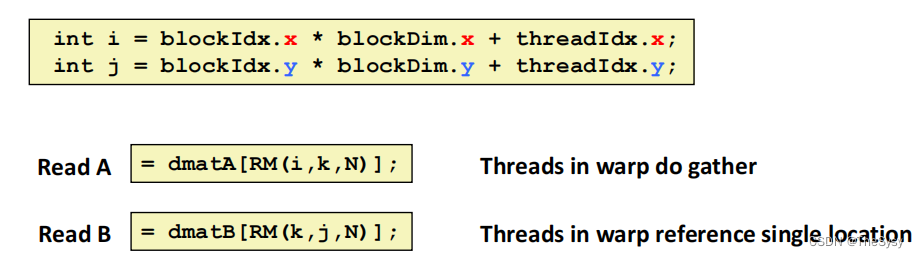
i是列号乘块的纵长,再加上块里的线程纵位置,也就是i和j对比刚才互换了,这样会导致什么,同一个warp里计算的是C矩阵纵向的元素。C矩阵纵向的元素,对于A,是不同的行,这样warp内整体也是连续的,可以进行块读,对于B,是同一列,这里读是不能块读的,因为内存是不连续的。
再看写,是竖着写的,所以写的也是C的不连续的位置,这样写也不能进行块写。
综上,这两个就差在一个块写和块读上了。
相关文章:
【并行计算】GPU,CUDA
一、CUDA层次结构 1.kernel核函数 一个CUDA程序是一个kernel核函数被GPU的多个计算单元并行执行的过程,CUDA给了如下抽象 dim3 threadsPerBlock(4, 3, 1); dim3 numBlocks(3, 2, 1); matrixAdd<<<numBlocks, threadsPerBlock>>>(A, B, C); 2.G…...

计算机网络教案——计算机网络设备章节
第五章 计算机网络设备 一、教学目标: 1. 了解计算机网络的主要设备 2. 了解计算机网络设备的主要原理 3. 掌握计算机网络设备的基本用途 4. 掌握计算机网络设备的使用常识 二、教学重点、难点 计算机网络设备的主要原理 三、技能培训重点、难点 计算机网络设备的使用…...

什么是SLAM中的回环检测,如果没有回环检测会怎样
目录 什么是回环检测 如果没有回环检测 SLAM(Simultaneous Localization and Mapping,即同时定位与地图构建)是一种使机器人或自动驾驶汽车能够在未知环境中建立地图的同时定位自身位置的技术。回环检测(Loop Closure Detectio…...

ubuntu 通过文件设置静态IP、DNS、网关
1. 确定网络接口名称 首先,使用 ip a 命令确定您要配置的网络接口名称。 2. 编辑 Netplan 配置文件 使用文本编辑器(如 nano)打开或创建 Netplan 配置文件: sudo nano /etc/netplan/01-netcfg.yaml3. 输入 Netplan 配置 在编…...
mapboxgl 中热力图的实现以及给热力图点增加鼠标移上 popup 效果
文章目录 概要效果预览技术思路技术细节小结 概要 本篇文章还是关于最近做到的 mapboxgl 地图展开的。 借鉴官方示例:https://iclient.supermap.io/examples/mapboxgl/editor.html#heatMapLayer 效果预览 技术思路 将接口数据渲染到地图中形成热力图。还需要将热…...
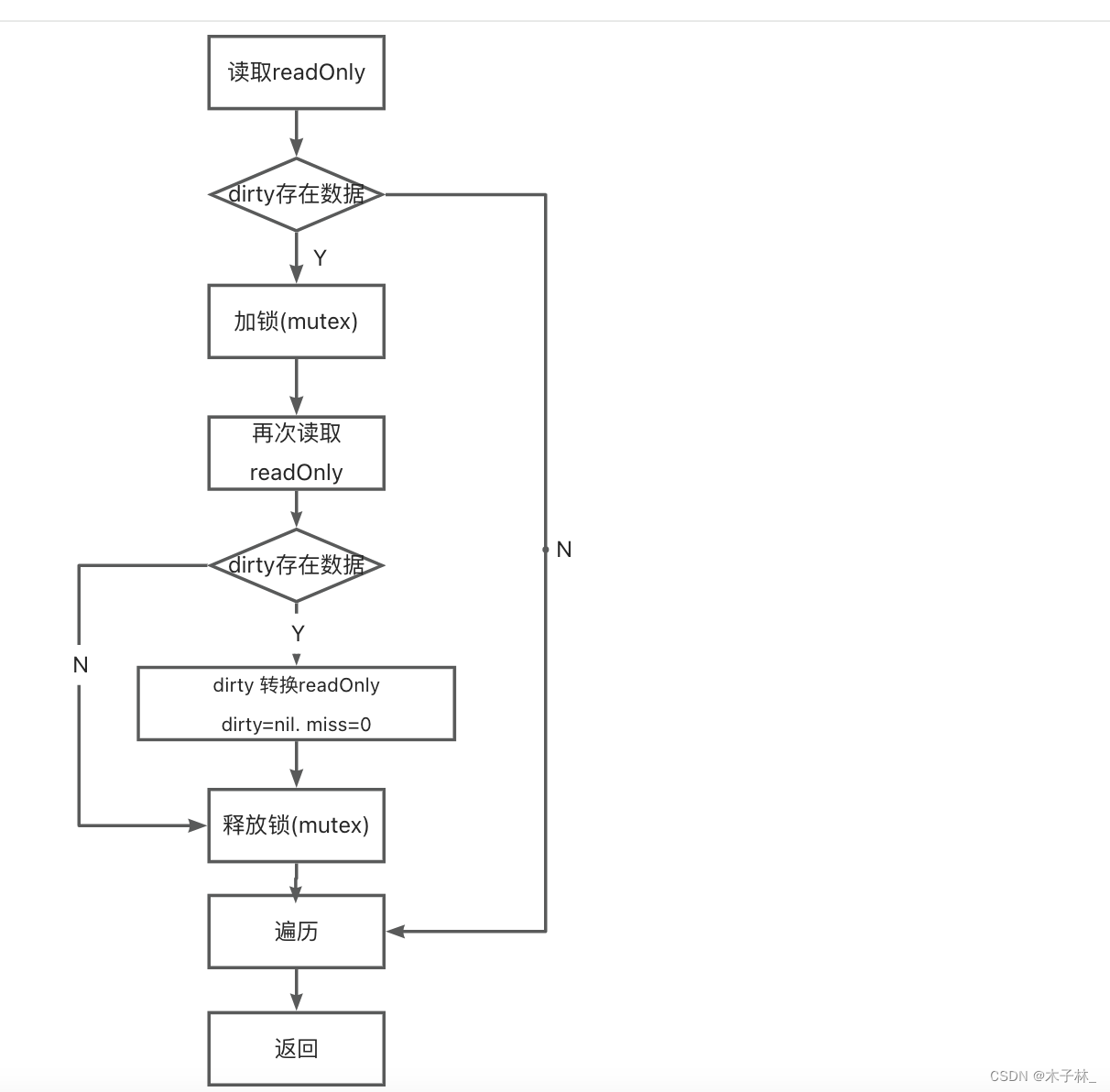
golang并发安全-sync.map
sync.map解决的问题 golang 原生map是存在并发读写的问题,在并发读写时候会抛出异常 func main() {mT : make(map[int]int)g1 : []int{1, 2, 3, 4, 5, 6}g2 : []int{4, 5, 6, 7, 8, 9}go func() {for i : range g1 {mT[i] i}}()go func() {for i : range g2 {mT[…...

开发第一个SpringBoot程序
使用命令创建Maven工程 mvn archetype:generate -DgroupIdorg.sang -DartifactIdchapter01 -DarchetypeArtifactIdmaven-archetype-quickstart -DinteractiveModefalse 参数说明: -DgroupId 组织Id(项目包名) -DartifactId 项目名称或模块…...

2023年度总结—你是你的年度MVP吗?
这段年度总结其实我之前就想写了,大概就是市赛比完之后18号的样子把,但是因为太懒了就一直拖到了现在哈哈,我思来想去,翻来覆去,彻夜难眠,想了想,还是决定把它写了吧!毕竟࿰…...

Linux基础知识学习3
vim编辑器 其分为四种模式 1.普通(命令)模式 2.编辑模式 3.底栏模式 4.可视化模式 vim编辑器被称为编辑器之神,而Emacs更是神之编辑器 普通模式: 1.光标移动 ^ 移动到行首 w 跳到下一个单词的开头…...
)
Leetcode5-在长度2N的数组中找出重复N次的元素(961)
1、题目 给你一个整数数组 nums ,该数组具有以下属性: nums.length 2 * n. nums 包含 n 1 个 不同的 元素 nums 中恰有一个元素重复 n 次 找出并返回重复了 n 次的那个元素。 示例 1: 输入:nums [1,2,3,3] 输出:…...

openssl的 openssl.cnf配置文件详解
背景:在上一篇文中,提到要写一篇openssl 配置文件详解的,这就来了~~~ find / -name openssl.cnf /etc/pki/tls/openssl.cnf /etc/pki/tls/openssl.cnf,该文件主要设置了证书请求、签名、crl相关的配置。主要相关的伪命令为ca和req…...
SpringBoot集成支付宝,看这一篇就够了。
前 言 在开始集成支付宝支付之前,我们需要准备一个支付宝商家账户,如果是个人开发者,可以通过注册公司或者让有公司资质的单位进行授权,后续在集成相关API的时候需要提供这些信息。 下面我以电脑网页端在线支付为例,介…...
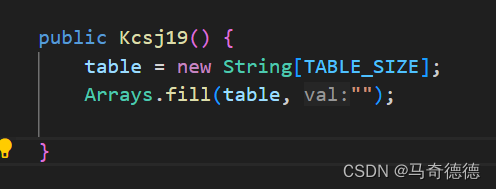
数据结构程序设计——哈希表的应用(2)->哈希表解决冲突的方法
目录 实验须知 代码实现 实验报告 一:问题分析 二、数据结构 1.逻辑结构 2.物理结构 三、算法 (一)主要算法描述 1.用除留余数法构造哈希函数 2.线性探测再散列法 (一)主要算法实现代码 四、上机调试 实…...
微信小程序开发系列-07组件
微信小程序开发系列目录 《微信小程序开发系列-01创建一个最小的小程序项目》《微信小程序开发系列-02注册小程序》《微信小程序开发系列-03全局配置中的“window”和“tabBar”》《微信小程序开发系列-04获取用户图像和昵称》《微信小程序开发系列-05登录小程序》《微信小程序…...

JavaScript 中 Set 和 Map 的区别
JavaScript 中的 Set 和 Map 都是用来存储数据的数据结构,它们之间的区别如下: Set 是一组唯一值的集合,而 Map 是一组键值对的集合。Set 中的值是唯一的,不允许重复;Map 中的键是唯一的,值可以重复。Set …...

web前端之JavaScript
MENU JavaScript之设计模式、单例、代理、装饰者、中介者、观察者、发布订阅、策略JavaScript之数组静态方法的实现、reduce、forEach、map、push、every JavaScript之设计模式、单例、代理、装饰者、中介者、观察者、发布订阅、策略 单例模式 概念 保证一个类仅有一个实例&am…...
C# 图标标注小工具-查看重复文件
目录 效果 项目 代码 下载 效果 项目 代码 using System; using System.Collections.Generic; using System.Data; using System.IO; using System.Linq; using System.Security.Cryptography; using System.Windows.Forms;namespace ImageDuplicate {public partial clas…...

浅谈冯诺依曼体系和操作系统
🌎冯诺依曼体系结构 文章目录 冯诺依曼体系结构 认识冯诺依曼体系结构 硬件分类 各个硬件的简单认识 输入输出设备 中央处理器 存储器 关于内存 对冯诺依曼体系的理解 操作系统 操作系统…...

Good Bye 2023
Good Bye 2023 Good Bye 2023 A. 2023 题意:序列a中所有数的乘积应为2023,现在给出序列中的n个数,找到剩下的k个数并输出,报告不可能。 思路:把所有已知的数字乘起来,判断是否整除2023,不够…...

多开工具对手机应用响应速度的优化与改进
多开工具对手机应用响应速度的优化与改进 摘要: 如今,手机应用的多样化和个性化需求不断增长,用户对应用的响应速度要求也越来越高。为了满足用户的需求,开发者们使用了多种技术手段进行应用的优化和改进。其中,多开工…...

FPG财盛国际:投资者教育生态的全面布局
FPG财盛国际:投资者教育生态的全面布局金融服务行业的复杂性决定了平台需要在多个维度上同时具备较高的水准。FPG财盛国际经过多年的发展,已经在合规、技术、服务、教育等方面形成了一套相互支撑的体系。本文从评测视角出发,对其综合实力进行…...

ikhono开源框架:AI应用开发的统一抽象与实战指南
1. 项目概述与核心价值最近在AI应用开发圈子里,一个名为ikhono-ai/ikhono的开源项目引起了我的注意。乍一看这个标题,你可能会有点懵,这名字不像我们常见的那些“XX-GPT”、“XX-Agent”那么直白。但恰恰是这种独特的命名,让我产生…...

告别英文恐惧症!PowerToys-CN让Windows效率工具真正为你所用
告别英文恐惧症!PowerToys-CN让Windows效率工具真正为你所用 【免费下载链接】PowerToys-CN PowerToys Simplified Chinese Translation 微软增强工具箱 自制汉化 项目地址: https://gitcode.com/gh_mirrors/po/PowerToys-CN 你是否曾经面对微软官方的PowerT…...

3分钟掌握PC端聊天软件防撤回:RevokeMsgPatcher实战指南
3分钟掌握PC端聊天软件防撤回:RevokeMsgPatcher实战指南 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitcode.…...

基于Lepton AI构建对话式搜索引擎:RAG技术实践指南
1. 项目概述:用Lepton AI构建你的对话式搜索引擎 如果你对AI应用开发感兴趣,尤其是想快速搭建一个能理解自然语言、并能联网搜索的智能助手,那么“Search with Lepton”这个项目绝对值得你花时间研究。它本质上是一个开源的对话式搜索引擎框…...

PC显示器HDR选购指南:DisplayHDR标准详解与实战应用
1. 从混乱到清晰:PC显示器HDR标准的演进与现状如果你最近在挑选一台新的PC显示器,尤其是为了游戏、影音剪辑或者专业设计,那么“HDR”这个标签你一定绕不开。它被印在包装盒上,出现在电商页面的标题里,是销售员口中的“…...

终极OFD转PDF指南:3分钟掌握免费开源转换工具Ofd2Pdf的完整教程
终极OFD转PDF指南:3分钟掌握免费开源转换工具Ofd2Pdf的完整教程 【免费下载链接】Ofd2Pdf Convert OFD files to PDF files. 项目地址: https://gitcode.com/gh_mirrors/ofd/Ofd2Pdf 你是否经常遇到OFD格式文件无法打开的困扰?无论是电子发票、政…...

STM32 PID温度控制系统:实现±0.5°C高精度控制的完整指南
STM32 PID温度控制系统:实现0.5C高精度控制的完整指南 【免费下载链接】STM32 项目地址: https://gitcode.com/gh_mirrors/stm322/STM32 你是否曾面临温度控制系统的精度不足、响应迟缓或稳定性差的困扰?在工业自动化、实验室研究和智能家居领域…...

从Nautilus案看专利权利要求撰写:如何避免模糊性陷阱
1. 专利权利要求“模糊性”的边界:从Nautilus案看撰写核心 在科技行业,尤其是半导体、硬件和软件开发领域,专利是保护创新、构筑商业壁垒的生命线。但你是否想过,你或你的公司赖以生存的那份专利文件,其核心——权利要…...

AI HYCAN 007 空气悬架智能功率 MOSFET 完整选型方案
2026年随着 AI 技术在车身控制系统中的深度渗透,HYCAN 007 空气悬架对功率 MOSFET 提出更高要求:高频化、低损耗、高可靠性、小封装。微碧半导体(VBsemi)基于先进 Trench 工艺,为您提供覆盖压缩机驱动、电磁阀控制、电…...