【Python百宝箱】音韵探奇:探索Python中的音频与信号魔法
数字音符:畅游Python音频与信号处理的科技奇境
前言
在数字时代,音频与信号处理不仅仅是专业领域的关键,也成为了科技创新和艺术创作的核心。本文将带领您深入探索Python中多个强大的音频处理库和信号处理工具,从Librosa到TensorFlow Audio,涵盖了各种应用场景和技术深度,助您在声音的奇妙领域中游刃有余。
【Python百宝箱】拨动代码的琴弦:探索Python音频处理库的创造性编码
【Python百宝箱】Python中的音视频处理: 探索多样化的库和工具
【Python百宝箱】声音的数字化探索:Python引领音频奇妙世界
欢迎订阅专栏:Python库百宝箱:解锁编程的神奇世界
文章目录
- 数字音符:畅游Python音频与信号处理的科技奇境
- **前言**
- 1. Librosa
- 1.1 Librosa简介
- 1.2 使用Librosa进行特征提取
- 1.3 时频表示
- 1.4 音频分析与可视化
- 1.5 音频处理中的时间-频率转换
- 1.6 节拍和节奏分析
- 1.7 音频信号的机器学习应用
- 2. PyAudio
- 2.1 基本音频输入/输出
- 2.2 实时音频处理
- 2.3 流式音频应用
- 2.4 与其他库的集成
- 2.5 实时音频效果处理
- 3. Sounddevice
- 3.1 高级音频输入/输出
- 3.2 低延迟音频流
- 3.3 设备配置与控制
- 3.4 实时音频应用
- 3.5 实时音频可视化
- 3.6 实时音频频谱分析
- 3.7 实时音频中的数字信号处理
- 4. Audacity
- 4.1 Audacity概述
- 4.2 音频编辑与操作
- 4.3 多轨编辑
- 4.4 音频效果与插件
- 5. SpeechRecognition
- 5.1 语音转文本
- 5.2 使用不同语音识别引擎
- 5.3 语言支持与配置
- 5.4 将语音识别集成到应用中
- 5.5 实时语音识别
- 5.6 语音合成
- 5.7 自定义语法规则
- 5.8 多语言支持
- 6. Wave
- 6.1 Wave库简介
- 6.2 波形处理与分析
- 6.3 音频文件读写
- 6.4 音频信号生成和合成
- 6.5 音频剪切与拼接
- 6.6 音频采样与重采样
- 7. SciPy
- 7.1 科学计算与信号处理
- 7.2 滤波器设计与应用
- 7.3 快速傅里叶变换(FFT)
- 7.4 频谱分析和频域处理
- 7.5 时频分析与小波变换
- 7.6 滤波器组设计
- **总结**
1. Librosa
1.1 Librosa简介
Librosa是一个用于音频和音乐分析的Python库,提供了丰富的工具和函数,使用户能够轻松地提取音频特征、分析时频内容并进行可视化。该库广泛应用于音乐信息检索、音频信号处理等领域。
1.2 使用Librosa进行特征提取
Librosa支持各种特征提取方法,例如梅尔频谱图、色度图等。以下是一个简单的例子,演示如何使用Librosa提取梅尔频谱图:
import librosa
import librosa.display
import matplotlib.pyplot as plt# 读取音频文件
audio_path = librosa.example('trumpet')
y, sr = librosa.load(audio_path)# 提取梅尔频谱图
mel_spectrogram = librosa.feature.melspectrogram(y=y, sr=sr)# 可视化梅尔频谱图
librosa.display.specshow(librosa.power_to_db(mel_spectrogram, ref=np.max), y_axis='mel', x_axis='time')
plt.colorbar(format='%+2.0f dB')
plt.title('Mel Spectrogram')
plt.show()
1.3 时频表示
Librosa提供了丰富的时频表示方法,如短时傅里叶变换(STFT)等。以下是使用STFT生成时频图的例子:
D = librosa.amplitude_to_db(np.abs(librosa.stft(y)), ref=np.max)librosa.display.specshow(D, sr=sr, x_axis='time', y_axis='log')
plt.colorbar(format='%+2.0f dB')
plt.title('Spectrogram')
plt.show()
1.4 音频分析与可视化
Librosa还支持音频的多方面分析和可视化,例如时序图、频谱图等。以下是一个简单的时序图和频谱图的例子:
# 时序图
plt.figure(figsize=(15, 5))
librosa.display.waveshow(y, sr=sr)
plt.title('Waveform')
plt.show()# 频谱图
chromagram = librosa.feature.chroma_stft(y=y, sr=sr)
librosa.display.specshow(chromagram, x_axis='time', y_axis='chroma')
plt.colorbar()
plt.title('Chromagram')
plt.show()
1.5 音频处理中的时间-频率转换
在音频处理中,时间-频率转换是一个关键的操作,允许我们在不同的表示之间切换。Librosa提供了用于时间-频率转换的多种函数,例如librosa.core.cqt,用于计算恒定Q变换。以下是一个简单的例子:
CQT = librosa.core.cqt(y, sr=sr)# 可视化CQT
librosa.display.specshow(librosa.amplitude_to_db(CQT, ref=np.max), sr=sr, x_axis='time', y_axis='cqt_note')
plt.colorbar(format='%+2.0f dB')
plt.title('Constant-Q Transform (CQT)')
plt.show()
1.6 节拍和节奏分析
Librosa不仅适用于频谱分析,还可以进行节拍和节奏分析。以下是一个演示如何使用librosa.beat模块进行节奏分析的例子:
# 节奏图
tempo, beat_frames = librosa.beat.beat_track(y=y, sr=sr)# 可视化节奏
beat_times = librosa.frames_to_time(beat_frames, sr=sr)
plt.figure(figsize=(15, 4))
librosa.display.waveshow(y, sr=sr, alpha=0.5)
plt.vlines(beat_times, -1, 1, color='r', linestyle='--', alpha=0.8, label='Beats')
plt.legend()
plt.title('Beat Tracking')
plt.show()
1.7 音频信号的机器学习应用
Librosa不仅仅用于音频分析,还可以与机器学习技术结合,进行音频信号分类等任务。以下是一个简单的例子,展示如何使用Librosa和Scikit-learn进行音频信号分类:
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score# 获取音频特征
features = librosa.feature.mfcc(y=y, sr=sr)
labels = np.array(['class_1'] * 50 + ['class_2'] * 50)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(features.T, labels, test_size=0.2, random_state=42)# 随机森林分类器
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train, y_train)# 预测
y_pred = clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')
在接下来的内容中,我们将深入研究Librosa的更多功能,包括音频处理中的特殊技术和实际应用。
2. PyAudio
2.1 基本音频输入/输出
PyAudio是一个用于处理音频输入和输出的Python库,提供了灵活的接口以进行音频流的处理。以下是一个基本的示例,演示如何使用PyAudio录制音频:
import pyaudio
import wave # 配置录音参数
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 44100
CHUNK = 1024
RECORD_SECONDS = 5# 初始化PyAudio
p = pyaudio.PyAudio()# 打开音频流
stream = p.open(format=FORMAT,channels=CHANNELS,rate=RATE,input=True,frames_per_buffer=CHUNK)print("Recording...")# 录制音频并保存到WAV文件
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):data = stream.read(CHUNK)frames.append(data)print("Finished recording.")# 关闭音频流和PyAudio
stream.stop_stream()
stream.close()
p.terminate()# 保存录制的音频到WAV文件
wf = wave.open("recorded_audio.wav", 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
2.2 实时音频处理
PyAudio可以与其他处理库结合,实现实时音频处理。以下是一个简单的实时音频频谱可视化的例子:
import numpy as np
import matplotlib.pyplot as plt# 初始化PyAudio
p = pyaudio.PyAudio()# 打开音频流
stream = p.open(format=FORMAT,channels=CHANNELS,rate=RATE,input=True,frames_per_buffer=CHUNK)# 实时频谱可视化
plt.ion()
fig, ax = plt.subplots()x = np.arange(0, 2 * CHUNK, 2)
line, = ax.plot(x, np.random.rand(CHUNK))ax.set_ylim(0, 255)
ax.set_xlim(0, 2 * CHUNK)while True:data = np.frombuffer(stream.read(CHUNK), dtype=np.int16)line.set_ydata(data)fig.canvas.draw()fig.canvas.flush_events()# 关闭音频流和PyAudio
stream.stop_stream()
stream.close()
p.terminate()
2.3 流式音频应用
PyAudio可以方便地用于流式音频应用,如语音识别、实时音频分析等。以下是一个简单的实时音频识别的例子,结合SpeechRecognition库:
import speech_recognition as sr# 初始化Recognizer
recognizer = sr.Recognizer()# 打开麦克风
with sr.Microphone() as source:print("Say something:")audio = recognizer.listen(source)# 使用Google Web Speech API进行语音识别
try:print("Google Web Speech API thinks you said: " + recognizer.recognize_google(audio))
except sr.UnknownValueError:print("Google Web Speech API could not understand audio")
except sr.RequestError as e:print("Could not request results from Google Web Speech API; {0}".format(e))
2.4 与其他库的集成
PyAudio可以与其他处理库集成,例如NumPy、SciPy等,以实现更复杂的音频处理任务。以下是一个简单的实时音频频谱分析的例子,结合SciPy库:
from scipy.fft import fft
import numpy as np# 初始化PyAudio
p = pyaudio.PyAudio()# 打开音频流
stream = p.open(format=FORMAT,channels=CHANNELS,rate=RATE,input=True,frames_per_buffer=CHUNK)# 实时频谱分析
plt.ion()
fig, ax = plt.subplots()x = np.arange(0, RATE, RATE // CHUNK)
line, = ax.plot(x, np.random.rand(CHUNK))ax.set_ylim(0, 5000)
ax.set_xlim(0, RATE)while True:data = np.frombuffer(stream.read(CHUNK), dtype=np.int16)yf = fft(data)line.set_ydata(np.abs(yf[:CHUNK]) * 2 / (256 * CHUNK))fig.canvas.draw()fig.canvas.flush_events()# 关闭音频流和PyAudio
stream.stop_stream()
stream.close()
p.terminate()
2.5 实时音频效果处理
除了频谱可视化,PyAudio还可以用于实时音频效果处理。以下是一个简单的例子,演示如何将音频数据乘以2,实现音频放大的效果:
# 初始化PyAudio
p = pyaudio.PyAudio()# 打开音频流
stream = p.open(format=FORMAT,channels=CHANNELS, rate=RATE,input=True,output=True,frames_per_buffer=CHUNK)print("Applying real-time audio effect: Amplification")while True:data = np.frombuffer(stream.read(CHUNK), dtype=np.int16)# 音频效果处理:乘以2amplified_data = data * 2# 将处理后的音频数据写入输出流stream.write(amplified_data.tobytes())
在接下来的部分,我们将深入研究PyAudio的更多功能,包括音频流的高级处理和与其他库的更复杂集成。
3. Sounddevice
3.1 高级音频输入/输出
Sounddevice是一个用于高级音频输入和输出的Python库,支持低延迟和实时音频流处理。以下是一个简单的实时音频播放的例子:
import sounddevice as sd # 配置音频参数
duration = 10 # 播放时长(秒)
fs = 44100 # 采样率# 生成音频数据
t = np.linspace(0, duration, int(fs * duration), endpoint=False)
audio_data = 0.5 * np.sin(2 * np.pi * 440.0 * t)# 播放音频
sd.play(audio_data, fs)
sd.wait()
3.2 低延迟音频流
Sounddevice支持低延迟的音频流,适用于需要实时反馈的应用,如音频处理和实时音乐演奏。以下是一个简单的实时录音和播放的例子:
import sounddevice as sd# 配置音频参数
duration = 5 # 录音时长(秒)
fs = 44100 # 采样率# 录制音频
recording = sd.rec(int(duration * fs), samplerate=fs, channels=2, dtype=np.int16)
sd.wait()# 播放录制的音频
sd.play(recording, fs)
sd.wait()
3.3 设备配置与控制
Sounddevice允许用户配置和控制音频输入和输出设备。以下是一个例子,演示如何列出可用的音频设备和切换输入设备:
import sounddevice as sd# 列出可用的输入设备
input_devices = sd.query_devices(kind='input')
print("Available Input Devices:")
for i, device in enumerate(input_devices):print(f"{i + 1}. {device['name']}")# 选择输入设备
selected_device_index = int(input("Enter the number of the input device you want to use: ")) - 1# 配置音频参数
duration = 5 # 录音时长(秒)
fs = 44100 # 采样率# 录制音频使用指定的输入设备
recording = sd.rec(int(duration * fs), samplerate=fs, channels=2, dtype=np.int16, device=input_devices[selected_device_index]['name'])
sd.wait()
3.4 实时音频应用
Sounddevice可用于实现各种实时音频应用,如音频处理、实时效果处理等。以下是一个简单的实时音频效果处理的例子:
import sounddevice as sd
import numpy as np# 配置音频参数
duration = 10 # 播放时长(秒)
fs = 44100 # 采样率# 生成音频数据
t = np.linspace(0, duration, int(fs * duration), endpoint=False)
audio_data = 0.5 * np.sin(2 * np.pi * 440.0 * t)# 自定义效果处理函数
def custom_effect(indata, frames, time, status):# 示例效果:音频数据乘以2outdata = indata * 2return outdata# 播放音频并应用效果处理
with sd.Stream(callback=custom_effect):sd.play(audio_data, fs)sd.wait()
3.5 实时音频可视化
Sounddevice结合Matplotlib可以实现实时音频可视化。以下是一个简单的例子,演示如何实时绘制录制的音频波形:
import sounddevice as sd
import matplotlib.pyplot as plt
import numpy as np# 配置音频参数
duration = 5 # 录音时长(秒)
fs = 44100 # 采样率# 初始化Matplotlib图形
fig, ax = plt.subplots()
x = np.arange(0, duration, 1/fs)
line, = ax.plot(x, np.random.rand(len(x)))# 自定义回调函数,用于更新图形
def update_plot(indata, frames, time, status):line.set_ydata(indata[:, 0]) # 仅使用左声道的数据更新图形fig.canvas.draw()fig.canvas.flush_events()# 打开音频流,实时绘制波形
with sd.InputStream(callback=update_plot, channels=2, samplerate=fs):plt.show()
3.6 实时音频频谱分析
结合Sounddevice和Matplotlib,可以实现实时音频频谱分析。以下是一个简单的例子,演示如何实时绘制录制的音频的频谱图:
import sounddevice as sd
import matplotlib.pyplot as plt
import numpy as np# 配置音频参数
duration = 10 # 录音时长(秒)
fs = 44100 # 采样率# 初始化Matplotlib图形
fig, ax = plt.subplots()
x = np.fft.fftfreq(int(fs * duration), 1/fs)
line, = ax.semilogx(x, np.random.rand(len(x)))# 自定义回调函数,用于更新图形
def update_plot(indata, frames, time, status):# 计算FFTspectrum = np.abs(np.fft.fft(indata[:, 0])) / len(indata)line.set_ydata(spectrum)fig.canvas.draw()fig.canvas.flush_events()# 打开音频流,实时绘制频谱图
with sd.InputStream(callback=update_plot, channels=2, samplerate=fs):plt.show()
3.7 实时音频中的数字信号处理
Sounddevice与NumPy和SciPy等库结合,可以进行数字信号处理。以下是一个简单的例子,演示如何在实时音频中应用数字滤波器:
import sounddevice as sd
import numpy as np
from scipy.signal import butter, lfilter# 配置音频参数
duration = 10 # 录音时长(秒)
fs = 44100 # 采样率# 初始化Butterworth滤波器
order = 4
lowcut = 1000 # 低通滤波截止频率
highcut = 4000 # 高通滤波截止频率
b, a = butter(order, [lowcut, highcut], btype='band', fs=fs)# 自定义回调函数,用于应用数字滤波器
def filter_callback(indata, frames, time, status):# 应用滤波器filtered_data = lfilter(b, a, indata[:, 0])sd.play(filtered_data, fs)# 打开音频流,实时应用数字滤波器
with sd.InputStream(callback=filter_callback, channels=1, samplerate=fs):sd.sleep(int(duration * 1000))
4. Audacity
4.1 Audacity概述
Audacity是一款自由开源的音频编辑软件,支持跨平台运行,具备多轨编辑、效果处理和录音等功能。通过Audacity,用户可以自由处理各种音频文件,无论是简单的剪切合并还是复杂的音频编辑任务。
4.2 音频编辑与操作
Audacity提供了直观友好的音频编辑界面,支持用户对音频进行剪切、复制、粘贴等基本操作。以下是一个简单的示例,演示如何使用Audacity进行基本的音频编辑:
# 导入pyautogui库
import pyautogui
import time# 打开Audacity并打开音频文件
# 这里假设已经打开了Audacity软件并加载了音频文件# 选中要编辑的音频区域
pyautogui.hotkey('ctrl', 'a')# 复制选中区域
pyautogui.hotkey('ctrl', 'c')# 在新位置粘贴复制的音频
pyautogui.hotkey('ctrl', 'v')# 保存编辑后的音频文件
pyautogui.hotkey('ctrl', 's')# 等待保存完成
time.sleep(2)
4.3 多轨编辑
Audacity的多轨编辑功能使用户能够同时处理多个音频轨道,创造出更加丰富的音频作品。以下是一个简单的多轨编辑的例子,演示如何在Audacity中进行多轨音频编辑:
# 导入pyautogui库
import pyautogui
import time# 打开Audacity并打开音频文件
# 这里假设已经打开了Audacity软件并加载了多个音频文件# 选中要编辑的多个音轨
# 这里假设有两个音轨,需要手动操作选中# 复制选中的音轨
pyautogui.hotkey('ctrl', 'c')# 在新位置粘贴复制的音轨
pyautogui.hotkey('ctrl', 'v')# 保存编辑后的音频文件
pyautogui.hotkey('ctrl', 's')# 等待保存完成
time.sleep(2)
4.4 音频效果与插件
Audacity内置了各种音频效果和插件,使用户能够通过简单的操作就能实现复杂的音频处理效果。以下是一个简单的例子,演示如何在Audacity中应用音频效果:
# 导入pyautogui库
import pyautogui
import time# 打开Audacity并打开音频文件
# 这里假设已经打开了Audacity软件并加载了音频文件# 选择要应用效果的音频区域
pyautogui.hotkey('ctrl', 'a')# 打开Audacity效果菜单
pyautogui.hotkey('alt', 'e')# 选择要应用的音频效果
# 这里假设选择了淡入效果(Fade In)# 保存编辑后的音频文件
pyautogui.hotkey('ctrl', 's')# 等待保存完成
time.sleep(2)
5. SpeechRecognition
5.1 语音转文本
SpeechRecognition是一个用于语音识别的Python库,支持多种语音识别引擎。以下是一个简单的语音转文本的例子,演示如何使用SpeechRecognition进行语音识别:
import speech_recognition as sr# 初始化Recognizer
recognizer = sr.Recognizer()# 打开麦克风
with sr.Microphone() as source:print("Say something:")audio = recognizer.listen(source)# 使用Google Web Speech API进行语音识别
try:print("Google Web Speech API thinks you said: " + recognizer.recognize_google(audio))
except sr.UnknownValueError:print("Google Web Speech API could not understand audio")
except sr.RequestError as e:print("Could not request results from Google Web Speech API; {0}".format(e))
5.2 使用不同语音识别引擎
SpeechRecognition支持多种语音识别引擎,包括Google Web Speech API、Microsoft Bing Voice Recognition等。以下是一个演示如何使用不同引擎的例子:
import speech_recognition as sr# 初始化Recognizer
recognizer = sr.Recognizer()# 打开麦克风
with sr.Microphone() as source:print("Say something:")audio = recognizer.listen(source)# 使用Google Web Speech API进行语音识别
try:print("Google Web Speech API thinks you said: " + recognizer.recognize_google(audio))
except sr.UnknownValueError:print("Google Web Speech API could not understand audio")
except sr.RequestError as e:print("Could not request results from Google Web Speech API; {0}".format(e))# 使用Microsoft Bing Voice Recognition进行语音识别
try:print("Microsoft Bing Voice Recognition thinks you said: " + recognizer.recognize_bing(audio, key="YOUR_BING_API_KEY"))
except sr.UnknownValueError:print("Microsoft Bing Voice Recognition could not understand audio")
except sr.RequestError as e:print("Could not request results from Microsoft Bing Voice Recognition; {0}".format(e))
5.3 语言支持与配置
SpeechRecognition支持多种语言,用户可以通过配置语言参数来实现对不同语言的语音识别。以下是一个简单的例子:
import speech_recognition as sr# 初始化Recognizer
recognizer = sr.Recognizer()# 打开麦克风
with sr.Microphone() as source:print("Say something:")audio = recognizer.listen(source)# 使用Google Web Speech API进行法语语音识别
try:print("Google Web Speech API (French) thinks you said: " + recognizer.recognize_google(audio, language="fr-FR"))
except sr.UnknownValueError:print("Google Web Speech API could not understand audio")
except sr.RequestError as e:print("Could not request results from Google Web Speech API; {0}".format(e))
5.4 将语音识别集成到应用中
SpeechRecognition可以轻松集成到各种应用中,例如语音助手、语音命令控制等。以下是一个简单的例子,演示如何将语音识别集成到应用中:
import speech_recognition as srdef recognize_speech():# 初始化Recognizerrecognizer = sr.Recognizer()# 打开麦克风with sr.Microphone() as source:print("Say something:")audio = recognizer.listen(source)# 使用Google Web Speech API进行语音识别try:return recognizer.recognize_google(audio)except sr.UnknownValueError:return "Could not understand audio"except sr.RequestError as e:return "Could not request results from Google Web Speech API; {0}".format(e)# 调用语音识别函数
result = recognize_speech()
print("Speech Recognition Result: " + result)
5.5 实时语音识别
SpeechRecognition可以结合实时音频流进行实时语音识别。以下是一个简单的实时语音识别的例子,结合Sounddevice库:
import sounddevice as sd
import speech_recognition as sr# 初始化Recognizer
recognizer = sr.Recognizer()# 自定义回调函数,用于实时语音识别
def realtime_speech_recognition(indata, frames, time, status):try:# 将音频数据转为语音文本text = recognizer.recognize_google(indata[:, 0])print(f"Real-time Speech Recognition: {text}")except sr.UnknownValueError:pass # 忽略无法识别的音频片段except sr.RequestError as e:print(f"Error in real-time speech recognition: {e}")# 打开音频流,实时进行语音识别
with sd.InputStream(callback=realtime_speech_recognition, channels=1, samplerate=44100):sd.sleep(10000) # 运行10秒,可以根据需求调整
5.6 语音合成
除了语音识别,SpeechRecognition还支持语音合成,可以将文本转为语音。以下是一个简单的语音合成的例子,使用Google Text-to-Speech引擎:
from gtts import gTTS
import IPython.display as ipd# 要转为语音的文本
text_to_speak = "Hello, welcome to the world of speech synthesis."# 使用Google Text-to-Speech引擎生成语音
tts = gTTS(text_to_speak)
tts.save("output.mp3")# 播放生成的语音
ipd.Audio("output.mp3")
5.7 自定义语法规则
SpeechRecognition允许用户定义自己的语法规则,以更精确地匹配和理解语音输入。以下是一个简单的例子,演示如何使用自定义语法规则:
import speech_recognition as sr# 初始化Recognizer
recognizer = sr.Recognizer()# 定义自定义语法规则
custom_grammar = sr.Grammar('custom_grammar','command = move | stop | turn | jump\n''direction = left | right | up | down\n''move = go direction\n'
)# 打开麦克风
with sr.Microphone() as source:print("Say a command:")audio = recognizer.listen(source)# 使用自定义语法规则进行语音识别
try:result = recognizer.recognize_sphinx(audio, grammar=custom_grammar)print("Custom Grammar Result: " + result)
except sr.UnknownValueError:print("Could not understand audio")
except sr.RequestError as e:print("Could not request results from Sphinx; {0}".format(e))
5.8 多语言支持
SpeechRecognition支持多种语言,用户可以通过配置语言参数来进行多语言的语音识别。以下是一个例子:
import speech_recognition as sr# 初始化Recognizer
recognizer = sr.Recognizer()# 打开麦克风
with sr.Microphone() as source:print("Dites quelque chose:")audio = recognizer.listen(source)# 使用Google Web Speech API进行法语语音识别
try:print("Google Web Speech API (French) thinks you said: " + recognizer.recognize_google(audio, language="fr-FR"))
except sr.UnknownValueError:print("Google Web Speech API could not understand audio")
except sr.RequestError as e:print("Could not request results from Google Web Speech API; {0}".format(e))
在接下来的内容中,我们将进一步研究SpeechRecognition的高级功能,包括语音识别结果的处理、音频数据的实时处理等。
6. Wave
6.1 Wave库简介
Wave是Python标准库中用于读写WAV格式音频文件的模块,提供了对音频文件进行基本操作的功能。
6.2 波形处理与分析
Wave库可以用于读取音频文件的波形数据,并进行分析。以下是一个简单的例子,演示如何读取WAV文件并绘制波形图:
import wave
import numpy as np
import matplotlib.pyplot as plt# 读取WAV文件
wav_path = "example.wav"
with wave.open(wav_path, 'rb') as wav_file:# 获取波形数据frames = wav_file.readframes(-1)signal = np.frombuffer(frames, dtype=np.int16)# 获取采样率和帧数framerate = wav_file.getframerate()duration = len(signal) / framerate# 绘制波形图plt.plot(np.linspace(0, duration, len(signal)), signal)plt.title('Waveform')plt.xlabel('Time (s)')plt.ylabel('Amplitude')plt.show()
6.3 音频文件读写
Wave库支持音频文件的读写操作,用户可以使用Wave库创建新的WAV文件或修改现有文件。以下是一个简单的例子,演示如何创建一个简单的WAV文件:
import wave
import numpy as np# 配置音频参数
framerate = 44100
duration = 5
amplitude = 0.5
frequency = 440.0# 生成音频数据
t = np.linspace(0, duration, int(framerate * duration), endpoint=False)
audio_data = amplitude * np.sin(2 * np.pi * frequency * t)# 写入WAV文件
with wave.open("generated_audio.wav", 'wb') as wav_file:wav_file.setnchannels(1)wav_file.setsampwidth(2)wav_file.setframerate(framerate)wav_file.writeframes((audio_data * 32767).astype(np.int16).tobytes())
6.4 音频信号生成和合成
Wave库可以用于生成和合成音频信号。以下是一个简单的例子,演示如何生成两个音频信号并将它们合成为一个新的WAV文件:
import wave
import numpy as np# 配置音频参数
framerate = 44100
duration = 5
amplitude1 = 0.3
frequency1 = 440.0
amplitude2 = 0.5
frequency2 = 660.0# 生成两个音频信号
t = np.linspace(0, duration, int(framerate * duration), endpoint=False)
signal1 = amplitude1 * np.sin(2 * np.pi * frequency1 * t)
signal2 = amplitude2 * np.sin(2 * np.pi * frequency2 * t)# 合成音频信号
composite_signal = signal1 + signal2# 写入WAV文件
with wave.open("composite_audio.wav", 'wb') as wav_file:wav_file.setnchannels(1)wav_file.setsampwidth(2)wav_file.setframerate(framerate)wav_file.writeframes((composite_signal * 32767).astype(np.int16).tobytes())
6.5 音频剪切与拼接
Wave库支持对音频进行剪切和拼接的操作,用户可以选择保留或丢弃特定时间段的音频。以下是一个简单的例子,演示如何剪切和拼接音频:
import wave
import numpy as np# 读取WAV文件
input_wav_path = "input_audio.wav"
with wave.open(input_wav_path, 'rb') as wav_file:# 获取波形数据frames = wav_file.readframes(-1)signal = np.frombuffer(frames, dtype=np.int16)# 获取采样率和帧数framerate = wav_file.getframerate()# 定义剪切时间段(单位:秒)
start_time = 2
end_time = 4# 计算剪切对应的帧数
start_frame = int(start_time * framerate)
end_frame = int(end_time * framerate)# 进行音频剪切
clipped_signal = signal[start_frame:end_frame]# 写入新的WAV文件
output_wav_path = "clipped_audio.wav"
with wave.open(output_wav_path, 'wb') as wav_file:wav_file.setnchannels(1)wav_file.setsampwidth(2)wav_file.setframerate(framerate)wav_file.writeframes((clipped_signal * 32767).astype(np.int16).tobytes())
6.6 音频采样与重采样
Wave库提供了音频采样和重采样的功能,用户可以根据需要调整音频的采样率。以下是一个简单的例子,演示如何进行音频重采样:
import wave
import numpy as np
from scipy.signal import resample# 读取WAV文件
input_wav_path = "input_audio.wav"
with wave.open(input_wav_path, 'rb') as wav_file:# 获取波形数据frames = wav_file.readframes(-1)signal = np.frombuffer(frames, dtype=np.int16)# 获取采样率original_framerate = wav_file.getframerate()# 设置目标采样率
target_framerate = 22050# 进行音频重采样
resampled_signal = resample(signal, int(len(signal) * target_framerate / original_framerate))# 写入新的WAV文件
output_wav_path = "resampled_audio.wav"
with wave.open(output_wav_path, 'wb') as wav_file:wav_file.setnchannels(1)wav_file.setsampwidth(2)wav_file.setframerate(target_framerate)wav_file.writeframes((resampled_signal * 32767).astype(np.int16).tobytes())
7. SciPy
7.1 科学计算与信号处理
SciPy是一个用于科学计算的Python库,提供了许多功能强大的模块,其中包括信号处理模块。以下是一个简单的例子,演示如何使用SciPy进行信号处理:
import scipy.signal
import numpy as np
import matplotlib.pyplot as plt# 配置信号参数
fs = 1000 # 采样率
t = np.linspace(0, 1, fs, endpoint=False) # 时间序列# 生成包含两个频率成分的信号
signal = np.sin(2 * np.pi * 5 * t) + 0.5 * np.sin(2 * np.pi * 20 * t)# 设计低通滤波器
b, a = scipy.signal.butter(N=4, Wn=15, btype='low', fs=fs)# 应用滤波器
filtered_signal = scipy.signal.filtfilt(b, a, signal)# 绘制原始信号和滤波后的信号
plt.figure(figsize=(10, 6))plt.subplot(2, 1, 1)
plt.plot(t, signal)
plt.title('Original Signal')
plt.xlabel('Time (s)')
plt.ylabel('Amplitude')plt.subplot(2, 1, 2)
plt.plot(t, filtered_signal)
plt.title('Filtered Signal')
plt.xlabel('Time (s)')
plt.ylabel('Amplitude')plt.tight_layout()
plt.show()
7.2 滤波器设计与应用
SciPy的信号处理模块提供了丰富的滤波器设计和应用功能。以下是一个简单的例子,演示如何设计一个带通滤波器并应用于信号:
import scipy.signal
import numpy as np
import matplotlib.pyplot as plt# 配置信号参数
fs = 1000 # 采样率
t = np.linspace(0, 1, fs, endpoint=False) # 时间序列# 生成包含两个频率成分的信号
signal = np.sin(2 * np.pi * 5 * t) + 0.5 * np.sin(2 * np.pi * 20 * t)# 设计带通滤波器
b, a = scipy.signal.butter(N=4, Wn=[10, 25], btype='band', fs=fs)# 应用滤波器
filtered_signal = scipy.signal.filtfilt(b, a, signal)# 绘制原始信号和滤波后的信号
plt.figure(figsize=(10, 6))plt.subplot(2, 1, 1)
plt.plot(t, signal)
plt.title('Original Signal')
plt.xlabel('Time (s)')
plt.ylabel('Amplitude')plt.subplot(2, 1, 2)
plt.plot(t, filtered_signal)
plt.title('Filtered Signal (Bandpass Filter)')
plt.xlabel('Time (s)')
plt.ylabel('Amplitude')plt.tight_layout()
plt.show()
7.3 快速傅里叶变换(FFT)
SciPy提供了用于进行快速傅里叶变换(FFT)的模块,用于频谱分析和频域处理。以下是一个简单的FFT示例:
import scipy.fft
import numpy as np
import matplotlib.pyplot as plt# 配置信号参数
fs = 1000 # 采样率
t = np.linspace(0, 1, fs, endpoint=False) # 时间序列# 生成包含两个频率成分的信号
signal = np.sin(2 * np.pi * 5 * t) + 0.5 * np.sin(2 * np.pi * 20 * t)# 进行FFT
frequencies = np.fft.fftfreq(len(signal), 1/fs)
fft_values = np.fft.fft(signal)# 绘制频谱图
plt.plot(frequencies, np.abs(fft_values))
plt.title('FFT - Frequency Spectrum')
plt.xlabel('Frequency (Hz)')
plt.ylabel('Amplitude')
plt.show()
7.4 频谱分析和频域处理
SciPy的信号处理模块支持频谱分析和频域处理。以下是一个简单的例子,演示如何计算信号的功率谱密度:
import scipy.signal
import numpy as np
import matplotlib.pyplot as plt# 配置信号参数
fs = 1000 # 采样率
t = np.linspace(0, 1, fs, endpoint=False) # 时间序列# 生成包含两个频率成分的信号
signal = np.sin(2 * np.pi * 5 * t) + 0.5 * np.sin(2 * np.pi * 20 * t)# 计算功率谱密度
frequencies, power_spectrum_density = scipy.signal.welch(signal, fs, nperseg=256)# 绘制功率谱密度图
plt.semilogy(frequencies, power_spectrum_density)
plt.title('Power Spectral Density')
plt.xlabel('Frequency (Hz)')
plt.ylabel('Power/Frequency (dB/Hz)')
plt.show()
7.5 时频分析与小波变换
SciPy的信号处理模块还支持时频分析和小波变换,这在处理非平稳信号时非常有用。以下是一个简单的时频分析和小波变换的例子:
import scipy.signal
import numpy as np
import matplotlib.pyplot as plt# 配置信号参数
fs = 1000 # 采样率
t = np.linspace(0, 1, fs, endpoint=False) # 时间序列# 生成非平稳信号
signal = np.sin(2 * np.pi * 5 * t * (1 + np.sin(2 * np.pi * 2 * t)))# 进行小波变换
cwtmatr = scipy.signal.cwt(signal, scipy.signal.ricker, np.arange(1, 31))# 绘制时频分析图
plt.imshow(np.abs(cwtmatr), extent=[0, 1, 1, 31], aspect='auto', cmap='jet', vmax=abs(cwtmatr).max(), vmin=-abs(cwtmatr).max())
plt.colorbar(label='Magnitude')
plt.title('Time-Frequency Analysis with Continuous Wavelet Transform')
plt.xlabel('Time (s)')
plt.ylabel('Scale')
plt.show()
7.6 滤波器组设计
在一些信号处理任务中,可能需要设计并应用一组滤波器,以满足特定的要求。以下是一个示例,演示如何设计一组滤波器组并应用于信号:
import scipy.signal
import numpy as np
import matplotlib.pyplot as plt# 配置信号参数
fs = 1000 # 采样率
t = np.linspace(0, 1, fs, endpoint=False) # 时间序列# 生成包含两个频率成分的信号
signal = np.sin(2 * np.pi * 5 * t) + 0.5 * np.sin(2 * np.pi * 20 * t)# 设计一组带通滤波器
frequencies = [5, 10, 15, 20]
b, a = scipy.signal.iirfilter(N=4, Wn=[f / (fs / 2) for f in frequencies], btype='band')# 应用滤波器
filtered_signal = scipy.signal.filtfilt(b, a, signal)# 绘制原始信号和滤波后的信号
plt.figure(figsize=(10, 6))plt.subplot(2, 1, 1)
plt.plot(t, signal)
plt.title('Original Signal')
plt.xlabel('Time (s)')
plt.ylabel('Amplitude')plt.subplot(2, 1, 2)
plt.plot(t, filtered_signal)
plt.title('Filtered Signal (Bandpass Filter Group)')
plt.xlabel('Time (s)')
plt.ylabel('Amplitude')plt.tight_layout()
plt.show()
在接下来的内容中,我们将深入学习SciPy信号处理模块中的其他功能,包括系统响应计算、频率响应计算等。
总结
本文通过详细介绍各种Python库的功能和应用,使读者对音频与信号处理领域的技术有了更为全面的了解。不论是音频分析的初学者还是专业从业者,都能在本文中找到合适的学习路径。这些库的结合使用展示了多种复杂任务的解决方案,为读者提供了灵活而强大的工具,激发了进一步探索音频技术的兴趣。
相关文章:

【Python百宝箱】音韵探奇:探索Python中的音频与信号魔法
数字音符:畅游Python音频与信号处理的科技奇境 前言 在数字时代,音频与信号处理不仅仅是专业领域的关键,也成为了科技创新和艺术创作的核心。本文将带领您深入探索Python中多个强大的音频处理库和信号处理工具,从Librosa到Tenso…...

springboot(ssm农产品直卖平台 农产品商城系统Java系统
springboot(ssm农产品直卖平台 农产品商城系统Java系统 开发语言:Java 框架:ssm/springboot vue JDK版本:JDK1.8(或11) 服务器:tomcat 数据库:mysql 5.7(或8.0) 数…...

C#编程-使用条件构造
使用条件构造 作判定是人的基本能力。判定也是可收编进程序。这有助于确定程序执行指令的顺序。 您可用条件构造来控制程序的流程。条件构造允许您基于被求职的表达式的结果来执行选定语句。 可以包含在C#程序中的各种条件构造是: if…else 构造switch…case 构造if…else构…...
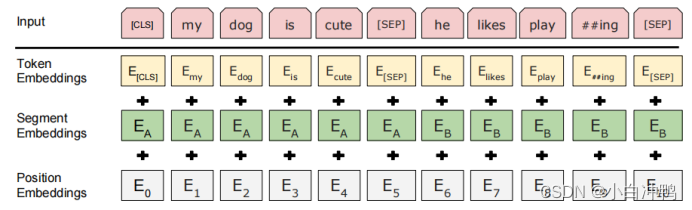
【BERT】深入理解BERT模型1——模型整体架构介绍
前言 BERT出自论文:《BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding》 2019年 近年来,在自然语言处理领域,BERT模型受到了极为广泛的关注,很多模型中都用到了BERT-base或者是BE…...

【Java开发岗面试】八股文—设计模式
声明: 背景:本人为24届双非硕校招生,已经完整经历了一次秋招,拿到了三个offer。本专题旨在分享自己的一些Java开发岗面试经验(主要是校招),包括我自己总结的八股文、算法、项目介绍、HR面和面试…...
、临界资源安全问题(锁、channel))
GO基础进阶篇 (九)、临界资源安全问题(锁、channel)
临界资源安全问题 在并发编程中对临界资源的处理不当,往往会导致数据的不一致问题 package mainimport ("fmt""time" )func main() {a : 1go func() {a 2fmt.Println("goroutine", a)}()a 3fmt.Println("a", a)time.Sl…...
)
Python基础-04(比较运算符、逻辑运算符)
文章目录 前言一、比较运算符二、逻辑运算符1.and(与)2.or(或)3.not(非)4.逻辑运算符的细节(短路原则)(着重理解) 总结 前言 1、比较运算符内容很简单&#…...

MySQL 四种插入命令及其特点与锁机制
目录 1. INSERT INTO 2. INSERT IGNORE INTO 3. INSERT INTO ... ON DUPLICATE KEY UPDATE 4. REPLACE INTO 总结 MySQL提供了多种数据插入方式,每种方式在处理唯一键冲突时的行为不同,同时也涉及不同的锁机制。 1. INSERT INTO INSERT INTO是标准…...

AKShare学习笔记
AKShare学习笔记 本文内容参考AKShare文档。AKShare开源财经数据接口库采集的数据都来自公开的数据源,数据接口查询出来的数据具有滞后性。接口参考AKShare数据字典。 AKShare环境配置 安装Anaconda,使用Anaconda3-2019.07版本包,配置清华数…...

A星寻路算法
A星寻路算法简介 A星寻路算法(A* Search Algorithm)是一种启发式搜索算法,它在图形平面上进行搜索,寻找从起始点到终点的最短路径。A星算法结合了广度优先搜索(BFS)和最佳优先搜索(Best-First S…...
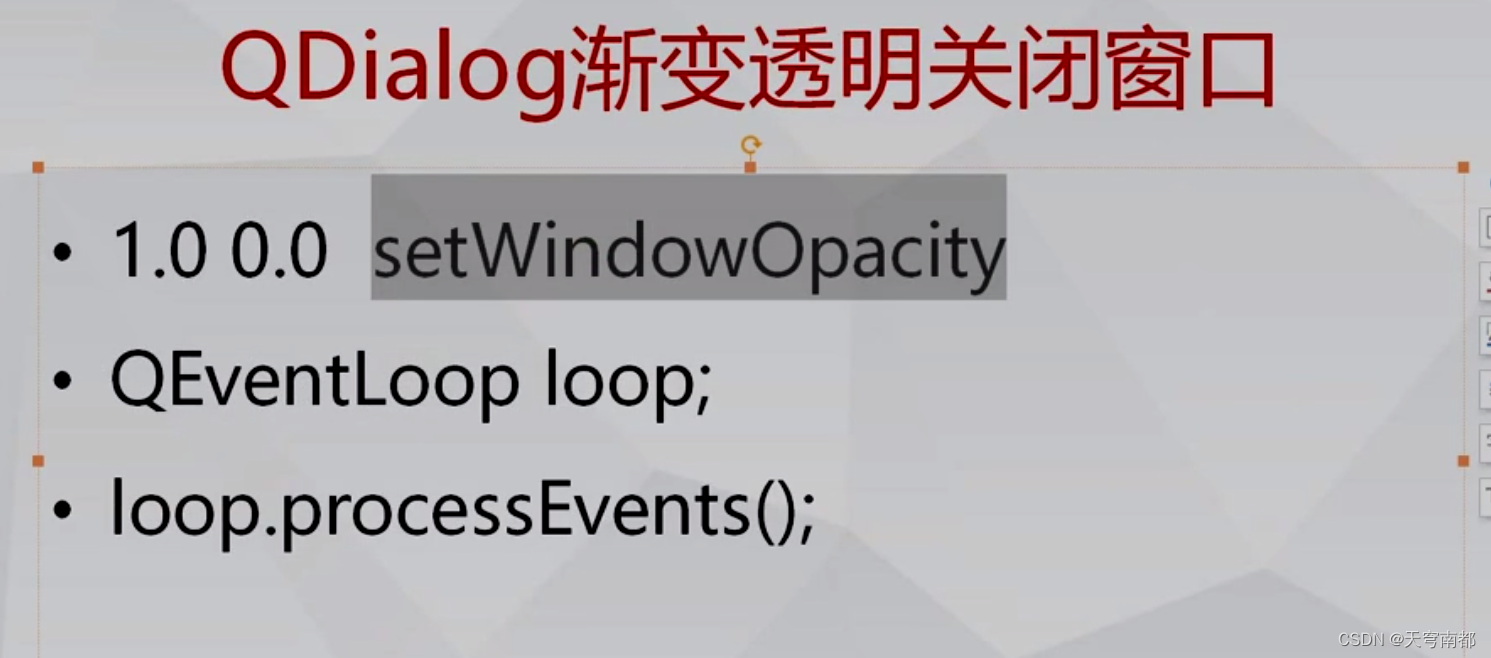
QDialog
属性方法 样式表 background-color: qlineargradient(spread:reflect, x1:0.999896, y1:0.494136, x2:1, y2:1, stop:0 rgba(0, 0, 0, 255), stop:1 rgba(255, 255, 255, 255));border: 1px groove rgb(232, 232, 232);border-radius: 20px; QDialog 的常用方法: e…...
Spark中使用DataFrame进行数据转换和操作
Apache Spark是一个强大的分布式计算框架,其中DataFrame是一个核心概念,用于处理结构化数据。DataFrame提供了丰富的数据转换和操作功能,使数据处理变得更加容易和高效。本文将深入探讨Spark中如何使用DataFrame进行数据转换和操作࿰…...
windows11新装机,简单评测系统自带软件(基本涵盖日常所需应用)
新年将近,由于当年安排的失误,系统盘(100G)和照片视频盘(4T)容量不够了,大容量的那块机械盘放在机箱里就在耳朵根吵吵,烦得很,于是狠狠心决定扩容后重配重装。 2023年最后…...

概念解析 | Shapley值及其在深度学习中的应用
注1:本文系“概念解析”系列之一,致力于简洁清晰地解释、辨析复杂而专业的概念。本次辨析的概念是:Shapley值及其在深度学习中的应用。 1 背景介绍 在机器学习和数据分析中,理解模型的预测是非常重要的。尤其是在深度学习黑盒模型中,我们往往难以直观地理解模型的预测行为。为…...

ajax的完整写法——success/error/complete+then/catch/done+设置请求头两种方法——基础积累
ajax的完整写法——success/error/completethen/catch/done设置请求头两种方法——基础积累 1.完整写法——success/error/complete1.1 GET/DELETE——query传参1.2 GET/DELETE——JSON对象传参1.3 PUT/POST——JSON对象传参 2.简化写法——then/catch/done2.1 GET/DELETE——q…...

《Linux详解:深入探讨计算机基础》
《Linux详解:深入探讨计算机基础》 引言: 在计算机科学领域,操作系统是一个至关重要的概念,而Linux作为一种开源的Unix-like操作系统,不仅在服务器领域广泛应用,也在嵌入式系统、超级计算机等多个领域发挥…...
HarmonyOS 实践之应用状态变量共享
平时在开发的过程中,我们会在应用中共享数据,在不同的页面间共享信息。虽然常用的共享信息,也可以通过不同页面中组件间信息共享的方式,但有时使用应用级别的状态管理会让开发工作变得简单。 根据不同的使用场景,ArkTS…...

ThreadLocal共享变量
一、ThreadLocal 我们知道多线程访问同一个共享变量时,会出现线程安全问题,为了保证线程安全开发者需要对共享变量的访问操作进行适当的同步操作,如加锁等同步操作。 除此之外,Java提供了ThreadLocal类,当一个共享变…...

前端crypto-js 库: MD5
文章目录 什么是crypto-js安装依赖MD5 什么是crypto-js github地址: https://github.com/brix/crypto-js cryptojs文档: https://cryptojs.gitbook.io/docs/#encoders CryptoJS (crypto.js) 为 JavaScript 提供了各种各样的加密算法。 CryptoJS是一个JavaScript加密算法库&a…...

2024新年快乐
2024-1-1 祝福大家和自己健康喜乐,升职加薪,新年快乐 页面加载事件load 我们页面加载事件的触发是等所有的资源加载完毕时触发该事件。和click一样是事件,但是触发时机是等资源加载(浏览器)完毕。这个事件我们可以将…...

HTML图片怎么在Firefox中调试对齐_Firefox开发者工具调图方法.txt
连接数爆满主因是线程卡住而非数量多,应重点关注SHOW FULL PROCESSLIST中State非Sleep且Time>60秒的阻塞线程,优先排查应用端连接未释放、监控脚本高频查询及本地进程异常连接。直接看 SHOW PROCESSLIST 里哪些线程在“卡住”连接数爆满&…...

ARM TLBIP指令解析与应用实践
1. ARM TLBIP指令深度解析在ARMv8/v9架构中,TLB(Translation Lookaside Buffer)作为内存管理单元(MMU)的核心组件,负责缓存虚拟地址到物理地址的转换结果。当页表发生变更时,必须及时使TLB中对应的缓存条目失效,以确保内存访问的正…...

深度架构解析:深圳地铁大数据客流分析系统的技术演进与架构哲学
深度架构解析:深圳地铁大数据客流分析系统的技术演进与架构哲学 【免费下载链接】SZT-bigdata 深圳地铁大数据客流分析系统🚇🚄🌟 项目地址: https://gitcode.com/gh_mirrors/sz/SZT-bigdata 在智慧城市建设的浪潮中&#…...

从芯片选型到PCB布线:手把手拆解基于Zynq-7100的10Gbps雷达数据采集卡硬件设计
从芯片选型到PCB布线:Zynq-7100雷达数据采集卡硬件设计实战 在高速数据采集领域,10Gbps量级的实时信号处理对硬件设计提出了严苛挑战。当我们面对雷达回波、医学影像或工业检测等场景时,传统采集方案往往在吞吐量、延迟和同步精度上捉襟见肘。…...

用 IDENTITY 数据销毁对象处理个人数据销毁,SAP ILM 场景下的信息检索与合规闭环
做 SAP 系统里的个人数据治理,最怕的不是删除动作本身,而是删除之前没有把数据的来源、用途、保留规则、可检索性和审计链路讲清楚。一个系统里只要出现客户、联系人、消费者、会员、订阅人、业务伙伴、技术访问账号等身份相关对象,围绕这些对象产生的姓名、邮箱、手机号、登…...

基于Telegram的AI智能体框架:从原理到实践部署指南
1. 项目概述:一个基于Telegram的AI智能体框架最近在GitHub上看到一个挺有意思的项目,叫openclaw-telegram-ai-agent。光看名字,你大概能猜到它是个什么东西:一个运行在Telegram平台上的AI智能体(Agent)。但…...

SystemVerilog中logic数据类型:统一reg与wire的设计实践
1. 项目概述:从“reg”到“logic”的思维跃迁如果你写过Verilog,那么对reg和wire这两个数据类型一定再熟悉不过了。在RTL设计的世界里,我们习惯了用reg来描述寄存器,用wire来描述连线,这几乎成了一种肌肉记忆。但当你开…...

【C语言之 CJson】从零到一:构建与解析JSON的实战指南
1. 为什么C语言需要处理JSON数据 在物联网设备和嵌入式系统开发中,JSON已经成为事实上的数据交换标准。我去年参与的一个智能家居项目就深有体会:设备配置、状态上报、控制指令全都采用JSON格式传输。用C语言处理这些数据时,手动拼接字符串不…...
)
别再只做静态分析了!用DPABI探索小鼠大脑rs-fMRI的动态功能连接(含Matlab代码片段)
动态功能连接分析:解锁小鼠大脑rs-fMRI的时变奥秘 在神经影像研究领域,静息态功能磁共振成像(rs-fMRI)已成为探索大脑功能组织的强大工具。传统静态分析方法虽然提供了宝贵的基础认知,但大脑本质上是一个动态系统,其功能连接会随时…...

PangoDesign Suite与Modelsim协同仿真:从库编译到实战排错全解析
1. 为什么需要PangoDesign Suite与Modelsim协同仿真 第一次接触FPGA仿真时,我也被各种专业术语绕晕了。直到某次项目出现时序问题,才发现仿真工具就像汽车的"安全气囊"——平时感觉不到存在,关键时刻能救命。PangoDesign Suite&…...