ElasticSearch 文档操作

创建文档
指定id
// 无则插入,有则覆盖(覆盖的逻辑是先删除,再插入)
PUT /<target>/_doc/<_id>
// 无则插入,有则覆盖
POST /<target>/_doc/<_id>
// 无则插入,有则报错
PUT /<target>/_create/<_id>
// 无则插入,有则报错
POST /<target>/_create/<_id>
不指定id
// 正常插入
POST /<target>/_doc
// 报错
POST /<target>/_create
// 报错
PUT /<target>/_create
// 报错
PUT /<target>/_doc
PUT user/_doc/5
{"name": "张三(5)","age": 10,"email": "1.qq.com","address": "北京朝阳"
}
删除文档
// 根据 id 删除
DELETE /<index>/_doc/<_id>
// 根据查询删除
POST /<target>/_delete_by_query
删除 id 为1的数据
DELETE user/_doc/1
删除全部数据
POST user/_delete_by_query
{"query": {"match_all": {}}
}
更新文档
// 根据 id 更新
POST /<index>/_update/<_id>
// 根据查询更新
POST /<target>/_update_by_query
将 id 为1的数据的 name 修改为张三(修改后)
POST user/_update/1
{"doc": {"name": "张三(修改后)"}
}
将 id 为1,2的数据 age 修改为70
POST user/_update_by_query
{"query": {"ids": {"values": [1, 2]}},"script": {"source": "ctx._source.age = 70"}
}
索引重建(reindex)
索引在使用一段时间后,如果想修改索引的静态设置,比如主分片的数目,分词器等(这些设置无法直接修改),此时就可以使用索引重建
POST _reindex
{"source": {"index": "my-index-000001"},"dest": {"index": "my-new-index-000001"}
}
并发控制
当进行并发控制时通常有乐观锁和悲观锁两种方式:
乐观锁:适用于读多写少的情况,冲突比较少,可以提高系统的吞吐量
悲观锁:适用于读少写多的情况,经常会产生冲突,如果使用乐观锁,应用会不断的重试,会降低性能
ElasticSearch 使用乐观锁的形式来进行并发控制,即 if_primary_term 参数和 if_seq_no 参数
| 参数 | 作用 |
|---|---|
| if_primary_term | 数据在哪个分片 |
| if_seq_no | 版本号,每次修改都会增加 |
POST user/_doc/5
{"name": "张三(5)","age": 10,"email": "1.qq.com","address": "北京朝阳"
}
{"_index" : "user","_id" : "5","_version" : 12,"result" : "updated","_shards" : {"total" : 2,"successful" : 2,"failed" : 0},"_seq_no" : 38,"_primary_term" : 2
}
GET user/_doc/5
{"_index" : "user","_id" : "5","_version" : 12,"_seq_no" : 38,"_primary_term" : 2,"found" : true,"_source" : {"name" : "张三(5)","age" : 10,"email" : "1.qq.com","address" : "北京朝阳"}
}
当 _seq_no=38 时,执行如下请求报错,加if_seq_no改为38时正常执行
POST user/_doc/5?if_primary_term=2&if_seq_no=30
{"name": "张三(5)","age": 10,"email": "1.qq.com","address": "北京朝阳"
}
创建,更新,删除文档等操作的 api 都可以使用这2个参数
批量操作
批量操作对json有严格的要求,每个json串不能换行,只能放在同一行,相邻的json串之间必须要有换行。每个操作必须是一对json串(delete语法除外)
{ action: { metadata }}
{ request body }
{ action: { metadata }}
{ request body }
| 操作类型 | 介绍 |
|---|---|
| create | 文档id不存在则创建,不存在则报错 |
| index | 文档id不存在则创建,存在则更新文档 |
| update | 根据文档id更新文档,不存在则返回错误 |
| delete | 根据文档id删除文档,不存在则返回错误 |
批量新增
{"index": {"_id": 1}}
{"name": "张三", "age": 10, "email": "1.qq.com", "address": "北京朝阳"}
{"index": {"_id": 2}}
{"name": "李四", "age": 20, "email": "2.qq.com", "address": "北京西城"}
{"index": {"_id": 3}}
{"name": "王五", "age": 30, "email": "3.qq.com", "address": "北京东城"}
{"index": {"_id": 4}}
{"name": "赵六", "age": 40, "email": "4.qq.com", "address": "北京海淀"}
文档写入
单个文档
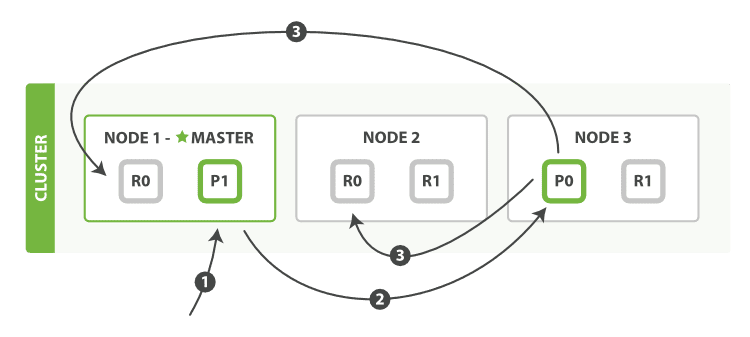
多个文档
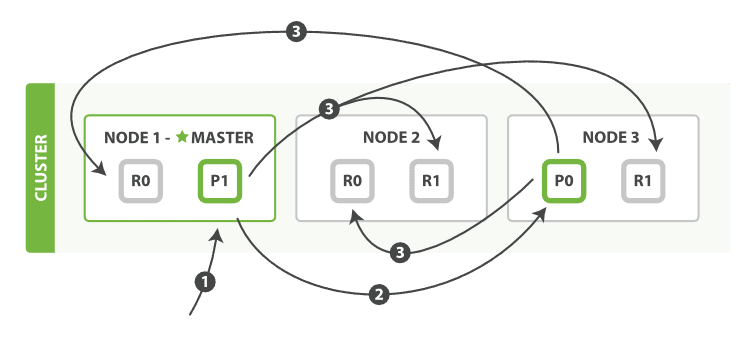
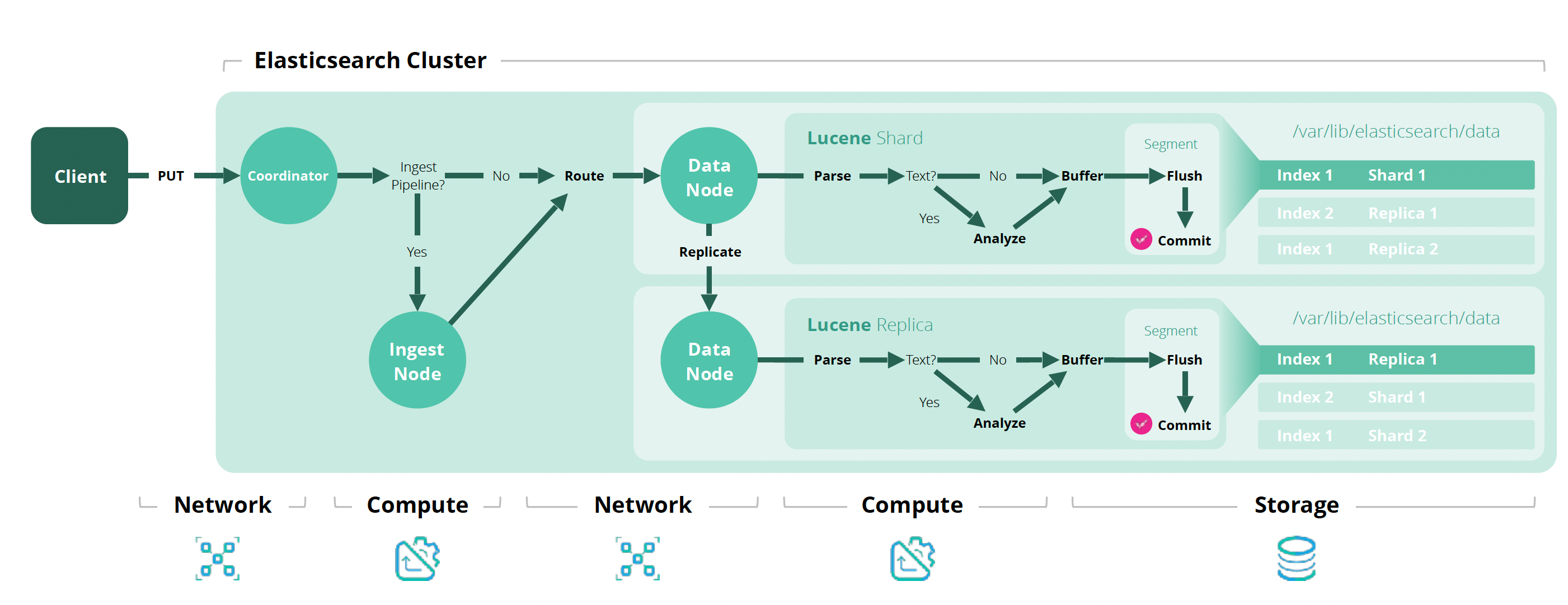
文档查询
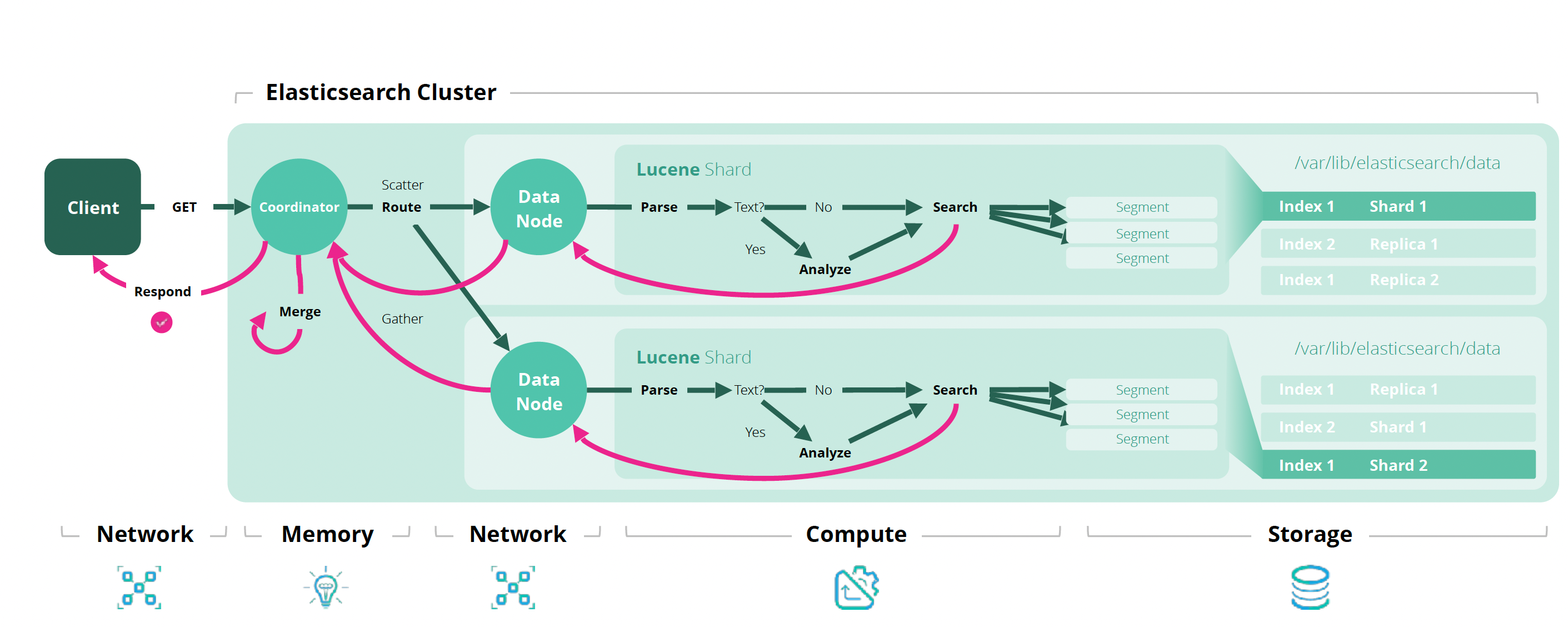
参考博客
官方文档
[0]https://www.elastic.co/guide/en/elasticsearch/reference/8.11/docs.html
[1]https://blog.csdn.net/weixin_39723544/article/details/109237175
[2]https://cloud.tencent.com/developer/article/2133017
大佬博客
[3]https://elasticstack.blog.csdn.net/article/details/128835177
插入方式的区别
[4]https://www.modb.pro/db/1717735427791724544
相关文章:
ElasticSearch 文档操作
创建文档 指定id // 无则插入,有则覆盖(覆盖的逻辑是先删除,再插入) PUT /<target>/_doc/<_id> // 无则插入,有则覆盖 POST /<target>/_doc/<_id> // 无则插入,有则报错 PUT /&l…...
NXOpenC++布尔求和命令
一、概述 在进行批量布尔求和时,采用NXOpenC的方式要比UFun的方式美观的多,个人认为,ufun中UF_MODL_unite_bodies函数采用的是两两进行合并,显示多个步骤,而NXOpenC采用的是一个工具体和多个目标体进行合并,…...
ubuntu python播放MP3,wav音频和录音
目录 一.利用pygame(略显麻烦,有时候播放不太正常)1.安装依赖库2.代码 二.利用mpg123(简洁方便,但仅争对mp3)1.安装依赖库2.代码 三.利用sox(简单方便,支持的文件格式多)…...

Rust学习笔记000 安装
安装命令 curl --proto https --tlsv1.2 -sSf https://sh.rustup.rs | sh $ curl --proto https --tlsv1.2 -sSf https://sh.rustup.rs | sh info: downloading installerWelcome to Rust!This will download and install the official compiler for the Rust programming la…...

python AI五子棋对战
我写过一篇c++五子棋 c++五子棋代码-CSDN博客 现在又写了python import copy import time from enum import IntEnum import pygame from pygame.locals import *time = time.strftime("%Y-%m-%d %H:%M:%S") version = str(time)# 基础参数设置 square_size = 40 …...

图文证明 费马,罗尔,拉格朗日,柯西
图文证明 罗尔,拉格朗日,柯西 费马引理和罗尔都比较好证,不过多阐述,看图即可: 费马引理: 罗尔定理: 重点来证明拉格朗日和柯西 拉格朗日: 我认为不需要去看l(x)的那一行更好推: 详细的推理过程: 构造 h ( x ) f ( x ) − l ( x ) , 因为 a , b 两点为交点 , f ( a ) l ( …...
CEC2017(Python):粒子群优化算法PSO求解CEC2017(提供Python代码)
一、CEC2017简介 参考文献: [1]Awad, N. H., Ali, M. Z., Liang, J. J., Qu, B. Y., & Suganthan, P. N. (2016). “Problem definitions and evaluation criteria for the CEC2017 special session and competition on single objective real-parameter numer…...
(一))
AUTOSAR从入门到精通- 虚拟功能总线(RTE)(一)
目录 前言 几个高频面试题目 RTE S/R接口implicit与Explicit的实现与区别 接口的代码 implicit...

B/S架构云端SaaS服务的医院云HIS系统源码,自主研发,支持电子病历4级
医院云HIS系统源码,自主研发,自主版权,电子病历病历4级 系统概述: 一款满足基层医院各类业务需要的云HIS系统。该系统能帮助基层医院完成日常各类业务,提供病患挂号支持、病患问诊、电子病历、开药发药、会员管理、统…...
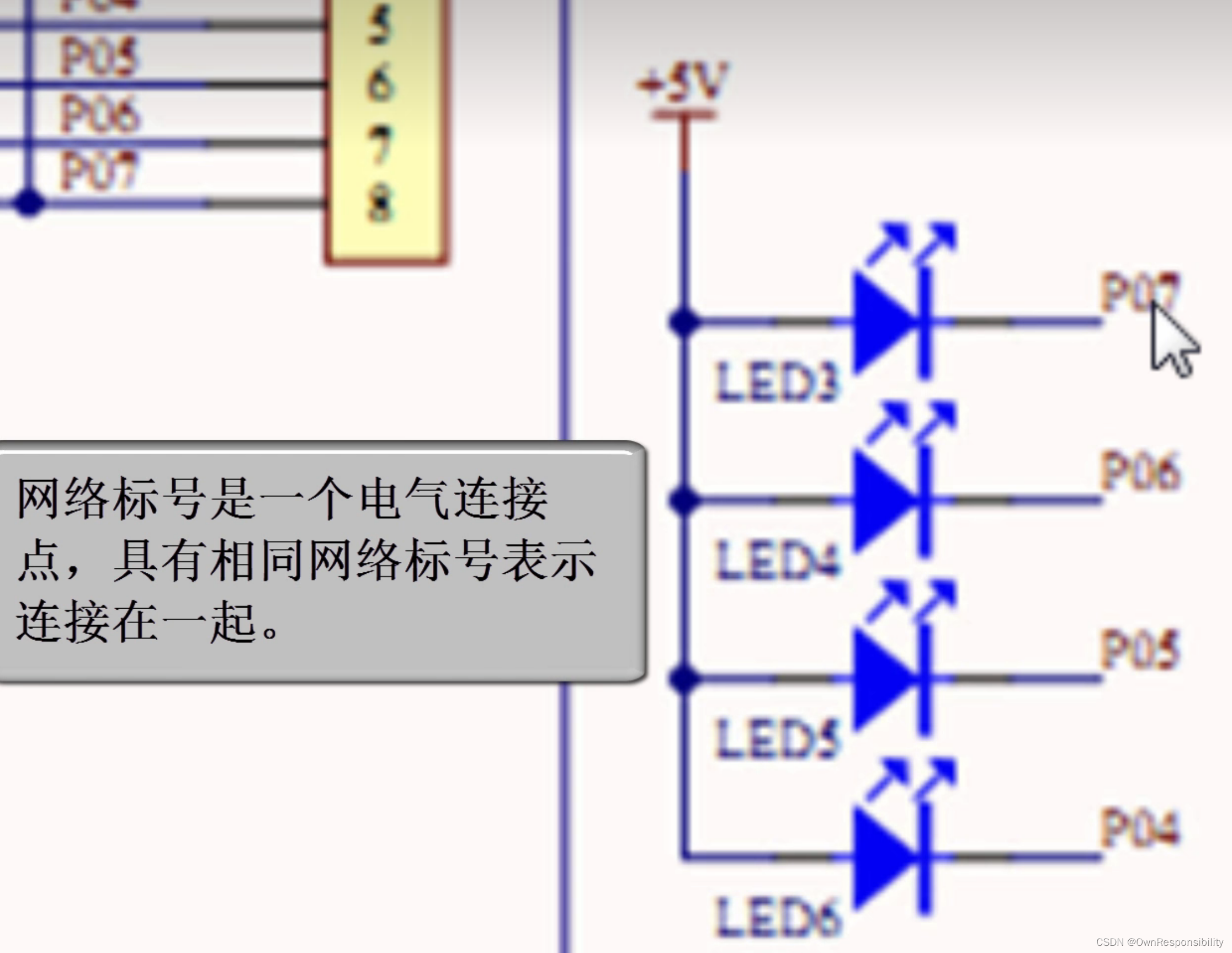
看懂基本的电路原理图(入门)
文章目录 前言一、二极管二、电容三、接地一般符号四、晶体振荡器五、各种符号的含义六、查看原理图的顺序总结 前言 电子入门,怎么看原理图,各个图标都代表什么含义,今天好好来汇总一下。 就比如这个电路原理图来说,各个符号都…...

赫夫曼树基本数据结构
自编头文件: #ifndef HUFFMAN_H_INCLUDED #define HUFFMAN_H_INCLUDED#include<limits.h> #include<string.h> typedef struct {unsigned int weight;unsigned int parent,lchild,rchild; }HTNode,*HuffmanTree; typedef char** HuffmanCode;void Sele…...
10TB海量JSON数据从OSS迁移至MaxCompute
前提条件 开通MaxCompute。 在DataWorks上完成创建业务流程,本例使用DataWorks简单模式。详情请参见创建业务流程。 将JSON文件重命名为后缀为.txt的文件,并上传至OSS。本文中OSS Bucket地域为华东2(上海)。示例文件如下。 {&qu…...
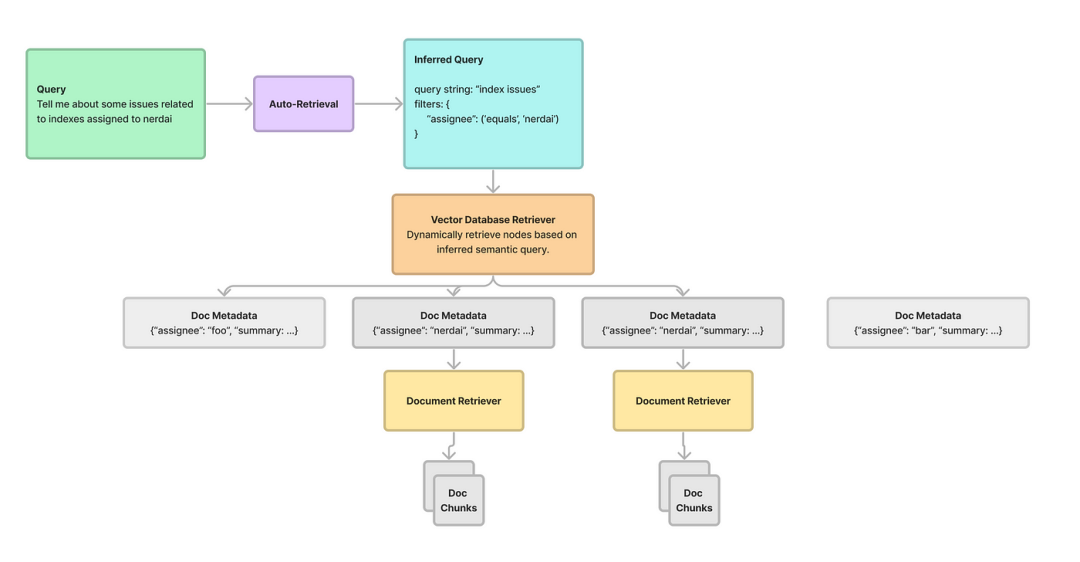
LLM之RAG实战(九)| 高级RAG 03:多文档RAG体系结构
在RAG(检索和生成)这样的框架内管理和处理多个文档有很大的挑战。关键不仅在于提取相关内容,还在于选择包含用户查询所寻求的信息的适当文档。基于用户查询对齐的多粒度特性,需要动态选择文档,本文将介绍结构化层次检索…...

Windows电脑引导损坏?按照这个教程能修复
前言 Windows系统的引导一般情况下是不会坏的,小伙伴们可以不用担心。发布这个帖子是因为要给接下来的文章做点铺垫。 关注小白很久的小伙伴应该都知道,小白的文章都讲得比较细。而且文章与文章之间的关联度其实还是蛮高的。在文章中,你会遇…...

记Android字符串资源支持的参数类型
参数以%开头,后拼接对应的参数类型名称,如下所示: <string name"tips">Hello, %s! You have some new messages.</string> 类型名称如下所示: s字符串格式用于插入字符串值。例如,"Hel…...
Java实现树结构(为前端实现级联菜单或者是下拉菜单接口)
Java实现树结构(为前端实现级联菜单或者是下拉菜单接口) 我们常常会遇到这样一个问题,就是前端要实现的样式是一个级联菜单或者是下拉树,如图 这样的数据接口是怎么实现的呢,是什么样子的呢? 我们可以看看 …...

MySQL中常用的数据类型
整型 int 有符号范围: -2147483648 ~ 2147483647 int unsigned 无符号范围: 0 ~ 4294967295 int(5) zerofill 仅用于显示,当不满足5位时,按照左边补0,例如: 00002满足时,正常显示 tinyint[(m)] [unsigned] [zerofill] 有符号&a…...

HTML+CSS+JS制作三款雪花酷炫特效
🎀效果展示 🎀代码展示 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html...
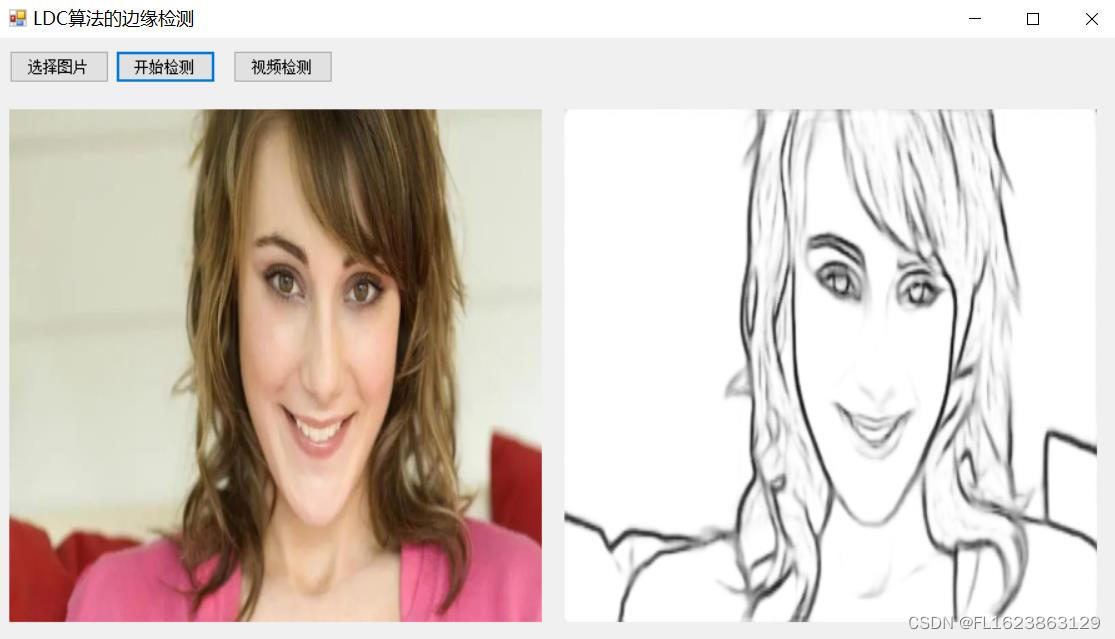
[C#]使用ONNXRuntime部署一种用于边缘检测的轻量级密集卷积神经网络LDC
源码地址: github.com/xavysp/LDC LDC: Lightweight Dense CNN for Edge Detection算法介绍: 由于深度学习方法的快速发展,近年来,用于执行图像边缘检测的卷积神经网络(CNN)模型爆炸性地传播。但边缘检测…...

ZigBee案例笔记 - 无线点灯
文章目录 无线点灯实验概述工程关键字工程文件夹介绍Basic RF软件设计框图简单说明工程操作Basic RF启动流程Basic RF发送流程Basic RF接收流程 无线点灯案例无线点灯现象 无线点灯实验概述 ZigBee无线点灯实验(即Basic RF工程),由TI公司提供…...

避开这5个坑,你的癫痫脑电AI模型准确率能翻倍:从数据标注到特征工程实战
避开这5个坑,你的癫痫脑电AI模型准确率能翻倍:从数据标注到特征工程实战 在医疗AI领域,癫痫脑电信号分析一直是个充满挑战的课题。许多开发者满怀信心地构建模型,却在验证阶段遭遇性能瓶颈——准确率停滞不前,误报率居…...

网盘下载新革命:九大平台一键直链,告别客户端束缚
网盘下载新革命:九大平台一键直链,告别客户端束缚 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

LearningX:构建结构化开发者知识体系,从基础到架构的实践指南
1. 项目概述:一个面向开发者的系统性学习仓库最近在GitHub上看到一个挺有意思的项目,叫“LearningX”。光看名字,你可能会觉得这又是一个普通的“Awesome-XXX”列表,或者是一堆学习资料的简单堆砌。但当我点进去,花了一…...

从日志到环境变量:根治 Android Studio AVD 启动报错“The emulator process has terminated”
1. 从错误弹窗到日志分析:定位问题的第一步 当你兴冲冲地打开Android Studio准备启动AVD(Android Virtual Device)时,突然弹出一个冰冷的提示框:"The emulator process has terminated",这感觉就…...
Translumo:5分钟掌握Windows实时屏幕翻译终极指南
Translumo:5分钟掌握Windows实时屏幕翻译终极指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否在玩外…...

YimMenu:GTA V终极游戏增强工具完整实战手册
YimMenu:GTA V终极游戏增强工具完整实战手册 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMenu …...

DLSS Swapper终极指南:免费开源的游戏DLSS智能管理工具
DLSS Swapper终极指南:免费开源的游戏DLSS智能管理工具 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款革命性的免费开源工具,专为PC游戏玩家设计,能够智能管理、…...

Obsidian智能模板终极指南:3步打造高效笔记自动化系统
Obsidian智能模板终极指南:3步打造高效笔记自动化系统 【免费下载链接】Templater A template plugin for obsidian 项目地址: https://gitcode.com/gh_mirrors/te/Templater Templater插件是Obsidian生态系统中功能最强大的智能模板解决方案,它能…...

深入解析go-containerregistry:无守护进程的容器镜像操作利器
1. 项目概述:容器镜像的“瑞士军刀”如果你在容器化这条路上已经走了一段时间,那么对“镜像”这个概念一定不会陌生。无论是 Docker Hub 上的nginx:latest,还是你公司私有仓库里的myapp:v1.2.3,这些镜像都是容器世界的基石。但你是…...

Bun用Rust重写核心代码,百万行新增代码直接把GitHub干爆了!
Bun 项目刚刚完成了一次惊人的技术跨越。5月14日,Bun 正式宣布其核心运行时已从 Zig 重写为 Rust——这个版本包含 6755 个 commit,二进制文件体积缩小 3-8 MB,性能测试在各个平台上均达到或超越原有水平。Jarred Sumner(Bun 的创…...