ES应用_ES实战
依靠知识库使用es总结一些使用技巧。
1 快速入门
ES是将查询语句写成类似json的形式,通过关键字进行查询和调用。
1.1 创建
下面创建了一个主分片为5,副本分片为1的ES结构。ES本身是一种noschema的结构,但是可以通过指定mapping编程schema的结构(具体mapping的一些用法会在后文提及)。
# 建设向量索引
PUT test
{"settings": {"number_of_shards": 5,"number_of_replicas": 1,"index.codec": "proxima","index.vector.algorithm": "hnsw"},"mappings": {"properties": {"id": {"type": "text"},"gmt_create": {"type": "text"},"gmt_modified": {"type": "text"},"title": {"type": "text"},"question_id": {"type": "text"},"category_id": {"type": "text"},"bu_id": {"type": "text"},"bu_platform": {"type": "text"},"product": {"type": "text"},"platform": {"type": "text"},"status": {"type": "text"},"creator": {"type": "text"},"modifier": {"type": "text"},"knowledge_id": {"type": "text"},"space_id": {"type": "text"},"ext_info": {"type": "text"},"lan": {"type": "text"},"default_lan": {"type": "text"},"content_type": {"type": "text"},"content": {"type": "text"},"section_type": {"type": "text"},"terminal_type": {"type": "text"},"simQuestions": {"type": "text"},"recommand": {"type": "text"},"qq_vects": {"type": "proxima_vector","dim": 128,"vector_type": "float","distance_method": "SquaredEuclidean"}}}
}1.2 删除
delete test1.3 查询
GET test/_search
{"query": {"match": {"product":"ding"}}
}2 mapping使用
2.1 text类型
由于es是基于搜索引擎建立的。因此会对文本类型字段需要分词并建立倒排索引。使用该类型的优点是能够加快查询速度(50毫秒内),缺点是不支持排序(因为进行了分词倒排索引,无法实现排序)。
2.2 keyword
该字段不会进行分词,但仍然会建立索引。严格匹配的场景或者需要排序,聚合等。
例如,上述建立的表中需要指定gmt_create和gmt_modified进行排序,应当建立如下mapping
PUT test
{"settings": {"number_of_shards": 5,"number_of_replicas": 1,"index.codec": "proxima","index.vector.algorithm": "hnsw"},"mappings": {"properties": {"id": {"type": "text"},"gmt_create": {"type":"text","fields":{"row":{"type":"keyword"}},"fielddata":true},"gmt_modified": {"type":"text","fields":{"row":{"type":"keyword"}},"fielddata":true},"title": {"type": "text"},"question_id": {"type": "text"},"category_id": {"type": "text"},"bu_id": {"type": "text"},"bu_platform": {"type": "text"},"product": {"type": "text"},"platform": {"type": "text"},"status": {"type": "text"},"creator": {"type": "text"},"modifier": {"type": "text"},"knowledge_id": {"type": "text"},"space_id": {"type": "text"},"ext_info": {"type": "text"},"lan": {"type": "text"},"default_lan": {"type": "text"},"content_type": {"type": "text"},"content": {"type": "text"},"section_type": {"type": "text"},"terminal_type": {"type": "text"},"simQuestions": {"type": "text"},"recommand": {"type": "text"},"qq_vects": {"type": "proxima_vector","dim": 128,"vector_type": "float","distance_method": "SquaredEuclidean"}}}
}其他类型不做过多介绍,参见官方文档
3 Tips
3.1 数据同步
可以使用datax构建实时/离线数据同步到es,前提是es的mapping结构能够和数据源映射
如果需要进行数据加工,使用:数据源 -> datahub -> flink -> es的链路
3.2 修改mapping
es本身是一种非schema结构,一旦index的mapping在建好之后是不可以更改字段类型的。所以直接将mapping从long改为string(text)、或者增加keyword排序是不行的。
因此修改mapping的方式有两种:
正规军方案:新增字段
在mapping中新增加一个字段,废弃原油字段。但是字段不支持rename,因此会花费很多时间和前后端沟通。
野战军方案:利用别名
别名可以理解成增加一个逻辑层。例如,index A(es物理表)对应别名cco_dw。此时可以新建一个index B(es物理表),构建正确的mapping后将index A中的数据同步进来,然后将别名cco_dw下挂表换为index B。即从index A -> cco_dw变为index B -> cco_dw。对于后端来说使用的是cco_dw。
{"actions" : [{ "remove" : { "index" : "A", "alias" : "cco_dw" } },{ "add" : { "index" : "B", "alias" : "cco_dw" } }]
}
实现数据同步的方法:reindex
POST _reindex
{"max_docs": 10000,"source": {"index": "test_order"},"dest": {"index": "test"}
}
PS:如果实时数据写入,切换过程中可能丢失部分数据流。因此:
- 在低流量时进行变更
- 变更过程实时任务回追点位,避免数据丢失
3.3 条件删除
POST test/_delete_by_query
{"query":{"match":{"product":"ding"}}
}4 简单查询
4.1 查询所有(match_all)
match_all关键字: 返回索引中的全部文档
GET /ems/_search
{"query": { "match_all": {} }
}4.2 查询结果中返回指定条数(size)
size 关键字: 指定查询结果中返回指定条数。
GET /ems/_search
{"query": { "match_all": {} },"size": 1
}4.3 分页查询(from)
from 关键字: 用来指定起始返回位置
size关键字连用可实现分页效果,size表示从起始位置开始的文档数量;类似于mysql中的select * from tablename limit 1, 2;ES默认的分页深度是10000,也就是from+size超过了10000就会报错,ES内部是通过index.max_result_window这个参数控制分页深度的,可进行修改。分页越深,ES的处理开销越大,占用内存越大。
解决上面深度分页问题可使用scroll 或 search after,具体参考, 缺点是不能跳页(如从1页直接到第5页),只能一页一页翻。
GET /ems/_search
{"query": {"match_all": {}},"sort": [{"age": {"order": "desc"}}],"size": 2, "from": 1
}4.4 查询结果中返回指定字段(_source)
GET /ems/_search
{"query": { "match_all": {} },"_source": ["name", "age"]
}4.5 关键词查询(term)
term 关键字: 用来使用关键词查询
- 通过使用term查询得知ES中默认使用分词器为标准分词器(StandardAnalyzer),标准分词器对于英文单词分词,对于中文单字分词。
- 通过使用term查询得知,在ES的Mapping Type 中 keyword , date ,integer, long , double , boolean or ip 这些类型不分词,只有text类型分词。
GET /ems/_search
{"query": {"term": {"address": {"value": "北京"}}}
}4.6 范围查询(range)
range 关键字: 用来指定查询指定范围内的文档
GET /ems/_search
{"query": {"range": {"age": {"gte": 8,"lte": 30}}}
}4.7 前缀查询(prefix)
prefix 关键字: 用来检索含有指定前缀的关键词的相关文档
GET /ems/_search
{"query": {"prefix": {"content": {"value": "redis"}}}
}4.8 通配符查询(wildcard)
wildcard 关键字: 通配符查询,? 用来匹配一个任意字符 ,* 用来匹配多个任意字符,注意全模糊wildcard会有性能问题,具体参考。
wildcard query应杜绝使用通配符打头,实在不得已要这么做,就一定需要限制用户输入的字符串长度。 最好换一种实现方式,通过在index time做文章,选用合适的分词器,比如nGram tokenizer预处理数据,然后使用更廉价的term query来实现同等的模糊搜索功能。 对于部分输入即提示的应用场景,可以考虑优先使用completion suggester, phrase/term suggeter一类性能更好,模糊程度略差的方式查询,待suggester没有匹配结果的时候,再fall back到更模糊但性能较差的wildcard, regex, fuzzy一类的查询。
GET /ems/_search
{"query": {"wildcard": {"content": {"value": "re*"}}}
}4.9 多id查询(ids)
ids 关键字 : 值为数组类型,用来根据一组id获取多个对应的文档
GET /ems/_search
{"query": {"ids": {"values": ["lOiUsHUBe6kjTlxcqX3c","lQ5HwWkBxH7z6xax7W3_"]}}
}4.10 模糊查询(fuzzy)
fuzzy 关键字: 用来模糊查询含有指定关键字的文档 注意:允许出现的错误必须在0-2之间
GET /ems/_search
{"query": {"fuzzy": {"content":"spoong"}}
}
# 注意: 最大编辑距离为 0 1 2
如果关键词为2个长度 0..2 must match exactly 必须完全匹配
如果关键词长度3..5之间 one edit allowed 允许一个失败
如果关键词长度>5 two edits allowed 最多允许两个错误4.11 布尔查询(bool)
bool 关键字: 用来组合多个条件实现复杂查询 boolb表达式查询
must: 相当于&& 同时成立
should: 相当于|| 成立一个就行
must_not: 相当于! 不能满足任何一个
GET /ems/_search
{"query": {"bool": {"must": [{"range": {"age": {"gte": 0,"lte": 30}}}],"must_not": [{"wildcard": {"content": {"value": "redi?"}}}]}},"sort": [{"age": {"order": "desc"}}]
}4.12 高亮查询(highlight)
highlight 关键字: 可以让符合条件的文档中的关键词高亮
GET /ems/_search
{"query": {"term": {"content": {"value": "redis"}}},"highlight": {"fields": {"*": {}}}
}自定义高亮html标签: 设置高亮html标签,默认是> _标签,可以在highlight中使用pre_tags和post_tags属性自定义高亮显示的html标签,去替代默认的em标签。
GET /ems/_search
{"query":{"term":{"content":"spring"}},"highlight": {"pre_tags": ["<span style='color:red'>"],"post_tags": ["</span>"],"fields": {"*":{}}}
}_多字段高亮 使用require_field_match设置为false,开启多个字段高亮,默认为true。
GET /ems/_search
{"query":{"term":{"content":"spring"}},"highlight": {"pre_tags": ["<span style='color:red'>"],"post_tags": ["</span>"],"require_field_match":false,"fields": {"*":{}}}
}4.13 多字段查询(multi_match)
注意:使用这种方式进行查询时,为了更好获取搜索结果,在查询过程中先将查询条件根据当前的分词器分词之后进行查询
GET /ems/_search
{"query": {"multi_match": {"query": "中国","fields": ["name","content"] #这里写要检索的指定字段}}
}4.14 多字段分词查询(query_String)
注意:使用这种方式进行查询时,为了更好获取搜索结果,在查询过程中先将查询条件根据当前的分词器分词之后进行查询
GET /dangdang/book/_search
{"query": {"query_string": {"query": "中国声音","analyzer": "ik_max_word", "fields": ["name","content"]}}
}4.15 精准查询(match_phrase)
精准查询确切的phase,在对查询字段定义了分词器的情况下,会使用分词器对输入进行分词,然后返回满足下述两个条件的document:
match_phase中的所有term都出现在待查询字段之中
待查询字段之中的所有term都必须和match_phase具有相同的顺序
GET /ems/_search
{"query": {"match_phrase": {"name": "Hello World"}}
}5 过滤查询
其实准确来说,ES中的查询操作分为2种: 查询(query)和过滤(filter)。查询即是之前提到的query查询,它 (查询)默认会计算每个返回文档的得分,然后根据得分排序。而过滤(filter)只会筛选出符合的文档,并不计算得分,且它可以缓存文档 。所以,单从性能考虑,过滤比查询更快。换句话说,过滤适合在大范围筛选数据,而查询则适合精确匹配数据。一般应用时, 应先使用过滤操作过滤数据, 然后使用查询匹配数据。
5.1 过滤语法
GET /ems/_search
{"query": {"bool": {"must": [{"match_all": {}}],"filter": {"range": {"age": {"gte": 10}}}}}
}NOTE: 在执行filter和query时,先执行filter在执行query{}
NOTE: Elasticsearch会自动缓存经常使用的过滤器,以加快性能。
5.1 term、terms
含义与查询时一致,term用于精确匹配,terms用于多词条匹配,过滤上使用没有很大区别
GET /ems/_search # 使用term过滤
{"query": {"bool": {"must": [{"term": {"name": {"value": "小黑"}}}],"filter": {"term": {"content":"spring"}}}}
}
GET /ems/_search #使用terms过滤
{"query": {"bool": {"must": [{"term": {"name": {"value": "梅超风"}}}],"filter": {"terms": {"content":["redis","开源"]}}}}
}5.2 ranage filter
GET /ems/_search
{"query": {"bool": {"must": [{"term": {"name": {"value": "中国"}}}],"filter": {"range": {"age": {"gte": 7,"lte": 20}}}}}
}5.3 exists filter
过滤存在指定字段,获取字段不为空的索引记录使用
GET /ems/_search
{"query": {"bool": {"must": [{"term": {"name": {"value": "中国"}}}],"filter": {"exists": {"field":"aaa"}}}}
}5.4 ids filter
过滤含有指定字段的索引记录
GET /ems/_search
{"query": {"bool": {"must": [{"term": {"name": {"value": "中国"}}}],"filter": {"ids": {"values": ["1","2","3"]}}}}
}6 排序
6.1 基础字段排序
详细参考
#索引结构
PUT /my-index-000001
{"mappings": {"properties": {"post_date": { "type": "date" },"user": {"type": "keyword"},"name": {"type": "keyword"},"age": { "type": "integer" }}}
}#基础字段按post_date升序,name降序,age降序查询。
GET /my-index-000001/_search
{"sort" : [{ "post_date" : {"order" : "asc"}},"user",{ "name" : "desc" },{ "age" : "desc" },"_score"],"query" : {"term" : { "user" : "kimchy" }}
}6.2 嵌套字段排序
详细参考
#按嵌套字段中price升序排序。
POST /_search
{"query" : {"term" : { "product" : "chocolate" }},"sort" : [{"offer.price" : {"mode" : "avg","order" : "asc","nested": {"path": "offer","filter": {"term" : { "offer.color" : "blue" }}}}}]
}7 聚合查询
7.1 Bucket Aggregations
Bucket可以理解为一个桶,它会遍历文档中的内容,凡是符合某一要求的就放在一个桶中,分桶相当于sql中的group by, 关键字有Terms Aggregation,Filter Aggregation,Histogram Aggregation, Date Aggregation
#创建索引类型
PUT /cars
{"mappings": { "properties": {"price": {"type": "long"},"color": {"type": "keyword"},"brand": {"type": "keyword"},"sellTime": {"type": "date"}} }
}
#添加数据
POST /cars/_bulk
{ "index": {}}
{ "price" : 80000, "color" : "red", "brand" : "BMW", "sellTime" : "2014-01-28" }
{ "index": {}}
{ "price" : 85000, "color" : "green", "brand" : "BMW", "sellTime" : "2014-02-05" }
{ "index": {}}
{ "price" : 120000, "color" : "green", "brand" : "Mercedes", "sellTime" : "2014-03-18" }
{ "index": {}}
{ "price" : 105000, "color" : "blue", "brand" : "Mercedes", "sellTime" : "2014-04-02" }
{ "index": {}}
{ "price" : 72000, "color" : "green", "brand" : "Audi", "sellTime" : "2014-05-19" }
{ "index": {}}
{ "price" : 60000, "color" : "red", "brand" : "Audi", "sellTime" : "2014-06-05" }
{ "index": {}}
{ "price" : 40000, "color" : "red", "brand" : "Audi", "sellTime" : "2014-07-01" }
{ "index": {}}
{ "price" : 35000, "color" : "blue", "brand" : "Honda", "sellTime" : "2014-08-12" }7.2 Terms Aggregation
Terms Aggregation关键字:** 根据某一项的每个唯一的值来聚合
GET /cars/_search
{"aggs": {"car_brand": {"terms": {"field": "brand"}}}
}
#分桶后只显示文档数量的前3的桶
GET /cars/_search
{"aggs": {"car_brand": {"terms": {"field": "brand","size": 3}}}
}
#分桶后排序
GET /cars/_search
{"aggs": {"car_brand": {"terms": {"field": "brand","order": {"_count": "asc"}}}}
}
#显示文档数量大于3的桶
GET /cars/_search
{"aggs": {"brands_max_num": {"terms": {"field": "brand","min_doc_count": 3}}}
}
#使用精确指定的词条进行分桶
GET /cars/_search
{"aggs": {"brand_cars": {"terms": {"field": "brand","include": ["BMW", "Audi"]}}}
}7.3 Filter Aggregation
Filter Aggregation关键字: 指具体的域和具体的值,可以在Terms Aggregation 的基础上进行了过滤,只对特定的值进行了聚合
#过滤获取品牌为BMW的桶,并求该桶平均值
GET /cars/_search
{"aggs": {"car_brands": {"filter": {"term": {"brand": "BMW"}},"aggs": {"avg_price": {"avg": {"field": "price"}}}}}
}Filters Aggregation关键字: Filter Aggregation 只能指定一个过滤条件,响应也只是单个桶。如果要对特定多个值进行聚合,使用Filters Aggragation
#过滤获取品牌为BMW的或color为绿色的桶
GET /cars/_search
{"aggs": {"cars": {"filters": {"filters": {"colorBucket":{"match":{"color":"red"}},"brandBucket":{"match":{"brand":"Audi"}}}}}}
}7.4 Histogram Aggregation
Histogram Aggregation关键字: Histogram与Terms聚合类似,都是数据分组,区别是Terms是按照Field的值分组,而Histogram可以按照指定的间隔对Field进行分组
#根据价格区间为10000分桶
GET /cars/_search
{"aggs": {"prices": {"histogram": {"field": "price","interval": 10000}}}
}
#根据价格区间为10000分桶,同时如果桶中没有文档就不显示桶
GET /cars/_search
{"aggs": {"prices": {"histogram": {"field": "price","interval": 10000,"min_doc_count": 1}}}
}7.5 Range Aggregation
Range Aggregation关键字: 根据用户传递的范围参数作为桶,进行相应的聚合。在同一请求中,请求传递多组范围,每组范围作为一个桶
#根据价格区间分桶
GET /cars/_search
{"aggs": {"prices_range": {"range": {"field": "price","ranges": [{"to":50000},{"from": 50000,"to": 80000},{"from": 80000}]}}}
}
#也可以指定key的名称
GET /cars/_search
{"aggs": {"prices_range": {"range": {"field": "price","ranges": [{"key": "<50000", "to":50000},{"key": "50000~80000", "from": 50000,"to": 80000},{"key": ">80000", "from": 80000}]}}}
}7.6 Date Aggregation
Date Aggregation关键字: 分为Date Histogram Aggregation 和 Date Range Aggregation
1. Date Histogram
Date Histogram关键字: 针对时间格式数据的直方图聚合,基本特性与Histogram Aggregation一致
#按月分桶显示每个月的销量
GET /cars/_search
{"aggs": {"sales_over_time": {"date_histogram": {"field": "sellTime","interval": "month","format": "yyyy-MM-dd"}}}
}2. Date Range
Date Range关键字: 针对时间格式数据的直范围聚合,基本特性与Range Aggregation一致
GET /cars/_search
{"aggs": {"range": {"date_range": {"field": "sellTime","format": "yyyy", "ranges": [{"from": "2014","to": "2019"}]}}}
}8 搜索模板
如果是java用户,用过velocity模板会比较清楚,就是指定模板和对应参数即可生成实际的数据。先来看一个入门的使用方式,inline 和之前的脚本类似,直接写模板。
以下示例会替换field,value为实际值再进行搜索。
GET /blog_website/_search/template
{"inline":{"query": {"match": {"{{field}}": "{{value}}"}}},"params": {"field": "content","value": "博客"}
}8.1 toJson
限制:inline 的内容只能在一行上
GET /blog_website/_search/template
{"inline": "{\"query\": {\"match\": {{#toJson}}matchCondition{{/toJson}}}}","params": {"matchCondition":{"content":"博客"}}
}8.2 join
作用:把一个数组转为具体分隔符的字符串连接起来
如下效果:会吧 titles 数组转成 「博客 网站」,delimiter 规定了连接符是什么
GET /blog_website/blogs/_search/template
{"inline": {"query": {"match": {"title": "{{#join delimiter=' '}}titles{{/join delimiter=' '}}"}}},"params": {"titles": ["博客", "网站"]}
}以上模板渲染后会变成以下语法
GET /blog_website/blogs/_search
{"query": {"match" : {"title" : "博客 网站"}}
}8.3 default value
增加一个 views 字段
POST /blog_website/blogs/1/_update
{"doc": {"views": 5}
}GET /blog_website/blogs/_search/template
{"inline": {"query": {"range": {"views": {"gte": "{{start}}","lte": "{{end}}{{^end}}20{{/end}}"}}}},"params": {"start": 1,"end": 10}
}如上指定了两个参数,并使用
{{^end}}20指定了 end 的默认值为 20, 当 params.end 没有指定的之后,就会使用默认值 20
8.4 conditional
插入一条数据
POST /my_index/my_type/10
{"line":"我的博客","line_no": 5
}查询语法
GET /my_index/_search/template
{"file": "conditional","params": {"text": "博客","line_no": true,"start": 1,"end": 10}
}看到 file 就知道需要事先准备好模板文件了,文件名以后缀 .mustache 结尾
config\scripts\conditonal.mustache
{"query": {"bool": {"must": {"match": {"line": "{{text}}"}},"filter": {{{#line_no}}"range": {"line_no": {{{#start}}"gte": "{{start}}"{{#end}},{{/end}}{{/start}}{{#end}}"lte": "{{end}}"{{/end}}}}{{/line_no}}}}}
}这个意思是要对应 params 里面的参数来看,#line_no 以 「#」开头的为条件判定语法, 只要存在该参数,即打开对应的模板条件
添加文件之后,记得重启 es
适应场景
主要是复用,比如说,一般在大型的团队中,可能不同的人,都会想要执行一些类似的搜索操作, 这个时候,有一些负责底层运维的一些同学,就可以基于搜索模板search template,封装一些模板出来, 放在各个 es 进程的 scripts 目录下,其他的团队,其实就不用各个团队自己反复手写复杂的通用的查询语句了,直接调用某个搜索模板,传入一些参数就好了。
相关文章:
ES应用_ES实战
依靠知识库使用es总结一些使用技巧。 1 快速入门 ES是将查询语句写成类似json的形式,通过关键字进行查询和调用。 1.1 创建 下面创建了一个主分片为5,副本分片为1的ES结构。ES本身是一种noschema的结构,但是可以通过指定mapping编程schema的…...

Ubuntu上如何找到设备,打印串口日志
dmesg 找设备 sudo mincom -s 配置minicom mincom 打印串口日志 PS: Windows上使用MobaXterm / putty / Xshell / SecureCRT等 ubuntu串口的安装和使用(usb转串口)_ubuntu上如何把usb设备映射到tty-CSDN博客...

本地映射测试环境域名,解决登录测试环境后,也可以使用本地域名访问,可以正常跑本地项目
问题:单点登录进入系统不使用token,是将token携带在cookie中,登录成功后每次调用接口,都会在cookie中自动携带,这样导致即使在本地使用proxy代理解决了跨域,但由于本地域名不一致,也无法进行本地…...
VSCode使用Remote SSH远程连接Windows 7
结论 VSCode Server不能启动,无法建立连接。 原因 .vscode-server 目录中的 node.exe 无法运行。 原因是Node.js仅在Windows 8.1、Windows Server 2012 R2或更高版本上受支持。 由于vscode基于node.js v14,不支持Windows 7操作系统。 另ÿ…...

uniapp中uview组件库丰富的Calendar 日历用法
目录 基本使用 #日历模式 #单个日期模式 #多个日期模式 #日期范围模式 #自定义主题颜色 #自定义文案 #日期最大范围 #是否显示农历 #默认日期 基本使用 通过show绑定一个布尔变量用于打开或收起日历弹窗。通过mode参数指定选择日期模式,包含单选/多选/范围…...
云原生Kubernetes:K8S集群实现容器运行时迁移(docker → containerd) 与 版本升级(v1.23.14 → v1.24.1)
目录 一、理论 1.K8S集群升级 2.环境 3.升级策略 4.master1节点迁移容器运行时(docker → containerd) 5.master2节点迁移容器运行时(docker → containerd) 6.node1节点容器运行时迁移(docker → containerd) 7.升级集群计划(v1.23.14 → v1.24.1&#…...

Redis 数据结构和常用命令
* 代表多个,?代表一个 (不用全部敲出来,按住tab可以自动补全) -2是无效,-1是永久有效 ;贴心小提示:内存非常宝贵,对于一些数据,我们应当给他一些过期时间&a…...

Docker 容器命令总汇
目录 1、创建Docker容器(不启动) 2、创建Docker容器(启动) 3、列出正在运行的容器 4、停止和启动容器 5、重启容器 6、进入容器 7、查看容器信息 8、查看容器日志 9、删除容器和镜像 10、重命名容器 11、从旧容器复制数…...
react + redux 之 美团案例
1.案例展示 2.环境搭建 克隆项目到本地(内置了基础静态组件和模版) git clone http://git.itcast.cn/heimaqianduan/redux-meituan.git 安装所有依赖 npm i 启动mock服务(内置了json-server) npm run serve 启动前端服务 npm…...

【形式语言与自动机/编译原理】CFG-->Greibach-->NPDA(2)
本文将详细讲解《形式语言与自动机》(研究生课程)或《编译原理》(本科生课程)中的上下文无关文法(CFG)转换成Greibach范式,再转成下推自动机(NPDA)识别语言是否可以被接受…...
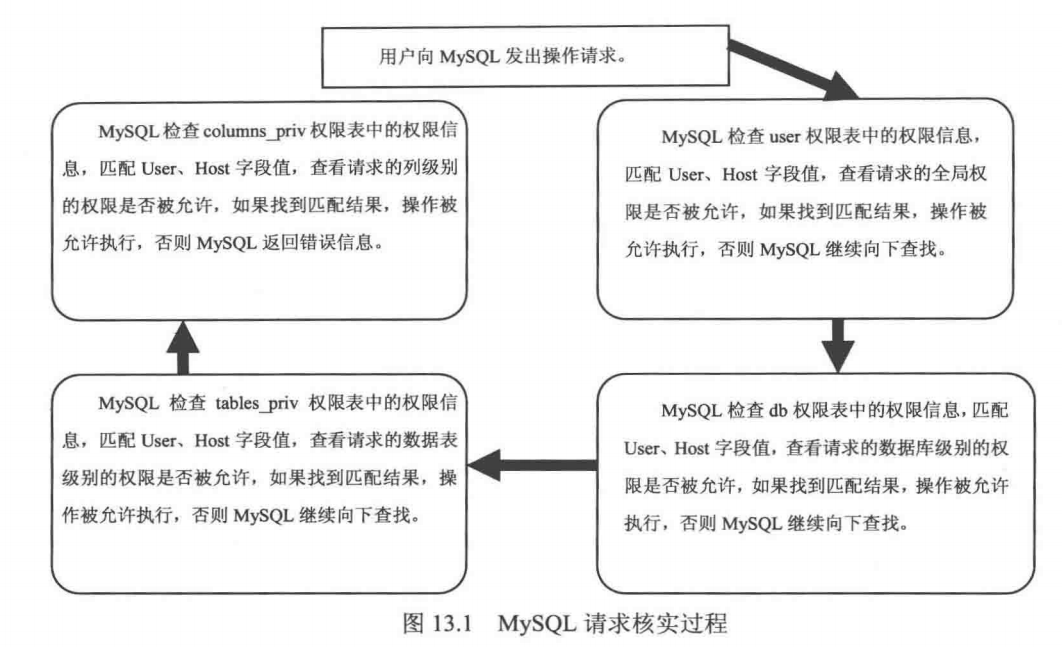
14.用户管理
目录 1、权限表 1、user表 1.用户列 2.权限列 3.安全列 4.资源控制列 2、db表和host 表 1.用户列 2.权限列 3. tables_priv 表和 columns _priv 表 4.procs_priv 表 2、账户管理 1. 登录和退出MySQL服务器 2、创建普通用户: 1.使用CREATE USER语创建…...

【交叉编译环境】安装arm-linux交叉编译环境到虚拟机教程(简洁版本)
就是看到了好些教程有些繁琐,我就写了一个 我这个解压安装的交叉编译环境是Linaro GCC的一个版本,可以用于在x86_64的主机上编译arm-linux-gnueabihf的目标代码 步骤来了 在你的Ubuntu系统中创建一个目录,例如/usr/local/arm,然后…...
感染了后缀为.[sqlback@memeware.net].2700勒索病毒如何应对?数据能够恢复吗?
导言: 近期,[sqlbackmemeware.net].2700 勒索病毒成为网络安全的一大威胁。该勒索病毒采用高度复杂的加密算法,将用户文件加密并勒索赎金。了解该病毒的特征对于有效恢复被加密数据以及预防进一步感染至关重要。如果受感染的数据确实有恢复的…...
[Linux开发工具]——vim使用
Linux编辑器——vim的使用 一、什么是集成开发环境?二、什么是vim?三、vim的概念四、vim的基本操作五、vim命令模式命令集5.1 移动光标5.2 删除文字5.3 复制粘贴5.4 其他操作 六、vim底行模式命令集6.1 首先在命令模式下shift;进入末行模式。…...
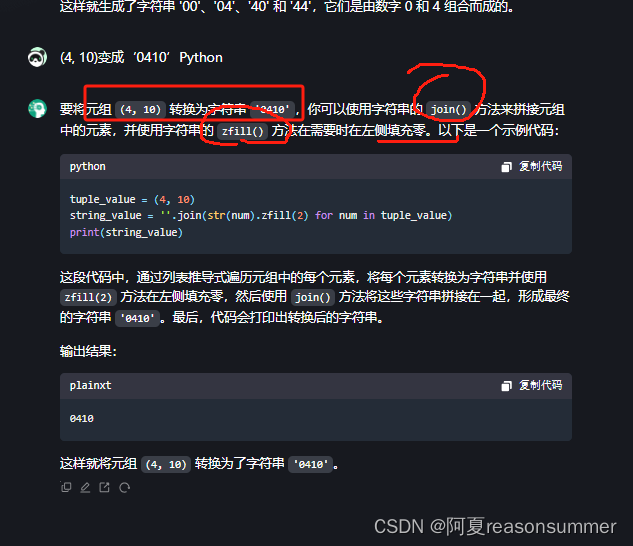
【教学类-43-11】 20231231 3*3宫格数独提取单元格坐标数字的通用模板(做成2*2=4套、3*2=6套)
背景需求: 1、以前做单元格填充,都是制作N个分开的单元格 (表格8) 2、这次做五宫格数独的Word模板,我图方便,就只用了一个大表格,第六行第六列隐藏框线,看上去就是分开的ÿ…...

Spring Boot日志:从Logger到@Slf4j的探秘
写在前面 Hello大家好,今日是2024年的第一天,祝大家元旦快乐🎉 2024第一篇文章从SpringBoot日志开始 文章目录 一、前言二、日志有什么用?三、日志怎么用?四、自定义日志打印💬 常见日志框架说明4.1 在程序…...
如何实现GTM与VADC关联的配置)
英飞凌TC3xx之一起认识GTM系列(六)如何实现GTM与VADC关联的配置
英飞凌TC3xx之一起认识GTM系列(六)如何实现GTM与VADC关联的配置 1 GTM与ADC的接口2 GTM与VADC的连接2.1 VADC 到 GTM 的连接2.1.1 简要介绍2.1.2 应用举例2.2 EVADC到 GTM的连接2.2.1 应用举例3 总结本文介绍实现GTM与VADC的连接性的相关寄存器配置。 1 GTM与ADC的接口 由英…...
(建议收藏))
【基础】【Python网络爬虫】【6.数据持久化】Excel、Json、Csv 数据保存(附大量案例代码)(建议收藏)
Python网络爬虫基础 数据持久化(数据保存)1. Excel创建数据表批量数据写入读取表格数据案例 - 豆瓣保存 Excel案例 - 网易新闻Excel保存 2. Json数据序列化和反序列化中文指定案例 - 豆瓣保存Json案例 - Json保存 3. Csv写入csv列表数据案例 - 豆瓣列表保…...

王道考研计算机网络——应用层
如何为用户提供服务? CS/P2P 提高域名解析的速度:local name server高速缓存:直接地址映射/低级的域名服务器的地址 本机也有告诉缓存:本机开机的时候从本地域名服务器当中下载域名和地址的对应数据库,放到本地的高…...
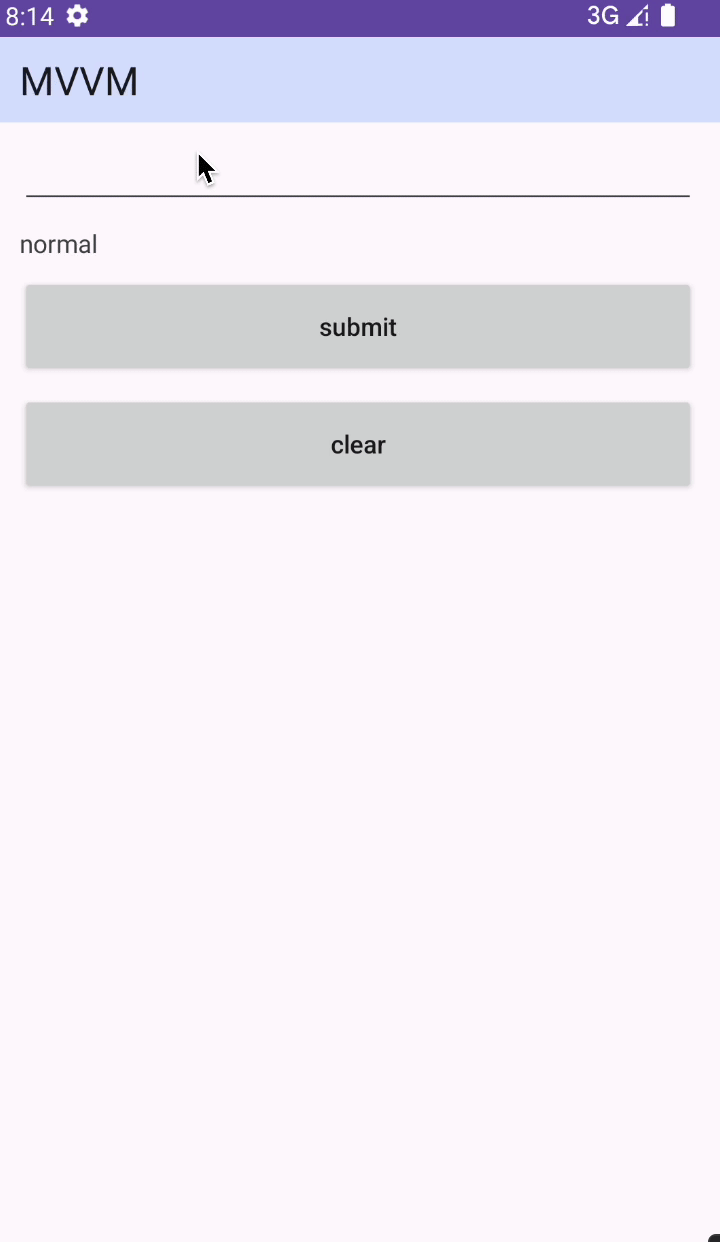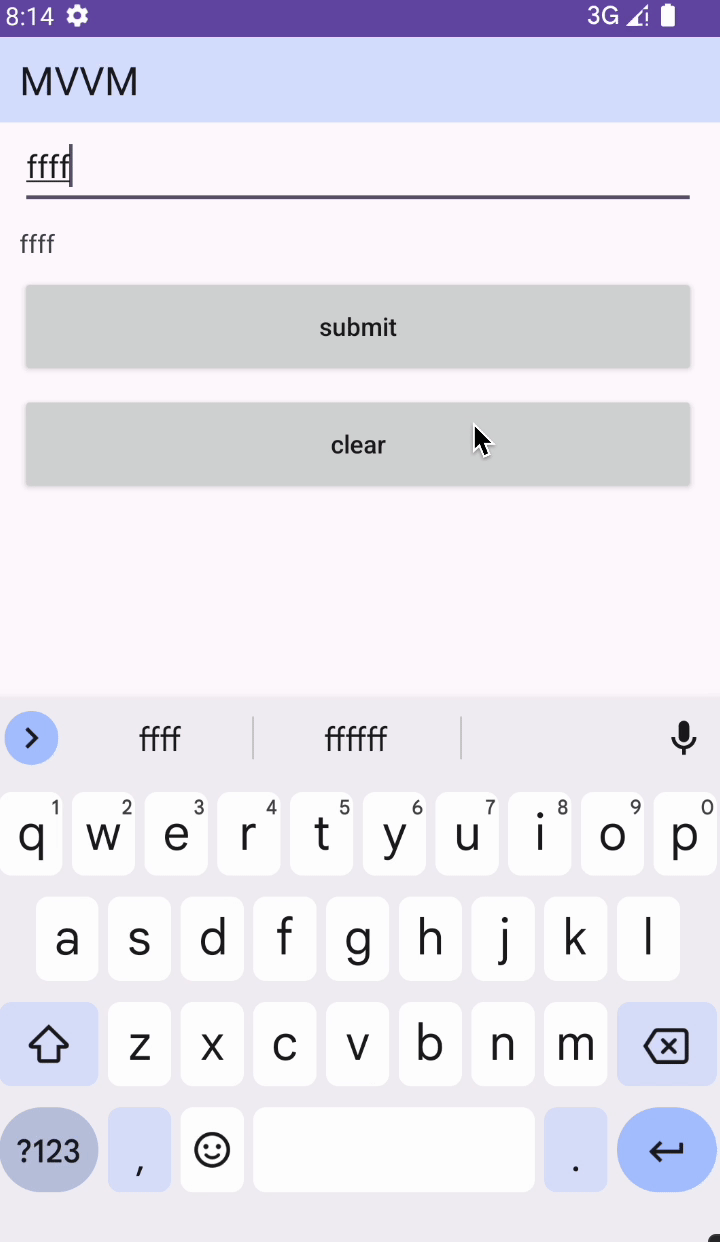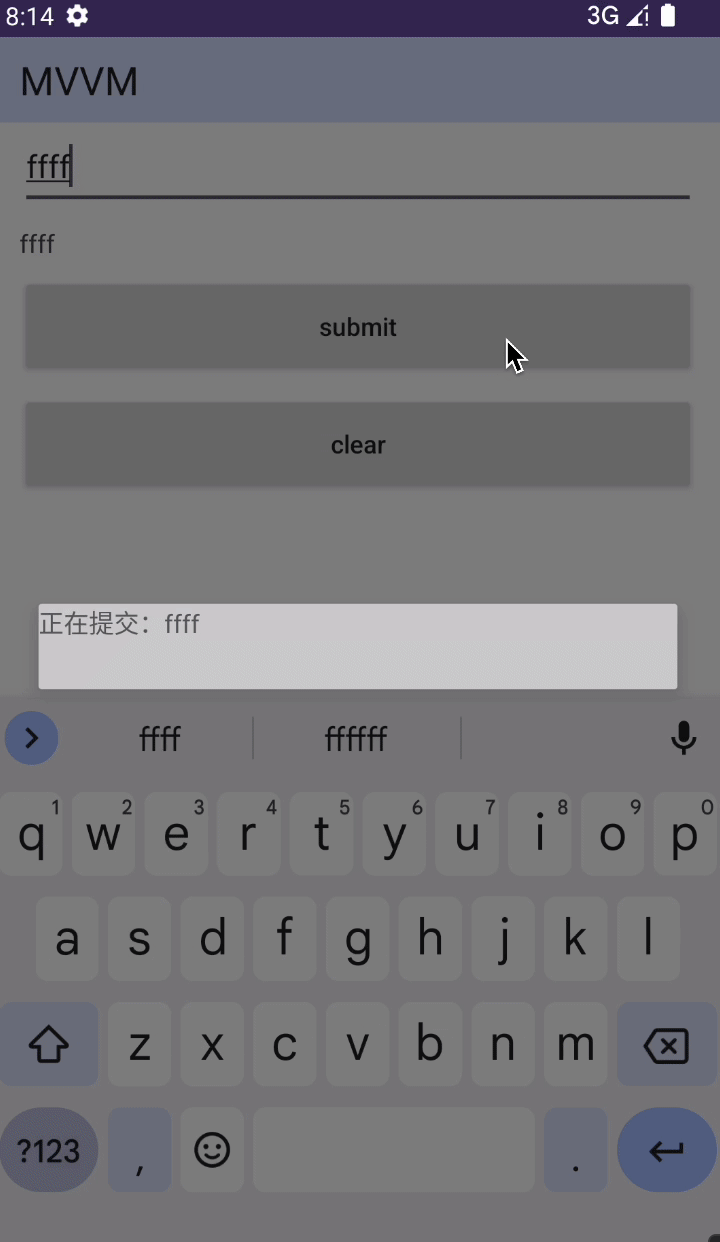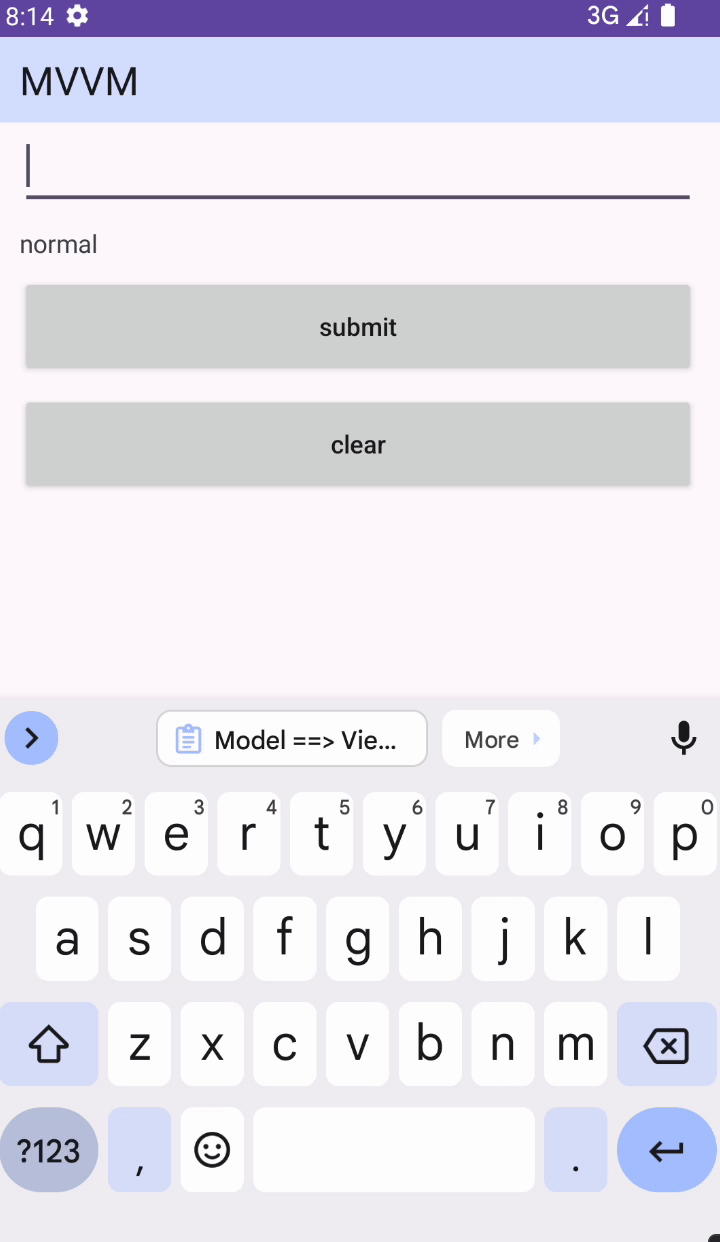
Android MVVM 写法
前言 Model:负责数据逻辑 View:负责视图逻辑 ViewModel:负责业务逻辑 持有关系: 1、ViewModel 持有 View 2、ViewModel 持有 Model 3、Model 持有 ViewModel 辅助工具:DataBinding 执行流程:View &g…...

从零到一:Android Studio集成Uniapp离线SDK打包实战
1. 环境准备:工具选择与版本匹配 第一次接触Uniapp离线打包时,最让我头疼的就是工具版本匹配问题。记得去年接手一个混合开发项目时,因为HBuilderX和SDK版本不兼容,整整浪费了两天时间排查问题。为了避免大家重蹈覆辙,…...

手把手教你用三菱FX3U PLC的RS指令和RS2指令与电脑串口调试助手‘对话’
三菱FX3U PLC串口通信实战:从零搭建RS485数据收发系统 第一次接触工业控制系统的串口通信时,我被那些密密麻麻的接线和晦涩的协议参数弄得晕头转向。直到在自动化生产线上亲眼看到PLC通过两根电线与十几台设备稳定通信,才意识到串口技术的精妙…...

Biomni:生物医学图像分析从入门到精通,AI与传统CV融合实战
1. 项目概述:当AI学会“看”懂生物医学图像如果你在生物医学研究、药物发现或者临床诊断领域工作,大概率会和我一样,对海量的生物医学图像数据感到既兴奋又头疼。兴奋的是,这些图像——无论是显微镜下的细胞切片、组织病理学玻片&…...

终极指南:如何用BabelDOC彻底解决PDF翻译格式错乱问题
终极指南:如何用BabelDOC彻底解决PDF翻译格式错乱问题 【免费下载链接】BabelDOC Yet Another Document Translator 项目地址: https://gitcode.com/GitHub_Trending/ba/BabelDOC 还在为学术论文翻译后排版全乱而烦恼吗?😫 技术文档翻…...

2026生鲜店收银软件特点功能对比
每天傍晚高峰期,生鲜店门口排起的长队总是让店主心头一紧。顾客手里拿着刚挑好的蔬菜水果,眼神里透着急切,而收银台前的店员却还在手忙脚乱地查找商品代码、手动输入重量,甚至因为系统卡顿导致支付失败。这种场景不仅流失了潜在客…...

Linux内存使用分析与泄漏排查
Linux内存使用分析与泄漏排查内存问题往往不像磁盘满那样直观,也不像进程崩溃那样立刻可见。很多服务在内存异常初期仍然可以运行,只是响应逐渐变慢、交换开始活跃、最终被系统回收或触发 OOM。中级 Linux 工程师需要掌握的,不只是看“还剩多…...

AI攻防时间差:当漏洞发现速度碾压修复速度— 聚焦技术核心
AI攻防时间差:当漏洞发现速度碾压修复速度 — 聚焦技术核心 引言:当两个世界碰撞 2026年5月,对于网络安全领域而言,是一个具有分水岭意义的月份。 一边是360人工智能安全研究院在5月12日发布的重磅报告,首次提出**“AI…...

湿版摄影风格失效的5个致命误区,第4个连Midjourney官方文档都未披露——基于217组AB测试的权威归因报告
更多请点击: https://intelliparadigm.com 第一章:湿版摄影风格失效的5个致命误区,第4个连Midjourney官方文档都未披露——基于217组AB测试的权威归因报告 为何“wet plate collodion”提示词突然失灵? 在 Midjourney v6.1 及 N…...

2026 私域救命玩法!90% 的老板赚不到钱,根本不是产品不行
我在杭州做电商、做私域、做投资这么多年,见过各行各业的起起伏伏。这些年接触过的实体老板,没有一百也有八十。手里握着工厂的、拿着自主知识产权的、有正规生产资质的,比比皆是。但 90% 的人都在亏钱。他们天天抱怨流量太贵、同行乱价、客户…...

终极虚拟显示器解决方案:ParsecVDisplay完全指南
终极虚拟显示器解决方案:ParsecVDisplay完全指南 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd ParsecVDisplay是一款基于Parsec虚拟显示驱动(VDD&#x…...